替代Druid,HakariCP 为什么这么快?
转自:https://mp.weixin.qq.com/s/Td5faeBY3fX3JUnM3QGJyw
引言
Springboot 2.0将 HikariCP 作为默认数据库连接池这一事件之后,HikariCP 作为一个后起之秀出现在大众的视野中。HikariCP 是在日本的程序员开源的,hikari日语意思为“光”,HikariCP 也以速度快的特点受到越来越多人的青睐。
今天就让我们来探讨一下HikariCP为什么这么快?
连接池技术
我们平常编码过程中,经常会碰到线程池啊,数据库连接池啊等等,那么这个池到底是一门怎样的技术呢?
简单来说,连接池是一个创建和管理连接的缓冲池技术。连接池主要由三部分组成:连接池的建立、连接池中连接的使用管理、连接池的关闭。
连接池技术的核心思想是:连接复用,通过建立一个数据库连接池以及一套连接使用、分配、管理策略,使得该连接池中的连接可以得到高效、安全的复用。它不仅仅只限于管理数据库访问连接,也可以管理其他连接资源。
HakariCP
HakariCP 项目的 README 中的一段话。
Fast, simple, reliable. HikariCP is a “zero-overhead” production ready JDBC connection pool. At roughly 130Kb, the library is very light.
快速、简单、可靠。HikariCP是一个“零开销”的生产就绪JDBC连接池。这个库大约有130Kb,非常轻。
这个介绍真是简洁但“全面”。搭配上下边这张图。
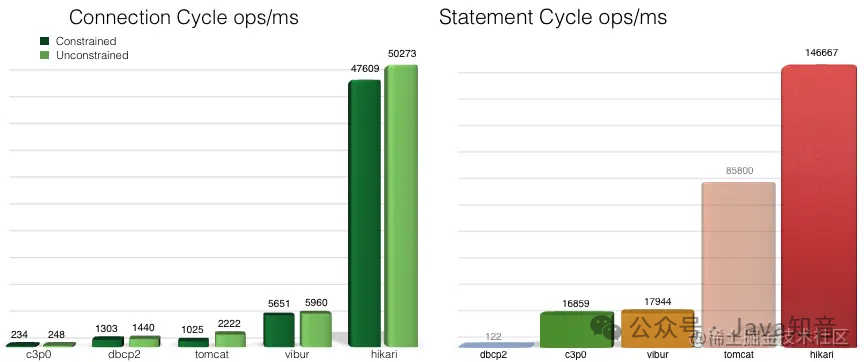
看到这些数据,再加上Springboot 2.0 将 HikariCP 作为默认数据库连接池这件事,我已经十分好奇 HikariCP 的实现原理了。
HikariCP为什么这么快?
- 两个HikariPool:定义了两个HikariPool对象,一个采用final类型定义,避免在获取连接时才初始化,提高性能,也避免
volatile的额外开销。 - FastList替代ArrayList:采用自定义的FastList替代了ArrayList,FastList的get方法去除了范围检查逻辑,并且remove方法是从尾部开始扫描的,而并不是从头部开始扫描的。因为Connection的打开和关闭顺序通常是相反的。
- 更快的并发集合实现:使用自定义ConcurrentBag,性能更优。
- 更快的获取连接:同一个线程获取数据库连接时从ThreadLocal中获取,没有并发操作。
- 精简字节码:HikariCP利用了一个第三方的Java字节码修改类库Javassist来生成委托实现动态代理,速度更快,相比于JDK 代理生成的字节码更少。
HikariCP原理
我们通过分析源码来看 HikariCP 是如何这么快的。先来看一下 HikariCP 的简单使用。
maven依赖:
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>4.0.3</version>
</dependency>
@Test
public void testHikariCP() throws SQLException {
// 1、创建Hikari配置
HikariConfig hikariConfig = new HikariConfig();
// JDBC连接串
hikariConfig.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/iam?characterEncoding=utf8");
// 数据库用户名
hikariConfig.setUsername("root");
// 数据库用户密码
hikariConfig.setPassword("123456");
// 连接池名称
hikariConfig.setPoolName("testHikari");
// 连接池中最小空闲连接数量
hikariConfig.setMinimumIdle(4);
// 连接池中最大空闲连接数量
hikariConfig.setMaximumPoolSize(8);
// 连接在池中的最大空闲时间
hikariConfig.setIdleTimeout(600000L);
// 数据库连接超时时间
hikariConfig.setConnectionTimeout(10000L);
// 2、创建数据源
HikariDataSource dataSource = new HikariDataSource(hikariConfig);
// 3、获取连接
Connection connection = dataSource.getConnection();
// 4、获取Statement
Statement statement = connection.createStatement();
// 5、执行Sql
ResultSet resultSet = statement.executeQuery("SELECT COUNT(*) AS countNum tt_user");
// 6、输出执行结果
if (resultSet.next()) {
System.out.println("countNum结果为:" + resultSet.getInt("countNum"));
}
// 7、释放链接
resultSet.close();
statement.close();
connection.close();
dataSource.close();
}
HikariConfig:可以设置一些数据库基本配置信息和一些连接池的配置信息。
HikariDataSource:实现了 DataSource,DataSource是一个数据源标准或者说规范,Java所有连接池需要基于这个规范进行实现。
我们就从 HikariDataSource 开始说起。HikariDataSource有两个构造方法HikariDataSource()和HikariDataSource(HikariConfig configuration)。
private final HikariPool fastPathPool;
private volatile HikariPool pool;
public HikariDataSource()
{
super();
fastPathPool = null;
}
public HikariDataSource(HikariConfig configuration)
{
configuration.validate();
configuration.copyStateTo(this);
LOGGER.info("{} - Starting...", configuration.getPoolName());
pool = fastPathPool = new HikariPool(this);
LOGGER.info("{} - Start completed.", configuration.getPoolName());
this.seal();
}
HikariPool为什么要有两个(fastPathPool和pool)呢?
可以看到无参构造方法fastPathPool是null,有参构造pool = fastPathPool,采用无参构造在getConnection()时候才会初始化(下边会详细讲解),性能略低,并且pool是volatile关键字修饰,会有一些额外开销。所以建议使用有参构造。这也是HikariPool快的原因之一。
有参构造里有一行new HikariPool(this),我们来看一下怎么个事。
代码太多了,往后只贴关键代码了。。。
