关于知识蒸馏,这三篇论文详解不可错过

作者 | 孟让
转载自知乎
导语:继《从Hinton开山之作开始,谈知识蒸馏的最新进展》之后,作者对知识蒸馏相关重要进行了更加全面的总结。在上一篇文章中主要介绍了attention transfer,FSP matrix和DarkRank,关注点在于寻找不同形式的“知识”。
本篇文章主要介绍17年图森发布的文章Neuron Selectivity Transfer,对Attention和Gram矩阵做出总结,使用CGANs来做KD的方法以及介绍KD用于非模型压缩目的互相学习(Mutual Learning)和再生网络(Born Again NN)。
papers :
Like What You Like: Knowledge Distill via Neuron Selectivity Transfer
https://arxiv.org/pdf/1707.01219.pdf
Training Shallow and Thin Networks for Acceleration via Knowledge Distillation with Conditional Adversarial Networks
https://arxiv.org/pdf/1709.00513.pdf
Deep Mutual Learning
https://arxiv.org/pdf/1706.00384.pdf
Born Again Neural Networks
https://arxiv.org/pdf/1805.04770.pdf
一. Neuron Selectivity Transfer

本文将teacher-student的knowledge transfer过程看作两者对应feature distribution matching,使用domian adaptation 常用方法MMD(最大平均差异)进行优化。(知识蒸馏本是一种同任务迁移学习)
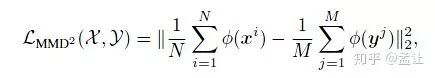
相关概念
I. Maximum Mean Discrepancy
简而言之,将两个分布映射到一个可度量距离的空间计算距离。计算距离的方法是,计算分布上每一个点映射到另一空间的距离然后求和。具体而言就是将两个分布映射到再生核希尔伯特空间(可以利用核技巧简化无穷维度内积计算),在这个RKHS中两个分布的距离用两个分布的核函数各点距离之和计算。
II. Kernel Trick 简而言之,存在低维到高维的映射;求解形式中只有映射的内积项,没有关于映射的奇数次项,所以可以使用Kernel Trick(以上只是充分条件)来简化高维映射的内积计算。使得高维变换+高维内积简化为低维内积计算。核技巧与MMD结合:
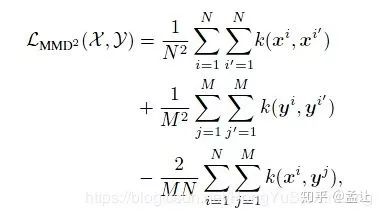
Motivations

按照深度学习分布式特征的特点,每个神经元按照任务从输入提取某(几)种特定的特征,这是神经元的选择性。反过来说如果一个神经元被某些样本或者图像某些区域激活(上图的猴脸和字符),那么这些区域/样本就是有共同语义特征的。所以本文的方法是使用MMD来使得student网络的神经元选择性特征分布(Neuron Selectivity Feature Distributions)mimic对应teacher的的这种分布。
下图是teacher-student框架:

