如何正确选择聚类算法? | CSDN博文精选

作者 | Josh Thompson
翻译 | 张睿毅
校对 | 王雨桐
来源 | 数据派THU(ID:DatapiTHU)
本文将介绍四种基本的聚类算法—层次聚类、基于质心的聚类、最大期望算法和基于密度的聚类算法,并讨论不同算法的优缺点。
聚类算法十分容易上手,但是选择恰当的聚类算法并不是一件容易的事。
数据聚类是搭建一个正确数据模型的重要步骤。数据分析应当根据数据的共同点整理信息。然而主要问题是,什么通用性参数可以给出最佳结果,以及什么才能称为“最佳”。
本文适用于菜鸟数据科学家或想提升聚类算法能力的专家。下文包括最广泛使用的聚类算法及其概况。根据每种方法的特殊性,本文针对其应用提出了建议。
四种基本算法以及如何选择
聚类模型可以分为四种常见的算法类别。尽管零零散散的聚类算法不少于100种,但是其中大部分的流行程度以及应用领域相对有限。
基于整个数据集对象间距离计算的聚类方法,称为基于连通性的聚类(connectivity-based)或层次聚类。根据算法的“方向”,它可以组合或反过来分解信息——聚集和分解的名称正是源于这种方向的区别。最流行和合理的类型是聚集型,你可以从输入所有数据开始,然后将这些数据点组合成越来越大的簇,直到达到极限。
层次聚类的一个典型案例是植物的分类。数据集的“树”从具体物种开始,以一些植物王国结束,每个植物王国都由更小的簇组成(门、类、阶等)。
层次聚类算法将返回树状图数据,该树状图展示了信息的结构,而不是集群上的具体分类。这样的特点既有好处,也有一些问题:算法会变得很复杂,且不适用于几乎没有层次的数据集。这种算法的性能也较差:由于存在大量的迭代,因此整个处理过程浪费了很多不必要的时间。最重要的是,这种分层算法并不能得到精确的结构。
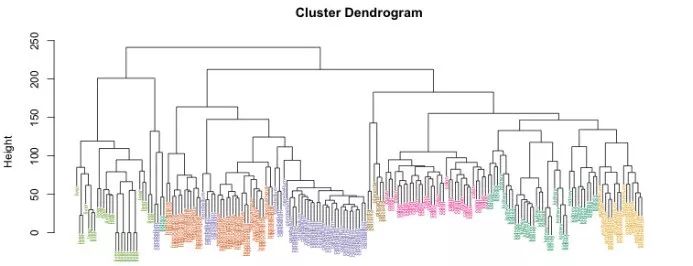
同时,从预设的类别一直分解到所有的数据点,类别的个数不会对最终结果产生实质性影响,也不会影响预设的距离度量,该距离度量粗略测量和近似估计得到的。
根据我的经验,由于简单易操作,基于质心的聚类(Centroid-based)是最常出现的模型。 该模型旨在将数据集的每个对象划分为特定的类别。 簇数(k)是随机选择的,这可能是该方法的最大问题。 由于与k最近邻居(kNN)相似,该k均值算法在机器学习中特别受欢迎。(附链接:https://www.kaggle.com/chavesfm/tuning-parameters-for-k-nearest-neighbors-iris)
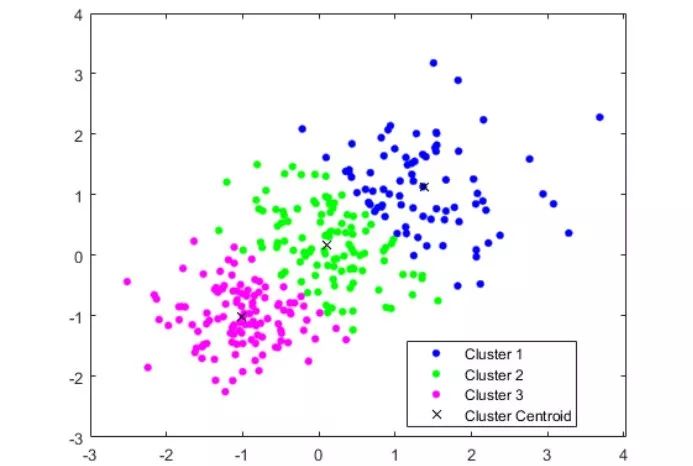
计算过程包括多个步骤。首先,输入数据集的目标类别数。聚类的中心应当尽可能分散,这有助于提高结果的准确性。
其次,该算法找到数据集的每个对象与每个聚类中心之间的距离。最小坐标距离(若使用图形表示)确定了将对象移动到哪个群集。
之后,将根据类别中所有点的坐标平均值重新计算聚类的中心。重复算法的上一步,但是计算中要使用簇的新中心点。除非达到某些条件,否则此类迭代将继续。例如,当簇的中心距上次迭代没有移动或移动不明显时,聚类将结束。
尽管数学和代码都很简单,但k均值仍有一些缺点,因此我们无法在所有情景中使用它。缺点包括:
因为优先级设置在集群的中心,而不是边界,所以每个集群的边界容易被疏忽。
无法创建数据集结构,其对象可以按等量的方式分类到多个群集中。
需要猜测最佳类别数(k),或者需要进行初步计算以指定此量规。
相比之下,期望最大化算法可以避免那些复杂情况,同时提供更高的准确性。简而言之,它计算每个数据集点与我们指定的所有聚类的关联概率。用于该聚类模型的主要工具是高斯混合模型(GMM)–假设数据集的点服从高斯分布。(链接:https://www.encyclopedia.com/science-and-technology/mathematics/mathematics/normal-distribution#3)
k-means算法可以算是EM原理的简化版本。它们都需要手动输入簇数,这是此类方法要面对的主要问题。除此之外,计算原理(对于GMM或k均值)很简单:簇的近似范围是在每次新迭代中逐渐更新的。
与基于质心的模型不同,EM算法允许对两个或多个聚类的点进行分类-它仅展示每个事件的可能性,你可以使用该事件进行进一步的分析。更重要的是,每个聚类的边界组成了不同度量的椭球体。这与k均值聚类不同,k均值聚类方法用圆形表示。但是,该算法对于不服从高斯分布的数据集根本不起作用。这也是该方法的主要缺点:它更适用于理论问题,而不是实际的测量或观察。
最后,基于数据密度的聚类成为数据科学家心中的最爱。(链接:http://www.mastersindatascience.org/careers/data-scientist/)这个名字已经包括了模型的要点——将数据集划分为聚类,计数器会输入ε参数,即“邻居”距离。因此,如果目标点位于半径为ε的圆(球)内,则它属于该集群。
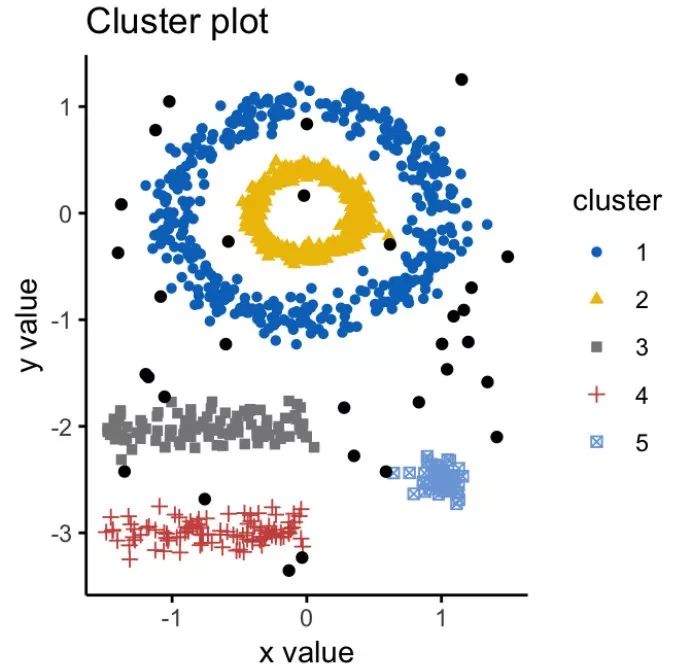
具有噪声的基于密度的聚类方法(DBSCAN)将逐步检查每个对象,将其状态更改为“已查看”,将其划分到具体的类别或噪声中,直到最终处理整个数据集。用DBSCAN确定的簇可以具有任意形状,因此非常精确。此外,该算法无需人为地设定簇数 —— 算法可以自动决定。
尽管如此,DBSCAN也有一些缺点。如果数据集由可变密度簇组成,则该方法的结果较差;如果对象的位置太近,并且无法轻易估算出ε参数,那么这也不是一个很好的选择。
总而言之,我们并不能说选择了错误的算法,只能说其中有些算法会更适合特定的数据集结构。为了采用最佳的(看起来更恰当的)算法,你需要全面了解它们的优缺点。
例如,如果某些算法不符合数据集规范,则可以从一开始就将其排除在外。为避免繁琐的工作,你可以花一些时间来记住这些信息,而无需反复试验并从自己的错误中学习。
我们希望本文能帮助你在初始阶段选择最好的算法。继续这了不起的工作吧!
原文标题:
Choosing the Right Clustering Algorithm for your Dataset
原文链接:
https://www.kdnuggets.com/2019/10/right-clustering-algorithm.html
扫码查看作者更多文章
▼▼▼

(*本文为 AI科技大本营转载文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
即日起,限量 5 折票开售,数量有限,扫码购买,先到先得!

