windows10 vs2013控制台工程中添加并编译cuda8.0文件操作步骤
一般有两种方法可以在vs2013上添加运行cuda8.0程序:
一、直接新建一个基于CUDA8.0的项目:如下图所示,
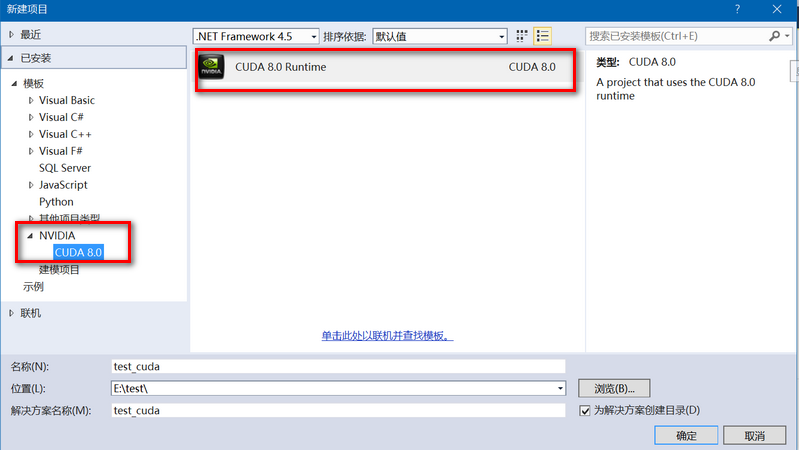
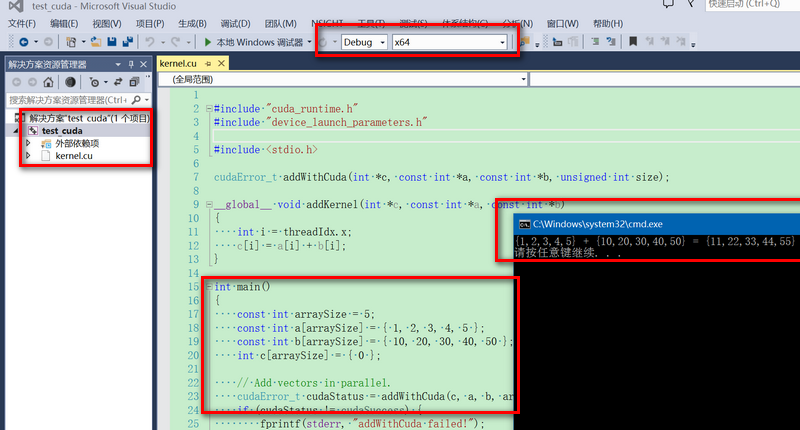
点击确定后即可生成test_cuda项目;默认会自动生成一个kernel.cu文件;默认已经配置好Debug/Release, Win32/x64环境,直接编译运行,结果如下图所示:函数执行的是两个数组的加操作。移除kernel.cu文件,加入自己需要的cuda文件即可进行实际操作了,非常方便。
二、实际情况下,多是在已有的项目中添加一些cuda文件,用于加速,下面说下具体的操作步骤:
1、新建一个CUDA_Test x64控制台空工程;
2、新建CUDA_Test.cpp文件;
3、选中CUDA_Test项目,右键单击-->生成依赖项-->生成自定义,勾选CUDA8.0,点击确定,如下图所示:
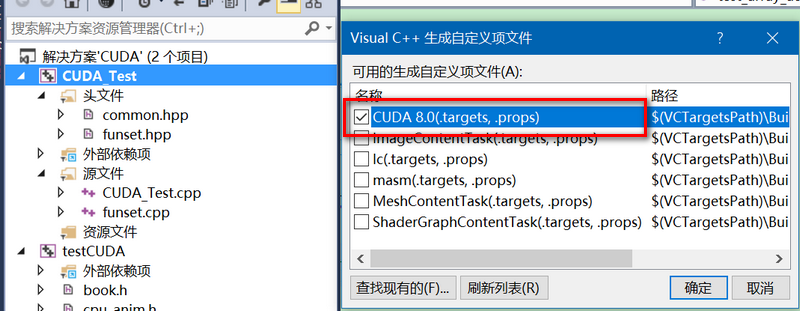
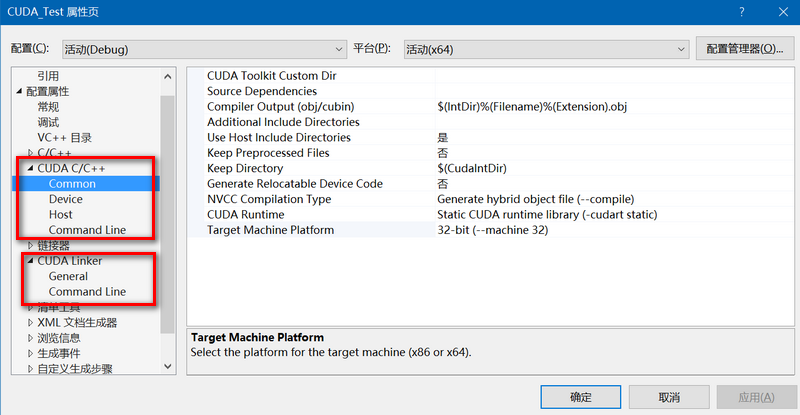
4、完成第3步后,再次打开工程的属性配置,会多出两项,CUDA C/C++和CUDA Linker,如下图所示:
5、新建或添加几个已有的文件,包括common.hpp、simple.hpp、simple.cpp、simple.cu,各个文件内容如下:
common.hpp:
#ifndef FBC_CUDA_TEST_COMMON_HPP_
#define FBC_CUDA_TEST_COMMON_HPP_#define PRINT_ERROR_INFO(info) { \fprintf(stderr, "Error: %s, file: %s, func: %s, line: %d\n", #info, __FILE__, __FUNCTION__, __LINE__); \return -1; }#endif // FBC_CUDA_TEST_COMMON_HPP_#ifndef FBC_CUDA_TEST_SIMPLE_HPP_
#define FBC_CUDA_TEST_SIMPLE_HPP_// reference: C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple
int test_vectorAdd();int vectorAdd_cpu(const float *A, const float *B, float *C, int numElements);int vectorAdd_gpu(const float *A, const float *B, float *C, int numElements);#endif // FBC_CUDA_TEST_SIMPLE_HPP_#include "simple.hpp"
#include <stdlib.h>
#include <iostream>
#include "common.hpp"// =========================== vector add =============================
int test_vectorAdd()
{// Vector addition: C = A + B, implements element by element vector additionconst int numElements{ 50000 };float* A = new float[numElements];float* B = new float[numElements];float* C1 = new float[numElements];float* C2 = new float[numElements];// Initialize vectorfor (int i = 0; i < numElements; ++i) {A[i] = rand() / (float)RAND_MAX;B[i] = rand() / (float)RAND_MAX;}int ret = vectorAdd_cpu(A, B, C1, numElements);if (ret != 0) PRINT_ERROR_INFO(vectorAdd_cpu);ret = vectorAdd_gpu(A, B, C2, numElements);if (ret != 0) PRINT_ERROR_INFO(vectorAdd_gpu);for (int i = 0; i < numElements; ++i) {if (fabs(C1[i] - C2[i]) > 1e-5) {fprintf(stderr, "Result verification failed at element %d!