Jackson 用起来!
Jackson简介
Jackson是一个用于处理JSON数据的开源Java库。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和编写,同时也易于计算机解析和生成。在Java领域,Jackson已经成为处理JSON数据的事实标准库。它提供了丰富的功能,包括将Java对象转换为JSON字符串(序列化)以及将JSON字符串转换为Java对象(反序列化)。
Jackson主要由三个核心包组成:
- jackson-databind:提供了通用的数据绑定功能(将Java对象与JSON数据相互转换)
- jackson-core:提供了核心的低级JSON处理API(例如JsonParser和JsonGenerator)
- jackson-annotations:提供了用于配置数据绑定的注解
为什么选择Jackson
尽管Java生态系统中有其他处理JSON数据的库(如Gson和JSON-java),但Jackson仍然是许多开发者的首选,原因包括:
- 性能:Jackson性能优越,对内存和CPU的使用都相对较低。许多性能基准测试表明,Jackson在序列化和反序列化方面都比其他库更快。
- 功能丰富:Jackson提供了许多功能,包括注解、自定义序列化和反序列化、动态解析等,使其非常灵活和强大。
- 易于使用:Jackson的API简单易用,使得开发者可以轻松地在他们的应用程序中集成和使用。
- 社区支持:Jackson拥有庞大的开发者社区,这意味着有更多的文档、教程和问题解答可供参考。
- 模块化:Jackson支持通过模块扩展其功能,例如Java 8时间库、Joda-Time和Kotlin等。
- 兼容性:Jackson可以很好地与其他流行的Java框架(如Spring)集成。
综上所述,Jackson是一个强大且易于使用的库,值得Java开发者在处理JSON数据时使用。
Jackson的基本功能
Jackson库的核心功能是将Java对象转换为JSON字符串(序列化)以及将JSON字符串转换为Java对象(反序列化)。下面是这两个功能的详细介绍:
将Java对象转换为JSON字符串(序列化)
序列化是将Java对象转换为JSON字符串的过程。这在许多场景中非常有用,例如在将数据发送到Web客户端时,或者在将数据存储到文件或数据库时。Jackson通过ObjectMapper类来实现序列化。以下是一个简单的示例:
import com.fasterxml.jackson.databind.ObjectMapper;
public class Person {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public static void main(String[] args) {
ObjectMapper objectMapper = new ObjectMapper();
Person person = new Person("Alice", 30);
try {
String jsonString = objectMapper.writeValueAsString(person);
System.out.println(jsonString); // 输出:{"name":"Alice","age":30}
} catch (Exception e) {
e.printStackTrace();
}
}
}
将JSON字符串转换为Java对象(反序列化)
反序列化是将JSON字符串转换回Java对象的过程。这在从Web客户端接收数据或从文件或数据库读取数据时非常有用。同样,Jackson使用ObjectMapper类来实现反序列化。以下是一个简单的示例:
import com.fasterxml.jackson.databind.ObjectMapper;
public class Person {
public String name;
public int age;
public Person() {
}
public static void main(String[] args) {
ObjectMapper objectMapper = new ObjectMapper();
String jsonString = "{\"name\":\"Alice\",\"age\":30}";
try {
Person person = objectMapper.readValue(jsonString, Person.class);
System.out.println("Name: " + person.name + ", Age: " + person.age); // 输出:Name: Alice, Age: 30
} catch (Exception e) {
e.printStackTrace();
}
}
}
这些示例展示了Jackson库的基本功能。接下来的部分将介绍如何使用Jackson库,包括添加依赖、创建Java对象模型以及使用ObjectMapper进行序列化和反序列化。
由于Jackson库的API非常多,这里无法一一详细介绍。我将为你提供一些主要的API和组件概览,以便于你更好地了解Jackson库。具体实现和使用方法,你可以参考官方文档和相关教程。
以下是Jackson库的一些主要API和组件:
1.ObjectMapper:这是Jackson库的核心类,用于序列化和反序列化操作。主要方法有:
writeValueAsString(Object):将Java对象序列化为JSON字符串。readValue(String, Class):将JSON字符串反序列化为Java对象。
2.JsonParser:用于从JSON数据源(如文件、输入流或字符串)解析JSON数据。主要方法有:
nextToken():获取下一个JSON令牌(如START_OBJECT、FIELD_NAME等)。getValueAsString():将当前令牌作为字符串返回。getValueAsInt():将当前令牌作为整数返回。
3.JsonGenerator:用于将JSON数据写入数据源(如文件、输出流或字符串缓冲区)。主要方法有:
writeStartObject():写入开始对象标记({)。writeFieldName(String):写入字段名称。writeString(String):写入字符串值。writeEndObject():写入结束对象标记(})。
4.JsonNode:用于表示JSON树模型中的节点,可以是对象、数组、字符串、数字等。主要方法有:
get(String):获取指定字段的子节点。path(String):获取指定字段的子节点,如果不存在则返回一个“missing”节点。isObject():检查当前节点是否是一个对象。isArray():检查当前节点是否是一个数组。
5.注解:Jackson提供了一系列注解来配置序列化和反序列化过程。一些常用注解包括:
@JsonProperty:指定字段在JSON数据中的名称。@JsonIgnore:指定字段在序列化和反序列化过程中被忽略。@JsonCreator:指定用于反序列化的构造函数或工厂方法。@JsonSerialize:指定用于序列化特定字段或类的自定义序列化器。@JsonDeserialize:指定用于反序列化特定字段或类的自定义反序列化器。
这只是Jackson库API和组件的一个概览。如果你想深入了解具体的API和使用方法,请参考官方文档(github.com/FasterXML/j…[1] )和相关教程。同时,实际编程过程中,根据具体需求学习和了解相应的API也是非常有效的方法。
使用Jackson的基本步骤
要开始使用Jackson,你需要遵循以下基本步骤:
添加依赖(Maven或Gradle)
首先,你需要将Jackson库添加到你的项目中。这可以通过Maven或Gradle来完成。以下是添加Jackson库的方法:
Maven:
将以下依赖添加到你的pom.xml文件中:
<dependencies>
<!-- Jackson core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.13.0</version>
</dependency>
<!-- Jackson databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.0</version>
</dependency>
<!-- Jackson annotations -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.13.0</version>
</dependency>
</dependencies>
Gradle:
将以下依赖添加到你的build.gradle文件中:
dependencies {
implementation 'com.fasterxml.jackson.core:jackson-core:2.13.0'
implementation 'com.fasterxml.jackson.core:jackson-databind:2.13.0'
implementation 'com.fasterxml.jackson.core:jackson-annotations:2.13.0'
}
创建Java对象模型
在使用Jackson之前,你需要创建一个Java对象模型,该模型表示你要序列化和反序列化的JSON数据。例如,以下是一个表示Person的简单Java类:
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
在这个示例中,我们使用了一个简单的Java Bean(具有私有字段、公共构造函数和getter/setter方法的类)来表示Person对象。
使用ObjectMapper进行序列化和反序列化
使用ObjectMapper类,你可以轻松地将Java对象序列化为JSON字符串以及将JSON字符串反序列化为Java对象。以下是一个简单的示例:
序列化:
import com.fasterxml.jackson.databind.ObjectMapper;
public class Main {
public static void main(String[] args) {
ObjectMapper objectMapper = new ObjectMapper();
Person person = new Person("Alice", 30);
try {
String jsonString = objectMapper.writeValueAsString(person);
System.out.println(jsonString); // 输出:{"name":"Alice","age":30}
} catch (Exception e) {
e.printStackTrace();
}
}
}
反序列化:
import com.fasterxml.jackson.databind.ObjectMapper;
public class Main {
public static void main(String[] args) {
ObjectMapper objectMapper = new ObjectMapper();
String jsonString = "{\"name\":\"Alice\",\"age\":30}";
try {
Person person = objectMapper.readValue(jsonString, Person.class);
System.out.println("Name: " + person.getName() + ", Age: " + person.getAge()); // 输出:Name: Alice, Age: 30
} catch (Exception e) {
e.printStackTrace();
}
}
}
这些示例展示了如何使用Jackson库进行序列化和反序列化操作。在实际项目中,你可能需要根据需求对这些操作进行更多的配置和自定义,例如使用注解、自定义序列化器和反序列化器等。
高级特性
注解(如@JsonProperty, @JsonIgnore)
Jackson库提供了一系列注解,可以帮助你在序列化和反序列化过程中对字段和类进行配置。以下是一些常用注解的示例:
@JsonProperty 注解:
该注解用于指定 Java 属性与 JSON 属性之间的映射关系,常用的参数有:
value:用于指定 JSON 属性的名称,当 Java 属性和 JSON 属性名称不一致时使用。access:用于指定该属性的访问方式,常用的取值有JsonAccess.READ_ONLY(只读),JsonAccess.WRITE_ONLY(只写)和JsonAccess.READ_WRITE(可读可写)。
public class Person {
