CV02-FCN笔记
目录
一、Convolutionalization 卷积化
二、Upsample 上采样
2.1 Unpool反池化
2.2 Interpolation差值
2.3 Transposed Convolution转置卷积
三、Skip Architecture
3.1 特征融合
3.2 裁剪
FCN原理及实践,记录一些自己认为重要的要点,以免日后遗忘。
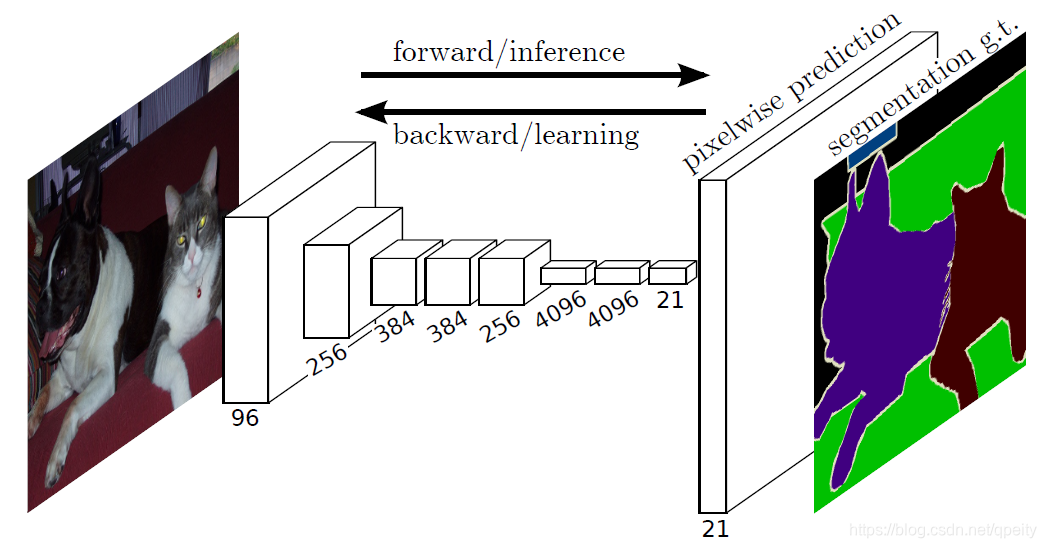
原始思路是,去掉全连接层,全部改为卷积操作。保持图片spatial大小做Dense Prediction,就需要做same卷积,也就是加padding。如果一直保持图片spatial大小不变,那么计算量巨大。
FCN的思路是,特征提取阶段图像spatial减小,图像分类阶段把特征通过upsample方式放大到原来图像大小。再通过融合过程中的数据(保持位置信息)来提高推断的准确率。
FCN的三个重点:Convolutionalization卷积化、Upsample上采样、Skip Architecture。
参考实现:https://github.com/wkentaro/pytorch-fcn/tree/master/torchfcn/models
自己的实现:https://github.com/Ascetics/LaneSegmentation/tree/master/nets
一、Convolutionalization 卷积化
原有的分类网络,特征提取阶段用卷积,图像分类阶段用全连接。输入的spatial大小是固定的。
以VGG16为例,输入是固定大小3×224×224,经过5个阶段的卷积、池化(每次spatial缩小一半),最终得到512×7×7的输出。这个512×7×7做flatten以后变成一维向量,再做后面全连接操作,映射到4096个神经元。

FCN特征提取阶段用卷积,不用全连接层,这就是卷积化操作。注意,卷积化得到的是Coarse Output,这并不能将图像放大到原来的大小。FCN的输入是任意大小的。
用FCN改造VGG16,如果输入图像CHW=3×224×224,经过5个阶段的卷积、池化(每次spatial缩小一半),得到512×7×7的输出。然后,不连全连接层,改为继续连接卷积操作。卷积核是7×7的,out_channel=4096,那么经过这个卷积以后得到4096×1×1的输出。考虑维数为1的维度可以移除,这样结果就和VGG16的结果是一样的。
如果输入图像的spatial比224×224更大,那么经过上述过程,最终的输出是4096××
,就变成了下图第二行的情况。输出就变成了一个heatmap,heatmap的大小就是
×
。
如果输入图像的spatial比224×224更小,那么怎么保证最后输出不小于7×7,不影响后面的卷积操作呢?办法就是第一次卷积加padding=100,这样就保证输出不小于7×7。

