练手扎实基本功必备:非结构文本特征提取方法

作者 | Dipanjan (DJ) Sarkar
编译 | ronghuaiyang
来源 | AI公园(ID:AI_Paradise)
【导读】本文介绍了一些传统但是被验证是非常有用的,现在都还在用的策略,用来对非结构化的文本数据提取特征。
介绍
动机
理解文本数据
特征工程策略
import pandas as pd import numpy as np import re import nltk import matplotlib.pyplot as plt pd.options.display.max_colwidth = 200 %matplotlib inline corpus = ['The sky is blue and beautiful.', 'Love this blue and beautiful sky!', 'The quick brown fox jumps over the lazy dog.', "A king's breakfast has sausages, ham, bacon, eggs, toast and beans", 'I love green eggs, ham, sausages and bacon!', 'The brown fox is quick and the blue dog is lazy!', 'The sky is very blue and the sky is very beautiful today', 'The dog is lazy but the brown fox is quick!' ] labels = ['weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather', 'animals'] corpus = np.array(corpus) corpus_df = pd.DataFrame({'Document': corpus, 'Category': labels}) corpus_df = corpus_df[['Document', 'Category']]
文本预处理
- 删除标签:我们的文本经常包含不必要的内容,如HTML标签,分析文本的时候这不会增加多少价值。BeautifulSoup库可以帮我们做很多必须的工作。
- 删除重音字符:在任何文本语料库中,特别是在处理英语时,通常可能要处理重音字符/字母。因此,我们需要确保将这些字符转换并标准化为ASCII字符。一个简单的例子是将é转换为e。
- 扩展缩略语:在英语中,缩略语基本上是单词或音节的缩写形式。这些现有单词或短语的缩略形式是通过删除特定的字母和声音来创建的。例如,do not变为don 't以及I would 变为I 'd 。将每个缩略语转换为其扩展的原始形式通常有助于文本标准化。
- 删除特殊字符:非字母数字字符的特殊字符和符号通常会增加非结构化文本中的额外噪音。通常,可以使用简单正则表达式(regexes)来实现这一点。
- 词根提取和词形还原:词干通常是可能的单词的基本形式,可以通过在词干上附加词缀,如前缀和后缀来创建新单词。这就是所谓的拐点。获取单词基本形式的反向过程称为“词根提取”。一个简单的例子是单词WATCHES, WATCHING,和WATCHED。它们以词根WATCH作为基本形式。词形还原与词根提取非常相似,在词根提取中,我们去掉词缀以得到单词的基本形式。然而,在这种情况下,基本形式被称为根词,而不是词根。不同之处在于,词根总是一个词典上正确的单词(存在于字典中),但根词的词干可能不是这样。
- 删除停止词:在从文本中构造有意义的特征时,意义不大或者没有意义的词被称为停止词或停止词。如果你在语料库中做一个简单的词或词的频率,这些词的频率通常是最高的。像a、an、the、and等词被认为是停止词。没有一个通用的停止词列表,但是我们使用了一个来自“nltk”的标准英语停止词列表。你还可以根据需要添加自己的域特定的停止词。
wpt = nltk.WordPunctTokenizer() stop_words = nltk.corpus.stopwords.words('english') def normalize_document(doc): # lower case and remove special characters\whitespaces doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I|re.A) doc = doc.lower() doc = doc.strip() # tokenize document tokens = wpt.tokenize(doc) # filter stopwords out of document filtered_tokens = [token for token in tokens if token not in