SpanBERT:提出基于分词的预训练模型,多项任务性能超越现有模型!

作者 | Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy
译者 | Rachel
责编 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导读】本文提出了一个新的模型预训练方法 SpanBERT ,该方法能够更好地表示和预测文本的分词情况。新方法对 BERT 模型进行了改进,在实验中, SpanBERT 的表现优于 BERT 及其他基线,并在问答任务、指代消解等分词选择类任务中取得了重要进展。特别地,在使用和 BERT 相同的训练数据和模型大小时,SpanBERT 在 SQuAD 1.0 和 2.0 中的 F1 score 分别为 94.6% 和 88.7% 。在 OntoNotes 指代消解任务中, SpanBERT 获得了 79.6% 的 F1 score,优于现有模型。另外, SpanBERT 在 TACRED 关系抽取任务中的表现也超过了基线,获得 70.8% 的 F1 score,在 GLUE 数据集上的表现也有所提升。

介绍
在现有研究中,包括 BERT 在内的许多预训练模型都有很好的表现,已有模型在单个单词或更小的单元上增加掩膜,并使用自监督方法进行模型训练。但是在许多 NLP 任务中都涉及对多个文本分词间关系的推理。例如,在抽取式问答任务中,在回答问题“Which NFL team won Super Bown 50?”时,判断“Denver Broncos” 是否属于“NFL team”是非常重要的步骤。相比于在已知“Broncos”预测“Denver”的情况,直接预测“Denver Broncos”难度更大,这意味着这类分词对自监督任务提出了更多的挑战。
在本文中,作者提出了一个新的分词级别的预训练方法 SpanBERT ,其在现有任务中的表现优于 BERT ,并在问答、指代消解等分词选择任务中取得了较大的进展。对 BERT 模型进行了如下改进:(1)对随机的邻接分词(span)而非随机的单个词语(token)添加掩膜;(2)通过使用分词边界的表示来预测被添加掩膜的分词的内容,不再依赖分词内单个 token 的表示。
SpanBERT 能够对分词进行更好地表示和预测。该模型和 BERT 在掩膜机制和训练目标上存在差别。首先,SpanBERT 不再对随机的单个 token 添加掩膜,而是对随机对邻接分词添加掩膜。其次,本文提出了一个新的训练目标 span-boundary objective (SBO) 进行模型训练。通过对分词添加掩膜,作者能够使模型依据其所在语境预测整个分词。另外,SBO 能使模型在边界词中存储其分词级别的信息,使得模型的调优更佳容易。图1展示了模型的原理。
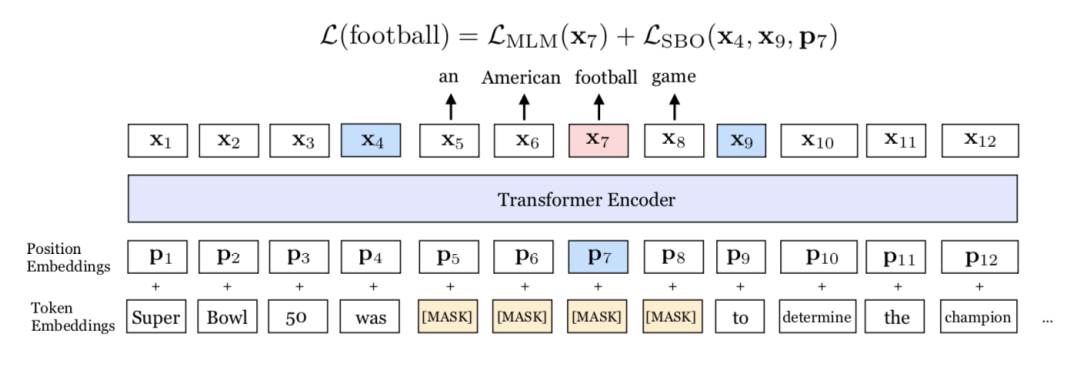
图1 SpanBERT 图示。在该示例中,分词 an American football game上添加了掩膜。模型之后使用边界词 was和 to来预测分词中的每个单词。
为了搭建 SpanBERT ,作者首先构建了一个 BERT 模型的并进行了微调,该模型的表现优于原始 BERT 模型。在搭建基线的时候,作者发现对单个部分进行预训练的效果,比使用 next sentence prediction (NSP) 目标对两个长度为一半的部分进行训练的效果更优,在下游任务中表现尤其明显。因此,作者在经过调优的 BERT 模型的顶端对模型进行了改进。
本文模型在多个任务中的表现都超越了所有的 BERT 基线模型,且在分词选择类任务中取得了重要提升。SpanBERT 在 SQuAD 1.0 和 2.0 中分别获得 94.6% 和 88.7% 的 F1 score 。另外,模型在其他五个抽取式问答基线(NewsQA, TriviaQA, SearchQA, HotpotQA, Natural Questions)中的表现也有所提升。
