7min到40s:SpringBoot 启动优化实践
0 背景
公司 SpringBoot 项目在日常开发过程中发现服务启动过程异常缓慢,常常需要6-7分钟才能暴露端口,严重降低开发效率。通过 SpringBoot 的 SpringApplicationRunListener 、BeanPostProcessor 原理和源码调试等手段排查发现,在 Bean 扫描和 Bean 注入这个两个阶段有很大的性能瓶颈。
通过 JavaConfig 注册 Bean, 减少 SpringBoot 的扫描路径,同时基于 Springboot 自动配置原理对第三方依赖优化改造,将服务本地启动时间从7min 降至40s 左右的过程。 本文会涉及以下知识点:
- 基于 SpringApplicationRunListener 原理观察 SpringBoot 启动 run 方法;
- 基于 BeanPostProcessor 原理监控 Bean 注入耗时;
- SpringBoot Cache 自动化配置原理;
- SpringBoot 自动化配置原理及 starter 改造;
1 耗时问题排查
SpringBoot 服务启动耗时排查,目前有2个思路:
- 排查 SpringBoot 服务的启动过程;
- 排查 Bean 的初始化耗时;
1.1 观察 SpringBoot 启动 run 方法
该项目使用基于 SpringBoot 改造的内部微服务组件 XxBoot 作为服务端实现,其启动流程与 SpringBoot 类似,分为 ApplicationContext 构造和 ApplicationContext 启动两部分,即通过构造函数实例化 ApplicationContext 对象,并调用其 run 方法启动服务:
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
public static ConfigurableApplicationContext run(Class<?>[] primarySources, String[] args) {
return new SpringApplication(primarySources).run(args);
}
ApplicationContext 对象构造过程,主要做了自定义 Banner 设置、应用类型推断、配置源设置等工作,不做特殊扩展的话,大部分项目都是差不多的,不太可能引起耗时问题。通过在 run 方法中打断点,启动后很快就运行到断点位置,也能验证这一点。
接下就是重点排查 run 方法的启动过程中有哪些性能瓶颈?SpringBoot 的启动过程非常复杂,庆幸的是 SpringBoot 本身提供的一些机制,将 SpringBoot 的启动过程划分了多个阶段,这个阶段划分的过程就体现在 SpringApplicationRunListener 接口中,该接口将 ApplicationContext 对象的 run 方法划分成不同的阶段:
public interface SpringApplicationRunListener {
// run 方法第一次被执行时调用,早期初始化工作
void starting();
// environment 创建后,ApplicationContext 创建前
void environmentPrepared(ConfigurableEnvironment environment);
// ApplicationContext 实例创建,部分属性设置了
void contextPrepared(ConfigurableApplicationContext context);
// ApplicationContext 加载后,refresh 前
void contextLoaded(ConfigurableApplicationContext context);
// refresh 后
void started(ConfigurableApplicationContext context);
// 所有初始化完成后,run 结束前
void running(ConfigurableApplicationContext context);
// 初始化失败后
void failed(ConfigurableApplicationContext context, Throwable exception);
}
目前,SpringBoot 中自带的 SpringApplicationRunListener 接口只有一个实现类:EventPublishingRunListener,该实现类作用:通过观察者模式的事件机制,在 run 方法的不同阶段触发 Event 事件,ApplicationListener 的实现类们通过监听不同的 Event 事件对象触发不同的业务处理逻辑。
通过自定义实现
ApplicationListener实现类,可以在 SpringBoot 启动的不同阶段,实现一定的处理,可见SpringApplicationRunListener接口给SpringBoot带来了扩展性。
这里我们不必深究实现类 EventPublishingRunListener 的功能,但是可以通过 SpringApplicationRunListener 原理,添加一个自定义的实现类,在不同阶段结束时打印下当前时间,通过计算不同阶段的运行时间,就能大体定位哪些阶段耗时比较高,然后重点排查这些阶段的代码。
先看下 SpringApplicationRunListener 的实现原理,其划分不同阶段的逻辑体现在 ApplicationContext 的 run 方法中:
public ConfigurableApplicationContext run(String... args) {
...
// 加载所有 SpringApplicationRunListener 的实现类
SpringApplicationRunListeners listeners = getRunListeners(args);
// 调用了 starting
listeners.starting();
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
// 调用了 environmentPrepared
ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
configureIgnoreBeanInfo(environment);
Banner printedBanner = printBanner(environment);
context = createApplicationContext();
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class, new Class[] { ConfigurableApplicationContext.class }, context);
// 内部调用了 contextPrepared、contextLoaded
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
refreshContext(context);
afterRefresh(context, applicationArguments);
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);
}
// 调用了 started
listeners.started(context);
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
// 内部调用了 failed
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
// 调用了 running
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}
run 方法中 getRunListeners(args) 通过 SpringFactoriesLoader 加载 classpath 下 META-INF/spring.factotries 中配置的所有 SpringApplicationRunListener 的实现类,通过反射实例化后,存到局部变量 listeners 中,其类型为 SpringApplicationRunListeners;然后在 run 方法不同阶段通过调用 listeners 的不同阶段方法来触发 SpringApplicationRunListener 所有实现类的阶段方法调用。
因此,只要编写一个 SpringApplicationRunListener 的自定义实现类,在实现接口不同阶段方法时,打印当前时间;并在 META-INF/spring.factotries 中配置该类后,该类也会实例化,存到 listeners 中;在不同阶段结束时打印结束时间,以此来评估不同阶段的执行耗时。
在项目中添加实现类 MySpringApplicationRunListener :
@Slf4j
public class MySpringApplicationRunListener implements SpringApplicationRunListener {
// 这个构造函数不能少,否则反射生成实例会报错
public MySpringApplicationRunListener(SpringApplication sa, String[] args) {
}
@Override
public void starting() {
log.info("starting {}", LocalDateTime.now());
}
@Override
public void environmentPrepared(ConfigurableEnvironment environment) {
log.info("environmentPrepared {}", LocalDateTime.now());
}
@Override
public void contextPrepared(ConfigurableApplicationContext context) {
log.info("contextPrepared {}", LocalDateTime.now());
}
@Override
public void contextLoaded(ConfigurableApplicationContext context) {
log.info("contextLoaded {}", LocalDateTime.now());
}
@Override
public void started(ConfigurableApplicationContext context) {
log.info("started {}", LocalDateTime.now());
}
@Override
public void running(ConfigurableApplicationContext context) {
log.info("running {}", LocalDateTime.now());
}
@Override
public void failed(ConfigurableApplicationContext context, Throwable exception) {
log.info("failed {}", LocalDateTime.now());
}
}
这边 (SpringApplication sa, String[] args) 参数类型的构造函数不能少,因为源码中限定了使用该参数类型的构造函数反射生成实例。
在 resources 文件下的 META-INF/spring.factotries 文件中配置上该类:
# Run Listeners
org.springframework.boot.SpringApplicationRunListener=\
com.xxx.ad.diagnostic.tools.api.MySpringApplicationRunListener
run方法中是通过getSpringFactoriesInstances方法来获取META-INF/spring.factotries下配置的SpringApplicationRunListener的实现类,其底层是依赖SpringFactoriesLoader来获取配置的类的全限定类名,然后反射生成实例;
这种方式在 SpringBoot 用的非常多,如EnableAutoConfiguration、ApplicationListener、ApplicationContextInitializer等。
重启服务,观察 MySpringApplicationRunListener 的日志输出,发现主要耗时都在 contextLoaded 和 started 两个阶段之间,在这两个阶段之间调用了2个方法:refreshContext 和 afterRefresh 方法,而 refreshContext 底层调用的是 AbstractApplicationContext#refresh,Spring 初始化 context 的核心方法之一就是这个 refresh。

