阿里云智能运维的自动化三剑客

整理 | 王银
出品 | AI科技大本营(ID:rgznai100)
近日,2019 AI开发者大会在北京举行。会上,近百位中美顶尖AI专家、知名企业代表以及千余名AI开发者进行技术解读和产业论证。而在AI+DevOps论坛上,阿里巴巴高级技术专家滕圣波就阿里云与智能运维的发展之路对智能运维自动化三剑客——弹性伸缩、资源编排和运维编排进行了重点介绍。
在介绍自动化三剑客之前,滕圣波为我们讲述了阿里的上云路和智能运维的发展策略。
以双十一为例,阿里集团的业务量往年只有60%~70%承载在阿里云上,而今年将百分之百跑在公有云上。这意味着阿里云就是整个阿里集团的运维——将创建机器、计算力、存储、网络和管理机器及数据库这些本质上都是运维的要做的事进行代码化和自动化。
由此可见,阿里云已经成为阿里集团的技术底座。滕圣波还表示,未来阿里云集团的技术输出只通过阿里云,并且技术全面开放,从而达到集团和生态共享,促进互联网生态发展。
既然阿里云担当了整个集团的运维一角色,那传统运维人员又该何去何从?这本质上也是DevOps的问题。滕圣波以这么一个场景为例给出答案:半夜有一个严重告警,目前的机制是系统一旦出现异常,就会把相关开发或负责人叫起来。这意味着,截至目前,人工职守无可避免。但是阿里云的目标是无人职守,毕竟一周连续四次都被凌晨叫起来去处理告警身体是吃不消的。想象一下一个运维人员半夜起来看日志、采取动作;动作是什么?无非就是机器不够用了、代码多了、负载多了,如果加机器加资源解决不了就回滚代码。这些肯定都是可以自动化的,顺势而为,人工智能必成发展突破口。
我们都知道阿里云有SLA,而所有都是从架构出发的,但是架构不仅仅是阿里云的事情,也是客户的事情。一个架构是针对容量规划的,针对1万人的架构和针对1亿人的架构一定是不一样的。众所周知,企业都不是一开始就走到1亿人这个步骤,而是从1万人慢慢成长起来的。企业成长过程中需要不断调整自己的架构和运维。所以无人职守并不只是阿里云的职责,也是客户的职责。
简言之,“从运维到SRE,无人值守是目的,自动化是无人值守的手段,而人工智能又是自动化的手段之一。其中,无人值守的最后一公里由客户侧运维开发。”
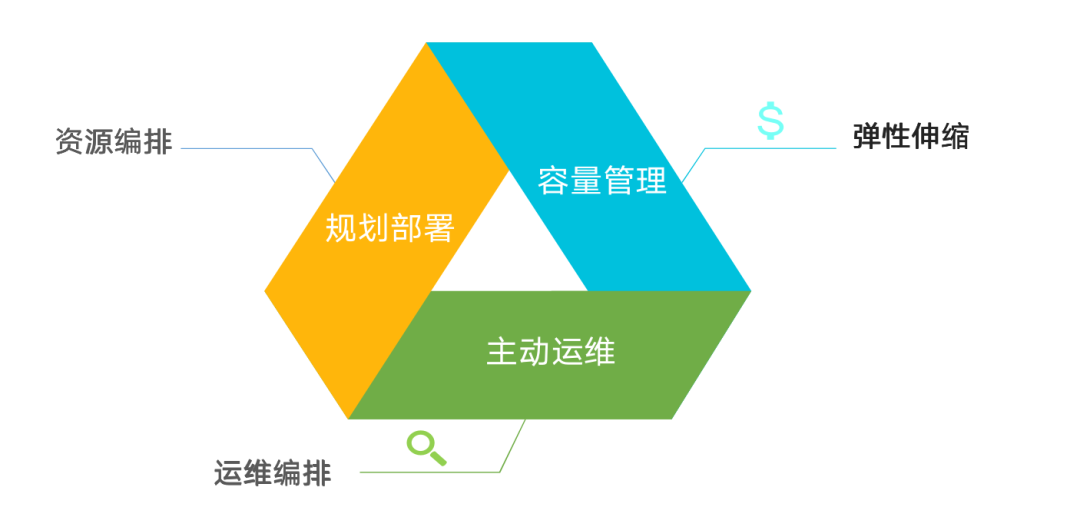
而后滕圣波为我们重点介绍了自动化三剑客。
第一便是弹性伸缩——即基于AI预测的弹性伸缩。原有监控指标模式,监控指标变化敏感,引起实例数量震荡,扩、缩容操作和业务变化存在延迟;智能预测模式可以做到预测业务变化智能调整实例数量,结合目标追踪模式完美贴合业务变化,能够最大程度地节省成本。
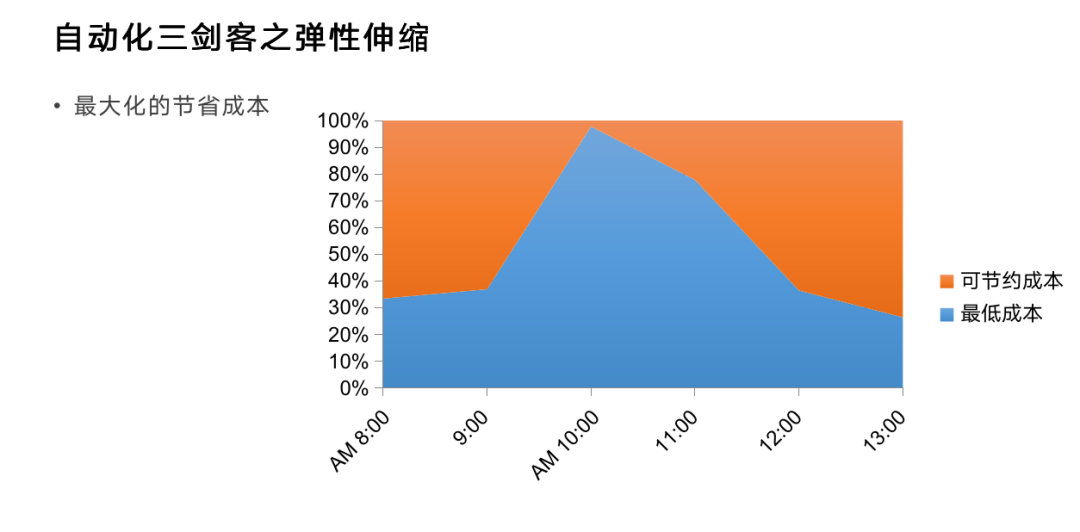
