NLP命名实体识别开源实战教程 | 深度应用

作者 | 小宋是呢
来源 | CSDN博客
近几年来,基于神经网络的深度学习方法在计算机视觉、语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展。在NLP的关键性基础任务—命名实体识别(Named Entity Recognition,NER)的研究中,深度学习也获得了不错的效果。
目录
1.概念讲解
1.1 NER 简介
1.2 深度学习方法在NER中的应用
2.编程实战
2.1 概述
2.2数据预处理
2.3 模型搭建
2.4 模型训练
2.5模型应用
3. 总结&待续
1.概念讲解
1.1 NER 简介
NER又称作专名识别,是自然语言处理中的一项基础任务,应用范围非常广泛。命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括人名、地名、组织机构名、日期时间、专有名词等。NER系统就是从非结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。

学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
实际应用中,NER模型通常只要识别出人名、地名、组织机构名、日期时间即可,一些系统还会给出专有名词结果(比如缩写、会议名、产品名等)。货币、百分比等数字类实体可通过正则搞定。另外,在一些应用场景下会给出特定领域内的实体,如书名、歌曲名、期刊名等。
NER是NLP中一项基础性关键任务。从自然语言处理的流程来看,NER可以看作词法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
NER当前并不算是一个大热的研究课题,因为学术界部分学者认为这是一个已经解决的问题。当然也有学者认为这个问题还没有得到很好地解决,原因主要有:命名实体识别只是在有限的文本类型(主要是新闻语料中)和实体类别(主要是人名、地名、组织机构名)中取得了不错的效果;与其他信息检索领域相比,实体命名评测预料较小,容易产生过拟合;命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要;通用的识别多种类型的命名实体的系统性能很差。
总结一下就是从语句中提取出关键名词
1.2 深度学习方法在NER中的应用
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。
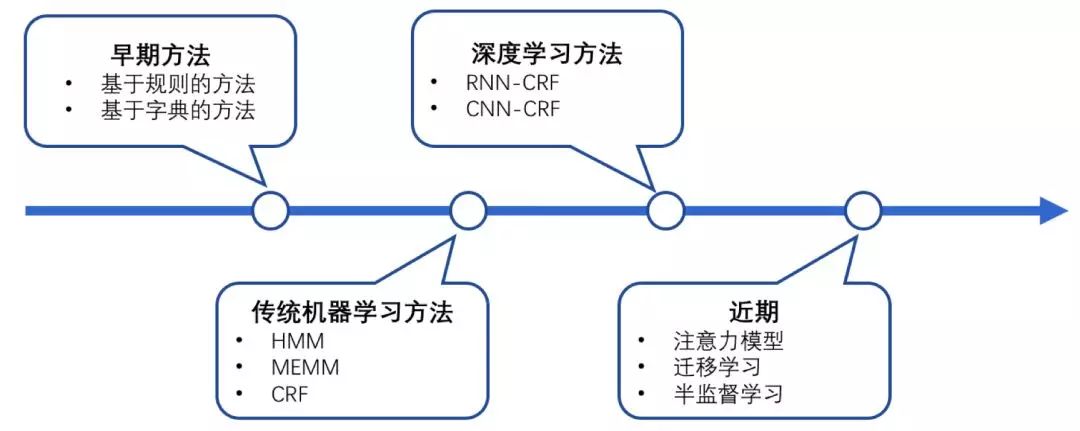 图1:NER发展趋势
图1:NER发展趋势
在基于机器学习的方法中,NER被当作序列标注问题。利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。NER 任务中的常用模型包括生成式模型HMM、判别式模型CRF等。条件随机场(ConditionalRandom Field,CRF)是NER目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用Viterbi算法解码来得到最优标签序列。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。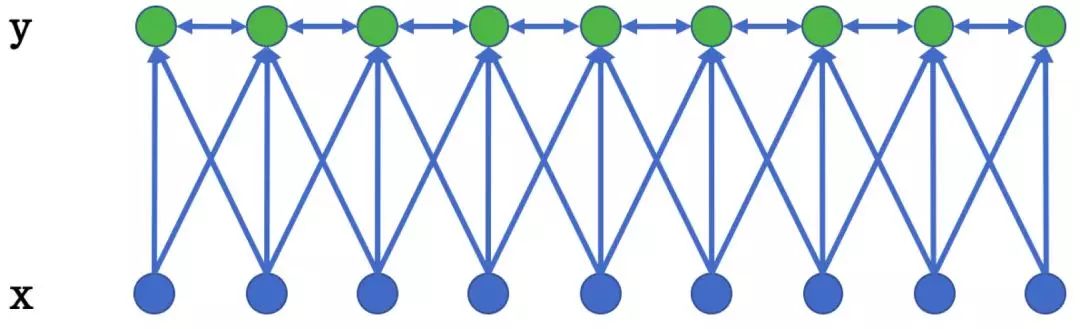 图2:一种线性链条件随机场
