旷视张祥雨:高效轻量级深度模型的研究和实践 | AI ProCon 2019

演讲嘉宾 | 张祥雨(旷视研究院主任研究员、基础模型组负责人)
编辑 | Just
出品 | AI科技大本营(ID:rgznai100)
基础模型是现代视觉识别系统中一个至关重要的关注点。基础模型的优劣主要从精度、速度或功耗等角度判定,如何设计模型应对复杂应用场景是非常重要的课题。
近日,由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文 IT 技术社区 CSDN 主办的 2019 中国 AI 开发者大会(AI ProCon 2019)在北京举办。在计算机视觉技术专题,旷视研究院主任研究员、基础模型组负责人张祥雨主要从轻量级架构、模型裁剪、模型搜索三大思路讲述了高效轻量级深度模型的研究和实践。
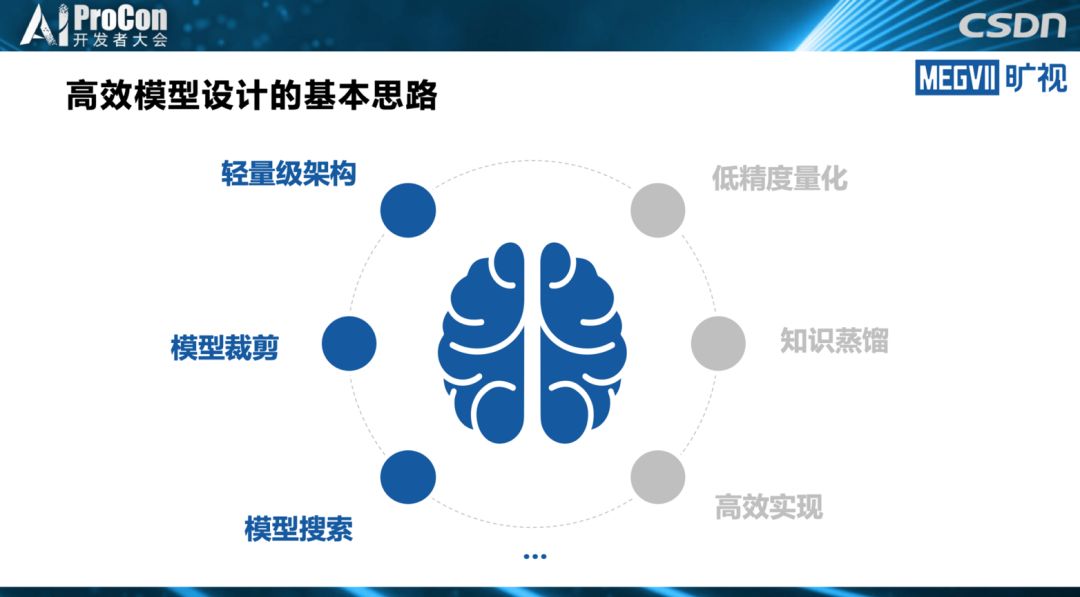
