【Elasticsearch 5.6.12 源码】——【3】启动过程分析(下)...
版权声明:本文为博主原创,转载请注明出处!
简介
本文主要解决以下问题:
1、ES启动过程中的Node对象都初始化了那些服务?
构造流程
Step 1、创建一个List暂存初始化失败时需要释放的资源,并使用临时的Logger对象输出开始初始化的日志。
这里首先创建了一个
List<Closeable>然后输出日志initializing ...。代码比较简单:
final List<Closeable> resourcesToClose = new ArrayList<>(); // register everything we need to release in the case of an error
boolean success = false;{// use temp logger just to say we are starting. we can't use it later on because the node name might not be setLogger logger = Loggers.getLogger(Node.class, NODE_NAME_SETTING.get(environment.settings()));logger.info("initializing ...");}Step 2、强制设置settings中client.type的配置为node,设置node.name并检查索引data目录的设置。
这部分首先设置
client.type为node,接下来调用TribeService的processSettings方法来处理了“部落”的配置,然后创建NodeEnvironment,检查并设置node.name属性,最后按需检查索引数据的Path的配置并打印一些JVM的信息。代码如下:
Settings tmpSettings = Settings.builder().put(environment.settings()).put(Client.CLIENT_TYPE_SETTING_S.getKey(), CLIENT_TYPE).build();tmpSettings = TribeService.processSettings(tmpSettings);// create the node environment as soon as possible, to recover the node id and enable loggingtry {nodeEnvironment = new NodeEnvironment(tmpSettings, environment);resourcesToClose.add(nodeEnvironment);} catch (IOException ex) {throw new IllegalStateException("Failed to create node environment", ex);}final boolean hadPredefinedNodeName = NODE_NAME_SETTING.exists(tmpSettings);Logger logger = Loggers.getLogger(Node.class, tmpSettings);final String nodeId = nodeEnvironment.nodeId();tmpSettings = addNodeNameIfNeeded(tmpSettings, nodeId);if (DiscoveryNode.nodeRequiresLocalStorage(tmpSettings)) {checkForIndexDataInDefaultPathData(tmpSettings, nodeEnvironment, logger);}// this must be captured after the node name is possibly added to the settingsfinal String nodeName = NODE_NAME_SETTING.get(tmpSettings);if (hadPredefinedNodeName == false) {logger.info("node name [{}] derived from node ID [{}]; set [{}] to override", nodeName, nodeId, NODE_NAME_SETTING.getKey());} else {logger.info("node name [{}], node ID [{}]", nodeName, nodeId);}Step 3、创建PluginsService及Environment实例。
在
PluginsService的构造方法中会加载plugins和modules目录下的jar包,并创建相应的plugin和module实例。创建完以后,Node的构造方法中会调用pluginsService的updatedSettings方法来获取plugin和module中定义的配置项。接下来Node或使用新的settings和nodeId来创建LocalNodeFactory,并使用最新的settings重新创建Environment对象。代码如下:
this.pluginsService = new PluginsService(tmpSettings, environment.modulesFile(), environment.pluginsFile(), classpathPlugins);this.settings = pluginsService.updatedSettings();localNodeFactory = new LocalNodeFactory(settings, nodeEnvironment.nodeId());// create the environment based on the finalized (processed) view of the settings// this is just to makes sure that people get the same settings, no matter where they ask them fromthis.environment = new Environment(this.settings);Environment.assertEquivalent(environment, this.environment);Step 4、创建ThreadPool及ThreadContext实例。
首先,通过
pluginsService获取plugin及module中提供的ExecutorBuilder对象列表。接下来基于settings及获取的ExecutorBuilder对象列表创建ThreadPool及ThreadContext实例。代码如下:
final ThreadPool threadPool = new ThreadPool(settings, executorBuilders.toArray(new ExecutorBuilder[0]));resourcesToClose.add(() -> ThreadPool.terminate(threadPool, 10, TimeUnit.SECONDS));// adds the context to the DeprecationLogger so that it does not need to be injected everywhereDeprecationLogger.setThreadContext(threadPool.getThreadContext());resourcesToClose.add(() -> DeprecationLogger.removeThreadContext(threadPool.getThreadContext()));Step 5、依次创建NodeClient、ResourceWatcherService、ScriptModule、AnalysisModule、SettingsModule、NetworkService、ClusterService、IngestService及ClusterInfoService等主要模块。
ScriptModule中持有ScriptService通过该服务可以获取到ES中配置的各类脚本引擎的实例。AnalysisModule中持有AnalysisRegistry对象,通过该对象可以获取到ES中配置的各类查询分析器的实例。SettingModule中按类型保存了ES中可以解析的配置对象。NetworkService主要用来解析网络地址,ClusterService用例维护集群的信息。代码如下:
final List<Setting<?>> additionalSettings = new ArrayList<>(pluginsService.getPluginSettings());final List<String> additionalSettingsFilter = new ArrayList<>(pluginsService.getPluginSettingsFilter());for (final ExecutorBuilder<?> builder : threadPool.builders()) {additionalSettings.addAll(builder.getRegisteredSettings());}client = new NodeClient(settings, threadPool);final ResourceWatcherService resourceWatcherService = new ResourceWatcherService(settings, threadPool);final ScriptModule scriptModule = ScriptModule.create(settings, this.environment, resourceWatcherService,pluginsService.filterPlugins(ScriptPlugin.class));AnalysisModule analysisModule = new AnalysisModule(this.environment, pluginsService.filterPlugins(AnalysisPlugin.class));additionalSettings.addAll(scriptModule.getSettings());// this is as early as we can validate settings at this point. we already pass them to ScriptModule as well as ThreadPool// so we might be late here alreadyfinal SettingsModule settingsModule = new SettingsModule(this.settings, additionalSettings, additionalSettingsFilter);scriptModule.registerClusterSettingsListeners(settingsModule.getClusterSettings());resourcesToClose.add(resourceWatcherService);final NetworkService networkService = new NetworkService(settings,getCustomNameResolvers(pluginsService.filterPlugins(DiscoveryPlugin.class)));final ClusterService clusterService = new ClusterService(settings, settingsModule.getClusterSettings(), threadPool,localNodeFactory::getNode);clusterService.addStateApplier(scriptModule.getScriptService());resourcesToClose.add(clusterService);final IngestService ingestService = new IngestService(clusterService.getClusterSettings(), settings, threadPool, this.environment,scriptModule.getScriptService(), analysisModule.getAnalysisRegistry(), pluginsService.filterPlugins(IngestPlugin.class));final ClusterInfoService clusterInfoService = newClusterInfoService(settings, clusterService, threadPool, client);Step 6、创建ModulesBuilder并加入各种Module。
ES使用google开源的
Guice管理程序中的依赖。加入ModulesBuilder中的Module有:通过PluginsService获取的插件提供的Module;NodeModule内部持有MonitorService;ClusterModule内部持有ClusterService及相关的ClusterPlugin;IndicesModule内部持有MapperPlugin;SearchModule内部持有相关的SearchPlugin;ActionModule内部持有ThreadPool、ActionPlugin、NodeClient及CircuitBreakerService;GatewayModule;RepositoriesModule内部持有RepositoryPlugin;SttingsModule内部ES可用的各类配置对象等;最好调用modules的createInjector方法创建应用的“依赖注入器”。
Step 7、收集各plugin的LifecycleComponent对象,并出初始化NodeClient。
代码如下:
List<LifecycleComponent> pluginLifecycleComponents = pluginComponents.stream().filter(p -> p instanceof LifecycleComponent).map(p -> (LifecycleComponent) p).collect(Collectors.toList());pluginLifecycleComponents.addAll(pluginsService.getGuiceServiceClasses().stream().map(injector::getInstance).collect(Collectors.toList()));resourcesToClose.addAll(pluginLifecycleComponents);this.pluginLifecycleComponents = Collections.unmodifiableList(pluginLifecycleComponents);client.initialize(injector.getInstance(new Key<Map<GenericAction, TransportAction>>() {}),() -> clusterService.localNode().getId());if (NetworkModule.HTTP_ENABLED.get(settings)) {logger.debug("initializing HTTP handlers ...");actionModule.initRestHandlers(() -> clusterService.state().nodes());}logger.info("initialized");Step 8、调用Node的Start方法,在该方法内依次调用各重要模块的start方法。
依次启动各个关键服务。代码如下:
// hack around dependency injection problem (for now...)injector.getInstance(Discovery.class).setAllocationService(injector.getInstance(AllocationService.class));pluginLifecycleComponents.forEach(LifecycleComponent::start);injector.getInstance(MappingUpdatedAction.class).setClient(client);injector.getInstance(IndicesService.class).start();injector.getInstance(IndicesClusterStateService.class).start();injector.getInstance(IndicesTTLService.class).start();injector.getInstance(SnapshotsService.class).start();injector.getInstance(SnapshotShardsService.class).start();injector.getInstance(RoutingService.class).start();injector.getInstance(SearchService.class).start();injector.getInstance(MonitorService.class).start();final