二、Upsample 上采样
特征提取也被称为下采样。上采样与其相反,将小的图像上采样变成大的图像。
上采样有三种方法
- Unpool反池化
- Interpolation差值
- Transposed Convolution转置卷积
FCN里面上采样采用Transposed Convolution转置卷积。
2.1 Unpool反池化
Unpool反池化;torch的API为
torch.nn.MaxUnpool1d
torch.nn.MaxUnpool2d
torch.nn.MaxUnpool3d反池化操作要依赖池化操作。在池化操作的时候,要记录池化数据的位置信息(torch.nn.MaxPool2d里面的return_indices=True),在根据这个位置信息(indices)将池化数据返回到原有位置,上采样的空白位置补0,也就是说反池化只能恢复部分信息。

2.2 Interpolation差值
Interpolation差值;torch的API为
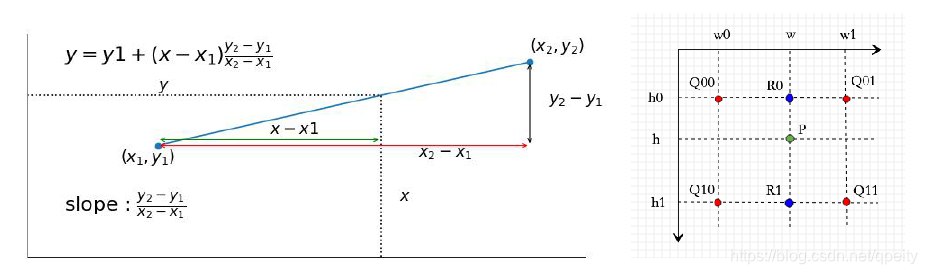
torch.nn.functional.interpolate()差值就是用已知的点来估计未知点的值。常用线性差值、双线性差值、最近差值等……其中,线性差值就是用两个点之间的斜率来估算中间插入的点。平面上用双线性差值,也就是用周边4个点来估计插入的点,在另外一篇双线性差值博客中单独分析。差值根据斜率计算,因此不需要机器学习。
2.3 Transposed Convolution转置卷积
Transposed Convolution转置卷积;torch的API为
torch.nn.ConvTranspose1d
torch.nn.ConvTranspose2d
torch.nn.ConvTranspose3d如果想上采样N倍,有多种实现方式。其中一种,就是ConvTranspose2d的参数设置为kernel_size=2N,stride=N,就可以上采样N倍。下面举例就是上采样32倍。
upsample = nn.ConvTranspose2d(in_channels=num_class,out_channels=num_class,kernel_size=64,stride=32,bias=False
)先想想卷积可以做全连接操作。如图,输入4×4,经过3×3的卷积,输出2×2。将4×4的输入变成一个16×1的向量,要输出是4×1的向量,那么就是在16×1的向量上乘以一个4×16的矩阵即可,矩阵的元素就是3×3卷积的权重。

那么,反过来,输入2×2,能否用一个3×3的卷积操作让输出4×4呢?把输入2×2变成4×1的向量,乘以16×4的矩阵,输出16×1的向量。这个16×4的矩阵元素就来自转置卷积核。