@JsonProperty(value = "name")
private String fullName;
@JsonProperty(access = JsonProperty.Access.WRITE_ONLY)
private String password;
// getters and setters
}
Person person = new Person();
person.setFullName("John Smith");
person.setPassword("123456");
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(person);
// {"name":"John Smith"}
Person person2 = mapper.readValue(json, Person.class);
System.out.println(person2.getFullName());
// John Smith
System.out.println(person2.getPassword());
// null
@JsonIgnore 注解:
该注解用于禁用 Java 属性的序列化和反序列化。
public class Person {
private String fullName;
@JsonIgnore
private String password;
// getters and setters
}
Person person = new Person();
person.setFullName("John Smith");
person.setPassword("123456");
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(person);
// {"fullName":"John Smith"}
Person person2 = mapper.readValue("{\"fullName\":\"John Smith\",\"password\":\"123456\"}", Person.class);
System.out.println(person2.getFullName());
// John Smith
System.out.println(person2.getPassword());
// null
@JsonFormat 注解:
该注解用于指定 Java 属性的日期和时间格式,常用的参数有:
shape:用于指定日期和时间的格式,可选的取值有JsonFormat.Shape.STRING(以字符串形式表示)和JsonFormat.Shape.NUMBER(以时间戳形式表示)。pattern:用于指定日期和时间的格式模板,例如"yyyy-MM-dd HH:mm:ss"。
public class Person {
private String fullName;
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss")
private Date birthDate;
// getters and setters
}
Person person = new Person();
person.setFullName("John Smith");
person.setBirthDate(new Date());
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(person);
// {"fullName":"John Smith","birthDate":"2022-05-16 10:38:30"}
Person person2 = mapper.readValue(json, Person.class);
System.out.println(person2.getFullName());
// John Smith
System.out.println(person2.getBirthDate());
// Mon May 16 10:38:30 CST 2022
@JsonInclude 注解:
该注解用于指定序列化 Java 对象时包含哪些属性,常用的参数有:
value:用于指定包含哪些属性,可选的取值有JsonInclude.Include.ALWAYS(始终包含)、JsonInclude.Include.NON_NULL(值不为 null 时包含)、JsonInclude.Include.NON_DEFAULT(值不为默认值时包含)、JsonInclude.Include.NON_EMPTY(值不为空时包含)和JsonInclude.Include.CUSTOM(自定义条件)。content:用于指定自定义条件的实现类。
@JsonInclude(JsonInclude.Include.NON_NULL)
public class Person {
private String fullName;
private Integer age;
// getters and setters
}
Person person = new Person();
person.setFullName("John Smith");
// person.setAge(null);
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(person);
// {"fullName":"John Smith"}
Person person2 = mapper.readValue("{\"fullName\":\"John Smith\",\"age\":null}", Person.class);
System.out.println(person2.getFullName());
// John Smith
System.out.println(person2.getAge());
// null
@JsonCreator 注解:
该注解用于指定反序列化时使用的构造方法或工厂方法。
public class Person {
private String fullName;
private Integer age;
@JsonCreator
public Person(@JsonProperty("fullName") String fullName, @JsonProperty("age") Integer age) {
this.fullName = fullName;
this.age = age;
}
// getters and setters
}
ObjectMapper mapper = new ObjectMapper();
Person person = mapper.readValue("{\"fullName\":\"John Smith\",\"age\":30}", Person.class);
System.out.println(person.getFullName());
// John Smith
System.out.println(person.getAge());
// 30
@JsonSetter 注解:
该注解用于指定反序列化时使用的方法,常用的参数有:
value:用于指定 JSON 属性的名称,当方法名和 JSON 属性名称不一致时使用。
public class Person {
private String fullName;
private Integer age;
@JsonSetter("name")
public void setFullName(String fullName) {
this.fullName = fullName;
}
// getters and setters
}
ObjectMapper mapper = new ObjectMapper();
Person person = mapper.readValue("{\"name\":\"John Smith\",\"age\":30}", Person.class);
System.out.println(person.getFullName());
// John Smith
System.out.println(person.getAge());
// 30
@JsonGetter 注解:
该注解用于指定序列化时使用的方法,常用的参数有:
value:用于指定 JSON 属性的名称,当方法名和 JSON 属性名称不一致时使用。
public class Person {
private String fullName;
private Integer age;
@JsonGetter("name")
public String getFullName() {
return fullName;
}
// getters and setters
}
@JsonAnySetter 注解:
该注解用于指定反序列化时使用的方法,用于处理 JSON 中未知的属性。
public class Person {
private String fullName;
private Map<String, Object> otherProperties = new HashMap<>();
@JsonAnySetter
public void setOtherProperties(String key, Object value) {
otherProperties.put(key, value);
}
// getters and setters
}
ObjectMapper mapper = new ObjectMapper();
Person person = mapper.readValue("{\"fullName\":\"John Smith\",\"age\":30}", Person.class);
System.out.println(person.getFullName());
// John Smith
System.out.println(person.getOtherProperties());
// {age=30}
@JsonAnyGetter 注解:
该注解用于指定序列化时使用的方法,用于处理 Java 对象中未知的属性。
public class Person {
private String fullName;
private Map<String, Object> otherProperties = new HashMap<>();
public void addOtherProperty(String key, Object value) {
otherProperties.put(key, value);
}
@JsonAnyGetter
public Map<String, Object> getOtherProperties() {
return otherProperties;
}
// getters and setters
}
Person person = new Person();
person.setFullName("John Smith");
person.addOtherProperty("age", 30);
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(person);
// {"fullName":"John Smith","age":30}
@JsonTypeInfo 注解:
该注解用于指定 Java 对象在序列化和反序列化时的类型信息,常用的参数有:
use:用于指定类型信息的使用方式,可选的取值有JsonTypeInfo.Id.CLASS(使用 Java 类的全限定名)、JsonTypeInfo.Id.NAME(使用名称)和JsonTypeInfo.Id.NONE(不使用类型信息)。include:用于指定类型信息的包含方式,可选的取值有JsonTypeInfo.As.PROPERTY(作为 JSON 属性)和JsonTypeInfo.As.EXTERNAL_PROPERTY(作为外部属性)。property:用于指定包含类型信息的属性名,当include的值为JsonTypeInfo.As.PROPERTY时使用。visible:用于指定类型信息是否可见。
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, include = JsonTypeInfo.As.PROPERTY, property = "type")
@JsonSubTypes({
@JsonSubTypes.Type(value = Rectangle.class, name = "rectangle"),
@JsonSubTypes.Type(value = Circle.class, name = "circle")
})
public abstract class Shape {
// ...
