Caffe源码中layer文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/layer.hpp文件的内容:
1. include文件:
(1)、<caffe/blob.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/59106613
(2)、<caffe/common.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/54955236
(3)、<caffe/layer_factory.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/54310956
(4)、<caffe/proto/caffe.pb.h>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/55267162
(5)、<caffe/util/device_alternate.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/54955236
2. 类Layer:抽象基类,有纯虚函数,不能实例化,定义了所有layer的基本接口,具体的每个layer完成一类特定的计算
Layer是Caffe模型的本质内容和执行计算的基本单元。Layer可以进行很多运算,如convolve(卷积)、pool(池化)、inner product(内积),rectified-linear和sigmoid等非线性运算,元素级的数据变换,normalize(归一化)、load data(数据加载)、softmax和hinge等losses(损失计算)。可在Caffe的 http://caffe.berkeleyvision.org/tutorial/layers.html (层目录)中查看所有操作,其囊括了绝大部分目前最前沿的深度学习任务所需要的层类型。
一个layer通过bottom(底部) 连接层接收blobs数据,通过top(顶部)连接层输出blobs数据。Caffe中每种类型layer的参数说明定义在caffe.proto文件中,具体的layer参数值则定义在具体应用的prototxt网络结构说明文件中。
在Caffe中,一个网络的大部分功能都是以layer的形式去展开的。在创建一个Caffe模型的时候,也是以layer为基础进行的,需按照caffe.proto中定义的网络及参数格式定义网络prototxt文件。在.prototxt文件中会有很多个layer { } 字段。
每一个layer都定义了3种重要的运算:setup(初始化设置),forward(前向传播),backward(反向传播)。
(1)、setup:在模型初始化时重置layers及其相互之间的连接;
(2)、forward:从bottom层中接收数据,进行计算后将输出送人到top层中;
(3)、backward:给定相对于top层输出的梯度,计算其相对于输入的梯度,并传递到bottom层。一个有参数的layer需要计算相对于各个参数的梯度值并存储在内部。
特别地,forward和backward函数分别有CPU和GPU两张实现方式。如果没有实现GPU版本,那么layer将转向作为备用选项的CPU方式。这样会增加额外的数据传送成本(输入数据由GPU上复制到CPU,之后输出数据从CPU又复制回到GPU)。
总的来说,Layer承担了网络的两个核心操作:forward pass(前向传播)----接收输入并计算输出;backward pass(反向传播)----接收关于输出的梯度,计算相对于参数和输入的梯度并反向传播给在它前面的层。由此组成了每个layer的前向和反向传播。
Layer是网络的基本单元,由此派生出了各种层类。在Layer中input data用bottom表示,output data用top表示。由于Caffe网络的组合性和其代码的模块化,自定义layer是很容易的。只要定义好layer的setup(初始化设置)、forward(前向传播,根据input计算output)和backward(反向传播,根据output计算input的梯度),就可将layer纳入到网络中。
前传(forward)过程为给定的待推断的输入计算输出。在前传过程中,Caffe组合每一层的计算以得到整个模型的计算”函数”。本过程自底向上进行。
反传(backward)过程根据损失来计算梯度从而进行学习。在反传过程中,Caffe通过自动求导并反向组合每一层的梯度来计算整个网络的梯度。这就是反传过程的本质。本过程自顶向下进行。
反传过程以损失开始,然后根据输出计算梯度。根据链式准则,逐层计算出模型其余部分的梯度。有参数的层,会在反传过程中根据参数计算梯度。
与大多数的机器学习模型一样,在Caffe中,学习是由一个损失函数驱动的(通常也被称为误差、代价或者目标函数)。一个损失函数通过将参数集(即当前的网络权值)映射到一个可以标识这些参数”不良程度”的标量值来学习目标。因此,学习的目的是找到一个网络权重的集合,使得损失函数最小。
在Caffe中,损失是通过网络的前向计算得到的。每一层由一系列的输入blobs(bottom),然后产生一系列的输出blobs(top)。这些层的某些输出可以用来作为损失函数。典型的一对多分类任务的损失函数是softMaxWithLoss函数。
Caffe中每种类型layer的参数说明定义在caffe.proto文件中,具体的layer参数值则定义在具体应用的protobuf网络结构说明文件中。
注:以上关于Layer内容的介绍主要摘自由CaffeCN社区翻译的《Caffe官方教程中译本》。
<caffe/layer.hpp>文件的详细介绍如下:
#ifndef CAFFE_LAYER_H_
#define CAFFE_LAYER_H_#include <algorithm>
#include <string>
#include <vector>#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer_factory.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/device_alternate.hpp"/**Forward declare boost::thread instead of including boost/thread.hppto avoid a boost/NVCC issues (#1009, #1010) on OSX.*/
// 前向声明boost的互斥类:boost::mutex
namespace boost { class mutex; }namespace caffe {
/*** @brief An interface for the units of computation which can be composed into a* Net.** Layer%s must implement a Forward function, in which they take their input* (bottom) Blob%s (if any) and compute their output Blob%s (if any).* They may also implement a Backward function, in which they compute the error* gradients with respect to their input Blob%s, given the error gradients with* their output Blob%s.*/
template <typename Dtype>
class Layer { // 抽象基类,有纯虚函数,不能实例化,定义了所有layer的基本接口public:/*** You should not implement your own constructor. Any set up code should go* to SetUp(), where the dimensions of the bottom blobs are provided to the* layer.*/