我们知道大多数公司的业务都是有流量曲线的,有高峰、有低谷,那对应的业务承载能力如何得知?好比双十一,阿里云在双十一有庞大体量,它所承载的业务量一定是在双十一之前按照顶峰就计算好的。但是这有什么问题?比如双十一之前阿里云有预估,通过全链路的压力测试知道需要准备多少资源,但是问题也来了,我们要提取多久准备这个资源?这是个成本的问题,资源是很贵的,如果我们提前1个月准备资源可能就多几亿元的成本负担在上面;如果我们能够提前1小时准备这个资源,那我就可能节省出来很多资源。越能够灵活地准备自己的资源,就越能够省钱,省钱极致到什么程度?最多能省多少钱?如图所示,容量上限和曲线之间的面积是我们最多能省的钱,这是弹性伸缩最大的价值。可惜,理想很丰满,现实很骨感。弹性伸缩很难把所有的成本都省出来。
弹性伸缩具体是怎么应用的?以下用两个例子来说明。
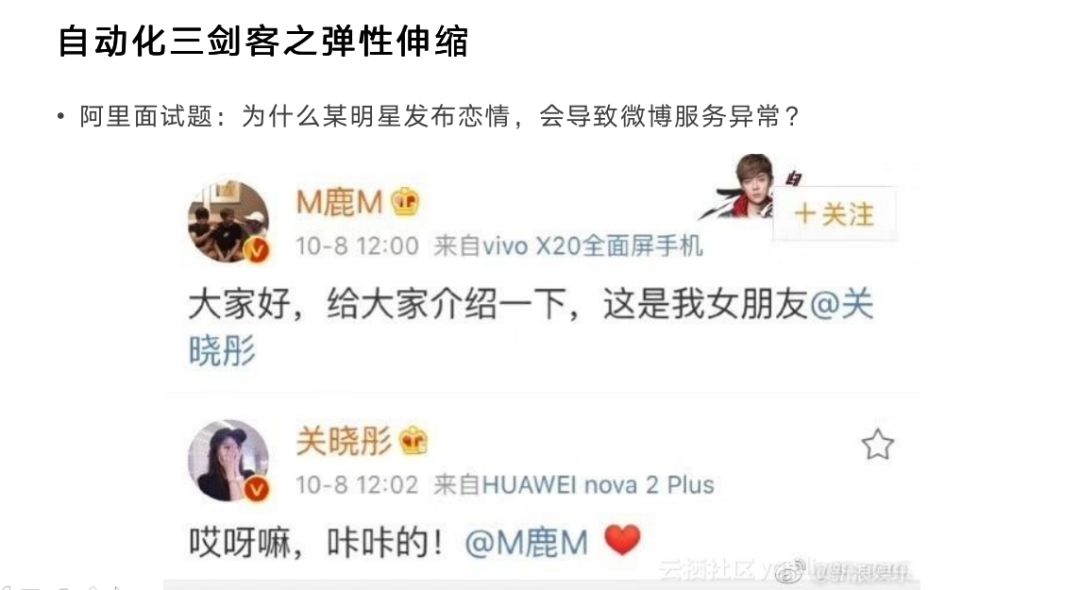
先看上面这张图,从技术角度分析为什么会出这个问题。首先发生的事情是一大堆狂点赞,这两个人的粉丝量加起来是巨大的。如果这些粉丝只狂点赞还好,赞就是数据库里多一条消息,多一条数据记录。赞并不难,难的是转发。转发这个事情太恐怖了,它不仅仅是克隆,在数据库里多几条记录。转发造成了更多消息流推送,消息量瞬间几何倍增。比如一开始100万人看到这个消息,里面有10万人转发,迅速在整个网络里造成了大量消息,挤占了大量网络,造成了大量数据库写操作。
读不可怕,因为读的话可以做分级、可以做CDN,但写这个东西太夸张了,写是必须真实的往数据库里做操作的。而且数据库当时有大量的缓存,而写不是缓存的特点,所以一下子就被打穿,接着就成为数据库的累赘了。在疯狂写数据的时候,数据库突然崩了,那么服务就会限流。但限流对于很多用户来讲是不可接受的,他会认为是服务宕掉了。这时候我们就可以用弹性伸缩去解决。有两个思路,一个是一定要快,快是什么概念?
大家看看基于监控逐步转化的预测,有很多都是基于监控指标的算法。当你的曲线已经开始往上走时,监控一定是第一时间能发现的,这时候我们能做的是赶紧扩充自己的计算资源、存储资源、数据库、缓存,可是实际上我们资源扩充的真实情况是滞后的。为什么?监控指标出现动作时意味着流量已经来了,这时候弹指标已经迟了、跟不上了。阿里云上弹一个指标大概十几秒,这个十几秒对一个突发的新闻事件来说是不够快的,有可能它涨了1倍了,资源才涨了30%。所以弹性计算、弹性伸缩最核心的就是要做到快。
再比如用户抢火车票或者干什么生意,火车票发售一定有个高峰,负载一下子涨了5倍是非常恐怖的,相当于多了4000台机器。但是4000台机器对阿里云来讲是万分之一、千分之一,是流量上出现一个很平滑的不太引人注意的小刺而已。我们的弹性伸缩有提前准备的库存 ,这就是资源大的优势,本身也是云的优势。
