Python之父发文,将重构现有核心解析器

原题 | PEG Parsers
作者 | Guido van Rossum
译者 | 豌豆花下猫
转载自 Python猫(ID: python_cat)
导语:Guido van Rossum 是 Python 的创造者,虽然他现在放弃了“终身仁慈独裁者”的职位,但却成为了指导委员会的五位成员之一,其一举一动依然备受瞩目。近日,他开通了 Medium 账号,并发表了第一篇文章,透露出要替换 Python 的核心部件(解析器)的想法。这篇文章分析了当前的 pgen 解析器的诸多缺陷,并介绍了 PEG 解析器的优点,令人振奋。这项改造工作仍在进行中,Guido 说他还会写更多相关的文章。
几年前,有人问 Python 是否会转换用 PEG 解析器(或者是 PEG 语法,我不记得确切内容、谁说的、什么时候说的)。我稍微看过这个主题,但没有头绪,就放弃了。
最近,我学了很多关于 PEG(Parsing Expression Grammars)的知识,如今我认为它是个有趣的替代品,正好替换掉我在 30 年前刚开始创造 Python 时自制的(home-grown)语法分析生成器(parser generator)(那个语法分析生成器,被称为“pgen”,是我为 Python 写下的第一段代码)。
我现在感兴趣于 PEG,原因是对 pgen 的局限性感到有些恼火了。
它使用了我自己写的 LL(1) 解析的变种——我不喜欢可以产生空字符串的语法规则,所以我禁用了它,进而稍微地简化了生成解析表的算法。
同时,我还发明了一套类似 EBNF 的语法符号(译注:Extended Backus-Naur Form,BNF 的扩展,是一种形式化符号,用于描述给定语言中的语法),至今仍非常喜欢。
以下是 pgen 令我感到烦恼的一些问题。
LL(1) 名字中的 “1” 表明它只使用单一的前向标记符(a single token lookahead),而这限制了我们编写漂亮的语法规则的能力。例如,一个 Python 语句(statement)既可以是表达式(expression),又可以是赋值(assignment)(或者是其它东西,但那些都以 if 或 def 这类专用的关键字开头)。
我们希望使用 pgen 表示法来编写如下的语法。(请注意,这个示例描述了一种玩具语言(toy language),它是 Python 的一个微小的子集,就像传统中的语言设计一样。)
关于这些符号,解释几句:NAME 和 NUMBER 是标记符(token),预定义在语法之外。引号中的字符串如 '+' 或 'if' 也是标记符。(我以后会讲讲标记符。)语法规则以其名称开头,跟在后面的是 : 号,再后面则是一个或多个以 | 符号分隔的可选内容(alternatives)。
但问题是,如果你这样写语法,解析器不会起作用,pgen 将会罢工。
其中一个原因是某些规则(如 expr 和 term)是左递归的,而 pgen 还不足以聪明地解析。这通常需要通过重写规则来解决,例如(在保持其它规则不变的情况下):
这就揭示了 pgen 的一部分 EBNF 能力:你可以在括号内嵌套可选内容,并且可以在括号后放 * 来创建重复,所以这里的 expr 规则就意味着:它是一个术语(term),跟着零个或多个语句块,语句块内是加号跟术语,或者是减号跟术语。
这个语法兼容了第一个版本的语言,但它并没有反映出语言设计者的本意——尤其是它并没有表明运算符是左绑定的,而这在你尝试生成代码时非常重要。
但是在这种玩具语言(以及在 Python)中,还有另一个烦人的问题。
由于前向的单一标记符,解析器无法确定它查看的是一个表达式的开头,还是一个赋值。在一个语句的开头,解析器需要根据它看到的第一个标记符,来决定它要查看的 statement 的可选内容。(为什么呢?pgen 的自动解析器就是这样工作的。)
假设我们的程序是这样的:
这句程序会被解析成三个标记符:NAME(值是answer),‘=’ 和 NUMBER(值为 42)。在程序开始时,我们拥有的唯一的前向标记符是 NAME。此时,我们试图满足的规则是statement(这个语法的起始标志)。此规则有三个可选内容:expr、assignment以及if_statement。我们可以排除if_statement,因为前向标记符不是 “if”。
但是 expr 与 assignment 都能以 NAME 标记符开头,因此就会引起歧义(ambiguous),pgen 会拒绝我们的语法。
(这也不完全正确,因为语法在技术上并不会导致歧义;但我们先不管它,因为我想不到更好的词来表达。那么 pgen 是如何做决定的呢?它会为每条语法规则计算出一个叫做 FIRST 组的东西,如果在给定的点上,FIRST 组出现了重叠选项,它就会抱怨)(译注:抱怨?应该指的是解析不下去,前文译作了罢工)。
那么,我们能否为解析器提供一个更大的前向缓冲区,来解决这个烦恼呢?