}
public class Rectangle extends Shape {
// ...
}
public class Circle extends Shape {
// ...
}
Shape shape = new Rectangle();
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(shape);
// {"type":"rectangle"}
Shape shape2 = mapper.readValue(json, Shape.class);
System.out.println(shape2.getClass().getSimpleName());
// Rectangle
自定义序列化和反序列化
你可以创建自定义序列化器和反序列化器以自定义特定字段或类的序列化和反序列化行为。为此,请创建一个实现JsonSerializer或JsonDeserializer接口的类,并在需要自定义的字段或类上使用@JsonSerialize和@JsonDeserialize注解。例如:
public class CustomDateSerializer extends JsonSerializer<Date> {
private SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
@Override
public void serialize(Date value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
gen.writeString(dateFormat.format(value));
}
}
public class Person {
private String name;
@JsonSerialize(using = CustomDateSerializer.class)
private Date birthdate;
// ...其他代码...
}
使用JsonNode进行动态解析
你可以使用JsonNode类来动态地解析和操作JSON数据。例如:
String jsonString = "{\"name\":\"Alice\",\"age\":30,\"address\":{\"street\":\"Main St\",\"city\":\"New York\"}}";
ObjectMapper objectMapper = new ObjectMapper();
JsonNode rootNode = objectMapper.readTree(jsonString);
String name = rootNode.get("name").asText(); // Alice
int age = rootNode.get("age").asInt(); // 30
String street = rootNode.get("address").get("street").asText(); // Main St
处理日期和时间类型
Jackson可以处理Java日期和时间类型,例如java.util.Date和Java 8时间库中的类型。你可以通过配置ObjectMapper来指定日期和时间格式,例如:
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd"));
处理泛型
Jackson可以处理泛型类型,例如List<T>和Map<String, T>。在反序列化时,你需要使用TypeReference来指定泛型类型。例如:
String jsonString = "[{\"name\":\"Alice\",\"age\":30},{\"name\":\"Bob\",\"age\":25}]";
ObjectMapper objectMapper = new ObjectMapper();
List<Person> persons = objectMapper.readValue(jsonString, new TypeReference<List<Person>>() {});
使用模块扩展Jackson(如Java 8时间支持)
Jackson可以通过模块来扩展其功能。例如,你可以使用jackson-datatype-jsr310模块为Jackson添加对Java 8时间库的支持。首先,将依赖添加到项目中:
Maven:
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>2.13.0</version>
</dependency>
