Uber提出损失变化分配方法LCA,揭秘神经网络“黑盒”

【导读】神经网络(Neural networks,NN)在过去十年来硕果累累,推动了整个行业的机器学习进程。然而,虽然许多神经网络在一些任务中表现相当出色,但网络本质上是一个复杂的系统,之前的研究已经分析了神经网络训练的过程,但它在很大程度上仍然是一个黑盒子,我们对其训练和操作模式仍然知之甚少。因此,产学研界都在为更好地理解网络属性和模型预测而不懈努力。针对这个问题,Uber 在论文中提出了一种称为损失变化分配 (Loss Change Allocation,LCA)的方法,为神经网络训练过程提供了丰富的观察窗口,有望提高神经网络的可解释性。

- 如果参数具有零梯度或者不移动,那么它的 LCA 为零,如图 1b 所示。
- 如果参数具有非零梯度并沿着负梯度方向移动,那么它具有负 LCA,如图 1c 所示。Uber 称这些参数为“帮助”,因为它们减少了迭代中的损失。
- 如果参数沿着梯度的正方向移动,它就会因为增加损失而“受伤”。这可能是由于嘈杂的小批量或动量导致的参数移动错误方向引起的。
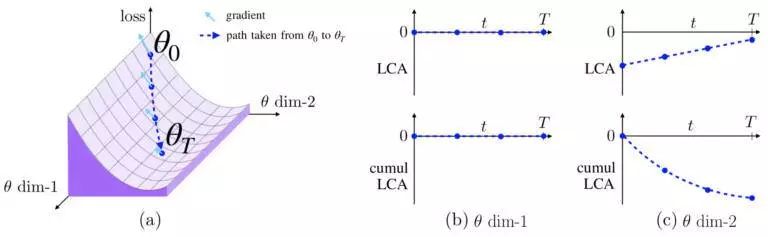
图 1. 损失表面的虚构示例 (a) 描述了两个参数的 LCA。一个参数 (b) 移动但不影响损失,另一个参数 (c) 具有负 LCA,因为它的移动导致损失减少。
- 迭代 1-10:在开始时,损失急剧下降,Uber看到许多绿色参数。
- 迭代 10-100:经过几次迭代之后,Uber看到绿色和红色的嘈杂混合,表明一些参数是有帮助的,而另一些参数正在受伤。
- 迭代 100+:一旦损失接近其最终值,Uber看到大多数像素接近白色,表明参数不再具有明显的帮助或伤害。
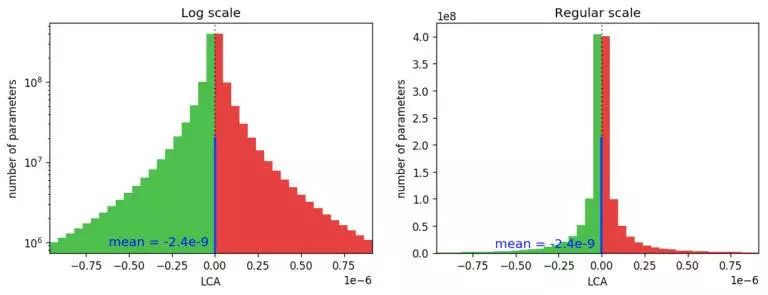
图 2. 显示所有 LCA 元素分布情况的直方图(所有迭代中的所有参数),显示只有不到一半是负数(帮助)。相应的直方图以对数刻度(左)显示,以查看分布的尾部和常规刻度(右),以便更清楚地显示负 / 正比率。