public HikariPool(final HikariConfig config)
{
super(config);
// 初始化ConcurrentBag对象
this.connectionBag = new ConcurrentBag<>(this);
// 创建SuspendResumeLock对象
this.suspendResumeLock = config.isAllowPoolSuspension() ? new SuspendResumeLock() : SuspendResumeLock.FAUX_LOCK;
// 根据配置的最大连接数,创建链表类型阻塞队列
LinkedBlockingQueue<Runnable> addConnectionQueue = new LinkedBlockingQueue<>(maxPoolSize);
this.addConnectionQueueReadOnlyView = unmodifiableCollection(addConnectionQueue);
// 初始化创建连接线程池
this.addConnectionExecutor = createThreadPoolExecutor(addConnectionQueue, poolName + " connection adder", threadFactory, new ThreadPoolExecutor.DiscardOldestPolicy());
// 初始化关闭连接线程池
this.closeConnectionExecutor = createThreadPoolExecutor(maxPoolSize, poolName + " connection closer", threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());
// 创建保持连接池连接数量的任务
this.houseKeeperTask = houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);
...
}
HikariPool 是为HikariCP提供基本池行为的主要连接池类。
houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS)这行代码是 创建保持连接池连接数量的任务。该任务会关闭需要被丢弃的连接,保证最小连接数,HouseKeeper类的run()方法中有一行代码fillPool()会创建连接,我们来看一下。
创建连接
private synchronized void fillPool()
{
// 计算需要添加的连接数量
final int connectionsToAdd = Math.min(config.getMaximumPoolSize() - getTotalConnections(), config.getMinimumIdle() - getIdleConnections()) - addConnectionQueue.size();
for (int i = 0; i < connectionsToAdd; i++) {
// 向创建连接线程池中提交创建连接的任务
addConnectionExecutor.submit((i < connectionsToAdd - 1) ? poolEntryCreator : postFillPoolEntryCreator);
}
...
}
来看一下PoolEntryCreator是如何创建连接的。
@Override
public Boolean call()
{
// 连接池状态正常并且需求创建连接时
while (poolState == POOL_NORMAL && shouldCreateAnotherConnection()) {
// 创建PoolEntry对象
final PoolEntry poolEntry = createPoolEntry();
if (poolEntry != null) {
// 将PoolEntry对象添加到ConcurrentBag对象中的sharedList中
connectionBag.add(poolEntry);
return Boolean.TRUE;
}
}
...
return Boolean.FALSE;
}
PoolEntryCreator实现了Callable接口,在call()方法里可以看到创建连接的过程。来继续看一下createPoolEntry()方法。
private PoolEntry createPoolEntry()
{
// 初始化PoolEntry对象
final PoolEntry poolEntry = newPoolEntry();
...
}
继续进入newPoolEntry()方法。
PoolEntry newPoolEntry() throws Exception
{
return new PoolEntry(newConnection(), this, isReadOnly, isAutoCommit);
}
PoolEntry构造时会先创建Connection对象传入构造函数中。PoolEntry是ConcurrentBag实例中用来跟踪Connection的。
获取链接
获取链接是通过getConnection()方法获取的,源码如下。
public Connection getConnection() throws SQLException
{
if (isClosed()) {
throw new SQLException("HikariDataSource " + this + " has been closed.");
}
if (fastPathPool != null) {
return fastPathPool.getConnection();
}
HikariPool result = pool;
if (result == null) {
synchronized (this) {
result = pool;
if (result == null) {
validate();
LOGGER.info("{} - Starting...", getPoolName());
try {
pool = result = new HikariPool(this);
this.seal();
}
catch (PoolInitializationException pie) {
if (pie.getCause() instanceof SQLException) {
throw (SQLException) pie.getCause();
}
else {
throw pie;
}
}
LOGGER.info("{} - Start completed.", getPoolName());
}
}
}
会先去fastPathPool获取连接,如果fastPathPool为null,就会通过pool获取,如果pool也为null,会通过 双检 代码来初始化线程池。
这个上文提到过为什么两个HikariPool,fastPathPool是 final 修饰的,而pool是 volatile 修饰的,这就说明fastPathPool比pool性能更高,所以建议要用有参构造来创建HikariDataSource,才能享受到这点小细节的优化。
继续进入HikariPool#getConnection(final long hardTimeout),方法中有一行关键的代码PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS),这行代码的作用是从ConcurrentBag中借出一个PoolEntry对象。PoolEntry可以看作是对Connection对象的封装,连接池中存储的连接其实就是一个个的PoolEntry。