至此基本可以断定,高耗时的原因就是在初始化 Spring 的 context,然而这个方法依然十分复杂,好在 refresh 方法也将初始化 Spring 的 context 的过程做了整理,并详细注释了各个步骤的作用:

通过简单调试,很快就定位了高耗时的原因:
- 在
invokeBeanFactoryPostProcessors(beanFactory)方法中,调用了所有注册的BeanFactory的后置处理器; - 其中,
ConfigurationClassPostProcessor这个后置处理器贡献了大部分的耗时; - 查阅相关资料,该后置处理器相当重要,主要负责
@Configuration、@ComponentScan、@Import、@Bean等注解的解析; - 继续调试发现,主要耗时都花在主配置类的
@ComponentScan解析上,而且主要耗时还是在解析属性basePackages;

即项目主配置类上 @SpringBootApplication 注解的 scanBasePackages 属性:

通过该方法 JavaDoc、查看相关代码,大体了解到该过程是在递归扫描、解析 basePackages 所有路径下的 class,对于可作为 Bean 的对象,生成其 BeanDefinition;如果遇到 @Configuration 注解的配置类,还得递归解析其 @ComponentScan。 至此,服务启动缓慢的原因就找到了:
- 作为数据平台,我们的服务引用了很多第三方依赖服务,这些依赖往往提供了对应业务的完整功能,所以提供的 jar 包非常大;
- 扫描这些包路径下的 class 非常耗时,很多 class 都不提供 Bean,但还是花时间扫描了;
- 每添加一个服务的依赖,都会线性增加扫描的时间;
弄明白耗时的原因后,我有2个疑问:
- 是否所有的 class 都需要扫描,是否可以只扫描那些提供 Bean 的 class?
- 扫描出来的 Bean 是否都需要?我只接入一个功能,但是注入了所有的 Bean,这似乎不太合理?
1.2 监控 Bean 注入耗时
第二个优化的思路是监控所有 Bean 对象初始化的耗时,即每个 Bean 对象实例化、初始化、注册所花费的时间,有没有特别耗时 Bean 对象?
同样的,我们可以利用 SpringBoot 提供了 BeanPostProcessor 接口来监控 Bean 的注入耗时,BeanPostProcessor 是 Spring 提供的 Bean 初始化前后的 IOC 钩子,用于在 Bean 初始化的前后执行一些自定义的逻辑:
public interface BeanPostProcessor {
// 初始化前
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
// 初始化后
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
对于 BeanPostProcessor 接口的实现类,其前后置处理过程体现在 AbstractAutowireCapableBeanFactory#doCreateBean,这也是 Spring 中非常重要的一个方法,用于真正实例化 Bean 对象,通过 BeanFactory#getBean 方法一路 Debug 就能找到。在该方法中调用了 initializeBean 方法:
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
...
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 应用所有 BeanPostProcessor 的前置方法
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
// 应用所有 BeanPostProcessor 的后置方法
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
通过 BeanPostProcessor 原理,在前置处理时记录下当前时间,在后置处理时,用当前时间减去前置处理时间,就能知道每个 Bean 的初始化耗时,下面是我的实现:
@Component
public class TimeCostBeanPostProcessor implements BeanPostProcessor {
private Map<String, Long> costMap = Maps.newConcurrentMap();
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
costMap.put(beanName, System.currentTimeMillis());
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (costMap.containsKey(beanName)) {
Long start = costMap.get(beanName);
long cost = System.currentTimeMillis() - start;
if (cost > 0) {
costMap.put(beanName, cost);
System.out.println("bean: " + beanName + "\ttime: " + cost);
}
}
return bean;
}
}
BeanPostProcessor 的逻辑是在 Beanfactory 准备好后处理的,就不需要通过 SpringFactoriesLoader 加载了,直接 @Component 注入即可。
重启服务,通过以上方法排查 Bean 初始化过程,还真的有所发现:  这个 Bean 初始化耗时43s,具体看下这个 Bean 的初始化方法,发现会从数据库查询大量配置元数据,并更新到 Redis 缓存中,所以初始化非常慢:
这个 Bean 初始化耗时43s,具体看下这个 Bean 的初始化方法,发现会从数据库查询大量配置元数据,并更新到 Redis 缓存中,所以初始化非常慢:

另外,还发现了一些非项目自身服务的service、controller对象,这些 Bean 来自于第三方依赖:UPM服务,项目中并不需要:

其实,原因上文已经提到:我只接入一个功能,但我注入了该服务路径下所有的 Bean,也就是说,服务里注入其他服务的、对自身无用的 Bean。
2 优化方案
2.1 如何解决扫描路径过多?
想到的解决方案比较简单粗暴:
梳理要引入的 Bean,删掉主配置类上扫描路径,使用 JavaConfig 的方式显式手动注入。
以 UPM 的依赖为例,之前的注入方式 是,项目依赖其 UpmResourceClient 对象,Pom 已经引用了其 Maven 坐标,并在主配置类上的 scanBasePackages 中添加了其服务路径:“com.xxx.ad.upm”,通过扫描整个服务路径下的 class,找到 UpmResourceClient 并注入,因为该类注解了 @Service,因此会注入到服务的 Spring 上下文中,UpmResourceClient 源码片段及主配置类如下:


使用 JavaConfig 的改造方式是:不再扫描 UPM 的服务路径,而是主动注入。删除"com.xxx.ad.upm",并在服务路径下添加以下配置类:
@Configuration
public class ThirdPartyBeanConfig {
@Bean
public UpmResourceClient upmResourceClient() {
return new UpmResourceClient();
}
}
Tips:如果该 Bean 还依赖其他 Bean,则需要把所依赖的 Bean 都注入; 针对 Bean 依赖情况复杂的场景梳理起来就比较麻烦了,所幸项目用到的服务 Bean 依赖关系都比较简单,一些依赖关系复杂的服务,观察到其路径扫描耗时也不是很高,就不处理了。
同时,通过 JavaConfig 按需注入的方式,就不存在冗余 Bean 的情况了,也有利于降低服务的内存消耗;解决了上面的引入无关的 upmService、upmController 的问题。
2.2 如何解决 Bean 初始化高耗时?
Bean 初始化耗时高,就需要 case by case 地处理了,比如项目中遇到的初始化配置元数据的问题,可以考虑通过将该任务提交到线程池的方式异步处理或者懒加载的方式来解决。
3 新的问题
完成以上优化后,本地启动时间从之前的 7min 左右降低至 40s,效果还是非常显著的。本地自测通过后,便发布到预发进行验证,验证过程中,有同学发现项目接入的 Redis 缓存组件失效了。
该组件接入方式与上文描述的接入方式类似,通过添加扫描服务的根路径"com.xxx.ad.rediscache",注入对应的 Bean 对象;查看该缓存组件项目的源码,发现该路径下有一个 config 类注入了一个缓存管理对象 CacheManager,其实现类是 RedisCacheManager:

缓存组件代码片段:

本次优化中,我是通过 每次删除一条扫描路径,启动服务后根据启动日志中 Bean 缺失错误的信息,来逐个梳理、添加依赖的 Bean,保证服务正常启动 的方式来改造的,而删除"com.xxx.ad.rediscache"后启动服务并无异常,因此就没有进一步的操作,直接上预发验证了。这就奇怪了,既然不扫描该组件的业务代码根路径,也就没有执行注入该组件中定义的 CacheManager 对象,为啥用到缓存的地方没有报错呢?
尝试在未添加扫描路径的情况下,从 ApplicationContext 中获取 CacheManager 类型的对象看下是否存在?结果发现确实存在 RedisCacheManager 对象:

其实,前面的分析并没有错,删除扫描路径后生成的 RedisCacheManager 并不是缓存组件代码中配置的,而是 SpringBoot 的自动化配置生成的,也就是说该对象并不是我们想要的对象,是不符合预期的,下文介绍其原因。
3.1 SpringBoot 自动化装配,让人防不胜防
查阅 SpringBoot Cache 相关资料,发现 SpringBoot Cache 做了一些自动推断和注入的工作,原来是 SpringBoot 自动化装配的锅呀,接下来就分析下 SpringBoot Cache 原理,明确出现以上问题的原因。
SpringBoot 自动化配置,体现在主配置类上复合注解 @SpringBootApplication 中的@EnableAutoConfiguration 上,该注解开启了 SpringBoot 的自动配置功能。该注解中的@Import(AutoConfigurationImportSelector.class) 通过加载 META-INF/spring.factotries 下配置一系列 *AutoConfiguration 配置类,根据现有条件推断,尽可能地为我们配置需要的 Bean。这些配置类负责各个功能的自动化配置,其中用于 SpringBoot Cache 的自动配置类是 CacheAutoConfiguration,接下来重点分析这个配置类就行了。

@SpringBootApplication复合注解中集成了三个非常重要的注解:@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan,其中@EnableAutoConfiguration就是负责开启自动化配置功能;
SpringBoot 中有多@EnableXXX的注解,都是用来开启某一方面的功能,其实现原理也是类似的:通过@Import筛选、导入满足条件的自动化配置类。
可以看到 CacheAutoConfiguration 上有许多注解,重点关注下@Import({CacheConfigurationImportSelector.class}),CacheConfigurationImportSelector 实现了 ImportSelector 接口,该接口用于动态选择想导入的配置类,这个 CacheConfigurationImportSelector 用来导入不同类型的 Cache 的自动配置类:

通过调试 CacheConfigurationImportSelector 发现,根据 SpringBoot 支持的缓存类型(CacheType),提供了10种 cache 的自动配置类,按优先级排序,最终只有一个生效,而本项目中恰恰就是 RedisCacheConfiguration,其内部提供的是 RedisCacheManager,和引入第三方缓存组件一样,所以造成了困惑: 
看下 RedisCacheConfiguration 的实现:  这个配置类上有很多条件注解,当这些条件都满足的话,这个自动配置类就会生效,而本项目恰恰都满足,同时项目主配置类上还加上了
这个配置类上有很多条件注解,当这些条件都满足的话,这个自动配置类就会生效,而本项目恰恰都满足,同时项目主配置类上还加上了 @EnableCaching,开启了缓存功能,即使缓存组件没生效,SpringBoot 也会自动生成一个缓存管理对象;
即:缓存组件服务扫描路径存在的话,缓存组件中的代码生成缓存管理对象,@ConditionalOnMissingBean(CacheManager.class) 失效;扫描路径不存在的话,SpringBoot 通过推断,自动生成一个缓存管理对象。
这个也很好验证,在 RedisCacheConfiguration 中打断点,不删除扫描路径是走不到这边的SpringBoot 自动装配过程的(缓存组件显式生成过了),删除了扫描路径是能走到的(SpringBoot 自动生成)。
上文多次提到@Import,这是 SpringBoot 中重要注解,主要有以下作用:
1、导入@Configuration注解的类;
2、导入实现了ImportSelector或ImportBeanDefinitionRegistrar的类;
3、导入普通的 POJO。
3.2 使用 starter 机制,开箱即用
了解缓存失效的原因后,就有解决的办法了,因为是自己团队的组件,就没必要通过 JavaConfig 显式手动导入的方式改造,而是通过 SpringBoot 的 starter 机制,优化下缓存组件的实现,可以做到自动注入、开箱即用。 只要改造下缓存组件的代码,在 resources 文件中添加一个 META-INF/spring.factotries 文件,在下面配置一个 EnableAutoConfiguration 即可,这样项目在启动时也会扫描到这个 jar 中的 spring.factotries 文件,将 XxxAdCacheConfiguration 配置类自动引入,而不需要扫描"com.xxx.ad.rediscache"整个路径了:
# EnableAutoConfigurations
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.xxx.ad.rediscache.XxxAdCacheConfiguration
SpringBoot 的
EnableAutoConfiguration自动配置原理还是比较复杂的,在加载自动配置类前还要先加载自动配置的元数据,对所有自动配置类做有效性筛选,具体可查阅 EnableAutoConfiguration 相关代码;
4 参考
相关文章:

SpringCloud Alibaba集成 Gateway(自定义负载均衡器)、Nacos(配置中心、注册中心)、Loadbalancer
要为未被某些网关路由谓词处理的请求提供相同的CORS配置,请将属性spring.cloud.gateway.globalcors.add-to-simple-url-handler-mapping设置为true。断言(Predicate):Java8中的断言函数,Spring Cloud Gateway中的断言函数输入类型是 Spring5.0框架中的ServerWebExchange。对于所有GET请求的路径,来自docs.spring.io的请求都将允许CORS请求。
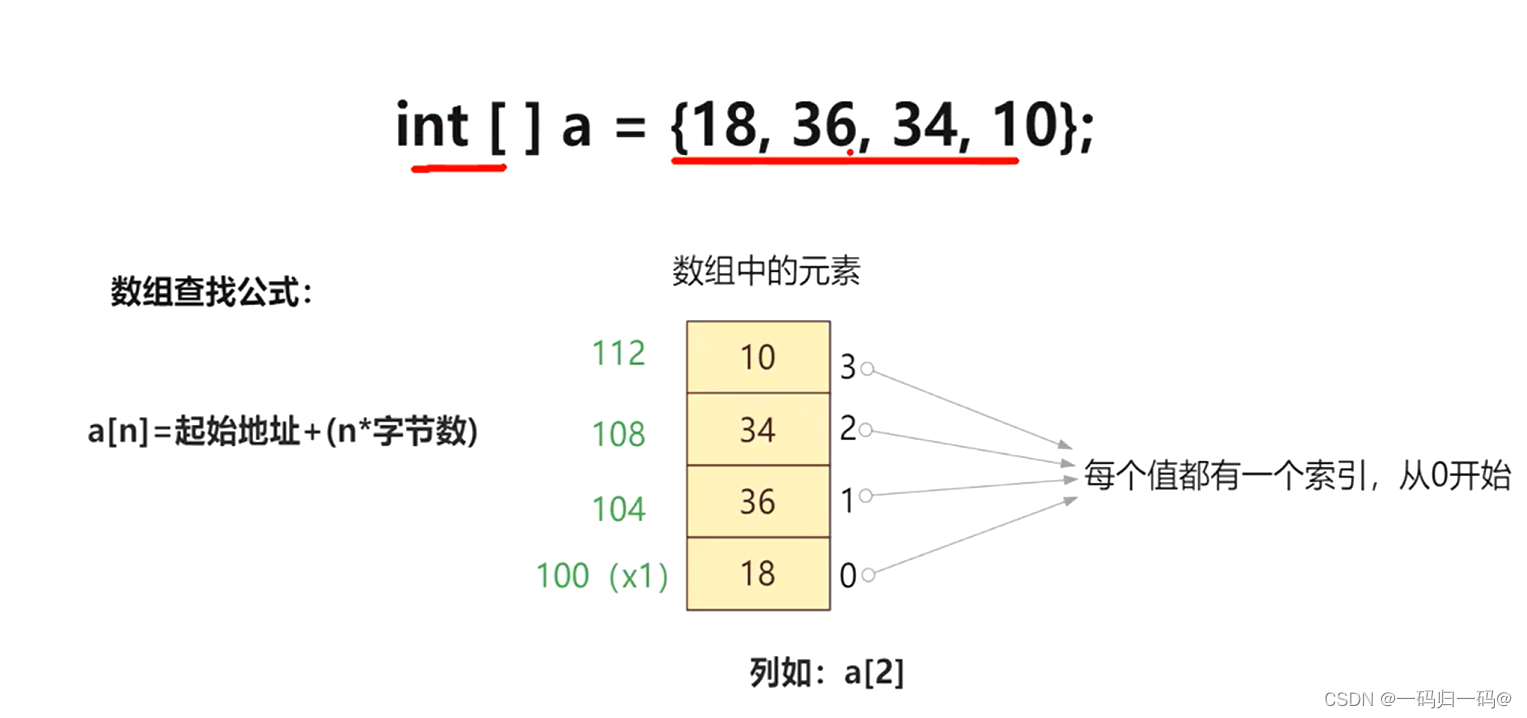
并发编程下的集合:数组寻址、LinkedList、HashMap、ConcurrentHashMap
如果发现hash取模后的数组索引位下无元素则直接新增,若不是空那就说明存在hash冲突,则判断数组索引位链表结构中的第一个元素的key以及hash值是否与新的key一致则直接覆盖,若不一致则判断当前的数组索引下的链表结构是否为红黑树,若为红黑树则走红黑树的新增方法,若不为红黑树则遍历当前链表结构,遍历中发现某个节点元素的next为null是则直接将新元素指针与next进行关联,若在遍历到next为空前判断到,某个节点的key以及key的hash值与新的key与新的keyhash值一致时则走覆盖。

【日常开发之插件篇】IDEA plugins 神器助我!!
今早因为老代码的一些bug让我突然觉得Idea的一些插件特别好用,我准备将我平时所用到的一些插件做个推荐以及记录。

【日常开发之FTP】Windows开启FTP、Java实现FTP文件上传下载
FTP是一个专门进行文件管理的操作服务,一般来讲可以在任意的操作系统之中进行配置,但是如果考虑到简便性,一般来讲可以直接在Linux系统下进行安装。FTP (File Transfer Protocol、文件传输协议)是TCP/IP协议中的一部分,属于应用层协议。使用FTP最主要的功能是对文件进行管理,所以在FTP内部对于文件支持有两种传输模式:文本模式(ASCII、默认)和二进制模式(Binary),通常文本文件使用ASCIl模式,而对于图片、视频、声音、压缩等文件则会使用二进制的方式进行传输。

【Linux之升华篇】Linux内核锁、用户模式与内核模式、用户进程通讯方式
alloc_pages(gfp_mask, order),_ _get_free_pages(gfp_mask, order)等。字符设备描述符 struct cdev,cdev_alloc()用于动态的分配 cdev 描述符,cdev_add()用于注。外,还支持语义符合 Posix.1 标准的信号函数 sigaction(实际上,该函数是基于 BSD 的,BSD。从最初的原子操作,到后来的信号量,从。(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的。

【Mongdb之数据同步篇】什么是Oplog、Mongodb 开启oplog,java监听oplog并写入关系型数据库、Mongodb动态切换数据源
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。Oplog 可以说是Mongodb Replication的纽带了。
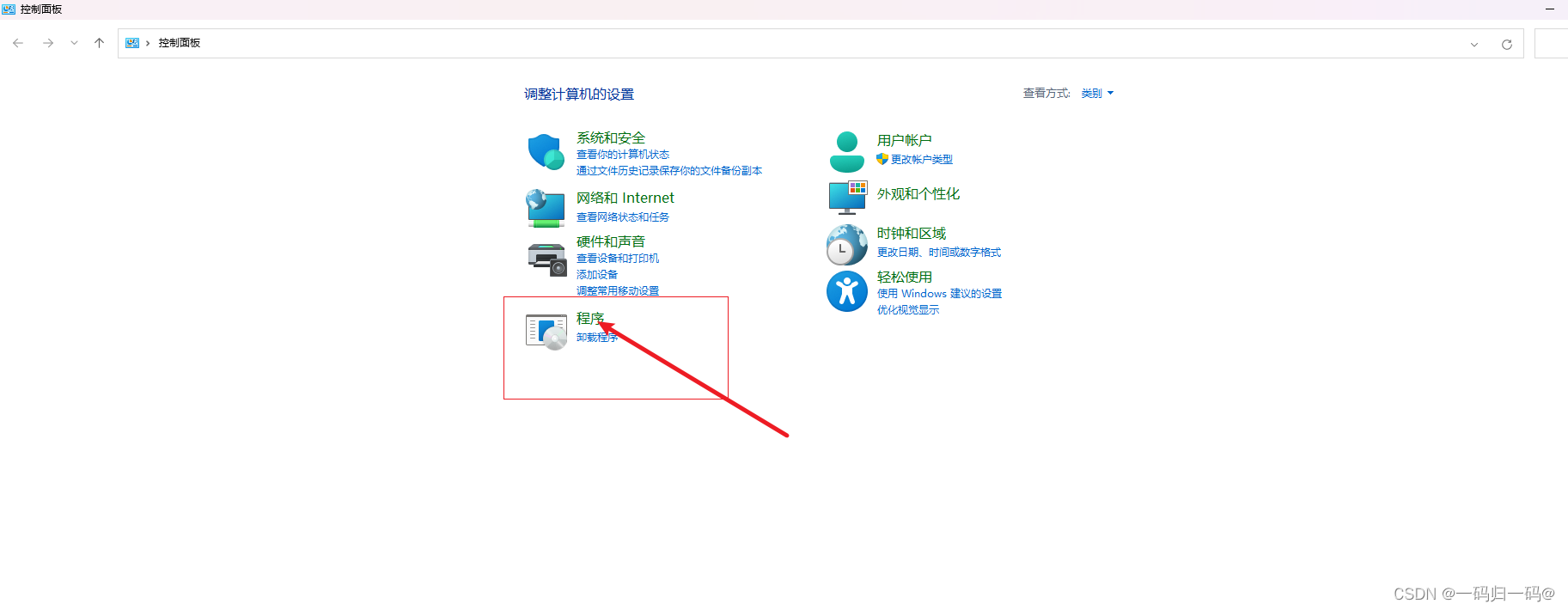
【日常开发之Windows共享文件】Java实现Windows共享文件上传下载
下拉框选择你选择的用户点击添加,然后共享确定。创建一个文件夹然后点击属性界面,点击共享。maven版本存在于SMB协议的兼容问题。首先开启服务,打开控制面板点击程序。点击启用或关闭Windows功能。我这边是专门创建了一个用户。SMB1.0选中红框内的。