图2:一种线性链条件随机场
近年来,随着硬件计算能力的发展以及词的分布式表示(word embedding)的提出,神经网络可以有效处理许多NLP任务。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的:将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。
这种方法使得模型的训练成为一个端到端的过程,而非传统的pipeline,不依赖于特征工程,是一种数据驱动的方法,但网络种类繁多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程是独立的进行,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),进而导致预测出的标签序列可能是无效的,例如标签I-PER后面是不可能紧跟着B-PER的,但Softmax不会利用到这个信息。
学界提出了DL-CRF模型做序列标注。在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。
1.2.1 BiLSTM-CRF(RNN base)
LongShort Term Memory网络一般叫做LSTM,是RNN的一种特殊类型,可以学习长距离依赖信息。LSTM由Hochreiter &Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题上,LSTM 都取得了相当巨大的成功,并得到了广泛的使用。LSTM 通过巧妙的设计来解决长距离依赖问题。
所有 RNN 都具有一种重复神经网络单元的链式形式。在标准的RNN中,这个重复的单元只有一个非常简单的结构,例如一个tanh层。
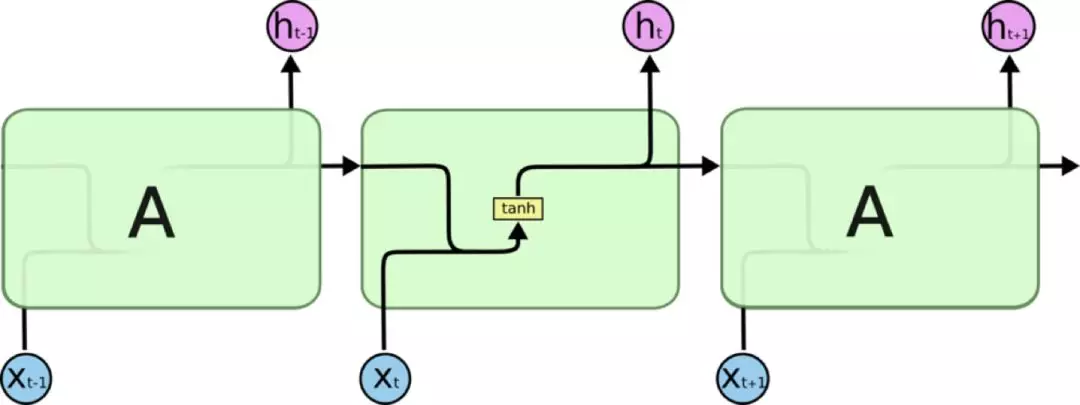 图3:传统RNN结构
图3:传统RNN结构
LSTM 同样是这样的结构,但是重复的单元拥有一个不同的结构。不同于普通RNN单元,这里是有四个,以一种非常特殊的方式进行交互。
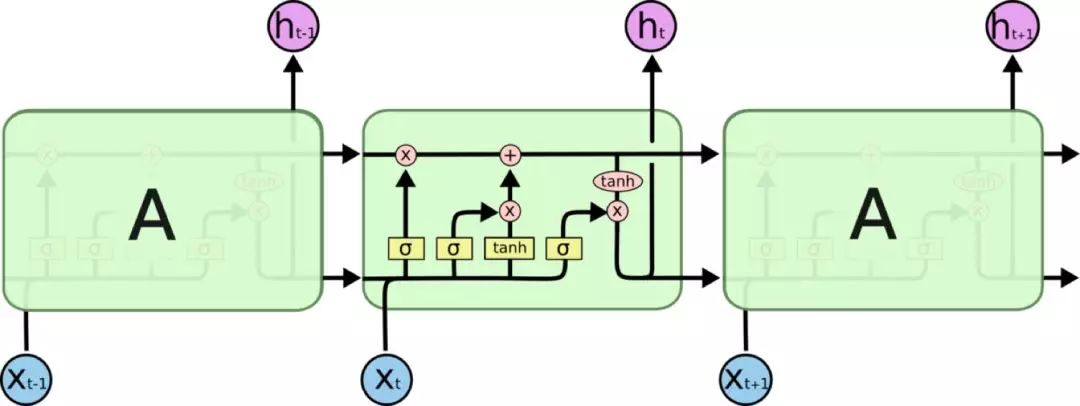 图4:LSTM结构
图4:LSTM结构
LSTM通过三个门结构(输入门,遗忘门,输出门),选择性地遗忘部分历史信息,加入部分当前输入信息,最终整合到当前状态并产生输出状态。
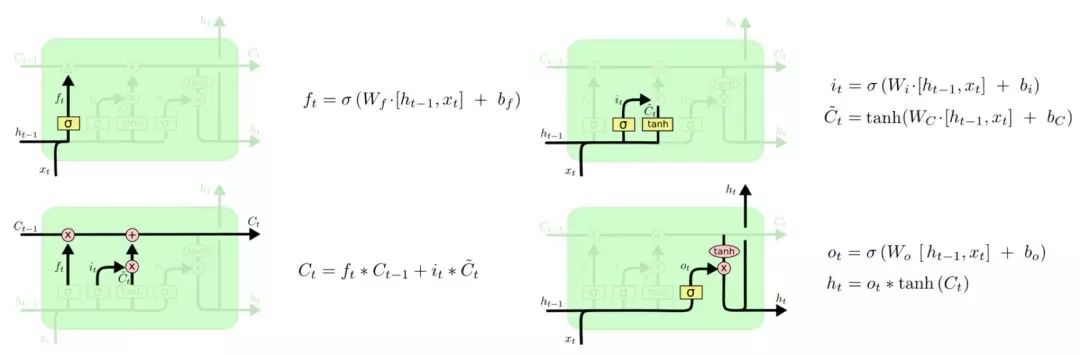 图5:LSTM各个门控结构
图5:LSTM各个门控结构
应用于NER中的biLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
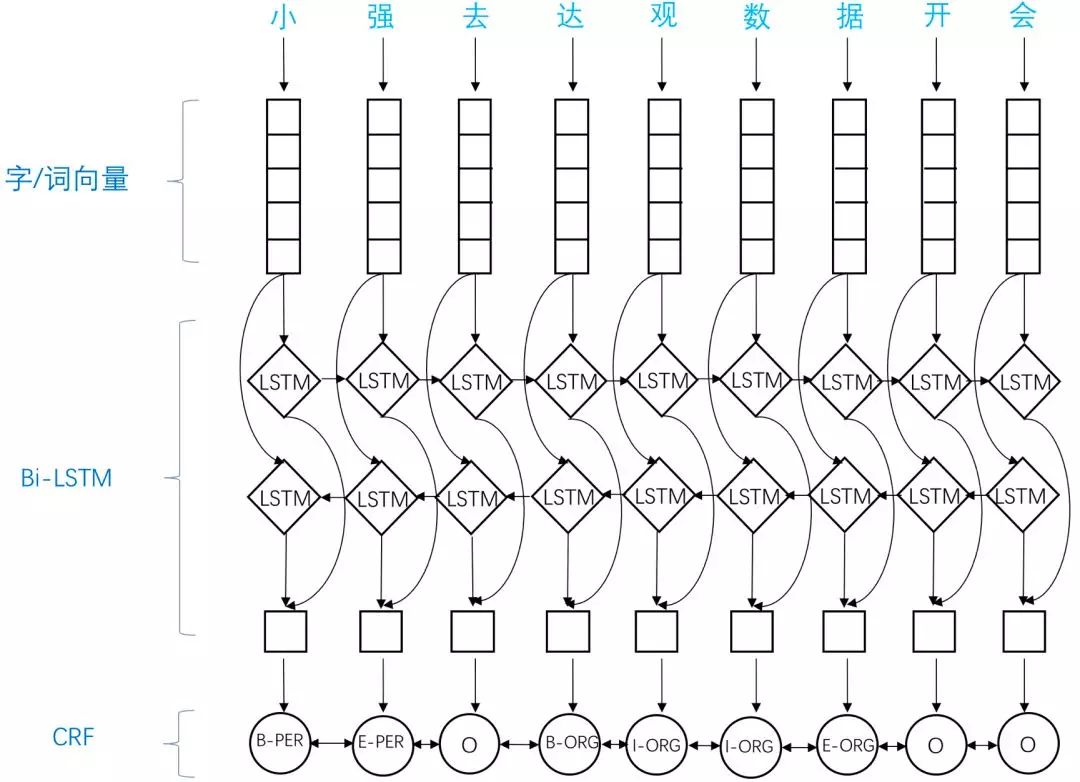 图6:biLSTM-CRF结构示意图
图6:biLSTM-CRF结构示意图
1.2.2 IDCNN-CRF(CNN base)