// 显式构造函数,不需要重写,获得成员变量layer_param_、phase_、blobs_的值explicit Layer(const LayerParameter& param): layer_param_(param), is_shared_(false) {// Set phase and copy blobs (if there are any).phase_ = param.phase();if (layer_param_.blobs_size() > 0) {blobs_.resize(layer_param_.blobs_size());for (int i = 0; i < layer_param_.blobs_size(); ++i) {blobs_[i].reset(new Blob<Dtype>());blobs_[i]->FromProto(layer_param_.blobs(i));}}}
// 虚析构函数virtual ~Layer() {}/*** @brief Implements common layer setup functionality.** @param bottom the preshaped input blobs* @param top* the allocated but unshaped output blobs, to be shaped by Reshape** Checks that the number of bottom and top blobs is correct.* Calls LayerSetUp to do special layer setup for individual layer types,* followed by Reshape to set up sizes of top blobs and internal buffers.* Sets up the loss weight multiplier blobs for any non-zero loss weights.* This method may not be overridden.*/
// layer初始化,此方法不需要重写void SetUp(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {InitMutex();CheckBlobCounts(bottom, top);LayerSetUp(bottom, top);Reshape(bottom, top);SetLossWeights(top);}/*** @brief Does layer-specific setup: your layer should implement this function* as well as Reshape.** @param bottom* the preshaped input blobs, whose data fields store the input data for* this layer* @param top* the allocated but unshaped output blobs** This method should do one-time layer specific setup. This includes reading* and processing relevent parameters from the <code>layer_param_</code>.* Setting up the shapes of top blobs and internal buffers should be done in* <code>Reshape</code>, which will be called before the forward pass to* adjust the top blob sizes.*/
// 通过Layer参数即LayerParameter类获得layer中某些成员变量的值virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {}/*** @brief Whether a layer should be shared by multiple nets during data* parallelism. By default, all layers except for data layers should* not be shared. data layers should be shared to ensure each worker* solver access data sequentially during data parallelism.*/
// 获得layer data共享状态:一个layer的data是否被多个net共享virtual inline bool ShareInParallel() const { return false; }/** @brief Return whether this layer is actually shared by other nets.* If ShareInParallel() is true and using more than one GPU and the* net has TRAIN phase, then this function is expected return true.*/
// 获得layer是否被其它net共享inline bool IsShared() const { return is_shared_; }/** @brief Set whether this layer is actually shared by other nets* If ShareInParallel() is true and using more than one GPU and the* net has TRAIN phase, then is_shared should be set true.*/
// 设置layer是否被其它net共享inline void SetShared(bool is_shared) {CHECK(ShareInParallel() || !is_shared)<< type() << "Layer does not support sharing.";is_shared_ = is_shared;}/*** @brief Adjust the shapes of top blobs and internal buffers to accommodate* the shapes of the bottom blobs.** @param bottom the input blobs, with the requested input shapes* @param top the top blobs, which should be reshaped as needed** This method should reshape top blobs as needed according to the shapes* of the bottom (input) blobs, as well as reshaping any internal buffers* and making any other necessary adjustments so that the layer can* accommodate the bottom blobs.*/
// 调整top blobs的shapevirtual void Reshape(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) = 0;/*** @brief Given the bottom blobs, compute the top blobs and the loss.** @param bottom* the input blobs, whose data fields store the input data for this layer* @param top* the preshaped output blobs, whose data fields will store this layers'* outputs* \return The total loss from the layer.** The Forward wrapper calls the relevant device wrapper function* (Forward_cpu or Forward_gpu) to compute the top blob values given the* bottom blobs. If the layer has any non-zero loss_weights, the wrapper* then computes and returns the loss.** Your layer should implement Forward_cpu and (optionally) Forward_gpu.*/
