百度CTO王海峰:深度学习如何大规模产业化?

编者按:10月17日-19日,2019年中国计算机大会(CNCC2019)在苏州举办。百度首席技术官王海峰在会上发表题为《深度学习平台支撑产业智能化》的演讲,分享了百度关于深度学习技术推动人工智能发展及产业化应用的思考。

以下为演讲实录:
各位专家,各位来宾大家上午好!非常荣幸有机会参加世界计算机大会,非常感谢中国计算机学会及大会的邀请。今天我跟大家分享的题目是《深度学习平台支撑产业智能化》。
我们都知道,从18世纪60年代开始,人类已经经历了三次工业革命。第一次工业革命为我们带来了机械技术,第二次带来了电气技术,第三次带来了信息技术。我们回顾这三次工业革命的历史会发现,驱动每一次工业革命的核心技术都有非常强的通用性。虽然它可能是从某一个行业开始,比如机械技术最开始从纺织等行业开始,但最后都会应用于生产生活的方方面面,有非常强的通用性。除了通用性以外,这些技术都会推动人类进入一个新的工业大生产阶段,而支撑这个工业大生产的技术有几个特点:标准化、自动化、模块化。而我们现在正处于第四次工业革命的开端,人工智能则是新一轮科技革命和产业变革的一个核心驱动力量。人工智能会推动我们人类社会逐渐进入智能时代。
回顾人工智能技术的发展,人工智能技术的发展阶段有很多分类维度,我理解大概可以归结为:最早期更多都是在用人工的规则,我26年前进入这一行的时候,其实也是在用人工规则来开发机器翻译系统;后来逐渐开始机器学习,尤其是统计机器学习,在很长的一段时间里占主流地位,也产生了很大的影响,带来了很多应用产业的价值;深度学习是机器学习的一个子方向,现在,深度学习逐渐成为新一代人工智能最核心的技术。

举几个例子,文字识别OCR技术早期是用规则+机器学习的方法来做,那时候,一个OCR技术系统可能会分为几部分,从区域检测、行分割、字分割、单字识别、语言模型解码、后处理等一步步做下来。加入深度学习技术后,我们开始使用大数据进行训练,而且阶段目标也很明确,我们找到一些深度学习的特征,这个时候一个OCR系统就简化到只需要检测、识别两个过程,典型的基于深度学习的OCR系统大概是这样。随着深度学习技术进一步发展,我们开始在OCR里面进行多任务的联合训练、端到端学习、特征复用/互补,这个时候,甚至这两个阶段也不用区分了,而是一体化地就把一个文字识别的任务给做了。
我们再看机器翻译。26年以前我进入人工智能领域就是在做机器翻译,当时我们用数以万计的规则写出一个翻译系统,其中包括很多语言专家的工作。20多年以前,我们做的这个系统曾得到全国比赛的第一,但是这个系统想继续发展,进入一个大规模产业化的阶段,仍然面临着很多问题。比如说人工规则费时费力,而且随着规则的增加,冲突也越来越严重,挂一漏万,总是很难把所有的语言现象都覆盖到。后来,统计机器翻译在机器翻译领域占据最主流技术的地位,像百度翻译八年以前上线的第一个版本的系统,其实就是统计机器翻译。统计机器翻译的过程当中,仍然要一步一步来做,比如说先做统计的词对齐,然后做短语的提取,再做结构的对齐等等,其中也涉及到人工特征的提取、定向的优化,仍然很复杂。大概四年多以前,百度上线了世界上第一个大规模的、基于神经网络的翻译产品,这时候我们可以进行端到端的学习了。当然了,这样一个神经网络,或者说是深度学习的系统,也有它的不足之处,现在真正在线上跑的、每天服务数以亿计人的翻译系统,其实是以神经网络的机器翻译方法为主体,同时融合了一些规则、统计的技术。
刚才说起,随着深度学习的发展,这些技术越来越标准化、自动化。大家可以看到深度学习有一个很重要的特点,就是通用性。我们之前做机器学习的时候,有非常多的模型大家都耳熟能详,比如说SVM、CRF等等。深度学习出现以后,人们发现,几乎我们看到的各种问题它都能很不错的解决,甚至能得到目前最佳的解决效果,这和以前的模型各有擅长不一样,它具有很强的通用性。
深度学习所处的位置,一方面它会向下对接芯片,像我们开发的深度学习框架,也会跟各个芯片厂商联合进行优化,前天我们还跟华为芯片一起做了一个联合优化的发布;向上它会承接各种应用,不管是各种模型,还是真正的产品。所以我们认为深度学习框架会是智能时代的一个操作系统。
我们真正把深度学习大规模产业化的时候,也会面临一些要解决的问题,比如说,开发这样一个深度学习的模型或者是系统,实现起来很复杂,开发效率很低,也很不容易;而在训练的时候,我们在真正工业大生产中用的这些模型,比如说百度的产品,都是非常庞大的模型,进行超大的模型训练很困难;到了部署阶段,还要考虑推理速度是不是够快,以及部署成本是不是可控合理。
针对这几个方面,我们开发了百度的深度学习平台“飞桨”,英文我们叫PaddlePaddle。我们认为它已经符合标准化、自动化、模块化的工业大生产特征。

