【目标检测】yolo系列:从yolov1到yolov5之YOLOv1详解及复现
检测器通常能够被分为两类,一类是two-stage检测器,最具代表的为faster R-CNN;另一类是one-stage检测器,包括YOLO,SSD等。一般来说,two-stage检测器具有高定位和识别准确性,而one-stage则有速度上的优势。其在结构上的区别就是two-stage检测器有一个生成region proposal的步骤,然后对其进行预测和分类;而one-stage则是直接对预测框进行回归和分类预测。
一阶段(one-stage)目标检测算法直接将目标边界定位问题转化为回归问题来处理。对图像的多层特征图进行均匀密集采样,使用CNN网络提取特征,然后直接进行分类和回归。
YOLO系列是典型的目标检测one-stage模型。本系列文章主要介绍从 YOLO v1发展到YOLO v5的改进和主要设计思路,并且会用教程的方式讲述每一个YOLO模型。
YOLO v1(2015)
Redmon等人提出的 YOLO(You Only Look Once)算法,将目标检测作为回归问题解决,将候选区和检测两个阶段合二为一。
下面讲详细说明yolo v1。
yolov1解决的需求
- 能够检测出图中的多个大小不同的目标
通俗地讲,就是用分类的算法设计了一个检测器,YOLO的作者的思路如下:分类器输出是一个one-hot vector,那将检测器的输出转换成(c, x, y, w, h),c表示confidence置信度,把问题转化成一个回归问题,直接回归出Bounding Box的位置。
主要的思路就是用一个(c,x,y,w,h)去负责image某个区域的目标。比如说图片设置为16个区域,每个区域用1个(c,x,y,w,h)去负责,就可以一次输出16个框,每个框是1个(c,x,y,w,h)。
所以,现在的模型是
img→cbrp16→cbrp32→cbrp64→cbrp128→...→fc256−fc[5]→c,x,y,w,himg \rightarrow cbrp16 \rightarrow cbrp32 \rightarrow cbrp64 \rightarrow cbrp128 \rightarrow ... \\ \rightarrow fc256-fc[5] \rightarrow c,x,y,w,h img→cbrp16→cbrp32→cbrp64→cbrp128→...→fc256−fc[5]→c,x,y,w,h
- 能够检测多类的目标
如果目标特别密集的情况下,只预测一个类别 的目标肯定不够用,所以将预测出的输出加上一个类别概率值,即C,则是某个目标框框出来的物体属于其中一个类别的概率,C是一个one-hot vector,长度为类别的数目。
现在的模型是:
img→cbrp16→cbrp32→cbrp64→cbrp128→...→fc256−fc[5+C]∗S∗S→[c,x,y,w,h,one−hot]∗S∗Simg \rightarrow cbrp16 \rightarrow cbrp32 \rightarrow cbrp64 \rightarrow cbrp128 \rightarrow \\ ... \rightarrow fc256-fc[5+C]*S*S \\ \rightarrow [c,x,y,w,h,one-hot]*S*S img→cbrp16→cbrp32→cbrp64→cbrp128→...→fc256−fc[5+C]∗S∗S→[c,x,y,w,h,one−hot]∗S∗S
- 检测小目标
小目标总是检测不佳,所以我们专门设计神经元去拟合小目标。
对于每个区域,我们用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子,来表示目标框框出来的属于哪一类。
yolo v1的详细思路
总体思路