stop_words] # re-create document from filtered tokens doc = ' '.join(filtered_tokens) return docnorm_corpus = normalize_corpus(corpus) norm_corpus Output ------ array(['sky blue beautiful', 'love blue beautiful sky', 'quick brown fox jumps lazy dog', 'kings breakfast sausages ham bacon eggs toast beans', 'love green eggs ham sausages bacon', 'brown fox quick blue dog lazy', 'sky blue sky beautiful today', 'dog lazy brown fox quick'], dtype='<U51')词袋模型
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(min_df=0., max_df=1.) cv_matrix = cv.fit_transform(norm_corpus) cv_matrix = cv_matrix.toarray() cv_matrix Output ------ array([[0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0], [1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0], [1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0], [0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 1], [0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0] ], dtype=int64)# get all unique words in the corpus vocab = cv.get_feature_names() # show document feature vectors pd.DataFrame(cv_matrix, columns=vocab)
N-Grams袋模型
# you can set the n-gram range to 1,2 to get unigrams as well as bigrams bv = CountVectorizer(ngram_range=(2,2)) bv_matrix = bv.fit_transform(norm_corpus) bv_matrix = bv_matrix.toarray() vocab = bv.get_feature_names() pd.DataFrame(bv_matrix, columns=vocab)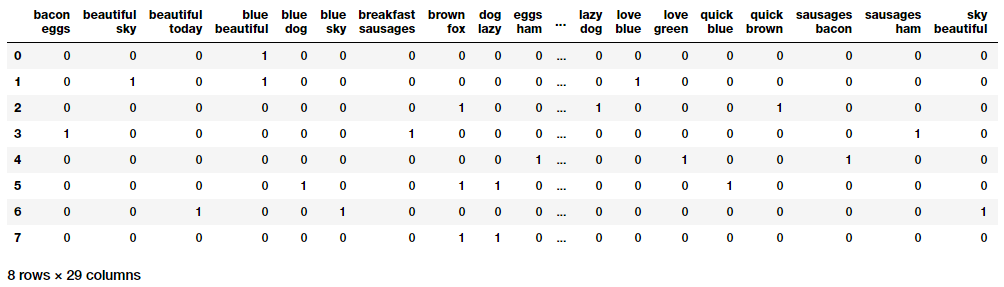
TF-IDF模型
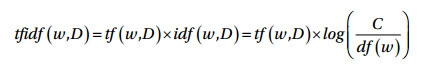
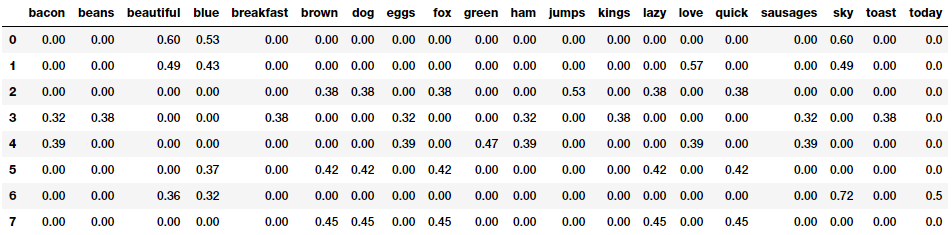
文档相似度
from sklearn.metrics.pairwise import cosine_similarity similarity_matrix = cosine_similarity(tv_matrix)
similarity_df = pd.DataFrame(similarity_matrix)
similarity_df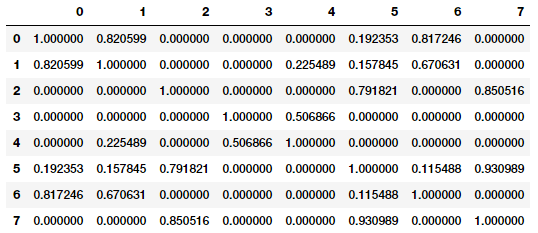
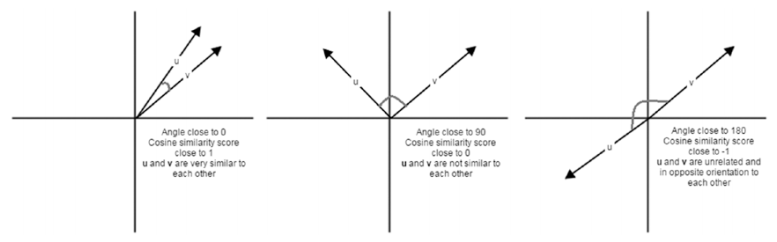
使用相似特征对文档进行聚类
plt.figure(figsize=(8, 3))
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point')
plt.ylabel('Distance')
dendrogram(Z)
plt.axhline(y=1.0, c='k', ls='--', lw=0.5)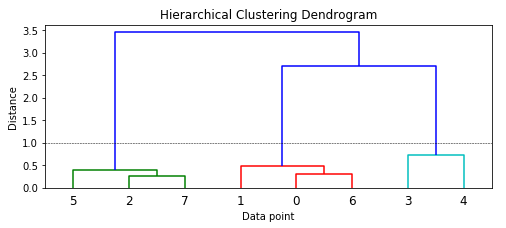
from scipy.cluster.hierarchy import fcluster
max_dist = 1.0 cluster_labels = fcluster(Z, max_dist, criterion='distance')
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)
总结
◆
精彩推荐
◆