对于我们的玩具语言,第二个前向标记符就足够了,因为在这个语法中,assignment 的第二个标记符必须是 “=”。
但是在 Python 这种更现实的语言中,你可能需要一个无限的前向缓冲,因为在 “=” 标记符左侧的东西可能极其复杂,例如:
在 “=” 标记符之前,它已经用了 10 个标记符,如果想挑战的话,我还可以举出任意长的例子。为了在 pgen 中解决它,我们的方法是修改语法,并增加一个额外的检查,令它能接收一些非法的程序,但如果检查到对左侧的赋值是无效的,则会抛出一个 SyntaxError 。
对于我们的玩具语言,这可归结成如下写法:
(方括号表示了一个可选部分。)然后在随后的编译过程中(比如,在生成字节码时),我们会检查是否存在 “=”,如果存在,我们再检查左侧是否有 target 语法。
在调用函数时,关键字参数也有类似的麻烦。我们想要写成这样(同样,这是 Python 的调用语法的简化版本):
但是前向的单一标记符无法告诉解析器,一个参数的开头中的 NAME 到底是 posarg 的开头(因为 expr 可能以 NAME 开头)还是 kwarg 的开头。
同样地,Python 当前的解析器在解决这个问题时,是通过特别声明:
然后在后续的编译过程中再解决问题。(我们甚至出了点小错,允许了像 foo((a)=1) 这样的东西,给了它跟 foo(a=1) 相同的含义,直到 Python 3.8 时才修复掉。)
那么,PEG 解析器是如何解决这些烦恼的呢?
通过使用无限的前向缓冲!PEG 解析器的经典实现中使用了一个叫作“packrat parsing”(译注:PackRat,口袋老鼠)的东西,它不仅会在解析之前将整个程序加载到内存中,而且还能允许解析器任意地回溯。
虽然 PEG 这个术语主要指的是语法符号,但是以 PEG 语法生成的解析器是可以无限回溯的递归下降(recursive-descent)解析器,“packrat parsing”通过记忆每个位置所匹配的规则,来使之生效。
这使一切变得简单,然而当然也有成本:内存。
三十年前,我有充分的理由来使用单一前向标记符的解析技术:内存很昂贵。LL(1) 解析(以及其它技术像 LALR(1),因 YACC 而著名)使用状态机和堆栈(一种“下推自动机”)来有效地构造解析树。
幸运的是,运行 CPython 的计算机比 30 年前有了更多的内存,将整个文件存在内存中确实已不再是一个负担。例如,我能在标准库中找到的最大的非测试文件是 _pydecimal.py,它大约有 223 千字节(译注:kilobytes,即 KB)。在一个 GB 级的世界里,这基本不算什么。
这就是令我再次研究解析技术的原因。
但是,当前 CPython 中的解析器还有另一个 bug 我的东西。