这个connectionBag是用来做什么的呢?
ConcurrentBag
ConcurrentBag 是HikariCP自定义的一个无锁并发集合类。我们接着来看一下 ConcurrentBag 的成员变量。
private final CopyOnWriteArrayList<T> sharedList;
private final boolean weakThreadLocals;
private final ThreadLocal<List<Object>> threadList;
private final IBagStateListener listener;
private final AtomicInteger waiters;
private volatile boolean closed;
private final SynchronousQueue<T> handoffQueue;
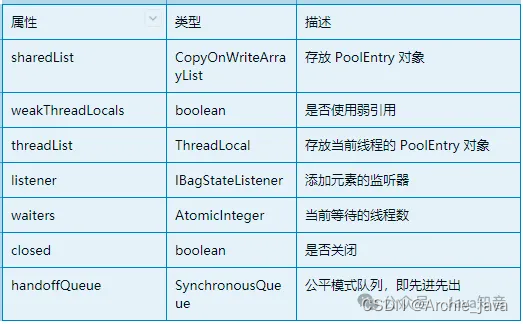
回到borrow()方法,看一下borrow的实现逻辑。
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 从ThreadLocal中获取当前线程绑定的对象集合,存在则获取
final List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 等待对象加一
final int waiting = waiters.incrementAndGet();
try {
// sharedList有未使用的则返回一个
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// If we may have stolen another waiter's connection, request another bag add.
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
// sharedList没有,添加一个监听任务
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 阻塞队列计时获取
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
// 等待线程数减一
waiters.decrementAndGet();
}
}
- 先从ThreadLocal中获取以前用过的连接。ThreadLocal是当前线程的缓存,加快本地连接获取速度。
- ThreadLocal中未获取到,会尝试从sharedList中获取,sharedList集合存在初始化的PoolEntry。sharedList是CopyOnWriteArrayList类型的,写时复制,特别适合这种读多写少的场景。
- sharedList中未获取到那就到阻塞队列中等着,看有没有归还的连接可以使用。
释放连接
用完连接后我们要释放,通过connection.close()释放连接,释放连接时HakariCP也做到了一些巧妙的细节。ProxyConnection的close()方法是HakariCP释放连接的实现逻辑。我们知道连接关闭前必须要关闭Statement,HakariCP对这里做了优化,来看一下代码实现。
private final FastList<Statement> openStatements;
private synchronized void closeStatements()
{
final int size = openStatements.size();
if (size > 0) {
for (int i = 0; i < size && delegate != ClosedConnection.CLOSED_CONNECTION; i++) {
try (Statement ignored = openStatements.get(i)) {
}
catch (SQLException e) {
LOGGER.warn("{} - Connection {} marked as broken because of an exception closing open statements during Connection.close()",
poolEntry.getPoolName(), delegate);
leakTask.cancel();
poolEntry.evict("(exception closing Statements during Connection.close())");
delegate = ClosedConnection.CLOSED_CONNECTION;
}
}
openStatements.clear();
}
}
存储Statement对象用的是 FastList,这也是 HakariCP 之所以快的原因之一。
为什么用FastList而不用ArrayList呢?
- 去掉索引范围检查:查看源码会发现,FastList的get()方法比ArrayList少了一行代码
rangeCheck(index),这行代码的作用是范围检查,少了这行代码必然会性能更优。不禁感叹真的是太细了啊,到处都是细节。 - 尾部删除:
FastList#remove()方法是从尾部开始扫描的,而并不是从头部开始扫描的。因为Connection的打开和关闭顺序通常是相反的。FastList的根据下标删除方法也去掉索引范围检查。
关闭掉Statement之后,我们再回过头来继续往下看。
poolEntry.recycle(lastAccess);
recycle方法会将该连接归还给线程池,recycle方法套了好几层,最终执行的是ConnectionBag的recycle方法,我们直接进入看一下。
public void requite(final T bagEntry)
{
bagEntry.setState(STATE_NOT_IN_USE);
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
Thread.yield();
}
}
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) {
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}
}
首先将状态设置为未使用,然后判断当前是否存在等待连接的线程,如果存在则将连接加入到公平队列中,由队列中有等待连接的线程则会从阻塞队列中去获取使用;如果当前没有等待连接的线程,并且ThreadLocal中的连接小于50,则将连接添加到本地线程变量ThreadLocal缓存中,当前线程下次获取连接时直接可从ThreadLocal中获取到。
总结
这次源码探究,真的感觉看到了无数个小细节,无数个小优化,积少成多。平时开发过程中,一些小的细节也一定要“扣”。
相关文章:
常见的七种加密算法及实现
**数字签名**、**信息加密** 是前后端开发都经常需要使用到的技术,应用场景包括了用户登入、交易、信息通讯、`oauth` 等等,不同的应用场景也会需要使用到不同的签名加密算法,或者需要搭配不一样的 **签名加密算法** 来达到业务目标。这里简单的给大家介绍几种常见的签名加密算法和一些典型场景下的应用。## 正文### 1. 数字签名**数字签名**,简单来说就是通过提供 **可鉴别** 的 **数字信息** 验证 **自身身份** 的一种方式。一套 **数字签名** 通常定义两种 **互补

