一文读懂GoogLeNet神经网络 | CSDN博文精选

本文介绍的是著名的网络结构GoogLeNet,目的是试图领会其中结构设计思想。
GoogLeNet特点
优化网络质量的生物学原理
GoogLeNet网络结构的动机
GoogLeNet架构细节
Inception模块和普通卷积结构的差异
辅助分类器
GoogLeNet网络架构
GoogLeNet训练以及样本预处理
GoogLeNet测试以及测试样本处理
GoogLeNet检测+分类
MultiBox方法
SelectiveSearch方法
Inception,来源于论文Network in Network和电影Inception中的台词:we need to go deeper。GoogLeNet在2014年的ImageNet比赛中获得第一名。
GoogLeNet特点
1.此网络架构的主要特点就是提升了对网络内部计算资源的利用。
2.增加了网络的深度和宽度,网络深度达到22层(不包括池化层和输入层),但没有增加计算代价。
3.参数比2012年冠军队的网络少了12倍,但是更加准确。
4.对象检测得益于深度架构和传统的计算机视觉算法(R-CNN)。
优化网络质量的生物学原理
基于赫布原理和多尺度处理。
赫布原理:突触前神经元向突触后神经元的持续重复的刺激可以导致突触传递效能的增加。赫布理论有下列的特性:
1.知觉获知是在神经系统中的表征是一群而不是一个细胞,因此这是一个较为分散的表征系统。表征不同的心智活动,并不完全系于细胞的独特身分,因为一个细胞可同时参与几个细胞集团。
2.在细胞集合中,无论是组成分子或是联络通路,均有相当程度的余裕性,所以容许神经系统有部分的破坏,依然能执行所负担的功能。同时这些平行通路可容许由不同的部位到达兴奋全体的目的。
3.细胞集合的成立虽然依赖连结,但连结的成果并非使刺激直通于反应,而是在中枢建立一个有缓冲作用(使刺激的影响能盘桓较久)的回路。
4.人的大脑神经元运作的方式的确和原子内粒子的运作方式类似,人类的大脑的确是所有神经网络的总和。每个神经元本身并不重要,重要的是这些神经元怎么联合起来,联合起来可以做些什么事,这才是的细胞集合的核心。
GoogLeNet网络结构的动机
提高网络性能最直接的方法就是增加网络的尺寸(深度和宽度)这样会带来两个问题:
扩大后的网络含有大量的参数,容易产生过拟合,大量的带标签的训练样本不容易得到。
扩大后的网络要消耗大量的计算资源。
解决这两个问题的基本方法:将全连接变成稀疏连接,包括卷积层。即Dropout理论,符合赫布原理,在非严格条件下,实际上是可行的。同时GoogLeNet还参考了以下方法:
1.CNN典型的结构:一堆卷积层+若干全连接层。
2.针对大规模数据集问题,现在的趋势是增加层数和层的尺寸,并且使用dropout解决过拟合问题。
3.使用Max Pool和Average Pool。
4.使用Network in Network方法,增加网络的表现能力,这种方法可以看做是一个额外的1*1卷积层再加上一个ReLU层。NIN最重要的是降维,解决了计算瓶颈,从而解决网络尺寸受限的问题。这样就可以增加网络的深度和宽度了,而且不会有很大的性能损失。
5.当前最好的对象检测方法是R-CNN。R-CNN将检测问题分解为两个子问题:首先利用低级特征(颜色和超像素一致性)在分类不可知时寻找潜在目标,然后使用CNN分类器识别潜在目标所属类别。GoogLeNet在这两个阶段都进行了增强效果。
GoogLeNet架构细节
Inception模块和普通卷积结构的差异
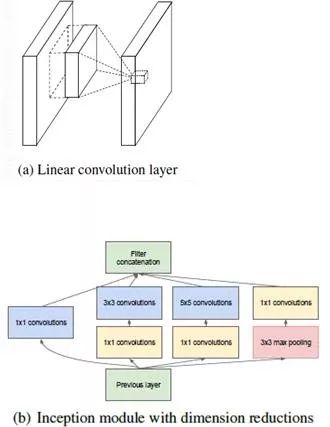
图(a)是传统的多通道卷积操作,图(b)是GoogLeNet中使用的Inception模块,两者的区别在于:
Inception使用了多个不同尺寸的卷积核,还添加了池化,然后将卷积和池化结果串联在一起。
卷积之前有1×1的卷积操作,池化之后也有1×1的卷积操作。
Inception模块中的多尺寸卷积核的卷积卷积过程和普通卷积过程不同。
第一点不同的原因是:Inception的主要思想就是如何找出最优的局部稀疏结构并将其覆盖为近似的稠密组件,这里就是将不同的局部结构组合到了一起。
第二点不同的原因是:原始的卷积是广义线性模型GLM(generalized linear model),GLM的抽象等级较低,无法很好的表达非线性特征,这种1×1的卷积操作将高相关性的节点聚集在一起。什么是高相关性节点呢?两张特征图中相同位置的节点就是相关性高的节点。假设当前层的输入大小是28×28×256,卷积核大小为1×1×256,卷积得到的输出大小为28×28×1。可以看出这种操作一方面将原来的线性模型变成了非线性模型,将高相关性节点组合到了一起,具有更强的表达能力,另一方面减少了参数个数。举个例子:
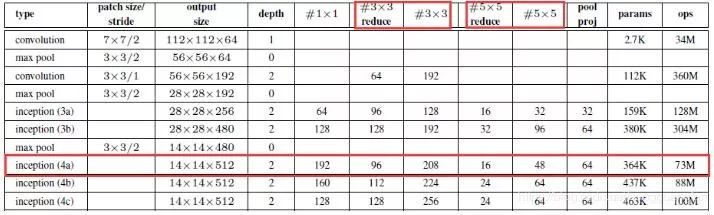
假设将Inception(4a)换成传统的3×3卷积,那么转换前后的参数个数对比如下:
3×3卷积的参数个数是512×3×3×480=2211840,Inception的参数个数是192×1×1×480 + 96×1×1×480 + 208×3×3×96 + 16×1×1×480 + 48×5×5×16 + 64×1×1×480 = 536064。Inception结构的参数个数明显比普通卷积结构的少了很多。
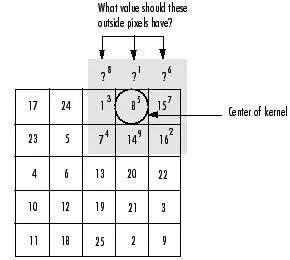
第三点不同体现在:卷积核与接受域对齐方式不同。图3左是普通卷积过程,其对齐方式是让卷积核的左上角和接受域的左上角对齐,这种对齐方式卷积核始终在接受域的内部,不会跑到接受域的外部。图3右是GoogLeNet使用的卷积过程,其对齐方式是让卷积核的中心和接受域的左上角对齐,这种对齐方式卷积核可能会跑到接受域的外部,此时接受域外部和卷积核重合的部分采取补0的措施。GoogLeNet卷积方式使得步长是1的卷积得到的输出大小和输入大小一致。