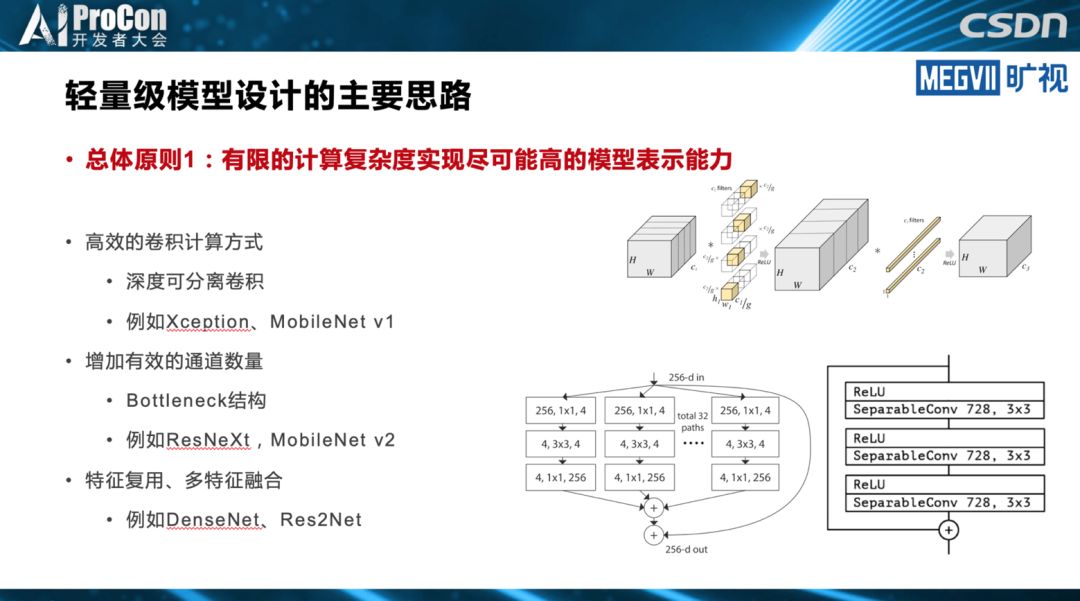
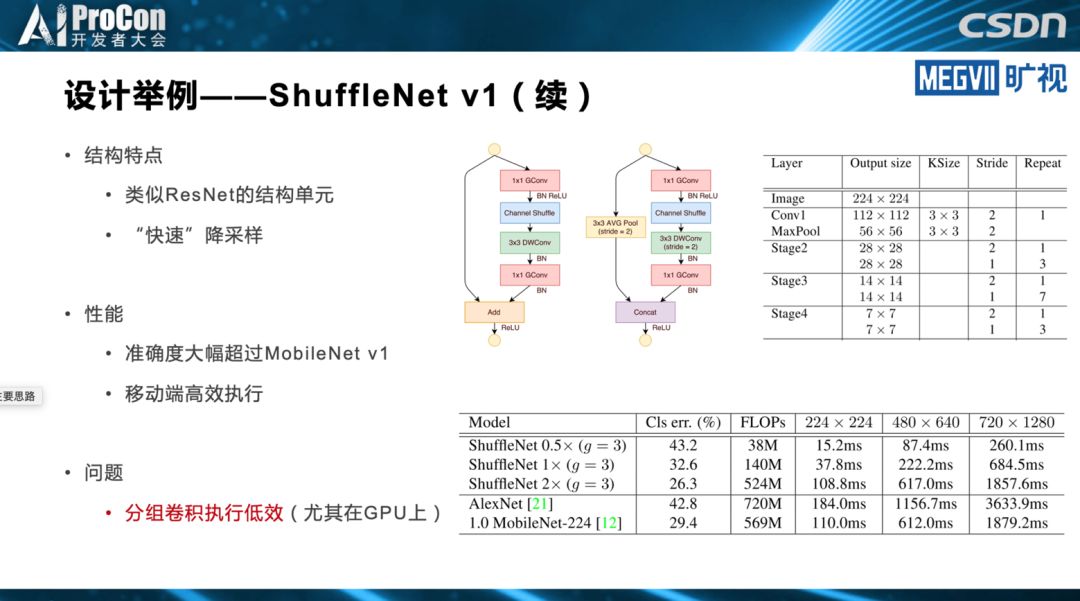
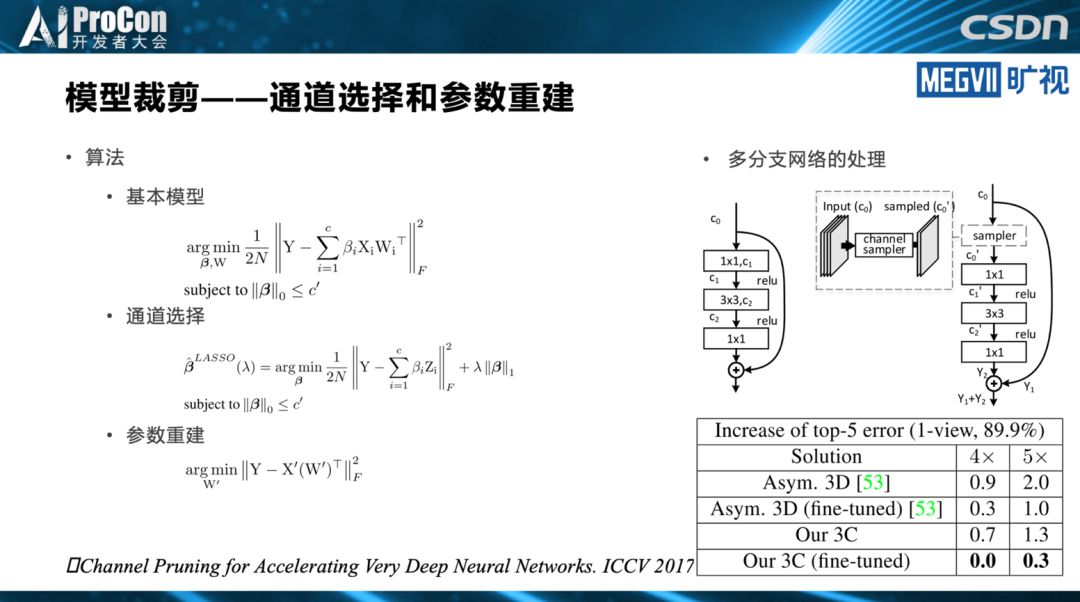
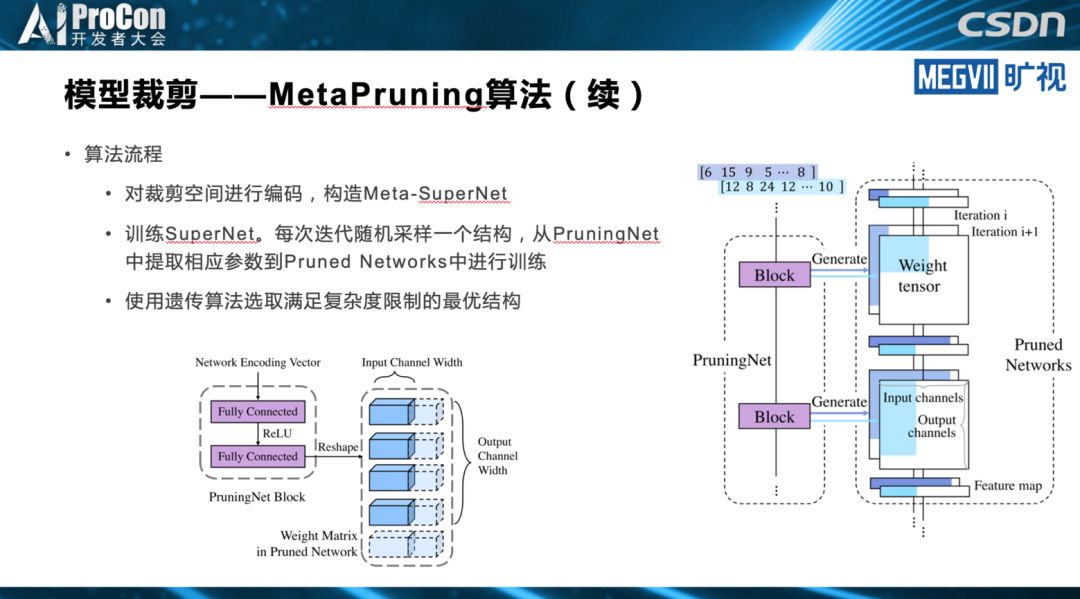
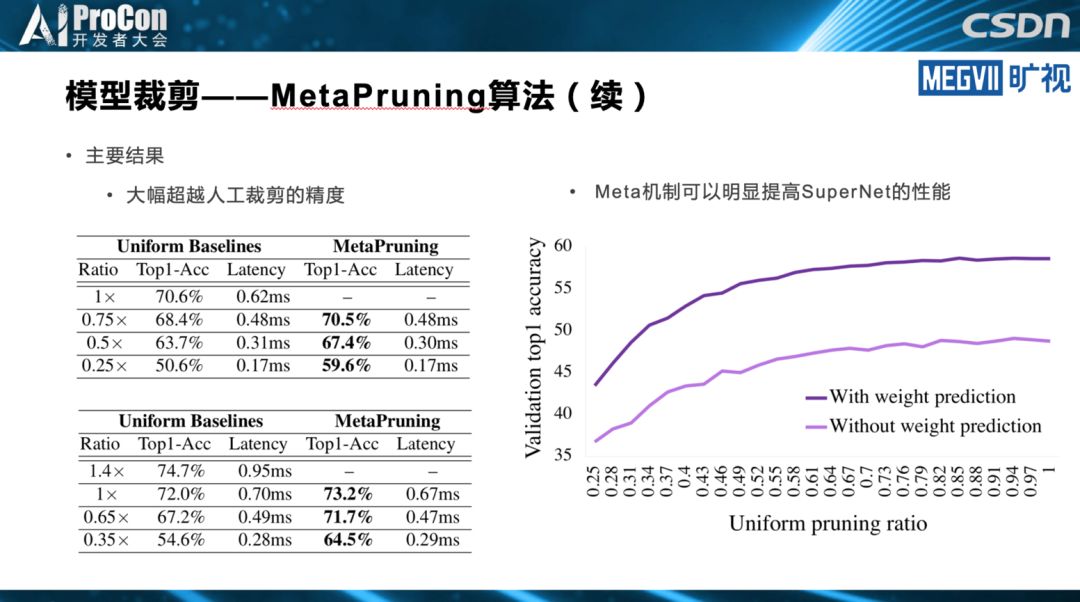
轻量级架构是模型设计最简单,也是最彻底的做法。而模型裁剪的思路是,先设计一个相对比较重量级的架构,但是通过一些模型裁剪的方法裁下来,得到一个能在端上实时跑的模型。模型搜索则利用模型搜索的方法自动完成模型设计和设备匹配。
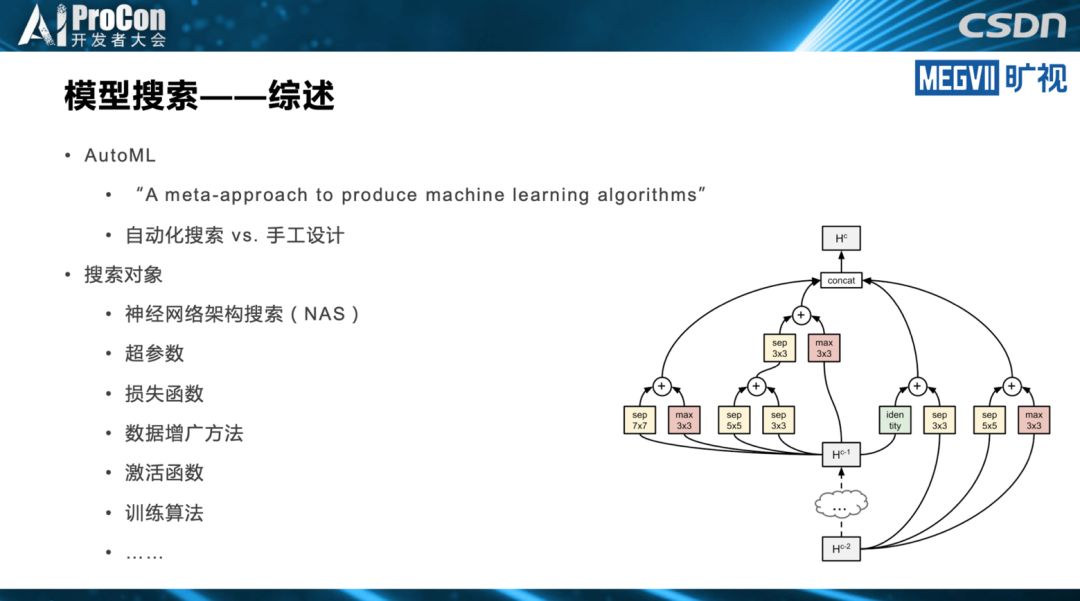
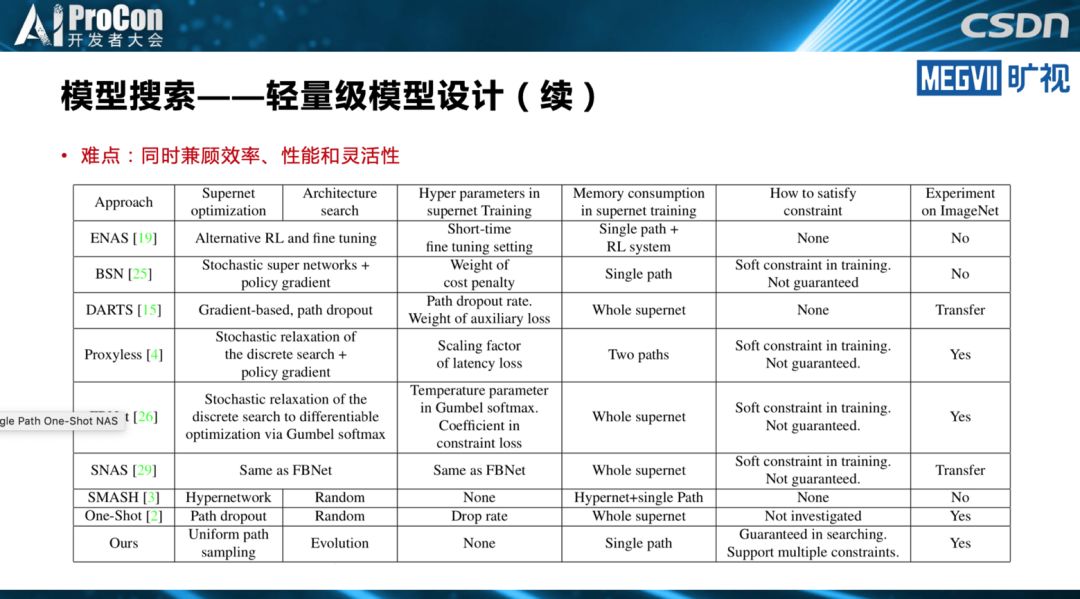
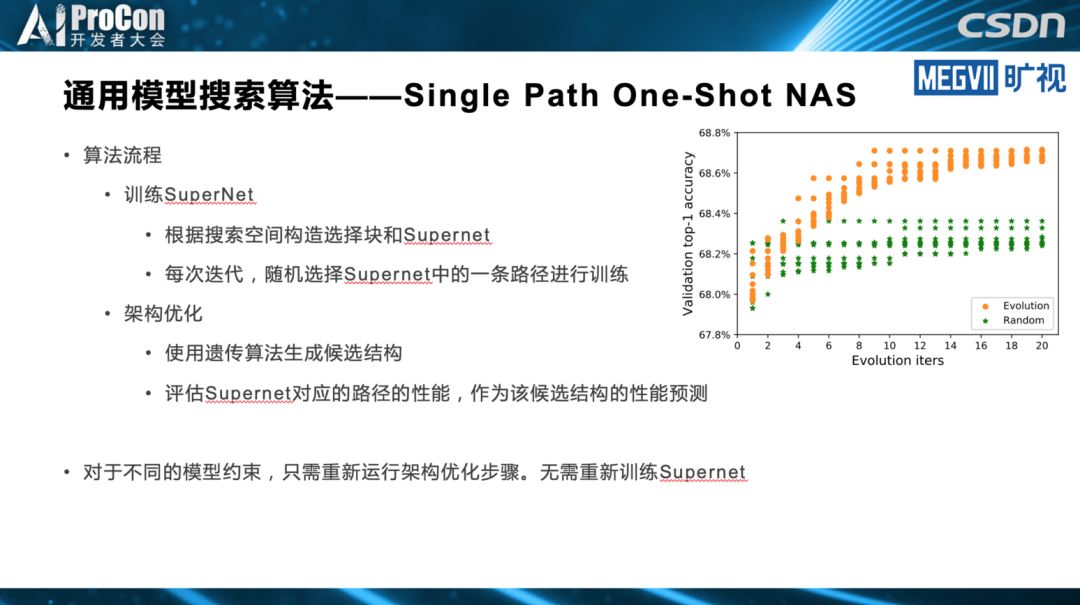
