CUDA Samples: Image Process: BGR to BGR565
图像像素格式BGR565是每一个像素占2个字节,其中Blue占5位,Green占6位,Red占5位。在OpenCV中,BGR到BGR565的每一个像素的计算公式是:
unsigned short dst = (unsigned short)((B >> 3) | ((G & ~3) << 3) | ((R & ~7) << 8) )下面分别给出了C++和CUDA实现的测试代码,如下:
bgr2bgr565.cpp:
#include "funset.hpp"
#include <chrono>
#include "common.hpp"int bgr2bgr565_cpu(const unsigned char* src, int width, int height, unsigned char* dst, float* elapsed_time)
{TIME_START_CPUfor (int y = 0; y < height; ++y) {const unsigned char* p1 = src + y * width * 3;unsigned char* p2 = dst + y * width * 2;for (int x = 0; x < width; ++x, p1+=3) {((unsigned short*)p2)[x] = (unsigned short)((p1[0] >> 3) | ((p1[1] & ~3) << 3) | ((p1[2] & ~7) << 8));}}TIME_END_CPUreturn 0;
}#include "funset.hpp"
#include <iostream>
#include <chrono>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include "common.hpp"/* __global__: 函数类型限定符;在设备上运行;在主机端调用,计算能力3.2及以上可以在
设备端调用;声明的函数的返回值必须是void类型;对此类型函数的调用是异步的,即在
设备完全完成它的运行之前就返回了;对此类型函数的调用必须指定执行配置,即用于在
设备上执行函数时的grid和block的维度,以及相关的流(即插入<<< >>>运算符);
a kernel,表示此函数为内核函数(运行在GPU上的CUDA并行计算函数称为kernel(内核函
数),内核函数必须通过__global__函数类型限定符定义);*/
__global__ static void bgr2bgr565(const unsigned char* src, int width, int height, unsigned char* dst)
{/* gridDim: 内置变量,用于描述线程网格的维度,对于所有线程块来说,这个变量是一个常数,用来保存线程格每一维的大小,即每个线程格中线程块的数量.一个grid为三维,为dim3类型;blockDim: 内置变量,用于说明每个block的维度与尺寸.为dim3类型,包含了block在三个维度上的尺寸信息;对于所有线程块来说,这个变量是一个常数,保存的是线程块中每一维的线程数量;blockIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程块的索引;用于说明当前thread所在的block在整个grid中的位置,blockIdx.x取值范围是[0,gridDim.x-1],blockIdx.y取值范围是[0, gridDim.y-1].为uint3类型,包含了一个block在grid中各个维度上的索引信息;threadIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程索引;用于说明当前thread在block中的位置;如果线程是一维的可获取threadIdx.x,如果是二维的还可获取threadIdx.y,如果是三维的还可获取threadIdx.z;为uint3类 型,包含了一个thread在block中各个维度的索引信息 */int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;//if (x == 0 && y == 0) {// printf("%d, %d\n", width, height);//}if (x < width && y < height) { const unsigned char* p = src + (y * width * 3 + x * 3);((unsigned short*)dst)[y * width + x] = (unsigned short)((p[0] >> 3) | ((p[1] & ~3) << 3) | ((p[2] & ~7) << 8));}
}int bgr2bgr565_gpu(const unsigned char* src, int width, int height, unsigned char* dst, float* elapsed_time)
{unsigned char *dev_src{ nullptr }, *dev_dst{ nullptr };// cudaMalloc: 在设备端分配内存cudaMalloc(&dev_src, width * height * 3 * sizeof(unsigned char));cudaMalloc(&dev_dst, width * height * 2 * sizeof(unsigned char));/* cudaMemcpy: 在主机端和设备端拷贝数据,此函数第四个参数仅能是下面之一:(1). cudaMemcpyHostToHost: 拷贝数据从主机端到主机端(2). cudaMemcpyHostToDevice: 拷贝数据从主机端到设备端(3). cudaMemcpyDeviceToHost: 拷贝数据从设备端到主机端(4). cudaMemcpyDeviceToDevice: 拷贝数据从设备端到设备端(5). cudaMemcpyDefault: 从指针值自动推断拷贝数据方向,需要支持统一虚拟寻址(CUDA6.0及以上版本)cudaMemcpy函数对于主机是同步的 */cudaMemcpy(dev_src, src, width * height * 3 * sizeof(unsigned char), cudaMemcpyHostToDevice);/* cudaMemset: 存储器初始化函数,在GPU内存上执行。