对于序列标注来讲,普通CNN有一个不足,就是卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息。而对NER来讲,整个输入句子中每个字都有可能对当前位置的标注产生影响,即所谓的长距离依赖问题。为了覆盖到全部的输入信息就需要加入更多的卷积层,导致层数越来越深,参数越来越多。而为了防止过拟合又要加入更多的Dropout之类的正则化,带来更多的超参数,整个模型变得庞大且难以训练。因为CNN这样的劣势,对于大部分序列标注问题人们还是选择biLSTM之类的网络结构,尽可能利用网络的记忆力记住全句的信息来对当前字做标注。
但这又带来另外一个问题,biLSTM本质是一个序列模型,在对GPU并行计算的利用上不如CNN那么强大。如何能够像CNN那样给GPU提供一个火力全开的战场,而又像LSTM这样用简单的结构记住尽可能多的输入信息呢?
Fisher Yu and Vladlen Koltun 2015 提出了dilated CNN模型,意思是“膨胀的”CNN。其想法并不复杂:正常CNN的filter,都是作用在输入矩阵一片连续的区域上,不断sliding做卷积。dilated CNN为这个filter增加了一个dilation width,作用在输入矩阵的时候,会skip所有dilation width中间的输入数据;而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。
具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而receptive field却是指数增加的,可以很快覆盖到全部的输入数据。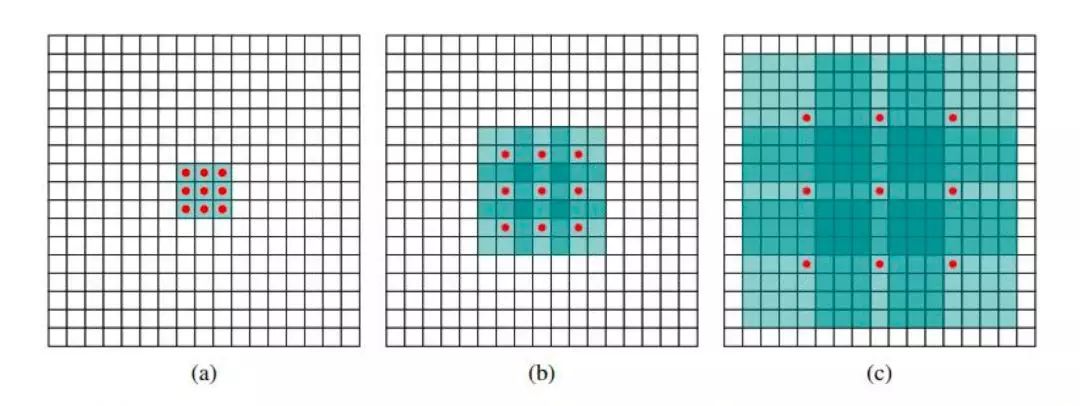 图7:idcnn示意图
图7:idcnn示意图
图7中可见感受域是以指数速率扩大的。原始感受域是位于中心点的1x1区域:
(a)图中经由原始感受域按步长为1向外扩散,得到8个1x1的区域构成新的感受域,大小为3x3;
(b)图中经过步长为2的扩散,上一步3x3的感受域扩展为为7x7;
(c)图中经步长为4的扩散,原7x7的感受域扩大为15x15的感受域。每一层的参数数量是相互独立的。感受域呈指数扩大,但参数数量呈线性增加。
对应在文本上,输入是一个一维的向量,每个元素是一个character embedding:
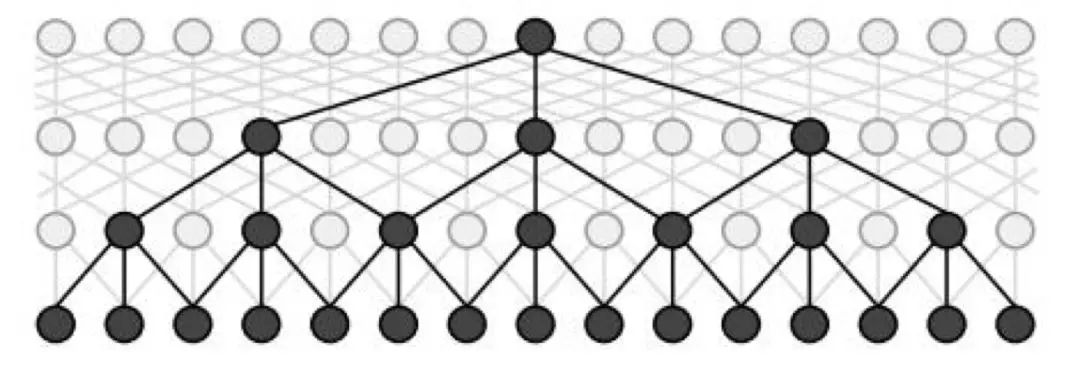 图8:一个最大膨胀步长为4的idcnn块
图8:一个最大膨胀步长为4的idcnn块
IDCNN对输入句子的每一个字生成一个logits,这里就和biLSTM模型输出logits完全一样,加入CRF层,用Viterbi算法解码出标注结果。
CNN base方法利用空洞卷积+多层的方式实现提取整句的功能,同时也能实现并行计算加速(相较于RNN,CNN与RNN速度对比区别可以参考我之间博文,CNN RNN 并行理解)。
在biLSTM或者IDCNN这样的网络模型末端接上CRF层是序列标注的一个很常见的方法。biLSTM或者IDCNN计算出的是每个词的各标签概率,而CRF层引入序列的转移概率,最终计算出loss反馈回网络。
现在就剩一个问题了:什么是CRF层?为什么要用?