方法
特征图的一个通道表示了一个神经元的选择性知识,神经元选择性传递(Neuron Selectivity Transfer)的损失函数是:
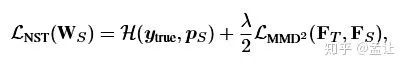
等号右边第一项是交叉熵,第二项是加入核技巧的平方最大平均差异损失,MMD LOSS如下:
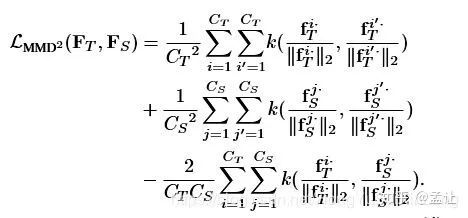
式中每个通道进行了L2正则化,之前研究表明是涨点很关键的一点。关于不同核函数的选取是重头戏了,因为之前的工作Attention Transfer的损失函数可以理解为一种带线性核函数的MMD。带某个多项式核函数的MMD是在传递Gram矩阵。
1.带线性核函数的MMD
线性核
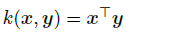
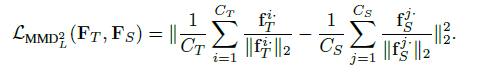
对比Attention Transfer loss:
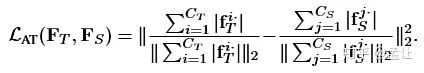
发现AT LOSS除了在正则化方式上的差别以外,是一种NTS的特例。
2.带多项式核的MMD
多项式核
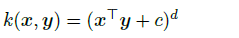
在d=2,c=0的时候有:
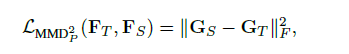
其中G为Gram矩阵,各元素为
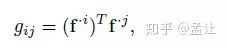
该gram矩阵表示嵌入空间的空间相似度(前提是需要通道正则化)。
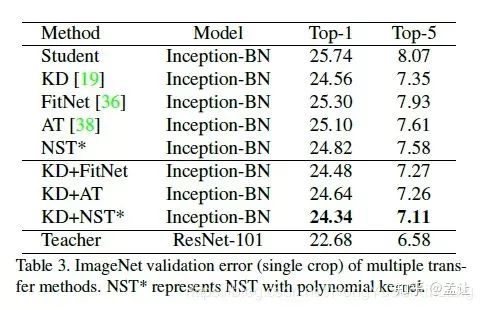
实验
teacher:ResNet1001
student:Inception-BN
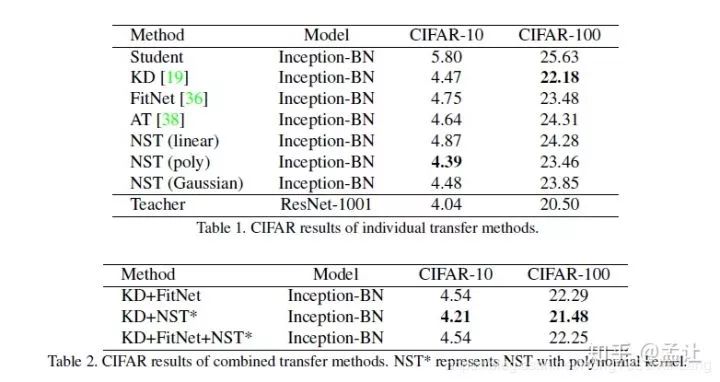
不同核函数的NTS以及不同知识蒸馏方法对比如下:
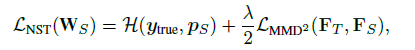
二. Knowledge Distillation with Conditional Adversarial Networks

对于一般KD的teacher-student框架来讲,除了需要有一个pre-trained的student网络以及一个suboptimal的student网络之外,技术的关键还在于需要传递的知识形式以及传递所需的衡量标准--KD损失函数。最原始的KD损失是soft label的KL散度,之后大多数是抽取中间层特征以某种形式进行传递。损失函数对于深度学习的重要性不言而喻。自然而言就想到了很厉害的一种可学习损失函数——GAN。 teacher-student框架,是studen对teacher的模仿的过程。那么,即使任务是分类,判别任务,也可以将student网络看作一个生成器,产生对于输入的logits。这个logits 使用soft label的方法来模仿student。这时候加入一个判别器,作用是甄别logits出自teacher还是student。这种生成-对抗的推拉之下,使得student很好的学到了来自teacher的知识,完成知识蒸馏。
方法
1. 一般的知识蒸馏
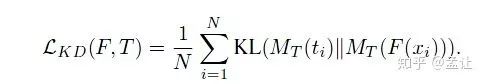
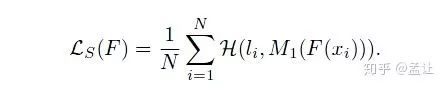
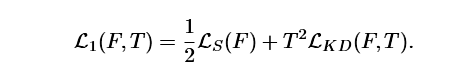
F( )是student,t是teacher,MT是soft label方法。
2. CGAN teacher-student整体框架
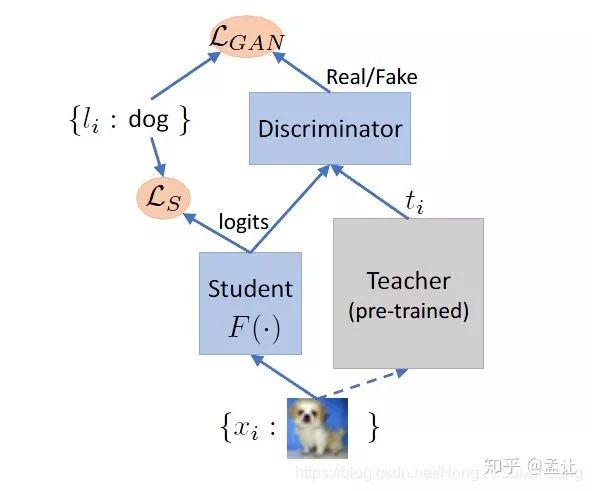
3. Discriminator
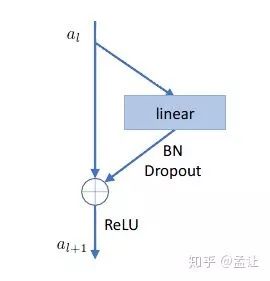
使用残差结构的MLP作为Discriminator,训练Disc的损失函数是二值交叉熵
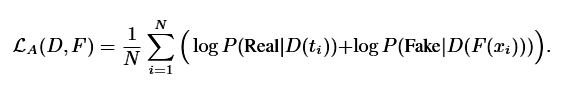
当然也可以使用宣称收敛最易的LSGAN:
disc_loss = (tf.reduce_mean((disc_t - 1)**2) + tf.reduce_mean((disc_s - 0)**2))/2.
gen_loss = tf.reduce_mean((disc_s - 1)**2)但是不好意思,训练依然比较难。
按照Auxiliary Classifier GANs的思路,在判别器中也施加类别信息作条件,判别器的输出是一个C+2维的向量。C是类别数目。
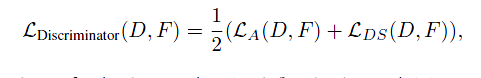
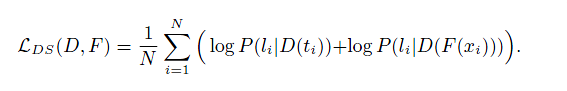
然后假设:类别条件和logits出自teacher or student是独立的,训练得出C+2维度的概率输出。
4. Generator
Auxiliary Classifier提供了类别信息,为了获得实例级别的知识作条件,使用L1loss来对其teacher-student的logits.所以总loss:
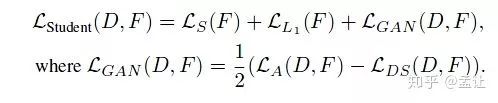
5. 训练过程
先固定student,用Discriminator Loss优化D;然后用Student Loss来优化Student。
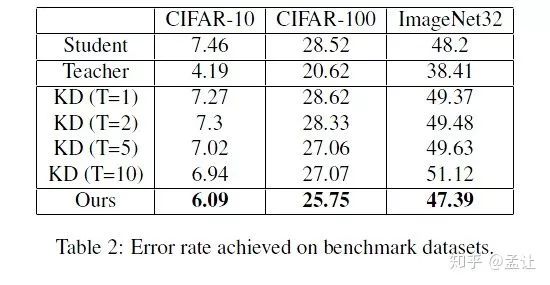
实验
teacher:WRN-40-10
student: WRN-10-4(CIFAR)/WRN-22-4(Imagenet32)
三. Mutual Learning & Born Again NN
两篇不以模型压缩为目的应用知识蒸馏的文章