辅助分类器
根据实验数据,发现神经网络的中间层也具有很强的识别能力,为了利用中间层抽象的特征,在某些中间层中添加含有多层的分类器。如下图所示,红色边框内部代表添加的辅助分类器。
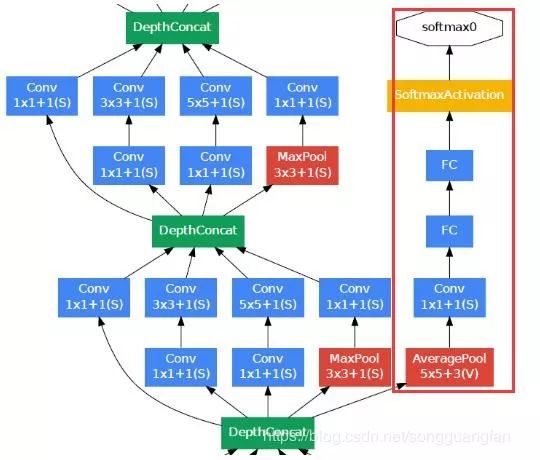
GoogLeNet网络架构
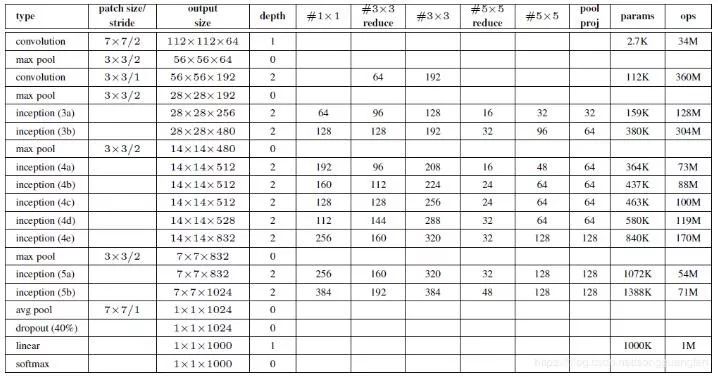
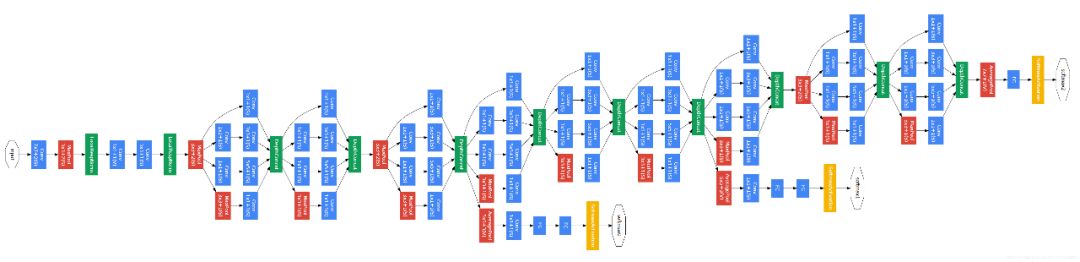
第一幅图是GoogLeNet基本结构,第二幅图是添加了辅助分类器的结构。
GoogLeNet神经网络中,使用了前两节提到的Inception模块和辅助分类器,而且由于全连接网络参数多,计算量大,容易过拟合,所以GoogLeNet没有采用AlexNet(2012年ImageNet冠军队使用的网络结构,前五层是卷积层,后三层是全连接层)中的全连接结构,直接在Inception模块之后使用Average Pool和Dropout方法,不仅起到降维作用,还在一定程度上防止过拟合。
在Dropout层之前添加了一个7×7的Average Pool,一方面是降维,另一方面也是对低层特征的组合。我们希望网络在高层可以抽象出图像全局的特征,那么应该在网络的高层增加卷积核的大小或者增加池化区域的大小,GoogLeNet将这种操作放到了最后的池化过程,前面的Inception模块中卷积核大小都是固定的,而且比较小,主要是为了卷积时的计算方便。
第二幅图中蓝色部分是卷积块,每个卷积块后都会跟一个ReLU(受限线性单元)层作为激活函数(包括Inception内部的卷积块)
GoogLeNet训练以及样本预处理
1. 训练7个GoogLeNet模型,其中包含一个加宽版本,其余6个模型初始化和超参数都一样,只是采样方法和样本顺序不同。
2. 采用模型和数据并行技术,用几个高端GPU训练一周可得到收敛(估算)。
3. 多个模型的训练是不同步的,超参数的变化也是不一样的,比如dropout和学习率
4. 有些模型主要训练小尺寸样本,有些模型训练大尺寸样本。
5. 采样时,样本尺寸缩放从8%到100%,宽高比随机选取3/4或4/3(多尺度)
6. 将图像作光度扭曲,也就是随机更改图像的对比度,亮度和颜色。这样可以增加网络对这些属性的不变性。