- 随着训练网络的时间越来越长,损失最终会停止下降,可以想象,有帮助的参数百分比将会收敛到 50%。因此,他们不禁要问:这个接近 50% 的比例,仅仅是否因为网络训练时间过长而产生的?然而,下面的图 3a 表明,情况并非如此:在训练期间的大多数时间点,这个比率仅略高于 50%,在最速学习的早期迭代中,这一比例略高,但仍然低于 60%。
- 其次,鉴于许多函数的帮助被许多参数的伤害所抵消,那么一些参数是否一直在“帮忙”,如果是,它们是否一直被其他参数的伤害所抵消?换句话说,是否有一些“英雄”参数几乎一直在帮助,而“恶棍”参数却不断造成伤害?但图 3b 显示并非如此:帮助最多的参数通常在 53% 的时间内有帮助,而帮助最少的参数仍然有 48% 的时间帮助。
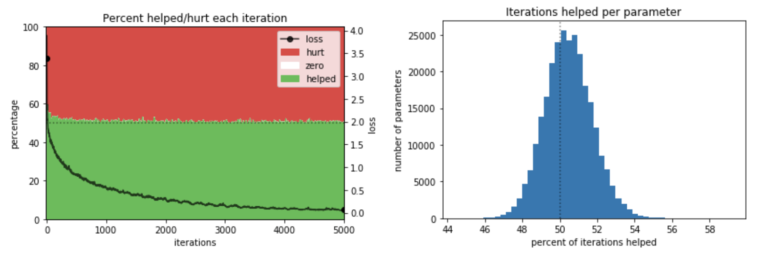
图 3. 研究发现:(a) 在所有迭代中,参数的帮助率接近 50%;(b) 所有参数的帮助大约为一半时间。
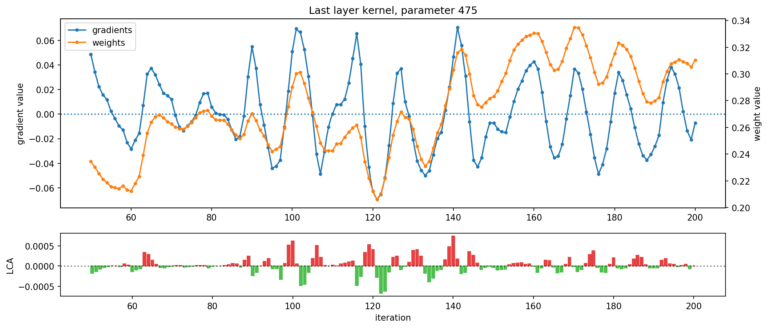
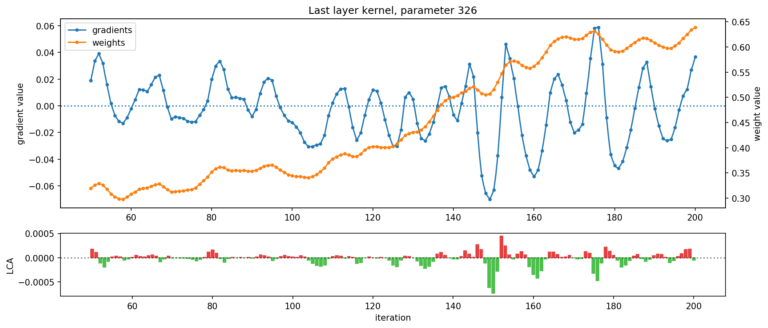
图 4. 显示了 ResNet 最后一层的两个参数:在给定的迭代过程中,一个参数伤害最大(顶部),另一个参数帮助最大(底部)(net LCA 分别为 +3.41e-3 和 -3.03e-3)。权重(橙色)和梯度(蓝色)轨迹都在震荡,导致 LCA(绿色和红色)在帮助和伤害之间交替。
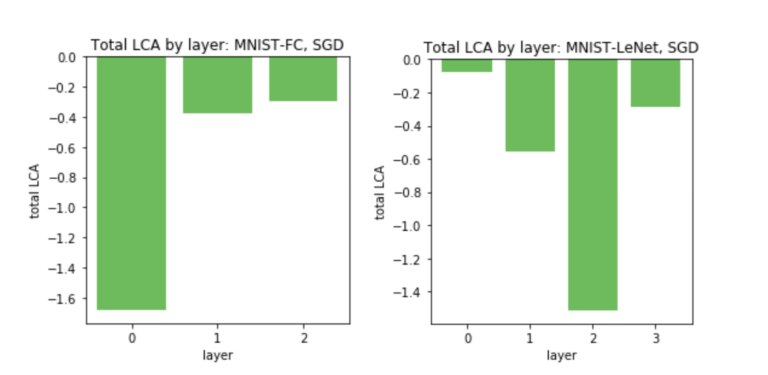
图 5. Uber对 FC(左)和 LeNet(右)的每个层中的所有参数进行 LCA 求和。不同的层学习不同的数量,每层 LCA 的差异主要可以通过层中参数的数量来解释。
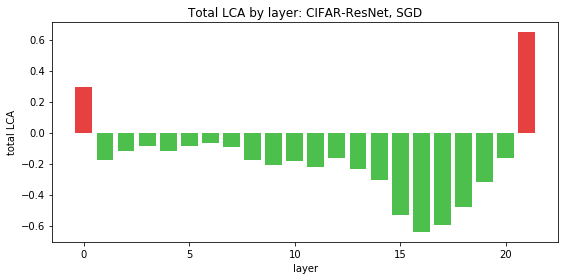
图 6.ResNet 揭示了一个不同的模式:第一层和最后一层具有正 LCA,这意味着它们的移动实际上增加了训练过程的损失。这很让人惊讶,因为网络总体上是有学习能力的,而且对于一大组参数的 LCA 总和而言,持续为正是没有意义的。
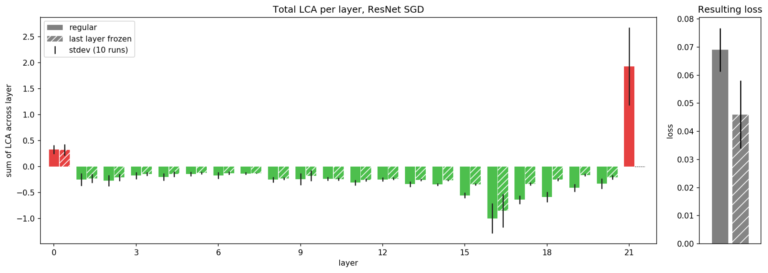