Deep Mutual Learning VS Knowledge Distillation
Deep Mutual Learning(DML)与用于模型压缩的一般知识蒸馏不同的地方在于知识蒸馏是将预训练好的、不进行反向传播的“静态”teacher网络的知识单项传递给需要反向传播的"动态"student网络。DML是在训练过程中,一众需要反向传播的待训student网络协同学习,互相传递知识。所以区别就在是否teacher、student网络都需要反向传播。
方法
DML框架如下
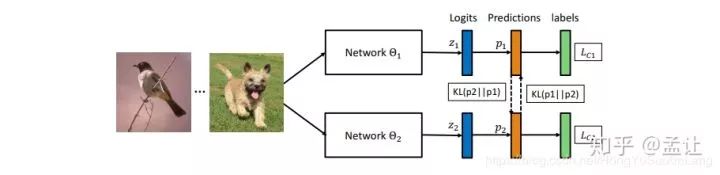
每个互相学习的网络都有一个标准的分类Loss和互学习Loss,其中互学习Loss是一个KL散度。具体而言,两个网络的softmax输出为p1,p2.则互学习的意义在于,对于Net1(Net2亦然),对了提高其泛化能力,使用Net2的p2作为一种后验概率,然后最小化p1,p2的KL散度。从p1到p2的KL距离如下
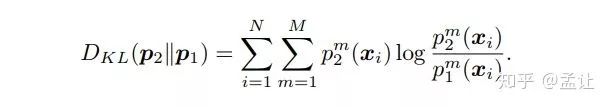
所以,Net1的损失函数是交叉熵加上p1到p2的KL散度:
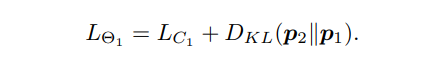
Net2的是p2到p1的距离:
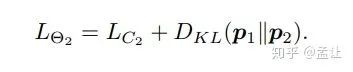
如果是多个网络,比如K>2个网络互相学习,则每个student网络的Loss:
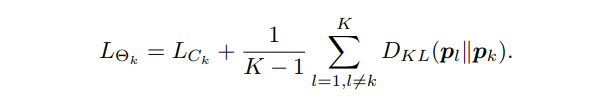
还有一种方法就是对于每个student,使其模仿其他student网络softmax输出之平均。不过该方法会因为多个网络softmaxgailv取平均导致gt class分量很大,不够soft,有违文章提到的提供后验熵的初衷。
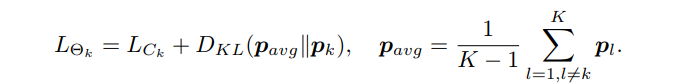
文章给出的优化过程是异步的。即先对不同网络进行不同的初始化,然后各网络同时前传得到softmax概率,继而每个网络在分类+互学习loss作用下逐个反传。
实验
实验所有模型如下:

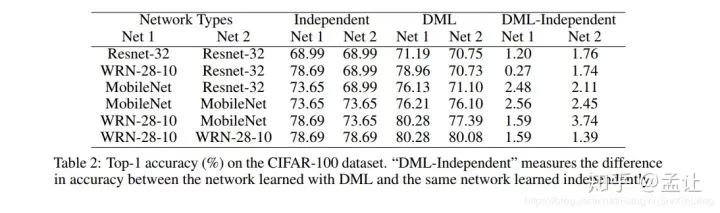
在CIFAR100数据集结果
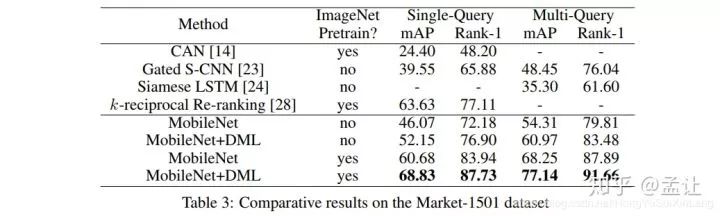
在Market-1501 Re-id结果
和单向传递知识的知识蒸馏相比
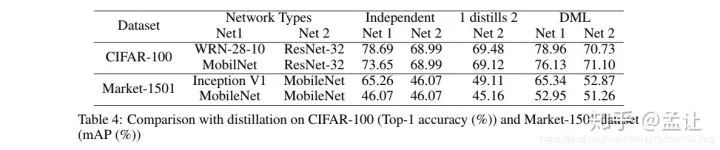
最后实验还发现互相学习的网络多一些可以涨点
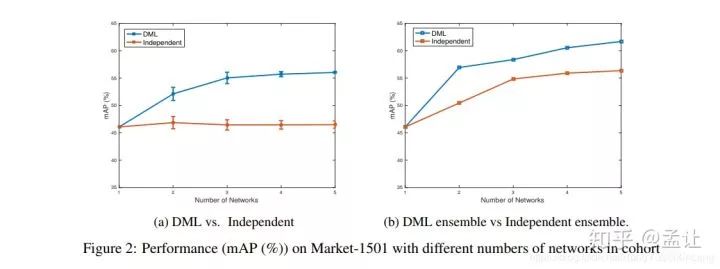
理论解释
每个网络都有交叉熵在训练,接受one-hot类别监督信息从而收敛到最小值点minina(训练损失为0)。但是各网络这种情况下的minima是不够稳定的。由于每个student网络初始化不一样,预测的类别向量第一分量是标准答案了,但是第二分量各不相同,还是和蒸馏一样,这种第二分量作为后验熵互相提供了丰富的信息,使得网络找到了较为宽广的、就是很鲁棒的最小值点,结果就是泛化能力提升。
再生网络

方法
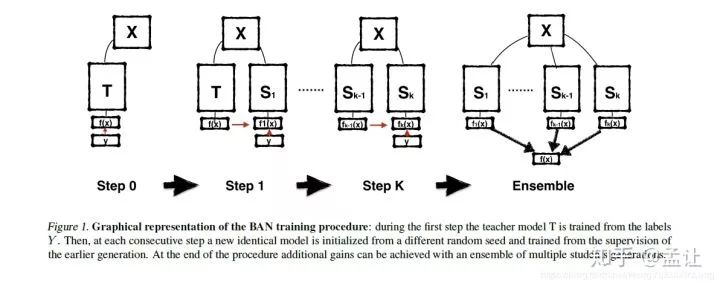
如上图,直接将teacher网络的prediction当作student网络的target,得到第一代student网络的prediction,然后传递给后一代,历经几代之后,将各代student网络的prediction ensemble.形成一个sequence of teaching selves。对于分类任务,X是输入,Y是输出的predictions,我们的网咯就是在拟合这样一个映射f(x):X->Y。学习参数的过程就是使用比如SGD来优化一个损失函数,通常是交叉熵。
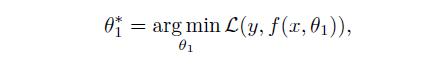
BANs就是替换这个交叉熵为:
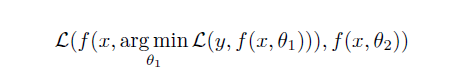
文章中还讨论了logits中非最大值分量的作用,使用teacher网络logit加权和非最大值分量打乱两种方法做了实验。
原文链接:https://zhuanlan.zhihu.com/p/53864403
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆

“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。大会早鸟票倒计时最后一天,速抢进行中......
推荐阅读
数十篇推荐系统论文被批无法复现:源码、数据集均缺失,性能难达预期
SpanBERT:提出基于分词的预训练模型,多项任务性能超越现有模型!
百度、快手、商汤、旷视、图森等重磅嘉宾确认出席AI ProCon 2019
抢程序员饭碗?自动写代码的Deep TabNine真如此神奇?
华为收入超过阿里腾讯总和!等等,先把鸿蒙说清楚!
扎克伯格再谈Libra:为十亿人打造“金融梦”(全文)
漫画 | Kubernetes带你一帆风顺去远航
“对不起,我就是传说中的 10 倍工程师”
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:
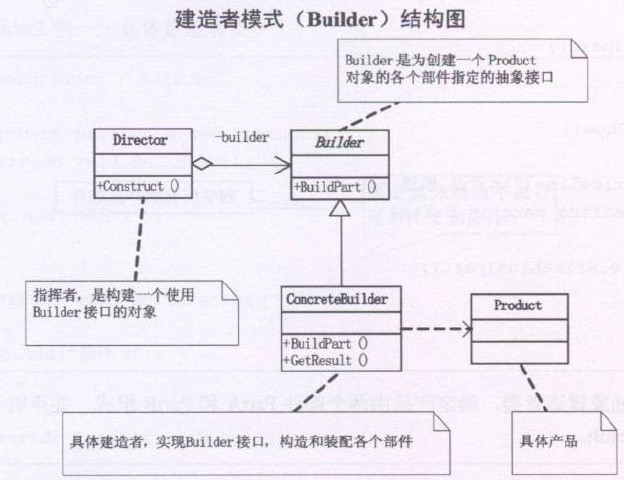
设计模式之建造者模式(生成器模式、Builder)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…

[置顶] webservice系列2---javabeanhandler
摘要:本节主要介绍以下两点,1.带javabean的webservice的开发和调用 2.handler的简单介绍及使用1.引言在之前的一篇博客webservice系列1---基于web工程上写一个基本数据类型的webservice中介绍了如何采用axis1.4来完成一个简单的webservice的开发流程(入参…

AI教育公司物灵科技完成战略融资,商汤科技投资
1月2日消息,从相关媒体报道,AI教育公司物灵科技近日完成了商汤的战略融资,本轮融资将用于产品迭代和扩大市场。 此前投资界曾报道,物灵科技已经获得1.5亿元Pre-A轮融资,当时具体资方未透露。 公开资料显示࿰…

Python之父发文,将重构现有核心解析器
原题 | PEG Parsers作者 | Guido van Rossum译者 | 豌豆花下猫转载自 Python猫(ID: python_cat) 导语:Guido van Rossum 是 Python 的创造者,虽然他现在放弃了“终身仁慈独裁者”的职位,但却成为了指导委员会的五位成员…