\n", i);return -1;}}delete[] A;delete[] B;delete[] C1;delete[] C2;return 0;
}int vectorAdd_cpu(const float *A, const float *B, float *C, int numElements)
{for (int i = 0; i < numElements; ++i) {C[i] = A[i] + B[i];}return 0;
}#include "simple.hpp"
#include <iostream>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>// reference: C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple// =========================== vector add =============================
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements)
{int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < numElements) {C[i] = A[i] + B[i];}
}int vectorAdd_gpu(const float *A, const float *B, float *C, int numElements)
{// Error code to check return values for CUDA callscudaError_t err{ cudaSuccess };size_t length{ numElements * sizeof(float) };fprintf(stderr, "Length: %d\n", length);float* d_A{ nullptr };float* d_B{ nullptr };float* d_C{ nullptr };err = cudaMalloc(&d_A, length);if (err != cudaSuccess) {fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaMalloc(&d_B, length);if (err != cudaSuccess) {fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaMalloc(&d_C, length);if (err != cudaSuccess) {fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaMemcpy(d_A, A, length, cudaMemcpyHostToDevice);if (err != cudaSuccess) {fprintf(stderr, "Failed to copy vector A from host to device (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaMemcpy(d_B, B, length, cudaMemcpyHostToDevice);if (err != cudaSuccess) {fprintf(stderr, "Failed to copy vector B from host to device (error code %s)!