Gradle:
dependencies {
implementation 'com.fasterxml.jackson.datatype:jackson-datatype-jsr310:2.13.0'
}
然后,你需要注册模块到ObjectMapper:
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
现在,Jackson可以正确地处理Java 8时间库中的类型,例如LocalDate、LocalTime和Instant。
总结
Jackson的优势和局限性
优势:
- 性能优异:Jackson在序列化和反序列化过程中表现出优秀的性能,通常比其他Java JSON库更快。
- 灵活性:通过注解、自定义序列化器/反序列化器等功能,Jackson提供了丰富的配置选项,允许你根据需求灵活地处理JSON数据。
- 易于使用:Jackson的API设计简洁明了,易于学习和使用。同时,官方文档和社区支持也非常丰富。
- 可扩展性:通过模块系统,你可以轻松地为Jackson添加新功能或与其他库进行集成。
局限性:
- 库大小:由于Jackson提供了许多功能和选项,它的库文件相对较大。在某些对程序大小有严格要求的场景中,这可能是一个问题。
- 学习曲线:虽然Jackson的基本功能易于学习,但要充分利用其高级特性,可能需要一定的学习成本。
建议和最佳实践
- 了解你的需求:在使用Jackson之前,请确保你了解项目的需求。针对具体需求,学习和使用相应的API和特性会更加高效。
- 遵循Java命名规范:使用标准的Java命名规范(如驼峰命名法)来命名字段和类。这将有助于Jackson自动处理JSON字段映射。
- 尽量避免循环引用:在Java对象模型中避免循环引用,因为这可能导致序列化过程中出现问题。如果确实存在循环引用,请使用
@JsonManagedReference和@JsonBackReference注解来解决。 - 使用注解进行配置:在可能的情况下,使用注解来配置序列化和反序列化过程。这将使配置更加集中和易于理解。
- 优先使用对象模型:尽量使用Java对象模型来表示JSON数据,而非动态解析。这将使代码更加清晰和易于维护。
其他的JSON库
除了Jackson之外,还有其他一些流行的Java JSON处理库。以下是一些常见的库:
- Gson:Gson是Google开发的一个Java库,用于将Java对象转换为JSON表示以及将JSON字符串转换为等效的Java对象。Gson的API简洁易用,性能也相当不错。官方网站:github.com/google/gson[2]
- Fastjson:Fastjson是Alibaba开发的一个高性能的JSON库。Fastjson提供了灵活的API和丰富的功能,同时注重性能优化。然而,它在安全性方面存在一些问题,因此在使用时需要谨慎。官方网站:github.com/alibaba/fas…[3]
- JSON-java(org.json):JSON-java库,也称为org.json库,是一个非常轻量级的JSON处理库。它提供了基本的JSON编码和解码功能,但不支持对象映射等高级功能。官方网站:github.com/stleary/JSO…[4]
- Moshi:Moshi是Square公司开发的一个现代化的JSON库,具有简单易用的API和良好的性能。Moshi支持Kotlin协程,并与Kotlin编程语言非常兼容。官方网站:github.com/square/mosh…[5]
- Boon:Boon是另一个高性能的JSON处理库。它具有易用的API,支持流式处理和速度优化。然而,Boon的社区和文档相对较少。官方网站:github.com/boonproject…[6]
这些库各有优缺点,选择哪个库取决于项目的具体需求和团队的熟悉程度。在实际项目中,你可能需要比较这些库的性能、功能、易用性等方面的差异,以找到最适合你的解决方案。
参考资料
[1]https://github.com/FasterXML/jackson-docs: https://github.com/FasterXML/jackson-docs[2]https://github.com/google/gson: https://github.com/google/gson[3]https://github.com/alibaba/fastjson: https://github.com/alibaba/fastjson[4]https://github.com/stleary/JSON-java: https://github.com/stleary/JSON-java[5]https://github.com/square/moshi: https://github.com/square/moshi[6]https://github.com/boonproject/boon: https://github.com/boonproject/boon