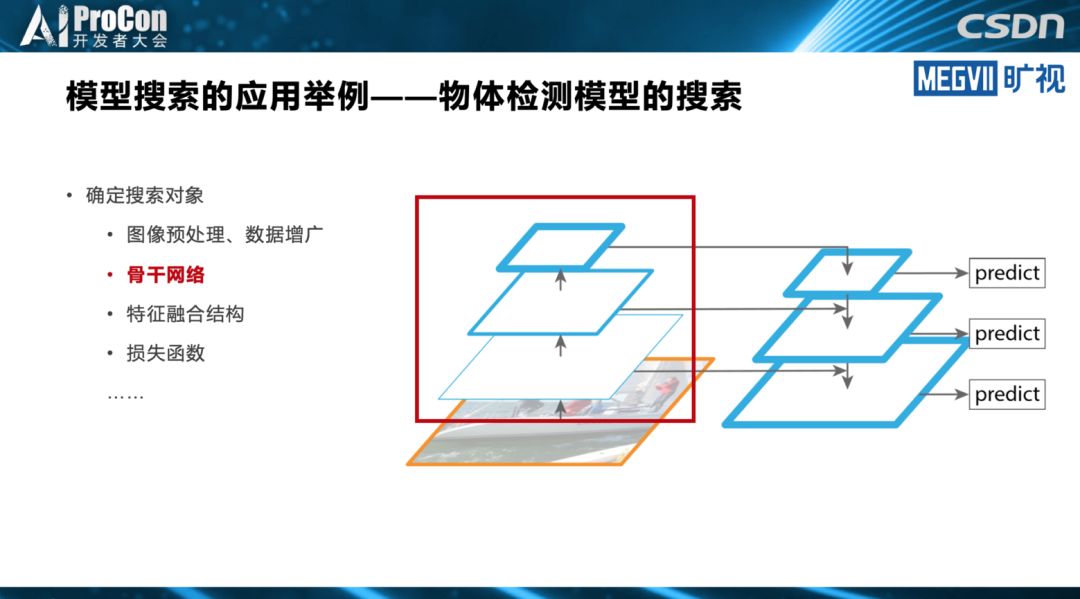
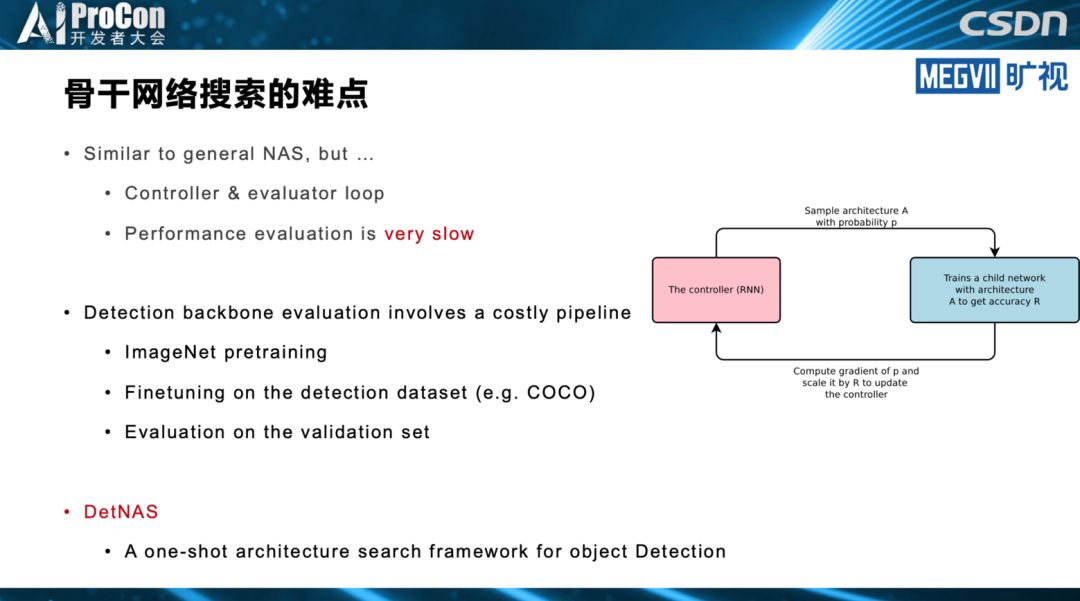
其中,张祥雨重点讲述了模型搜索。在他看来,目前模型搜索在轻量级模型设计领域,已逐渐成为最重要的研究方向之一。模型搜索在模型结构的排列组合、结构超参数的调优方面,相对人工设计有明显优势,不过搜索空间设计的好坏很大程度上依靠人工经验。他同时指出,人工设计在网络基本单元挖掘等方面目前仍不可替代,不过,目前已经有相关的NAS工作进行初步尝试。
他还提到模型搜索所面临的的问题和挑战,这包括精度、效率和灵活性的权衡,搜索空间设计,模型搜索的稳定性、可解释性和可重现性以及复杂Pipeline下高效的模型搜索与流程优化。
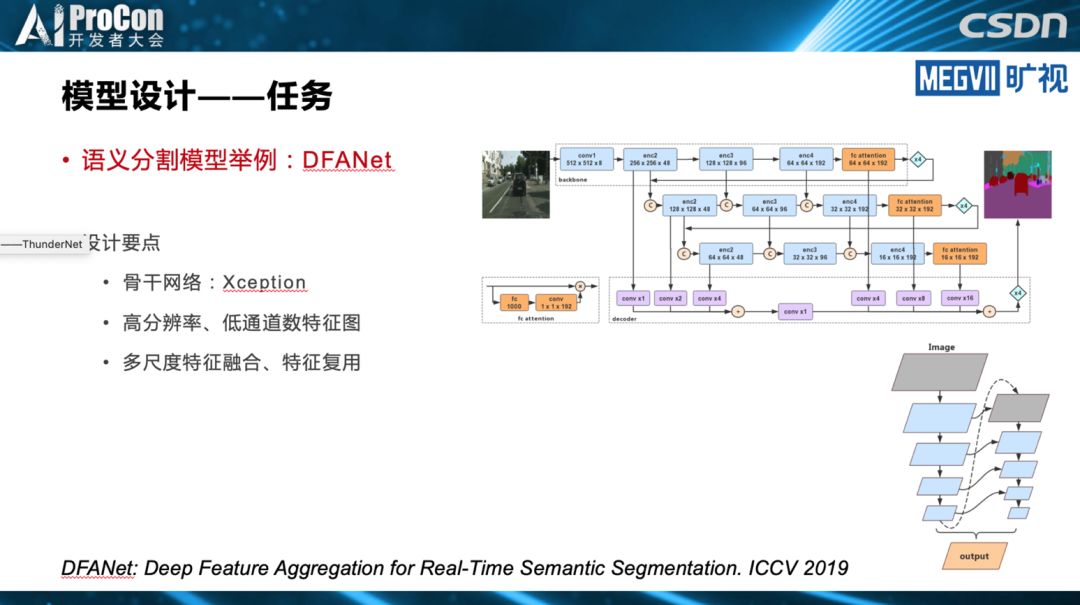
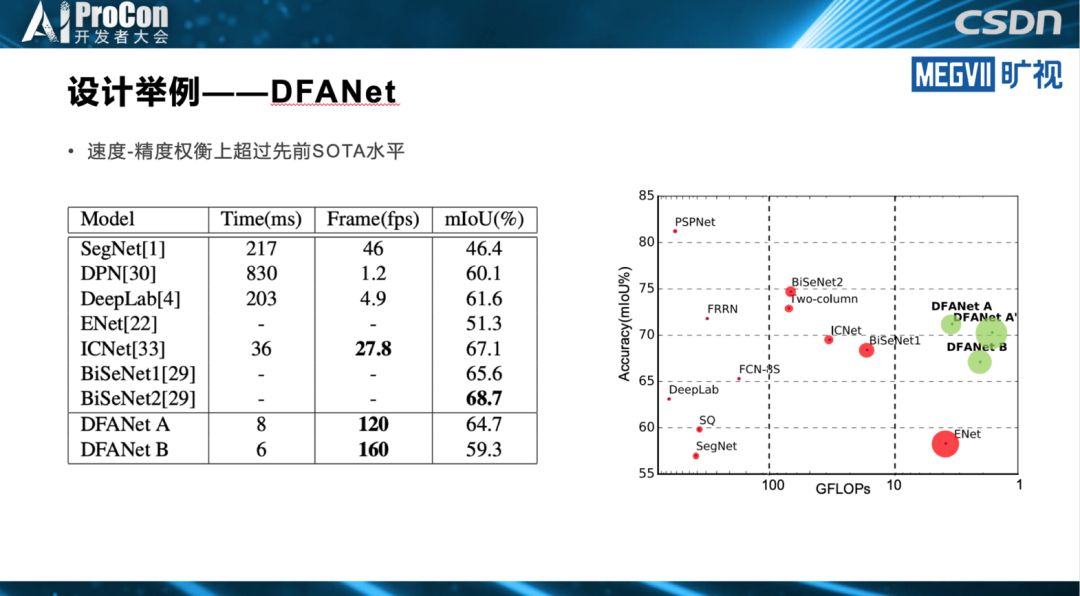