\n", cudaGetErrorString(err));return -1;}// Launch the Vector Add CUDA kernelint threadsPerBlock = 256;int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;fprintf(stderr, "CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);vectorAdd << <blocksPerGrid, threadsPerBlock >> >(d_A, d_B, d_C, numElements);err = cudaGetLastError();if (err != cudaSuccess) {fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n", cudaGetErrorString(err));return -1;}// Copy the device result vector in device memory to the host result vector in host memory.err = cudaMemcpy(C, d_C, length, cudaMemcpyDeviceToHost);if (err != cudaSuccess) {fprintf(stderr, "Failed to copy vector C from device to host (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaFree(d_A);if (err != cudaSuccess) {fprintf(stderr, "Failed to free device vector A (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaFree(d_B);if (err != cudaSuccess) {fprintf(stderr, "Failed to free device vector B (error code %s)!\n", cudaGetErrorString(err));return -1;}err = cudaFree(d_C);if (err != cudaSuccess) {fprintf(stderr, "Failed to free device vector C (error code %s)!\n", cudaGetErrorString(err));return -1;}return err;
}#include <iostream>
#include "simple.hpp"int main()
{int ret = test_vectorAdd();if (ret == 0) fprintf(stderr, "***** test success *****\n");else fprintf(stderr, "===== test fail =====\n");return 0;
}(1)、CUDA C/C++-->Common中Target Machine Platform中默认是32-bit(--machine32),因为是x64,所以将其调整为64-bit(--machine 64);
(2)、添加附加库:链接器-->输入-->附加依赖项:cudart.lib;
(3)、消除nvcc warning: The 'compute_20', 'sm_20', and'sm_21' architectures are deprecated, and may be removed in a future release:CUDA C/C++-->Device: Code Generation:由compute_20,sm_20修改为compute_30,sm_30; compute_35,sm_35; compute_37,sm_37;compute_50,sm_50; compute_52,sm_52; compute_60,sm_60
以上code是参考NVIDIA Corporation\CUDA Samples\v8.0\0_Simple中vectorAdd例子进行的改写,输出结果如下:
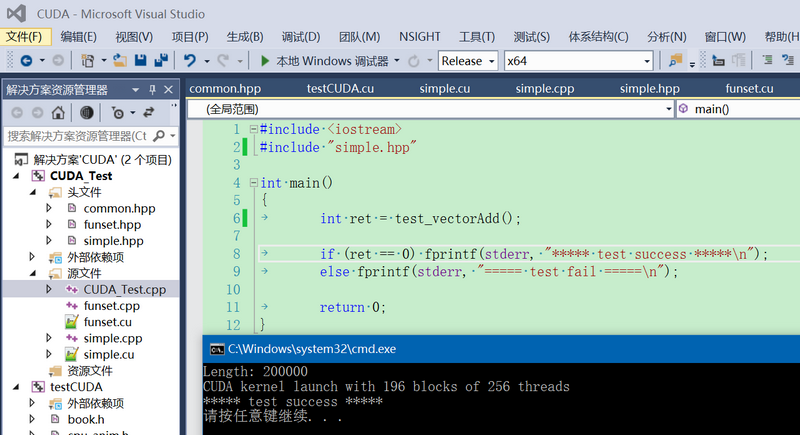
GitHub:https://github.com/fengbingchun/CUDA_Test
相关文章:

算法人必懂的进阶SQL知识,4道面试常考题
(图片付费下载自视觉中国)作者 | 石晓文来源|小小挖掘机(ID:wAlsjwj)近期在不同群里有小伙伴们提出了一些在面试和笔试中遇到的Hive SQL问题,Hive作为算法工程师的一项必备技能,在面…

007-迅雷定时重启AutoHotkey脚本-20190411
;; 定时重启迅雷.ahk,;;~ 2019年04月11日;#SingleInstance,forceSetWorkingDir,%A_ScriptDir%DetectHiddenWindows,OnSetTitleMatchMode,2#Persistent ;让脚本持久运行(即直到用户关闭或遇到 ExitApp)。#NoEnv;~ #NoTrayIcon Hotkey,^F10,ExitThisApp lo…

关于ExtJS在使用下拉列表框的二级联动获取数据
2019独角兽企业重金招聘Python工程师标准>>> 使用下拉列表框的二级联动获取数据,如果第一个下拉列表框有默认值时,需要设置fireEvent执行select事件 示例: var combo Ext.getCmp("modifyBuildCom"); combo.setValue(re…
C++中std::sort/std::stable_sort/std::partial_sort的区别及使用
某些算法会重排容器中元素的顺序,如std::sort。调用sort会重排输入序列中的元素,使之有序,它默认是利用元素类型的<运算符来实现排序的。也可以重载sort的默认排序,即通过sort的第三个参数,此参数是一个谓词(predic…

阿里云智能 AIoT 首席科学家丁险峰:阿里全面进军IoT这一年 | 问底中国IT技术演进...
作者 | 屠敏受访者 | 丁险峰来源 | CSDN(ID:CSDNnews)「忽如一夜春风来,千树万树梨花开。」从概念的流行、至科技巨头的相继入局、再到诸多应用的落地,IoT 的发展终于在万事俱备只欠东风的条件下真正地迎来了属于自己的…

eBCC性能分析最佳实践(1) - 线上lstat, vfs_fstatat 开销高情景分析...
Guide: eBCC性能分析最佳实践(0) - 开启性能分析新篇章eBCC性能分析最佳实践(1) - 线上lstat, vfs_fstatat 开销高情景分析eBCC性能分析最佳实践(2) - 一个简单的eBCC分析网络函数的latency敬请期待...0. I…

spring-data-mongodb必须了解的操作
http://docs.spring.io/spring-data/data-mongo/docs/1.0.0.M5/api/org/springframework/data/mongodb/core/MongoTemplate.html 在线api文档 1关键之识别 KeywordSampleLogical resultGreaterThanfindByAgeGreaterThan(int age){"age" : {"$gt" : age}}Le…

旷视张祥雨:高效轻量级深度模型的研究和实践 | AI ProCon 2019
演讲嘉宾 | 张祥雨(旷视研究院主任研究员、基础模型组负责人)编辑 | Just出品 | AI科技大本营(ID:rgznai100)基础模型是现代视觉识别系统中一个至关重要的关注点。基础模型的优劣主要从精度、速度或功耗等角度判定,如何…
Python脱产8期 Day02
一 语言分类 机器语言,汇编语言,高级语言(编译和解释) 二 环境变量 1、配置环境变量不是必须的2、配置环境变量的目的:为终端提供执行环境 三Python代码执行的方式 1交互式:.控制台直接编写运行python代码 …

分别用Eigen和C++(OpenCV)实现图像(矩阵)转置
(1)、标量(scalar):一个标量就是一个单独的数。(2)、向量(vector):一个向量是一列数,这些数是有序排列的,通过次序中的索引,可以确定每个单独的数。(3)、矩阵(matrix):矩阵是一个二维数组,其中的…
Linux基础优化
***************************************************************************************linux系统的优化有很多,我简单阐述下我经常优化的方针:记忆口诀:***********************一清、一精、一增;两优、四设、七其他。*****…
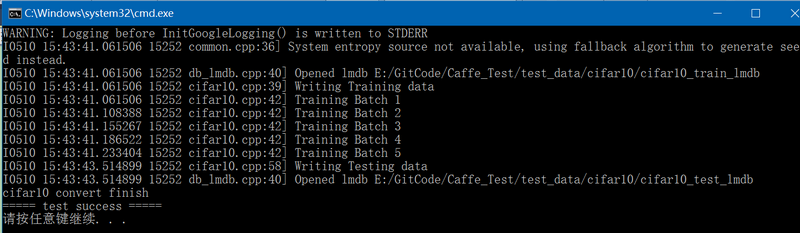
数据集cifar10到Caffe支持的lmdb/leveldb转换的实现
在 http://blog.csdn.net/fengbingchun/article/details/53560637 对数据集cifar10进行过介绍,它是一个普通的物体识别数据集。为了使用Caffe对cifar10数据集进行train,下面实现了将cifar10到lmdb/leveldb的转换实现:#include "funset.h…
计算两个时间的间隔时间是多少
/*** 计算两个时间间隔* param startTime 开始时间* param endTime 结束时间* param type 类型(1:相隔小时 2:)* return*/public static int compareTime(String startTime, String endTime, int type) {if (endTime nul…