1.2.3 CRF层讲解
接下来,简明介绍一下该模型。
示意图如下所示:
首先,句子xxx中的每个单词表达成一个向量,该向量包含了上述的word embedding和character embedding,其中character embedding随机初始化,word embedding通常采用预训练模型初始化。所有的embeddings 将在训练过程中进行微调。
其次,BiLSTM-CRF模型的的输入是上述的embeddings,输出是该句子xxx中每个单词的预测标签。
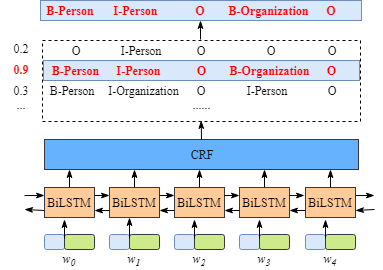
尽管,我们讲的是CRF层,不必了解BiLSTM层的细节,但是为了便于了解CRF层,我们必须知道BiLSTM层输出的意义。
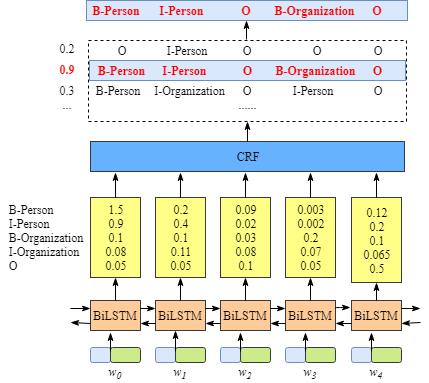
从上图可以看出,BiLSTM层的输出是每个标签的得分,如单词w0w_0w0,BiLSTM的输出为1.5(B-Person),0.9(I-Person),0.1(B-Organization), 0.08 (I-Organization) and 0.05 (O),这些得分就是CRF层的输入。
将BiLSTM层预测的得分喂进CRF层,具有最高得分的标签序列将是模型预测的最好结果。
如果没有CRF层将如何?
根据上文,能够发现,如果没有CRF层,即我们用下图所示训练BiLSTM命名实体识别模型:
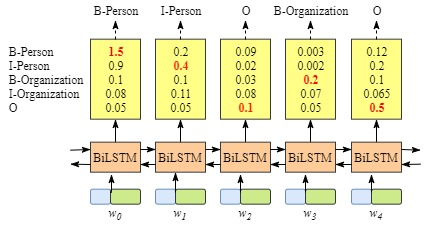
因为BiLSTM针对每个单词的输出是标签得分,对于每个单词,我们可以选择最高得分的标签作为预测结果。
例如,对于w0w_0w0,“B-Person"得分最高(1.5),因此我们可以选择“B-Person”最为其预测标签;同样的,w1w_1w1的标签为"I-Person”,w2w_2w2的为"O", w3w_3w3的标签为"B-Organization",w4w_4w4的标签为"O"。
按照上述方法,对于xxx虽然我们得到了正确的标签,但是大多数情况下是不能获得正确标签的,例如下图的例子:
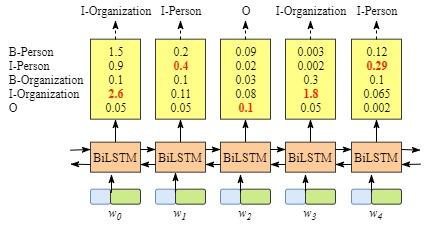
显然,输出标签“I-Organization I-Person” 和 “B-Organization I-Person”是不对的。
CRF能够从训练数据中学习到约束条件
CRF层可以对最终的约束标签添加一些约束条件,从而保证预测标签的有效性。而这些约束条件是CRF层自动从训练数据中学到。
约束可能是:
一句话中第一个单词的标签应该是“B-“ or “O”,而不能是"I-";
“B-label1 I-label2 I-label3 I-…”中,label1, label2, label3 …应该是相同的命名实体标签。如“B-Person I-Person”是有效的,而“B-Person I-Organization” 是无效的;
“O I-label” 是无效的。一个命名实体的第一个标签应该以 “B-“ 开头,而不能以“I-“开头,换句话说, 应该是“O B-label”这种模式;
…
有了这些约束条件,无效的预测标签序列将急剧减少。
CRF层就是加了约束使得输出更加符合要求,同时也增加算法成本,有些类似束搜索的功能,下面我们看一看CRF层具体如何工作的。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
逐帧softmax并没有直接考虑输出的上下文关联
条件随机场
然而,当我们设计标签时,比如用s、b、m、e的4个标签来做字标注法的分词,目标输出序列本身会带有一些上下文关联,比如s后面就不能接m和e,等等。逐标签softmax并没有考虑这种输出层面的上下文关联,所以它意味着把这些关联放到了编码层面,希望模型能自己学到这些内容,但有时候会“强模型所难”。
而CRF则更直接一点,它将输出层面的关联分离了出来,这使得模型在学习上更为“从容”:
CRF在输出端显式地考虑了上下文关联
数学
当然,如果仅仅是引入输出的关联,还不仅仅是CRF的全部,CRF的真正精巧的地方,是它以路径为单位,考虑的是路径的概率。
模型概要
假如一个输入有nn帧,每一帧的标签有kk种可能性,那么理论上就有knkn中不同的输出。我们可以将它用如下的网络图进行简单的可视化。在下图中,每个点代表一个标签的可能性,点之间的连线表示标签之间的关联,而每一种标注结果,都对应着图上的一条完整的路径。
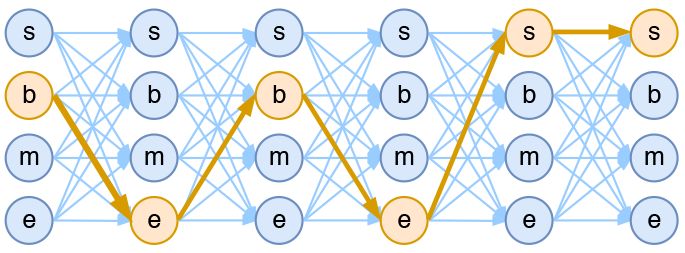
4tag分词模型中输出网络图
而在序列标注任务中,我们的正确答案是一般是唯一的。比如“今天天气不错”,如果对应的分词结果是“今天/天气/不/错”,那么目标输出序列就是bebess,除此之外别的路径都不符合要求。换言之,在序列标注任务中,我们的研究的基本单位应该是路径,我们要做的事情,是从knkn条路径选出正确的一条,那就意味着,如果将它视为一个分类问题,那么将是knkn类中选一类的分类问题!