7min到40s:SpringBoot 启动优化实践
然后重点排查这些阶段的代码。先看下。

SpringBoot系列教程之Bean之指定初始化顺序的若干姿势
之前介绍了@Order注解的常见错误理解,它并不能指定 bean 的加载顺序,那么问题来了,如果我需要指定 bean 的加载顺序,那应该怎么办呢?本文将介绍几种可行的方式来控制 bean 之间的加载顺序。

在Java中使用WebSocket
WebSocket是一种协议,用于在Web应用程序和服务器之间建立实时、双向的通信连接。它通过一个单一的TCP连接提供了持久化连接,这使得Web应用程序可以更加实时地传递数据。WebSocket协议最初由W3C开发,并于2011年成为标准。
3种方案,模拟两个线程抢票
在多线程编程中,资源竞争是一个常见的问题。资源竞争发生在多个线程试图同时访问或修改共享资源时,可能导致数据不一致或其他并发问题。在模拟两个线程抢票的场景中,我们需要考虑如何公平地分配票,并确保每个线程都有机会成功获取票。本篇文章将通过三种方式来模拟两个线程抢票的过程,以展示不同的并发控制策略。使用 Synchronized 来确保一次只有一个线程可以访问票资源。使用 ReentrantLock 来实现线程间的协调。使用 Semaphore 来限制同时访问票的线程数量。
Java中volatile 的使用场景有哪些?
volatile是一种轻量级的同步机制,它能保证共享变量的可见性,同时禁止重排序保证了操作的有序性,但是它无法保证原子性。所以使用volatilevolatile。

JDK22 正式发布了 !
Java 22 除了推出了新的增强功能和特性,也获得 Java Management Service (JMS) 的支持,这是一项新的 Oracle 云基础设施远程软件服务(Oracle Cloud Infrastructure, OCI) 原生服务,提供统一的控制台和仪表盘,帮助企业管理本地或云端的 Java 运行时和应用。使包含运行时计算值的字符串更容易表达,简化 Java 程序的开发工作,同时提高将用户提供的值编写成字符串,并将字符串传递给其他系统的程序的安全性。支持开发人员自由地表达构造器的行为。

Jackson 用起来!
你可以创建自定义序列化器和反序列化器以自定义特定字段或类的序列化和反序列化行为。为此,请创建一个实现或接口的类,并在需要自定义的字段或类上使用和注解。@Override// ...其他代码...优势性能优异:Jackson在序列化和反序列化过程中表现出优秀的性能,通常比其他Java JSON库更快。灵活性:通过注解、自定义序列化器/反序列化器等功能,Jackson提供了丰富的配置选项,允许你根据需求灵活地处理JSON数据。易于使用:Jackson的API设计简洁明了,易于学习和使用。
拜托!别再滥用 ! = null 判空了!!
另外,也许受此习惯影响,他们总潜意识地认为,所有的返回都是不可信任的,为了保护自己程序,就加了大量的判空。如果你养成习惯,都是这样写代码(返回空collections而不返回null),你调用自己写的方法时,就能大胆地忽略判空)这种情况下,null是个”看上去“合理的值,例如,我查询数据库,某个查询条件下,就是没有对应值,此时null算是表达了“空”的概念。最终,项目中会存在大量判空代码,多么丑陋繁冗!,而不要返回null,这样调用侧就能大胆地处理这个返回,例如调用侧拿到返回后,可以直接。
详解Java Math类的toDegrees()方法:将参数从弧度转换为角度
Java Math 类的 toDegrees() 方法是将一个角度的弧度表示转换为其度表示,返回值为double类型,表示从弧度数转换而来的角度数。这就是Java Math 类的 toDegrees() 方法的攻略。我们已经了解了该方法的基本概念、语法、注意事项以及两个示例。希望这篇攻略对你有所帮助。