此外,张祥雨也提到模型设计的其他思路,比如低精度量化,浮点运算通常比较慢,相反用低精度运算可以实现很明显的模型加速。通过知识蒸馏或高效的底层实现也可以进行模型加速,他们会使用以上六种甚至更多的方案综合进行模型的设计。
以下为张祥雨演讲内容实录,A科技大本营(ID:rgznai100)整理:
旷视研究院基础模型组是偏研发类的部门,主要是为其他各个部门提供优质的基础模型,对算法本身的创新性和实用性都有比较高的要求。
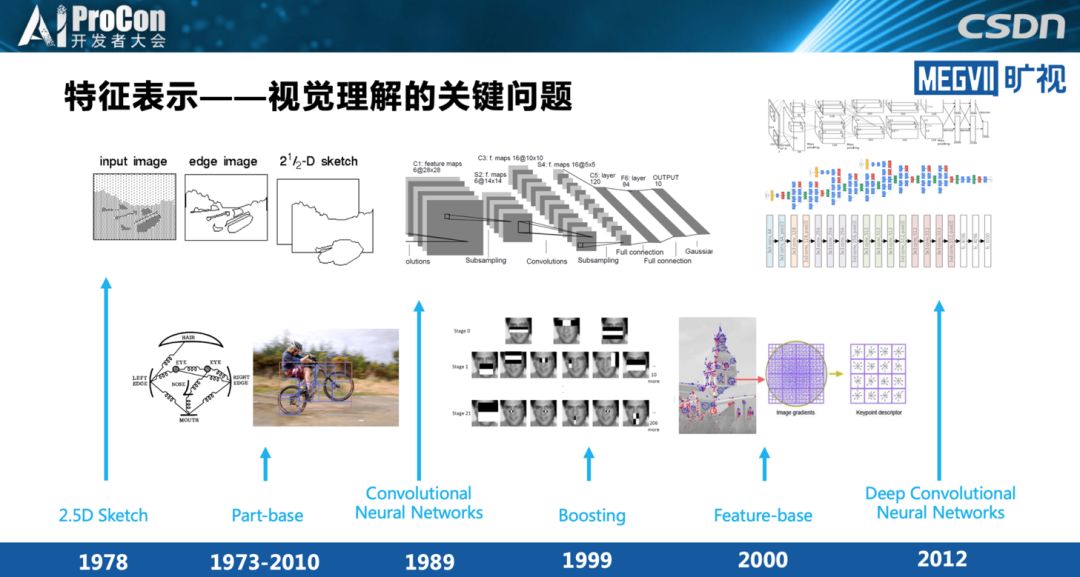
视觉理解中,特征表示是最为关键的问题。在深度学习之前的手工设计时代,为了完成了一个视觉理解的任务,通常情况下特征抽取是最重要的模块。进入深度学习时代后这个观点仍然没变,特征仍然是我们物体识别最重要的点。
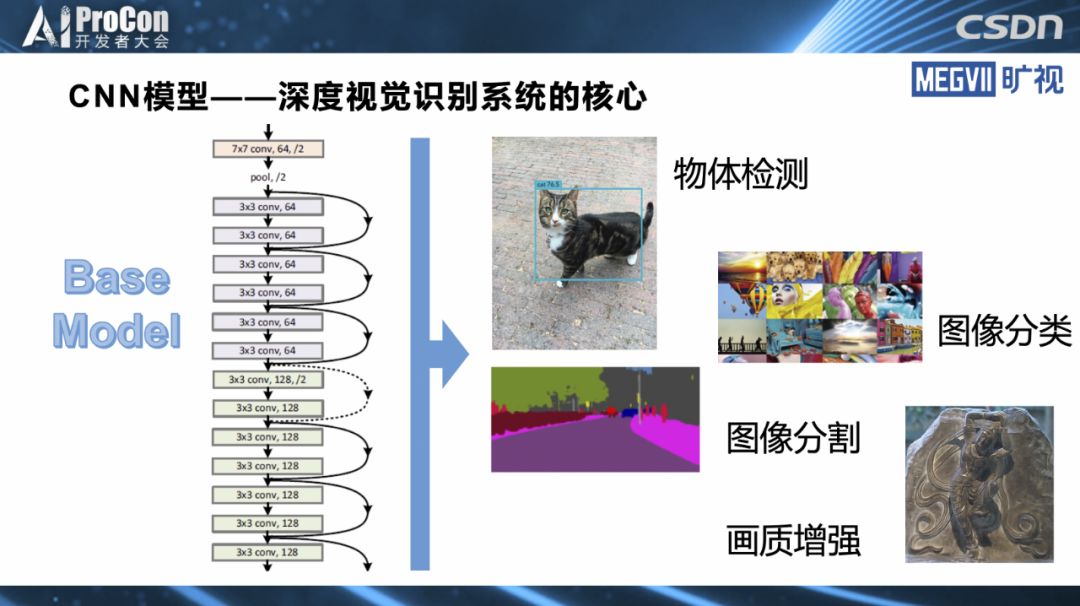
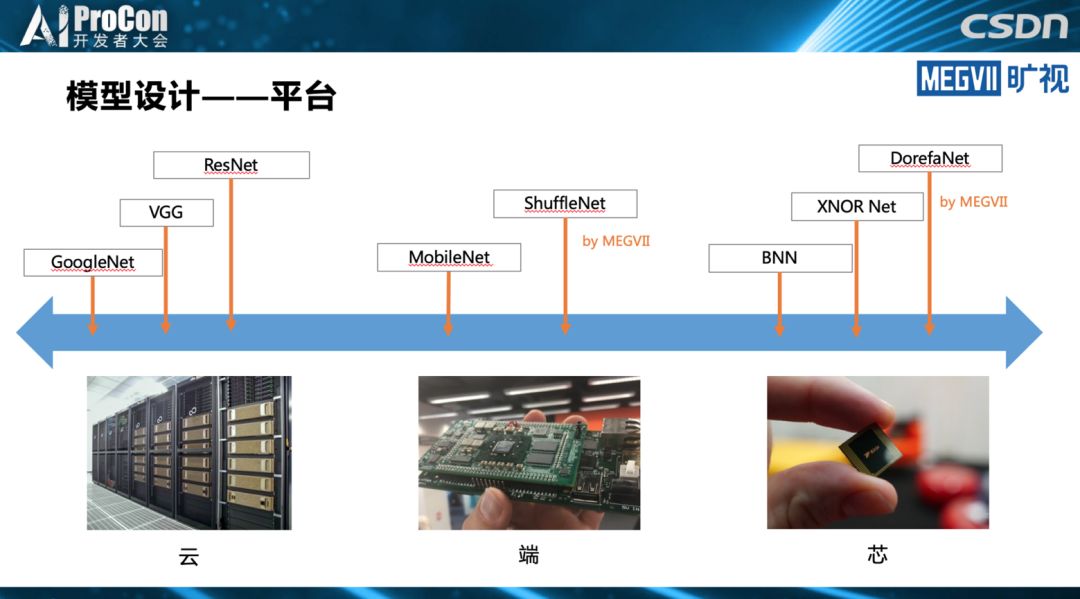