yolo v1 将一张图片分为S × S个网格,每个网格负责预测中心点落在此网格内的目标,每个网格通过卷积,提取成一个特征向量,然后用这个特征向量去预测目标框。每个网格会预测B 个bounding box,C 个类别概率值,每个bounding box预测5个值(x, y , w, h, confidence) ,如下图所示,一张图片的预测结果有[S×S×(5∗B+C)]个值。
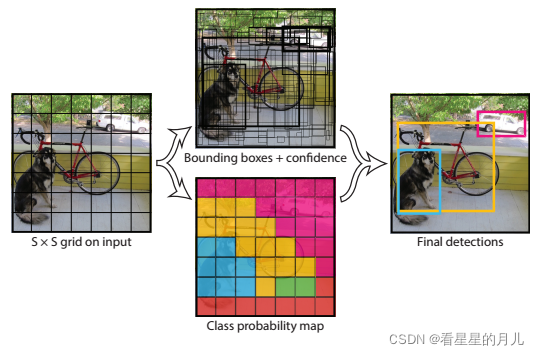
下图是论文中的图:

YOLO v1其实就是划分成了7*7个区域,预测49个目标,分了20个类别。
网络结构
Yolov1的整个网络先使用卷积层进行特征提取,再通过全连接层进行分类和回归。构思来自GoogleNet,网络由24层卷积+2层全连接层组成。在3×3的卷积后面加上1×1卷积来降低feature map的空间大小,从而较少网络的参数和计算量。使用PASCAL VOC 数据集来评估模型,所以网络的最后输出为7×7×30=1470。

模型训练
网络的训练分为2部分:
(1)预训练一个分类网络:使用上述网络的前20个卷积层+average-pool+全连接层在ImageNet进行训练,网络输入为(224×224×3)。
(2)训练检测网络:移除预训练网络中的后两层,再在预训练网络的基础上+4层卷积层+2层全连接层,将网络的输入变为(448×448×3)。
在神经网络结构确定之后,训练效果好坏,由Loss函数和优化器决定。Yolo v1使用普通的梯度下降法作为优化器。Yolo v1使用的Loss函数如下:

一个网格中会预测多个bbox,在训练时,只选择IOU最大的那个bbox来负责预测目标,其他bbox的Pr(Object)值被设为0,使得bbox的预测更加专业,提高整体的recall。
模型预测
1. 使用非极大抑制生成预测框
在预测的时候,格点与格点并不会冲突,但是在预测一些大物体或者邻近物体时,会有多个格点预测了同一个物体。此时采用非极大抑制(NMS),一个目标可能有多个预测框,通过NMS可以过滤掉一些多余的预测框,确保一个目标只有一个预测框。NMS是通过类别置信度来筛选的。
2. 推理时将 p∗cp*cp∗c 作为输出置信度
在推理时,使用物体的类别预测最大值 p 乘以 预测框的最大值 c ,作为输出预测物体的置信度。
首先从所有的预测框中找到置信度最大的那个bbox,然后挨个计算其与剩余bbox的IOU,如果其值大于一定阈值(重合度过高),那么就将该剩余bbox剔除;然后对剩余的预测框重复上述过程,直到处理完所有的检测框
这样也可以过滤掉一些大部分重叠的矩形框。输出检测物体的置信度,同时考虑了矩形框与类别,满足阈值的输出更加可信。
yolo v1存在的问题
- yolo v1每个网格只能预测一个类别,让所有同一个网格预测出来的多个框属于一个类别,所以对于相邻目标的预测效果不好。(这个问题从yolo v2后就已经解决)
- 没有计算背景的geo_loss,只计算了前景的geo_loss,样本不均衡问题依然存在。
- 小目标预测效果不好
完整代码如下:
https://github.com/abeardear/pytorch-YOLO-v1
yolov1源码复现
数据集准备
选用voc2012+2007 数据集,可以提前下载,如需使用自己的数据集,请参考数据集格式。
- 下载voc2012的训练数据集
- 下载voc2007的测试数据集
- 将所有图片放在一个文件夹中,
- 对数据集进行预处理。
(1)xml_2_txt.py 将xml标注转换为txt文件(应该将xml_2_txt.py放在voc数据集的同一文件夹中,或者在 xml_2_txt.py 中更改标注文件的路径)
(2)dataset预处理数据集,txt描述文件,image_name.jpg x y w h c x y w h c 这样就是说一张图片中有两个目标