SpanBERT 在另外两个具有挑战性的任务中也取得了新进展。在 CoNLL-2012 ("OnroNoets")的文本级别指代消解任务中,模型获得了 79.6% 的 F1 socre ,超出现有最优模型 6.6% 。在关系抽取任务中,SpanBERT 在 TACRED 中的 F1 score 为 70.8% ,超越现有最优模型 2.8% 。另外,模型在一些不涉及分词选择的任务中也取得了进展,例如提升了 GLUE 上的表现。
在已有的一些研究中,学者提出了增加数据、扩大模型能够带来的优势。本文则探讨了设计合理的预训练任务和目标的重要性。
研究背景:BERT
BERT 是一个用于预训练深度 transformer 编码器的自监督方法,在预训练后可以针对不同的下游任务进行微调。BERT 针对两个训练目标进行最优化—— 带掩膜的语言模型(mask language modeling, MLM)和单句预测(next sentence prediction, NSP),其训练只需使用不带标签的大数据集。
符号
对于每一个单词或子单元的序列 X = (x1, ..., xn) ,BERT 通过编码器产生出其基于语境的向量表示: x1, ..., xn = enc(x1, ..., xn)。由于 BERT 是通过使用一个深度 transformor 结构使用该编码器,模型使用其位置嵌入 p1, ..., pn 来标识序列中每个单词的绝对位置。
带掩膜的语言模型(MLM)
MLM 又称填空测验,其内容为预测一个序列中某一位置的缺失单词。该步骤从单词集合 X 中采样一个子集合 Y ,并使用另一个单词集合替换。在 BERT 中, Y 占 X 的 15% 。在 Y 中,80% 的词被使用 [MASK] 替换,10% 的词依据 unigram 分布使用随机的单词替换,10% 保持不变。任务即使用这些被替换的单词预测 Y 中的原始单词。
在 BERT 中,模型通过随机选择一个子集来找出 Y ,每个单词的选择是相互独立的。在 SpanBERT 中,Y 的选择是通过随机选择邻接分词得到的(详见3.1)。
单句预测(NSP)
NSP 任务中包含两个输入序列 XA, XB,并预测 XB 是否为 XA 的直接邻接句。在 BERT 中,模型首先首先从词汇表中读取 XA ,之后有两种操作的选择:(1)从 XA 结束的地方继续读取 XB;(2)从词汇表的另一个部分随机采样得到 XB 。两句之间使用 [SEP] 符号隔开。另外,模型使用 [CLS] 符号表示 XB 是否是 XA 中的邻接句,并加入到输入之中。
在 SpanBERT 中,作者不再使用 NSP 目标,且只采样一个全长度的序列(详见3.3)。
模型
3.1 分词掩膜
对于每一个单词序列 X = (x1, ..., xn),作者通过迭代地采样文本的分词选择单词,直到达到掩膜要求的大小(例如 X 的 15%),并形成 X 的子集 Y。在每次迭代中,作者首先从几何分布 l ~ Geo(p) 中采样得到分词的长度,该几何分布是偏态分布,偏向于较短的分词。之后,作者随机(均匀地)选择分词的起点。
基于预进行的实验,作者设定 p = 0.2,并将 l 裁剪为 lmax = 10 。因此分词的平均长度为 3.8 。作者还测量了词语(word)中的分词程度,使得添加掩膜的分词更长。图2展示了分词掩膜长度的分布情况。
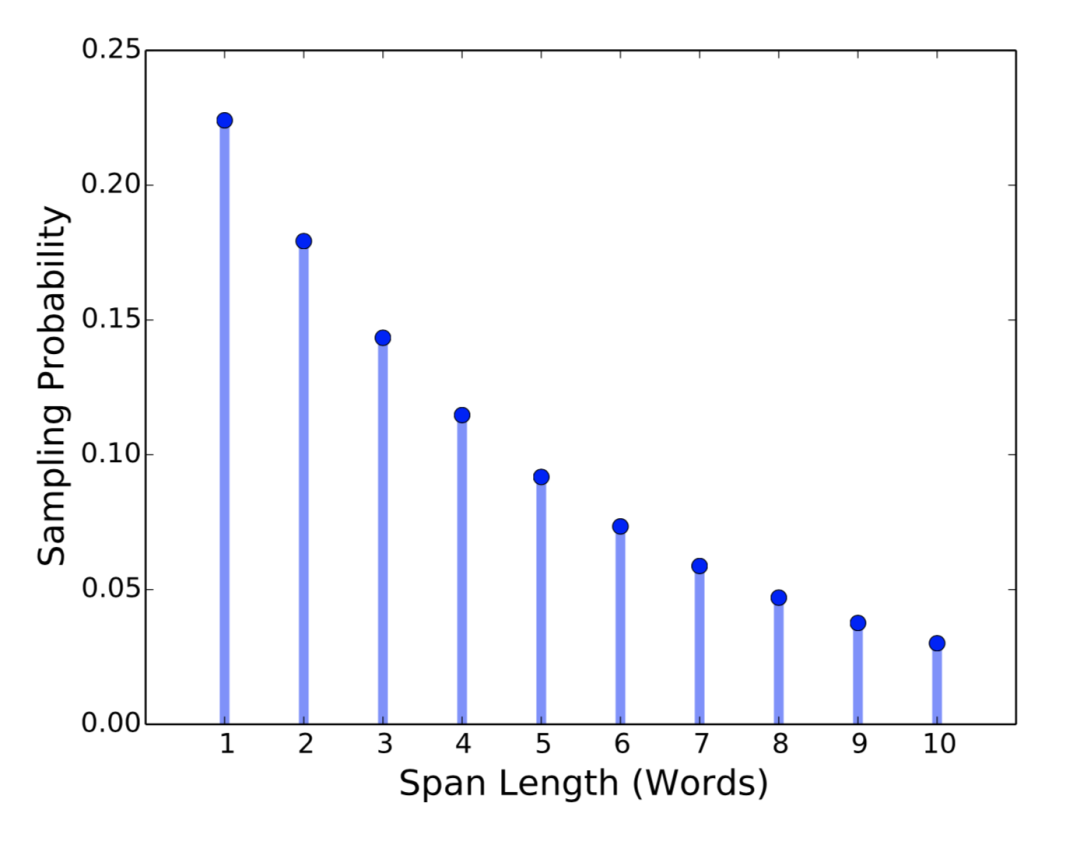
图2 分词长度(单词)
和在 BERT 中一样,作者将 Y 的规模设定为 X 的15%,其中 80% 使用 [MASK] 进行替换,10% 使用随机单词替换,10%保持不变。与之不同的是,作者是在分词级别进行的这一替换,而非将每个单词单独替换。
3.2 分词边界目标(SBO)
分词选择模型一般使用其边界词创建一个固定长度的分词表示。为了于该模型相适应,作者希望结尾分词的表示的总和与中间分词的内容尽量相同。为此,作者引入了 SBO ,其仅使用观测到的边界词来预测带掩膜的分词的内容(如图1)。
对于每一个带掩膜的分词 (xs, ..., xe) ,使用(s, e)表示其起点和终点。对于分词中的每个单词 xi ,使用外边界单词 xs-1 和 xe+1 的编码进行表示,并添加其位置嵌入信息 pi ,如下:
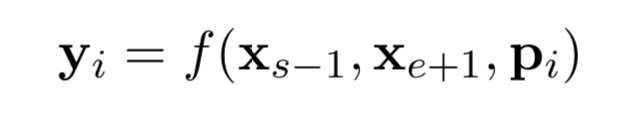
在本文中,作者使用一个两层的前馈神经网络作为表示函数,该网络使用 GeLu 激活函数,并使用层正则化:

作者使用向量表示 yi 来预测 xi ,并和 MLM 一样使用交叉熵作为损失函数。
对于带掩膜的分词中的每一个单词,SpanBERT 对分词边界和带掩膜的语言模型的损失进行加和。
3.3 单序列训练
BERT 使用两个序列 (XA, XB)进行训练,并预测两个句子是否邻接(NSP)。本文发现使用单个序列并移除 NSP 的效果比该方法更优。作者推测其可能原因如下:(a)更长的语境对模型更有利;(b)加入另一个文本的语境信息会给带掩膜的语言模型带来噪音。
因此,本文仅采样一个单独的邻接片段,该片段长度最多为512个单词,其长度与 BERT 使用的两片段的最大长度总和相同。
实验设置
4.1 任务
本文在多个任务中对模型进行了评测,包括7个问答任务,指代消解任务,9个 BLUE 基线中对任务,以及关系抽取任务。
抽取式问答
该任务的内容为,给定一个短文本和一个问题作为输入,模型从中抽取一个邻接分词作为答案。
本文首先在两个主要的问答任务基线 SQuAD 1.1 和 2.0 上进行了评测,之后在 5 个 MRQA 的共享任务中进行了评测,包括 NewsQA, TirviaQA, HotpotQA, Natural Questions(Natural QA)。由于 MRQA 任务没有一个公共的测试集,因此作者将开发集中的一半作为了测试集。由于这些数据集的领域和收集方式都不相同,这些任务能够很好地测试 SpanBERT 的泛化性能。
作者对所有数据集都使用了与 BERT 相同的 QA 模型。作者首先将文段 P = (p1, ..., pn)和问题 Q = (q1, ..., ql') 转化为一个序列 X = [CLS] p1 ... pl [SEP] q1 ... qL' [SEP] ,之后将其输入到预训练的 transformer 编码器中,并在其顶端独立训练两个线性分类器,用于预测回答分词的边界(起点和终点)。对于 SQuAD 2.0 中的不可回答问题,作者使用[CLS] 作为回答分词。
指代消解
该任务的内容为将文本中指向相同真实世界实体的内容进行聚类。作者在 CoNLL-2012 共享任务中进行了评测,该评测为文档级的指代消解。作者使用了高阶指代模型(higher-order coreference model),并将其中的 LSTM 编码器替换为了 BERT 的预训练 transformer 编码器。
关系抽取