用指定的值初始化或设置设备内存 */cudaMemset(dev_dst, 0, width * height * 2 * sizeof(unsigned char));TIME_START_GPU/* dim3: 基于uint3定义的内置矢量类型,相当于由3个unsigned int类型组成的结构体,可表示一个三维数组,在定义dim3类型变量时,凡是没有赋值的元素都会被赋予默认值1 */// Note:每一个线程块支持的最大线程数量为1024,即threads.x*threads.y必须小于等于1024dim3 threads(32, 32);dim3 blocks((width + 31) / 32, (height + 31) / 32);/* <<< >>>: 为CUDA引入的运算符,指定线程网格和线程块维度等,传递执行参数给CUDA编译器和运行时系统,用于说明内核函数中的线程数量,以及线程是如何组织的;尖括号中这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码,传递给设备代码本身的参数是放在圆括号中传递的,就像标准的函数调用一样;不同计算能力的设备对线程的总数和组织方式有不同的约束;必须先为kernel中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界等 ;使用运行时API时,需要在调用的内核函数名与参数列表直接以<<<Dg,Db,Ns,S>>>的形式设置执行配置,其中:Dg是一个dim3型变量,用于设置grid的维度和各个维度上的尺寸.设置好Dg后,grid中将有Dg.x*Dg.y*Dg.z个block;Db是一个dim3型变量,用于设置block的维度和各个维度上的尺寸.设置好Db后,每个block中将有Db.x*Db.y*Db.z个thread;Ns是一个size_t型变量,指定各块为此调用动态分配的共享存储器大小,这些动态分配的存储器可供声明为外部数组(extern __shared__)的其他任何变量使用;Ns是一个可选参数,默认值为0;S为cudaStream_t类型,用于设置与内核函数关联的流.S是一个可选参数,默认值0. */// Note: 核函数不支持传入参数为vector的data()指针,需要cudaMalloc和cudaMemcpy,因为vector是在主机内存中bgr2bgr565 << <blocks, threads >> >(dev_src, width, height, dev_dst);/* cudaDeviceSynchronize: kernel的启动是异步的, 为了定位它是否出错, 一般需要加上cudaDeviceSynchronize函数进行同步; 将会一直处于阻塞状态,直到前面所有请求的任务已经被全部执行完毕,如果前面执行的某个任务失败,将会返回一个错误;当程序中有多个流,并且流之间在某一点需要通信时,那就必须在这一点处加上同步的语句,即cudaDeviceSynchronize;异步启动reference: https://stackoverflow.com/questions/11888772/when-to-call-cudadevicesynchronize */cudaDeviceSynchronize();TIME_END_GPUcudaMemcpy(dst, dev_dst, width * height * 2 * sizeof(unsigned char), cudaMemcpyDeviceToHost);// cudaFree: 释放设备上由cudaMalloc函数分配的内存cudaFree(dev_dst);cudaFree(dev_src);return 0;
}#include "funset.hpp"
#include <random>
#include <iostream>
#include <vector>
#include <memory>
#include <string>
#include <algorithm>
#include "common.hpp"int test_image_process_bgr2bgr565()
{const std::string image_name{ "E:/GitCode/CUDA_Test/test_data/images/lena.png" };cv::Mat mat = cv::imread(image_name, 1);CHECK(mat.data);const int width{ 1513 }, height{ 1473 };cv::resize(mat, mat, cv::Size(width, height));std::unique_ptr<unsigned char[]> data1(new unsigned char[width * height * 2]), data2(new unsigned char[width * height * 2]);float elapsed_time1{ 0.f }, elapsed_time2{ 0.f }; // millisecondscv::Mat bgr565;cv::cvtColor(mat, bgr565, cv::COLOR_BGR2BGR565);CHECK(bgr2bgr565_cpu(mat.data, width, height, data1.get(), &elapsed_time1) == 0);CHECK(bgr2bgr565_gpu(mat.data, width, height, data2.get(), &elapsed_time2) == 0);fprintf(stdout, "image bgr to bgr565: cpu run time: %f ms, gpu run time: %f ms\n", elapsed_time1, elapsed_time2);CHECK(compare_result(data1.get(), bgr565.data, width*height * 2) == 0);CHECK(compare_result(data1.get(), data2.get(), width*height*2) == 0);return 0;
}
GitHub: https://github.com/fengbingchun/CUDA_Test
相关文章:

NoSQL数据库探讨 - 为什么要用非关系数据库?
源地址:http://robbin.javaeye.com/blog/524977 随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。而传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类…
手机内存RAM、ROM简介
手机内存包含两个:一个是运行内存(RAM),一个是机身内存(ROM)。两者的功能有所不同,运行内存是对手机操作系统和其它程序运行过程中,产生的临时数据进行存储的媒介。如果手机运行的程序比较多,占用运行内存空间较大&…

一个月入门Python爬虫,轻松爬取大规模数据
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样一个月入门Python爬虫,轻松爬的编程语言提供越来越多的优秀工具&#x…

软件包管理 之 软件在线升级更新yum 图形工具介绍
作者:北南南北来自:LinuxSir.Org提要:yum 是Fedora/Redhat 软件包管理工具,包括文本命令行模式和图形模式;图形模式的yum也是基于文本模式的;目前yum图形前端程序主要有 yumex和kyum ; 正文一、…

[PHPUnit]自动生成PHPUnit测试骨架脚本-提供您的开发效率【2015升级版】
2019独角兽企业重金招聘Python工程师标准>>> 场景 在编写PHPUnit单元测试代码时,其实很多都是对各个类的各个外部调用的函数进行测试验证,检测代码覆盖率,验证预期效果。为避免增加开发量,可以使用PHPUnit提供的phpuni…

ORL Faces Database介绍
ORL人脸数据集共包含40个不同人的400张图像,是在1992年4月至1994年4月期间由英国剑桥的Olivetti研究实验室创建。此数据集下包含40个目录,每个目录下有10张图像,每个目录表示一个不同的人。所有的图像是以PGM格式存储,灰度图&…

张俊林:BERT和Transformer到底学到了什么 | AI ProCon 2019
演讲嘉宾 | 张俊林(新浪微博机器学习团队AI Lab负责人)编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】BERT提出的这一年,也是NLP领域迅速发展的一年。学界不断提出新的预训练模型,刷新各…
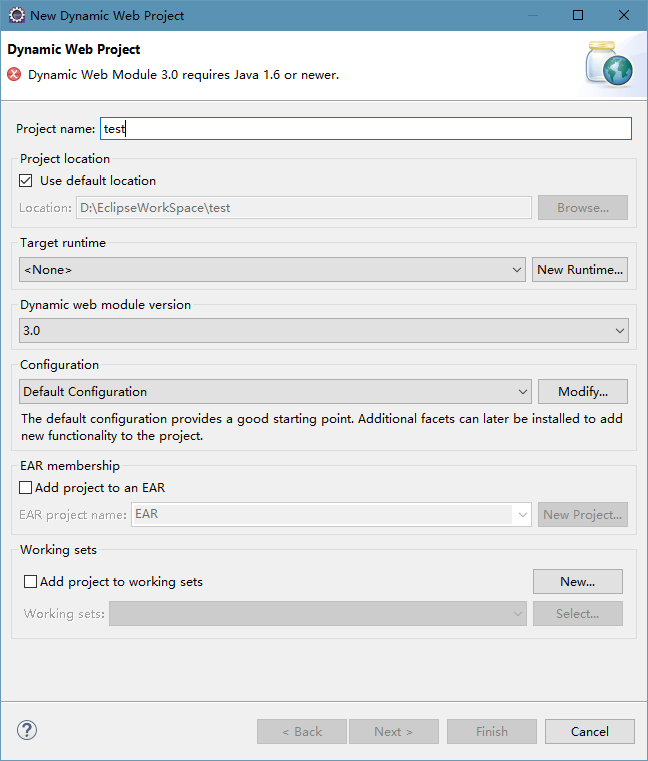
Eclipse创建web工程时,报错Dynamic Web Module 3.0 requires Java 1.6 or newer.
报错: 解决方案: 1.打开eclipse工具栏window->preferences 2.打开java->compiler 3.选择compiler compliance level在1.6以上版本(此处选择1.8) 4.点击apply and close保存修改,即可 转载于:https://www.cnblogs…
Maven学习总结(八)——使用Maven构建多模块项目
2019独角兽企业重金招聘Python工程师标准>>> Maven学习总结(八)——使用Maven构建多模块项目 在平时的Javaweb项目开发中为了便于后期的维护,我们一般会进行分层开发,最常见的就是分为domain(域模型层)、dao࿰…