依赖库
- pytorch
- opencv
- visdom
- tqdm
模型训练验证
运行 train.py文件,file_root修改成自己训练集的文件所在位置。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import models
from torch.autograd import Variablefrom net import vgg16, vgg16_bn
from resnet_yolo import resnet50, resnet18
from yoloLoss import yoloLoss
from dataset import yoloDatasetfrom visualize import Visualizer
import numpy as npuse_gpu = torch.cuda.is_available()file_root = '/home/xzh/data/VOCdevkit/VOC2012/allimgs/'learning_rate = 0.001
num_epochs = 50
batch_size = 24
use_resnet = True
if use_resnet:net = resnet50()
else:net = vgg16_bn()
# net.classifier = nn.Sequential(
# nn.Linear(512 * 7 * 7, 4096),
# nn.ReLU(True),
# nn.Dropout(),
# #nn.Linear(4096, 4096),
# #nn.ReLU(True),
# #nn.Dropout(),
# nn.Linear(4096, 1470),
# )
#net = resnet18(pretrained=True)
#net.fc = nn.Linear(512,1470)
# initial Linear
# for m in net.modules():
# if isinstance(m, nn.Linear):
# m.weight.data.normal_(0, 0.01)
# m.bias.data.zero_()
print(net)
#net.load_state_dict(torch.load('yolo.pth'))
print('load pre-trined model')
if use_resnet:resnet = models.resnet50(pretrained=True)new_state_dict = resnet.state_dict()dd = net.state_dict()for k in new_state_dict.keys():print(k)if k in dd.keys() and not k.startswith('fc'):print('yes')dd[k] = new_state_dict[k]net.load_state_dict(dd)
else:vgg = models.vgg16_bn(pretrained=True)new_state_dict = vgg.state_dict()dd = net.state_dict()for k in new_state_dict.keys():print(k)if k in dd.keys() and k.startswith('features'):print('yes')dd[k] = new_state_dict[k]net.load_state_dict(dd)
if False:net.load_state_dict(torch.load('best.pth'))