转置卷积只能恢复位置(维度)的大小,但是不能恢复信息,想要恢复信息要通过学习。
三、Skip Architecture
3.1 特征融合
实验发现,如果直接上采样效果不好,原因是多层卷积使位置信息损失太多。解决办法是,将丢失的信息补充进来。特征融合有多种方式,一种是在维度一致的情况直接相加,另一种是在spatial维度一致的情况下对channel进行concatenate。

这里就用到了Skip Architecture来做特征融合,用到的就是直接相加的方式。根据不同的融合内容可以有FCN32s、FCN16s、FCN8s和FCN4s等。这里的NNs表示上采样多少倍进行融合。
FCN32s就是不进行特征融合,直接将卷积结果上采样32倍。
FCN16s就是将卷积结果上采样2倍,加上1/16的卷积结果;融合以后再上采样16倍。
FCN8s就是将卷积结果上采样2倍,加上1/16的卷积结果;融合以后再上采样2倍,加上1/8的卷积结果;融合以后再上采样8倍。
以此类推……

实验结论是FCN8s的效果最好。为什么FCN4s融合了更浅层、信息损失更少的层,结果不应该比FCN4s更好吗?事实上,FCN4s较FCN8s的提高微乎其微,计算量却大大增加。
3.2 裁剪
特征融合实际上就是再做加法,张量加法要求维数一致才能相加。由于卷积、池化和上采样操作,导致融合时张量维数不一致的情况。为此需要对融合的部分进行剪裁,剪裁成维数一致。下表就记录了各层之间维度的计算关系。
表第一列是卷积层。
表第一行是表头,scale之前的表示每层参数,scale之后的表示上采样的模式和剪裁的大小。in表示输入图片大小;K表示该层卷积核大小;S表示该层stride;P表示该层padding大小;out表示该层卷积输出大小;pool表示该层池化输出大小;scale表示下采样是输入的多少分之一;32s、16s、8s表示FCN32s、FCN16s、FCN8s上采样输出大小,32s_crop、16s_crop、8s_crop表示上采样输出应剪裁大小(整数表示剪裁上采样,负数表示剪裁池化输出);
因为下采样只是一般卷积操作,下采样输出与输入的关系是
上采样采用转置卷积没有padding等,上采样输出与输入的关系是
我们以FCN16s为例,说明计算过程。
FCN16s下采样过程。已知下采样所有层的K、S、P、pool的大小,注意下一层输入的大小是上一层pool输出的大小,如果输入为i,经过8层卷积、池化等层,表中scale前面的内容都可以得到。
FCN16s上采样过程。输入,转置卷积上采样2倍,S=2,K=4,带入上采用公式得到输出是
,spatial大小比pool输出
小10。pool输出经过1×1卷积使channel与2倍上采样结果一致,pool输出两边各裁剪掉5。裁剪后入2倍上采样大小都是
,相加融合。融合结果转置卷积上采样16倍,S=16,K=32,带入上采样公式输出是