飞桨底层的核心框架包括开发、训练、预测。开发既可以支持动态图,也可以支持静态图;训练可以支持大规模的分布式训练,也可以支持这种工业级的数据处理;同时可以有不同版本部署在服务器上、在端上,以及做非常高效的压缩、安全加密等等。核心框架之上有很多基础模型库,比如说自然语言处理的基础模型库、计算机视觉的基础模型库等等。同时也会提供一些开发的套件,再往上会有各种工具组件,比如说网络的自动训练、迁移学习、强化学习、多任务学习等等。此外,为了真正支撑各行各业的应用,我们提供很多使用者不需要理解底层这些技术、可以直接调用的服务平台。比如EasyDL,就是可以定制化训练和服务的,基本上可以不用了解深度学习背后的原理,零门槛就可以用它来开发自己的应用;AI Studio则是一个实训平台,很多大学也在用这样的平台上课、学习;当然,还包括端计算模型生成平台。
飞桨是一个非常庞大的平台,我们着重在四方面发力、且具有领先性的技术。
首先从开发的角度,我们提供一个开发便捷的深度学习框架;而从训练的角度,可以支持超大规模的训练;从部署的角度,可以进行多端、多平台的高性能推理引擎的部署;同时提供很多产业级的模型库。

从开发的角度,飞桨提供一个开发便捷的深度学习框架。一方面,大家知道这些软件系统都是很多程序员在写,程序员有自己写程序的习惯,我们这种组网式的编程范式与程序员的开发习惯非常一致,程序员开发起来会很有效率,而且也很容易上手;另外一个方面是设计网络结构,深度学习发展很多年,多数深度学习的系统网络都是人类专家来设计的,但是,设计网络结构是很专、很不容易的一件事情。所以,我们开发网络结构的自动设计。现在机器自动设计的网络,在很多情况下已经比人类专家设计的网络得到的效果还好。
另一个方面,大规模训练面临的挑战。飞桨支持超大规模的特征、训练数据、模型参数、流式学习等等。我们开发的这套系统现在已经可以支持万亿级参数模型,不止是能支持这样的训练,同时可以支持实时的更新。
说到多端多平台,飞桨能很好的支撑从服务器到端、不同的操作系统之间,甚至不同框架之间的无缝衔接。这里是一些具体的数据,大家可以看到,我们通用架构的推理,它的速度是非常快的。同时,刚才我提到的跟华为的合作,我们针对华为的NPU做了定向的优化,使它的推理速度得到进一步的提升。
另外一方面,所有这些基础框架,与真正的开发应用之间还有一步,我们定向地为不同的典型应用提供很多官方的模型库,比如说语言理解的、增强学习的、视觉的等等。飞桨的这些模型都在大规模的应用中得到过验证,同时我们也在一些国际的比赛中测试了这些模型,夺得了很多个第一。
刚才讲的是基本的框架模型等等,另一方面,我们还有完备的工具组件,以及面向任务的开发套件,以及产业级的服务平台。
举几个例子,比如说语言理解,大家知道现在语言理解,我们也都基于深度学习框架来做,像百度的ERNIE。一方面,我们现在用的深度学习技术是从海量的数据里进行学习,但是它没有知识作为前提。百度开发了一个非常庞大的,有3000多亿个事实的知识图谱,我们用知识来增强基于深度学习的语言理解框架,就产生了ERNIE。另一方面,我们又加入了持续学习的技术,从而让ERNIE有一个非常好的表现。下面浅蓝色的线是现在SOTA最好的结果,我们用ERNIE+百科知识——我们知识图谱也有很多来源——加进去以后,大家可以看到有很明显的提升。我们更高兴地看到,持续加入不同的知识,比如加入对话知识、篇章结构知识等等,这个系统还可以进一步提升它的性能。
这是前面讲的一系列套件之一,可以零门槛进入的定制化训练和服务平台。我们这些平台,希望能降低门槛,帮助各行各业来加速整个技术创新。现在大概是什么状态呢?现在我们已经服务了150多万的开发者,其中包括超过6.5万个企业。在这个平台上,他们自己训练了已经有16.9万个模型。
飞桨深度学习开源开放平台跟百度的智能云也有很好的结合,依托云服务更多的客户,让AI可以赋能各行各业。这里有一些例子,比如说在农业,我们帮助水培蔬菜的智能种植;在林业,帮助病虫害的监测识别;以及公共场所的控烟、商品销售的预测、人力资源系统的自动匹配、制造业零件的分拣,以及地震波、藏油预测,以及更广泛地覆盖通讯行业、地产、汽车等等领域,各行各业都基于这个平台都得到了智能化的升级。