7. 使用随机插值方法重置图像尺寸(因为网络输入层的大小是固定的),使用到的随机插值方法:双线性插值,区域插值,最近邻插值,三次方插值,这些插值方法等概率的被选择使用。图像放大时,像素也相应地增加 ,增加的过程就是“插值”程序自动选择信息较好的像素作为增加的像素,而并非只使用临近的像素,所以在放大图像时,图像看上去会比较平滑、干净。
8. 改变超参数(反向传播若干次之后改变超参数,或者误差达到某阈值时改变超参数)。
GoogLeNet测试以及测试样本处理
1. 对于一个测试样本,将图像的短边缩放成4种尺寸,分别为256,288,320,352。
2. 从每种尺寸的图像的左边,中间,右边(或者上面,中间,下面)分别截取一个方形区域。
3. 从每个方形区域的4个拐角和中心分别截取一个224×224区域,再将方形区域缩小到224×224,这样每个方形区域能得到6张大小为224×224的图像,加上它们的镜像版本(将图像水平翻转),一共得到4×3×6×2=144张图像。这样的方法在实际应用中是不必要的,可能存在更合理的修剪方法。下图展示了不同修剪方法和不同模型数量的组合结果:
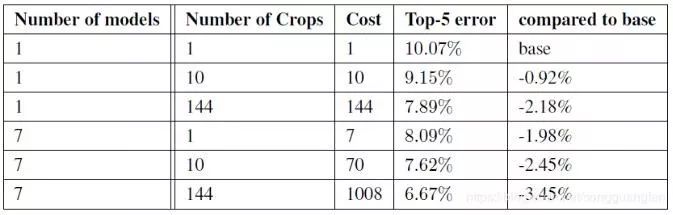
在论文《Some improvements on deep convolutional neural network based image classification》提到了用贪心算法只要10到15个修剪样本就可以了。
每个模型的Softmax分类器在多个修剪图片作为输入时都得到多个输出值,然后再对所有分类器的softmax概率值求平均。
GoogLeNet检测+分类
检测方法使用SelectiveSearch+MultiBox (Google),主要是为了获取可能含有对象的候选区域,分类方法使用上述提到的GoogLeNet神经网络。
MultiBox方法
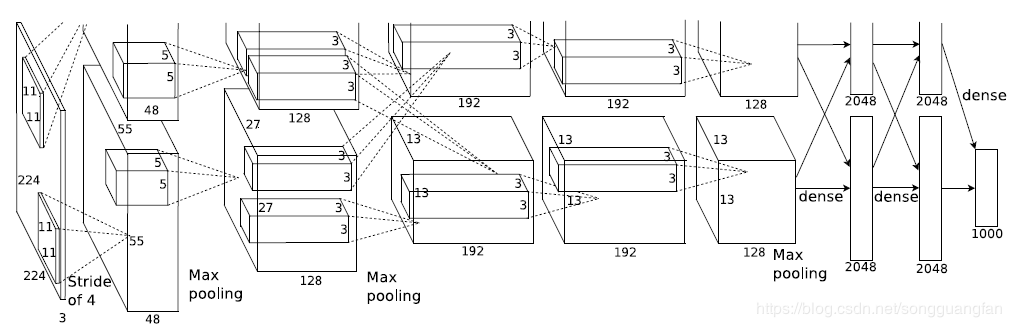
1. 将AlexNet(如图8)的最后一层改为输出k个边界框和k个置信度。
2. 边界框编码为四个节点值,分别是边界框的左上顶点和右下顶点的相对坐标。
3.置信度是为这个边界框打分,表示该边界框含有目标的可能性,这里k=200。
4. 位置损失函数:
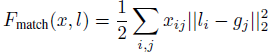
如果第i个预测框对应第j个目标,那么xij=1,否则为0。
5. 置信度损失函数(逻辑回归)
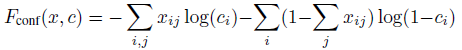
如果第i个预测框和某一个目标匹配,那么 。
6. 最终的损失函数为:

SelectiveSearch方法
将超像素尺寸改为原来的2倍,这样生成的候选框减少一半。此处并非严格的将超像素尺寸扩大1倍,而是在超像素合并过程中删除掉一半被合并的像素。


第一幅图是SelectiveSearch的合并效果图,第二幅图是SelectiveSearch合并算法伪代码。
假设R初始时有k个区域,合并两个区域时删除被合并的两个区域,直到R中只有k/2个区域时,执行正常的合并操作,不再删除候选区域。这样生成的候选框比原始SelectiveSearch算法生成的候选框数量少一半。
通过MultiBox和SelectiveSearch方法得到一系列的候选框,将这些候选框输入到GoogLeNet神经网络中进行分类,得到最终的结果。
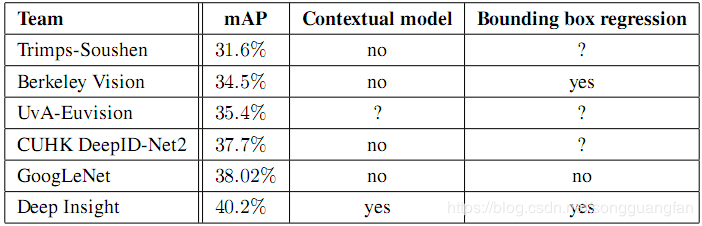
检测分类的性能:
1.单个模型性能:
2. 综合性能
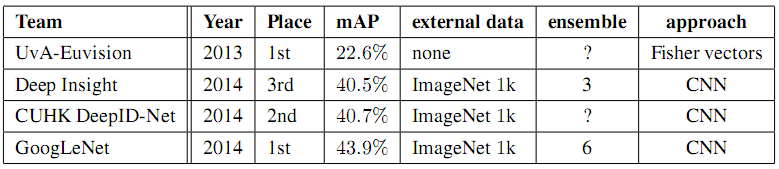
GoogLeNet单个模型的分类性能比Deep Insight差2个百分点,6个模型放在一起平均之后的性能比Deep Insight高了3个百分点。