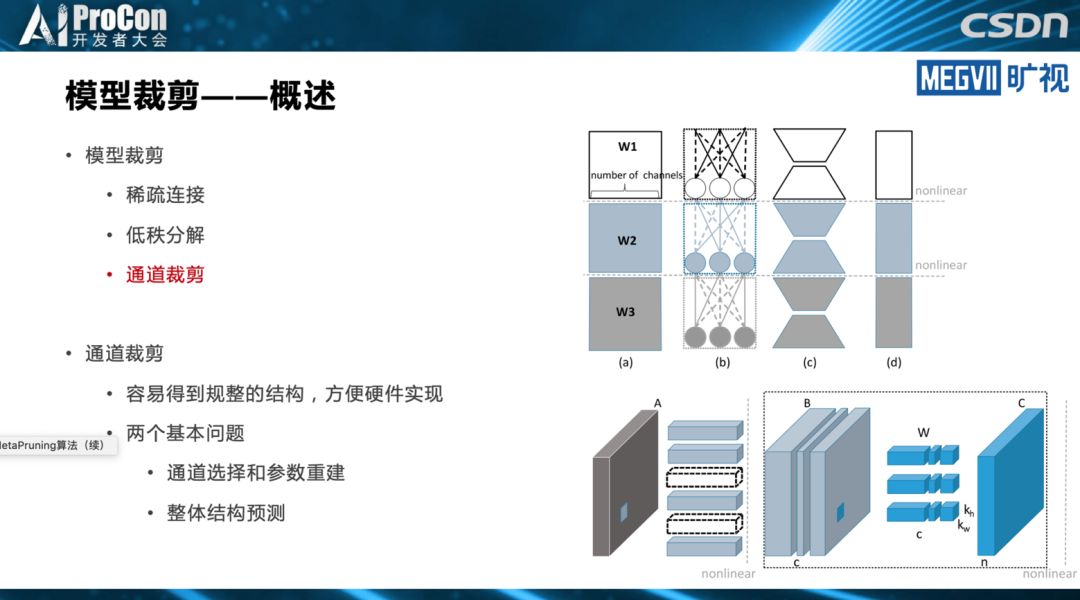
模型设计概述
深度学习时代,我们把抽取特征的结构称为基础模型,CNN是目前在视觉上使用最广泛的模型,我们要进行一项物体检测,比较典型的任务是都需要一个非常强力的基础模型作为支撑,这个基础模型是现代视觉识别系统的一个最为关键的点。
基础模型是最为关键的点有两层含义:第一,一个好的基础模型对整个系统的性能提升是决定性的,从精度或者从准确率来说优秀的基础模型起到了本质的作用。第二,从模型的实用性来说,搞深度学习的都知道基础模型通常占据了视觉系统的绝大部分运行时间,也吃了绝大多数运行功耗和存储。不管从精度还是从速度或功耗的角度,基础模型都是视觉系统的核心部分。
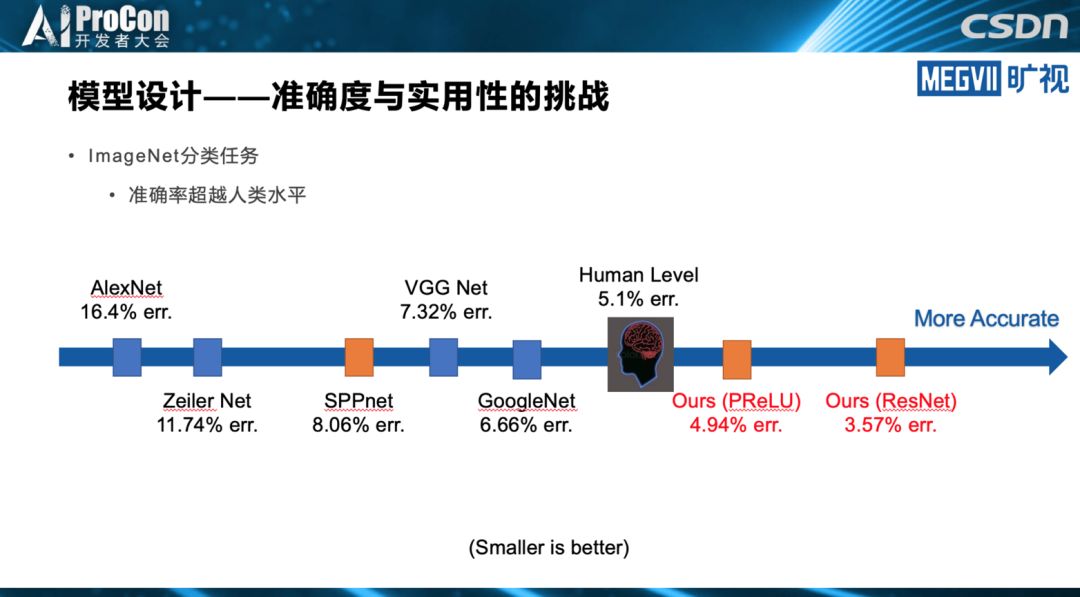
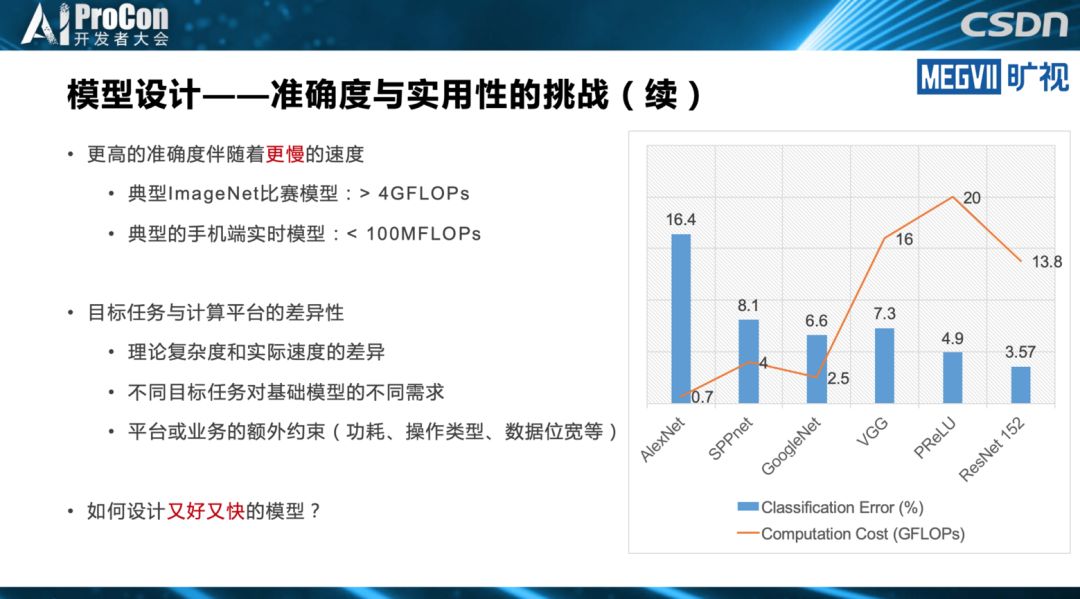
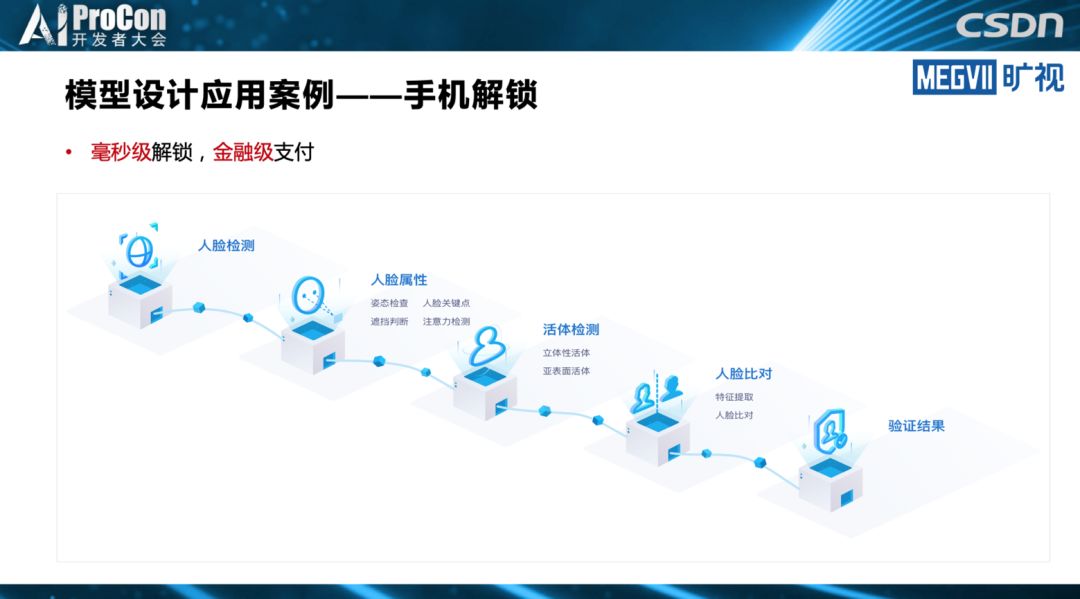