总结一下:CRF作用可以优化输出实体之间的关联
2.编程实战
2.1 概述
该实战项目参考博文
该项目使用了conll2003_v2数据集,其中标注的命名实体共计九类:
['O', 'B-LOC', 'B-PER', 'B-ORG', 'I-PER', 'I-ORG', 'B-MISC', 'I-LOC', 'I-MISC']
实现了将输入识别为命名实体的模型,如下所示:
# input
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
# output
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
2.2数据预处理
数据下载并解压,以供训练,地址
http://files.deeppavlov.ai/deeppavlov_data/conll2003_v2.tar.gz
下载解压后可以看到三个文件:test.txt,train.txt,valid.txt
打开后可以看到,数据格式如下:我们只需要每行开头和最后一个数据,他们分别是文本信息和命名实体。
-DOCSTART- -X- -X- O
EU NNP B-NP B-ORG
rejects VBZ B-VP O
German JJ B-NP B-MISC
call NN I-NP O
to TO B-VP O
boycott VB I-VP O
British JJ B-NP B-MISC
lamb NN I-NP O
. . O O
数据读取与预处理
我们需要将数据进行处理,使之成为网络能接收的形式。
读取数据,并测试输出
from tqdm import tqdm
class NerDatasetReader:
def read(self, data_path):
data_parts = ['train', 'valid', 'test']
extension = '.txt'
dataset = {}
for data_part in tqdm(data_parts):
file_path = data_path + data_part + extension
dataset[data_part] = self.read_file(str(file_path))
return dataset
def read_file(self, file_path):
fileobj = open(file_path, 'r', encoding='utf-8')
samples = []
tokens = []
tags = []
for content in fileobj:
content = content.strip('\n')
if content == '-DOCSTART- -X- -X- O':
pass
elif content == '':
if len(tokens) != 0:
samples.append((tokens, tags))
tokens = []
tags = []
else:
contents = content.split(' ')
tokens.append(contents[0])
tags.append(contents[-1])
return samples
if __name__ == "__main__":
ds_rd = NerDatasetReader()
data1 = ds_rd.read("./conll2003_v2/")
for sample in data1['train'][:2]:
print(sample)
for token, tag in zip(*sample):
print('%s\t%s' % (token, tag))
print()
输出结果
(['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.'], ['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O'])
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
(['Peter', 'Blackburn'], ['B-PER', 'I-PER'])
Peter B-PER
Blackburn I-PER
可以看出数据已经经过整理,每一句保存为了两个list,一个是单词list,另一个是标注list
但是这里还有两个问题:1.网络无法处理单词级别数据,我们需要准换成数值表示 2.每个句子长度不同,无法统一训练,需要归一化
对于问题1.我们可以通过转换为字典的方式来数值化。
def get_dicts(datas):
w_all_dict,n_all_dict = {},{}
for sample in datas:
for token, tag in zip(*sample):
if token not in w_all_dict.keys():
w_all_dict[token] = 1
else:
w_all_dict[token] += 1
if tag not in n_all_dict.keys():
n_all_dict[tag] = 1
else:
n_all_dict[tag] += 1
sort_w_list = sorted(w_all_dict.items(), key=lambda d: d[1], reverse=True)
sort_n_list = sorted(n_all_dict.items(), key=lambda d: d[1], reverse=True)
w_keys = [x for x,_ in sort_w_list[:15999]]
w_keys.insert(0,"UNK")
n_keys = [ x for x,_ in sort_n_list]
w_dict = { x:i for i,x in enumerate(w_keys) }
n_dict = { x:i for i,x in enumerate(n_keys) }
return(w_dict,n_dict)
if __name__ == "__main__":
ds_rd = NerDatasetReader()
data1 = ds_rd.read("./conll2003_v2/")
w_dict,n_dict = get_dicts(data1["train"])
print(len(w_dict),n_dict)
测试输出结果
8000 {'O': 0, 'B-LOC': 1, 'B-PER': 2, 'B-ORG': 3, 'I-PER': 4, 'I-ORG': 5, 'B-MISC': 6, 'I-LOC': 7, 'I-MISC': 8}
我们保留前15999个常用的单词,新增了一个"UNK"代表未知单词。
下面我们就要将利用这些字典把单词给替换为数值
def w2num(datas,w_dict,n_dict):
ret_datas = []
for sample in datas:
num_w_list,num_n_list = [],[]
for token, tag in zip(*sample):
if token not in w_dict.keys():
token = "UNK"
if tag not in n_dict:
tag = "O"
num_w_list.append(w_dict[token])
num_n_list.append(n_dict[tag])
ret_datas.append((num_w_list,num_n_list,len(num_n_list)))
return(ret_datas)
if __name__ == "__main__":
ds_rd = NerDatasetReader()
dataset = ds_rd.read("./conll2003_v2/")
w_dict,n_dict = get_dicts(dataset["train"])
data_num = {}
data_num["train"] = w2num(dataset["train"],w_dict,n_dict)
print(data_num["train"][:4])
print(dataset["train"][:4])
测试输出结果,已经实现了数值化的要求。为了方便统计句子长度,每个元祖最后一位保存为了句子长度。
[([957, 11983, 233, 762, 6, 4147, 209, 6182, 1], [3, 0, 6, 0, 0, 0, 6, 0, 0], 9), ([732, 2068], [2, 4], 2), ([1379, 134], [1, 0], 2), ([18, 226, 455, 13, 12, 66, 35, 8127, 24, 233, 4148, 6, 2476, 6, 11984, 209, 6182, 407, 3542, 2069, 499, 1789, 1920, 651, 287, 39, 8128, 6, 1921, 1], [0, 3, 5, 0, 0, 0, 0, 0, 0, 6, 0,
0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 30)]
[(['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.'], ['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']), (['Peter', 'Blackburn'], ['B-PER', 'I-PER']), (['BRUSSELS', '1996-08-22'], ['B-LOC', 'O']), (['The', 'European', 'Commission', 'said', 'on', 'Thursday', 'it', 'disagreed', 'with', 'German', 'advice', 'to', 'consumers', 'to', 'shun', 'British', 'lamb', 'until', 'scientists', 'determine', 'whether', 'mad', 'cow', 'disease', 'can', 'be', 'transmitted', 'to', 'sheep', '.'], ['O', 'B-ORG', 'I-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'B-MISC', 'O', 'O', 'O', 'O', 'O', 'B-MISC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'])]
我们输出句子长度的统计,发现最大值113,最小值为1,为了方便统一训练,我们归一化长度为80
data_num["train"] = w2num(dataset["train"],w_dict,n_dict)
w_lens = [data[-1] for data in data_num["train"]]