本任务内容为,给定一个包含主语分词和宾语分词的句子,预测两个分词的关系,关系为给定的42种类型之一,包括 np_relation 。本文在 TACRED 数据集上进行了测试,并使用该文提出的实体掩膜机制进行了模型构建。作者使用 NER 标签对分词进行了替换,形如“[CLS] [SUBG-PER] was born in [OBJ-LOC], Michigan, ...”,并在模型顶端加入了一个线性分类器用于预测关系类型。
GLUE
GLUE 包含9 个句子级的分类任务,包括两个单句任务(CoLA, SST-2),三个句子相似度任务( MRPC, STS-B, QQP),四个自然语言推理任务( MNLI, QNLI, Gi-, WNLI)。近期的模型主要针对单个任务,但本文在所有任务上进行了评测。模型设置与 BERT 相同,并在顶端加入了一个线性分类器用于 [CLS] 单词。
4.2 实验步骤
作者在 fairseq 中对 BERT 模型和预训练方法重新进行了训练。本文与之前的最大不同在于,作者在每一个 epoch 使用了不同的掩膜,而 BERT 对每个序列采样了是个不同的掩膜。另外,初始的 BERT 的采样率较低,为 0.1, 本文则使用多达 512 个单词作为采样,直到到达文档的边界。
4.3 基线
本文与三个基线进行了比较,包括 Google BERT, 作者训练的 BERT ,以及作者训练的单序列 BERT。
结果
5.1 各任务结果
抽取式问答
表 1 展示了 SQuAD 1.1 和 2.0 上的结果,表 2 展示了其他数据集上的结果。可以发现 SpanBERT 的效果由于基线模型。
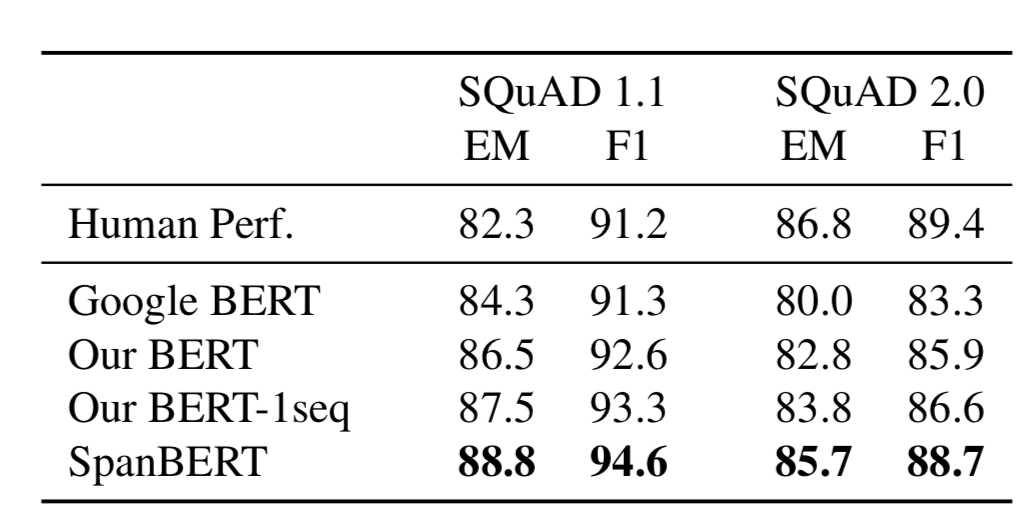
表1 SQuAD 1.1 和 2.0 数据集上的结果
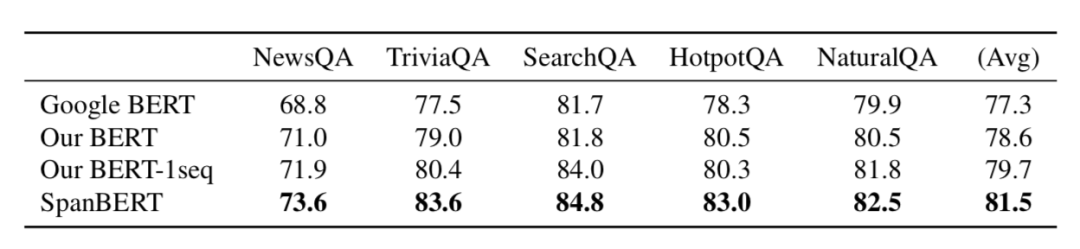
表2 其他五个数据集上的结果
指代消除
表3展示了 OntoNotes 上的模型表现。可以发现,SpanBERT 的模型效果优于基线。
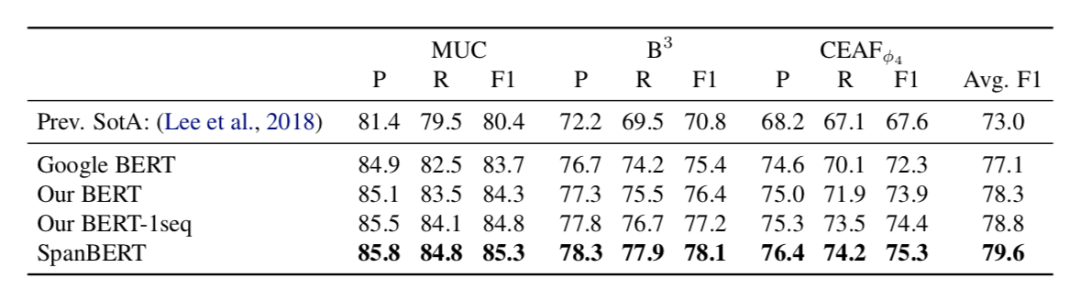
表3 OntoNotes 数据集上的结果
关系抽取
表5展示了 TACRED 上的模型效果。SpanBERT 的表现超出了基线模型的评分。
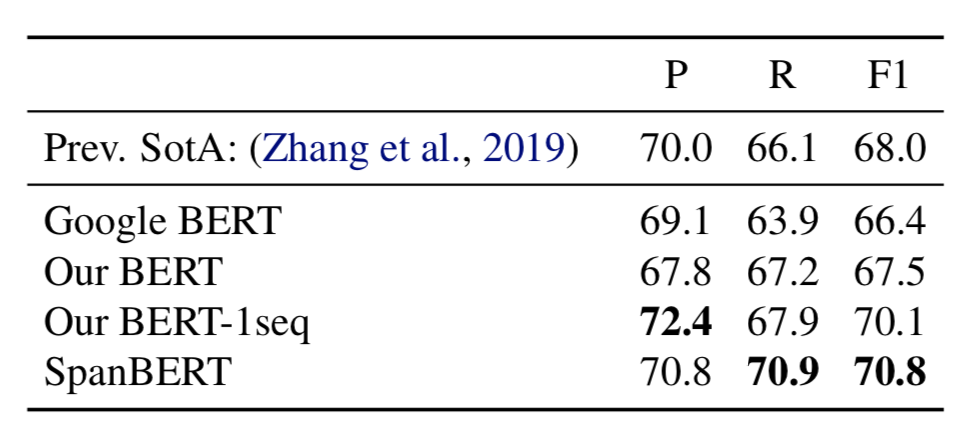
表5 TACRED 数据集上的结果
GLUE
表4 展示了 GLUE 上的模型表现, SpanBERT 同样超越了已有评分。