相关文章:
并发编程下的集合:数组寻址、LinkedList、HashMap、ConcurrentHashMap
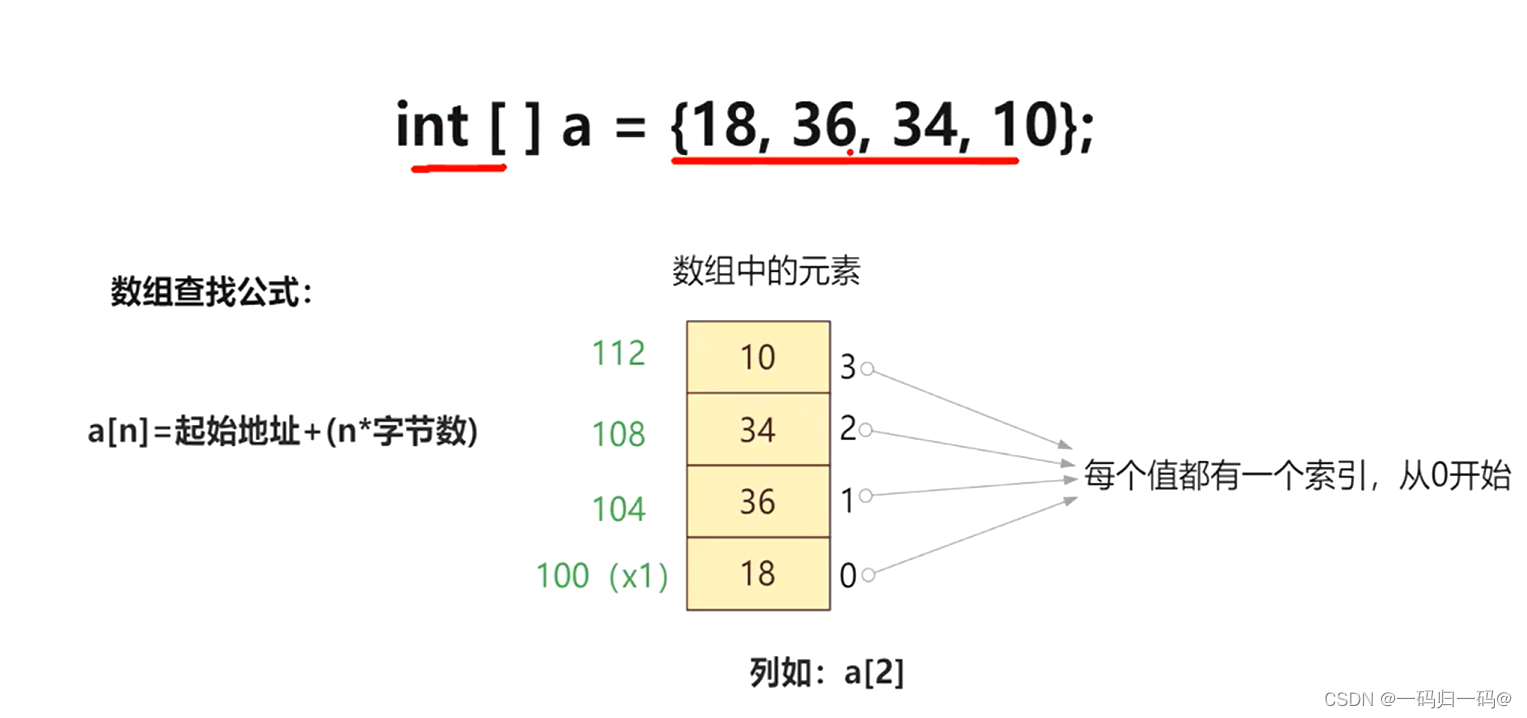
如果发现hash取模后的数组索引位下无元素则直接新增,若不是空那就说明存在hash冲突,则判断数组索引位链表结构中的第一个元素的key以及hash值是否与新的key一致则直接覆盖,若不一致则判断当前的数组索引下的链表结构是否为红黑树,若为红黑树则走红黑树的新增方法,若不为红黑树则遍历当前链表结构,遍历中发现某个节点元素的next为null是则直接将新元素指针与next进行关联,若在遍历到next为空前判断到,某个节点的key以及key的hash值与新的key与新的keyhash值一致时则走覆盖。

【日常开发之插件篇】IDEA plugins 神器助我!!
今早因为老代码的一些bug让我突然觉得Idea的一些插件特别好用,我准备将我平时所用到的一些插件做个推荐以及记录。

【日常开发之FTP】Windows开启FTP、Java实现FTP文件上传下载
FTP是一个专门进行文件管理的操作服务,一般来讲可以在任意的操作系统之中进行配置,但是如果考虑到简便性,一般来讲可以直接在Linux系统下进行安装。FTP (File Transfer Protocol、文件传输协议)是TCP/IP协议中的一部分,属于应用层协议。使用FTP最主要的功能是对文件进行管理,所以在FTP内部对于文件支持有两种传输模式:文本模式(ASCII、默认)和二进制模式(Binary),通常文本文件使用ASCIl模式,而对于图片、视频、声音、压缩等文件则会使用二进制的方式进行传输。

【Linux之升华篇】Linux内核锁、用户模式与内核模式、用户进程通讯方式
alloc_pages(gfp_mask, order),_ _get_free_pages(gfp_mask, order)等。字符设备描述符 struct cdev,cdev_alloc()用于动态的分配 cdev 描述符,cdev_add()用于注。外,还支持语义符合 Posix.1 标准的信号函数 sigaction(实际上,该函数是基于 BSD 的,BSD。从最初的原子操作,到后来的信号量,从。(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的。

【Mongdb之数据同步篇】什么是Oplog、Mongodb 开启oplog,java监听oplog并写入关系型数据库、Mongodb动态切换数据源
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。Oplog 可以说是Mongodb Replication的纽带了。
【日常开发之Windows共享文件】Java实现Windows共享文件上传下载
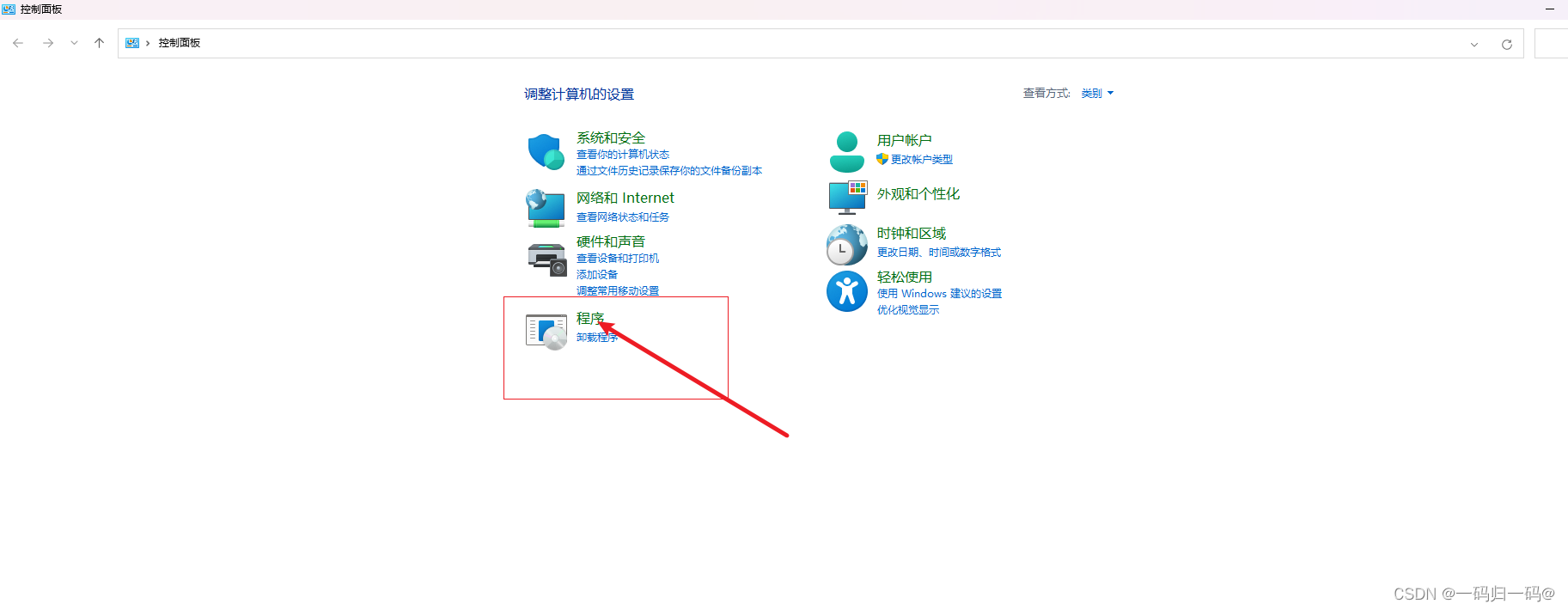
下拉框选择你选择的用户点击添加,然后共享确定。创建一个文件夹然后点击属性界面,点击共享。maven版本存在于SMB协议的兼容问题。首先开启服务,打开控制面板点击程序。点击启用或关闭Windows功能。我这边是专门创建了一个用户。SMB1.0选中红框内的。

CXFServlet类的作用
CXFServlet是Apache CXF框架中的一个核心组件,用于处理HTTP请求并将它们转换为Web服务调用。通过配置CXFServlet,你可以轻松地部署和管理SOAP和RESTful Web服务。
@Scheduled注解的scheduler属性什么作用
注解是 Spring Framework 提供的一种机制,用于定义计划任务,即周期性执行的任务。 注解可以应用于方法上,以指示 Spring 容器在特定的时间间隔或按照某种调度规则来调用该方法。 属性是 注解的一个可选属性,它的作用是允许开发者指定一个自定义的 对象来控制任务的调度方式。默认情况下, 注解使用 Spring 内部的 来执行任务,但如果需要更高级的定制化需求,可以通过 属性指定一个自定义的 实现。自定义调度器:共享调度器资源:高级调度需求:假设你想使用 作为调度器,并且希望所有带有
过滤器、拦截器、aop的先后顺序和作用范围&拦截器preHandle(),postHandle(),afterComplation()方法执行顺序