哈工大、清华、CSDN、嵌入式视觉联盟合办的 AIoT 盛会,你怎么舍得错过?!
2019 嵌入式智能国际大会即将来袭!随着物联网和人工智能技术的飞速发展与相互渗透,万物智联的新赛道已经开始显现。据中商产业研究院《2016—2021年中国物联网产业市场研究报告》显示,预计到2020年,中国物联网的整体规模将达2.2万…

OpenCV3.3中主成分分析(Principal Components Analysis, PCA)接口简介及使用
OpenCV3.3中给出了主成分分析(Principal Components Analysis, PCA)的实现,即cv::PCA类,类的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/pca.cpp文件中,其中:(1)、cv::PCA::PCA:构造函数࿱…
Spring MVC配置
为什么80%的码农都做不了架构师?>>> 一、传统方式配置Spring MVC (1)导入jar包 需要导入如下的jar包 junit-3.8.1.jar spring-core-3.0.5.RELEASE.jar commons-logging-1.1.1.jar spring-context-3.0.5.REL…
主成分分析(PCA)Python代码实现
主成分分析(Principal Components Analysis, PCA)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78977202 这里是参照 http://sebastianraschka.com/Articles/2014_pca_step_by_step.html 文章中的code整理的Python代码,实现过程为…
AI发展这一年:不断衍生的技术丑闻与抵制声潮
作者 | AI Now学院译者 | Raku编辑 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】10月2日,纽约大学AI Now学院在纽约大学斯克博剧院(Skirball Theatre)组织召开了第四届年度AI Now研讨会。研讨会邀请了业内组织者…
Distributed Configuration Management Platform(分布式配置管理平台)
2019独角兽企业重金招聘Python工程师标准>>> 专注于各种 分布式系统配置管理 的通用组件/通用平台, 提供统一的配置管理服务。 主要目标: 部署极其简单:同一个上线包,无须改动配置,即可在 多个环境中(RD/QA/PRODUCTION…
如何利用zendstudio新建 或导入php项目
为什么80%的码农都做不了架构师?>>> 一、利用ZendStudio创建 PHP Project 1. 打开ZendStudio, 选择:File à New à PHP Project, 如下图所示: 于是弹出如下界面: 在”Project name”后输入工程名(比如我这里…
一文读懂GoogLeNet神经网络 | CSDN博文精选
作者 | .NY&XX来源 | CSDN博客本文介绍的是著名的网络结构GoogLeNet,目的是试图领会其中结构设计思想。GoogLeNet特点优化网络质量的生物学原理GoogLeNet网络结构的动机GoogLeNet架构细节Inception模块和普通卷积结构的差异辅助分类器GoogLeNet网络架构GoogLeNe…
C++中的函数签名
C中的函数签名(function signature):包含了一个函数的信息,包括函数名、参数类型、参数个数、顺序以及它所在的类和命名空间。普通函数签名并不包含函数返回值部分,如果两个函数仅仅只有函数返回值不同,那么系统是无法区分这两个函…
MyEclipse断点调试
2019独角兽企业重金招聘Python工程师标准>>> 1、在编辑的程序的左边,你会看到一条浅浅的灰色编带,在这里设置断点。 2、设置断点的方法有很多 方法:1)、双击 ; 2)、右键,选择“Toggl…
C primer plus 练习题 第三章