但是再快也不一定足够快,即便预测流量来了,可是如果用户连5秒都不愿意承担损失 ,那怎么办?只能预测,在洪峰到来前就把资源准备好。对此,阿里有智能预测模式。不过目前还有局限性——只在有规律的场景下做得很好,例如定点发售火车票。而头条、微博、等等弹性伸缩不完全依赖于阿里云,阿里云有机器学习算法、动态预测、实时告警等等基于监控很快帮客户做弹性,但是最了解客户业务的一定是客户自己,所以很多时候还得结合客户的具体业务提前把资源准备好。
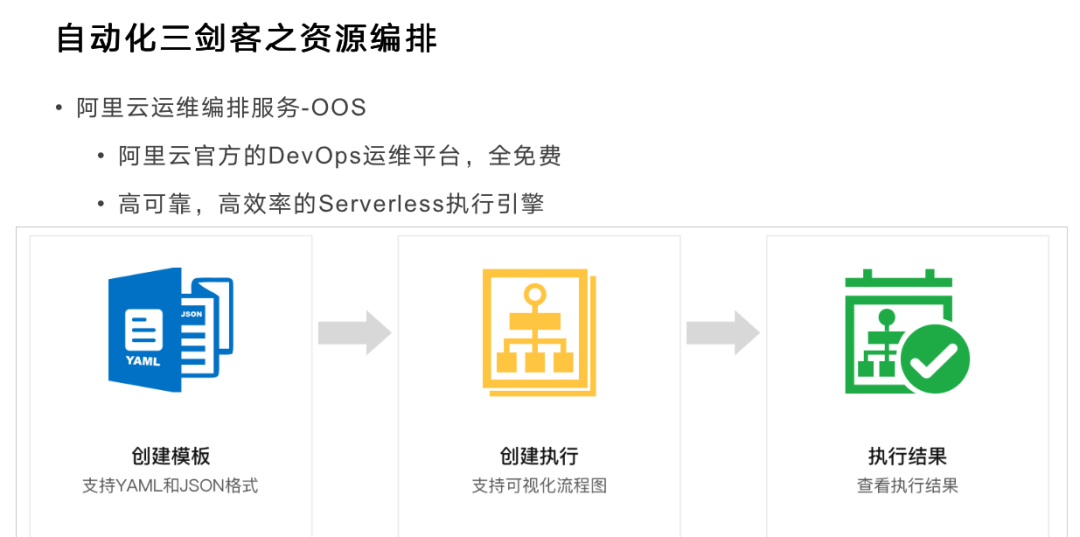
说到资源,自然就要引出另外一个三剑客——资源编排。阿里云资源编排-ROS,可以实现提交代码资源自动修改,版本化管理、随时回滚以及Copy/paste完成资源成套复制。
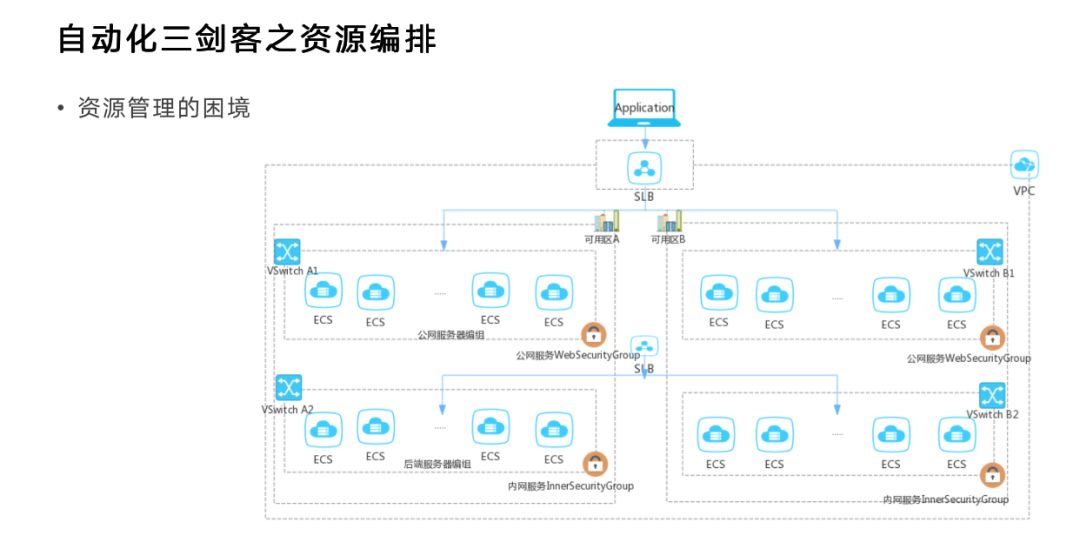
上面是一个经典的网上应用的架构图,能看得出它有四点困境。
第一,需要更多资源。一般情况下,在一个阿里云上,随着业务的增长,需要的阿里云资源会越来越多,可能需要10个、20个、30个。阿里云上现在有300多种多少资源,都是客户经常会用到的资源,随着资源越来越多,怎么管理是关键问题。CMDB是很流行的管理办法,但是它无法保证自己永远是最新的并且永远跟实际相吻合。
第二点是历史记录的存储问题。阿里云对ECS的历史记录不做保留 ,需要客户保留,资源编排就是一个很好的办法。
第三是准确操作问题,因为人是一定会犯错的。有这么一个场景:某一天一个阿里员工在操作VIP时引发一个故障,这个故障直接导致大量北京区域的很多ECS不可服务了。大家可能会责怪这个运维,但是是运维的责任吗?这是典型的让运维做背锅侠,最深层次的原因是自动化。没有什么人不会出错,除非让机器去操作,一个经过测试过的程序,让它再跑一遍是最不容易出错的,其他情况下都可能出错。所以要想不出错,就像代码那样把资源编排写成个代码,测试之后线上跑一遍,这才是万全之策。
最后一点就是重复操作问题。企业并不是只有一个区域、一个环境,他们大多有开发环境、线上环境等等,这些环境可能只有一点点区别,我们不可能每个都重复来一遍,所以用资源编排就可以很好的解决这点。
那现实资源编排具体是怎么实现的呢?阿里云提供一个资源编排的服务。比如把代码文件提交到代码库里,提交之后会发现阿里云上多了一服务器。另外,版本管理copy/paste完成资源成套复制。可能听起来有点模糊,所以腾圣波老师为我们讲述来一个真实的使用场景:云产品是分级的,最底层的是云存储等等,容服务器是架设在之上的。上层的产品对客户提供服务时一定会用到底层的产品,比如我们买了一个数据库,实际上我们是买了一个云服务器+数据库软件,但是这个云服务器是我们看不到的,是数据库这个产品帮我们运维了服务器。