编译器都是复杂的,CPython 也不例外:虽然 pgen-驱动的解析器输出的是一个解析树,但是这个解析树并不直接用作代码生成器的输入:它首先会被转换成抽象语法树(AST),然后再被编译成字节码。(还有更多细节,但在这我不关注。)
为什么不直接从解析树编译呢?这其实正是它最早的工作方式,但是大约在 15 年前,我们发现编译器因为解析树的结构而变得复杂了,所以我们引入了一个单独的 AST,还引入了一个将解析树翻译成 AST 的环节。随着 Python 的发展,AST 比解析树更稳定,这减少了编译器出错的可能。
AST 对于那些想要检查(inspect)Python 代码的第三方代码,也更加容易,它还通过被大众欢迎的 ast 模块而公开。这个模块还允许你从头构建 AST 节点,或是修改现有的 AST 节点,然后你可以将新的节点编译成字节码。
后一项能力支撑起了一整个为 Python 语言添加扩展的家庭手工业(译注:ast 模块为 Python 的三方扩展提供了便利)。(借助 parser 模块,解析树同样能面向 Python 的用户开放,但它使用起来太麻烦了,因此相比于 ast 模块,它就过时了。)
综上所述,我现在的想法是看看能否为 CPython 创造一个新的解析器,在解析时,使用 PEG 与 packrat parsing 来直接构建 AST,从而跳过中间解析树结构,并尽可能地节省内存,尽管它会使用无限的前向缓冲。
我还没进展到这个地步,但已经有了一个原型,可以将一个 Python 的子集编译成一个 AST,其速度与当前 CPython 的解析器大致相当。只不过,它占用的内存更多,所以我预计在将它扩展到整个语言时,将会降低 PEG 解析器的速度。
但是,我还没去优化它,所以还是挺有希望的。
转换成 PEG 的最后一个好处是它为语言的未来演化提供了更大的灵活性。
过去有人曾说,pgen 的 LL(1) 缺陷帮助了 Python 保持语法的简单。这很有道理,但我们还有很多适当的流程,可以防止语言不受控制地膨胀(主要是 PEP 流程,在非常严格的向后兼容性要求以及新的治理结构的帮助下)。所以我并不担心。
我还有很多内容要写,关于 PEG 解析以及我的具体实现,但是要等我整理好代码后,在后续的文章中再去写了。
原文链接:
https://medium.com/@gvanrossum_83706/peg-parsers-7ed72462f97c
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。大会早鸟票已售罄,优惠票限时抢购中......
推荐阅读
懂得“作恶”,机器人才算拥有人类的心智?
数十篇推荐系统论文被批无法复现:源码、数据集均缺失,性能难达预期
SpanBERT:提出基于分词的预训练模型,多项任务性能超越现有模型!