SpringBoot接口防抖(防重复提交)的一些实现方案
作为一名老码农,在开发后端Java业务系统,包括各种管理后台和小程序等。在这些项目中,我设计过单/多租户体系系统,对接过许多开放平台,也搞过消息中心这类较为复杂的应用,但幸运的是,我至今还没有遇到过线上系统由于代码崩溃导致资损的情况。这其中的原因有三点:一是业务系统本身并不复杂;二是我一直遵循某大厂代码规约,在开发过程中尽可能按规约编写代码;三是经过多年的开发经验积累,我成为了一名熟练工,掌握了一些实用的技巧。啥是防抖所谓防抖,一是防用户手抖,二是防网络抖动。
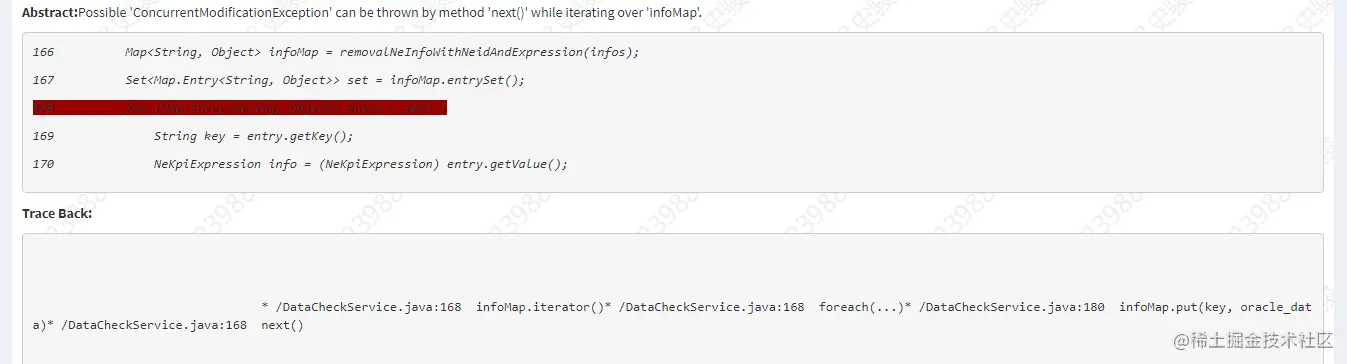
公司新来一个同事:为什么 HashMap 不能一边遍历一边删除?一下子把我问懵了!
前段时间,同事在代码中KW扫描的时候出现这样一条:上面出现这样的原因是在使用foreach对HashMap进行遍历时,同时进行put赋值操作会有问题,异常ConcurrentModificationException。于是帮同简单的看了一下,印象中集合类在进行遍历时同时进行删除或者添加操作时需要谨慎,一般使用迭代器进行操作。于是告诉同事,应该使用迭代器Iterator来对集合元素进行操作。同事问我为什么?这一下子把我问蒙了?对啊,只是记得这样用不可以,但是好像自己从来没有细究过为什么?
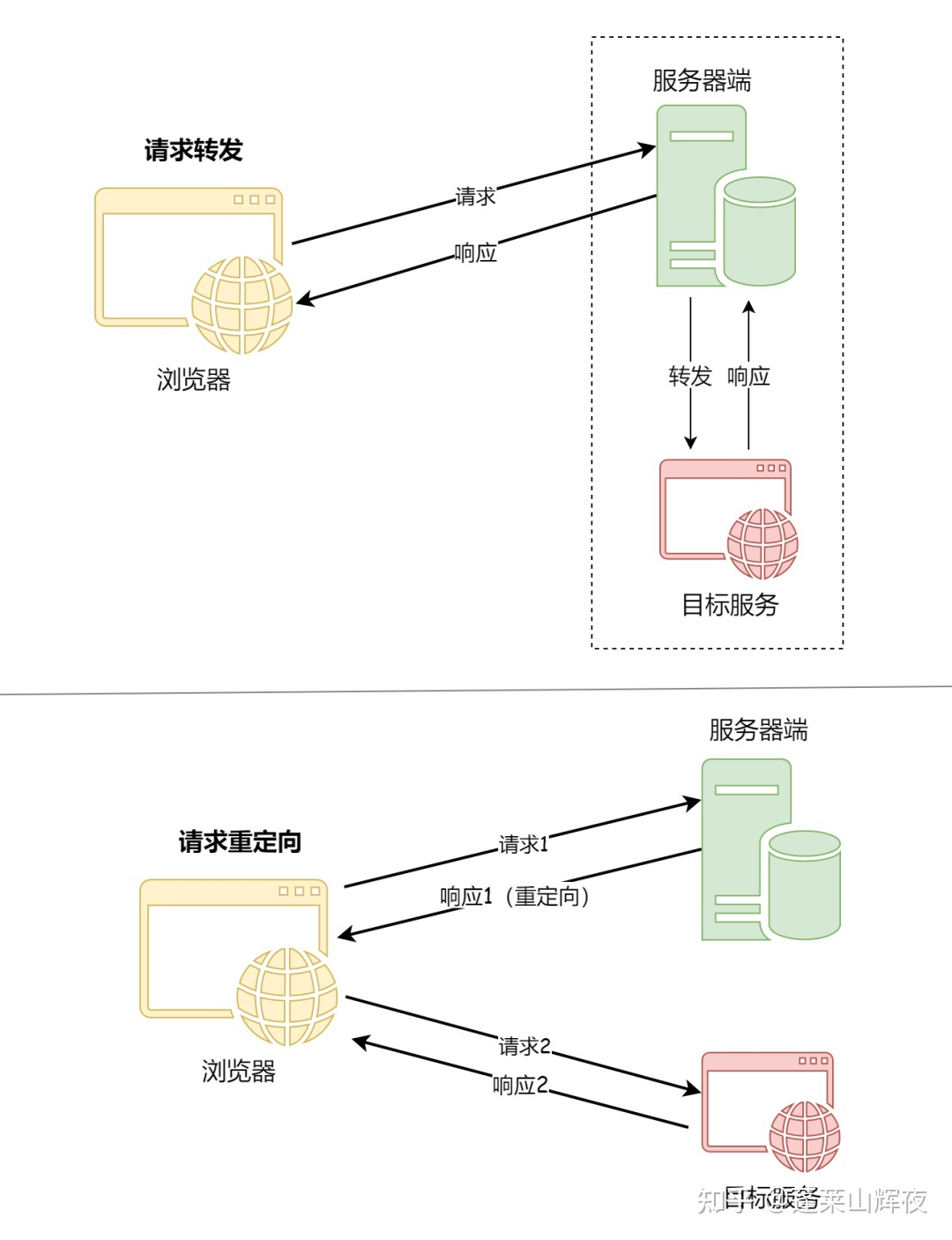
SpringBoot请求转发与重定向
但是可能由于B网址相对于A网址过于复杂,这样搜索引擎就会觉得网址A对用户更加友好,因而在重定向之后任然显示旧的网址A,但是显示网址B的内容。在平常使用手机的过程当中,有时候会发现网页上会有浮动的窗口,或者访问的页面不是正常的页面,这就可能是运营商通过某种方式篡改了用户正常访问的页面。重定向,是指在Nginx中,重定向是指通过修改URL地址,将客户端的请求重定向到另一个URL地址的过程,Nginx中实现重定向的方式有多种,比如使用rewrite模块、return指令等。使用场景:在返回视图的前面加上。
SSO 单点登录和 OAuth2.0 有何区别?
此方法的缺点是它依赖于浏览器和会话状态,对于分布式或者微服务系统而言,可能需要在服务端做会话共享,但是服务端会话共享效率比较低,这不是一个好的方案。在单点登录的上下文中,OAuth 可以用作一个中介,用户在一个“授权服务器”上登录,并获得一个访问令牌,该令牌可以用于访问其他“资源服务器”上的资源。首先,SSO 主要关注用户在多个应用程序和服务之间的无缝切换和保持登录状态的问题。这种方法通过将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。
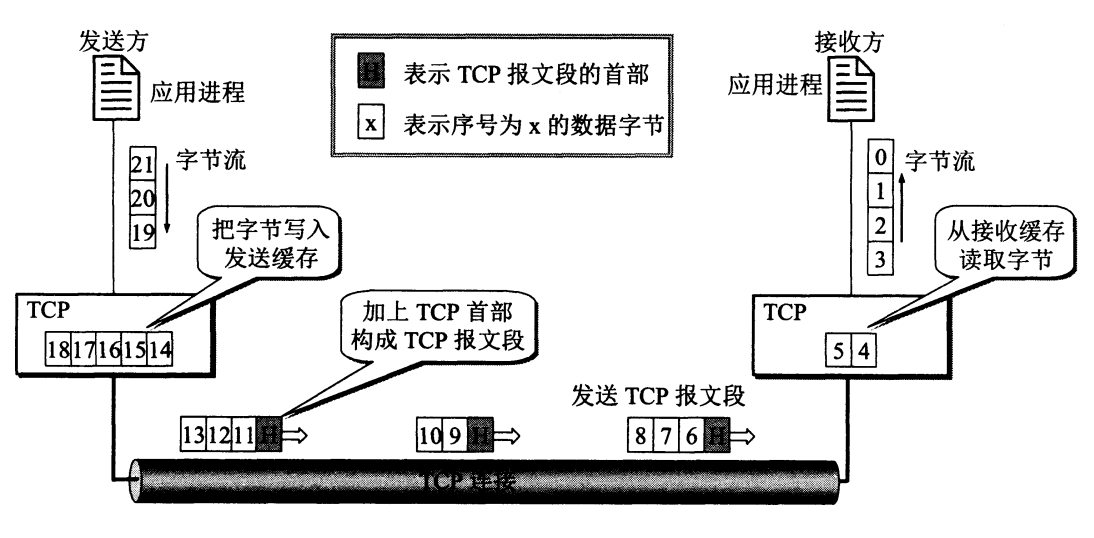
TCP协议-TCP连接管理
TCP协议是 TCP/IP 协议族中一个非常重要的协议。它是一种面向连接、提供可靠服务、面向字节流的传输层通信协议。TCP(Transmission Control Protocol,传输控制协议)。