表4 GLUE 上的结果
5.2 整体趋势
通过实验可以发现, SpanBERT 在所有任务上的评分几乎都优于 BERT ,在抽取式问答任务中最为明显。另外,作者发现单序列的训练优于两个序列的训练效果,且不再需要使用 NSP 。
消融实验
本部分中,作者比较了随机分词掩膜机制和基于语言学信息的掩膜机制,发现本文使用的随机分词掩膜机制效果更优。另外,作者研究了 SBO 的影响,并与 BERT 使用的 NSP 进行了比较。
6.1 掩膜机制
作者在子单词、完整词语、命名实体、名词短语和随机分词方面进行了比较,表6展示了分析结果。
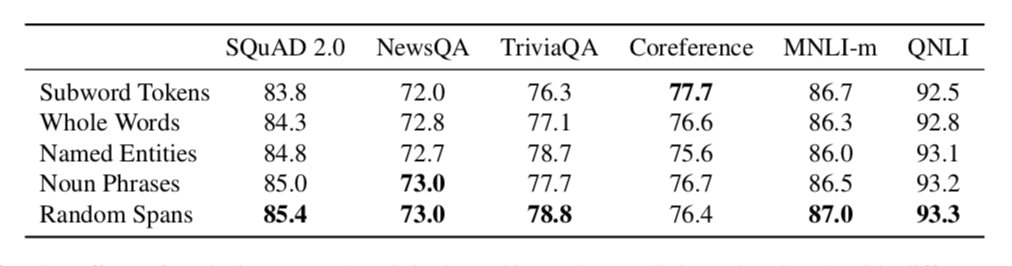
表6 使用不同掩膜机制替换 BERT 中掩膜机制的结果
6.2 辅助目标
表7展示了本实验的结果,可以发现,使用 SBO 替换 NSP 并使用单序列进行预测的效果更优。