print(max(w_lens),min(w_lens))
#out 113 1
句子长度归一化操作,这里采用padding为0,就是当做“UNK”与“O”来用,其实也可以使用Mask方法等
def len_norm(data_num,lens=80):
ret_datas = []
for sample1 in list(data_num):
sample = list(sample1)
ls = sample[-1]
#print(sample)
while(ls<lens):
sample[0].append(0)
ls = len(sample[0])
sample[1].append(0)
else:
sample[0] = sample[0][:lens]
sample[1] = sample[1][:lens]
ret_datas.append(sample[:2])
return(ret_datas)
if __name__ == "__main__":
ds_rd = NerDatasetReader()
dataset = ds_rd.read("./conll2003_v2/")
w_dict,n_dict = get_dicts(dataset["train"])
data_num = {}
data_num["train"] = w2num(dataset["train"],w_dict,n_dict)
data_norm = {}
data_norm["train"] = len_norm(data_num["train"])
print(data_norm["train"][:4])
测试输出结果为
[
], [3, 0, 6, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], [[732, 2068, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [2, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], [[1379, 134, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], [[18, 226, 455, 13, 12, 66, 35, 8127, 24, 233, 4148, 6, 2476, 6, 11984, 209, 6182, 407, 3542, 2069, 499, 1789, 1920, 651, 287, 39, 8128, 6, 1921, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 3, 5, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]]
2.3 模型搭建
模型搭建采用了BiRNN方法,具体的说是BiLSTM,为了方便讲解,采用的是RNN+Softmax方式,没有用CRF,后面有时间我会更新一个CRF的版本。网络结构如下:
模型搭建代码
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tensorflow.keras.optimizers import *
def build_model(num_classes=9):
model = Sequential()
model.add(Embedding(16000, 256, input_length=80))
model.add(Bidirectional(LSTM(128,return_sequences=True),merge_mode="concat"))
model.add(Bidirectional(LSTM(128,return_sequences=True),merge_mode="concat"))
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
return(model)
输出模型结构
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 80, 256) 4096000
_________________________________________________________________
bidirectional (Bidirectional (None, 80, 256) 394240
_________________________________________________________________
bidirectional_1 (Bidirection (None, 80, 256) 394240
_________________________________________________________________
dense (Dense) (None, 80, 128) 32896
_________________________________________________________________
dense_1 (Dense) (None, 80, 9) 1161
=================================================================
Total params: 4,918,537
Trainable params: 4,918,537
Non-trainable params: 0
_________________________________________________________________
None
2.4 模型训练
train_data = np.array(data_norm["train"])
train_x = train_data[:,0,:]
train_y = train_data[:,1,:]
print(train_x.shape)
model.fit(x=train_x,y=train_y,epochs=5,batch_size=200,verbose=1,validation_split=0.1)
model.save("model.h5")
训练10个epoch,MX150GPU耗时五分钟,可以发现train_loss与val_loss都在下降
12636/12636 [==============================] - 68s 5ms/sample - loss: 0.3199 - val_loss: 0.1359
Epoch 2/5
12636/12636 [==============================] - 58s 5ms/sample - loss: 0.1274 - val_loss: 0.1201
Epoch 3/5
12636/12636 [==============================] - 63s 5ms/sample - loss: 0.1099 - val_loss: 0.0957
Epoch 4/5
12636/12636 [==============================] - 58s 5ms/sample - loss: 0.0681 - val_loss: 0.0601
Epoch 5/5
12636/12636 [==============================] - 63s 5ms/sample - loss: 0.0372 - val_loss: 0.0498
2.5模型应用
最终训练10个epoch
model.load_weights("model.h5")
pre_y = model.predict(train_x[:4])
print(pre_y.shape)
pre_y = np.argmax(pre_y,axis=-1)
for i in range(0,len(train_y[0:4])):
print("label "+str(i),train_y[i])
print("pred "+str(i),pre_y[i])
测试输出结果,可以发现,预测前四个训练集数据达到不错的效果。
label 0 [3 0 6 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
pred 0 [3 0 6 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
label 1 [2 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
pred 1 [2 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
label 2 [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
pred 2 [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
label 3 [0 3 5 0 0 0 0 0 0 6 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
pred 3 [0 3 5 0 0 0 0 0 0 6 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0]
3. 总结&待续
为了简化,本文只用了RNN+Softmax方法进行了训练集测试,可以改进地方还有很多,例如加入CRF,使用Mask方法,三个数据集都用到等,后面有时间就会进行更新。也欢迎大家一起交流,共同改进。
参考链接:
https://www.jiqizhixin.com/articles/2018-08-31-2
https://blog.csdn.net/suan2014/article/details/89419283
https://spaces.ac.cn/archives/5542
https://blog.csdn.net/chinatelecom08/article/details/82871376
开源地址:https://github.com/xiaosongshine/NLP_NER_RNN_Keras
个人主页:http://www.yansongsong.cn/
本文链接:
https://blog.csdn.net/xiaosongshine/article/details/99622170
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

AI ProCon 2019 邀请到了亚马逊首席科学家@李沐,在大会的前一天(9.5)亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧。还有 9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!5折优惠票抢购中!

