1. 文件系统——磁盘分区、各目录功能、硬盘
一、磁盘分区及文件访问入口
在前文中介绍过,Linux的整个文件系统像一棵倒置的数,最顶层的是根文件系统,其下有很多一级子目录,一级子目录下面是二级子目录,依此类推:
/:根目录
/bin,/sbin:二进制程序,操作系统自身启动运行就需要用到的程序。
/bin下为普通用户使用的程序;/sbin下为管理员用户使用的程序
/usr/bin,/usr/sbin:二进制程序,基本的系统管理工具。
/usr/bin下的程序普通用户都能用;
/usr/sbin为管理命令。
/usr/local/bin, /usr/local/sbin:第三方程序,和操作系统的基本启 动运行无关,是管理员安装的用于 管理操作系统的特定工具。
事实上,/,/bin,/sbin,/usr/bin,/usr/sbin, /usr/local/bin, /usr/local/sbin 可以完全存在于不同的磁盘分区上,尽管他们看起来都像是存在于/目录之中的。
假设磁盘上一共有四个分区,其中根目录位于1号分区,那么所有对操作系统的访问都必须以1号分区为入口,因为所有的文件都是根/目录下的文件,都以根目录为访问入口,根/目录有且仅有一个,所以访问另外3个分区,就必须以根所在的1号分区为入口,1号分区即根分区。
如果我们希望另外3个分区中的某个分区,例如3号分区,也能派上用场,那么就需要让此分区下的文件和根目录建立关联关系。比如/usr这个目录位于根/目录之下,如果想把文件存入/usr这个目录下,完全可以不存放在分区1下而存放在3号分区下,只需要让文件和/usr目录建立关联关系。要注意的是,/usr目录位于1号分区,/usr里的文件位于3号分区。

根目录下的目录可以关联其他的文件,而这些文件也可以进一步关联其他的分区:如果/usr目录下有一个名为local的目录,即/usr/local,存放在3号分区上,而local目录又关联了一个新的分区,4号分区,在4号分区上存放有bin目录,即/usr/local/bin,这样一来,/,/usr,/usr/local,/usr/local/bin分别关联了1号、3号和4号分区。
事实上,文件所关联的位置(或目录),就是文件的入口。上述例子中,如果将4号分区拆卸下来,挂载到另一个系统里的某个目录下,如/test目录,那么要访问bin中的文件,就会以/test为入口,即/test/bin,而看不到/usr/local了。

以上就是linux 的分区形式,在逻辑上会给人以层次感,但在物理上各文件和目录可以是存在于不同的分区上的平行结构。
二、各目录的功能
1. 库目录lib
所谓的库,即是指的公共的功能模块,所有的二进制文件都需要依赖于共享的库赖运行。Linux的通过系统调用来操作内核,而系统调用过于复杂,为了使程序能够顺利运行,系统调用上存封装了很多接口帮助程序进行系统调用,这些接口就是库文件。

库文件存放在lib目录下,lib目录服务于/bin和/sbin下的程序。/usr/lib也是库目录,可以为/usr/bin 和 /usr/sbin 提供库,不过/usr/bin 和 /usr/sbin的库很多也直接由/lib提供了;/usr/local/bin 和 /usr/local/sbin下的程序所依赖的特殊库,通常由/usr/local/lib提供。
2. 配置文件
Linux中程序运行除了依赖于库文件外,还依赖配置文件。/etc这个目录通常为/bin、/sbin、/usr/bin、/usr/sbin提供配置文件;而/usr/local/bin和/usr/local/sbin的配置文件,通常放在/usr/local/etc下,但也有可能直接存放在/etc下。
3. 临时文件
通常程序在运行时会产生很多临时文件,这些临时文件多存放在/tmp目录下。
4. /var目录
/var目录下存放的文件多为内容经常变化的文件,主要有log,mail,cache等
A)日志文件
如果要知道系统的运行状况,或者是文件被访问的情况,可以查看日志文件,Linux中的日志文件多存放在/var/log中;
B)邮件缓存
/var/mail目录多用来为用户提供邮件缓存;
C)缓存文件
/var/cache目录主要用来存放缓存文件;
5. 伪文件系统/proc 和 /sys
A)内核映像 /proc
Linux的内核没有配置文件,如果用户想要自行定制内核的特性,只能在内核启动时给内核传递参数,一般参数的传递通过grub(后文中会详解)来实现。但是当系统启动之后,想要查看或改变内核的特性,就需要用到/proc这个目录,此目录用来存放内核的输出参数,每一个参数在/proc目录中都表现为一个文件,故可以通过修改/proc下的文件来模拟修改内核的运行参数,但要注意的是只有有写权限的参数才能修改,其他的可能只能用来查看内核的参数。