,spatial比输入i大54。因此,上采样结果两边各裁剪掉27。
| in | K | S | P | out | pool | scale | 32s | 32s_crop | 16s | 16s_crop | 8s | 8s_crop | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| conv1 | |||||||||||||
| conv2 | ↑×32 k=64 s=32 | ↑×16 k=32 s=16 | ↑×8 k=16 s=8 | ||||||||||
| conv3 | |||||||||||||
| conv4 | |||||||||||||
| conv5 | ↑×2 k=4 s=2 | ↑×2 k=4 s=2 | |||||||||||
| fc6 | 无 | ||||||||||||
| fc7 | 无 | ||||||||||||
| fc8 | 无 |
相关文章:

python基础之常用模块
6、TEXT PROCESSING SERVICES :文本处理服务 6.1、re 8、DATA TYPES : 数据类型 8.1、datetime 8.2、collections 8.3、copy 9、 NUMERIC AND MATHEMATICAL MODULES : 数字和数学模块 9.1、random 10、FUNCTIONAL PROGRAMMING MODULES : 函数式编程模块 10.1、iter…
笔记本电脑摄像头实现光流跟踪
看实验室里的师兄在写CSDN,自己也写一个,记录自己的学习进程吧。 研究生从机械转到了毫无基础的SLAM领域。研一半年上课加自学,对SLAM也有一丢丢的了解。最近看光流法时,想到用笔记本电脑的摄像头实现一下,就简单的…
JSON字符串 拼接与解析
常用方式: json字符串拼接(目前使用过两种方式): 1.运用StringBuilder拼接 StringBuilder json new StringBuilder(); json.append("{"); json.append(""uuid":" """ uuid "",&q…
iOS SwiftUI篇-3 排版布局layout
iOS SwiftUI篇-3 排版布局layout swiftUI提供的layout有: ZStack、GeometryReader、HStack、LazyVGrid、LazyHStack、LazyHGrid、LazyVStack、VStack、Spacer、ScrollViewReader等 HStack 水平横向布局容器,子view按顺序水平排列 HStack(alignment: .center, spacing: 10)…
CV04-UNet笔记