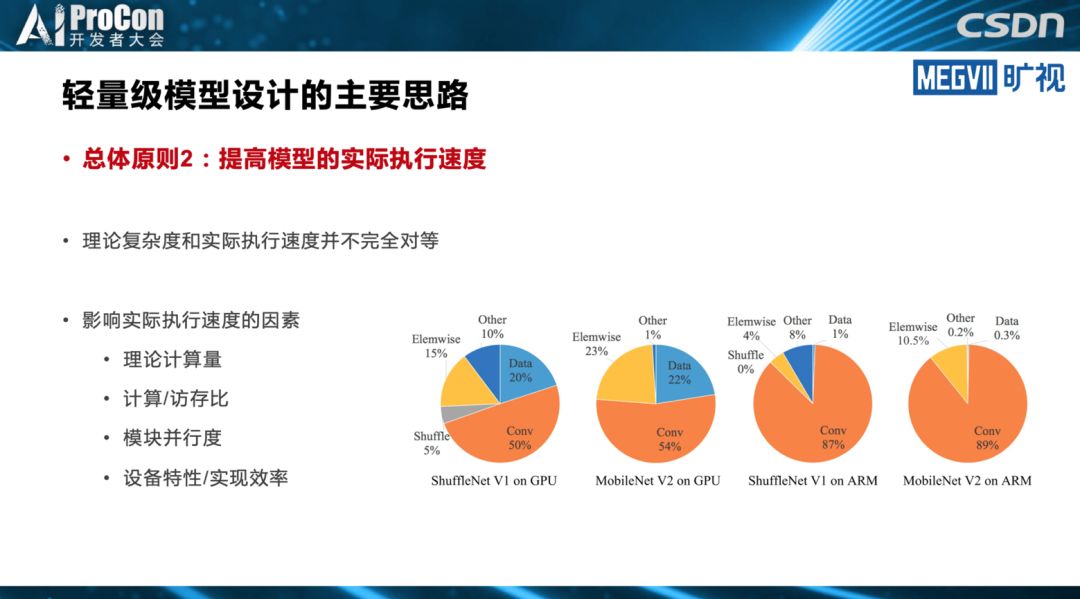
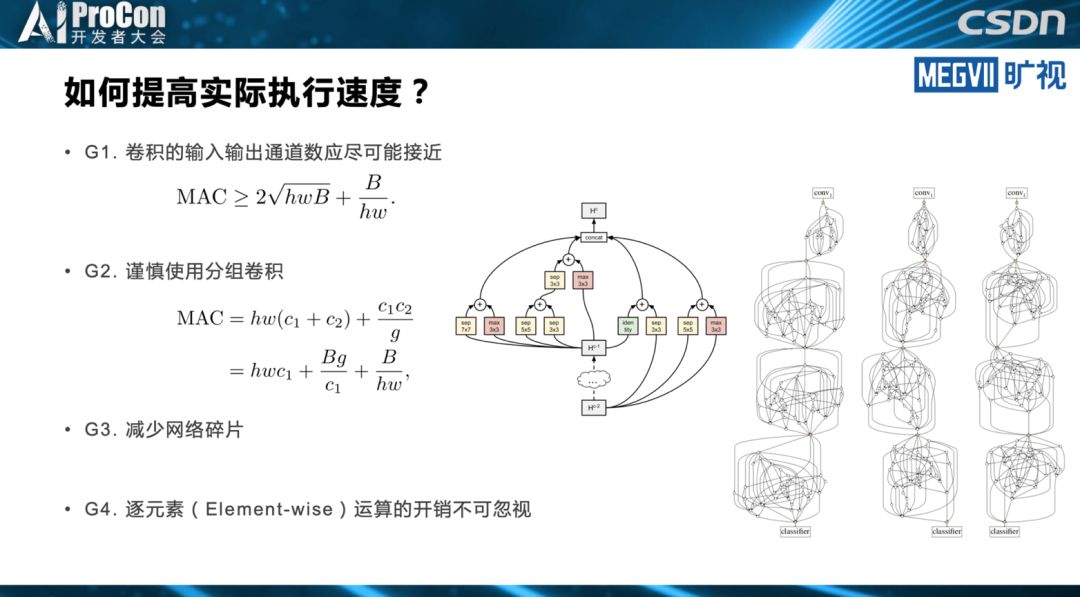
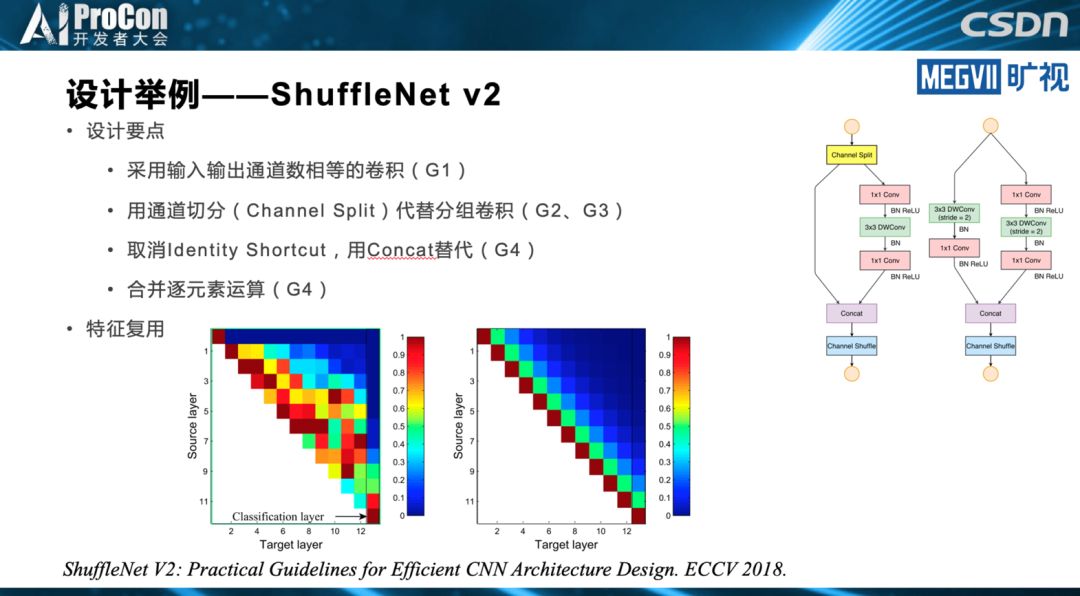
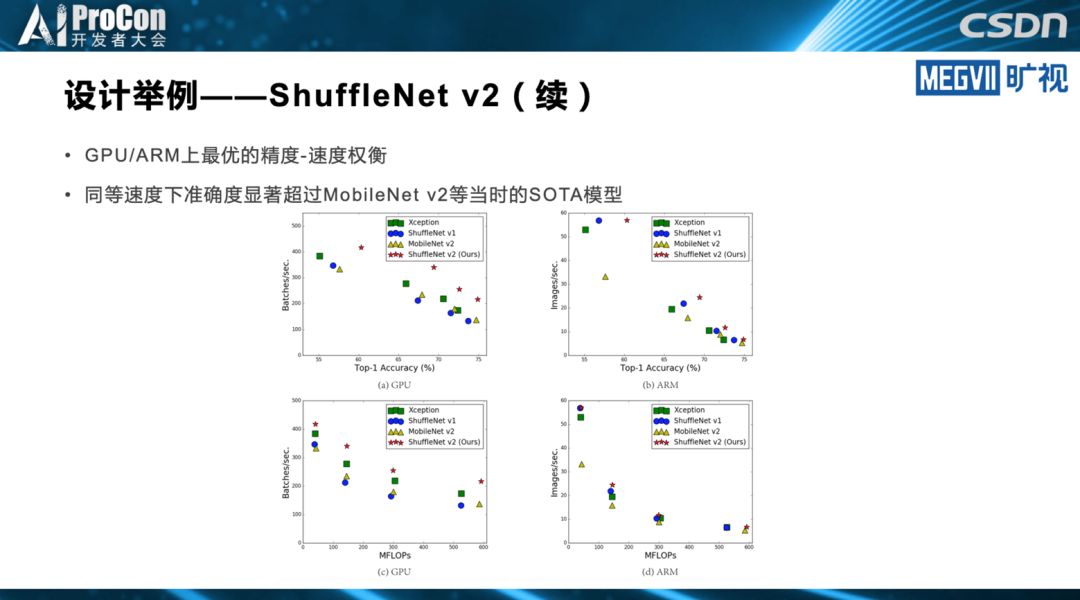