全面支持三大主流环境 |百度PaddlePaddle新增Windows环境支持
2019独角兽企业重金招聘Python工程师标准>>> PaddlePaddle作为国内首个深度学习框架,最近发布了更加强大的Fluid1.2版本, 增加了对windows环境的支持,全面支持了Linux、Mac、 windows三大环境。 PaddlePaddle在功能完备的基础上,也…
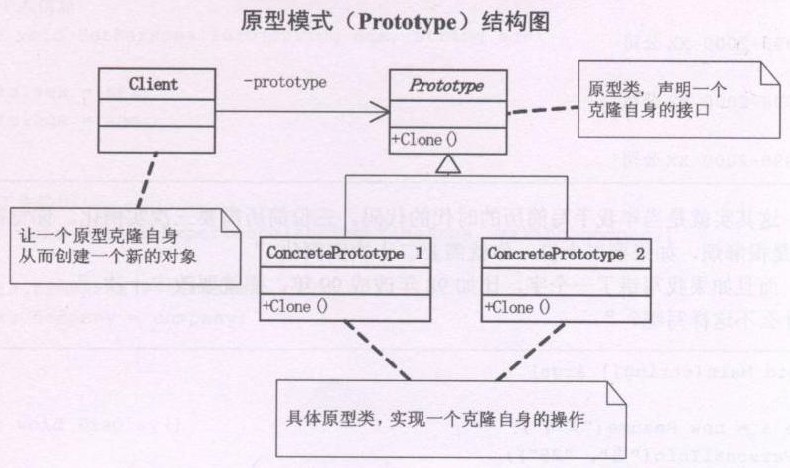
设计模式之原型模式(Prototype)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
NFS共享服务挂载时出现“access denied by server while mounting”的解决方法
笔者用的Linuxf发行版本为Centos6.4,以下方法理论上讲对于Fedora, Red Hat均有效: 搭建好NFS服务后,如果用以下的命令进行挂载: # mount -t nfs 172.16.12.140:/home/liangwode/test /mnt 出现如下错误提示: mount.nf…
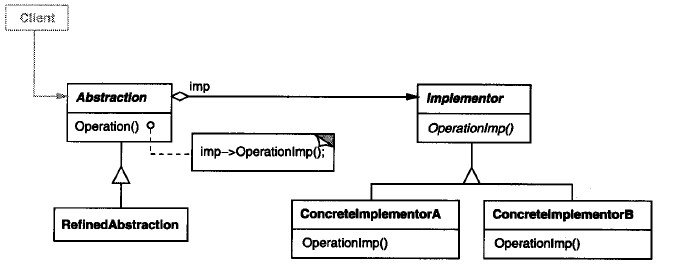
设计模式之桥接模式(Bridge)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式包括:1、FactoryMethod(工厂方法模式);2、Abstract Factory(抽象工厂模式);3、Singleton(单例模式);4、Builder(建造者模式、生成器模式…
原360首席科学家颜水成正式加入依图科技,任首席技术官
7 月 29 日,依图科技宣布原 360 首席科学家颜水成正式加入,担任依图科技首席技术官(CTO)一职。依图方面称,颜水成加入后将带领团队进一步夯实依图在人工智能基础理论和原创算法方面的技术优势,为依图在商业…
分布式存储fastdfs安装使用
1.下载地址https://github.com/happyfish100/fastdfshttps://github.com/happyfish100/fastdfs/wiki安装辅助说明文档2.安装编译环境yum install git gcc gcc-c make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel wget vim -y三台主机:…

Hibernate学习(九)———— 二级缓存和事务级别详讲
序言 这算是hibernate的最后一篇文章了,下一系列会讲解Struts2的东西,然后说完Struts2,在到Spring,然后在写一个SSH如何整合的案例。之后就会在去讲SSM,在之后我自己的个人博客应该也差不多可以做出来了。基本上先这样…

超详细中文预训练模型ERNIE使用指南
作者 | 高开远,上海交通大学,自然语言处理研究方向最近在工作上处理的都是中文语料,也尝试了一些最近放出来的预训练模型(ERNIE,BERT-CHINESE,WWM-BERT-CHINESE),比对之后还是觉得百…
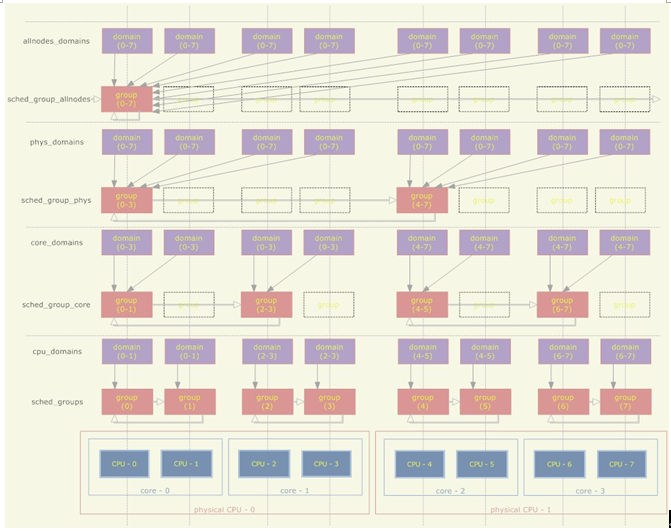
linux内核SMP负载均衡浅析
需求 在《linux进程调度浅析》一文中提到,在SMP(对称多处理器)环境下,每个CPU对应一个run_queue(可执行队列)。如果一个进程处于TASK_RUNNING状态(可执行状态),则它…
结构体中最后一个成员为[0]或[1]长度数组(柔性数组成员)的用法
结构体中最后一个成员为[0]长度数组的用法:这是个广泛使用的常见技巧,常用来构成缓冲区。比起指针,用空数组有这样的优势:(1)、不需要初始化,数组名直接就是所在的偏移;(2)、不占任何空间,指针需…
超全!深度学习在计算机视觉领域的应用一览
作者 | 黄浴,奇点汽车美研中心首席科学家兼总裁转载自知乎简单回顾的话,2006年Geoffrey Hinton的论文点燃了“这把火”,现在已经有不少人开始泼“冷水”了,主要是AI泡沫太大,而且深度学习不是包治百病的药方。计算机视…