目录 一、UNet模型 二、Encoder & Decoder 2.1 Encoder 2.2 Decoder 2.3 classifier 学习U-Net: Convolutional Networks for Biomedical Image Segmentation,记录一些自己认为重要的要点,以免日后遗忘。 代码:https://github.com/…
Scrapy 学习笔记(-)
Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 A…
Ubuntu18.04运行ORB_SLAM2
运行环境:Ubuntu18.04 预先安装的库 需要预先安装一些库,如Eign,Sophus,OpenCV等。笔者在阅读《SLAM十四讲》的时候已经安装,在此不再赘述。 ORB_SLAM2源码的下载与编译 git clone https://github.com/raulmur/ORB…
java中的各种流(老师的有道云笔记)
内存操作流-字节之前的文件操作流是以文件的输入输出为主的,当输出的位置变成了内存,那么就称为内存操作流。此时得使用内存流完成内存的输入和输出操作。如果程序运行过程中要产生一些临时文件,可采用虚拟文件方式实现;直接操作磁…
iOS SwiftUI篇-4 注解@State、@Binding、@ObservedObject、@EnvironmentObject、@Environment
iOS SwiftUI篇-4 注解@State、@Binding、@ObservedObject、@EnvironmentObject、@Environment @State 关联View的状态,当@State修饰的属性改变时,对应的View会跟着刷新,符合MVVM的设计理念 @State var count: Int = 0Section(header: Text("@States")) {Te
CV05-ResNet笔记
目录 一、为什么是ResNet 二、Residual Learning细节 2.1 shortcut计算 2.2 11卷积调整channel维度大小 2.3 ResNet层数 2.4 ResNet里的Basic Block 和 Bottleneck Block 2.5 Global Average Pooling 全局平均池化 2.6 Batch Normalization 学习ResNet,记录…
二叉树的前序,中序,后序的递归、迭代实现
二叉树的前序遍历 递归实现 递归实现没什么好说的。个人感觉将函数功能看成一个整体,不要去想栈中怎么实现的。毕竟自己的脑袋不是电脑,绕着绕着就蒙了。 void preordered_traversal_recursion(TreeNode* root) {if(root NULL) return;container.pus…
DataSet 动态添加列