ClusterService clusterService = injector.getInstance(ClusterService.class);final NodeConnectionsService nodeConnectionsService = injector.getInstance(NodeConnectionsService.class);nodeConnectionsService.start();clusterService.setNodeConnectionsService(nodeConnectionsService);// TODO hack around circular dependencies problemsinjector.getInstance(GatewayAllocator.class).setReallocation(clusterService, injector.getInstance(RoutingService.class));injector.getInstance(ResourceWatcherService.class).start();injector.getInstance(GatewayService.class).start();Discovery discovery = injector.getInstance(Discovery.class);clusterService.setDiscoverySettings(discovery.getDiscoverySettings());clusterService.addInitialStateBlock(discovery.getDiscoverySettings().getNoMasterBlock());clusterService.setClusterStatePublisher(discovery::publish);// start before the cluster service since it adds/removes initial Cluster state blocksfinal TribeService tribeService = injector.getInstance(TribeService.class);tribeService.start();// Start the transport service now so the publish address will be added to the local disco node in ClusterServiceTransportService transportService = injector.getInstance(TransportService.class);transportService.getTaskManager().setTaskResultsService(injector.getInstance(TaskResultsService.class));transportService.start();validateNodeBeforeAcceptingRequests(settings, transportService.boundAddress(), pluginsService.filterPlugins(Plugin.class).stream().flatMap(p -> p.getBootstrapChecks().stream()).collect(Collectors.toList()));clusterService.addStateApplier(transportService.getTaskManager());clusterService.start();assert localNodeFactory.getNode() != null;assert transportService.getLocalNode().equals(localNodeFactory.getNode()): "transportService has a different local node than the factory provided";assert clusterService.localNode().equals(localNodeFactory.getNode()): "clusterService has a different local node than the factory provided";// start after cluster service so the local disco is knowndiscovery.start();transportService.acceptIncomingRequests();discovery.startInitialJoin();// tribe nodes don't have a master so we shouldn't register an observer sfinal TimeValue initialStateTimeout = DiscoverySettings.INITIAL_STATE_TIMEOUT_SETTING.get(settings);if (initialStateTimeout.millis() > 0) {final ThreadPool thread = injector.getInstance(ThreadPool.class);ClusterState clusterState = clusterService.state();ClusterStateObserver observer = new ClusterStateObserver(clusterState, clusterService, null, logger, thread.getThreadContext());if (clusterState.nodes().getMasterNodeId() == null) {logger.debug("waiting to join the cluster. timeout [{}]", initialStateTimeout);final CountDownLatch latch = new CountDownLatch(1);observer.waitForNextChange(new ClusterStateObserver.Listener() {@Overridepublic void onNewClusterState(ClusterState state) { latch.countDown(); }@Overridepublic void onClusterServiceClose() {latch.countDown();}@Overridepublic void onTimeout(TimeValue timeout) {logger.warn("timed out while waiting for initial discovery state - timeout: {}",initialStateTimeout);latch.countDown();}}, state -> state.nodes().getMasterNodeId() != null, initialStateTimeout);try {latch.await();} catch (InterruptedException e) {throw new ElasticsearchTimeoutException("Interrupted while waiting for initial discovery state");}}}if (NetworkModule.HTTP_ENABLED.get(settings)) {injector.getInstance(HttpServerTransport.class).start();}if (WRITE_PORTS_FILE_SETTING.get(settings)) {if (NetworkModule.HTTP_ENABLED.get(settings)) {HttpServerTransport http = injector.getInstance(HttpServerTransport.class);writePortsFile("http", http.boundAddress());}TransportService transport = injector.getInstance(TransportService.class);writePortsFile("transport", transport.boundAddress());}// start nodes now, after the http server, because it may take some timetribeService.startNodes();logger.info("started");相关文章:

C++中的封装、继承、多态
封装(encapsulation):就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成”类”,其中数据和函数都是类的成员。封装的目的是增强安全性和简化编程&…

比尔盖茨护犊子 称iPad让大批用户沮丧
为什么80%的码农都做不了架构师?>>> 在5月6日接受美国CNBC电视台访问时,微软前任掌门人比尔盖茨维护了自家反响不那么好的Surface系列平板电脑,同时他还不忘吐槽了一把iPad。 当 谈到日渐颓败的PC市场时,盖茨称平板电…
小心陷阱:二维动态内存的不连续性
void new_test() {int** pp;pp new int*[10];for(int i0; i<10; i){pp[i] new int[10];}//pp[0], pp[1], ... , pp[9]在内存中连续;//a1 pp[0][0], pp[0][1], ... , pp[0][9]在内存中也是连续的;//a2 pp[1][0], pp[1][1], ... , pp[1][9]在内存中也是连续的;//...//a9 …

超酷炫!Facebook用深度学习和弱监督学习绘制全球精准道路图
作者 | Saikat Basu等译者 | 陆离责编 | 夕颜出品 | AI科技大本营(ID: rgznai100)导读:现如今,即使可以借助卫星图像和绘制软件,创建精确的道路图也依然是一个费时费力的人力加工过程。许多地区,特别是在发…

npm包发布记录
下雪了,在家闲着,不如写一个npm 包发布。简单的 npm 包的发布网上有很多教程,我就不记录了。这里记录下,一个复杂的 npm 包发布,复杂指的构建环境复杂。 整个工程使用 rollup 来构建,其中会引进 babel 来转…

设计模式之单例模式(Singleton)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式)࿱…
关于知识蒸馏,这三篇论文详解不可错过
作者 | 孟让转载自知乎导语:继《从Hinton开山之作开始,谈知识蒸馏的最新进展》之后,作者对知识蒸馏相关重要进行了更加全面的总结。在上一篇文章中主要介绍了attention transfer,FSP matrix和DarkRank,关注点在于寻找不…
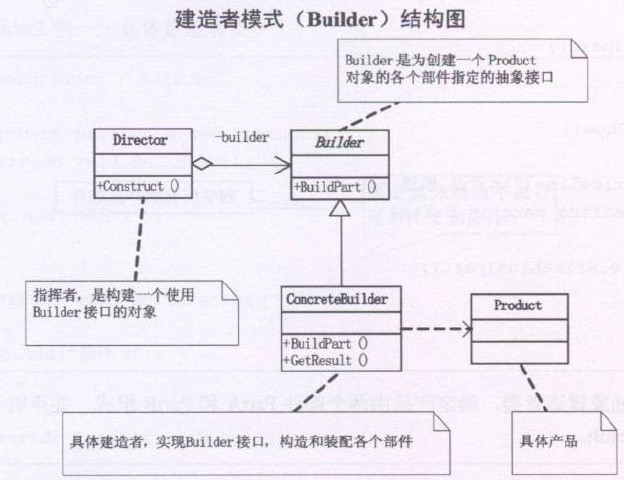
设计模式之建造者模式(生成器模式、Builder)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…