(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
即日起,限量 5 折票开售,数量有限,扫码购买,先到先得!

推荐阅读
张俊林:BERT和Transformer到底学到了什么 | AI ProCon 2019
哪些开发问题最让程序员“头秃”?我们分析了Stack Overflow的11000个问题
一站式解决:隐马尔可夫模型(HMM)全过程推导及实现
Python识别文字,实现看图说话 | CSDN博文精选
确认!语音识别大牛Daniel Povey将入职小米,曾遭霍普金斯大学解雇,怒拒Facebook
不足 20 行 Python 代码,高效实现 k-means 均值聚类算法
巨头垂涎却不能染指,loT 数据库风口已至
【建议收藏】数据中心服务器基础知识大全
身边程序员同事竟说自己敲代码速度快!Ctrl+C、Ctrl+V ?
100 美元一行代码,开源软件到底咋赚钱?

你点的每个“在看”,我都认真当成了AI
相关文章:

C++中的函数签名
C中的函数签名(function signature):包含了一个函数的信息,包括函数名、参数类型、参数个数、顺序以及它所在的类和命名空间。普通函数签名并不包含函数返回值部分,如果两个函数仅仅只有函数返回值不同,那么系统是无法区分这两个函…

MyEclipse断点调试
2019独角兽企业重金招聘Python工程师标准>>> 1、在编辑的程序的左边,你会看到一条浅浅的灰色编带,在这里设置断点。 2、设置断点的方法有很多 方法:1)、双击 ; 2)、右键,选择“Toggl…
C primer plus 练习题 第三章
5. 1 #include <stdio.h>2 3 int main()4 {5 float you_sec;6 printf("请输入你的年龄:");7 scanf("%f", &you_sec);8 printf("年龄合计:%e 秒!\n", you_sec * 3.156e7);9 getchar(); 10 return 0; 11 }
Echache整合Spring缓存实例讲解
2019独角兽企业重金招聘Python工程师标准>>> 摘要:本文主要介绍了EhCache,并通过整合Spring给出了一个使用实例。 一、EhCache 介绍 EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的C…
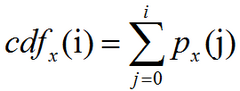
灰度图像直方图均衡化公式及实现
图像的直方图:直方图是图像中像素强度分布的图形表达方式。它统计了每一个强度值所具有的像素个数。直方图均衡化:是通过拉伸像素强度分布范围来增强图像对比度的一种方法。是图像处理领域中利用图像直方图对对比度进行调整的方法。均衡化指的是把一个分…
超越最新无监督域自适应方法,研究人员提轻量CNN新架构OSNet
作者 | Kaiyang Zhou, Xiatian Zhu, Yongxin Yang, Andrea Cavallaro, and Tao Xiang 译者 | TroyChang 编辑 | Jane 出品 | AI科技大本营(ID:rgznai100) CNN新架构OSNet 【导读】今天推荐论文《Learning Generalisable Omni-Scale Repre…
在一台机器上搭建多个redis实例
2019独角兽企业重金招聘Python工程师标准>>> 默认Redis程序安装在/usr/local/redis目录下; 配置文件:/usr/local/redis/redis.conf,该配置文件中配置的端口为默认端口:6379; Redis的启动命令路径࿱…
使用kaptcha生成验证码
2019独角兽企业重金招聘Python工程师标准>>> kaptcha是一个简单好用的验证码生成工具,通过配置,可以自己定义验证码大小、颜色、显示的字符等等。下面就来讲一下如何使用kaptcha生成验证码以及在服务器端取出验证码进行校验。 一、搭建测试环…