推荐阅读
鸿蒙 OS 的到来,能为我们改变什么?
干货 | OpenCV看这篇就够了,9段代码详解图像变换基本操作
周杰伦的《说好不哭》,20万点评Python来分析
算法人必懂的进阶SQL知识,4道面试常考题
6张拓扑图揭秘中心化交易所的5种行为, 原来中心化比你想象的重要
分布式存储春天已来Storj首登top10; Cardano排名上升; 以太坊比特币活跃地址双下降 | 数据周榜
华为愿出售5G技术渴望对手;苹果将向印度投资10亿美元;华为全联接大会首发计算战略;腾讯自研轻量级物联网操作系统正式开源……
TDD 就是个坑
厉害!接班马云的为何是张勇?

你点的每个“在看”,我都认真当成了喜欢“
相关文章:
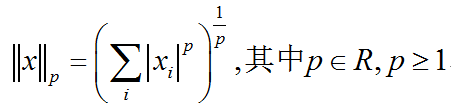
范数介绍及C++/OpenCV/Eigen的三种实现
有时我们需要衡量一个向量的大小。在机器学习中,我们经常使用被称为范数(norm)的函数衡量向量大小。形式上,Lp范数定义如下:范数(包括Lp范数)是将向量映射到非负值的函数。直观上来说,向量x的范数衡量从原点到点x的距离。更严格地…

js添加网页水印和three.js场景中加水印
我们在日常网页开发的时候,可能想给自己的网页或者canvas里面添加水印,增添个人标记,我这里分为普通静态html页面和threejs中3d场景里面添加水印功能。一 静态html页面添加水印你只需要在你的页面添加一个图片遮罩,通过绝对定位和…
JAVA学习笔记(6)
关于多线程的优先级,这个程序里面,现在计算机比较好,int存储不下了,我跑了好几次都是负分,特把int改成long。但是之后跑出来的结果,两个数字都差不多,不知道是什么问题?等待答案中。…
C++/C++11中std::deque的使用
std::deque是双端队列,可以高效的在头尾两端插入和删除元素,在std::deque两端插入和删除并不会使其它元素的指针或引用失效。在接口上和std::vector相似。与sdk::vector相反,std::deque中的元素并非连续存储:典型的实现是使用一个…

贾扬清:我对人工智能方向的一点浅见
阿里妹导读:作为 AI 大神,贾扬清让人印象深刻的可能是他写的AI框架Caffe ,那已经是六年前的事了。经过多年的沉淀,成为“阿里新人”的他,对人工智能又有何看法?最近,贾扬清在阿里内部分享了他的…

吴甘沙:天外飞“厕”、红绿灯消失,未来无人驾驶将被重新定义
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)2019 年9 月 5 日至 7 日,由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文 IT 技术社区 CS…

Linux内核--网络栈实现分析(二)--数据包的传递过程--转
转载地址http://blog.csdn.net/yming0221/article/details/7492423 作者:闫明 本文分析基于Linux Kernel 1.2.13 注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”…
C++/C++11中std::stack的使用
栈stack 是一个容器适配器(container adaptor)类型,被特别设计用来运行于LIFO(Last-in First-out,后进先出)场景,在该场景中,只能从容器末尾添加和删除元素,其定义在stack头文件中。stack默认基于std::deque实现&#…
团队前四次作业——个人总结
团队前四次作业——个人总结 描述 团队名称待就业六人组相关团队第四次作业答辩——反思与总结做了哪些事?工作量、完成度 作业负责工作量完成度团队队员展示创意合照后期1h95%项目选题报告编写创新和收益部分2h85%项目原型设计原型设计6h95%需求规格说明书功能需求…

吴甘沙:天外飞“厕”、红绿灯消失,未来无人驾驶将被重新定义 | AI ProCon 2019
2019 年9 月 5 日至 7 日,由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文 IT 技术社区 CSDN 主办的 2019 中国 AI 开发者大会(AI ProCon 2019&#x…
MySQL基础day03_数据的导入、导出-MySQL 5.6
MySQL基础day03_数据的导入、导出-MySQL 5.6注:把数据按照一定格式存放到文件里才能进行数据的导入。1,数据导入的条件把文件里的内容保存到数据的表里;把数据按照一定格式存放文件里;注:默认情况下,只有管…
“含光”剑出,谁与争锋?阿里重磅发布首颗AI芯片含光800
作者 | 夕颜、胡巍巍 编辑 | 唐小引 出品 | AI 科技大本营(ID:rgznai100) 9 月末的杭州气温适宜,宜出游,宜在湖边餐厅浅酌一杯清茶消闲。但在钱塘江水支流河畔的云栖小镇,却完全一副与闲适氛围不相称的热闹景象。 …