public DataSet GetNewId(List<string> IdArr){DataSet ds new DataSet();DataTable newtb new DataTable();DataColumn column new DataColumn("cnt", typeof(string));//新增列newtb.Columns.Add(column);for (int i 0; i < IdArr.Count; i){StringBu…
iOS专题1-蓝牙扫描、连接、读写
iOS专题1-蓝牙扫描、连接、读写 概念 外围设备 可以被其他蓝牙设备连接的外部蓝牙设备,不断广播自身的蓝牙名及其数据,如小米手环、共享单车、蓝牙体重秤 中央设备 可以搜索并连接周边的外围设备,并与之进行数据读写通讯,如手机 日常生活中常见的场景是手机app通过蓝…
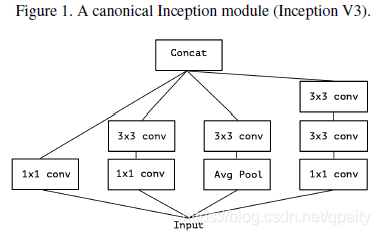
CV06-Xception笔记
目录 一、为啥是Xception 二、Xception结构 2.1 Xception结构基本描述 2.2 实现细节 2.3 DeepLabV3改进 三、记录pytorch采坑relu激活函数inplaceTrue Xception笔记,记录一些自己认为重要的要点,以免日后遗忘。 复现Xception论文、DeepLabV改进的…
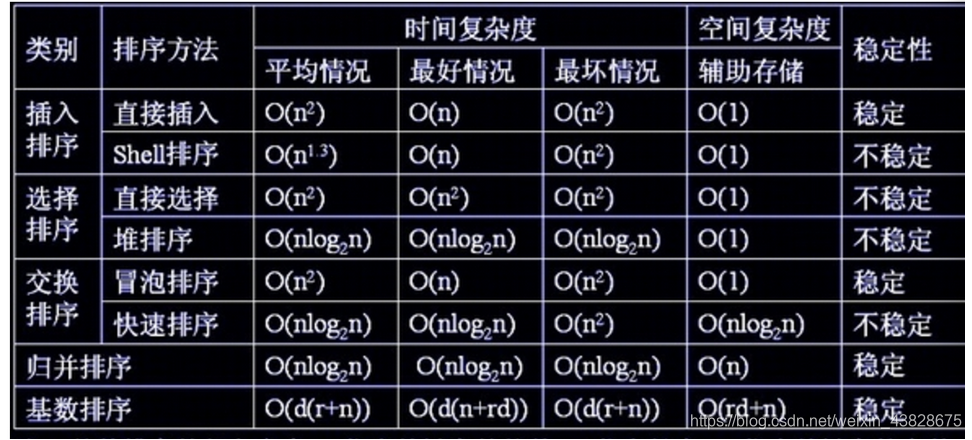
C++排序算法实现(更新中)
比较排序法:如冒泡排序、简单选择排序、合并排序、快速排序。其最优的时间复杂度为O(nlogn)。 其他排序法:如桶排序、基数排序等。时间复杂度可以达到O(n)。但试用范围有要求。 桶排序:排序的数组元素跨距不能很大。因为跨距很大的话…
iOS SwiftUI篇-5 专题NavigationView、NavigationLink
iOS SwiftUI篇-5 专题NavigationView、NavigationLink NavigationView:标题、展示模式、隐藏导航栏、隐藏返回按钮、添加导航栏按钮 NavigationLink:Text文本跳转、Image图片跳转、Button按钮跳转、点击按钮根据业务跳转到不同页面 NavigationView 标题、展示模式 import S…
PHP artisan
Artisan 是 Laravel 提供的 CLI(命令行接口),它提供了非常多实用的命令来帮助我们开发 Laravel 应用。前面我们已使用过 Artisan 命令来生成应用的 App Key 和控制器。在本教程中,我们会用到以下 Artisan 命令,你也可以…
【转载】Pytorch在加载模型参数时指定设备