B)硬件信息 /sys
和/proc类似,/sys也是伪文件系统。如果想要修改硬件的工作属性,而非内核的运行参数,就需要通过修改/sys中的文件来实现。
6. 挂载目录/media 和 /mnt
A)关联便携性设备:/media
B)关联第二块硬盘上的分区/mnt
上述两个挂载目录是一种约定俗成的挂载方式,如果不挂载在这两个目录下也是可以的。
7.引导目录/boot
/boot目录时引导目录,主要用来存放内核,操作系统的启动和进程的管理都必须由内核来完成
8. 家目录 /home
目前的操作系统基本上都是多任务多用户的,每一个用户登陆到系统中,其每一个操作都必然会处于一个目录中,这个目录就是用户的工作目录;而该用户最初登陆到操作系统中,必然也会处于某个目录中,且这个目录通常用来存放和管理工作,该目录即称为家目录/home。在/home目录下的/home/USERNAME 和 /root 都是用户的家目录。
9. 设备文件/dev
Linux所识别的任何一个硬件设备都存放在/dev目录下,且每一个硬件设备都有一个与之对应的文件,这个文件被作为往该设备上存储或读取数据的入口。
Linux支持的设备类型主要有两种,即:
b:块设备,支持随机访问。键盘不属于随机设备,因为如果输入的是ABC,则不会显示为BCA。
c:字符设备,也称为线性设备,即有一定的先后顺序。
不同种类的设备在/dev上表现为不同的文件,如:
IDE, ATA类的设备:显示为 /dev/hd[a-z]
常见的PC机上通常有两个IDE插槽,每一个槽上可以接两个IDE设备,一个主设备(master),一个从设备(slave),故一个PC机最多能接4块IDE类的设备,即/dev/hda,/dev/hdb,/dev/hdc,/dev/hdd。通常情况下第一个IDE控制器接两块硬盘,即/dev/hda,/dev/hdb;第二个IDE控制器接光驱设备,故光驱设备通常表现为 /dev/hdc,所以虚拟机模拟光驱设备时,也使用的是hdc。
SCSI,SAS,SATA,USB 类的设备:被识别为 /dev/sd[a-z]
由于上述四种设备都表现为sd,不论是光驱设备,还是硬盘设备,都以/dev/sda, /dev/sdb...的形式表现,这样必然会导致混淆的现象。为了有效控制这种情况,Linux引入了一个机制:udev。用户可以借助udev来自行定义设备的名称,如/dev/sata1,/dev/usb1等。
三、硬件设备简介
1. 硬盘设备:既支持随机访问,也支持线性访问,但通常把它当做随机存取访问的块设备。
2. I/O,I/O Controller:控制器
I/O Adapter:适配器

计算机的CPU在和不同的设备进行数据交互时,信号的传递机制是不一样的,这就需要一个芯片来转换或翻译CPU的指令。比如CPU和显卡进行数据交互时,就需要这种芯片来帮助显卡完成指令,该芯片如果集成在主板上,就称为控制器(Controller),如果主板上没有集成该芯片,那么可以通过主板上的扩展槽来外接芯片,这种不集成的芯片,称为适配器(Adapter)。
3. 硬盘
A)硬盘类型
硬盘根据其I/O控制器的不同,和工作属性的不同会分成不同的类型:
IDE, ATA:并行通信,133MB/s