CXFServlet类的作用
CXFServlet是Apache CXF框架中的一个核心组件,用于处理HTTP请求并将它们转换为Web服务调用。通过配置CXFServlet,你可以轻松地部署和管理SOAP和RESTful Web服务。
@Scheduled注解的scheduler属性什么作用
注解是 Spring Framework 提供的一种机制,用于定义计划任务,即周期性执行的任务。 注解可以应用于方法上,以指示 Spring 容器在特定的时间间隔或按照某种调度规则来调用该方法。 属性是 注解的一个可选属性,它的作用是允许开发者指定一个自定义的 对象来控制任务的调度方式。默认情况下, 注解使用 Spring 内部的 来执行任务,但如果需要更高级的定制化需求,可以通过 属性指定一个自定义的 实现。自定义调度器:共享调度器资源:高级调度需求:假设你想使用 作为调度器,并且希望所有带有
过滤器、拦截器、aop的先后顺序和作用范围&拦截器preHandle(),postHandle(),afterComplation()方法执行顺序
在Spring框架中,过滤器(Filter)、拦截器(Interceptor)和面向切面编程(AOP)都是用于处理请求和处理流程的组件,但它们的作用范围和触发时机有所不同。下面我会解释这三者的先后顺序和作用范围。执行顺序:请注意,这个顺序可能因具体的配置和使用的技术而有所不同。在实际应用中,建议根据项目的具体需求来合理配置和使用这些组件。拦截器执行流程图:实现拦截器需要实现这个接口,这个 接口中有三个默认方法,这三个方法的执行顺序:我们实现接口然后重写这三个方法,就会在对应的时机被自动执行。这里就是调用处理
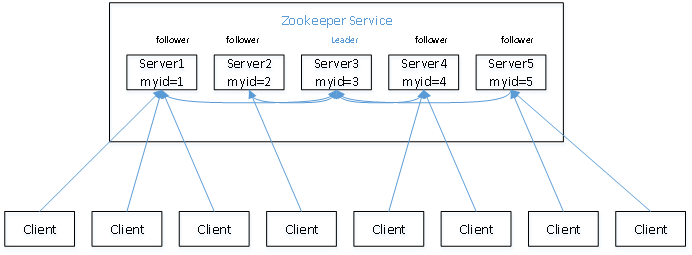
Zookeeper概要、协议、应用场景
Zoopkeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型,作为分布式系统的沟通调度桥梁。
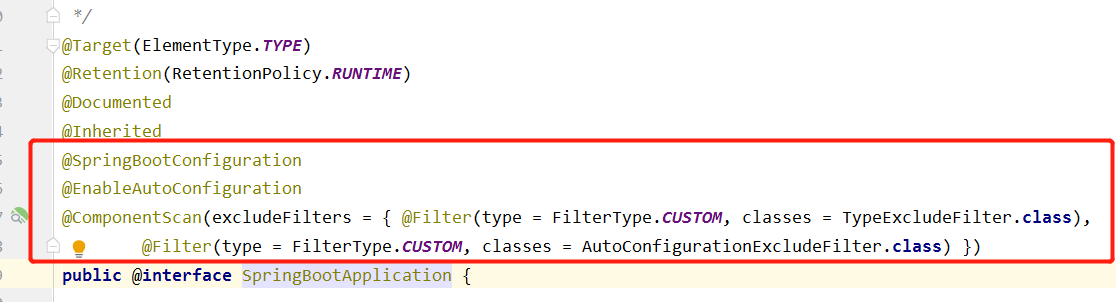