主成分分析(PCA) C++ 实现
主成分分析(Principal Components Analysis, PCA)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78977202以下是PCA的C实现,参考OpenCV 3.3中的cv::PCA类。使用ORL Faces Database作为测试图像。关于ORL Faces Database的介绍可以参…
为何Google、微软、华为将亿级源代码放一个仓库?从全球最大代码管理库说起...
作者 | 夕颜编辑 | Just出品 | AI 科技大本营(ID:rgznai100)【导读】2017 年,在当时微软的一篇官方博客中,时任微软云开发服务副总裁的 Brian Harry 表示微软内部代码开始向 Git 迁移,宣布推出针对大规模 repo 的“Git…
jquery mobie导致超链接不可用
在a标签中添加rel"external"即可转载于:https://blog.51cto.com/here2142/1435434
编译器GCC与Clang的异同
GCC:GNU(Gnus Not Unix)编译器套装(GNU Compiler Collection,GCC),指一套编程语言编译器,以GPL及LGPL许可证所发行的自由软件,也是GNU项目的关键部分,也是GNU工具链的主要组成部分之一。GCC(特别是其中的C语…
如何正确选择聚类算法? | CSDN博文精选
作者 | Josh Thompson翻译 | 张睿毅校对 | 王雨桐来源 | 数据派THU(ID:DatapiTHU)本文将介绍四种基本的聚类算法—层次聚类、基于质心的聚类、最大期望算法和基于密度的聚类算法,并讨论不同算法的优缺点。聚类算法十分容易上手,但…
Python工具 | 9个用来爬取网络站点的 Python 库
1️⃣Scrapy 一个开源和协作框架,用于从网站中提取所需的数据。 以快速,简单,可扩展的方式。 官网2️⃣cola 一个分布式爬虫框架。 GitHub3️⃣Demiurge 基于 PyQuery 的爬虫微型框架。 官网4️⃣feedparser 通用 feed 解析器。 官网5️⃣Gra…
Python并发编程实例教程
有关Python中的并发编程实例,主要是对Threading模块的应用,文中自定义了一个Threading类库。 一、简介 我们将一个正在运行的程序称为进程。每个进程都有它自己的系统状态,包含内存状态、打开文件列表、追踪指令执行情况的程序指针以及一个保存局部变量的调用栈。…
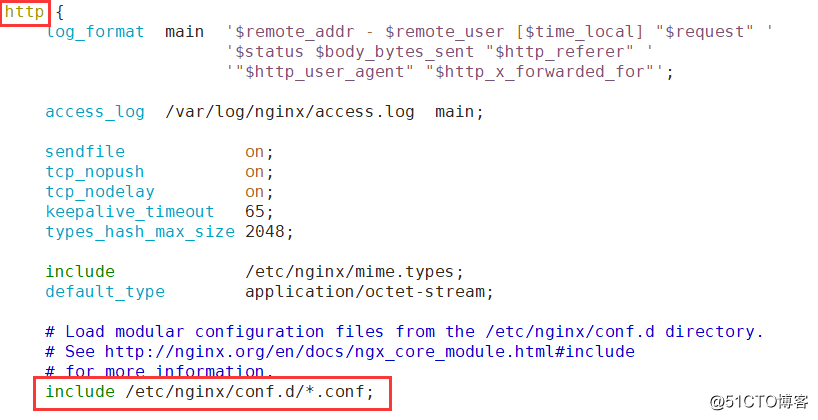
Nginx负载均衡之TCP端口高可用(二)
在前面我们实现了基本的HTTP反向代理,从互联网过来的请求已经可以分发到后端多台网站服务器上,但不是所有的业务都是网络类型的,此篇文章我们主要讨论的是TCP 端口的负载均衡做法,昨天也有小伙伴提到了,在HTTP反向代理…
语音识别大牛Daniel Povey为何加入小米?“手机+AIoT”强大生态,开源战略是关键...
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)10 月 17 日,语音识别开源工具 Kaldi 创始人,语音和 AI 领域大牛 Daniel Povey 在10 月 19 日,小米集团副总裁、集团技术委员会主席崔宝秋发布微博,欢迎 Dani…
Python运维项目中用到的redis经验及数据类型
先感叹下,学东西一定要活学活用! 我用redis也有几年的历史了,今个才想到把集合可以当python list用。 最近做了几个项目都掺杂了redis, 遇到了一些个问题和开发中提高性能的方法,这都分享出来,共同学习。…
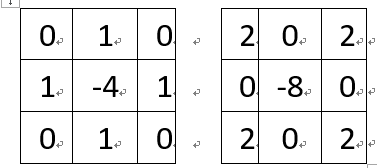
图像边缘检测之拉普拉斯(Laplacian)C++实现
拉普拉斯算子(Laplacian)可应用到图像边缘检测中。在OpenCV中当kernel大小为3*3时,支持两种kernel算子,分别为:在OpenCV中默认的计算方式如下,假设有一个5*5的小图像,原始值依次为1,2,…25,如下图红色部分,…
从0到1,Airbnb的深度学习实践经验总结
作者 | Haldar译者 | 陆离出品 | AI科技大本营(ID: rgznai100)此前,AI科技大本营发布了关于希望通过介绍的研究成果为读者提供一些有用的帮助和指引。模型中的生态系统本文要讨论的机器学习现实应用,是关于根据用户预约的可能性来…
高并发大流量专题---8、动态语言的并发处理
高并发大流量专题---8、动态语言的并发处理 一、总结 一句话总结: 和本科毕业论文连起来了:基于消息中间件Rocket MQ的研究;用于并发处理的消息队列 1、什么是进程、线程、协程? 进程(Process)是计算机中的…