print('cuda', torch.cuda.current_device(), torch.cuda.device_count())criterion = yoloLoss(7,2,5,0.5)
if use_gpu:net.cuda()net.train()
# different learning rate
params=[]
params_dict = dict(net.named_parameters())
for key,value in params_dict.items():if key.startswith('features'):params += [{'params':[value],'lr':learning_rate*1}]else:params += [{'params':[value],'lr':learning_rate}]
optimizer = torch.optim.SGD(params, lr=learning_rate, momentum=0.9, weight_decay=5e-4)
# optimizer = torch.optim.Adam(net.parameters(),lr=learning_rate,weight_decay=1e-4)# train_dataset = yoloDataset(root=file_root,list_file=['voc12_trainval.txt','voc07_trainval.txt'],train=True,transform = [transforms.ToTensor()] )
train_dataset = yoloDataset(root=file_root,list_file=['voc2012.txt','voc2007.txt'],train=True,transform = [transforms.ToTensor()] )
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=4)
# test_dataset = yoloDataset(root=file_root,list_file='voc07_test.txt',train=False,transform = [transforms.ToTensor()] )
test_dataset = yoloDataset(root=file_root,list_file='voc2007test.txt',train=False,transform = [transforms.ToTensor()] )
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False,num_workers=4)
print('the dataset has %d images' % (len(train_dataset)))
print('the batch_size is %d' % (batch_size))
logfile = open('log.txt', 'w')num_iter = 0
vis = Visualizer(env='xiong')
best_test_loss = np.inffor epoch in range(num_epochs):net.train()# if epoch == 1:# learning_rate = 0.0005# if epoch == 2:# learning_rate = 0.00075# if epoch == 3:# learning_rate = 0.001if epoch == 30:learning_rate=0.0001if epoch == 40:learning_rate=0.00001# optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate*0.1,momentum=0.9,weight_decay=1e-4)for