推荐阅读
时间序列的建模新思路:清华、李飞飞团队等提出强记忆力E3D-LSTM网络
为什么华为200万招聘AI博士,马斯克却推出脑机接口对抗AI?
机器学习知识点全攻略
白话中台战略:中台是个什么鬼?
从原理到代码,轻松深入逻辑回归模型
只需要支付0.5元就可以撤回交易?这下可坑苦DApp了……
鸿蒙OS背后神秘人物曝光
5G基站功耗,到底有多大?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

poj 2063完全背包
题意:给出总资金和投资年份 ,n个股票 给出股票价格和其一年的利润。问如何选择能获得最大利润。 思路:股票可以重复选择,完全背包问题,完全背包也是从01背包衍生而行的,其主要区别在于中间那层循环的次序不…
UTF-8 CPP的使用
UTF-8 CPP是一个简单、小巧、轻量级、跨平台的UTF-8编码字符串库。下面对其使用方法进行简单的介绍:1. 从http://sourceforge.net/projects/utfcpp/下载最新的utf8_v2_3_4.zip源码,将其解压缩;2. 新建一个vs2013 控制台工程TestUTF…

一行js代码识别Selenium+Webdriver及其应对方案
有不少朋友在开发爬虫的过程中喜欢使用Selenium Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。 先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用…

Android系统移植与调试之-------如何修改Android设备添加重启、飞行模式、静音模式等功能(一)...
1、首先先来看一下修改前后的效果对比图 修改之后的图片 确认重启界面 具体的修改内容在下一篇中具体介绍。 Android系统移植与调试之------->如何修改Android设备添加重启、飞行模式、静音模式等功能(二) 作者:欧阳鹏 欢迎转载…
鸿蒙霸榜GitHub,从最初的Plan B到“取代Android”?
整理 | 郭芮出品 | CSDN(ID:CSDNnews)距离 8 月 9 日鸿蒙(HarmonyOS)正式发布刚刚过去九天,这场由华为领衔的技术风暴,经过十年蛰伏,终于成功引爆全球。与此同时,一个非官…

CODING 最佳实践:快课网研发效能提升之路
快课企业移动学习平台是上海快微网络科技有限公司自主研发的企业级 SaaS 平台,提供移动学习、考试练习、培训管理、知识分享、统计分析等学习和培训功能,为员工、经销商及客户等全价值链合作伙伴提供全面的知识服务。本文将详细介绍快课网的研发团队是如…
基于chyh1990/caffe-compact在windows vs2013上编译caffe步骤
1. 从https://github.com/chyh1990/caffe-compact下载caffe-compact代码; 2. 通过CMake(cmake-gui)生成vs2013 x64 caffe工程; 3. 从https://github.com/google/protobuf下载ProtoBuf,解压缩,编译ProtoBuf…
菜鸟学***——菜鸟的旅程
第一章.菜鸟的旅程作为一个典型的菜鸟,第一次去网吧上网我不知道怎么开机是很正常的事情,但是无论怎么菜怎么无知也无法阻止我对于***的崇拜,我喜欢他们的那种神秘和在我们普通人眼中的无所不能,在网络世界里他们就想鱼…
程序员假冒AI,印度公司竟骗取2亿元投资
作者 | 神经小姐姐来源 | HyperAI超神经(ID:HyperAI)人工智能界有句调侃的话——「有多少智能,就有多少人工」,今天,印度的一家人工智能公司就印证了这句话。据《华尔街日报》报道,印度创业公司…

Windows7上使用VS2013编译Caffe源码(不带GPU支持)步骤
1. 从https://github.com/BVLC/caffe/通过git clone下载caffe源码,master分支,版本号为09868ac:$ git clone https://github.com/BVLC/caffe.git ;2. 先使用cmake-gui构建生成vs2013工程,发现有很多错误,提示缺少各种依…
区块链之比特币的潜在激励
想知道更多区块链技术知识,请百度【链客区块链技术问答社区】链客,有问必答!! 比特币,这个建立在开放P2P(点对点)网络结构之上的货币(文献9),继续享受人们的追…
每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛?