转载 https://sparkydogx.github.io/2018/09/26/pytorch-state-dict-gpu-to-cpu/ >>> torch.load(tensors.pt) # Load all tensors onto the CPU >>> torch.load(tensors.pt, map_locationtorch.device(cpu)) # Load all tensors onto the CPU, using a fun…

目标检测之Faster-RCNN的pytorch代码详解(数据预处理篇)
首先贴上代码原作者的github:https://github.com/chenyuntc/simple-faster-rcnn-pytorch(非代码作者,博文只解释代码) 今天看完了simple-faster-rcnn-pytorch-master代码的最后一个train.py文件,是时候认真的总结一下了࿰…
hp-ux 集群,内存 小记
hp-ux 集群,内存 小记 -----查看hp 集群状态信息 # cmviewcl -v CLUSTER STATUS dbsvr up NODE STATUS STATE db01 up running Cluster_Lock_LVM: VOLUM…
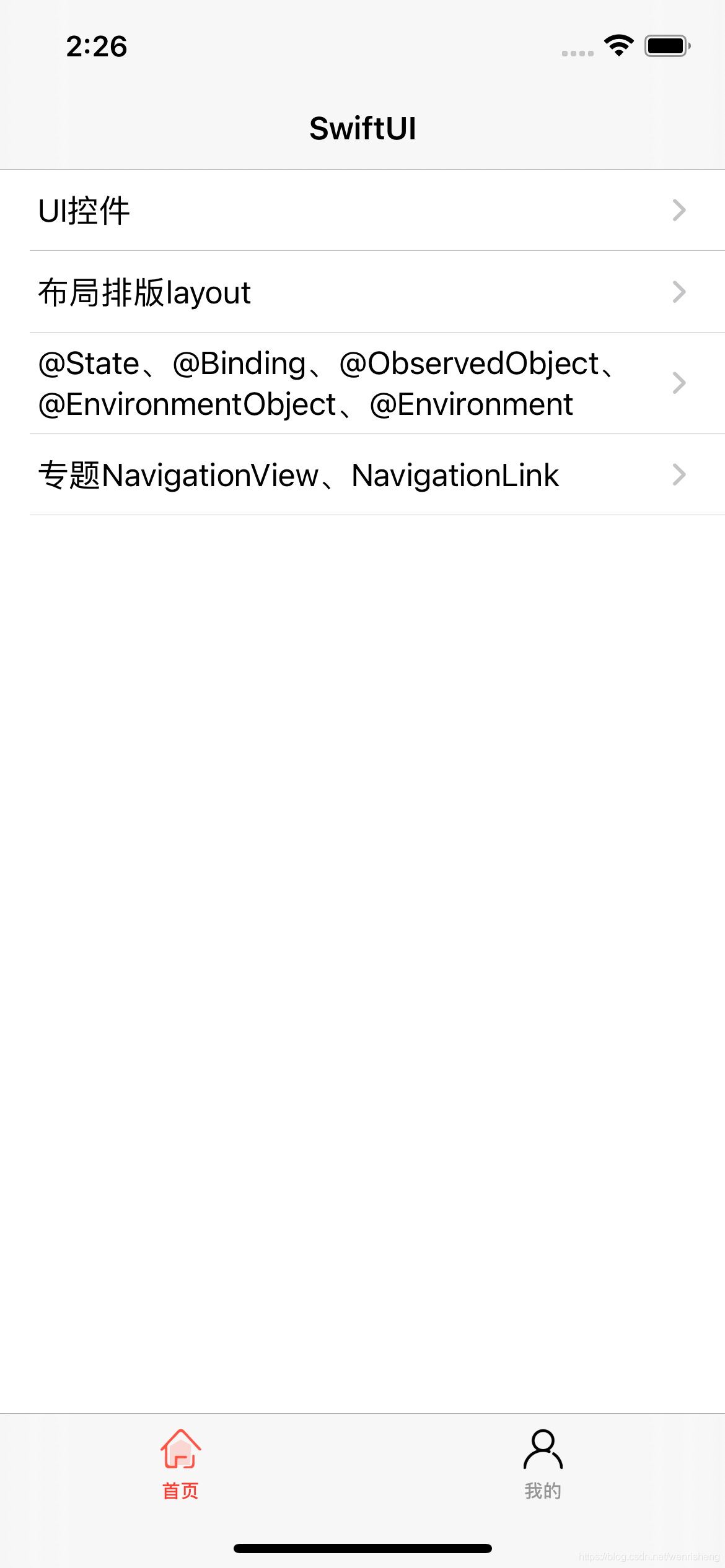
iOS SwiftUI篇-6 专题TabView
iOS SwiftUI篇-6 专题TabView TabView: 图片+文字组成tabItem,选中时改变图片和文字颜色 跳转到二级页面时隐藏tabbar,返回到首页时显示tabbar 首页、我的两个tab,效果图: 图片文字组成tabItem,选中时改变图片和文字颜色 代码: struct MainContentView: View {@State…
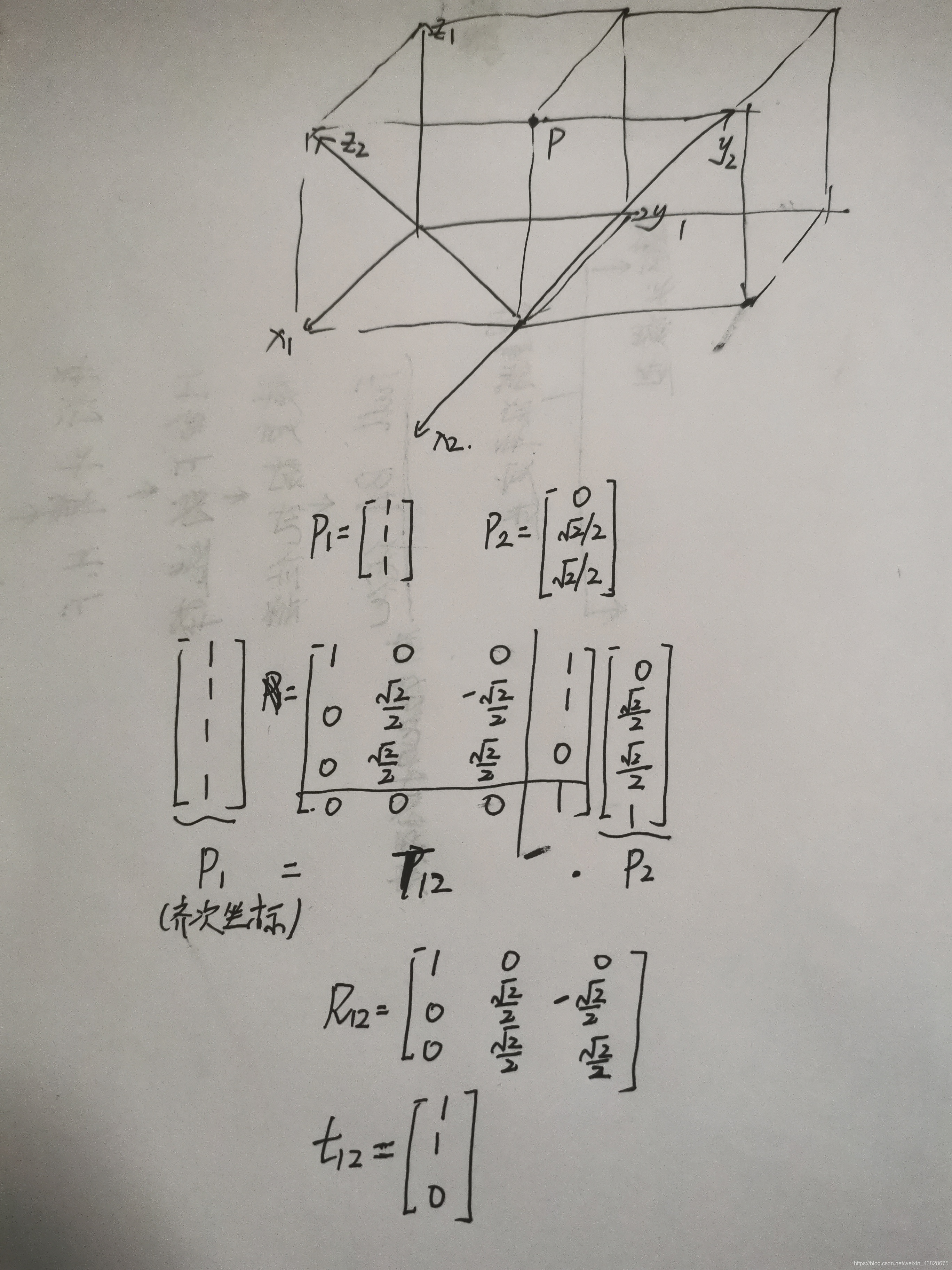
三维刚体变化中Rcw,tcw的含义
高翔博士的《视觉SLAM十四讲》中,介绍Tcw指从世界坐标w到c的变换矩阵。但研一学机器人学的时候,讲T12的含义是,坐标系2相对于坐标系1的变换。于是一脸懵逼。昨天想了一晚上,有了一点自己的想法,在这记录一下࿰…
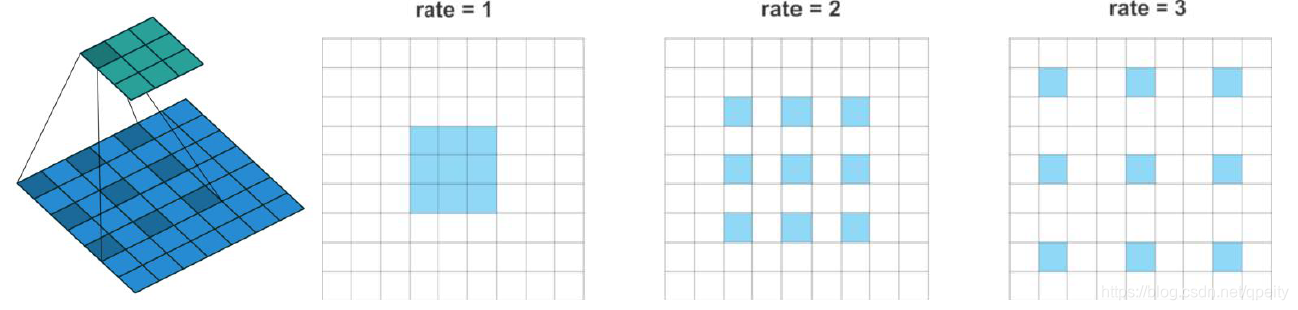
CV07-DeepLab v3+笔记
目录 一、Dilated Convolution 膨胀卷积 二、ASPP与Encoder & Decoder 三、深度可分离卷积 3.1 深度可分离卷积原理 3.2 深度可分离卷积减小参数量和计算量 3.3 深度可分离卷积实现细节 四、Xception作为Backbone DeepLab v3笔记,记录一些自己认为重要的…
1116.加减乘除
题目描述:根据输入的运算符对输入的整数进行简单的整数运算。 运算符只会是加、减-、乘*、除/、求余%、阶乘!六个运算符之一。 输出运算的结果,如果出现除数为零,则输出“error”,如果求余运算的第二个运算数为0,也输出…