在Spring框架中,过滤器(Filter)、拦截器(Interceptor)和面向切面编程(AOP)都是用于处理请求和处理流程的组件,但它们的作用范围和触发时机有所不同。下面我会解释这三者的先后顺序和作用范围。执行顺序:请注意,这个顺序可能因具体的配置和使用的技术而有所不同。在实际应用中,建议根据项目的具体需求来合理配置和使用这些组件。拦截器执行流程图:实现拦截器需要实现这个接口,这个 接口中有三个默认方法,这三个方法的执行顺序:我们实现接口然后重写这三个方法,就会在对应的时机被自动执行。这里就是调用处理
Zookeeper概要、协议、应用场景
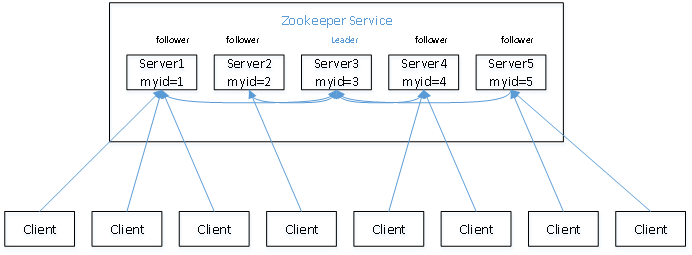
Zoopkeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型,作为分布式系统的沟通调度桥梁。
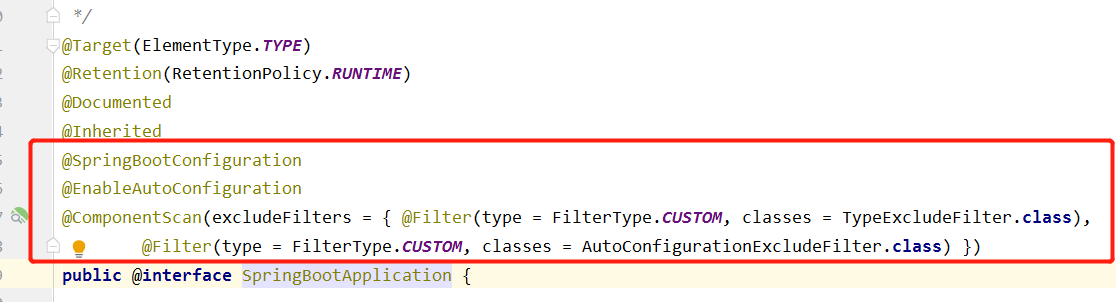
spring.factories文件的作用
即spring.factories文件是帮助spring-boot项目包以外的bean(即在pom文件中添加依赖中的bean)注册到spring-boot项目的spring容器中。在Spring Boot启动时,它会扫描classpath下所有的spring.factories文件,加载其中的自动配置类,并将它们注入到Spring ApplicationContext中,使得项目能够自动运行。spring.factories文件是Spring Boot自动配置的核心文件之一,它的作用是。
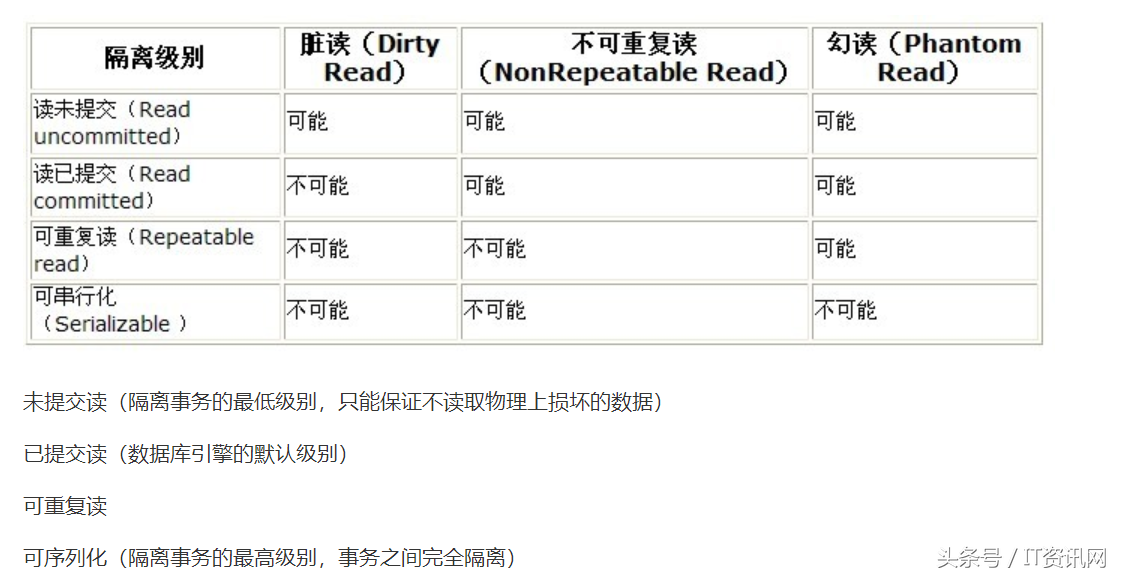
Spring事务七大传播机制与五个隔离级别,嵌套事务
如果当前方法正有一个事务在运行中,则该方法应该运行在一个嵌套事务中,被嵌套的事务可以独立于被封装的事务中进行提交或者回滚。如果封装事务存在,并且外层事务抛出异常回滚,那么内层事务必须回滚,反之,内层事务并不影响外层事务。当前方法必须在一个具有事务的上下文中运行,如有客户端有事务在进行,那么被调用端将在该事务中运行,否则的话重新开启一个事务。当前方法必须运行在它自己的事务中。一个新的事务将启动,而且如果有一个现有的事务在运行的话,则这个方法将在运行期被挂起,直到新的事务提交或者回滚才恢复执行。
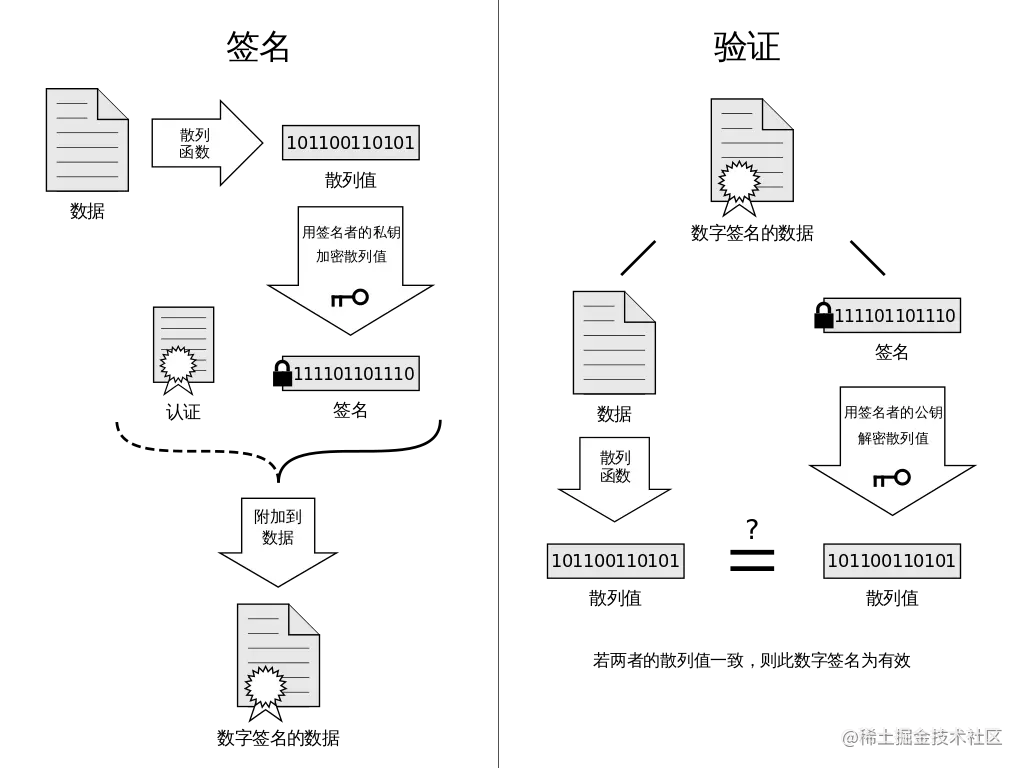
常见的七种加密算法及实现
**数字签名**、**信息加密** 是前后端开发都经常需要使用到的技术,应用场景包括了用户登入、交易、信息通讯、`oauth` 等等,不同的应用场景也会需要使用到不同的签名加密算法,或者需要搭配不一样的 **签名加密算法** 来达到业务目标。这里简单的给大家介绍几种常见的签名加密算法和一些典型场景下的应用。## 正文### 1. 数字签名**数字签名**,简单来说就是通过提供 **可鉴别** 的 **数字信息** 验证 **自身身份** 的一种方式。一套 **数字签名** 通常定义两种 **互补

7min到40s:SpringBoot 启动优化实践
然后重点排查这些阶段的代码。先看下。

SpringBoot系列教程之Bean之指定初始化顺序的若干姿势
之前介绍了@Order注解的常见错误理解,它并不能指定 bean 的加载顺序,那么问题来了,如果我需要指定 bean 的加载顺序,那应该怎么办呢?本文将介绍几种可行的方式来控制 bean 之间的加载顺序。

在Java中使用WebSocket
WebSocket是一种协议,用于在Web应用程序和服务器之间建立实时、双向的通信连接。它通过一个单一的TCP连接提供了持久化连接,这使得Web应用程序可以更加实时地传递数据。WebSocket协议最初由W3C开发,并于2011年成为标准。
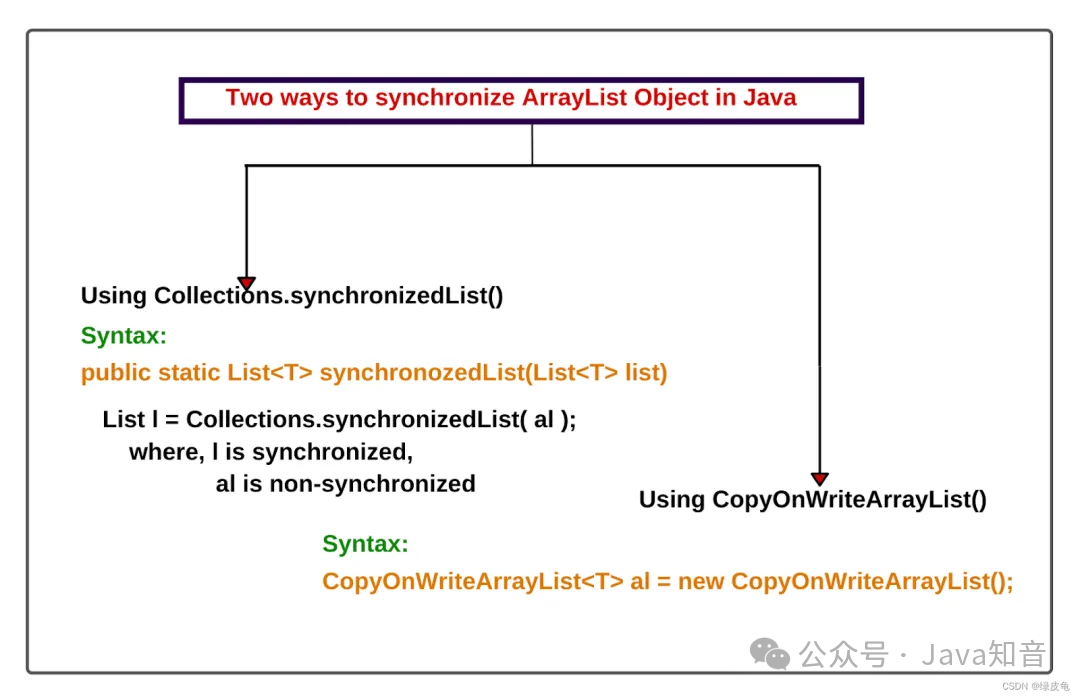
3种方案,模拟两个线程抢票
在多线程编程中,资源竞争是一个常见的问题。资源竞争发生在多个线程试图同时访问或修改共享资源时,可能导致数据不一致或其他并发问题。在模拟两个线程抢票的场景中,我们需要考虑如何公平地分配票,并确保每个线程都有机会成功获取票。本篇文章将通过三种方式来模拟两个线程抢票的过程,以展示不同的并发控制策略。使用 Synchronized 来确保一次只有一个线程可以访问票资源。使用 ReentrantLock 来实现线程间的协调。使用 Semaphore 来限制同时访问票的线程数量。
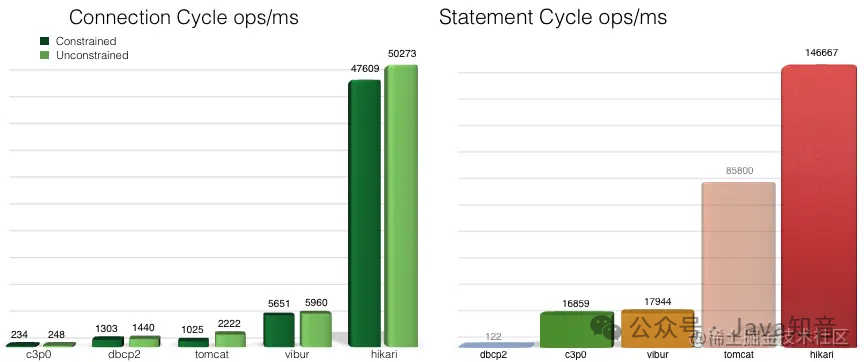
替代Druid,HakariCP 为什么这么快?