5. 1 #include <stdio.h>2 3 int main()4 {5 float you_sec;6 printf("请输入你的年龄:");7 scanf("%f", &you_sec);8 printf("年龄合计:%e 秒!\n", you_sec * 3.156e7);9 getchar(); 10 return 0; 11 }
Echache整合Spring缓存实例讲解
2019独角兽企业重金招聘Python工程师标准>>> 摘要:本文主要介绍了EhCache,并通过整合Spring给出了一个使用实例。 一、EhCache 介绍 EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的C…
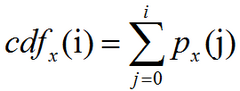
灰度图像直方图均衡化公式及实现
图像的直方图:直方图是图像中像素强度分布的图形表达方式。它统计了每一个强度值所具有的像素个数。直方图均衡化:是通过拉伸像素强度分布范围来增强图像对比度的一种方法。是图像处理领域中利用图像直方图对对比度进行调整的方法。均衡化指的是把一个分…
超越最新无监督域自适应方法,研究人员提轻量CNN新架构OSNet
作者 | Kaiyang Zhou, Xiatian Zhu, Yongxin Yang, Andrea Cavallaro, and Tao Xiang 译者 | TroyChang 编辑 | Jane 出品 | AI科技大本营(ID:rgznai100) CNN新架构OSNet 【导读】今天推荐论文《Learning Generalisable Omni-Scale Repre…
在一台机器上搭建多个redis实例
2019独角兽企业重金招聘Python工程师标准>>> 默认Redis程序安装在/usr/local/redis目录下; 配置文件:/usr/local/redis/redis.conf,该配置文件中配置的端口为默认端口:6379; Redis的启动命令路径࿱…
使用kaptcha生成验证码
2019独角兽企业重金招聘Python工程师标准>>> kaptcha是一个简单好用的验证码生成工具,通过配置,可以自己定义验证码大小、颜色、显示的字符等等。下面就来讲一下如何使用kaptcha生成验证码以及在服务器端取出验证码进行校验。 一、搭建测试环…

主成分分析(PCA) C++ 实现
主成分分析(Principal Components Analysis, PCA)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78977202以下是PCA的C实现,参考OpenCV 3.3中的cv::PCA类。使用ORL Faces Database作为测试图像。关于ORL Faces Database的介绍可以参…
为何Google、微软、华为将亿级源代码放一个仓库?从全球最大代码管理库说起...
作者 | 夕颜编辑 | Just出品 | AI 科技大本营(ID:rgznai100)【导读】2017 年,在当时微软的一篇官方博客中,时任微软云开发服务副总裁的 Brian Harry 表示微软内部代码开始向 Git 迁移,宣布推出针对大规模 repo 的“Git…
jquery mobie导致超链接不可用
在a标签中添加rel"external"即可转载于:https://blog.51cto.com/here2142/1435434
编译器GCC与Clang的异同
GCC:GNU(Gnus Not Unix)编译器套装(GNU Compiler Collection,GCC),指一套编程语言编译器,以GPL及LGPL许可证所发行的自由软件,也是GNU项目的关键部分,也是GNU工具链的主要组成部分之一。GCC(特别是其中的C语…
如何正确选择聚类算法? | CSDN博文精选
作者 | Josh Thompson翻译 | 张睿毅校对 | 王雨桐来源 | 数据派THU(ID:DatapiTHU)本文将介绍四种基本的聚类算法—层次聚类、基于质心的聚类、最大期望算法和基于密度的聚类算法,并讨论不同算法的优缺点。聚类算法十分容易上手,但…