◆
精彩推荐
◆
推荐阅读
鸿蒙 OS 的到来,能为我们改变什么?
干货 | OpenCV看这篇就够了,9段代码详解图像变换基本操作
周杰伦的《说好不哭》,20万点评Python来分析
算法人必懂的进阶SQL知识,4道面试常考题
6张拓扑图揭秘中心化交易所的5种行为, 原来中心化比你想象的重要
分布式存储春天已来Storj首登top10; Cardano排名上升; 以太坊比特币活跃地址双下降 | 数据周榜
华为愿出售5G技术渴望对手;苹果将向印度投资10亿美元;华为全联接大会首发计算战略;腾讯自研轻量级物联网操作系统正式开源……
TDD 就是个坑
厉害!接班马云的为何是张勇?

你点的每个“在看”,我都认真当成了喜欢“
相关文章:

Python脱产8期 Day02
一 语言分类 机器语言,汇编语言,高级语言(编译和解释) 二 环境变量 1、配置环境变量不是必须的2、配置环境变量的目的:为终端提供执行环境 三Python代码执行的方式 1交互式:.控制台直接编写运行python代码 …

分别用Eigen和C++(OpenCV)实现图像(矩阵)转置
(1)、标量(scalar):一个标量就是一个单独的数。(2)、向量(vector):一个向量是一列数,这些数是有序排列的,通过次序中的索引,可以确定每个单独的数。(3)、矩阵(matrix):矩阵是一个二维数组,其中的…
Linux基础优化
***************************************************************************************linux系统的优化有很多,我简单阐述下我经常优化的方针:记忆口诀:***********************一清、一精、一增;两优、四设、七其他。*****…
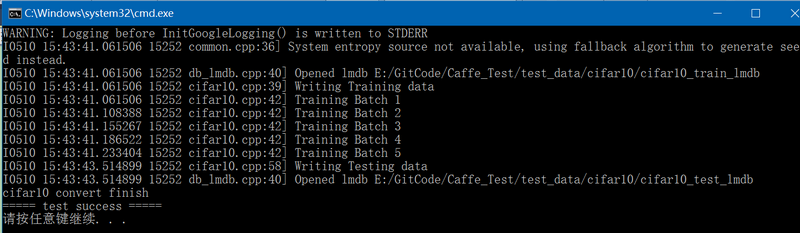
数据集cifar10到Caffe支持的lmdb/leveldb转换的实现
在 http://blog.csdn.net/fengbingchun/article/details/53560637 对数据集cifar10进行过介绍,它是一个普通的物体识别数据集。为了使用Caffe对cifar10数据集进行train,下面实现了将cifar10到lmdb/leveldb的转换实现:#include "funset.h…
计算两个时间的间隔时间是多少
/*** 计算两个时间间隔* param startTime 开始时间* param endTime 结束时间* param type 类型(1:相隔小时 2:)* return*/public static int compareTime(String startTime, String endTime, int type) {if (endTime nul…

作为西二旗程序员,我是这样学习的.........
作为一名合格的程序员,需要时刻保持对新技术的敏感度,并且要定期更新自己的技能储备,是每个技术人的日常必修课。但要做到这一点,知乎上的网友说最高效的办法竟然是直接跟 BAT 等一线大厂取经。讲真的,BAT大厂的平台是…

2月国内搜索市场:360继续上升 百度下降0.62%
IDC评述网(idcps.com)03月06日报道:根据CNZZ数据显示,在国内搜索引擎市场中,百度在2014年2月份所占的份额继续被蚕食,环比1月份,下降了0.62%,为60.50%。与此相反,360搜索…