param_group in optimizer.param_groups:param_group['lr'] = learning_rateprint('\n\nStarting epoch %d / %d' % (epoch + 1, num_epochs))print('Learning Rate for this epoch: {}'.format(learning_rate))total_loss = 0.for i,(images,target) in enumerate(train_loader):images = Variable(images)target = Variable(target)if use_gpu:images,target = images.cuda(),target.cuda()pred = net(images)loss = criterion(pred,target)total_loss += loss.data[0]optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 5 == 0:print ('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f, average_loss: %.4f' %(epoch+1, num_epochs, i+1, len(train_loader), loss.data[0], total_loss / (i+1)))num_iter += 1vis.plot_train_val(loss_train=total_loss/(i+1))#validationvalidation_loss = 0.0net.eval()for i,(images,target) in enumerate(test_loader):images = Variable(images,volatile=True)target = Variable(target,volatile=True)if use_gpu:images,target = images.cuda(),target.cuda()pred = net(images)loss = criterion(pred,target)validation_loss += loss.data[0]validation_loss /= len(test_loader)vis.plot_train_val(loss_val=validation_loss)if best_test_loss > validation_loss:best_test_loss = validation_lossprint('get best test loss %.5f' % best_test_loss)torch.save(net.state_dict(),'best.pth')logfile.writelines(str(epoch) + '\t' + str(validation_loss) + '\n') logfile.flush() torch.save(net.state_dict(),'yolo.pth')
运行eval_voc.py 进行模型验证,若模型表现效果不好,可以对train.py中对学习率等进行调整,也可以调整网络结构,进行模型调优。
模型预测
运行predict.py,将训练好并调好参数的最优模型传入其中,进行预测。
结果如图所示。

相关文章:

Ubuntu终端命令行缩短显示路径
平时我们使用linux终端命令行的时候,常常会被一个问题困扰,那就是文件路径过长, 有时候甚至超过了一行,这样看起来非常别扭,其实只要两步就可以解决这个问题: 1,修改.bashrc文件(用户…
主要的约瑟夫环问题