表7 使用不同的辅助目标带来的影响
结论
本文提出了一个新的基于分词的预训练模型,并对 BERT 进行了如下改进:(1)对邻接随机分词而非随机单词添加掩膜;(2)使用分词边界的表示进行训练来预测添加掩膜的分词的内容,而不再使用单词的表示进行训练。本文模型在多个评测任务中的得分都超越了 BERT 且在分词选择类任务中的提升尤其明显。
原文链接:
https://arxiv.org/pdf/1907.10529.pdf
(*本文为 AI科技大本营编译文章,转载请联系微信 1092722531)
◆
精彩推荐
◆

“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。大会早鸟票倒计时最后一天,速抢进行中......
推荐阅读
肖仰华:知识图谱如何解决行业智能化的工程问题?
抢程序员饭碗?自动写代码的Deep TabNine真如此神奇?
单v100 GPU,4小时搜索到一个鲁棒的网络结构
别再说学不会:超棒的Numpy可视化学习教程来了!
再不要这样起变量名了!
17 岁成为 iOS 越狱之父,25 岁造出无人车,黑客传奇!
刚刚!为吊打谷歌,微软砸10亿美元布局AI,网友炸了!发帖上热门……
华为,百度豪投,这类程序员要再次上榜了!
百度入局, 一文读懂年交易过4亿「超级链」究竟是什么?
云计算将会让数据中心消失?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

XP与Windows 7(Win7)等操作系统Ghost备份
XP与Windows 7(Win7)等操作系统Ghost备份 2013年5月5日 前提:备份还原win7的话,此种Ghost备份方法只针对没有100MB保留分区的win7安装方式。去掉100MB的方法可以参考《Windows7(win7)系统重装与破解》&…

SSE4.1和SSE4.2 Intrinsics各函数介绍
SIMD相关头文件包括: //#include <ivec.h>//MMX //#include <fvec.h>//SSE(also include ivec.h) //#include <dvec.h>//SSE2(also include fvec.h)#include <mmintrin.h> //MMX #include <xmmintrin.h> //SSE(include mmintrin.h) #…
Nacos v0.7.0:对接CMDB,实现基于标签的服务发现能力
Nacos近期发布了0.7.0版本,该版本支持对接第三方CMDB获取CMDB数据、使用Selector机制来配置服务的路由类型、支持单机模式使用MySQL数据库、上线Node.js客户端,并修复了一些bug。对接CMDB实现就近访问在服务进行多机房或者多地域部署时,跨地域…

数十篇推荐系统论文被批无法复现:源码、数据集均缺失,性能难达预期
作者 | Maurizio Ferrari Dacrema译者 | 凯隐责编 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】来自意大利米兰理工大学的 Maurizio 团队近日发表了一篇极具批判性的文章,剑指推荐系统领域的其他数十篇论文,指出这些论文中基…

crontab 总结
2019独角兽企业重金招聘Python工程师标准>>> 1.写法 每三天执行一次:0 0 */3 * * root command,注意:* * */3 * * root command 这样写是不对的。其它每N小时执行一次也类似 (后续补充) 转载于:https://…
ubuntu安装thrift
ubuntu环境下安装thrift-0.10.0 1.解压 2.编译安装 ./configure -with-cpp -with-boost -without-python -without-csharp -with-java -without-erlang -without-perl -with-php -without-php_extension -without-ruby -without-haskell -without-go make sudo make install3.是…
AES(Advanced Encryption Standard) Intrinsics各函数介绍
AES为高级加密标准,是较流行的一种密码算法。 SIMD相关头文件包括: //#include <ivec.h>//MMX //#include <fvec.h>//SSE(also include ivec.h) //#include <dvec.h>//SSE2(also include fvec.h)#include <mmintrin.h> //MMX #…
轻松应对Java试题,这是一份大数据分析工程师面试指南
作者 | HappyMint转载自大数据与人工智能(ai-big-data)导语:经过这一段时间与读者的互动与沟通,本文作者发现很多小伙伴会咨询面试相关的问题,特别是即将毕业的小伙伴,所以决定输出一系列面试相关的文章。本…
【Elasticsearch 5.6.12 源码】——【3】启动过程分析(下)...
版权声明:本文为博主原创,转载请注明出处!简介 本文主要解决以下问题: 1、ES启动过程中的Node对象都初始化了那些服务?构造流程 Step 1、创建一个List暂存初始化失败时需要释放的资源,并使用临时的Logger对…
C++中的封装、继承、多态
封装(encapsulation):就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成”类”,其中数据和函数都是类的成员。封装的目的是增强安全性和简化编程&…
比尔盖茨护犊子 称iPad让大批用户沮丧
为什么80%的码农都做不了架构师?>>> 在5月6日接受美国CNBC电视台访问时,微软前任掌门人比尔盖茨维护了自家反响不那么好的Surface系列平板电脑,同时他还不忘吐槽了一把iPad。 当 谈到日渐颓败的PC市场时,盖茨称平板电…
小心陷阱:二维动态内存的不连续性
void new_test() {int** pp;pp new int*[10];for(int i0; i<10; i){pp[i] new int[10];}//pp[0], pp[1], ... , pp[9]在内存中连续;//a1 pp[0][0], pp[0][1], ... , pp[0][9]在内存中也是连续的;//a2 pp[1][0], pp[1][1], ... , pp[1][9]在内存中也是连续的;//...//a9 …
超酷炫!Facebook用深度学习和弱监督学习绘制全球精准道路图
作者 | Saikat Basu等译者 | 陆离责编 | 夕颜出品 | AI科技大本营(ID: rgznai100)导读:现如今,即使可以借助卫星图像和绘制软件,创建精确的道路图也依然是一个费时费力的人力加工过程。许多地区,特别是在发…