串行通信数据按顺序单向传输,并行通信多个数据可以同时传输;直观上并行传输的速度高于串行传输速度,但可以串行通信的也可以通过提高传输速度来超越并行传输,例如并行传输速率为每秒10bit,而串行传输的速率为每秒100bit,那么传输50bit的数据,串行传输很有可能会快于并行传输,这依赖于传输的吞吐量。吞吐量即每秒能传输的数据量。
SATA:串行通信(Serial),(SATA1)300MB/s,(SATA2)600MB/s,(SATA3)6Gb/s由ATA 发展而来,因为尽管并行数据传输速度快,但数据传输过程中干扰严重,故发展SATA,通过提高吞吐量来实现传输速度的提高。
SCSI:Small Computer System Interface,小型计算机接口,并行传输,它比同期的IDE传输速度要快,(UtraSCSI)320MB/s,转速通常为10000RPM~15000RPM。
通常情况下CPU每读取4kb的数据,那么即使仅读取1MB的数据,CPU都需要在硬盘和内存中频繁切换,这样严重影响读取速度。SCSI的好处就在于它自带一个智能控制器,可以控制数据的读取和存放位置,类似于一个小型的CPU,从而可以大大降低CPU的压力,使CPU的资源从无谓的I/O操作中解放出来。
SAS:SCSI的串行版,它的传输速度比SCSI要快得多。尽管SCSI硬盘性能好且很智能,但随着时代的发展,SCSI硬盘的技术已逐步被其串行版SAS所取代
SSD:Solid-State Disk,固态磁盘。它属于闪存系列,但SSD的优势在于多个磁盘并行传输,使传输速度大为提升,读写速度能达到500MB/s,且这个值为真实速度而非理论值。
USB:(1.1,2.0, 3.0)
B)硬盘工作原理
硬盘为多个盘片组成,其中有一根轴将数个盘片串联,在盘片飞速旋转过程中,盘片外有一根机械臂上带有 盘片总数*2 的磁头,这些磁头用来读取盘片上正反两面的数据。

每一盘片被划分为数个同心圆,同心圆之间的圆环用来存放数据,此圆环称为磁道(Track),靠近圆心处的磁道转过的距离小于外围的磁道,且能存放的数据小于外围的磁道,故越靠外的磁道存储性能越好。不论是外围还是靠内的磁道,转过的角度都是一致的,故此设备又称为固定角速度设备。
如果单纯的使用磁道来存储数据未免太过粗糙了,故可以将磁道进一步划分为更小的单元,即扇区(Sector)。对于机械式硬盘来说,扇区是最小存储单元。
如果一个扇区的大小是512个字节,那么存放4kb的数据,则一共需要8个扇区,利用盘片正反两面存取,则只用让磁头滑过4个扇区,可以使存储速度更快。
不同盘面上相同位置的磁道,组合起来形成桶状结构,叫做柱面(Cylinder)。这种柱状结构要求不同的盘片上磁道位置保持一致,故硬盘在读取数据时不能震动,否则磁头会划坏硬盘。
现在假设要在10号柱面上读取数据,而磁头目前处于1号柱面,那么机械臂会向内移动,使磁头能接触到10号柱面。当磁头接触到10号柱面了,但所要读取的数据不在磁头触碰的扇区里,这时磁头就需要等待盘片转动,直到目标数据所在的扇区下一次出现,这个等待所需要的时间,即为等待时间,所有数据的等待时间叫做平均巡道时间。故磁盘转动速度越快,等待时间越短,性能就越好。这种转动速度表示为RPM(Rotation Per Minute),即一分钟多少转。由于磁盘转速极快,会产生巨大热量,故硬盘盒内需保持真空,以控制温度。
转载于:https://blog.51cto.com/wuyelan/1435770
相关文章:

吴恩达老师深度学习视频课笔记:逻辑回归公式推导及C++实现
逻辑回归(Logistic Regression)是一个二分分类算法。逻辑回归的目标是最小化其预测与训练数据之间的误差。为了训练逻辑回归模型中的参数w和b,需要定义一个成本函数(cost function)。成本函数(cost function):它是针对整个训练集的。衡量参数w和b在整个训…

网络运行时间提高100倍,Google使用的AI视频理解架构有多强?
译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)视频理解是一个很有挑战性的问题。由于视频包含时空数据,因此图像的特征表示需要同时提取图像和运动信息。这不仅对自动理解视频语义内容有重要性,还对机器人的感知和学习也至关重要…

iOS学习笔记(十三)——获取手机信息(UIDevice、NSBundle、NSLocale)
2019独角兽企业重金招聘Python工程师标准>>> iOS的APP的应用开发的过程中,有时为了bug跟踪或者获取用反馈的需要自动收集用户设备、系统信息、应用信息等等,这些信息方便开发者诊断问题,当然这些信息是用户的非隐私信息࿰…