Flutter专题1-环境搭建
Flutter专题1-环境搭建和创建项目 这里以MaciOS为例,其他平台参考官网https://flutter.dev/docs/get-started/install 1. 系统要求 系统:macOS (64-bit) 硬盘空间:2.8G 工具:Git 2.获取Flutter SDK 2.1下载SDK,从https://flutter.dev/docs/development/tools/s…
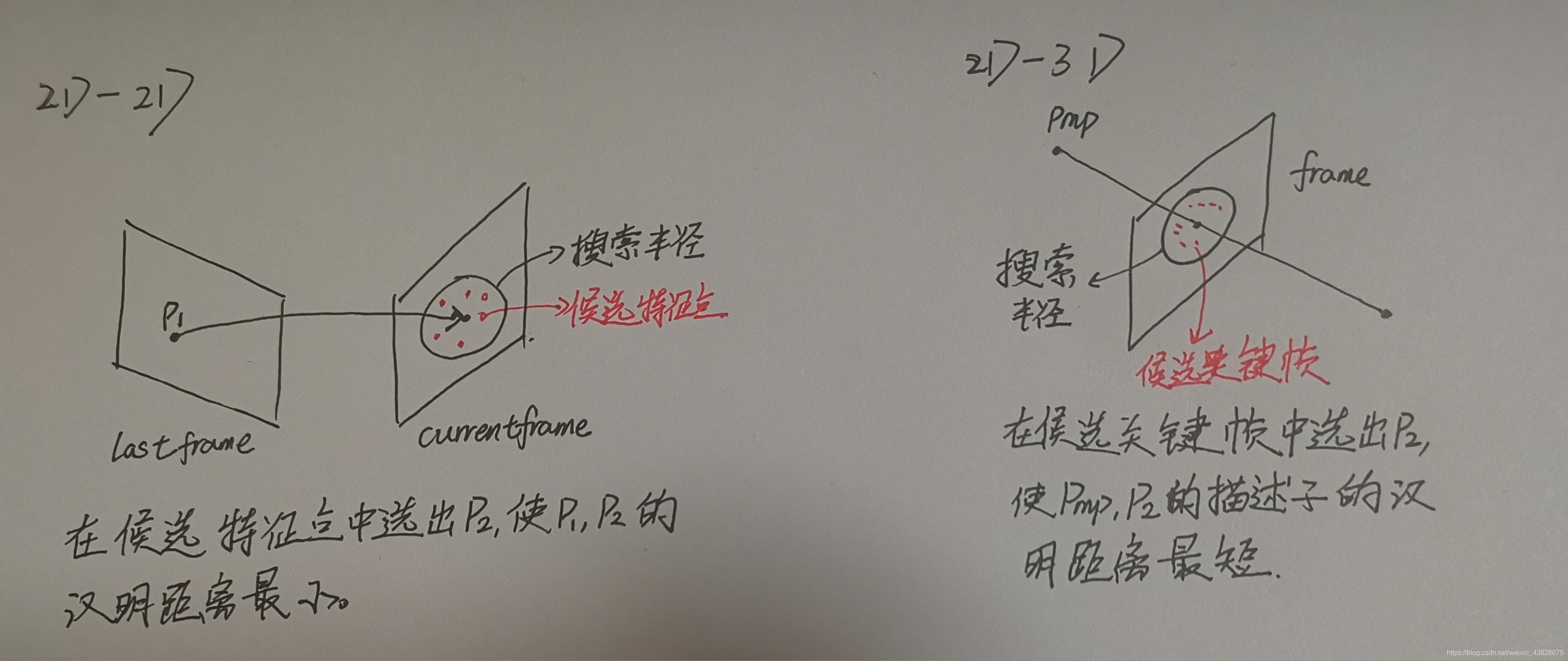
ORB_SLAM2源码:ORBmatcher.cc
ORBmatcher.cc中的函数,主要实现(1)路标点和特征点的匹配(2D-3D点对)。(2)特征点和特征点的匹配(2D-2D点对)。SearchByProjection的函数重载看得我一脸懵逼。在这做一下笔…
iOS国际化技巧
参考链接:http://www.cocoachina.com/ios/20151120/14258.html http://www.jianshu.com/p/88c1b65e3ddb http://www.cnblogs.com/levilinxi/p/4296712.html http://www.cocoachina.com/appstore/20160310/15632.html http://www.cocoachina.com/ios/20170214/18681.html转载于:…
CV08-数据预处理与数据增强
复现车道线分割项目(Lane Segmentation赛事说明在这里),学习数据预处理和数据增强。学习分为Model、Data、Training、Inference、Deployment五个阶段,也就是建模、数据、训练、推断、部署这五个阶段。现在进入的是Data阶段。项目的…
ORB_SLAM2程序入口(System.cc)
程序入口 ORB_SLAM2的程序入口为src/System.cc。在CMakeList.txt中可知,ORB_SLAM2的可执行程序为: Examples/Stereo/stereo_kitti.cc等。 add_executable(stereo_kitti Examples/Stereo/stereo_kitti.cc) target_link_libraries(stereo_kitti ${PROJECT…
HDU 6229 Wandering Robots 找规律+离散化
题目链接:Wandering Robots 题解:先讲一下规律,对于每一个格子它可以从多少个地方来有一个值(可以从自己到自己),然后答案就是统计合法格子上的数与所有格子的数的比值 比如说样例的3 0格子上的值就是 3 4 …