推荐阅读

你点的每个“在看”,我都认真当成了A
相关文章:

Python工具 | 9个用来爬取网络站点的 Python 库
1️⃣Scrapy 一个开源和协作框架,用于从网站中提取所需的数据。 以快速,简单,可扩展的方式。 官网2️⃣cola 一个分布式爬虫框架。 GitHub3️⃣Demiurge 基于 PyQuery 的爬虫微型框架。 官网4️⃣feedparser 通用 feed 解析器。 官网5️⃣Gra…
Python并发编程实例教程
有关Python中的并发编程实例,主要是对Threading模块的应用,文中自定义了一个Threading类库。 一、简介 我们将一个正在运行的程序称为进程。每个进程都有它自己的系统状态,包含内存状态、打开文件列表、追踪指令执行情况的程序指针以及一个保存局部变量的调用栈。…
Nginx负载均衡之TCP端口高可用(二)
在前面我们实现了基本的HTTP反向代理,从互联网过来的请求已经可以分发到后端多台网站服务器上,但不是所有的业务都是网络类型的,此篇文章我们主要讨论的是TCP 端口的负载均衡做法,昨天也有小伙伴提到了,在HTTP反向代理…
语音识别大牛Daniel Povey为何加入小米?“手机+AIoT”强大生态,开源战略是关键...
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)10 月 17 日,语音识别开源工具 Kaldi 创始人,语音和 AI 领域大牛 Daniel Povey 在10 月 19 日,小米集团副总裁、集团技术委员会主席崔宝秋发布微博,欢迎 Dani…
Python运维项目中用到的redis经验及数据类型
先感叹下,学东西一定要活学活用! 我用redis也有几年的历史了,今个才想到把集合可以当python list用。 最近做了几个项目都掺杂了redis, 遇到了一些个问题和开发中提高性能的方法,这都分享出来,共同学习。…
图像边缘检测之拉普拉斯(Laplacian)C++实现
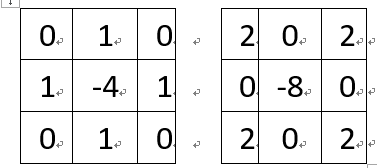
拉普拉斯算子(Laplacian)可应用到图像边缘检测中。在OpenCV中当kernel大小为3*3时,支持两种kernel算子,分别为:在OpenCV中默认的计算方式如下,假设有一个5*5的小图像,原始值依次为1,2,…25,如下图红色部分,…
从0到1,Airbnb的深度学习实践经验总结
作者 | Haldar译者 | 陆离出品 | AI科技大本营(ID: rgznai100)此前,AI科技大本营发布了关于希望通过介绍的研究成果为读者提供一些有用的帮助和指引。模型中的生态系统本文要讨论的机器学习现实应用,是关于根据用户预约的可能性来…
高并发大流量专题---8、动态语言的并发处理
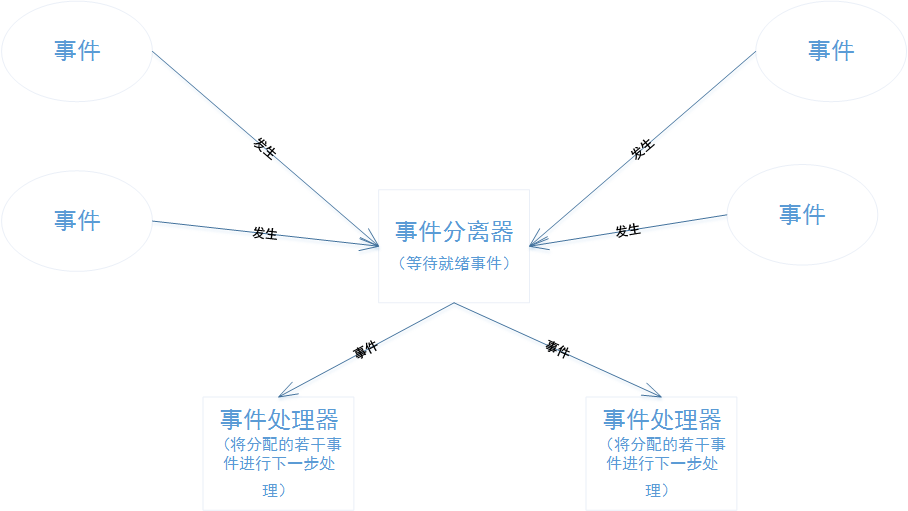
高并发大流量专题---8、动态语言的并发处理 一、总结 一句话总结: 和本科毕业论文连起来了:基于消息中间件Rocket MQ的研究;用于并发处理的消息队列 1、什么是进程、线程、协程? 进程(Process)是计算机中的…