百度、快手、商汤、旷视、图森等重磅嘉宾确认出席AI ProCon 2019
抢程序员饭碗?自动写代码的Deep TabNine真如此神奇?
华为收入超过阿里腾讯总和!等等,先把鸿蒙说清楚!
扎克伯格再谈Libra:为十亿人打造“金融梦”(全文)
漫画 | Kubernetes带你一帆风顺去远航
“对不起,我就是传说中的 10 倍工程师”
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

全面支持三大主流环境 |百度PaddlePaddle新增Windows环境支持
2019独角兽企业重金招聘Python工程师标准>>> PaddlePaddle作为国内首个深度学习框架,最近发布了更加强大的Fluid1.2版本, 增加了对windows环境的支持,全面支持了Linux、Mac、 windows三大环境。 PaddlePaddle在功能完备的基础上,也…
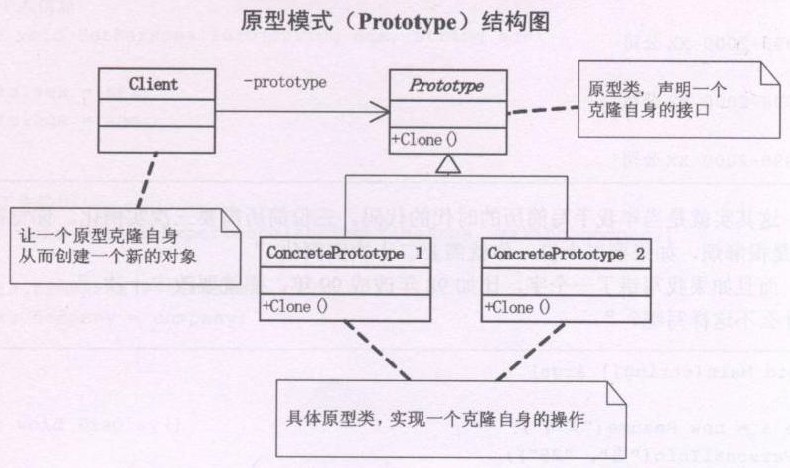
设计模式之原型模式(Prototype)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…

NFS共享服务挂载时出现“access denied by server while mounting”的解决方法
笔者用的Linuxf发行版本为Centos6.4,以下方法理论上讲对于Fedora, Red Hat均有效: 搭建好NFS服务后,如果用以下的命令进行挂载: # mount -t nfs 172.16.12.140:/home/liangwode/test /mnt 出现如下错误提示: mount.nf…
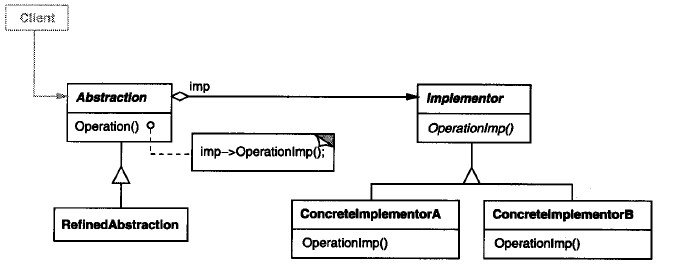
设计模式之桥接模式(Bridge)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
原360首席科学家颜水成正式加入依图科技,任首席技术官
7 月 29 日,依图科技宣布原 360 首席科学家颜水成正式加入,担任依图科技首席技术官(CTO)一职。依图方面称,颜水成加入后将带领团队进一步夯实依图在人工智能基础理论和原创算法方面的技术优势,为依图在商业…
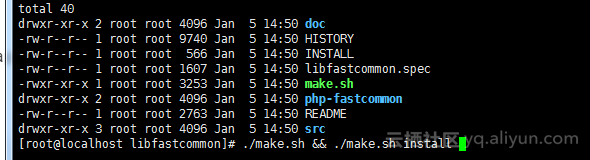
分布式存储fastdfs安装使用
1.下载地址https://github.com/happyfish100/fastdfshttps://github.com/happyfish100/fastdfs/wiki安装辅助说明文档2.安装编译环境yum install git gcc gcc-c make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel wget vim -y三台主机:…