[置顶] webservice系列2---javabeanhandler
摘要:本节主要介绍以下两点,1.带javabean的webservice的开发和调用 2.handler的简单介绍及使用1.引言在之前的一篇博客webservice系列1---基于web工程上写一个基本数据类型的webservice中介绍了如何采用axis1.4来完成一个简单的webservice的开发流程(入参…
AI教育公司物灵科技完成战略融资,商汤科技投资
1月2日消息,从相关媒体报道,AI教育公司物灵科技近日完成了商汤的战略融资,本轮融资将用于产品迭代和扩大市场。 此前投资界曾报道,物灵科技已经获得1.5亿元Pre-A轮融资,当时具体资方未透露。 公开资料显示࿰…

Python之父发文,将重构现有核心解析器
原题 | PEG Parsers作者 | Guido van Rossum译者 | 豌豆花下猫转载自 Python猫(ID: python_cat) 导语:Guido van Rossum 是 Python 的创造者,虽然他现在放弃了“终身仁慈独裁者”的职位,但却成为了指导委员会的五位成员…
全面支持三大主流环境 |百度PaddlePaddle新增Windows环境支持
2019独角兽企业重金招聘Python工程师标准>>> PaddlePaddle作为国内首个深度学习框架,最近发布了更加强大的Fluid1.2版本, 增加了对windows环境的支持,全面支持了Linux、Mac、 windows三大环境。 PaddlePaddle在功能完备的基础上,也…
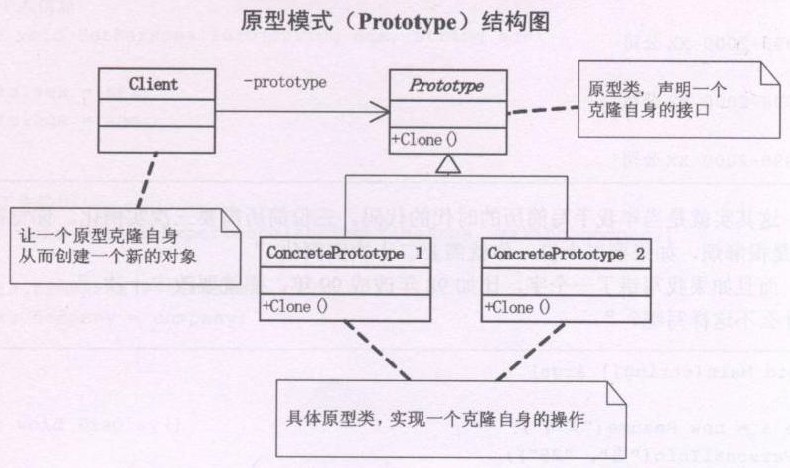
设计模式之原型模式(Prototype)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
NFS共享服务挂载时出现“access denied by server while mounting”的解决方法
笔者用的Linuxf发行版本为Centos6.4,以下方法理论上讲对于Fedora, Red Hat均有效: 搭建好NFS服务后,如果用以下的命令进行挂载: # mount -t nfs 172.16.12.140:/home/liangwode/test /mnt 出现如下错误提示: mount.nf…
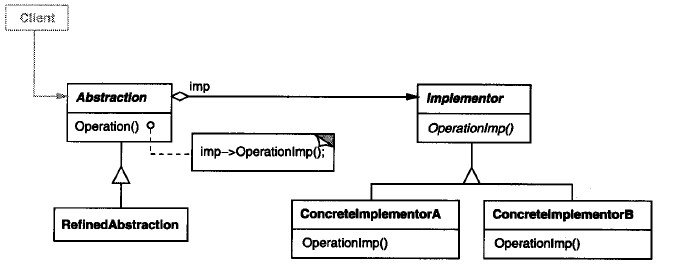
设计模式之桥接模式(Bridge)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
原360首席科学家颜水成正式加入依图科技,任首席技术官
7 月 29 日,依图科技宣布原 360 首席科学家颜水成正式加入,担任依图科技首席技术官(CTO)一职。依图方面称,颜水成加入后将带领团队进一步夯实依图在人工智能基础理论和原创算法方面的技术优势,为依图在商业…
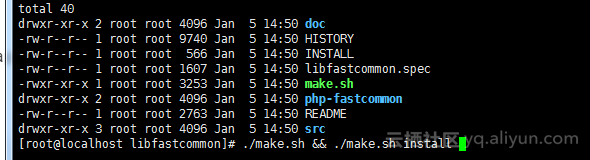
分布式存储fastdfs安装使用
1.下载地址https://github.com/happyfish100/fastdfshttps://github.com/happyfish100/fastdfs/wiki安装辅助说明文档2.安装编译环境yum install git gcc gcc-c make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel wget vim -y三台主机:…