接口响应慢?那是你没用 CompletableFuture 来优化!
大多数程序员在平时工作中,都是增删改查。这里我跟大家讲解如何利用CompletableFuture优化项目代码,使项目性能更佳!
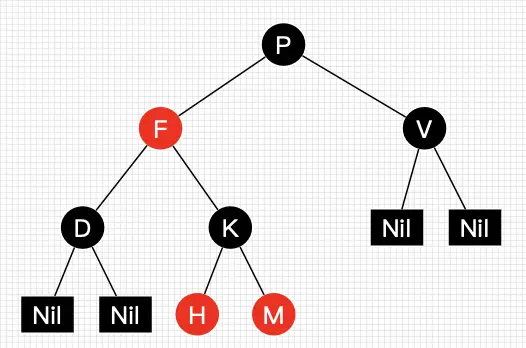
30张图带你彻底理解红黑树
当在10亿数据进行不到30次比较就能查找到目标时,不禁感叹编程之魅力!人类之伟大呀!—— 学红黑树有感。终于,在学习了几天的红黑树相关的知识后,我想把我所学所想和所感分享给大家。红黑树是一种比较难的数据结构,要完全搞懂非常耗时耗力,红黑树怎么自平衡?什么时候需要左旋或右旋?插入和删除破坏了树的平衡后怎么处理?等等一连串的问题在学习前困扰着我。如果你在学习过程中也会存在我的疑问,那么本文对你会有帮助,本文帮助你全面、彻底地理解红黑树!