SHAREPOINT2010数据库升级2013
在作TEST-SPCONTENT命令时,会提示认证方式不一样。 The [SharePoint - 80] web application is configured with claims authentication mode however the content database you are trying to attach is intended to be used against a windows classic authentic…
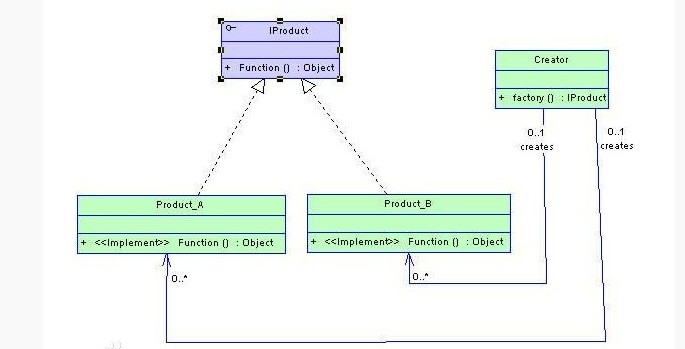
设计模式之简单工厂模式(Simply Factory)摘录
从设计模式的类型上来说,简单工厂模式是属于创建型模式,又叫静态工厂方法(Static Factory Method)模式,但不属于23种GOF设计模式之一。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的…
别得意,你只是假装收藏了而已
今天分享我在看罗振宇的《2018 时间的朋友》演讲视频记下的一些思考。跨年演讲中有过这样的一个来自印象笔记的片段,列举了几组对比来说明: 『你在朋友圈里又佛又丧,你在收藏夹里偷偷地积极向上。』 扎心了,这不就是说我吗&#x…

Exchange2003-2010迁移系列之四,配置第一台Exchange CAS/HUB服务器
配置第一台CAS/HUB关于Cas/hub的配置请大家详见前面关于Ex2010的部署(两个配置基本相同在这里就不做详细的解说了)下面关于Cas的配置在前面已经提到了但是下面是另一种新的方法大家就看看吧生产环境中部署Exchange2010服务器时,是需要按照一定…
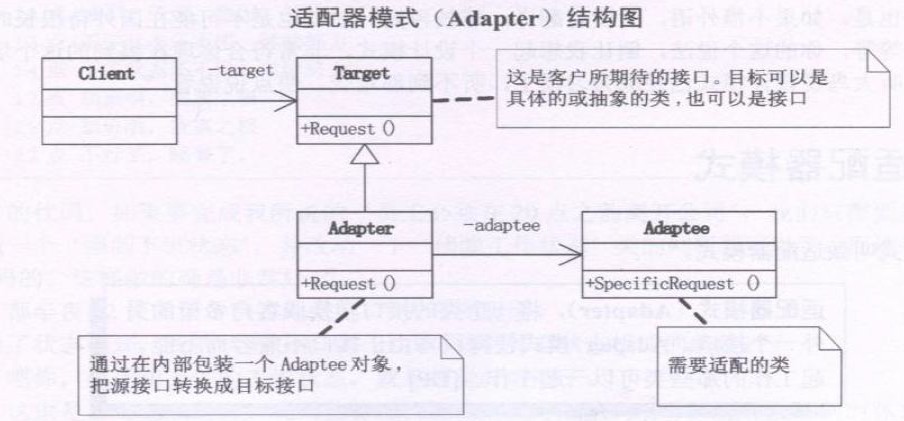
设计模式之适配器模式(Adapter)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…
JAVA方法中的参数用final来修饰的效果
很多人都说在JAVA中用final来修饰方法参数的原因是防止方法参数在调用时被篡改,其实也就是这个原因,但理解起来可能会有歧义,我们需要注意的是,在final修饰的方法参数中,如果修饰的是基本类型,那么在这个方…

2019世界机器人大赛圆满落幕,荆州中学等15支队伍获「全能奖」
7月28日,2019世界机器人大赛总决赛在河北保定圆满落下帷幕。保定市市委常委罗德强、中国电子学会副秘书长梁靓、保定市政府秘书长王保辉、保定市政府副秘书长安利文、保定市徐水区区长李志永、保定市莲池区政府党组副书记赵建军、世界机器人大赛组委会秘书长李洋、长…