解说 http://poj.org/problem?id3517 n个人,编号为1~n。每次从1開始数,数到m的人出圈。最后一个出圈的人的编号。f[1] 0; for(int i 2; i < n; i) {f[i] ( f[i-1] m)%i; } printf("%d\n",f[n]1);这里第一次出圈的人的编号是mÿ…
CSS之复合选择器(交集、并集选择器)
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title></title><style>/*将class为red的元素设置为红色*/.red{color: red;}/*将class为red的div字体大小设置为30px*//*1、交集选择器作用:选中同时复合多…
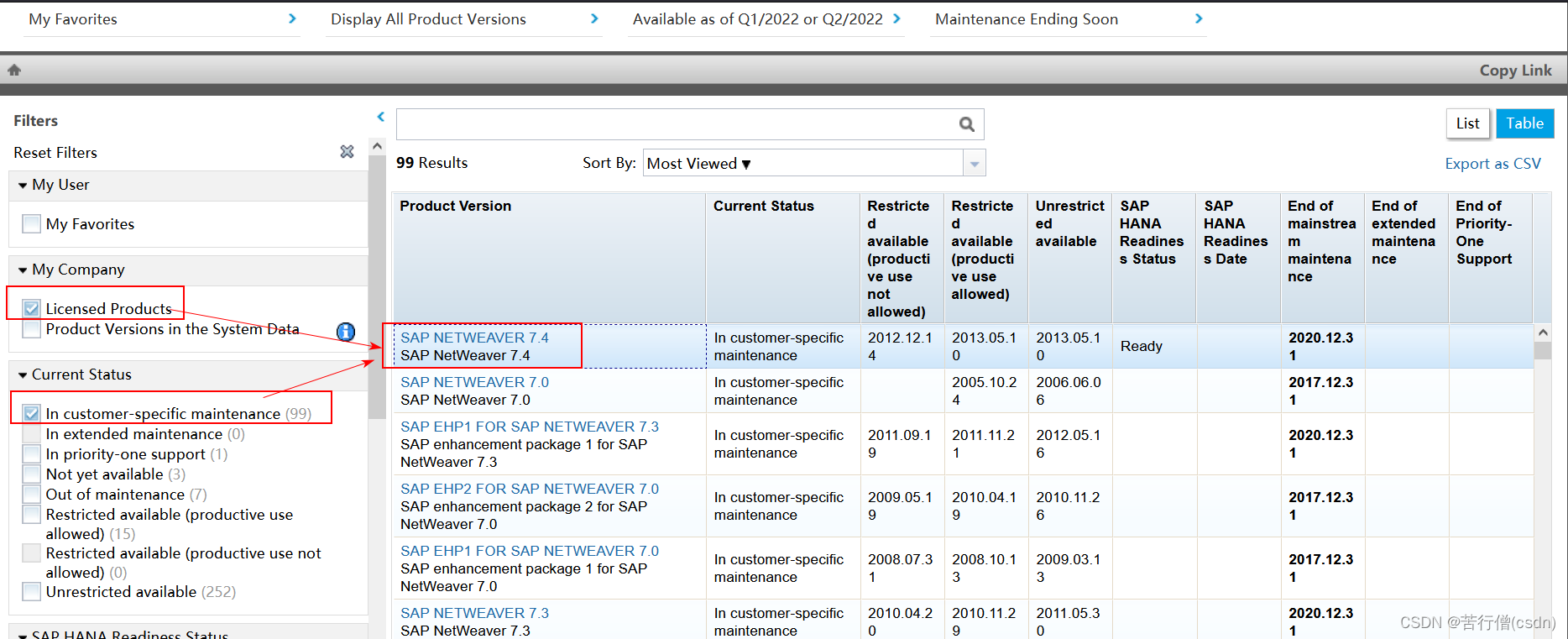
SAP有用的知识(持续更新)
一、安装SAP 1.1、产品可用性矩阵(Product Availability Matrix) SAP官网-Maintenance-Product Availability Matrix,点击页面的Access the Product Availability Matrix。 选中你公司授权的商品(Licensed Products)…
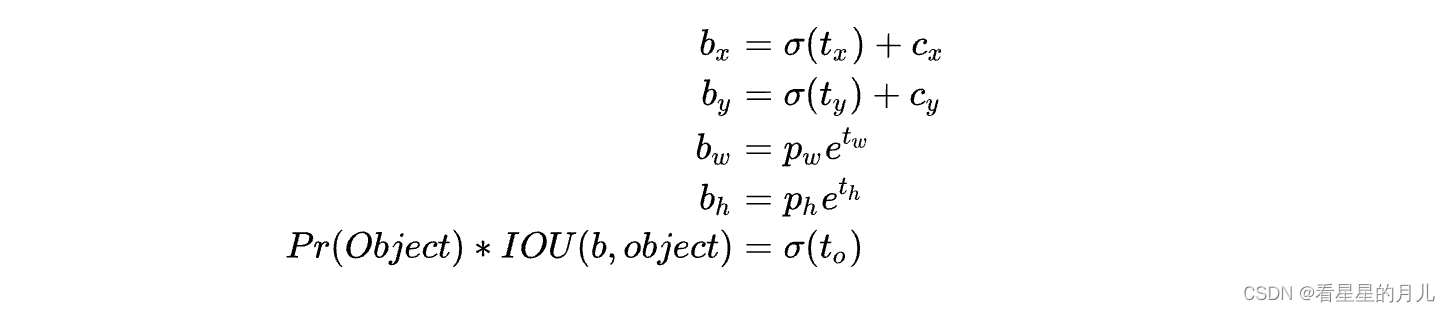
【目标检测】yolo系列:从yolov1到yolov5之YOLOv2详解及复现
YOLO v2 Yolov2论文链接:YOLO9000: Better, Faster, Stronger yolov2的改进 从Yolov2论文的标题可以直观看到就是Better、Faster、Stronger。Yolov1发表之后,计算机视觉领域出现了很多trick,例如批归一化、多尺度训练等等,v2也…
我有一个很好的思维习惯-反思
和我共事过的同事有的会说我聪明,我就暂且当做是夸奖吧,其实我并不是聪明,只是有一个思维习惯。做事过程中或者做完一件事之后会反思这个过程,有哪些地方我是重复操作的,有没有什么地方可以简化流程的,这应…
CSS之关系选择器(子元素、后代、兄弟选择器)
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title></title><style>/*为div的子元素span设置一个字体颜色*//*子元素选择器:作用:选中指定父元素的指定子元素语法:父元素>子…
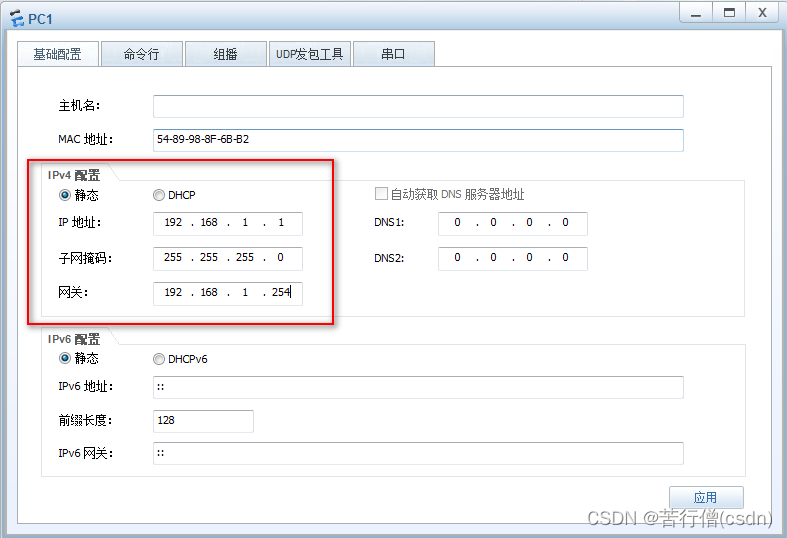
网络管理员比赛回顾01-基本操作和简单vlan
目录 一、模拟器eNSP 二、基本操作 三、配置IP地址 四、VLAN 一、模拟器eNSP 使用eNSP模拟器,来源于网络上的安装包,学习一个。基本操作就不多说了,在实践里慢慢记录 二、基本操作 认识3种视图:用户视图、系统视图、接口视…
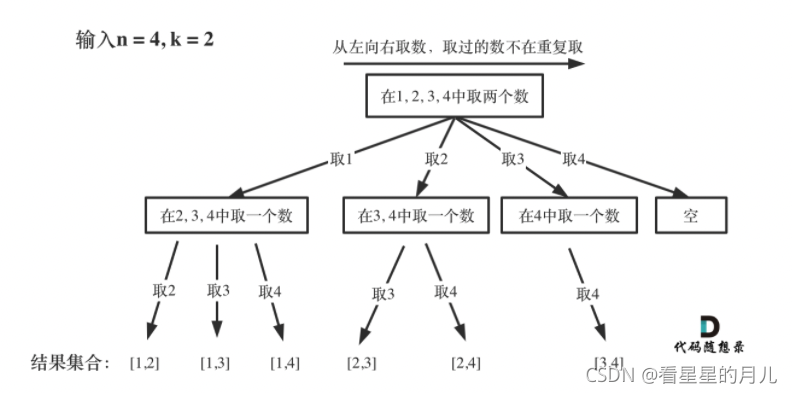
【Leetcode】刷题之路3(python版)
回溯专题 1.回溯算法的本质是n叉树的深度优先搜索,同时,需要注意剪枝减少复杂度。 2.回溯算法三部曲 确定参数和返回值回溯函数终止条件单层循环 3.回溯法思路 回溯法是一种算法思想,而递归是一种编程方法,回溯法可以用递归来…
Luogu 4438 [HNOI/AHOI2018]道路
$dp$。 这道题最关键的是这句话: 跳出思维局限大胆设状态,设$f_{x, i, j}$表示从$x$到根要经过$i$条公路,$j$条铁路的代价,那么对于一个叶子结点,有$f_{x, i, j} c_x * (a_x i) * (b_x j)$,对于内部结点…
52深入理解C指针之---不透明指针