比如水培蔬菜智能种植,我们通过深度学习平台支持它进行长势分析、水培方案的精调、环境的控制,使产量得以提高,同时成本得以降低。智能虫情监测也是一样,系统的识别准确率已经相当于人类专家的水平,而且监控的周期也从一周缩短到一小时。

精密零件智能分拣的案例中,我们真正用这个深度学习系统的时候,还是有不少事情要做,比如说如何选择分拣的模型,中间也会涉及一些数据的标注,尤其是一些错误case的积累等等,然后在飞桨平台上进行训练升级。
这是一个工业安全生产监控的例子,昨天在另一个会上,有一个来宾问我,他们特别想在一些场景下,监控一些不当的环节,比如说生产环境里打手机、抽烟、跃过护栏等等。这些都可以通过飞桨的平台自动实现。

在其他的行业中,比如国家重大工程用地的检测,智慧司法,以及AI眼底筛查都在应用飞桨,还有很多有温度的案例,比如AI寻人,一个孩子4岁的时候离家走失,27年以后,通过人脸比对技术,又帮助这个家庭把孩子找回来了,实现了家庭的团聚。截止到今年6月,百度AI寻人已经帮助6700个家庭团圆。除此之外,还有AI助盲行动、AI助老兵圆梦等等这些案例。

回到深度学习,刚才我说,各行各业都会从其中受益,实现自己的智能化升级。这是一个第三方的报告,我们可以看到,深度学习给不同的行业都会带来提升,平均大概是62%的水平。
这就是我今天要分享的。百度的飞桨深度学习平台非常愿意跟大家一起,帮助大家实现自己行业的智能化升级,推动人工智能的发展,谢谢大家!
◆
精彩推荐
◆

推荐阅读
确认!语音识别大牛Daniel Povey将入职小米,曾遭霍普金斯大学解雇,怒拒Facebook
大规模1.4亿中文知识图谱数据,我把它开源了
自动驾驶关键环节:行人的行为意图建模和预测(上)
不足 20 行 Python 代码,高效实现 k-means 均值聚类算法
巨头垂涎却不能染指,loT 数据库风口已至
【建议收藏】数据中心服务器基础知识大全
从4个维度深度剖析闪电网络现状,在CKB上实现闪电网络的理由 | 博文精选
身边程序员同事竟说自己敲代码速度快!Ctrl+C、Ctrl+V ?
100 美元一行代码,开源软件到底咋赚钱?