1. 文件系统——磁盘分区、各目录功能、硬盘
一、磁盘分区及文件访问入口在前文中介绍过,Linux的整个文件系统像一棵倒置的数,最顶层的是根文件系统,其下有很多一级子目录,一级子目录下面是二级子目录,依此类推:/:根目录/bin,/s…

吴恩达老师深度学习视频课笔记:逻辑回归公式推导及C++实现
逻辑回归(Logistic Regression)是一个二分分类算法。逻辑回归的目标是最小化其预测与训练数据之间的误差。为了训练逻辑回归模型中的参数w和b,需要定义一个成本函数(cost function)。成本函数(cost function):它是针对整个训练集的。衡量参数w和b在整个训…
网络运行时间提高100倍,Google使用的AI视频理解架构有多强?
译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)视频理解是一个很有挑战性的问题。由于视频包含时空数据,因此图像的特征表示需要同时提取图像和运动信息。这不仅对自动理解视频语义内容有重要性,还对机器人的感知和学习也至关重要…

iOS学习笔记(十三)——获取手机信息(UIDevice、NSBundle、NSLocale)
2019独角兽企业重金招聘Python工程师标准>>> iOS的APP的应用开发的过程中,有时为了bug跟踪或者获取用反馈的需要自动收集用户设备、系统信息、应用信息等等,这些信息方便开发者诊断问题,当然这些信息是用户的非隐私信息࿰…

吴恩达老师深度学习视频课笔记:单隐含层神经网络公式推导及C++实现(二分类)
关于逻辑回归的公式推导和实现可以参考: http://blog.csdn.net/fengbingchun/article/details/79346691 下面是在逻辑回归的基础上,对单隐含层的神经网络进行公式推导:选择激活函数时的一些经验:不同层的激活函数可以不一样。如果…

「2019中国大数据技术大会」超值学生票来啦!
大会官网:https://t.csdnimg.cn/U1wA经过11年的沉淀与发展,中国大数据技术大会见证了大数据技术生态在中国的建立、发展和成熟,已经成为国内大数据行业极具影响力的盛会,也是大数据人非常期待的年度深度分享盛会。在新的时代背景下…
校验正确获取对象或者数组的属性方法(babel-plugin-idx/_.get)
背景: 开发中经常遇到取值属性的时候,需要校验数值的有效性。 例如: 获取props对象里面的friends属性 props.user && props.user.friends && props.user.friends[0] && props.user.friends[0].friends 对于深层的对…
Ring Tone Manager on Windows Mobile
2019独角兽企业重金招聘Python工程师标准>>> 手机铃声经常能够体现一个人的个性,有些哥们儿在自习室不把手机设置成震动,一来电就#$^%^&^%#$&$*,声音还很大,唯恐别人听不到。 Windows Mobile设备上如何来设置手…

OpenCV3.3中K-Means聚类接口简介及使用
OpenCV3.3中给出了K-均值聚类(K-Means)的实现,即接口cv::kmeans,接口的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/kmeans.cpp文件中,其中:下面对此接口中的参数作个简单说明:(1)、data:…