吴恩达老师深度学习视频课笔记:单隐含层神经网络公式推导及C++实现(二分类)
关于逻辑回归的公式推导和实现可以参考: http://blog.csdn.net/fengbingchun/article/details/79346691 下面是在逻辑回归的基础上,对单隐含层的神经网络进行公式推导:选择激活函数时的一些经验:不同层的激活函数可以不一样。如果…

「2019中国大数据技术大会」超值学生票来啦!
大会官网:https://t.csdnimg.cn/U1wA经过11年的沉淀与发展,中国大数据技术大会见证了大数据技术生态在中国的建立、发展和成熟,已经成为国内大数据行业极具影响力的盛会,也是大数据人非常期待的年度深度分享盛会。在新的时代背景下…

校验正确获取对象或者数组的属性方法(babel-plugin-idx/_.get)
背景: 开发中经常遇到取值属性的时候,需要校验数值的有效性。 例如: 获取props对象里面的friends属性 props.user && props.user.friends && props.user.friends[0] && props.user.friends[0].friends 对于深层的对…
Ring Tone Manager on Windows Mobile
2019独角兽企业重金招聘Python工程师标准>>> 手机铃声经常能够体现一个人的个性,有些哥们儿在自习室不把手机设置成震动,一来电就#$^%^&^%#$&$*,声音还很大,唯恐别人听不到。 Windows Mobile设备上如何来设置手…

OpenCV3.3中K-Means聚类接口简介及使用
OpenCV3.3中给出了K-均值聚类(K-Means)的实现,即接口cv::kmeans,接口的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/kmeans.cpp文件中,其中:下面对此接口中的参数作个简单说明:(1)、data:…