容器也一样,我们买了容器,底下一定是有服务器的,我们看不到服务器,是因为容器产品帮我们运维了服务器。而容器服务我们可以一键部署。这是ROS控制台,一键部署本质上是做什么?这个文本文件描述了环境,VCP是网络,接下来点击创建,它就会自动帮你做,这就是ROS的模板。如果需要修改VPC,直接把VCP属性修改就可以来。
但为什么用阿里云的ROS?无非是资源编排有两个难点 :第一点是事务。什么叫事务?一个文档有十几个资源,涉及到回滚、加速 。另外一点是状态。今天一台ECS,明天两台ECS,把模板从1改到2,要2-1=1,然后要再创建1台并对比版本的差异,如此自建编排就复杂了很多,所以大家可以尝试使用阿里云的资源编排。
运维编排是自动化最后一位剑客,专门解决背锅侠、自建DevOps平台、事件消费的问题。
运维是事件驱动的。以前大家可能没注意到,因为在此之前运维是人工驱动的。比如你收到一个电话是个事件,事件驱动人去做运维。而自动化运维不应该这样,云监控产生一个告警事件,这个告警应该自动驱动工作,这是自动化运维。事件驱动为什么很难?因为做监控一定要做到不重不漏。不漏可以理解,通过ACK确认机制保证事件交付到位。一个事件发给你,你必须给我回ACK,我才知道你收到了,不然我就不停给你发,这样保证不漏。
可是我们无法保证不重。消费端去处理,消费端无法不重。事件有ID,例如ID为1表示消费过,为0表示没消费过,并行消费时把它指成1就会产生bug。如果用原子锁,当ID是1时表示第一次消费,当ID是2时表示第二次消费……那这就相当繁琐沉重了。为此推出OOS——阿里云的官方运维编排服务平台,是高效、高可靠的serverless执行引擎,只需要写模板,然后执行,从而保证秒级的处理。
技术不断在进步,阿里云智能运维技术已经成为新运维演化的一个开端,我们期待在更多的高效的优质平台实践之后,智能运维能壮大整个IT领域!
原文链接:https://zhuanlan.zhihu.com/p/82363522
◆
精彩推荐
◆
推荐阅读
我所理解的零次学习
华为全球最快AI训练集群Atlas 900诞生
还怕电脑被偷吗?我用Python偷偷写一个自动木马程序
用Python进行金融市场文本数据的情感计算
前端也能玩转机器学习?Google Brain 工程师来支招!
华为 | 泰山之巅 鲲鹏展翅 扶摇直上九万里
6大思维模型, 揭秘硅谷高管如何做区块链应用决策
走出腾讯和阿里,大厂员工转型记