为什么阿里巴巴修正了HashMap关于1024个元素扩容的次数?(典藏版)
此番修正主要是每个人对「扩容」定义存在了分歧,在JDK1.8中如果没有给HashMap设置初始容量,那么在第一次put()操作的时候会进行resize()。而有的人认为这算一次扩容,有的人认为这不是一次扩容,这只是HashMap容量的初始化。所以存储1024的元素时:前者的人认为扩容次数为8次。后者的人认为扩容次数为7次。孤尽老师说对此分歧,希望用没有「二义性」的语言来表示,所以「扩容次数」修正为「resize次数」。

强烈建议你不要再使用Date类了!!!
这里就不细说修改流程了,主要说一下我们在改造的时候遇到的一些问题。(Date从现在开始)是一个糟糕的类型,这解释了为什么它的大部分内容在 Java 1.1 中被弃用(但不幸的是仍在使用)。只能说这种基础的类改起来牵一发动全身,需要从DO实体类看起,然后就是各种Converter,最后是DTO。这个改造难度不高,但是复杂度非常高,一个地方没改好,轻则接口报错,重则启动失败,非常耗费精力,真不想改。我们要改的原因很简单,我们的代码缺陷扫描规则认为这是一个必须修改的缺陷,否则不给发布,不改不行,服了。
SpringBoot 中实现订单30分钟自动取消的策略
在电商和其他涉及到在线支付的应用中,通常需要实现一个功能:如果用户在生成订单后的一定时间内未完成支付,系统将自动取消该订单。本文将详细介绍基于Spring Boot框架实现订单30分钟内未支付自动取消的几种方案,并提供实例代码。

计算机网络TCP/IP协议-从双绞线到TCP
消息响应也是同理,这种带端口的消息发送方式,其实就是UDP协议,UDP简单粗暴,但是UDP存在很多问题,所以我们需要设计一个稳定可靠的协议,TCP协议,首先,网络是不稳定的,我们发送的消息很有可能会在中途丢失,所以需要设置重试机制,当消息发送失败时重新发送,为了判断是否成功,还需要要求接收方收到消息后,必须发送确认消息,这样就可以保证消息必达,另外大段的内容发送,很容易造成部分丢失,导致全部内容都要重新发送,于是我们可以将数据分包,分成多个包发送。到这,也行你会发现了,演示中的IP地址是怎么设置的呢?

自定义参数解析器,减少10%的代码
*** 赋值调用方法* 如果为空,默认调用name()方法* 该方法必须是一个不含参数的方法,否则将会调用失败* @return*/value() : value用于绑定请求参数和方法参数名一致时的对应关系。比如user?statusNo=1。方法的参数写法如下:getUser(@EnumParam(value=“statusNo”) int status) 或者 getUser(@EnumParam() int statusNo)valueMethod() : 赋值时调用枚举中的方法。

微服务全做错了!谷歌提出新方法,成本直接降9倍!
一位DataDog的客户收到6500万美元的云监控账单的消息,也再次让业界无数人惊到了。事实上有些团队在将集中式单体应用拆分为微服务时,首先进行的往往不是建立领域模型,而只是按照业务功能将原来单体应用的一个软件包拆分成多个所谓的“微服务”软件包,而这些“微服务”内的代码高度耦合,逻辑边界不清晰,长期以来,不管大厂还是小厂,微服务都被认为是云原生服务应用程序架构的事实标准,然而2023,不止那位37signals的DHH决心下云,放弃微服务,就连亚马逊和谷歌等这些云巨头,正在带头开始革了微服务的命。
Graphics2D API:Canvas操作
在中已经介绍了Canvas基本的绘图方法,本篇介绍一些基本的画布操作.注意:1、画布操作针对的是画布,而不是画布上的图形2、画布变换、裁剪影响后续图形的绘制,对之前已经绘制过的内容没有影响。
Java8 以后的 LocalDateTime,你真的会用吗?
本文从 LocalDateTime 类的创建、转换、格式化与解析、计算与比较以及其他操作几个方面详细介绍了 LocalDateTime 类在 Java 8 中的使用。掌握 LocalDateTime 类的使用可以大大提高日期时间处理效率和质量,希望本文对读者有所帮助。

我有一个朋友写出了17种触发NPE的代码!避免这些坑
在JUnit4中,使用Mockito框架时,any() 是一个参数匹配器,当与基本数据类型一起使用时,需要使用相应的类型特定的匹配器,例如使用anyInt() 而不是any()。要防范它,不在高超的编码技巧,在细。的可能性,却并不是万能的,比如开发者在使用Optional,不检查是否存在,直接调用Optional.get(),那么会得到一个NoSuchElementException。我有一个朋友,写代码的时候常常遭到NPE背刺,痛定思痛,总结了NPE出没的17个场景,哪一个你还没有遇到过?
一起学JDK源码 -- System类
System类是被final修饰的,不能被继承。