c++面试题中经常被面试官面试的小问题总结(一)(本篇偏向基础知识)
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/10711810.html 1.类中的函数定义后加了一个const代表什么? 代表它将具备以下三个性质:1.const对象只能调用const成员函数。2.const对象的值不能被修改,在…
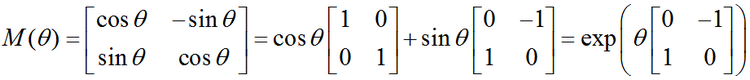
矩阵特征分解介绍及雅克比(Jacobi)方法实现特征值和特征向量的求解(C++/OpenCV/Eigen)
对角矩阵(diagonal matrix):只在主对角线上含有非零元素,其它位置都是零,对角线上的元素可以为0或其它值。形式上,矩阵D是对角矩阵,当且仅当对于所有的i≠j, Di,j 0. 单位矩阵就是对角矩阵,对角元素全部是1…

Entity Framework CodeFirst数据迁移
原文:Entity Framework CodeFirst数据迁移前言 紧接着前面一篇博文Entity Framework CodeFirst尝试。 我们知道无论是“Database First”还是“Model First”当模型发生改变了都可以通过Visual Studio设计视图进行更新,那么对于Code First如何更新已有的模型呢&…
限时早鸟票 | 2019 中国大数据技术大会(BDTC)超豪华盛宴抢先看!
2019 年12月5-7 日,由中国计算机学会主办,CCF 大数据专家委员会承办,CSDN、中科天玑数据科技股份有限公司协办的 2019 中国大数据技术大会,将于北京长城饭店隆重举行。届时,超过百位技术专家及行业领袖将齐聚于此&…

Google AI 系统 DeepMind无法通过 高中数学
Google 旗下 DeepMind 团队让 AI 系统接受一项高中程度的数学测试,结果在 40 道题目中只答对了 14 题,甚至连「1111111」也算错了。说来难以置信,Google AI 系统能打败人类世界棋王,却无法通过高中程度的数学考试。上周࿰…
C++11中std::tuple的使用
std::tuple是类似pair的模板。每个pair的成员类型都不相同,但每个pair都恰好有两个成员。不同std::tuple类型的成员类型也不相同,但一个std::tuple可以有任意数量的成员。每个确定的std::tuple类型的成员数目是固定的,但一个std::tuple类型的…
PHP Countable接口
实现该接口可以使用count()方法来获取集合的总数转载于:https://www.cnblogs.com/xiaodo0/p/3611307.html
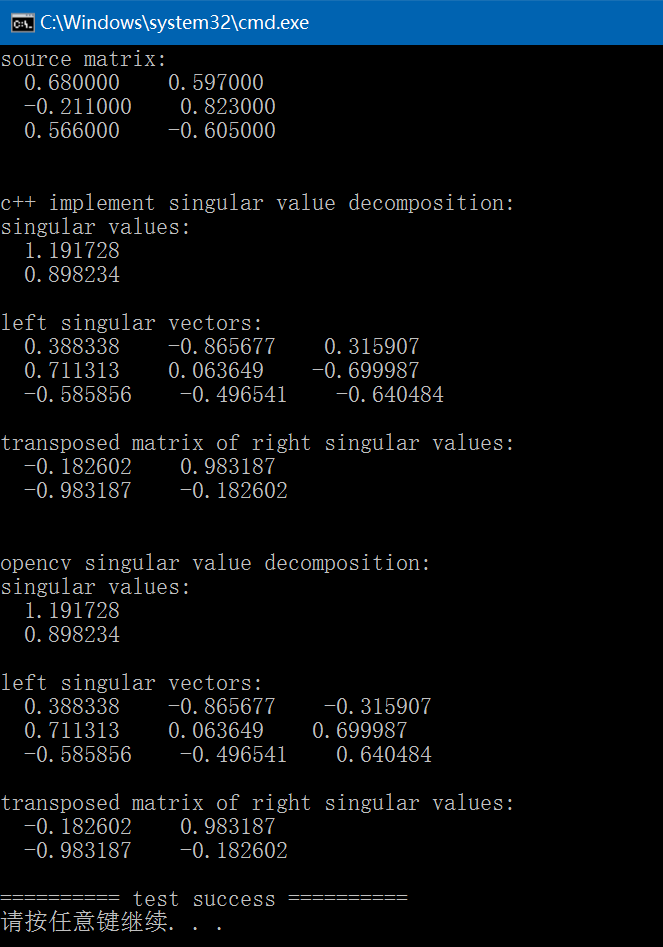
矩阵奇异值分解简介及C++/OpenCV/Eigen的三种实现
奇异值分解(singular value decomposition, SVD):将矩阵分解为奇异向量(singular vector)和奇异值(singular value)。通过奇异值分解,我们会得到一些与特征分解相同类型的信息。然而,奇异值分解有更广泛的应用。每个实数矩阵都有一个奇异值分…