该系列文章源于《深入理解C指针》的阅读与理解,由于本人的见识和知识的欠缺可能有误,还望大家批评指教。一、size_t:用于安全表示长度,所有平台和系统都会解析成自己对应的长度 1、定义:size_t类型表示C中任何对…
CSS之布局(文档流)
文档流: <!DOCTYPE html> <html><head><meta charset"utf-8" /><title>文档流</title><style>.box1{background-color: yellow;}</style></head><body><!--文档流(normal fl…

网络管理员比赛回顾02-网关、静态路由、动态路由
目录 一、配置网关 二、配置静态路由 三、配置动态路由 3.1、使用RIP协议配置动态路由 3.2、使用OSPF协议配置动态路由 2021年9月参加青年网络管理员比赛,因为网管超龄不能按照“青年”参赛,临时培训我们这批“青年”参赛,回顾一下经过以…
[模拟]纺车的轮子 Spinning Wheels
题目链接 题目大意 5个轮子 每个轮子上面有w个缺口 缺口的初始角度是n 宽度是m 每秒转速v 求当他们同时开始转的情况下,什么时候他们的缺口足以让一道阳光通过(就是有重叠部分) 思考 纯模拟题目没啥说的,就是模拟轮子转1S 2S 3S .…
从头理解self-attention机制
注意力机制中较为重要的是self-attention机制,直接做了个小白能看懂的总结,也便于自己复习。 简介 self-attention机制就是想实现一连串的特征编码,两两之间的互相注意。有一串特征编码,x1, x2, …, xn,这里x1 x2 ……
筛选法求N以内的所有素数
素数:一个数只能被1和它本身整除的数。2是最小的素数#include <iostream> using namespace std; #define NUM 100 char isPrime[NUM 10]; int main() {//筛选法求素数//假设所有的素数都是素数,标志位设为1for(int i 2 ; i < NUM ; i){isPrim…
CSS之布局(盒模型)
盒模型: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>盒模型</title><style>.box1{/* 内容区(content),元素中的所有的子元素和文本内容都在内容区中排列内容区的大小由width和height两个属性来…
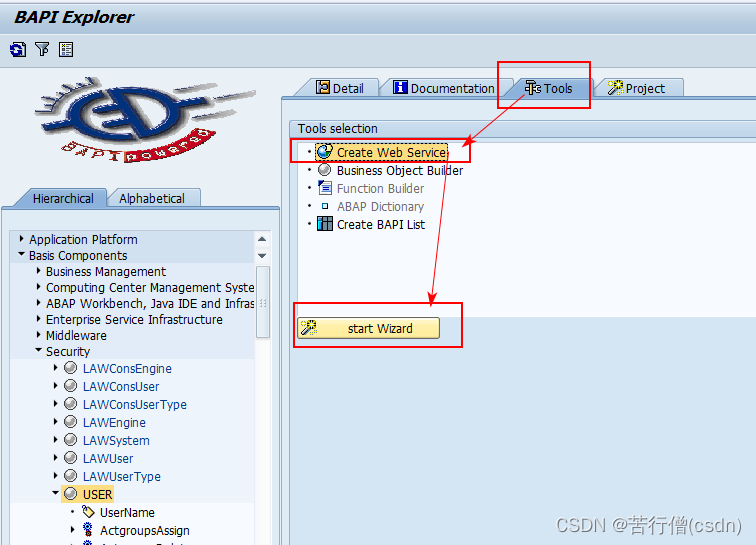
SAP创建webservice
目录 一、创建webservice 二、更改webservice 三、SoapUI测试webservice 四、查看webservice日志及排错 一、创建webservice 以用户相关的函数User为例创建webservice,事务码bapi查看bapi函数,BasisComponents-Security-User,选择Tools…

python面试题目
python面试题目 原文地址:https://www.usblog.cc/blog/post/justzhl/b5cc9a05c7d2 问题一:以下的代码的输出将是什么? 说出你的答案并解释。 ?1234567891011121314class Parent(object):x 1class Child1(Parent):passclass Child2(Parent):passprint …
vue2留言板
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>智能社——http://www.zhinengshe.com</title><meta name"viewport" content"widthdevice-width, initial-scale1.0, maximum…