你点的每个“在看”,我都认真当成了AI
相关文章:

Kali Linux***测试
Kali Linux***测试实战 第一章http://drops.wooyun.org/tips/826 1.1 Kali Linux简介如果您之前使用过或者了解BackTrack系列Linux的话,那么我只需要简单的说,Kali是BackTrack的升级换代产品,从Kali开始,BackTrack将成为历史。如果…
一站式解决:隐马尔可夫模型(HMM)全过程推导及实现
作者 | 永远在你身后转载自知乎用户永远在你身后【导读】隐马尔可夫模型(Hidden Markov Model,HMM)是关于时许的概率模型,是一个生成模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态序列,每个状态生…

CUDA Samples: Image Process: BGR to BGR565
图像像素格式BGR565是每一个像素占2个字节,其中Blue占5位,Green占6位,Red占5位。在OpenCV中,BGR到BGR565的每一个像素的计算公式是:unsigned short dst (unsigned short)((B >> 3) | ((G & ~3) << 3)…
NoSQL数据库探讨 - 为什么要用非关系数据库?
源地址:http://robbin.javaeye.com/blog/524977 随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。而传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类…
手机内存RAM、ROM简介
手机内存包含两个:一个是运行内存(RAM),一个是机身内存(ROM)。两者的功能有所不同,运行内存是对手机操作系统和其它程序运行过程中,产生的临时数据进行存储的媒介。如果手机运行的程序比较多,占用运行内存空间较大&…

一个月入门Python爬虫,轻松爬取大规模数据
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样一个月入门Python爬虫,轻松爬的编程语言提供越来越多的优秀工具&#x…

软件包管理 之 软件在线升级更新yum 图形工具介绍
作者:北南南北来自:LinuxSir.Org提要:yum 是Fedora/Redhat 软件包管理工具,包括文本命令行模式和图形模式;图形模式的yum也是基于文本模式的;目前yum图形前端程序主要有 yumex和kyum ; 正文一、…

[PHPUnit]自动生成PHPUnit测试骨架脚本-提供您的开发效率【2015升级版】
2019独角兽企业重金招聘Python工程师标准>>> 场景 在编写PHPUnit单元测试代码时,其实很多都是对各个类的各个外部调用的函数进行测试验证,检测代码覆盖率,验证预期效果。为避免增加开发量,可以使用PHPUnit提供的phpuni…

ORL Faces Database介绍
ORL人脸数据集共包含40个不同人的400张图像,是在1992年4月至1994年4月期间由英国剑桥的Olivetti研究实验室创建。此数据集下包含40个目录,每个目录下有10张图像,每个目录表示一个不同的人。所有的图像是以PGM格式存储,灰度图&…
张俊林:BERT和Transformer到底学到了什么 | AI ProCon 2019
演讲嘉宾 | 张俊林(新浪微博机器学习团队AI Lab负责人)编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】BERT提出的这一年,也是NLP领域迅速发展的一年。学界不断提出新的预训练模型,刷新各…
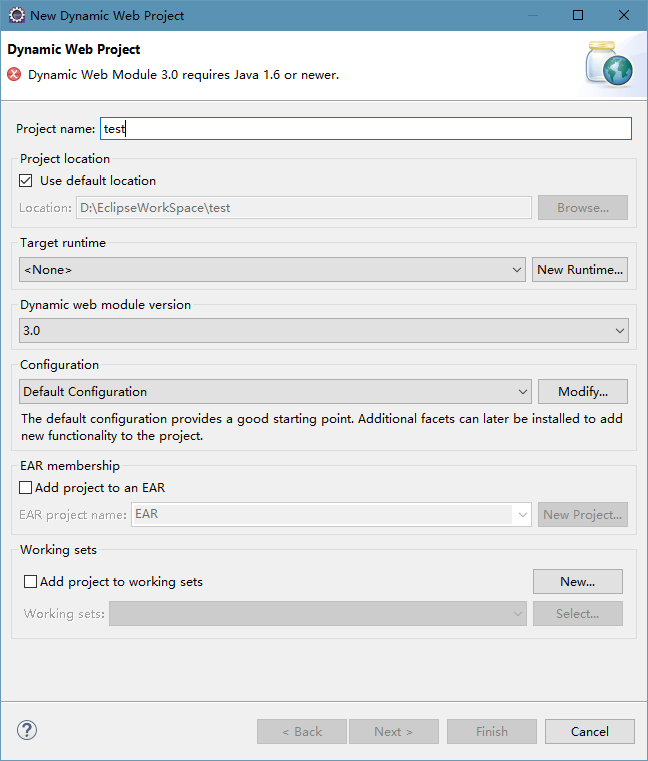
Eclipse创建web工程时,报错Dynamic Web Module 3.0 requires Java 1.6 or newer.
报错: 解决方案: 1.打开eclipse工具栏window->preferences 2.打开java->compiler 3.选择compiler compliance level在1.6以上版本(此处选择1.8) 4.点击apply and close保存修改,即可 转载于:https://www.cnblogs…
Maven学习总结(八)——使用Maven构建多模块项目
2019独角兽企业重金招聘Python工程师标准>>> Maven学习总结(八)——使用Maven构建多模块项目 在平时的Javaweb项目开发中为了便于后期的维护,我们一般会进行分层开发,最常见的就是分为domain(域模型层)、dao࿰…