这次源码探究,真的感觉看到了无数个小细节,无数个小优化,积少成多。平时开发过程中,一些小的细节也一定要“扣”。
Java中volatile 的使用场景有哪些?
volatile是一种轻量级的同步机制,它能保证共享变量的可见性,同时禁止重排序保证了操作的有序性,但是它无法保证原子性。所以使用volatilevolatile。

JDK22 正式发布了 !
Java 22 除了推出了新的增强功能和特性,也获得 Java Management Service (JMS) 的支持,这是一项新的 Oracle 云基础设施远程软件服务(Oracle Cloud Infrastructure, OCI) 原生服务,提供统一的控制台和仪表盘,帮助企业管理本地或云端的 Java 运行时和应用。使包含运行时计算值的字符串更容易表达,简化 Java 程序的开发工作,同时提高将用户提供的值编写成字符串,并将字符串传递给其他系统的程序的安全性。支持开发人员自由地表达构造器的行为。
拜托!别再滥用 ! = null 判空了!!
另外,也许受此习惯影响,他们总潜意识地认为,所有的返回都是不可信任的,为了保护自己程序,就加了大量的判空。如果你养成习惯,都是这样写代码(返回空collections而不返回null),你调用自己写的方法时,就能大胆地忽略判空)这种情况下,null是个”看上去“合理的值,例如,我查询数据库,某个查询条件下,就是没有对应值,此时null算是表达了“空”的概念。最终,项目中会存在大量判空代码,多么丑陋繁冗!,而不要返回null,这样调用侧就能大胆地处理这个返回,例如调用侧拿到返回后,可以直接。
详解Java Math类的toDegrees()方法:将参数从弧度转换为角度
Java Math 类的 toDegrees() 方法是将一个角度的弧度表示转换为其度表示,返回值为double类型,表示从弧度数转换而来的角度数。这就是Java Math 类的 toDegrees() 方法的攻略。我们已经了解了该方法的基本概念、语法、注意事项以及两个示例。希望这篇攻略对你有所帮助。

SpringBoot接口防抖(防重复提交)的一些实现方案
作为一名老码农,在开发后端Java业务系统,包括各种管理后台和小程序等。在这些项目中,我设计过单/多租户体系系统,对接过许多开放平台,也搞过消息中心这类较为复杂的应用,但幸运的是,我至今还没有遇到过线上系统由于代码崩溃导致资损的情况。这其中的原因有三点:一是业务系统本身并不复杂;二是我一直遵循某大厂代码规约,在开发过程中尽可能按规约编写代码;三是经过多年的开发经验积累,我成为了一名熟练工,掌握了一些实用的技巧。啥是防抖所谓防抖,一是防用户手抖,二是防网络抖动。
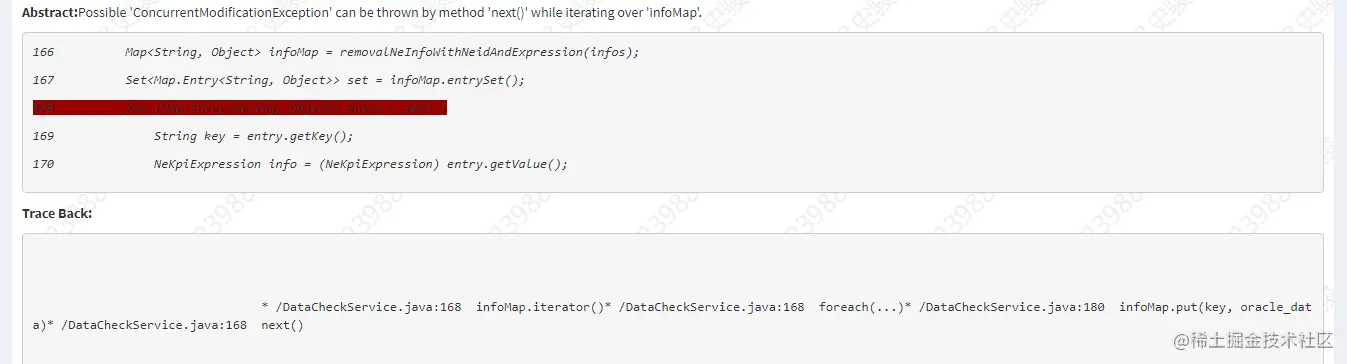
公司新来一个同事:为什么 HashMap 不能一边遍历一边删除?一下子把我问懵了!
前段时间,同事在代码中KW扫描的时候出现这样一条:上面出现这样的原因是在使用foreach对HashMap进行遍历时,同时进行put赋值操作会有问题,异常ConcurrentModificationException。于是帮同简单的看了一下,印象中集合类在进行遍历时同时进行删除或者添加操作时需要谨慎,一般使用迭代器进行操作。于是告诉同事,应该使用迭代器Iterator来对集合元素进行操作。同事问我为什么?这一下子把我问蒙了?对啊,只是记得这样用不可以,但是好像自己从来没有细究过为什么?