作为西二旗程序员,我是这样学习的.........
作为一名合格的程序员,需要时刻保持对新技术的敏感度,并且要定期更新自己的技能储备,是每个技术人的日常必修课。但要做到这一点,知乎上的网友说最高效的办法竟然是直接跟 BAT 等一线大厂取经。讲真的,BAT大厂的平台是…

2月国内搜索市场:360继续上升 百度下降0.62%
IDC评述网(idcps.com)03月06日报道:根据CNZZ数据显示,在国内搜索引擎市场中,百度在2014年2月份所占的份额继续被蚕食,环比1月份,下降了0.62%,为60.50%。与此相反,360搜索…

不止于刷榜,三大CV赛事夺冠算法技术的“研”与“用”
(由AI科技大本营付费下载自视觉中国)整理 | Jane出品 | AI科技大本营(ID:rgznai100)在 5 个月时间里(5月-9月),创新工场旗下人工智能企业创新奇智连续在世界顶级人脸检测竞赛 WIDER …
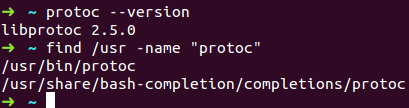
Ubuntu14.04上编译指定版本的protobuf源码操作步骤
Google Protobuf的介绍可以参考 http://blog.csdn.net/fengbingchun/article/details/49977903 ,这里介绍在Ubuntu14.04上编译安装指定版本的protobuf的操作步骤,这里以2.4.1为例:1. Ubuntu14.04上默认安装的是2.5.0,…
Linux下,各种解压缩命令集合
Linux下,各种解压缩命令集合tar xvfj lichuanhua.tar.bz2tar xvfz lichuanhua.tar.gztar xvfz lichuanhua.tgztar xvf lichuanhua.tarunzip lichuanhua.zip.gz解压 1:gunzip FileName.gz解压 2:gzip -d FileName.gz压缩:gzip File…
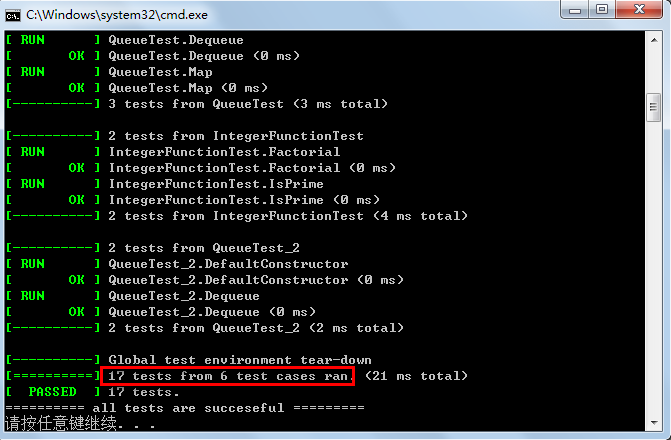
gtest使用初级指南
之前在 http://blog.csdn.net/fengbingchun/article/details/39667571 中对google的开源库gtest进行过介绍,现在看那篇博文,感觉有些没有说清楚,这里再进行总结下:Google Test是Google的开源C单元测试框架,简称gtest。…
iOS视频流采集概述(AVCaptureSession)
需求:需要采集到视频帧数据从而可以进行一系列处理(如: 裁剪,旋转,美颜,特效....). 所以,必须采集到视频帧数据. 阅读前提: 使用AVFoundation框架采集音视频帧数据GitHub地址(附代码) : iOS视频流采集概述 简书地址 : iOS视频流采…