Hibernate学习(九)———— 二级缓存和事务级别详讲
序言 这算是hibernate的最后一篇文章了,下一系列会讲解Struts2的东西,然后说完Struts2,在到Spring,然后在写一个SSH如何整合的案例。之后就会在去讲SSM,在之后我自己的个人博客应该也差不多可以做出来了。基本上先这样…

超详细中文预训练模型ERNIE使用指南
作者 | 高开远,上海交通大学,自然语言处理研究方向最近在工作上处理的都是中文语料,也尝试了一些最近放出来的预训练模型(ERNIE,BERT-CHINESE,WWM-BERT-CHINESE),比对之后还是觉得百…
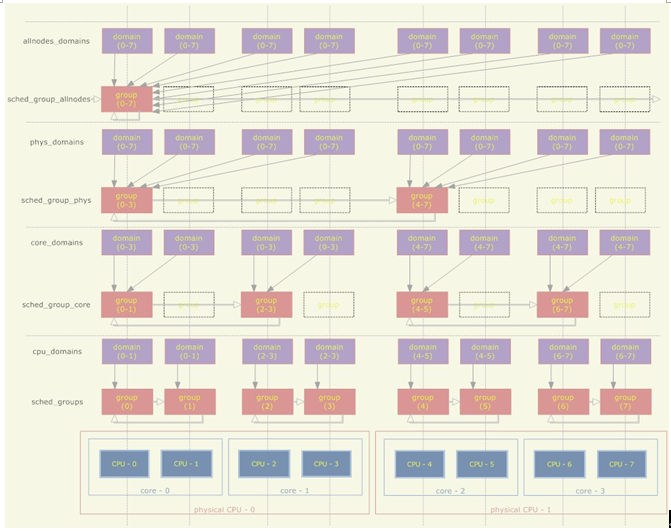
linux内核SMP负载均衡浅析
需求 在《linux进程调度浅析》一文中提到,在SMP(对称多处理器)环境下,每个CPU对应一个run_queue(可执行队列)。如果一个进程处于TASK_RUNNING状态(可执行状态),则它…
结构体中最后一个成员为[0]或[1]长度数组(柔性数组成员)的用法
结构体中最后一个成员为[0]长度数组的用法:这是个广泛使用的常见技巧,常用来构成缓冲区。比起指针,用空数组有这样的优势:(1)、不需要初始化,数组名直接就是所在的偏移;(2)、不占任何空间,指针需…
超全!深度学习在计算机视觉领域的应用一览
作者 | 黄浴,奇点汽车美研中心首席科学家兼总裁转载自知乎简单回顾的话,2006年Geoffrey Hinton的论文点燃了“这把火”,现在已经有不少人开始泼“冷水”了,主要是AI泡沫太大,而且深度学习不是包治百病的药方。计算机视…