你点的每个“在看”,我都认真当成了喜欢“
相关文章:

Sublime Text2.0.2注册码
直接输入注册码就可以了 ----- BEGIN LICENSE ----- Andrew Weber Single User License EA7E-855605 813A03DD 5E4AD9E6 6C0EEB94 BC99798F 942194A6 02396E98 E62C9979 4BB979FE 91424C9D A45400BF F6747D88 2FB88078 90F5CC94 1CDC92DC 8457107A F151657B 1D22E383 A997F016 …
Caffe源码中Solver文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/solver.hpp文件的内容:1. include文件: <caffe/solver.hpp>:此文件的介绍可以参考: http://b…
百度大脑金秋九月CV盛典,人脸识别新产品及伙伴计划发布会压轴开启
提起人脸识别你最先想到的是什么?是告别排队,刷脸就能支付的超市;还是告别黄牛,刷脸就能自助挂号建档的医院?其实,“刷脸”的时代早已到来,并且人脸识别技术的发展已经超越你的想象,…
BIML 101 - ETL数据清洗 系列 - BIML 快速入门教程 - 序
BIML 101 - BIML 快速入门教程 做大数据的项目,最花时间的就是数据清洗。 没有一个相对可靠的数据,数据分析就是无木之舟,无水之源。 如果你已经进了ETL这个坑,而且预算有限,并且有大量的活要做; 时间紧&am…
ADO数据库操作
void CSjtestDlg::OnBnClickedButtonAdd() {// TODO: 在此添加控件通知处理程序代码this->ShowWindow(SW_HIDE);DigAdd dig ;dig.DoModal() ;this->ShowWindow(SW_SHOW);m_Grid.DeleteAllItems() ;ADOConn m_Adoconn ;m_Adoconn.OnInitADOConn() ;CString sql ;sql.Forma…