经典!工业界深度推荐系统与CTR预估必读的论文汇总
(图片付费下载自视觉中国)来源 | 深度传送门(ID: gh_5faae7b50fc5)导读:本文是“深度推荐系统”专栏的第十一篇文章,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变…
docker上传自己的镜像
https://blog.csdn.net/boonya/article/details/74906927 需要注意的就是命名规范 docker push 注册用户名/镜像名 tag命令修改为规范的镜像: docker tag boonya/tomcat-allow-remote boonyadocker/tomcat-allow-remote转载于:https://www.cnblogs.com/MC-Curry/p/1…

多个class相同的input标签 获取当前值!方法!
2019独角兽企业重金招聘Python工程师标准>>> var a $(this).prev( ".你的class" ).val(); 转载于:https://my.oschina.net/u/1169079/blog/210082
C++11中std::forward_list单向链表的使用
std::forward_list是在C11中引入的单向链表或叫正向列表。forward_list具有插入、删除表项速度快、消耗内存空间少的特点,但只能向前遍历。与其它序列容器(array、vector、deque)相比,forward_list在容器内任意位置的成员的插入、提取(extracting)、移动…

即学即用的30段Python实用代码
(图片付费下载自视觉中国)原标题 | 30 Helpful Python Snippets That You Can Learn in 30 Seconds or Less作 者 | Fatos Morina翻 译 | Pita & AI开发者Python是目前最流行的语言之一,它在数据科学、机器学习、web开发、脚本编写、自…
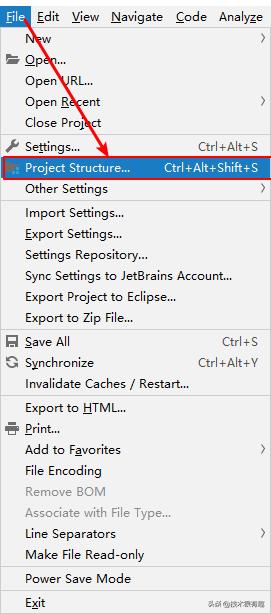
如何配置IntelliJ IDEA发布JavaEE项目?
一、以war的形式运行项目 步骤1 新建或者导入项目后,选择File菜单-》Project Structure...,如下图: 步骤2 配置项目类型,名字可以自定义: 说明:这里的Artifact如果没有配置好的话,配置Tomcat时没…
网络分布式软件bonic清除
近期,有一款网格计算软件,在很多服务器上进行了部署,利用cpu进行运算。虽然未构成安全隐患,但是比较消耗资源,影响设备正常运行。今天对设备彻底检查,发现了一个分布式计算软件boinc,他是利用网…
C++/C++11中std::list双向链表的使用
std::list是双向链表,是一个允许在序列中任何一处位置以常量耗时插入或删除元素且可以双向迭代的顺序容器。std::list中的每个元素保存了定位前一个元素及后一个元素的信息,允许在任何一处位置以常量耗时进行插入或删除操作,但不能进行直接随…
React组件设计之边界划分原则
简述 结合SOLID中的单一职责原则来进行组件的设计 Do one thing and do it well javaScript作为一个弱类型并在函数式和面对对象的领域里疯狂试探语言。SOLID原则可能与其他语言例如(java)的表现可能是不同的。不过作为软件开发领域通用的原则࿰…

阿里AI labs发布两大天猫精灵新品,将与平头哥共同定制智能语音芯片
作者 | 夕颜出品 | AI科技大本营(ID:rgznai100)2019 年,去年刮起的一阵智能音箱热浪似乎稍微冷却下来,新产品不再像雨后春笋一样层出不穷,挺过市场洗礼的产品更是凤毛麟角,这些产品的性能、技术支持和体验基…