300秒搞定第一超算1万年的计算量,量子霸权时代已来?
(由AI科技大本营付费下载自视觉中国)作者 | 马超责编 | 郭芮来源 | CSDN 博客近日,美国航天局(NASA)发布了一篇名为《Quantum Supremacy Using a Programmable Superconducting Processor》的报道,称谷歌的…
2014-3-6 星期四 [第一天执行分析]
昨日进度: [毛思想]:看测控技术量待定 --> [良]超额完成,昨天基本上把测控看了一大半啦 [汇编]:认真听课,边听边消化自学 --> [中]基本满足,还需要抽时间总结,特别是前面寻址的各种情况…

行列式介绍及Eigen/OpenCV/C++的三种实现
行列式,记作det(A),是一个将方阵A映射到实数的函数。行列式等于矩阵特征值的乘积。行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或者缩小了多少。如果行列式是0,那么空间至少沿着某一维完全收缩了,使其失去了所有的体积…

基于Go的语义解析开源库FMR,“屠榜”模型外的NLP利器
(由AI科技大本营付费下载自视觉中国)作者 | 刘占亮 一览群智技术副总裁编辑 | Jane出品 | AI科技大本营(ID:rgznai100)如何合理地表示语言的内在意义?这是自然语言处理业界中长久以来悬而未决的一个命题。在…
【高级数据类型2】- 10. 接口
2019独角兽企业重金招聘Python工程师标准>>> Go语言-接口 在Go语言中,一个接口类型总是代表着某一种类型(即所有实现它的类型)的行为。一个接口类型的声明通常会包含关键字type、类型名称、关键字interface以及由花括号包裹的若干…
Linux软件包命令
2019独角兽企业重金招聘Python工程师标准>>> dpkg命令: dpkg -i **/**.deb 安装软件 dpkg -x **.deb 解开.deb文件 dpkg -r /-p 删除并清配置 更详细的 用dpkg --help 查询 如下: dpkg -i|--install <.deb 文件的文件名> ... | -R|--re…
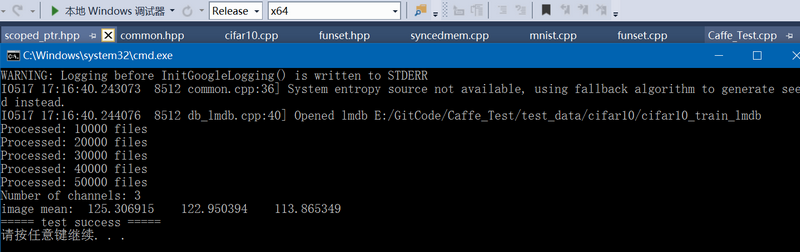
Caffe中计算图像均值的实现(cifar10)
在深度学习中,在进行test时经常会减去train数据集的图像均值,这样做的好处是:属于数据预处理中的数据归一化,降低数据间相似性,可以将数值调整到一个合理的范围。以下code是用于计算cifar10中训练集的图像均值…
阿里云弹性公网IP(EIP)的使用限制
阿里云弹性公网IP(EIP)是一种可以独立购买和持有的公网IP地址资源,弹性公网IP具有独立购买持有、弹性绑定和配置灵活等优势,但实际使用中弹性公网IP也是有很多限制的,阿里云惠网分享弹性公网IP(EIP…

400名微软员工主动曝光薪资:28万元到228万元不等!
作者 | Dave Gershgorn译者 | 弯月,编辑 | 郭芮来源 | CSDN(ID:CSDNnews)【导读】近日,近400名微软员工分享了他们的薪酬(从4万美元到32万美元不等,约为28万人民币到228万人民币)&am…
Extjs:添加查看全部按钮
var grid new Ext.grid.GridPanel({renderTo:tsllb,title:产品成本列表,selModel:csm,height:350,columns:[csm,{header: "编码", dataIndex: "bm", sortable: true,hidden:true},{header: "产品", dataIndex: "cp", sortable: true},…