C++中try/catch/throw的使用
C异常是指在程序运行时发生的反常行为,这些行为超出了函数正常功能的范围。当程序的某部分检测到一个它无法处理的问题时,需要用到异常处理。异常提供了一种转移程序控制权的方式。C异常处理涉及到三个关键字:try、catch、throw。 在C语言中…

掌握这些步骤,机器学习模型问题药到病除
作者 | Cecelia Shao编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】这篇文章提供了切实可行的步骤来识别和修复机器学习模型的训练、泛化和优化问题。众所周知,调试机器学习代码非常困难。即使对于简单的前馈神经网络也是这样&am…

How to list/dump dm thin pool metadata device?
2019独角兽企业重金招聘Python工程师标准>>> See: How to create metadata-snap for thin tools using? I dont think LVM provides any support for metadata snapshots so you will need to drive this process through dmsetup. The kernel interface is descri…

Linux基础(二)--基础的命令ls和date的详细用法
本文中主要介绍了linu系统下一些基础命令的用法,重点介绍了ls和date的用法。1.basename:作用:返回一个字符串参数的基本文件名称。用法:basename PATH例如:basename /usr/share/doc 返回结果为doc2.dirname:作用:返回一…
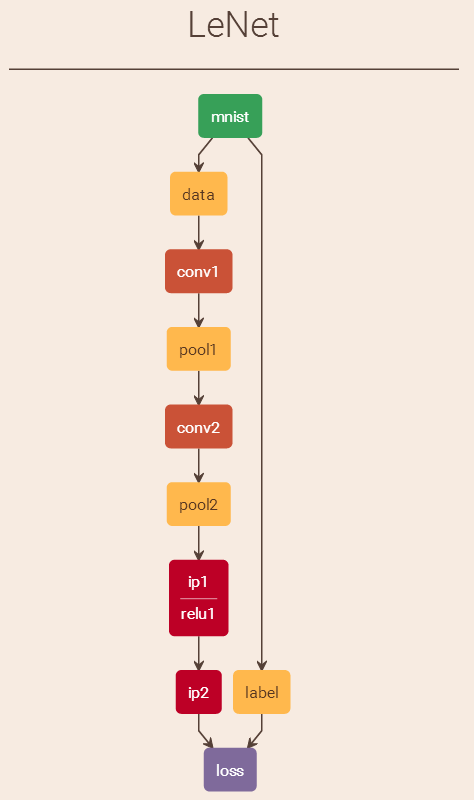
Caffe中对MNIST执行train操作执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/49849225 中简单介绍过使用Caffe train MNIST的文章,当时只是仿照caffe中的example实现了下,下面说一下执行流程,并精简代码到仅有10余行:1. 先注册所有层&…

华为云垃圾分类AI大赛三强出炉,ModelArts2.0让行业按下AI开发“加速键”
9月20日,华为云人工智能大赛垃圾分类挑战杯决赛在上海世博中心2019华为全联接大会会场顺利举办。经过近两个月赛程的层层筛选,入围决赛阵列的11支战队的高光时刻也如期而至。最终华为云垃圾分类挑战杯三强出炉。本次华为云人工智能大赛垃圾分类挑战杯聚焦…