作者 | 夕颜出品 | AI科技大本营(ID:rgznai100)随着深度学习、强化学习、知识图谱、AutoML 等 AI 技术出现更多突破,推荐系统领域的企业和开发者开始将这些技术与传统推荐算法相结合,使得推荐效果得到显著提升。不过,越…
常用的JQuery数字类型验证正则表达式
var regexEnum { intege:"^-?[1-9]//d*$", //整数 intege1:"^[1-9]//d*$", //正整数 intege2:"^-[1-9]//d*$", //负整数 num:"^([-]?)//d*//.?//d$", //数字 num1:"^([1-9]//d*|0)$", //正数ÿ…
Java多线程编程实战:模拟大量数据同步
背景 最近对于 Java 多线程做了一段时间的学习,笔者一直认为,学习东西就是要应用到实际的业务需求中的。否则要么无法深入理解,要么硬生生地套用技术只是达到炫技的效果。 不过笔者仍旧认为自己对于多线程掌握不够熟练,不敢轻易应…
Ubuntu中Atom编辑器显示中文乱码的处理方法
在Ubuntu14.04 64位机上安装Atom,依次在终端输入如下命令: 1. $ sudo add-apt-repository ppa:webupd8team/atom 2. $ sudo apt-get update 3. $ sudo apt-get install atom处理中文乱码的问题: 1. 安装文泉驿正黑等相关中文字体&#…

我的世界游戏安装
2019独角兽企业重金招聘Python工程师标准>>> Minecraft 是一款沙盘独立视频游戏,灵感来自于Infiniminer,使用Java编写,由Markus "Notch" Persson 所建立,现由Mojang AB 公司开发。 这里我们介绍如何在pcDuin…

RSA签名的PSS模式
本文由云社区发表作者:mariolu 一、什么是PSS模式? 1.1、两种签名方式之一RSA-PSS PSS (Probabilistic Signature Scheme)私钥签名流程的一种填充模式。目前主流的RSA签名包括RSA-PSS和RSA-PKCS#1 v1.5。相对应PKCS(Public Key Cryptography …
AI真人表情包、斗地主AI......DeeCamp学员做了50个好玩又实用的AI项目
8月16日,2019 DeeCamp人工智能训练营的结营仪式上,展示了600名DeeCamp学员的50个AI实践课题。 结营仪式上,由2019 DeeCamp学员组成的6个项目小组作为代表,现场展示了自己Demo成果,并由李开复、张潼等学术及产业导师现…
libcurl库的使用(通过libcurl库下载url图像)
1. 从http://curl.haxx.se/download.html下载libcurl源码,解压缩; 2. 通过CMake(cmake-gui)生成vs2013 x64位 CURL.sln; 3. 打开CURL.sln,编译会生成libcurl.dll动态库; 4. 在CURL.sln基础上&a…
SQL Server 2005/2008 用户数据库文件默认路径和默认备份路径修改方法
2019独角兽企业重金招聘Python工程师标准>>> 一直想把数据库的默认路径修改一下,在网上找了一下,真的发现有办法 , 特拿 来与大家共同分享。 以下仅为参照,如果有多个实例,可能会有些许不同: …
Linux下多线程编程互斥锁和条件变量的简单使用
Linux下的多线程遵循POSIX线程接口,称为pthread。编写Linux下的多线程程序,需要使用头文件pthread.h,链接时需要使用库libpthread.a。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基…
03基于python玩转人工智能最火框架之TensorFlow介绍
一句话介绍: Google开源的基于数据流图的科学计算库,适用于机器学习 不局限于机器学习,但目前被大多用于机器学习等。 TensorFlow计算流图的概念图 Tensor在图中流动。 TensorFlow的含义 拆字释义: Tensor 张量(tf中数据的表征) flow 流动 张量在图中流…
赴约北大,2019 CCF大数据与计算智能大赛正式启动
8月17日,以“数据驱动,智创未来”为主题的2019 CCF大数据与计算智能大赛(2019 CCF BDCI)全球启动仪式,在北京大学英杰交流中心阳光厅正式启幕。自2013年创办以来,大赛已成功举办六届,连续获得教…
Hadoop入门(10)_通过java代码实现从本地的文件上传到Hadoop的文件系统
2019独角兽企业重金招聘Python工程师标准>>> 第一步:首先搭建java的编译环境。创建一个Java Project工程,名为upload。 第二步:选中所需的Jar包。 选中JRE System Library 选择BuildPath Configure Build Path 选择ha…
Caffe源码中各种依赖库的作用及简单使用
1. Boost库:它是一个可移植、跨平台,提供源代码的C库,作为标准库的后备。 在Caffe中用到的Boost头文件包括: (1)、shared_ptr.hpp:智能指针,使用它可以不需要考虑内存释放的问题; (2)、dat…

漫画:5分钟了解什么是动态规划?
作者 | 调皮的阿广来源 | 视学算法(ID:z872561826)动态规划,英文是Dynamic Programming,简称DP,擅长解决“多阶段决策问题”,利用各个阶段阶段的递推关系,逐个确定每个阶段的最优决策…

小程序大转盘红包雨营销组件
前言 商城没几个营销活动能叫商城吗?所以就来几个组件吧,写的不好轻踩,对你有帮助记得给个小星星哦直接上链接github链接 运行例子 git clone https://github.com/sunnie1992/soul-weapp.git 微信开发者工具打开项目 营销组件 大转盘 "p…
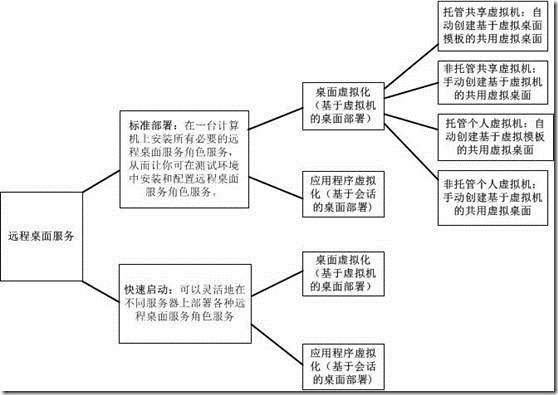
Windows Server 2012 RDS系列:虚拟桌面化(5)
概述:本次将系列地测试Windows Server 2012 远程桌面服务(RDS),将过程进行分享,总的感觉比2008 R2更简单了,体现着2012的自动化。2012的RDS部署有标准部署和快速启动两种,快速启动就是自动快速配…
里程碑式成果Faster RCNN复现难?我们试了一下 | 附完整代码
作者 | 已退逼乎 来源 | 知乎【导读】2019年以来,除各AI 大厂私有网络范围外,MaskRCNN,CascadeRCNN 成为了支撑很多业务得以开展的基础,而以 Faster RCNN 为基础去复现其他的检测网络既省时又省力,也算得上是里程碑性成…
【跃迁之路】【725天】程序员高效学习方法论探索系列(实验阶段482-2019.2.15)...
实验说明 从2017.10.6起,开启这个系列,目标只有一个:探索新的学习方法,实现跃迁式成长实验期2年(2017.10.06 - 2019.10.06)我将以自己为实验对象。我将开源我的学习方法,方法不断更新迭代&#…