spring.factories文件的作用
即spring.factories文件是帮助spring-boot项目包以外的bean(即在pom文件中添加依赖中的bean)注册到spring-boot项目的spring容器中。在Spring Boot启动时,它会扫描classpath下所有的spring.factories文件,加载其中的自动配置类,并将它们注入到Spring ApplicationContext中,使得项目能够自动运行。spring.factories文件是Spring Boot自动配置的核心文件之一,它的作用是。
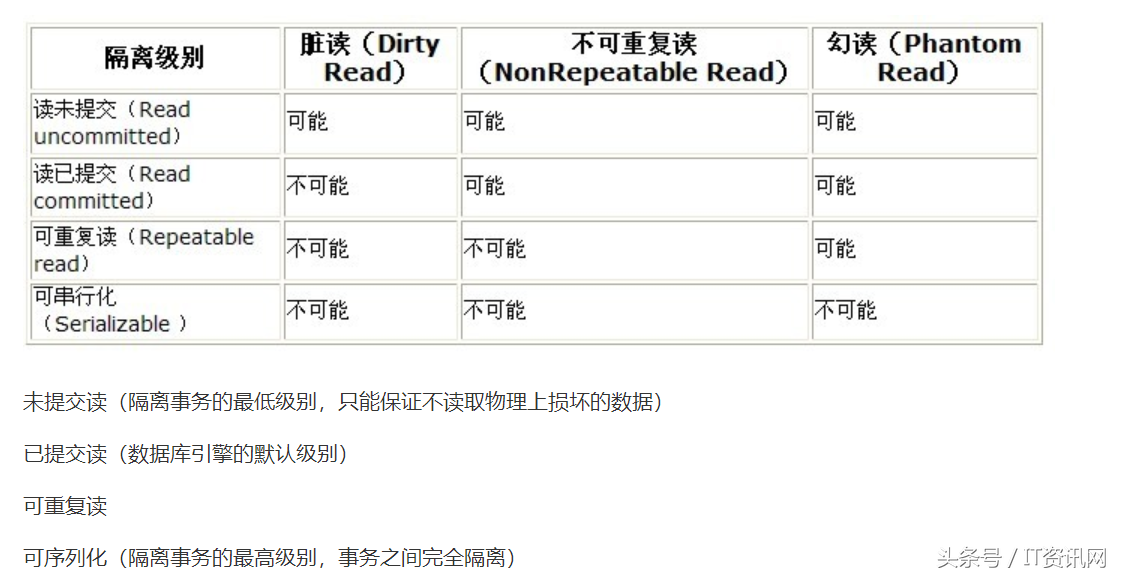
Spring事务七大传播机制与五个隔离级别,嵌套事务
如果当前方法正有一个事务在运行中,则该方法应该运行在一个嵌套事务中,被嵌套的事务可以独立于被封装的事务中进行提交或者回滚。如果封装事务存在,并且外层事务抛出异常回滚,那么内层事务必须回滚,反之,内层事务并不影响外层事务。当前方法必须在一个具有事务的上下文中运行,如有客户端有事务在进行,那么被调用端将在该事务中运行,否则的话重新开启一个事务。当前方法必须运行在它自己的事务中。一个新的事务将启动,而且如果有一个现有的事务在运行的话,则这个方法将在运行期被挂起,直到新的事务提交或者回滚才恢复执行。
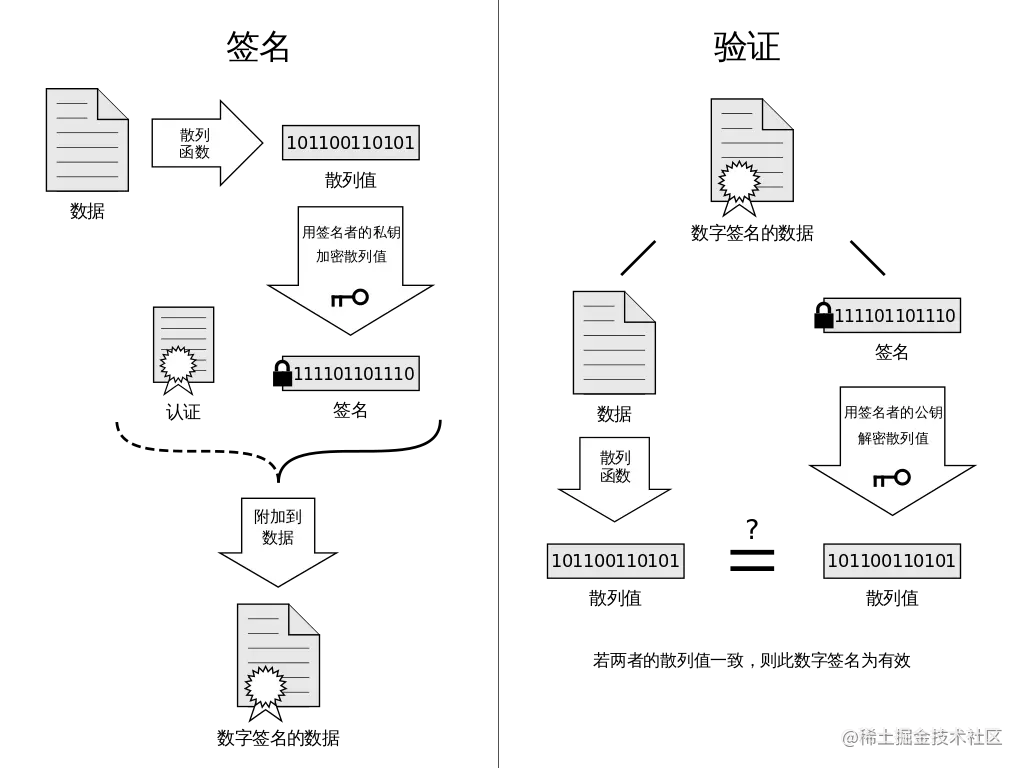
常见的七种加密算法及实现
**数字签名**、**信息加密** 是前后端开发都经常需要使用到的技术,应用场景包括了用户登入、交易、信息通讯、`oauth` 等等,不同的应用场景也会需要使用到不同的签名加密算法,或者需要搭配不一样的 **签名加密算法** 来达到业务目标。这里简单的给大家介绍几种常见的签名加密算法和一些典型场景下的应用。## 正文### 1. 数字签名**数字签名**,简单来说就是通过提供 **可鉴别** 的 **数字信息** 验证 **自身身份** 的一种方式。一套 **数字签名** 通常定义两种 **互补