SHAREPOINT2010数据库升级2013
在作TEST-SPCONTENT命令时,会提示认证方式不一样。 The [SharePoint - 80] web application is configured with claims authentication mode however the content database you are trying to attach is intended to be used against a windows classic authentic…
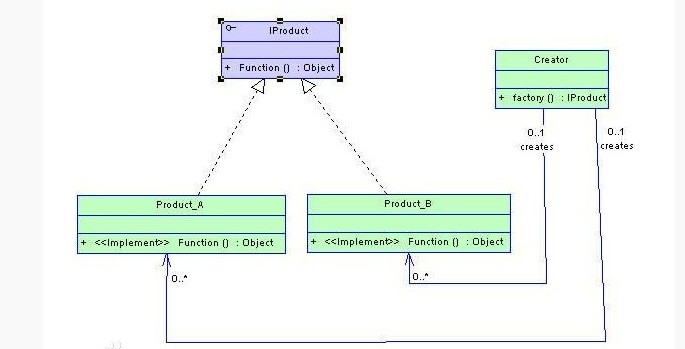
设计模式之简单工厂模式(Simply Factory)摘录
从设计模式的类型上来说,简单工厂模式是属于创建型模式,又叫静态工厂方法(Static Factory Method)模式,但不属于23种GOF设计模式之一。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的…
别得意,你只是假装收藏了而已
今天分享我在看罗振宇的《2018 时间的朋友》演讲视频记下的一些思考。跨年演讲中有过这样的一个来自印象笔记的片段,列举了几组对比来说明: 『你在朋友圈里又佛又丧,你在收藏夹里偷偷地积极向上。』 扎心了,这不就是说我吗&#x…

Exchange2003-2010迁移系列之四,配置第一台Exchange CAS/HUB服务器
配置第一台CAS/HUB关于Cas/hub的配置请大家详见前面关于Ex2010的部署(两个配置基本相同在这里就不做详细的解说了)下面关于Cas的配置在前面已经提到了但是下面是另一种新的方法大家就看看吧生产环境中部署Exchange2010服务器时,是需要按照一定…
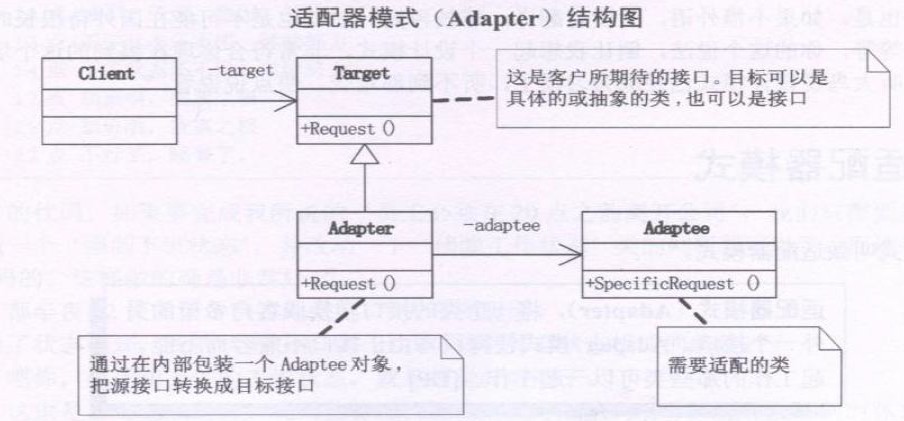
设计模式之适配器模式(Adapter)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…
JAVA方法中的参数用final来修饰的效果
很多人都说在JAVA中用final来修饰方法参数的原因是防止方法参数在调用时被篡改,其实也就是这个原因,但理解起来可能会有歧义,我们需要注意的是,在final修饰的方法参数中,如果修饰的是基本类型,那么在这个方…

2019世界机器人大赛圆满落幕,荆州中学等15支队伍获「全能奖」
7月28日,2019世界机器人大赛总决赛在河北保定圆满落下帷幕。保定市市委常委罗德强、中国电子学会副秘书长梁靓、保定市政府秘书长王保辉、保定市政府副秘书长安利文、保定市徐水区区长李志永、保定市莲池区政府党组副书记赵建军、世界机器人大赛组委会秘书长李洋、长…

在任何设备上都完美呈现的30个华丽的响应式网站
如今,一个网站只在桌面屏幕上好看是远远不够的,同时也要在平板电脑和智能手机中能够良好呈现。响应式的网站是指它能够适应客户端的屏幕尺寸,自动响应客户端尺寸变化。在这篇文章中,我将向您展示在任何设备上都完美的30个华丽的响…