Hibernate学习(九)———— 二级缓存和事务级别详讲
序言 这算是hibernate的最后一篇文章了,下一系列会讲解Struts2的东西,然后说完Struts2,在到Spring,然后在写一个SSH如何整合的案例。之后就会在去讲SSM,在之后我自己的个人博客应该也差不多可以做出来了。基本上先这样…

超详细中文预训练模型ERNIE使用指南
作者 | 高开远,上海交通大学,自然语言处理研究方向最近在工作上处理的都是中文语料,也尝试了一些最近放出来的预训练模型(ERNIE,BERT-CHINESE,WWM-BERT-CHINESE),比对之后还是觉得百…
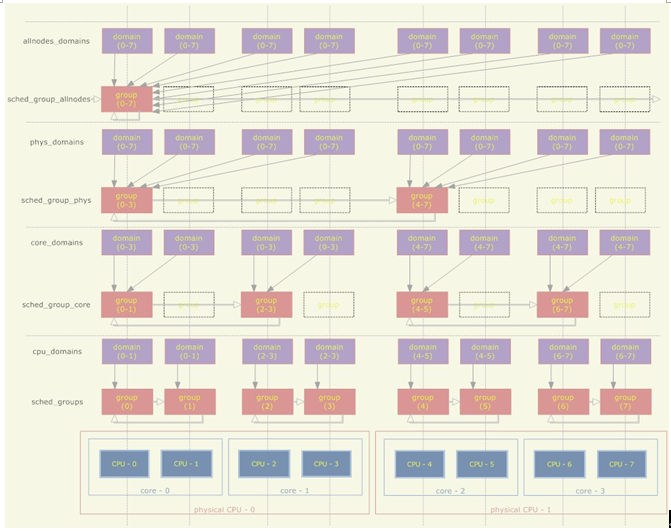
linux内核SMP负载均衡浅析
需求 在《linux进程调度浅析》一文中提到,在SMP(对称多处理器)环境下,每个CPU对应一个run_queue(可执行队列)。如果一个进程处于TASK_RUNNING状态(可执行状态),则它…
结构体中最后一个成员为[0]或[1]长度数组(柔性数组成员)的用法
结构体中最后一个成员为[0]长度数组的用法:这是个广泛使用的常见技巧,常用来构成缓冲区。比起指针,用空数组有这样的优势:(1)、不需要初始化,数组名直接就是所在的偏移;(2)、不占任何空间,指针需…
超全!深度学习在计算机视觉领域的应用一览
作者 | 黄浴,奇点汽车美研中心首席科学家兼总裁转载自知乎简单回顾的话,2006年Geoffrey Hinton的论文点燃了“这把火”,现在已经有不少人开始泼“冷水”了,主要是AI泡沫太大,而且深度学习不是包治百病的药方。计算机视…

SHAREPOINT2010数据库升级2013
在作TEST-SPCONTENT命令时,会提示认证方式不一样。 The [SharePoint - 80] web application is configured with claims authentication mode however the content database you are trying to attach is intended to be used against a windows classic authentic…
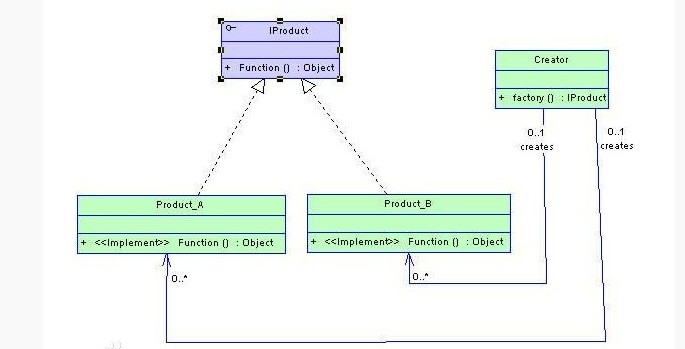
设计模式之简单工厂模式(Simply Factory)摘录
从设计模式的类型上来说,简单工厂模式是属于创建型模式,又叫静态工厂方法(Static Factory Method)模式,但不属于23种GOF设计模式之一。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的…