【目标检测】yolo系列:从yolov1到yolov5之YOLOv3详解及复现
在v1、v2的原理和技巧介绍之后,v3除了网络结构,其余的改变并不多。本文着重描述yolov3的原理细节。 相关阅读: 论文:YOLOv3: An Incremental Improvement 源码:https://github.com/ultralytics/yolov3 1. Yolov3网络…
CSS之布局(盒子模型—边框)
盒子模型—边框: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>盒子模型-边框</title><style>.box1{width: 200px;height: 200px;background-color: #bfa;/*border-width可以用来指定四个方向的…

SAP事务码f-02做账界面显示“页数”字段
事务码 f-02 做账界面,没有显示页数。 用户账号的参数添加 CSF (Country-Specific Fields)参数,参数值为 CN(伟大的China) 再次来到 f-02 的界面,显示了页数字段
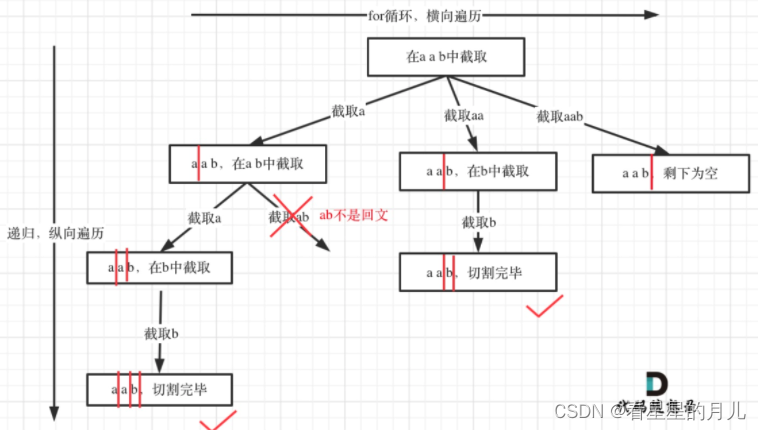
【Leetcode】刷题之路4(python版)
接上章回溯专题,本章挑选了分割问题、子集问题、排列问题。 分割问题 131.分割回文串93.复原IP地址 子集问题 78.子集90.子集II 排列问题 46.全排列47.全排列II 分割问题 我们来分析一下切割,其实切割问题类似组合问题。 例如对于字符串abcdef&#…

织梦文章内容屏蔽替换词语多个敏感字词
后台-系统-基本参数-互动设置-替换词语,这个是用于评论和会员投稿,网站后台添加的文章是不受制于这里的,我们可以直接在模板标签里runphp字符串替换 文章内容页标签写法 {dede:field.body runphpyes} global $cfg_replacestr; me preg_repla…
CSS之布局(盒子模型--内边距)
盒子模型--内边距: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>盒子模型--内边距</title><style>.box1{width: 200px;height: 200px;background-color: #bfa;border: solid 10px orange;/*内边…

网络管理员比赛回顾04-DHCP
目录 一、DHCP的配置 二、DHCP中继 2021年9月参加青年网络管理员比赛,因为网管超龄不能按照“青年”参赛,临时培训我们这批“青年”参赛,回顾一下经过以及学到的技能。本节回顾DHCP。 一、DHCP的配置 简单的启用一个DHCP功能。 <Huawe…
iOS-禁止scrollview垂直方向滚动,只允许水平方向滚动;或只允许垂直方向滚动...
禁止UIScrollView垂直方向滚动,只允许水平方向滚动 scrollview.contentSize CGSizeMake(你要的长度, 0); 禁止UIScrollView水平方向滚动,只允许垂直方向滚动 scrollview.contentSize CGSizeMake(0, 你要的宽度); 转载于:https://www.cnblogs.com/S…
go1.8之安装配置
说明: 之前学习过go语言(大概是0.9版本),后来更新太快,也没怎么使用,就荒废掉了,今年有项目需要用go开发,重新捡起。 这是我在学习go语言过程中整理的内容,这里记录下&am…

栈和队列在python中的实现
栈和队列是两种基本的数据结构,同为容器类型,队列是先进先出,栈是先进后出。 栈 栈提供 push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set…