npm包发布记录
下雪了,在家闲着,不如写一个npm 包发布。简单的 npm 包的发布网上有很多教程,我就不记录了。这里记录下,一个复杂的 npm 包发布,复杂指的构建环境复杂。 整个工程使用 rollup 来构建,其中会引进 babel 来转…

设计模式之单例模式(Singleton)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式)࿱…
关于知识蒸馏,这三篇论文详解不可错过
作者 | 孟让转载自知乎导语:继《从Hinton开山之作开始,谈知识蒸馏的最新进展》之后,作者对知识蒸馏相关重要进行了更加全面的总结。在上一篇文章中主要介绍了attention transfer,FSP matrix和DarkRank,关注点在于寻找不…
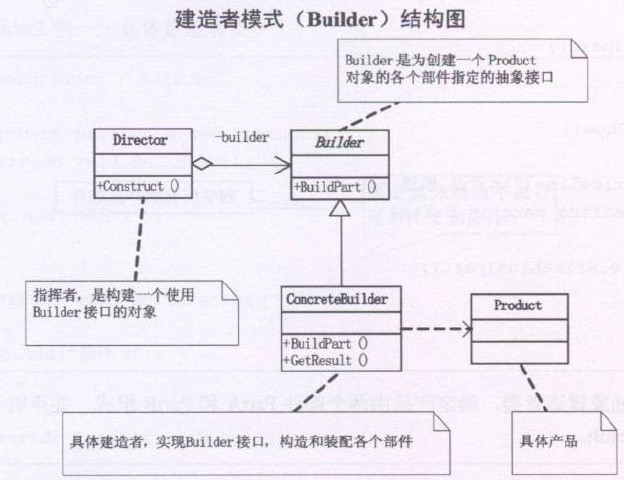
设计模式之建造者模式(生成器模式、Builder)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…

[置顶] webservice系列2---javabeanhandler
摘要:本节主要介绍以下两点,1.带javabean的webservice的开发和调用 2.handler的简单介绍及使用1.引言在之前的一篇博客webservice系列1---基于web工程上写一个基本数据类型的webservice中介绍了如何采用axis1.4来完成一个简单的webservice的开发流程(入参…
AI教育公司物灵科技完成战略融资,商汤科技投资
1月2日消息,从相关媒体报道,AI教育公司物灵科技近日完成了商汤的战略融资,本轮融资将用于产品迭代和扩大市场。 此前投资界曾报道,物灵科技已经获得1.5亿元Pre-A轮融资,当时具体资方未透露。 公开资料显示࿰…