一文读懂对抗机器学习Universal adversarial perturbations | CSDN博文精选
作者 | Icoding_F2014来源 | CSDN博客本文提出一种 universal 对抗扰动,universal 是指同一个扰动加入到不同的图片中,能够使图片被分类模型误分类,而不管图片到底是什么。示意图:形式化的定义:对于d维数据分布 μ&…
Reactor模式与Proactor模式
博主一脚刚踏进分布式的大门(看《分布式Java应用》,如果大家有啥推荐的书欢迎留言~),发现书中对NIO采用的Reactor模式、AIO采用的Proactor模式一笔带过,好奇心趋势我找了一下文章,发现两篇挺不错的文章&…
linux下使profile和.bash_profile立即生效的方法
使profile生效的方法1.source /etc/profile使用.bash_profile生效的方法1 . .bash_profile2 source .bash_profile3 exec bash --login转载于:https://blog.51cto.com/shine20/1436473
吴恩达老师深度学习视频课笔记:多隐含层神经网络公式推导(二分类)
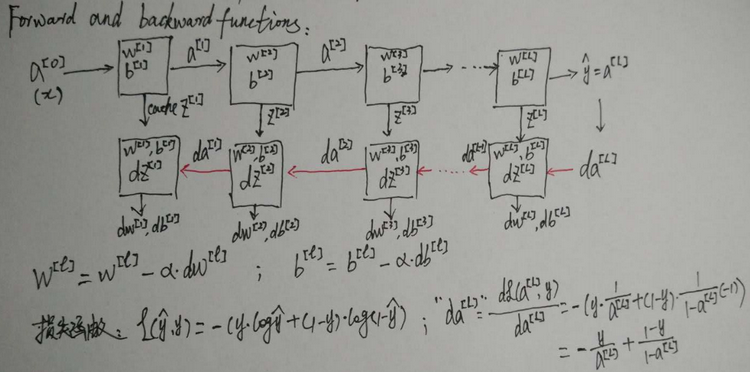
多隐含层神经网络的推导步骤非常类似于单隐含层神经网络的步骤,只不过是多重复几遍。关于单隐含层神经网络公式的推导可以参考: http://blog.csdn.net/fengbingchun/article/details/79370310 逻辑回归是一个浅层模型(shadow model),或称单层…
Python中的元编程:一个关于修饰器和元类的简单教程
作者 | Saurabh Kukade译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)最近,作者遇到一个非常有趣的概念,它就是用 Python 进行元编程。我想在本文中分享我对该主题的见解。作者希望它可以帮助解决这个问题,因为很多人说…
获取用户电脑的上网IP地址
在项目中经常要获取用户的上网的IP地址,如何获取用户的IP地址,方法很多,现在介绍以下2种。 /// <summary> /// 获取本机在局域网的IP地址 /// </summary> /// <returns></returns> …
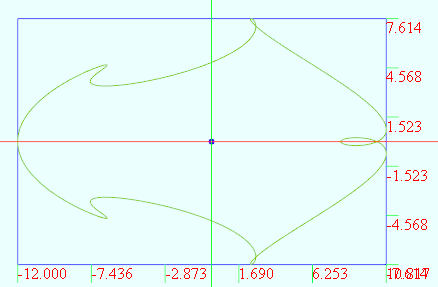
数学图形(1.40)T_parameter
不记得在哪搞了个数学公式生成的图形. vertices 1000t from 0 to (2*PI) r 2.0 x r*(5*cos(t) - cos(6*t)) y r*(3*sin(t) - sin(4*t)) 给线加上一维变量的变化,使之变成面: vertices D1:360 D2:21u from 0 to (2*PI) D1 v from 0 to 20 D2x (v2)*cos(u) - cos((v3)*u…

K-均值聚类(K-Means) C++代码实现
K-均值聚类(K-Means)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/79276668 以下是K-Means的C实现,code参考OpenCV 3.3中的cv::kmeans函数,均值点初始化的方法仅支持KMEANS_RANDOM_CENTERS。以下是从数据集MNIST中提取…
让学生网络相互学习,为什么深度相互学习优于传统蒸馏模型?| 论文精读
作者 | Ying Zhang,Tao Xiang等译者 | 李杰出品 | AI科技大本营(ID:rgznai100)蒸馏模型是一种将知识从教师网络(teacher)传递到学生网络(student)的有效且广泛使用的技术。通常来说,…

mac apache 配置
mac系统自带apache这无疑给广大的开发朋友提供了便利,接下来是针对其中的一些说明 一、自带apache相关命令 1. sudo apachectl start 启动服务,需要权限,就是你计算机的password 2. sudo apachectl stop 终止服务 ####3. sudo apachectl rest…
jQuery学习---------认识事件处理
3种事件模型:原始事件模型DOM事件模型IE事件模型原始事件模型(0级事件模型)1、事件处理程序被定义为函数实例,然后绑定到DOM元素事件对象上,实现事件的注册。例子:var btn document.getElementsByTagName(…
C++中的虚函数表介绍
在C语言中,当我们使用基类的引用或指针调用一个虚成员函数时会执行动态绑定。因为我们直到运行时才能知道到底调用了哪个版本的虚函数,所以所有虚函数都必须有定义。通常情况下,如果我们不使用某个函数,则无须为该函数提供定义。但是我们必须…

AI如何赋能金融行业?百度、图灵深视等同台分享技术实践
近日,由BTCMEX举办的金融技术创新研讨会在北京举办。BTCMEX投资人李笑来,AI技术公司TuringPass、百度、美国Apache基金会项目Pulsar、区块链安全公司SlowMist等相关专家参加了此次会议,共同探讨了金融技术在创新方面的现状。 图灵深视副总裁许…