一文读懂对抗机器学习Universal adversarial perturbations | CSDN博文精选
作者 | Icoding_F2014来源 | CSDN博客本文提出一种 universal 对抗扰动,universal 是指同一个扰动加入到不同的图片中,能够使图片被分类模型误分类,而不管图片到底是什么。示意图:形式化的定义:对于d维数据分布 μ&…
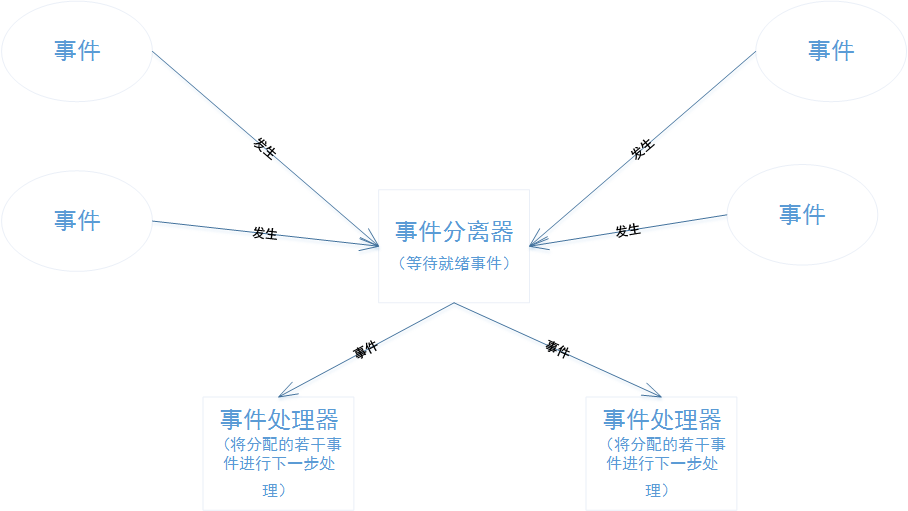
Reactor模式与Proactor模式
博主一脚刚踏进分布式的大门(看《分布式Java应用》,如果大家有啥推荐的书欢迎留言~),发现书中对NIO采用的Reactor模式、AIO采用的Proactor模式一笔带过,好奇心趋势我找了一下文章,发现两篇挺不错的文章&…
linux下使profile和.bash_profile立即生效的方法
使profile生效的方法1.source /etc/profile使用.bash_profile生效的方法1 . .bash_profile2 source .bash_profile3 exec bash --login转载于:https://blog.51cto.com/shine20/1436473
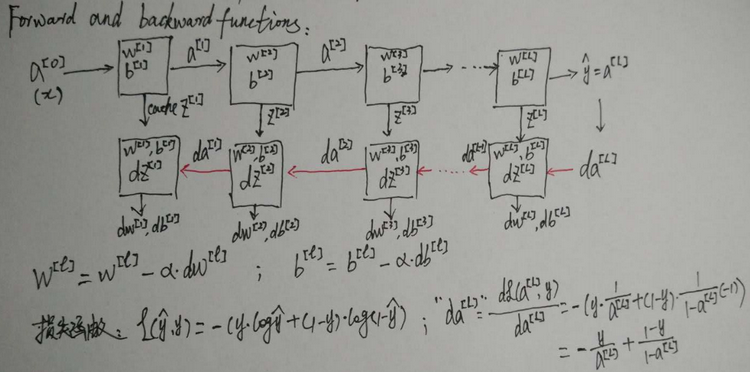
吴恩达老师深度学习视频课笔记:多隐含层神经网络公式推导(二分类)
多隐含层神经网络的推导步骤非常类似于单隐含层神经网络的步骤,只不过是多重复几遍。关于单隐含层神经网络公式的推导可以参考: http://blog.csdn.net/fengbingchun/article/details/79370310 逻辑回归是一个浅层模型(shadow model),或称单层…
Python中的元编程:一个关于修饰器和元类的简单教程
作者 | Saurabh Kukade译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)最近,作者遇到一个非常有趣的概念,它就是用 Python 进行元编程。我想在本文中分享我对该主题的见解。作者希望它可以帮助解决这个问题,因为很多人说…
获取用户电脑的上网IP地址
在项目中经常要获取用户的上网的IP地址,如何获取用户的IP地址,方法很多,现在介绍以下2种。 /// <summary> /// 获取本机在局域网的IP地址 /// </summary> /// <returns></returns> …
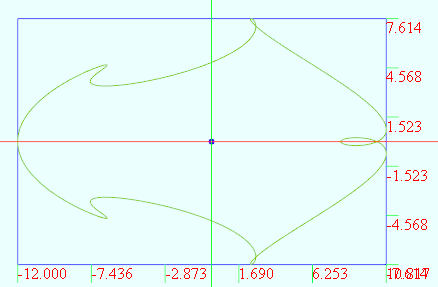
数学图形(1.40)T_parameter
不记得在哪搞了个数学公式生成的图形. vertices 1000t from 0 to (2*PI) r 2.0 x r*(5*cos(t) - cos(6*t)) y r*(3*sin(t) - sin(4*t)) 给线加上一维变量的变化,使之变成面: vertices D1:360 D2:21u from 0 to (2*PI) D1 v from 0 to 20 D2x (v2)*cos(u) - cos((v3)*u…

K-均值聚类(K-Means) C++代码实现
K-均值聚类(K-Means)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/79276668 以下是K-Means的C实现,code参考OpenCV 3.3中的cv::kmeans函数,均值点初始化的方法仅支持KMEANS_RANDOM_CENTERS。以下是从数据集MNIST中提取…
让学生网络相互学习,为什么深度相互学习优于传统蒸馏模型?| 论文精读
作者 | Ying Zhang,Tao Xiang等译者 | 李杰出品 | AI科技大本营(ID:rgznai100)蒸馏模型是一种将知识从教师网络(teacher)传递到学生网络(student)的有效且广泛使用的技术。通常来说,…

mac apache 配置
mac系统自带apache这无疑给广大的开发朋友提供了便利,接下来是针对其中的一些说明 一、自带apache相关命令 1. sudo apachectl start 启动服务,需要权限,就是你计算机的password 2. sudo apachectl stop 终止服务 ####3. sudo apachectl rest…
jQuery学习---------认识事件处理
3种事件模型:原始事件模型DOM事件模型IE事件模型原始事件模型(0级事件模型)1、事件处理程序被定义为函数实例,然后绑定到DOM元素事件对象上,实现事件的注册。例子:var btn document.getElementsByTagName(…
C++中的虚函数表介绍
在C语言中,当我们使用基类的引用或指针调用一个虚成员函数时会执行动态绑定。因为我们直到运行时才能知道到底调用了哪个版本的虚函数,所以所有虚函数都必须有定义。通常情况下,如果我们不使用某个函数,则无须为该函数提供定义。但是我们必须…