图 7. Uber 展示了 ResNet 中每层的 LCA,用于常规训练场景(实心柱),以及在初始化时冻结最后一层(阴影线)的场景,平均每个场景超过 10 次运行。通过冻结最后一层,Uber可以防止它受到伤害。虽然其他层的帮助没有那么多(LCA 的负面影响较小),但最后一层 LCA 的变化弥补了这一点,从而降低了整体损失(图右)。
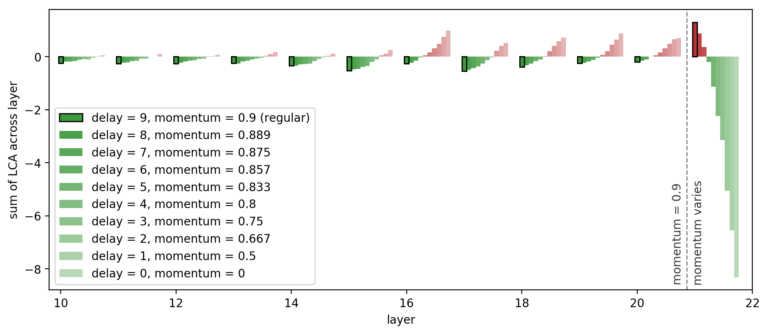
图 8. Uber 为最后一层训练了一个具有不同动量的 ResNet,并为每层绘制了总 LCA(为了更好的可视化效果,省略了前十层)。随着最后一层动量的减少,梯度新区驱动学习相对于其他层的延迟减小,最后一层的 LCA 以其他层的损失为代价向前推进。
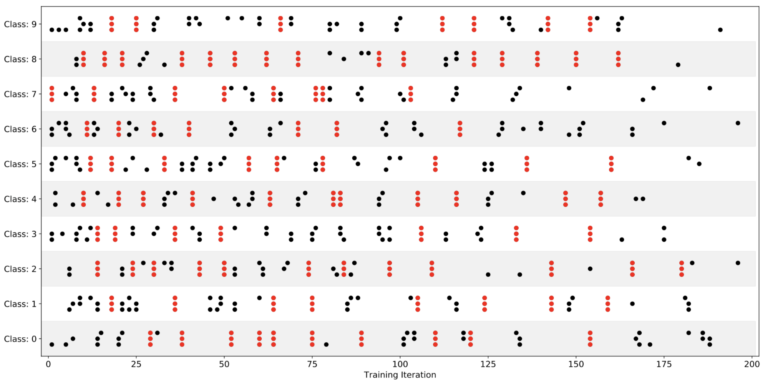
图 9. Uber 将 MNIST-FC 的“学习峰值时刻”按层和类进行可视化,每个点代表特定类和层的 LCA 峰值,其中网络中的三个层显示为三个堆叠的点。当所有个层的学习在同一次迭代中排列起来时,Uber 用红色标出这些点。
- 到目前为止讨论的所有实验都使用了训练集。如果Uber 也 跟踪验证 LCA,可以比较训练 LCA 和验证 LCA 来度量哪些参数导致了过拟合。这种分析可以实现有针对性的正则化。
- LCA 可用于识别没有帮助的权重,因此是修剪或重新初始化的目标。除了识别要冻结的层之外,LCA 还可能是一个重要的诊断工具,用于识别次优超参数或配置不良的网络结构。
- 更好的优化器可能能够考虑到频繁的参数级的震荡现象,或者实现每层可调的超参数。
◆
精彩推荐
◆
推荐阅读
掌握这些步骤,机器学习模型问题药到病除
值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(下)
6张拓扑图揭秘中心化交易所的5种行为, 原来中心化比你想象的重要!
分布式存储春天已来Storj首登top10; Cardano排名上升; 以太坊比特币活跃地址双下降 | 数据周榜
华为愿出售5G技术渴望对手;苹果将向印度投资10亿美元;华为全联接大会首发计算战略;腾讯自研轻量级物联网操作系统正式开源……
TDD 就是个坑!
我愿出 2 倍工资,挖这个被裁的程序员!
厉害!接班马云的为何是张勇?