1. 文件系统——磁盘分区、各目录功能、硬盘
一、磁盘分区及文件访问入口在前文中介绍过,Linux的整个文件系统像一棵倒置的数,最顶层的是根文件系统,其下有很多一级子目录,一级子目录下面是二级子目录,依此类推:/:根目录/bin,/s…

吴恩达老师深度学习视频课笔记:逻辑回归公式推导及C++实现
逻辑回归(Logistic Regression)是一个二分分类算法。逻辑回归的目标是最小化其预测与训练数据之间的误差。为了训练逻辑回归模型中的参数w和b,需要定义一个成本函数(cost function)。成本函数(cost function):它是针对整个训练集的。衡量参数w和b在整个训…
网络运行时间提高100倍,Google使用的AI视频理解架构有多强?
译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)视频理解是一个很有挑战性的问题。由于视频包含时空数据,因此图像的特征表示需要同时提取图像和运动信息。这不仅对自动理解视频语义内容有重要性,还对机器人的感知和学习也至关重要…
iOS学习笔记(十三)——获取手机信息(UIDevice、NSBundle、NSLocale)
2019独角兽企业重金招聘Python工程师标准>>> iOS的APP的应用开发的过程中,有时为了bug跟踪或者获取用反馈的需要自动收集用户设备、系统信息、应用信息等等,这些信息方便开发者诊断问题,当然这些信息是用户的非隐私信息࿰…

吴恩达老师深度学习视频课笔记:单隐含层神经网络公式推导及C++实现(二分类)
关于逻辑回归的公式推导和实现可以参考: http://blog.csdn.net/fengbingchun/article/details/79346691 下面是在逻辑回归的基础上,对单隐含层的神经网络进行公式推导:选择激活函数时的一些经验:不同层的激活函数可以不一样。如果…

「2019中国大数据技术大会」超值学生票来啦!
大会官网:https://t.csdnimg.cn/U1wA经过11年的沉淀与发展,中国大数据技术大会见证了大数据技术生态在中国的建立、发展和成熟,已经成为国内大数据行业极具影响力的盛会,也是大数据人非常期待的年度深度分享盛会。在新的时代背景下…
校验正确获取对象或者数组的属性方法(babel-plugin-idx/_.get)
背景: 开发中经常遇到取值属性的时候,需要校验数值的有效性。 例如: 获取props对象里面的friends属性 props.user && props.user.friends && props.user.friends[0] && props.user.friends[0].friends 对于深层的对…
Ring Tone Manager on Windows Mobile
2019独角兽企业重金招聘Python工程师标准>>> 手机铃声经常能够体现一个人的个性,有些哥们儿在自习室不把手机设置成震动,一来电就#$^%^&^%#$&$*,声音还很大,唯恐别人听不到。 Windows Mobile设备上如何来设置手…

OpenCV3.3中K-Means聚类接口简介及使用
OpenCV3.3中给出了K-均值聚类(K-Means)的实现,即接口cv::kmeans,接口的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/kmeans.cpp文件中,其中:下面对此接口中的参数作个简单说明:(1)、data:…