不止于刷榜,三大CV赛事夺冠算法技术的“研”与“用”
(由AI科技大本营付费下载自视觉中国)整理 | Jane出品 | AI科技大本营(ID:rgznai100)在 5 个月时间里(5月-9月),创新工场旗下人工智能企业创新奇智连续在世界顶级人脸检测竞赛 WIDER …
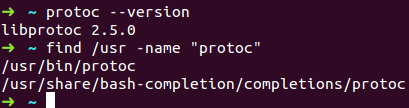
Ubuntu14.04上编译指定版本的protobuf源码操作步骤
Google Protobuf的介绍可以参考 http://blog.csdn.net/fengbingchun/article/details/49977903 ,这里介绍在Ubuntu14.04上编译安装指定版本的protobuf的操作步骤,这里以2.4.1为例:1. Ubuntu14.04上默认安装的是2.5.0,…
Linux下,各种解压缩命令集合
Linux下,各种解压缩命令集合tar xvfj lichuanhua.tar.bz2tar xvfz lichuanhua.tar.gztar xvfz lichuanhua.tgztar xvf lichuanhua.tarunzip lichuanhua.zip.gz解压 1:gunzip FileName.gz解压 2:gzip -d FileName.gz压缩:gzip File…
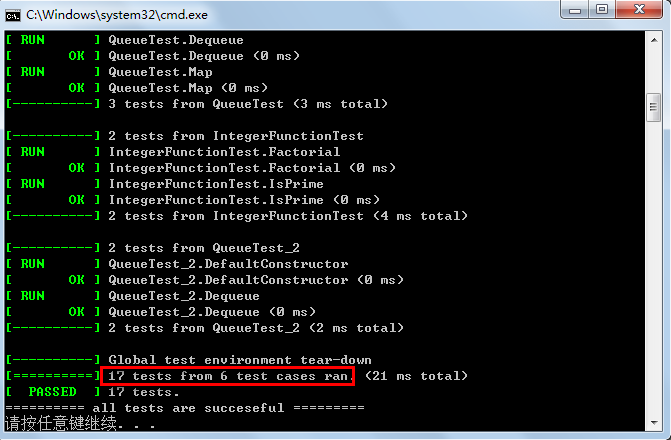
gtest使用初级指南
之前在 http://blog.csdn.net/fengbingchun/article/details/39667571 中对google的开源库gtest进行过介绍,现在看那篇博文,感觉有些没有说清楚,这里再进行总结下:Google Test是Google的开源C单元测试框架,简称gtest。…
iOS视频流采集概述(AVCaptureSession)
需求:需要采集到视频帧数据从而可以进行一系列处理(如: 裁剪,旋转,美颜,特效....). 所以,必须采集到视频帧数据. 阅读前提: 使用AVFoundation框架采集音视频帧数据GitHub地址(附代码) : iOS视频流采集概述 简书地址 : iOS视频流采…

300秒搞定第一超算1万年的计算量,量子霸权时代已来?
(由AI科技大本营付费下载自视觉中国)作者 | 马超责编 | 郭芮来源 | CSDN 博客近日,美国航天局(NASA)发布了一篇名为《Quantum Supremacy Using a Programmable Superconducting Processor》的报道,称谷歌的…
2014-3-6 星期四 [第一天执行分析]
昨日进度: [毛思想]:看测控技术量待定 --> [良]超额完成,昨天基本上把测控看了一大半啦 [汇编]:认真听课,边听边消化自学 --> [中]基本满足,还需要抽时间总结,特别是前面寻址的各种情况…

行列式介绍及Eigen/OpenCV/C++的三种实现
行列式,记作det(A),是一个将方阵A映射到实数的函数。行列式等于矩阵特征值的乘积。行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或者缩小了多少。如果行列式是0,那么空间至少沿着某一维完全收缩了,使其失去了所有的体积…

基于Go的语义解析开源库FMR,“屠榜”模型外的NLP利器
(由AI科技大本营付费下载自视觉中国)作者 | 刘占亮 一览群智技术副总裁编辑 | Jane出品 | AI科技大本营(ID:rgznai100)如何合理地表示语言的内在意义?这是自然语言处理业界中长久以来悬而未决的一个命题。在…

【高级数据类型2】- 10. 接口
2019独角兽企业重金招聘Python工程师标准>>> Go语言-接口 在Go语言中,一个接口类型总是代表着某一种类型(即所有实现它的类型)的行为。一个接口类型的声明通常会包含关键字type、类型名称、关键字interface以及由花括号包裹的若干…
Linux软件包命令
2019独角兽企业重金招聘Python工程师标准>>> dpkg命令: dpkg -i **/**.deb 安装软件 dpkg -x **.deb 解开.deb文件 dpkg -r /-p 删除并清配置 更详细的 用dpkg --help 查询 如下: dpkg -i|--install <.deb 文件的文件名> ... | -R|--re…
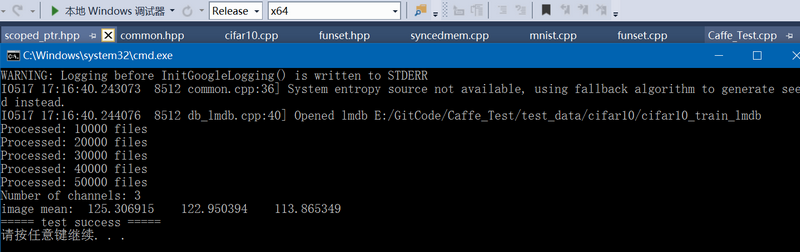
Caffe中计算图像均值的实现(cifar10)
在深度学习中,在进行test时经常会减去train数据集的图像均值,这样做的好处是:属于数据预处理中的数据归一化,降低数据间相似性,可以将数值调整到一个合理的范围。以下code是用于计算cifar10中训练集的图像均值…
阿里云弹性公网IP(EIP)的使用限制
阿里云弹性公网IP(EIP)是一种可以独立购买和持有的公网IP地址资源,弹性公网IP具有独立购买持有、弹性绑定和配置灵活等优势,但实际使用中弹性公网IP也是有很多限制的,阿里云惠网分享弹性公网IP(EIP…

400名微软员工主动曝光薪资:28万元到228万元不等!
作者 | Dave Gershgorn译者 | 弯月,编辑 | 郭芮来源 | CSDN(ID:CSDNnews)【导读】近日,近400名微软员工分享了他们的薪酬(从4万美元到32万美元不等,约为28万人民币到228万人民币)&am…
Extjs:添加查看全部按钮
var grid new Ext.grid.GridPanel({renderTo:tsllb,title:产品成本列表,selModel:csm,height:350,columns:[csm,{header: "编码", dataIndex: "bm", sortable: true,hidden:true},{header: "产品", dataIndex: "cp", sortable: true},…

练手扎实基本功必备:非结构文本特征提取方法
作者 | Dipanjan (DJ) Sarkar编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】本文介绍了一些传统但是被验证是非常有用的,现在都还在用的策略,用来对非结构化的文本数据提取特征。介绍在本文中,我们将研究如…
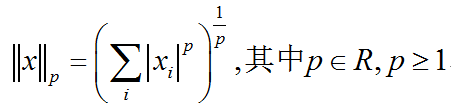
范数介绍及C++/OpenCV/Eigen的三种实现
有时我们需要衡量一个向量的大小。在机器学习中,我们经常使用被称为范数(norm)的函数衡量向量大小。形式上,Lp范数定义如下:范数(包括Lp范数)是将向量映射到非负值的函数。直观上来说,向量x的范数衡量从原点到点x的距离。更严格地…
js添加网页水印和three.js场景中加水印
我们在日常网页开发的时候,可能想给自己的网页或者canvas里面添加水印,增添个人标记,我这里分为普通静态html页面和threejs中3d场景里面添加水印功能。一 静态html页面添加水印你只需要在你的页面添加一个图片遮罩,通过绝对定位和…
JAVA学习笔记(6)
关于多线程的优先级,这个程序里面,现在计算机比较好,int存储不下了,我跑了好几次都是负分,特把int改成long。但是之后跑出来的结果,两个数字都差不多,不知道是什么问题?等待答案中。…
C++/C++11中std::deque的使用
std::deque是双端队列,可以高效的在头尾两端插入和删除元素,在std::deque两端插入和删除并不会使其它元素的指针或引用失效。在接口上和std::vector相似。与sdk::vector相反,std::deque中的元素并非连续存储:典型的实现是使用一个…

贾扬清:我对人工智能方向的一点浅见
阿里妹导读:作为 AI 大神,贾扬清让人印象深刻的可能是他写的AI框架Caffe ,那已经是六年前的事了。经过多年的沉淀,成为“阿里新人”的他,对人工智能又有何看法?最近,贾扬清在阿里内部分享了他的…

吴甘沙:天外飞“厕”、红绿灯消失,未来无人驾驶将被重新定义
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)2019 年9 月 5 日至 7 日,由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文 IT 技术社区 CS…

Linux内核--网络栈实现分析(二)--数据包的传递过程--转
转载地址http://blog.csdn.net/yming0221/article/details/7492423 作者:闫明 本文分析基于Linux Kernel 1.2.13 注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”…