别得意,你只是假装收藏了而已
今天分享我在看罗振宇的《2018 时间的朋友》演讲视频记下的一些思考。跨年演讲中有过这样的一个来自印象笔记的片段,列举了几组对比来说明: 『你在朋友圈里又佛又丧,你在收藏夹里偷偷地积极向上。』 扎心了,这不就是说我吗&#x…

Exchange2003-2010迁移系列之四,配置第一台Exchange CAS/HUB服务器
配置第一台CAS/HUB关于Cas/hub的配置请大家详见前面关于Ex2010的部署(两个配置基本相同在这里就不做详细的解说了)下面关于Cas的配置在前面已经提到了但是下面是另一种新的方法大家就看看吧生产环境中部署Exchange2010服务器时,是需要按照一定…
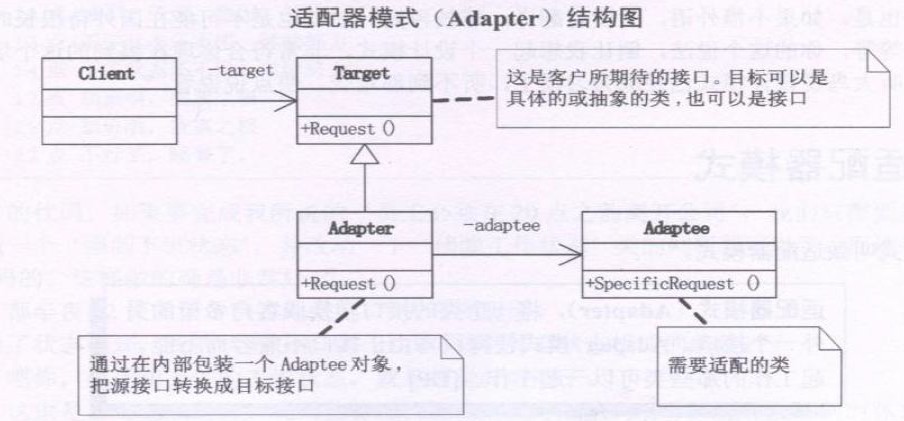
设计模式之适配器模式(Adapter)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…
JAVA方法中的参数用final来修饰的效果
很多人都说在JAVA中用final来修饰方法参数的原因是防止方法参数在调用时被篡改,其实也就是这个原因,但理解起来可能会有歧义,我们需要注意的是,在final修饰的方法参数中,如果修饰的是基本类型,那么在这个方…

2019世界机器人大赛圆满落幕,荆州中学等15支队伍获「全能奖」
7月28日,2019世界机器人大赛总决赛在河北保定圆满落下帷幕。保定市市委常委罗德强、中国电子学会副秘书长梁靓、保定市政府秘书长王保辉、保定市政府副秘书长安利文、保定市徐水区区长李志永、保定市莲池区政府党组副书记赵建军、世界机器人大赛组委会秘书长李洋、长…

在任何设备上都完美呈现的30个华丽的响应式网站
如今,一个网站只在桌面屏幕上好看是远远不够的,同时也要在平板电脑和智能手机中能够良好呈现。响应式的网站是指它能够适应客户端的屏幕尺寸,自动响应客户端尺寸变化。在这篇文章中,我将向您展示在任何设备上都完美的30个华丽的响…
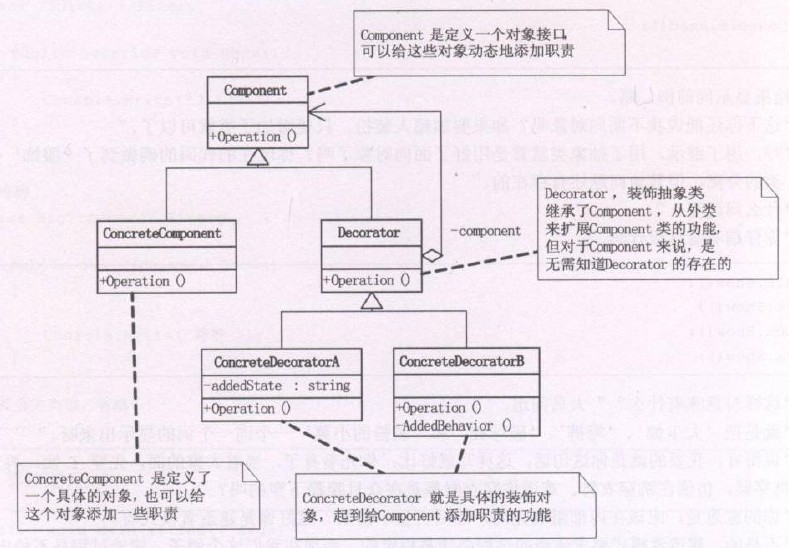
设计模式之装饰模式(Decorator)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…

解决流程自动化“最后一公里问题”,达观数据发布智能 RPA
2019 年7月 26 日,业界领先的人工智能企业达观数据在北京召开“达道至简”为主题的产品发布会,正式推出国内首款自主研发集OCR(光学字符识别)与 NLP(自然语言处理)于一体的达观智能RPA。达观数据创始人兼CEO陈运文、副总裁金克、贾学锋和联合创始人高翔携…
利用脚本生成GUID