你点的每个“在看”,我都认真当成了喜欢“
相关文章:

范登读书解读《亲密关系》(婚姻、爱情) 笔记
来源:邀请你看《樊登解读《亲密关系》(已婚人士必看)》,https://url.cn/5HJvLk5?sfuri 人们在童年的时候始终追寻着两种东西,第一种叫做归属感,第二叫做确认自己的重要性、价值感。 如果再童年的时候缺失这…

myeclipse莫名其妙的问题
2019独角兽企业重金招聘Python工程师标准>>> 怎么刷新,clean项目都不管用,结果删除相应工作空间下的那个项目就行。类似路径如D:\workspace\.metadata\.plugins\org.eclipse.core.resources\.projects 转载于:https://my.oschina.net/u/14488…

数据科学家需要知道的5种图算法
作者:Rahul Agarwal编译:ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】因为图分析是数据科学家的未来。作为数据科学家,我们对pandas、SQL或任何其他关系数据库非常熟悉。我们习惯于将用户的属性以列的形式显示在…

在Windows7/10上快速搭建深度学习框架Caffe开发环境
之前在 http://blog.csdn.net/fengbingchun/article/details/50987353 中介绍过在Windows7上搭建Caffe开发环境的操作步骤,那时caffe的项目是和其它依赖项目分开的,每次换新的PC机时再次重新配置搭建还是很不方便,而且caffe的版本较老&#x…
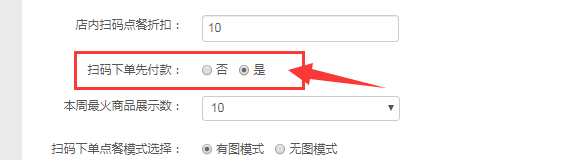
扫码下单支持同桌单人点餐FAQ
一、使用场景 满足较多商户希望同一桌台,各自点各自的菜品的业态场景(例如杭味面馆,黄焖鸡米饭店,面馆等大多数轻快餐店) 二、配置步骤及注意事项 管理员后台配置--配置管理--店铺配置--扫码点餐tab页 1、开启扫码下单…
使用photoshop 10.0制作符合社保要求的照片
2019独角兽企业重金招聘Python工程师标准>>> 北京市社保新参统人员照片修制方法 修改目标:照片规格:358像素(宽)×441像素(高),分辨率350dpi。 颜色模式:24位RGB真彩色。 储存格式&am…
C++11中std::addressof的使用
C11中的std::addressof获得一个对象的实际地址,即使 operator& 操作符已被重载。它常用于原本要使用 operator& 的地方,它接受一个参数,该参数为要获得地址的那个对象的引用。一般,若operator &()也被重载且不一致的话…