AI如何赋能金融行业?百度、图灵深视等同台分享技术实践
近日,由BTCMEX举办的金融技术创新研讨会在北京举办。BTCMEX投资人李笑来,AI技术公司TuringPass、百度、美国Apache基金会项目Pulsar、区块链安全公司SlowMist等相关专家参加了此次会议,共同探讨了金融技术在创新方面的现状。 图灵深视副总裁许…
【Win32 API学习]打开可执行文件
在MFC中打开其他可执行文件常用到的方法有:WinExec、ShellExecute、CreatProcess。 1.WinExec WinExec 主要运行EXE文件,用法简单,只有两个参数,前一个指定命令路径,后一个指定窗口显示方式: UINT WinExec(…
支付宝接口使用文档说明 支付宝异步通知
支付宝接口使用文档说明 支付宝异步通知(notify_url)与return_url. 现支付宝的通知有两类。 A服务器通知,对应的参数为notify_url,支付宝通知使用POST方式 B页面跳转通知,对应的参数为return_url,支付宝通知使用GET方式 ÿ…
完全隐藏Master Page Site Actions菜单只有管理员才可以看见
1. 在Master Page Head 增加下面的Style <style type"text/css"> .ms-cui-tt{visibility:hidden;} </style> 2. 增加SPSecurityTrimmedControl <SharePoint:SPRibbonPeripheralContent runat"server" Location"TabRowLeft&qu…
深度学习中的随机梯度下降(SGD)简介
随机梯度下降(Stochastic Gradient Descent, SGD)是梯度下降算法的一个扩展。机器学习中反复出现的一个问题是好的泛化需要大的训练集,但大的训练集的计算代价也更大。机器学习算法中的代价函数通常可以分解成每个样本的代价函数的总和。随着训练集规模增长为数十亿…
推荐系统中的前沿技术研究与落地:深度学习、AutoML与强化学习 | AI ProCon 2019...
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)个性化推荐算法滥觞于互联网的急速发展,随着国内外互联网公司,如 Netflix 在电影领域,亚马逊、淘宝、京东等在电商领域,今日头条在内容领域的采用和推动&…

运维日志管理系统
因公司数据安全和分析的需要,故调研了一下 GlusterFS lagstash elasticsearch kibana 3 redis 整合在一起的日志管理应用:安装,配置过程,使用情况等续一,glusterfs分布式文件系统部署:说明…

NLP学习思维导图,非常的全面和清晰
作者 | Tae Hwan Jung & Kyung Hee编译 | ronghuaiyang【导读】Github上有人整理了NLP的学习路线图(思维导图),非常的全面和清晰,分享给大家。先奉上GitHub地址:https://github.com/graykode/nlp-roadmapnlp-roadm…
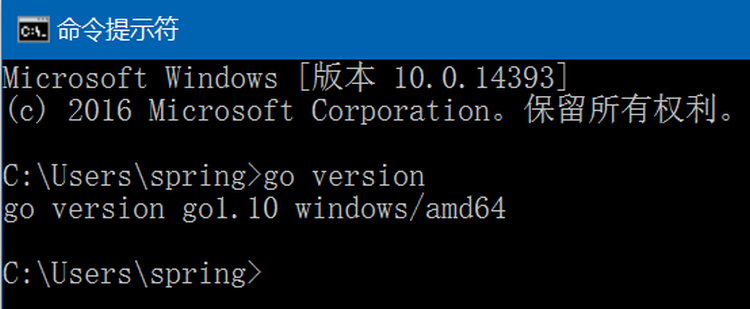
Go在windows10 64位上安装过程
1. 从 https://golang.org/dl/ 下载最新的发布版本go1.10即go1.10.windows-amd64.msi; 2. 双击go1.10.windows-amd64.msi ,使用默认选项,默认会安装到C:\Go目录下; 3. 将C:\Go\bin目录添加到系统环境变量中(默认已自动添加),此目录下有go.exe…
Windows SharePoint Services 3.0 应用程序模板
微软发布的一些WSS模板,看了一下,跟以前看到的模板好像不同模板分两类,一类是站点管理模板,一类是服务器管理模板站点管理模板:董事会、业务绩效报告、政府机构案例管理、课堂管理、临床试验启动和管理、竞争性分析站点…