SpringBoot系列教程之Bean之指定初始化顺序的若干姿势
之前介绍了@Order注解的常见错误理解,它并不能指定 bean 的加载顺序,那么问题来了,如果我需要指定 bean 的加载顺序,那应该怎么办呢?本文将介绍几种可行的方式来控制 bean 之间的加载顺序。

在Java中使用WebSocket
WebSocket是一种协议,用于在Web应用程序和服务器之间建立实时、双向的通信连接。它通过一个单一的TCP连接提供了持久化连接,这使得Web应用程序可以更加实时地传递数据。WebSocket协议最初由W3C开发,并于2011年成为标准。
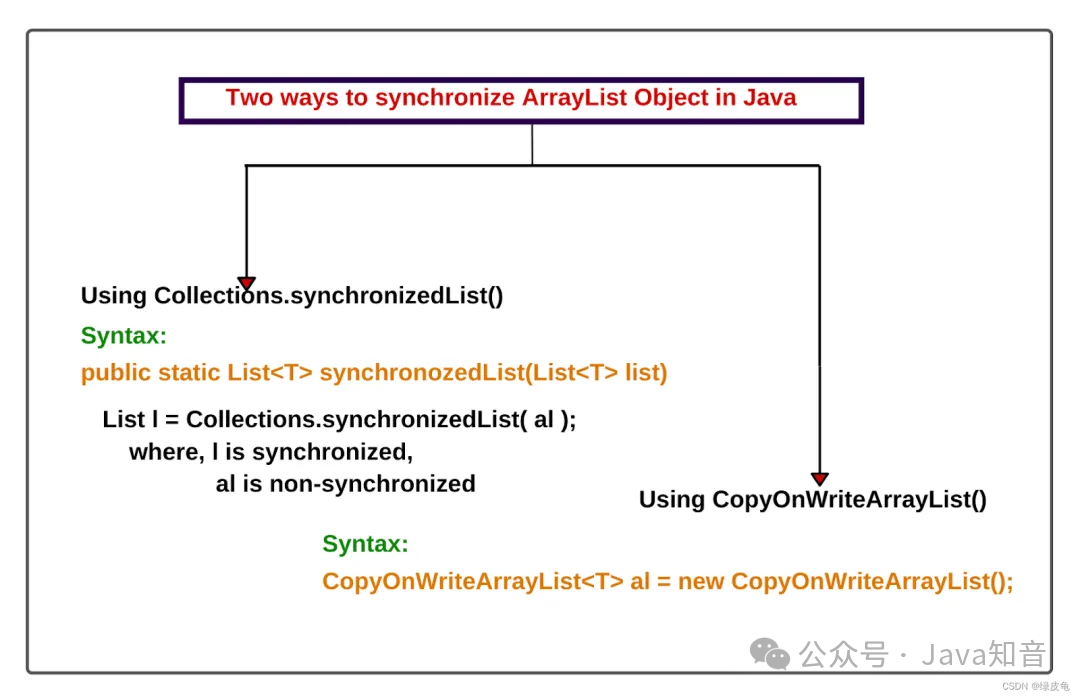
3种方案,模拟两个线程抢票
在多线程编程中,资源竞争是一个常见的问题。资源竞争发生在多个线程试图同时访问或修改共享资源时,可能导致数据不一致或其他并发问题。在模拟两个线程抢票的场景中,我们需要考虑如何公平地分配票,并确保每个线程都有机会成功获取票。本篇文章将通过三种方式来模拟两个线程抢票的过程,以展示不同的并发控制策略。使用 Synchronized 来确保一次只有一个线程可以访问票资源。使用 ReentrantLock 来实现线程间的协调。使用 Semaphore 来限制同时访问票的线程数量。
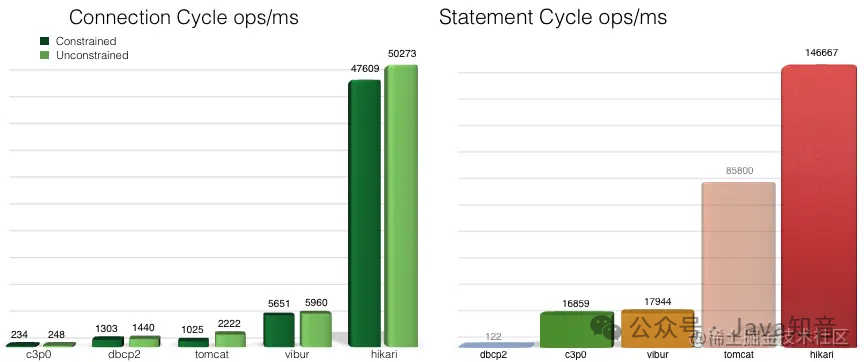
替代Druid,HakariCP 为什么这么快?
这次源码探究,真的感觉看到了无数个小细节,无数个小优化,积少成多。平时开发过程中,一些小的细节也一定要“扣”。
Java中volatile 的使用场景有哪些?
volatile是一种轻量级的同步机制,它能保证共享变量的可见性,同时禁止重排序保证了操作的有序性,但是它无法保证原子性。所以使用volatilevolatile。

JDK22 正式发布了 !
Java 22 除了推出了新的增强功能和特性,也获得 Java Management Service (JMS) 的支持,这是一项新的 Oracle 云基础设施远程软件服务(Oracle Cloud Infrastructure, OCI) 原生服务,提供统一的控制台和仪表盘,帮助企业管理本地或云端的 Java 运行时和应用。使包含运行时计算值的字符串更容易表达,简化 Java 程序的开发工作,同时提高将用户提供的值编写成字符串,并将字符串传递给其他系统的程序的安全性。支持开发人员自由地表达构造器的行为。
Jackson 用起来!
你可以创建自定义序列化器和反序列化器以自定义特定字段或类的序列化和反序列化行为。为此,请创建一个实现或接口的类,并在需要自定义的字段或类上使用和注解。@Override// ...其他代码...优势性能优异:Jackson在序列化和反序列化过程中表现出优秀的性能,通常比其他Java JSON库更快。灵活性:通过注解、自定义序列化器/反序列化器等功能,Jackson提供了丰富的配置选项,允许你根据需求灵活地处理JSON数据。易于使用:Jackson的API设计简洁明了,易于学习和使用。
拜托!别再滥用 ! = null 判空了!!
另外,也许受此习惯影响,他们总潜意识地认为,所有的返回都是不可信任的,为了保护自己程序,就加了大量的判空。如果你养成习惯,都是这样写代码(返回空collections而不返回null),你调用自己写的方法时,就能大胆地忽略判空)这种情况下,null是个”看上去“合理的值,例如,我查询数据库,某个查询条件下,就是没有对应值,此时null算是表达了“空”的概念。最终,项目中会存在大量判空代码,多么丑陋繁冗!,而不要返回null,这样调用侧就能大胆地处理这个返回,例如调用侧拿到返回后,可以直接。
详解Java Math类的toDegrees()方法:将参数从弧度转换为角度
Java Math 类的 toDegrees() 方法是将一个角度的弧度表示转换为其度表示,返回值为double类型,表示从弧度数转换而来的角度数。这就是Java Math 类的 toDegrees() 方法的攻略。我们已经了解了该方法的基本概念、语法、注意事项以及两个示例。希望这篇攻略对你有所帮助。