一份职位信息的精准推荐之旅,从AI底层架构说起
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】也许,每天早上你的邮箱中又多了一封职位推荐信息,点开一看,你可能发现这些推荐正合你意,于是按照这些信息,你顺利找到一份符合自己期待的…
Vue.js 生命周期
2019独角兽企业重金招聘Python工程师标准>>> 每个 Vue 实例在被创建之前都要经过一系列的初始化过程 vue在生命周期中有这些状态, beforeCreate,created,beforeMount,mounted,beforeUpdate,updated,beforeDestroy,destroyed。Vue在实例化的过程中&#x…
AX2009取销售订单的税额
直接用以下方法即可: Tax::calcTaxAmount(salesLine.TaxGroup, salesLine.TaxItemGroup, systemDateGet(), salesLine.CurrencyCode, salesParmLine.LineAmount, salesTable.taxModuleType()); salesParmLine.LineAmount:这个直接取的是装箱单或者发票…
Dubbo源码解析之服务路由策略
1. 简介 服务目录在刷新 Invoker 列表的过程中,会通过 Router 进行服务路由,筛选出符合路由规则的服务提供者。在详细分析服务路由的源码之前,先来介绍一下服务路由是什么。服务路由包含一条路由规则,路由规则决定了服务消费者的调…
C++中std::reverse和std::reverse_copy的使用
std::reverse:反转排序容器内指定范围中的元素。std::reverse_copy与std::reverse唯一的区别是:reverse_copy会将结果拷贝到另外一个容器中,而不影响原容器的内容。std::reverse: defined in header <algorithm>, reverses the order …

真相!30K拿到互联网大厂offer,网友:我服了!
最近笔者在知乎刷到一个帖子,其中,这条回答让人印象深刻:其实,最近几年人工智能大火,其中深度学习岗位的薪酬爆增,BAT大厂高薪招聘AI人才,收到的简历却寥寥无几?究竟是大厂岗位要求高…

OracleDesigner学习笔记1――安装篇
OracleDesigner学习笔记1――安装篇 QQ:King MSN:qiutianwhmsn.com Email:qqkinggmail.com 一. 前言 Oracle是当今最流行的关系型数据库之一,和很多朋友一样,我也是一个Oracle的爱好者,从…
C++/C++11中std::queue的使用
std::queue: 模板类queue定义在<queue>头文件中。队列(Queue)是一个容器适配器(Container adaptor)类型,被特别设计用来运行于FIFO(First-in first-out)场景,在该场景中,只能从容器一端添加(Insert)元素,而在另一端提取(Ext…
常见的http状态码(Http Status Code)
常见的http状态码:(收藏学习) 2**开头 (请求成功)表示成功处理了请求的状态代码。 200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。201 (已创…

“不给钱就删库”的勒索病毒, 程序员该如何防护?
作者 | 阿木,王洪鹏,运营有个人公众号新新生活志。目前任职网易云计算技术部高级工程师,近3年云计算从业经验,爱读书、爱写作、爱技术。责编 | 郭芮来源 | CSDN(ID:CSDNnews)近期一家名为ProPub…
ruby实时查看日志
(文章是从我的个人主页上粘贴过来的, 大家也可以访问我的主页 www.iwangzheng.com) 在调试代码的时候,把日志文件打开,边操作边调试能很快帮助我们发现系统中存在的问题。 $tail rails_2014_03_03.log -f转载于:https://www.cnblogs.com/iw…

