2019独角兽企业重金招聘Python工程师标准>>> 
摘要:本文主要介绍了EhCache,并通过整合Spring给出了一个使用实例。
一、EhCache 介绍
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储,缓存加载器,缓存扩展,缓存异常处理程序,一个gzip缓存servlet过滤器,支持REST和SOAP api等特点。
它的一个缺点就是使用磁盘Cache的时候非常占用磁盘空间,这源于DiskCache的算法简单,该算法简单也导致Cache的效率非常高。它只是对元素直接追加存储。因此搜索元素的时候非常的快。如果使用DiskCache的,在很频繁的应用中,很快磁盘会满。
另外一个问题是当突然kill掉java的时候,不能保证数据的安全,可能是产生冲突,Ehcache的解决方法是如果文件冲突了,则重建cache。这对于Cache数据需要保存的时候可能不利。当然,Cache只是简单的加速,而不能保证数据的安全。如果想保证数据的存储安全,可以使用Bekeley DB Java Edition版本。这是个嵌入式数据库。可以确保存储安全和空间的利用率。当然,还有很多的Cache。多数情况下,Ehcache能满足常见需求。
二、使用实例
本文要使用
1、引入jar包
- <dependency>
- <groupId>net.sf.ehcache</groupId>
- <artifactId>ehcache</artifactId>
- <version>2.8.2</version>
- </dependency>
2、在classpath下增加ehcache配置文件 ehcache.xml与配置文件

设置控制ehcache的bean,这部分的内容也可以直接写在spring的配置文件applicationContext.xml中去,这里为了方便管理,我给单独写出来了
beans-cache.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:cache="http://www.springframework.org/schema/cache"
- xmlns:p="http://www.springframework.org/schema/p"
- xsi:schemaLocation="
- http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
- http://www.springframework.org/schema/cache http://www.springframework.org/schema/cache/spring-cache-3.1.xsd">
- <cache:annotation-driven cache-manager="cacheManager" />
- <bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheCacheManager">
- <property name="cacheManager" ref="ehcache"></property>
- </bean>
- <bean id="ehcache"
- class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
- <property name="configLocation" value="classpath:beans/ehcache.xml"></property>
- </bean>
- </beans>
ehcache.xml设置缓存大小和时间,缓存空间名等。其中缓存空间可设置多个
- <?xml version="1.0" encoding="UTF-8"?>
- <ehcache updateCheck="false">
- <diskStore path="java.io.tmpdir" />
- <!-- DefaultCache setting. -->
- <defaultCache eternal="false"
- overflowToDisk="false"
- diskPersistent="false"
- timeToLiveSeconds="36000"
- timeToIdleSeconds="36000"
- maxElementsInMemory="10000"
- memoryStoreEvictionPolicy="LRU"/>
- <!-- Special objects setting. -->
- <!-- Refresh sysParamCache every hour. -->
- <cache name="sysParamCache"
- overflowToDisk="false"
- eternal="false"
- diskPersistent="false"
- timeToLiveSeconds="36000"
- timeToIdleSeconds="36000"
- maxElementsInMemory="10000"
- memoryStoreEvictionPolicy="LRU"/>
- </ehcache>
参数说明:
<diskStore>:
当内存缓存中对象数量超过maxElementsInMemory时,将缓存对象写到磁盘缓存中(需对象实现序列化接口)。
<diskStore path="">:
用来配置磁盘缓存使用的物理路径,Ehcache磁盘缓存使用的文件后缀名是*.data和*.index。
name:
缓存名称,cache的唯一标识(ehcache会把这个cache放到HashMap里)。
maxElementsOnDisk:
磁盘缓存中最多可以存放的元素数量,0表示无穷大。
maxElementsInMemory:
内存缓存中最多可以存放的元素数量,若放入Cache中的元素超过这个数值,则有以下两种情况。
1)若overflowToDisk=true,则会将Cache中多出的元素放入磁盘文件中。
2)若overflowToDisk=false,则根据memoryStoreEvictionPolicy策略替换Cache中原有的元素。
Eternal:
缓存中对象是否永久有效,即是否永驻内存,true时将忽略timeToIdleSeconds和timeToLiveSeconds。
timeToIdleSeconds:
缓存数据在失效前的允许闲置时间(单位:秒),仅当eternal=false时使用,默认值是0表示可闲置时间无穷大,此为可选属性即访问这个cache中元素的最大间隔时间,若超过这个时间没有访问此Cache中的某个元素,那么此元素将被从Cache中清除。
timeToLiveSeconds:
缓存数据在失效前的允许存活时间(单位:秒),仅当eternal=false时使用,默认值是0表示可存活时间无穷大,即Cache中的某元素从创建到清楚的生存时间,也就是说从创建开始计时,当超过这个时间时,此元素将从Cache中清除。
overflowToDisk:
内存不足时,是否启用磁盘缓存(即内存中对象数量达到maxElementsInMemory时,Ehcache会将对象写到磁盘中),会根据标签中path值查找对应的属性值,写入磁盘的文件会放在path文件夹下,文件的名称是cache的名称,后缀名是data。
diskPersistent:
是否持久化磁盘缓存,当这个属性的值为true时,系统在初始化时会在磁盘中查找文件名为cache名称,后缀名为index的文件,这个文件中存放了已经持久化在磁盘中的cache的index,找到后会把cache加载到内存,要想把cache真正持久化到磁盘,写程序时注意执行net.sf.ehcache.Cache.put(Element element)后要调用flush()方法。
diskExpiryThreadIntervalSeconds:
磁盘缓存的清理线程运行间隔,默认是120秒。
diskSpoolBufferSizeMB:
设置DiskStore(磁盘缓存)的缓存区大小,默认是30MB
memoryStoreEvictionPolicy:
内存存储与释放策略,即达到maxElementsInMemory限制时,Ehcache会根据指定策略清理内存,共有三种策略,分别为LRU(最近最少使用)、LFU(最常用的)、FIFO(先进先出)。
3.spring配置文件 applicationContext.xml 添加ehcache的配置
- <import resource="classpath:beans/beans-cache.xml" />
4.在service层增加注解配置
- @Override
- @Cacheable(value="sysParamCache",key="#systemId+#merchantId+#businessType")// 使用了一个缓存名叫 accountCache
- public SettUnit getSettUnitBySettUnitId(String systemId, String merchantId, String businessType) {
key=#systemId+#merchantId+#businessType" 对象缓存的key值,需要保证唯一, 用的是Spring的 SpEL表达式, 取值为 isbn对象的id属性值
value="sysParamCache":指的是ehcache.xml里的缓存名字
5、单元测试
- @Test
- public void getSettUnitBySettUnitIdTest() {
- String systemId = "CES";
- String merchantId = "133";
- SettUnit configSettUnit = settUnitService.getSettUnitBySettUnitId(systemId, merchantId, "ESP");
- SettUnit configSettUnit1 = settUnitService.getSettUnitBySettUnitId(systemId, merchantId, "ESP");
- boolean flag= (configSettUnit == configSettUnit1);
- System.out.println(configSettUnit);
- logger.info("查找结果" + configSettUnit.getBusinessType());
- // localSecondFIFOCache.put("configSettUnit", configSettUnit.getBusinessType());
- // String string = localSecondFIFOCache.get("configSettUnit");
- logger.info("查找结果" + string);
- }
这是有缓存的结果,第二次直接从缓存中去取,比较两个的地址,相等即表明两上是同一个对象,第二次取的是第一次的结果
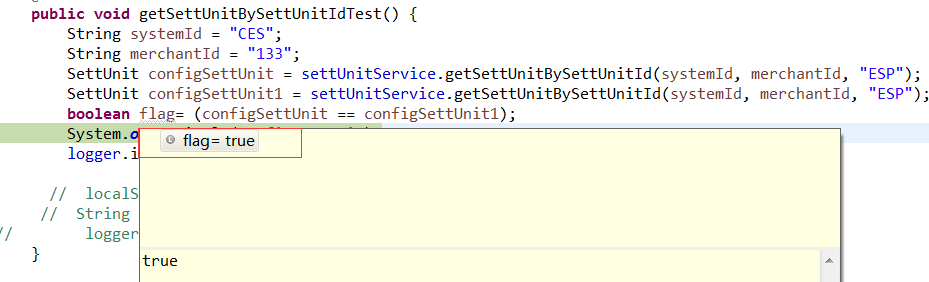
这是第一次取结果打印的SQL语句