SpringBoot接口防抖(防重复提交)的一些实现方案
作为一名老码农,在开发后端Java业务系统,包括各种管理后台和小程序等。在这些项目中,我设计过单/多租户体系系统,对接过许多开放平台,也搞过消息中心这类较为复杂的应用,但幸运的是,我至今还没有遇到过线上系统由于代码崩溃导致资损的情况。这其中的原因有三点:一是业务系统本身并不复杂;二是我一直遵循某大厂代码规约,在开发过程中尽可能按规约编写代码;三是经过多年的开发经验积累,我成为了一名熟练工,掌握了一些实用的技巧。啥是防抖所谓防抖,一是防用户手抖,二是防网络抖动。
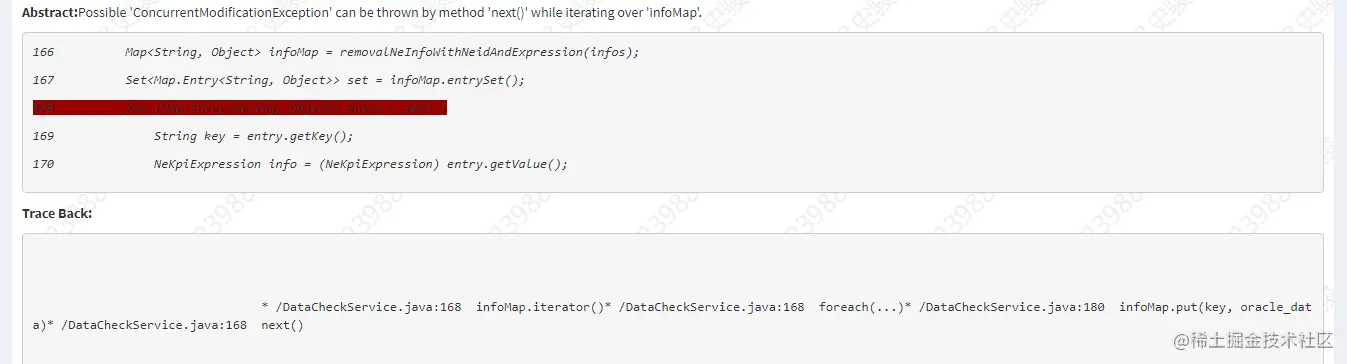
公司新来一个同事:为什么 HashMap 不能一边遍历一边删除?一下子把我问懵了!
前段时间,同事在代码中KW扫描的时候出现这样一条:上面出现这样的原因是在使用foreach对HashMap进行遍历时,同时进行put赋值操作会有问题,异常ConcurrentModificationException。于是帮同简单的看了一下,印象中集合类在进行遍历时同时进行删除或者添加操作时需要谨慎,一般使用迭代器进行操作。于是告诉同事,应该使用迭代器Iterator来对集合元素进行操作。同事问我为什么?这一下子把我问蒙了?对啊,只是记得这样用不可以,但是好像自己从来没有细究过为什么?
每天一个摆脱if-else工程师的技巧——优雅的参数校验
在日常的开发工作中,为了程序的健壮性,大部分方法都需要进行入参数据校验。最直接的当然是在相应方法内对数据进行手动校验,但是这样代码里就会有很多冗余繁琐的if-else。throw new IllegalArgumentException("用户姓名不能为空");throw new IllegalArgumentException("性别不能为空");throw new IllegalArgumentException("性别错误");
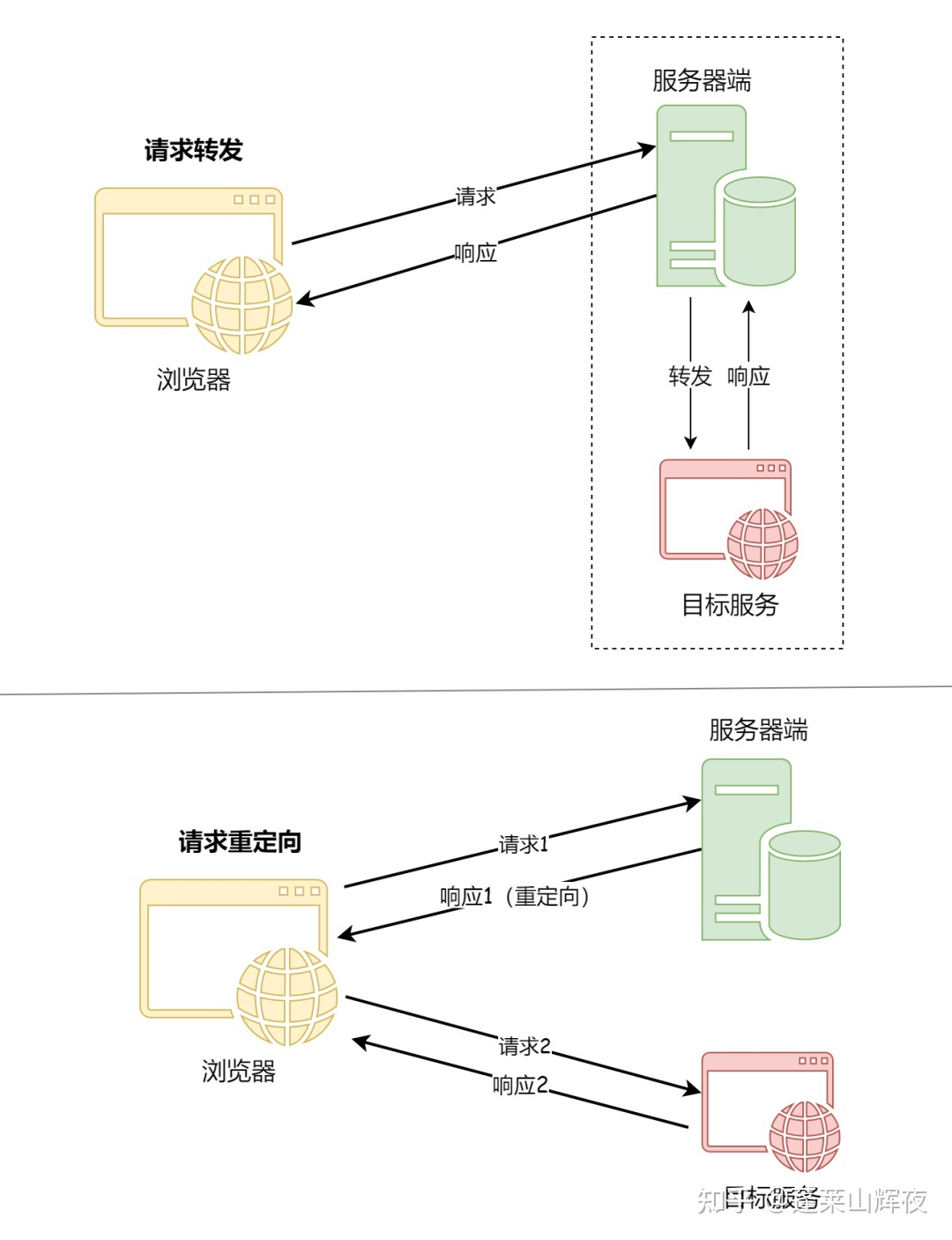
SpringBoot请求转发与重定向
但是可能由于B网址相对于A网址过于复杂,这样搜索引擎就会觉得网址A对用户更加友好,因而在重定向之后任然显示旧的网址A,但是显示网址B的内容。在平常使用手机的过程当中,有时候会发现网页上会有浮动的窗口,或者访问的页面不是正常的页面,这就可能是运营商通过某种方式篡改了用户正常访问的页面。重定向,是指在Nginx中,重定向是指通过修改URL地址,将客户端的请求重定向到另一个URL地址的过程,Nginx中实现重定向的方式有多种,比如使用rewrite模块、return指令等。使用场景:在返回视图的前面加上。
SSO 单点登录和 OAuth2.0 有何区别?
此方法的缺点是它依赖于浏览器和会话状态,对于分布式或者微服务系统而言,可能需要在服务端做会话共享,但是服务端会话共享效率比较低,这不是一个好的方案。在单点登录的上下文中,OAuth 可以用作一个中介,用户在一个“授权服务器”上登录,并获得一个访问令牌,该令牌可以用于访问其他“资源服务器”上的资源。首先,SSO 主要关注用户在多个应用程序和服务之间的无缝切换和保持登录状态的问题。这种方法通过将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。
TCP协议-TCP连接管理
TCP协议是 TCP/IP 协议族中一个非常重要的协议。它是一种面向连接、提供可靠服务、面向字节流的传输层通信协议。TCP(Transmission Control Protocol,传输控制协议)。

接口响应慢?那是你没用 CompletableFuture 来优化!
大多数程序员在平时工作中,都是增删改查。这里我跟大家讲解如何利用CompletableFuture优化项目代码,使项目性能更佳!