干货 | OpenCV看这篇就够了,9段代码详解图像变换基本操作
作者 | 王天庆,长期从事分布式系统、数据科学与工程、人工智能等方面的研究与开发,在人脸识别方面有丰富的实践经验。现就职某世界100强企业的数据实验室,从事数据科学相关技术领域的预研工作。来源 | 大数据(ID:hzdas…
C++/C++11中std::priority_queue的使用
std::priority_queue:在优先队列中,优先级高的元素先出队列,并非按照先进先出的要求,类似一个堆(heap)。其模板声明带有三个参数,priority_queue<Type, Container, Functional>, 其中Type为数据类型,Container为…
left join 和 left outer join 的区别
老是混淆,做个笔记,转自:https://www.cnblogs.com/xieqian111/p/5735977.html left join 和 left outer join 的区别 通俗的讲: A left join B 的连接的记录数与A表的记录数同 A right join B 的连接的记录数与…
php减少损耗的方法之一 缓存对象
即把实例后的对象缓存起来(存入变量),当需要再次实例化时,先去缓存里查看是否存在。存在则返回。否则实例化。转载于:https://www.cnblogs.com/zuoxiaobing/p/3581139.html
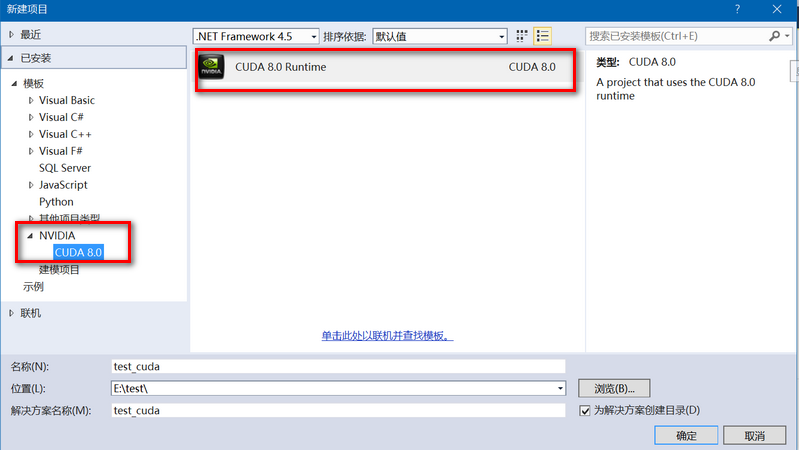
windows10 vs2013控制台工程中添加并编译cuda8.0文件操作步骤
一般有两种方法可以在vs2013上添加运行cuda8.0程序:一、直接新建一个基于CUDA8.0的项目:如下图所示,点击确定后即可生成test_cuda项目;默认会自动生成一个kernel.cu文件;默认已经配置好Debug/Release, Win32/x64环境&a…

算法人必懂的进阶SQL知识,4道面试常考题
(图片付费下载自视觉中国)作者 | 石晓文来源|小小挖掘机(ID:wAlsjwj)近期在不同群里有小伙伴们提出了一些在面试和笔试中遇到的Hive SQL问题,Hive作为算法工程师的一项必备技能,在面…
007-迅雷定时重启AutoHotkey脚本-20190411
;; 定时重启迅雷.ahk,;;~ 2019年04月11日;#SingleInstance,forceSetWorkingDir,%A_ScriptDir%DetectHiddenWindows,OnSetTitleMatchMode,2#Persistent ;让脚本持久运行(即直到用户关闭或遇到 ExitApp)。#NoEnv;~ #NoTrayIcon Hotkey,^F10,ExitThisApp lo…
关于ExtJS在使用下拉列表框的二级联动获取数据
2019独角兽企业重金招聘Python工程师标准>>> 使用下拉列表框的二级联动获取数据,如果第一个下拉列表框有默认值时,需要设置fireEvent执行select事件 示例: var combo Ext.getCmp("modifyBuildCom"); combo.setValue(re…
C++中std::sort/std::stable_sort/std::partial_sort的区别及使用
某些算法会重排容器中元素的顺序,如std::sort。调用sort会重排输入序列中的元素,使之有序,它默认是利用元素类型的<运算符来实现排序的。也可以重载sort的默认排序,即通过sort的第三个参数,此参数是一个谓词(predic…

阿里云智能 AIoT 首席科学家丁险峰:阿里全面进军IoT这一年 | 问底中国IT技术演进...
作者 | 屠敏受访者 | 丁险峰来源 | CSDN(ID:CSDNnews)「忽如一夜春风来,千树万树梨花开。」从概念的流行、至科技巨头的相继入局、再到诸多应用的落地,IoT 的发展终于在万事俱备只欠东风的条件下真正地迎来了属于自己的…

eBCC性能分析最佳实践(1) - 线上lstat, vfs_fstatat 开销高情景分析...
Guide: eBCC性能分析最佳实践(0) - 开启性能分析新篇章eBCC性能分析最佳实践(1) - 线上lstat, vfs_fstatat 开销高情景分析eBCC性能分析最佳实践(2) - 一个简单的eBCC分析网络函数的latency敬请期待...0. I…

spring-data-mongodb必须了解的操作
http://docs.spring.io/spring-data/data-mongo/docs/1.0.0.M5/api/org/springframework/data/mongodb/core/MongoTemplate.html 在线api文档 1关键之识别 KeywordSampleLogical resultGreaterThanfindByAgeGreaterThan(int age){"age" : {"$gt" : age}}Le…