哈工大、清华、CSDN、嵌入式视觉联盟合办的 AIoT 盛会,你怎么舍得错过?!
2019 嵌入式智能国际大会即将来袭!随着物联网和人工智能技术的飞速发展与相互渗透,万物智联的新赛道已经开始显现。据中商产业研究院《2016—2021年中国物联网产业市场研究报告》显示,预计到2020年,中国物联网的整体规模将达2.2万…

OpenCV3.3中主成分分析(Principal Components Analysis, PCA)接口简介及使用
OpenCV3.3中给出了主成分分析(Principal Components Analysis, PCA)的实现,即cv::PCA类,类的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/pca.cpp文件中,其中:(1)、cv::PCA::PCA:构造函数࿱…
Spring MVC配置
为什么80%的码农都做不了架构师?>>> 一、传统方式配置Spring MVC (1)导入jar包 需要导入如下的jar包 junit-3.8.1.jar spring-core-3.0.5.RELEASE.jar commons-logging-1.1.1.jar spring-context-3.0.5.REL…
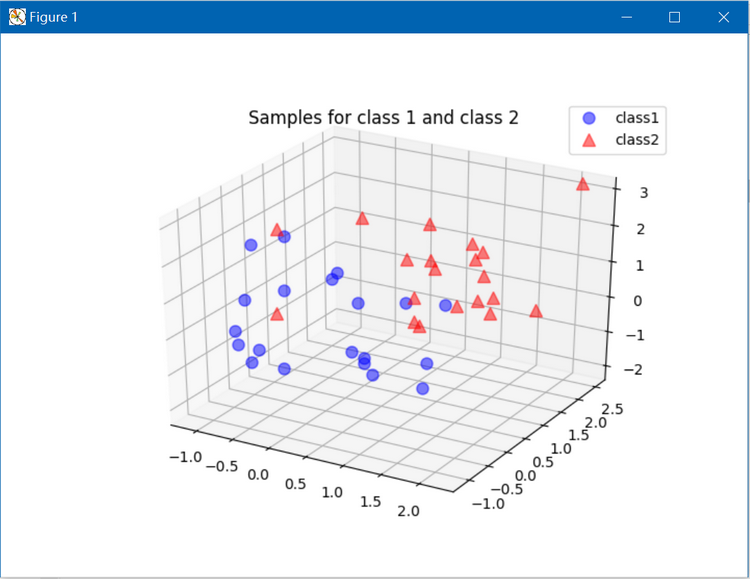
主成分分析(PCA)Python代码实现
主成分分析(Principal Components Analysis, PCA)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78977202 这里是参照 http://sebastianraschka.com/Articles/2014_pca_step_by_step.html 文章中的code整理的Python代码,实现过程为…
AI发展这一年:不断衍生的技术丑闻与抵制声潮
作者 | AI Now学院译者 | Raku编辑 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】10月2日,纽约大学AI Now学院在纽约大学斯克博剧院(Skirball Theatre)组织召开了第四届年度AI Now研讨会。研讨会邀请了业内组织者…
Distributed Configuration Management Platform(分布式配置管理平台)
2019独角兽企业重金招聘Python工程师标准>>> 专注于各种 分布式系统配置管理 的通用组件/通用平台, 提供统一的配置管理服务。 主要目标: 部署极其简单:同一个上线包,无须改动配置,即可在 多个环境中(RD/QA/PRODUCTION…
如何利用zendstudio新建 或导入php项目
为什么80%的码农都做不了架构师?>>> 一、利用ZendStudio创建 PHP Project 1. 打开ZendStudio, 选择:File à New à PHP Project, 如下图所示: 于是弹出如下界面: 在”Project name”后输入工程名(比如我这里…
一文读懂GoogLeNet神经网络 | CSDN博文精选
作者 | .NY&XX来源 | CSDN博客本文介绍的是著名的网络结构GoogLeNet,目的是试图领会其中结构设计思想。GoogLeNet特点优化网络质量的生物学原理GoogLeNet网络结构的动机GoogLeNet架构细节Inception模块和普通卷积结构的差异辅助分类器GoogLeNet网络架构GoogLeNe…
C++中的函数签名
C中的函数签名(function signature):包含了一个函数的信息,包括函数名、参数类型、参数个数、顺序以及它所在的类和命名空间。普通函数签名并不包含函数返回值部分,如果两个函数仅仅只有函数返回值不同,那么系统是无法区分这两个函…