实际上,可以使用一种非常简单的方法来生成 GUID,但这种方法近乎像是作弊。(您可听清楚了,我们说的可是“近乎”。)“Scriptlet.TypeLib”对象的设计用途是帮助您创建“Windows 脚本组件”(实质上࿰…
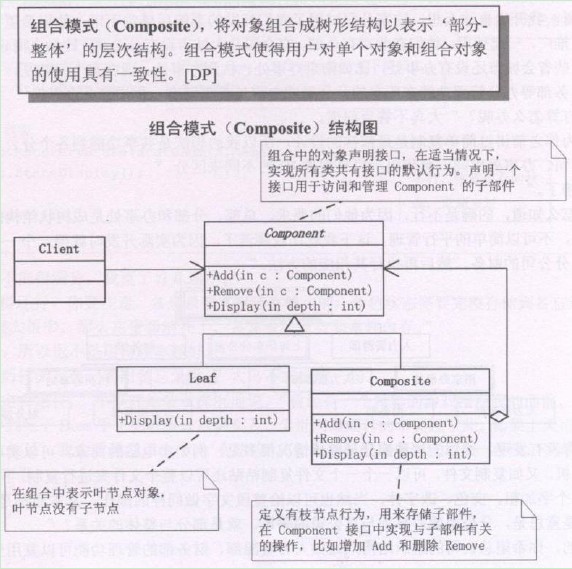
设计模式之组合模式(Composite)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…
快速开发生命周期支持工具
去年有幸研究公司管理产品的软件平台,当时考虑的产品是基于业务模型之上的一个系统平台,从建模到运行、部署、维护全生命周期管理.当时就提出两个希望先实践解决的就是可复用原型的设计和使用工作流和规则引擎的协作处理询标产品.前一阵子在公司研究成本产品的成本分析和算法,一…
华人学者解开计算机领域30年难题:布尔函数敏感度猜想
整理 | 郭芮来源 | CSDN(ID:CSDNnews)1992年,布尔函数敏感度猜想(Boolean Sensitivity)被提出,这成为了理论计算机科学近三十年来最重要、最令人困惑的开放性问题之一。而近日,来自E…
从1.5K到18K 一个程序员的5年成长之路(二)
这一切都来自于心态CSDN:从开始学习,到学有所成和找工作,再到工作中遇到各种困难,然后获得突破,在整个过程中,能总结下你心态都有哪些变化?是用运用什么方法或方式进行调整?雷果国&a…
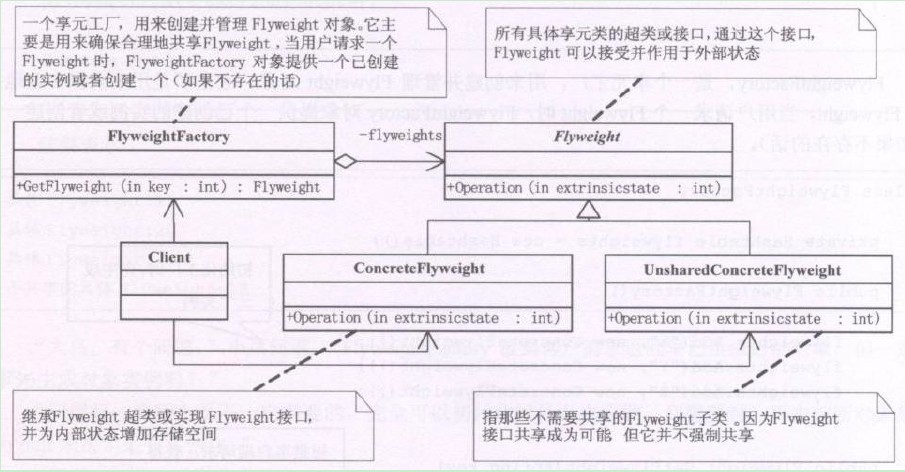
设计模式之享元模式(Flyweight)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…

你想见的大神都来AI ProCon 2019了,优惠票限时抢购开启!
如今 AI 的发展真实地面临着诸多瓶颈、尽管很多智能助手已经可以执行很多任务,但距离真正的人机自然交互还需要很长时间;强人工智能也迟迟未出现,不知何时才能出现;现有的 AI 只能做好一件事,Alpha Go 只会下棋&#x…
qt练习11 鼠标,按键,滚轮事件学习
源代码: http://files.cnblogs.com/hnrainll/event.zip

windows server 2008 R2上安装MRTG指南
一、实验环境 参考教程:http://www.netmon.org/dummies.htm http://www.docin.com/p-158415185.html MRTG中文手册:http://bbs.chinaunix.net/thread-1344687-1-1.html http://www.enterastream.com/whitepapers/mrtg/mrtg-manual-cap9.html 1.硬件平台 …