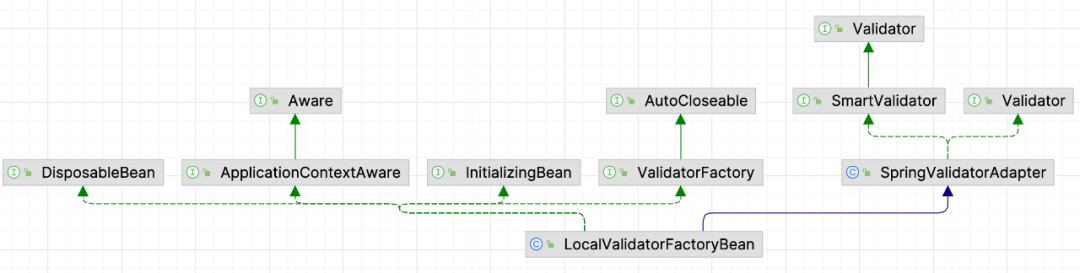
每天一个摆脱if-else工程师的技巧——优雅的参数校验
在日常的开发工作中,为了程序的健壮性,大部分方法都需要进行入参数据校验。最直接的当然是在相应方法内对数据进行手动校验,但是这样代码里就会有很多冗余繁琐的if-else。throw new IllegalArgumentException("用户姓名不能为空");throw new IllegalArgumentException("性别不能为空");throw new IllegalArgumentException("性别错误");
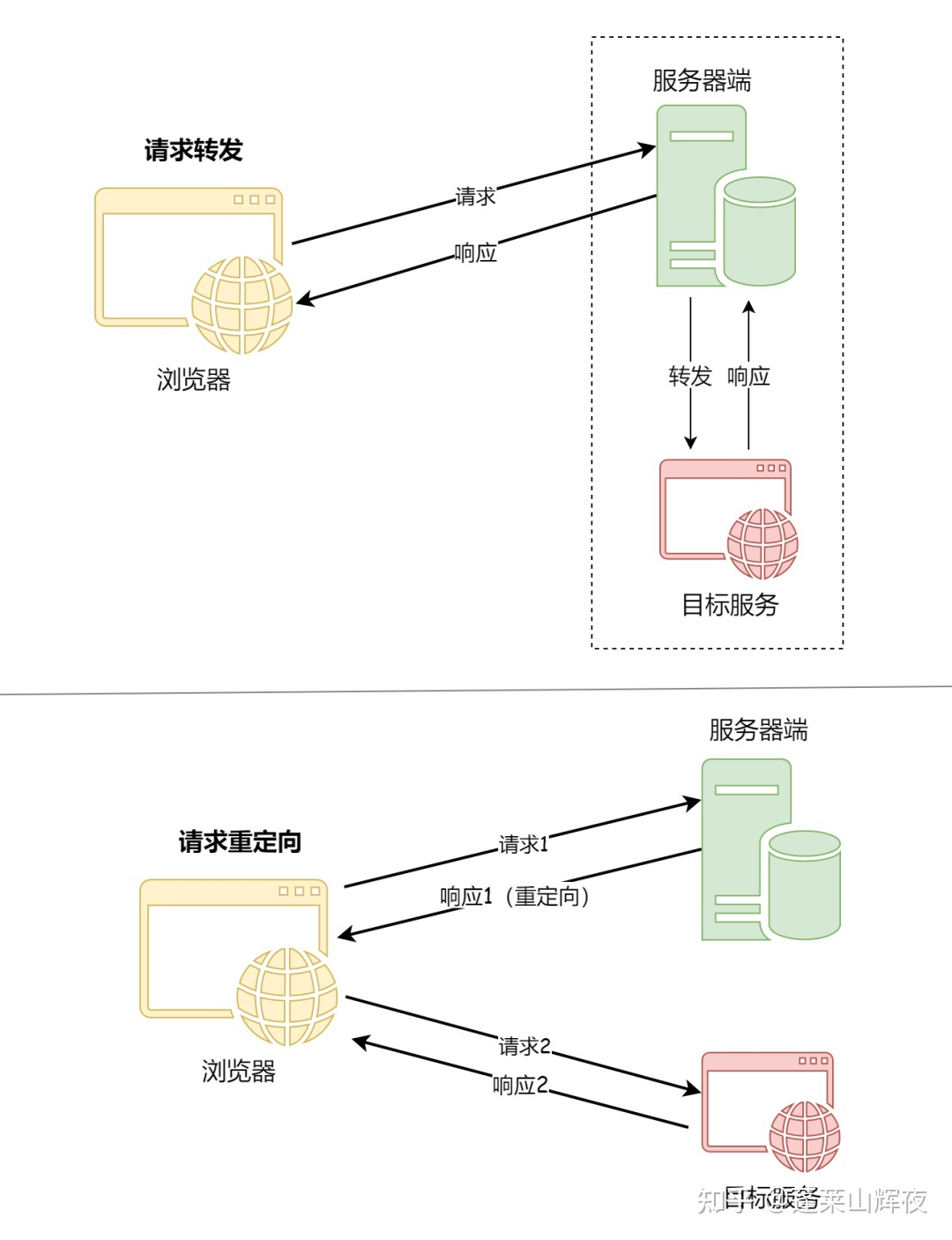
SpringBoot请求转发与重定向
但是可能由于B网址相对于A网址过于复杂,这样搜索引擎就会觉得网址A对用户更加友好,因而在重定向之后任然显示旧的网址A,但是显示网址B的内容。在平常使用手机的过程当中,有时候会发现网页上会有浮动的窗口,或者访问的页面不是正常的页面,这就可能是运营商通过某种方式篡改了用户正常访问的页面。重定向,是指在Nginx中,重定向是指通过修改URL地址,将客户端的请求重定向到另一个URL地址的过程,Nginx中实现重定向的方式有多种,比如使用rewrite模块、return指令等。使用场景:在返回视图的前面加上。
SSO 单点登录和 OAuth2.0 有何区别?
此方法的缺点是它依赖于浏览器和会话状态,对于分布式或者微服务系统而言,可能需要在服务端做会话共享,但是服务端会话共享效率比较低,这不是一个好的方案。在单点登录的上下文中,OAuth 可以用作一个中介,用户在一个“授权服务器”上登录,并获得一个访问令牌,该令牌可以用于访问其他“资源服务器”上的资源。首先,SSO 主要关注用户在多个应用程序和服务之间的无缝切换和保持登录状态的问题。这种方法通过将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。
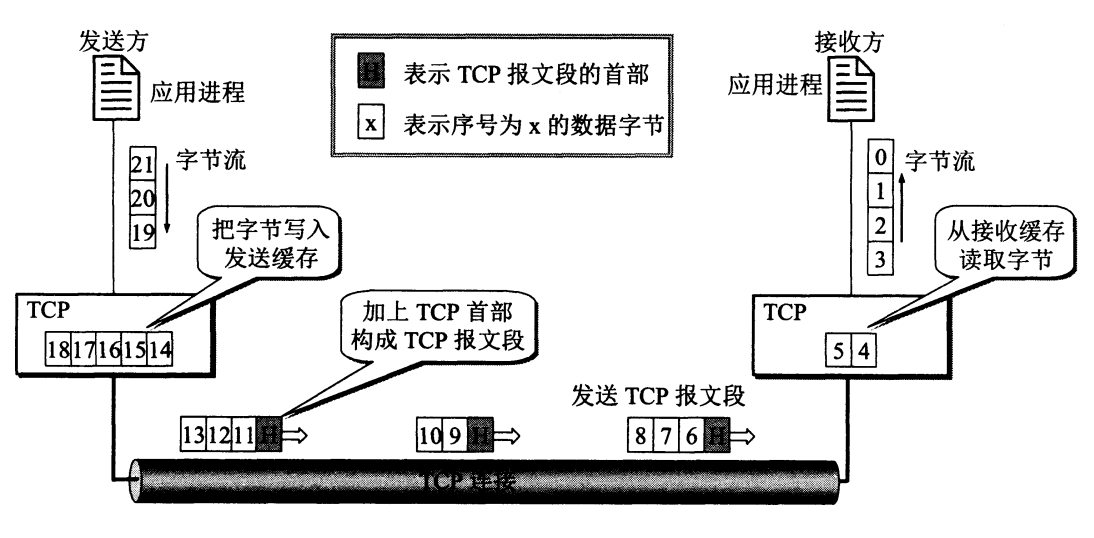
TCP协议-TCP连接管理
TCP协议是 TCP/IP 协议族中一个非常重要的协议。它是一种面向连接、提供可靠服务、面向字节流的传输层通信协议。TCP(Transmission Control Protocol,传输控制协议)。

接口响应慢?那是你没用 CompletableFuture 来优化!
大多数程序员在平时工作中,都是增删改查。这里我跟大家讲解如何利用CompletableFuture优化项目代码,使项目性能更佳!
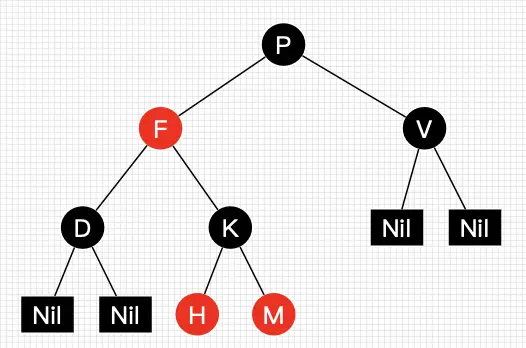
30张图带你彻底理解红黑树
当在10亿数据进行不到30次比较就能查找到目标时,不禁感叹编程之魅力!人类之伟大呀!—— 学红黑树有感。终于,在学习了几天的红黑树相关的知识后,我想把我所学所想和所感分享给大家。红黑树是一种比较难的数据结构,要完全搞懂非常耗时耗力,红黑树怎么自平衡?什么时候需要左旋或右旋?插入和删除破坏了树的平衡后怎么处理?等等一连串的问题在学习前困扰着我。如果你在学习过程中也会存在我的疑问,那么本文对你会有帮助,本文帮助你全面、彻底地理解红黑树!