Python之父发文,将重构现有核心解析器
原题 | PEG Parsers作者 | Guido van Rossum译者 | 豌豆花下猫转载自 Python猫(ID: python_cat) 导语:Guido van Rossum 是 Python 的创造者,虽然他现在放弃了“终身仁慈独裁者”的职位,但却成为了指导委员会的五位成员…
全面支持三大主流环境 |百度PaddlePaddle新增Windows环境支持
2019独角兽企业重金招聘Python工程师标准>>> PaddlePaddle作为国内首个深度学习框架,最近发布了更加强大的Fluid1.2版本, 增加了对windows环境的支持,全面支持了Linux、Mac、 windows三大环境。 PaddlePaddle在功能完备的基础上,也…
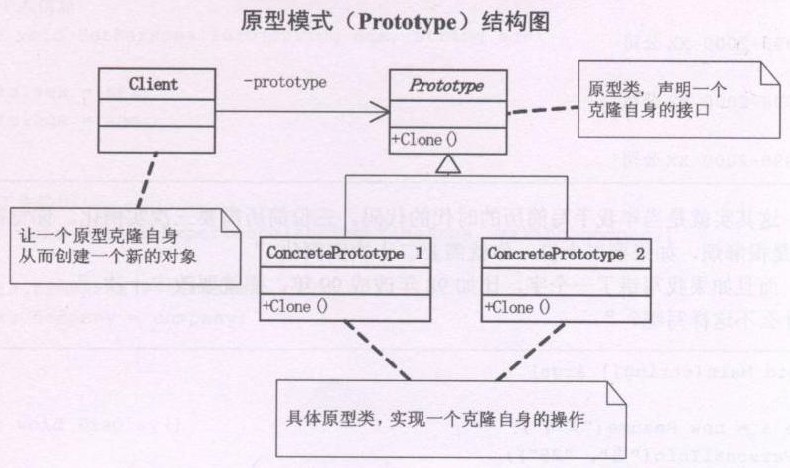
设计模式之原型模式(Prototype)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
NFS共享服务挂载时出现“access denied by server while mounting”的解决方法
笔者用的Linuxf发行版本为Centos6.4,以下方法理论上讲对于Fedora, Red Hat均有效: 搭建好NFS服务后,如果用以下的命令进行挂载: # mount -t nfs 172.16.12.140:/home/liangwode/test /mnt 出现如下错误提示: mount.nf…
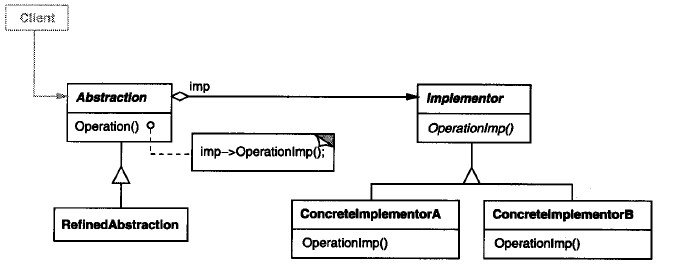
设计模式之桥接模式(Bridge)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
原360首席科学家颜水成正式加入依图科技,任首席技术官
7 月 29 日,依图科技宣布原 360 首席科学家颜水成正式加入,担任依图科技首席技术官(CTO)一职。依图方面称,颜水成加入后将带领团队进一步夯实依图在人工智能基础理论和原创算法方面的技术优势,为依图在商业…
分布式存储fastdfs安装使用
1.下载地址https://github.com/happyfish100/fastdfshttps://github.com/happyfish100/fastdfs/wiki安装辅助说明文档2.安装编译环境yum install git gcc gcc-c make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel wget vim -y三台主机:…

Hibernate学习(九)———— 二级缓存和事务级别详讲
序言 这算是hibernate的最后一篇文章了,下一系列会讲解Struts2的东西,然后说完Struts2,在到Spring,然后在写一个SSH如何整合的案例。之后就会在去讲SSM,在之后我自己的个人博客应该也差不多可以做出来了。基本上先这样…

超详细中文预训练模型ERNIE使用指南
作者 | 高开远,上海交通大学,自然语言处理研究方向最近在工作上处理的都是中文语料,也尝试了一些最近放出来的预训练模型(ERNIE,BERT-CHINESE,WWM-BERT-CHINESE),比对之后还是觉得百…
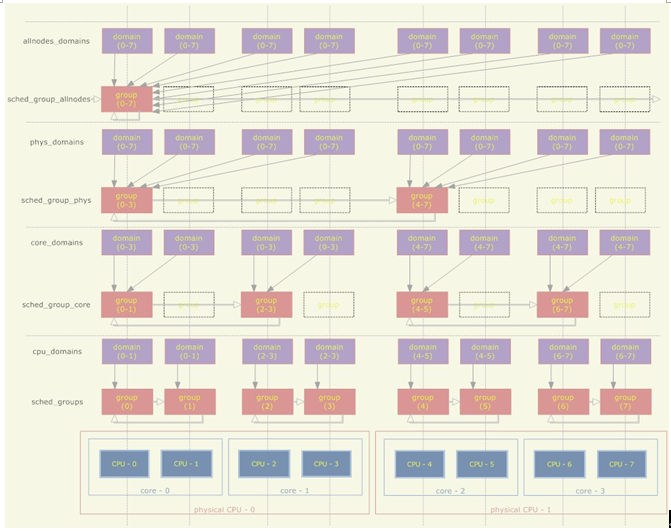
linux内核SMP负载均衡浅析
需求 在《linux进程调度浅析》一文中提到,在SMP(对称多处理器)环境下,每个CPU对应一个run_queue(可执行队列)。如果一个进程处于TASK_RUNNING状态(可执行状态),则它…
结构体中最后一个成员为[0]或[1]长度数组(柔性数组成员)的用法
结构体中最后一个成员为[0]长度数组的用法:这是个广泛使用的常见技巧,常用来构成缓冲区。比起指针,用空数组有这样的优势:(1)、不需要初始化,数组名直接就是所在的偏移;(2)、不占任何空间,指针需…