MyEclipse断点调试
2019独角兽企业重金招聘Python工程师标准>>> 1、在编辑的程序的左边,你会看到一条浅浅的灰色编带,在这里设置断点。 2、设置断点的方法有很多 方法:1)、双击 ; 2)、右键,选择“Toggl…
C primer plus 练习题 第三章
5. 1 #include <stdio.h>2 3 int main()4 {5 float you_sec;6 printf("请输入你的年龄:");7 scanf("%f", &you_sec);8 printf("年龄合计:%e 秒!\n", you_sec * 3.156e7);9 getchar(); 10 return 0; 11 }
Echache整合Spring缓存实例讲解
2019独角兽企业重金招聘Python工程师标准>>> 摘要:本文主要介绍了EhCache,并通过整合Spring给出了一个使用实例。 一、EhCache 介绍 EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的C…
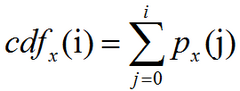
灰度图像直方图均衡化公式及实现
图像的直方图:直方图是图像中像素强度分布的图形表达方式。它统计了每一个强度值所具有的像素个数。直方图均衡化:是通过拉伸像素强度分布范围来增强图像对比度的一种方法。是图像处理领域中利用图像直方图对对比度进行调整的方法。均衡化指的是把一个分…
超越最新无监督域自适应方法,研究人员提轻量CNN新架构OSNet
作者 | Kaiyang Zhou, Xiatian Zhu, Yongxin Yang, Andrea Cavallaro, and Tao Xiang 译者 | TroyChang 编辑 | Jane 出品 | AI科技大本营(ID:rgznai100) CNN新架构OSNet 【导读】今天推荐论文《Learning Generalisable Omni-Scale Repre…
在一台机器上搭建多个redis实例
2019独角兽企业重金招聘Python工程师标准>>> 默认Redis程序安装在/usr/local/redis目录下; 配置文件:/usr/local/redis/redis.conf,该配置文件中配置的端口为默认端口:6379; Redis的启动命令路径࿱…
使用kaptcha生成验证码
2019独角兽企业重金招聘Python工程师标准>>> kaptcha是一个简单好用的验证码生成工具,通过配置,可以自己定义验证码大小、颜色、显示的字符等等。下面就来讲一下如何使用kaptcha生成验证码以及在服务器端取出验证码进行校验。 一、搭建测试环…

主成分分析(PCA) C++ 实现
主成分分析(Principal Components Analysis, PCA)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78977202以下是PCA的C实现,参考OpenCV 3.3中的cv::PCA类。使用ORL Faces Database作为测试图像。关于ORL Faces Database的介绍可以参…
为何Google、微软、华为将亿级源代码放一个仓库?从全球最大代码管理库说起...
作者 | 夕颜编辑 | Just出品 | AI 科技大本营(ID:rgznai100)【导读】2017 年,在当时微软的一篇官方博客中,时任微软云开发服务副总裁的 Brian Harry 表示微软内部代码开始向 Git 迁移,宣布推出针对大规模 repo 的“Git…