王坚十年前的坚持,才有了今天世界顶级大数据计算平台MaxCompute...
如果说十年前,王坚创立阿里云让云计算在国内得到了普及,那么王坚带领团队自主研发的大数据计算平台MaxCompute则推动大数据技术向前跨越了一大步。数据是企业的核心资产,但十年前阿里巴巴的算力已经无法满足当时急剧增长数据量的需求。基于Ha…

tomcat简单配置
-----------------------------------------一、前言二、环境三、安装JDK四、安装tomcat五、安装mysql六、安装javacenter七、tomcat后台管理-----------------------------------------一、前言Tomcat是Apache 软件基金会(Apache Software Foundation)的…
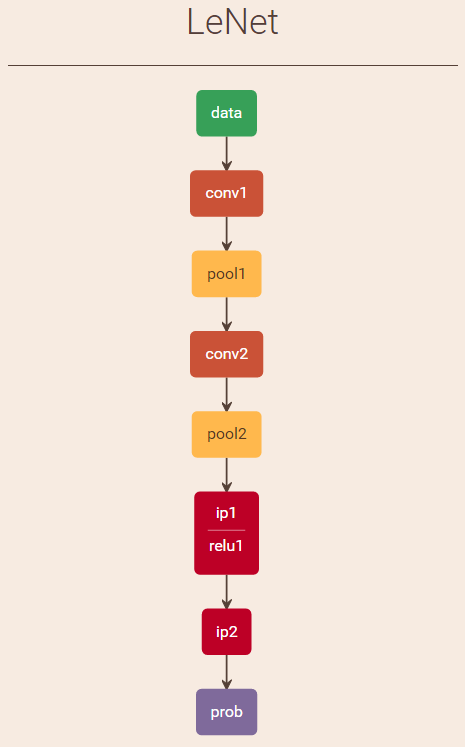
使用Caffe进行手写数字识别执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/50987185 中仿照Caffe中的examples实现对手写数字进行识别,这里详细介绍下其执行流程并精简了实现代码,使用Caffe对MNIST数据集进行train的文章可以参考 http://blog.csdn.net/fengbingchun/…

前端也能玩转机器学习?Google Brain 工程师来支招
演讲嘉宾 | 俞玶编辑 | 伍杏玲来源 | CSDN(ID:CSDNnews)导语:9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程师,TensorFlow.js 项目负责人俞玶发表《TensorFlow.js 遇到小程序》的主题演讲,…
mongoDB设置用户名密码的一个要点
2019独角兽企业重金招聘Python工程师标准>>> 增加用户之前, 先选好库 use <库名> #选择admin库后可查看system.users里面的用户数据 db.system.users.find() db.createUser 这个函数填写用户名密码与权限就行了, 在这里设置库的名称没用. 一定要用用use选择好…

基于HTML5的电信网管3D机房监控应用
先上段视频,不是在玩游戏哦,是规规矩矩的电信网管企业应用,嗯,全键盘的漫游3D机房:随着PC端支持HTML5浏览器的普及,加上主流移动终端Android和iOS都已支持HTML5技术,新一代的电信网管应用几乎一致性的首选H…

从原理到实现,详解基于朴素ML思想的协同过滤推荐算法
作者丨gongyouliu编辑丨Zandy来源 | 大数据与人工智能(ID: ai-big-data)作者在《协同过滤推荐算法》、《矩阵分解推荐算法》这两篇文章中介绍了几种经典的协同过滤推荐算法。我们在本篇文章中会继续介绍三种思路非常简单朴素的协同过滤算法,这…
C++/C++11中引用的使用
引用(reference)是一种复合类型(compound type)。引用为对象起了另外一个名字,引用类型引用(refer to)另外一种类型。通过将声明符写成&d的形式来定义引用类型,其中d是声明的变量名。 一、一般引用:一般在初始化变量时,初始值…
node.js学习5--------------------- 返回html内容给浏览器
/*** http服务器的搭建,相当于php中的Apache或者java中的tomcat服务器*/ // 导包 const httprequire("http"); const fsrequire("fs"); //创建服务器 /*** 参数是一个回调函数,回调函数2个参数,1个是请求参数,一个是返回参数*/ let serverhttp.createServe…
内核分析阅读笔记
内核分析阅读笔记 include/Linux/stddef.h中macro offsetof define,list: #define offsetof(TYPE,MEMBER) ((size_t) &((TYPE *)0)->MEMBER) offsetof macro对于上述示例的展开剂分析:&((struct example_struct *)0)->list表示当结构example_struct正好在地址0上…