JVM优雅退出
在某个Java应用增加新功能,缩容机器,或者应用以及机器发生异常,通常会停止正在运行的应用,该应用通常正在运行着任务,如果停止应用的操作处理不当的话,很有可能会导致数据丢失,损坏,从而影响业务。所以在停止应用的时候,需要考虑如何安全优雅的退出。维护了所有已经注册的钩子,由于jvm本身没有提供好用的方法去移除已经注册的钩子,可以通过反射的方式调用。对于强制关闭的几种情况,会直接停止JVM进程,JVM不会调用已注册的。对于正常关闭、异常关闭的几种情况,JVM关闭前,都会调用已注册的。
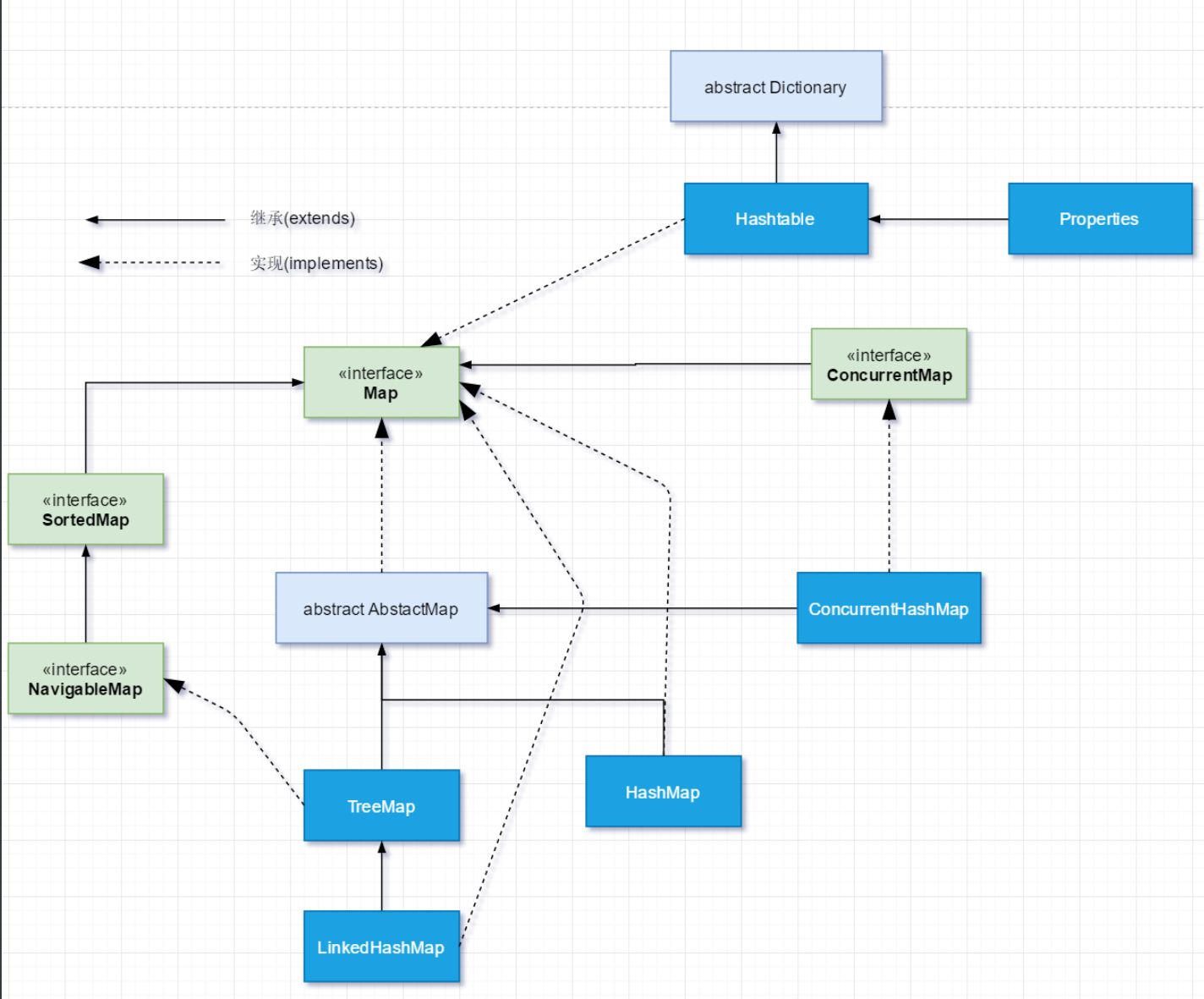
AbstractMap详解
/ 包:java.util// 包:java.util package java . util;Map.Entry;同 SimpleEntry 一样,都继承了 Map.Entry 和 序列化接口。

需要在method方法被调用之后,仅打印出a=100,b=200,请写出method方法的代码
通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。通常,此流对应于键盘输入或者由主机环境或用户指定的另一个输入源。public static final PrintStream err“标准”错误输出流。PrintStream 是打印输出流,它继承于FilterOutputStream。第二个用的是用的是char类型,根本不是方法,当要输出方法体的时候,会给你遍历数组。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。诡异的是,如果错了,面试官对你说了一句:你回去看看,