在任何设备上都完美呈现的30个华丽的响应式网站
如今,一个网站只在桌面屏幕上好看是远远不够的,同时也要在平板电脑和智能手机中能够良好呈现。响应式的网站是指它能够适应客户端的屏幕尺寸,自动响应客户端尺寸变化。在这篇文章中,我将向您展示在任何设备上都完美的30个华丽的响…
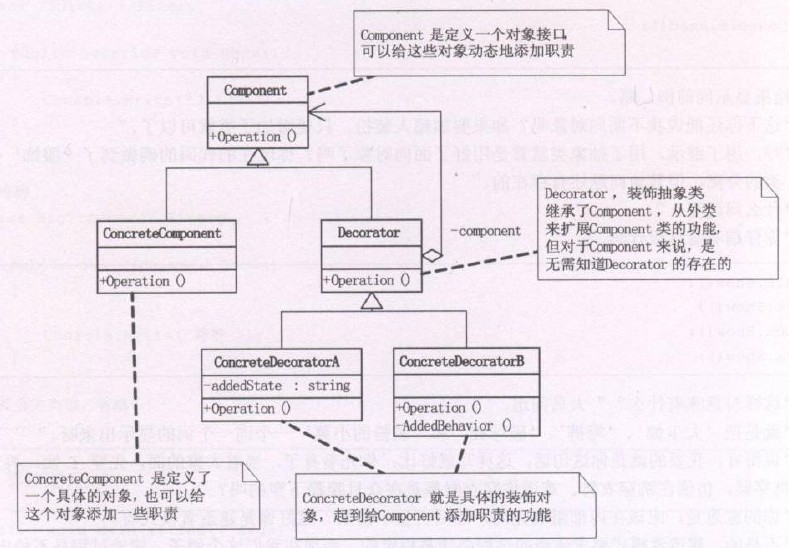
设计模式之装饰模式(Decorator)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…

解决流程自动化“最后一公里问题”,达观数据发布智能 RPA
2019 年7月 26 日,业界领先的人工智能企业达观数据在北京召开“达道至简”为主题的产品发布会,正式推出国内首款自主研发集OCR(光学字符识别)与 NLP(自然语言处理)于一体的达观智能RPA。达观数据创始人兼CEO陈运文、副总裁金克、贾学锋和联合创始人高翔携…
利用脚本生成GUID
实际上,可以使用一种非常简单的方法来生成 GUID,但这种方法近乎像是作弊。(您可听清楚了,我们说的可是“近乎”。)“Scriptlet.TypeLib”对象的设计用途是帮助您创建“Windows 脚本组件”(实质上࿰…
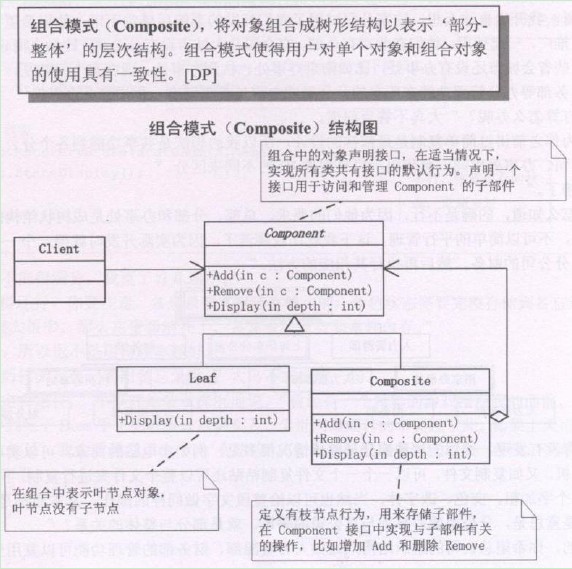
设计模式之组合模式(Composite)摘录
23种GOF设计模式一般分为三大类:创建型模式、结构型模式、行为模式。 创建型模式抽象了实例化过程,它们帮助一个系统独立于如何创建、组合和表示它的那些对象。一个类创建型模式使用继承改变被实例化的类,而一个对象创建型模式将实例化委托给…
快速开发生命周期支持工具
去年有幸研究公司管理产品的软件平台,当时考虑的产品是基于业务模型之上的一个系统平台,从建模到运行、部署、维护全生命周期管理.当时就提出两个希望先实践解决的就是可复用原型的设计和使用工作流和规则引擎的协作处理询标产品.前一阵子在公司研究成本产品的成本分析和算法,一…
华人学者解开计算机领域30年难题:布尔函数敏感度猜想
整理 | 郭芮来源 | CSDN(ID:CSDNnews)1992年,布尔函数敏感度猜想(Boolean Sensitivity)被提出,这成为了理论计算机科学近三十年来最重要、最令人困惑的开放性问题之一。而近日,来自E…
从1.5K到18K 一个程序员的5年成长之路(二)
这一切都来自于心态CSDN:从开始学习,到学有所成和找工作,再到工作中遇到各种困难,然后获得突破,在整个过程中,能总结下你心态都有哪些变化?是用运用什么方法或方式进行调整?雷果国&a…