杨强教授力荐,快速部署落地深度学习应用的实践手册
香港科技大学计算机科学与工程学系讲座教授、国际人工智能联合会(IJCAI)理事会主席(2017—2019)、深圳前海微众银行首席AI 官 杨强为《深度学习模型及应用详解》一书撰序,他提到现在亟需一本介绍深度学习技术实践的图书…
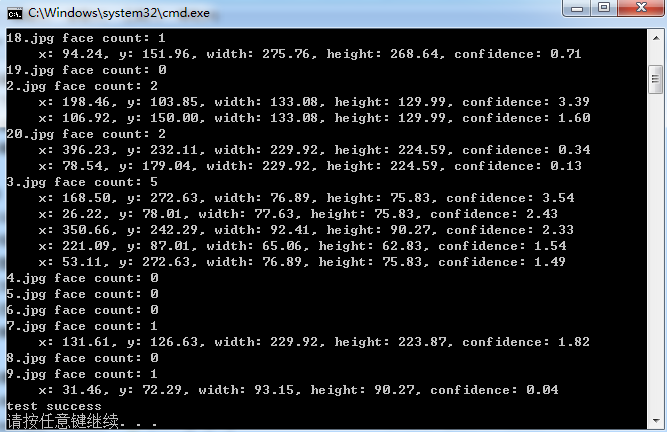
OpenFace库(Tadas Baltrusaitis)中基于HOG进行正脸人脸检测的测试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具,它的源码可以从https://github.com/TadasBaltrusaitis/OpenFace下载。OpenFace主要包括面部关键点检测(facial landmard detection)、头部姿势估计(head pose estimation)、面部动作单元识别(facial acti…
nginx conf 文件配置
打印输出: location / { default_type text/plain; return 502 "$uri"; } $remode_addr 获取访问者的ID$request_method 判断提交方式 GET POST$http_user_agent 获取浏览器软件 if (条件) {} #if之后要有空格 条件3种写法: 1: 来判断相等,用于字符串比较 …
js中 字符串与Unicode 字符值序列的相互转换
一. 字符串转Unicode 字符值序列 var str "abcdef"; var codeArr []; for(var i0;i<str.length;i){codeArr.push(str.charCodeAt(i)); } console.log(codeArr);-->[97, 98, 99, 100, 101, 102] 二.Unicode 字符值序列转字符串 var str String.fromCharCode…
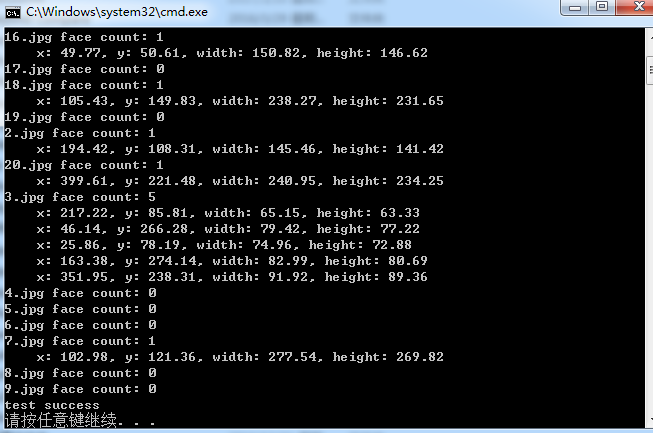
OpenFace库(Tadas Baltrusaitis)中基于Haar Cascade Classifiers进行人脸检测的测试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具,它的源码可以从 https://github.com/TadasBaltrusaitis/OpenFace 下载。OpenFace主要包括面部关键点检测(facial landmard detection)、头部姿势估计(head pose estimation)、面部动作单元识别(facial a…

Uber提出损失变化分配方法LCA,揭秘神经网络“黑盒”
作者 | Janice Lan,Rosanne Liu等译者 | 清儿爸责编 | 夕颜出品 | AI科技大本营(ID: rgznai100)【导读】神经网络(Neural networks,NN)在过去十年来硕果累累,推动了整个行业的机器学习进程。然而࿰…
范登读书解读《亲密关系》(婚姻、爱情) 笔记
来源:邀请你看《樊登解读《亲密关系》(已婚人士必看)》,https://url.cn/5HJvLk5?sfuri 人们在童年的时候始终追寻着两种东西,第一种叫做归属感,第二叫做确认自己的重要性、价值感。 如果再童年的时候缺失这…
myeclipse莫名其妙的问题
2019独角兽企业重金招聘Python工程师标准>>> 怎么刷新,clean项目都不管用,结果删除相应工作空间下的那个项目就行。类似路径如D:\workspace\.metadata\.plugins\org.eclipse.core.resources\.projects 转载于:https://my.oschina.net/u/14488…

数据科学家需要知道的5种图算法
作者:Rahul Agarwal编译:ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】因为图分析是数据科学家的未来。作为数据科学家,我们对pandas、SQL或任何其他关系数据库非常熟悉。我们习惯于将用户的属性以列的形式显示在…