// 前向传播,通过输入bottom blobs,计算输出top blobs和返回loss和inline Dtype Forward(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top);/*** @brief Given the top blob error gradients, compute the bottom blob error* gradients.** @param top* the output blobs, whose diff fields store the gradient of the error* with respect to themselves* @param propagate_down* a vector with equal length to bottom, with each index indicating* whether to propagate the error gradients down to the bottom blob at* the corresponding index* @param bottom* the input blobs, whose diff fields will store the gradient of the error* with respect to themselves after Backward is run** The Backward wrapper calls the relevant device wrapper function* (Backward_cpu or Backward_gpu) to compute the bottom blob diffs given the* top blob diffs.** Your layer should implement Backward_cpu and (optionally) Backward_gpu.*/
// 反向传播,通过给定top blob误差梯度,计算bottom blob误差梯度inline void Backward(const vector<Blob<Dtype>*>& top,const vector<bool>& propagate_down,const vector<Blob<Dtype>*>& bottom);/*** @brief Returns the vector of learnable parameter blobs.*/
// 获得layer的权值、偏置等vector<shared_ptr<Blob<Dtype> > >& blobs() {return blobs_;}/*** @brief Returns the layer parameter.*/
// 获得layer的配置参数const LayerParameter& layer_param() const { return layer_param_; }/*** @brief Writes the layer parameter to a protocol buffer*/
// 序列化函数,将layer参数写入protobuf文件virtual void ToProto(LayerParameter* param, bool write_diff = false);/*** @brief Returns the scalar loss associated with a top blob at a given index.*/
// 获得top blob指定index的loss值inline Dtype loss(const int top_index) const {return (loss_.size() > top_index) ? loss_[top_index] : Dtype(0);}/*** @brief Sets the loss associated with a top blob at a given index.*/
// 设置top blob指定index的loss值inline void set_loss(const int top_index, const Dtype value) {if (loss_.size() <= top_index) {loss_.resize(top_index + 1, Dtype(0));}loss_[top_index] = value;}/*** @brief Returns the layer type.*/
// 获得layer的类型virtual inline const char* type() const { return ""; }/*** @brief Returns the exact number of bottom blobs required by the layer,* or -1 if no exact number is required.** This method should be overridden to return a non-negative value if your* layer expects some exact number of bottom blobs.*/
// 获得layer所需的bottom blobs的个数virtual inline int ExactNumBottomBlobs() const { return -1; }/*** @brief Returns the minimum number of bottom blobs required by the layer,* or -1 if no minimum number is required.** This method should be overridden to return a non-negative value if your* layer expects some minimum number of bottom blobs.*/
// 获得layer所需的bottom blobs的最少个数virtual inline int MinBottomBlobs() const { return -1; }/*** @brief Returns the maximum number of bottom blobs required by the layer,* or -1 if no maximum number is required.** This method should be overridden to return a non-negative value if your* layer expects some maximum number of bottom blobs.*/
// 获得layer所需的bottom blobs的最多个数virtual inline int MaxBottomBlobs() const { return -1; }/*** @brief Returns the exact number of top blobs required by the layer,* or -1 if no exact number is required.** This method should be overridden to return a non-negative value if your* layer expects some exact number of top blobs.*/
// 获得layer所需的top blobs的个数virtual inline int ExactNumTopBlobs() const { return -1; }/*** @brief Returns the minimum number of top blobs required by the layer,* or -1 if no minimum number is required.** This method should be overridden to return a non-negative value if your* layer expects some minimum number of top blobs.*/
// 获得layer所需的top blobs的最少个数virtual inline int MinTopBlobs() const { return -1; }/*** @brief Returns the maximum number of top blobs required by the layer,* or -1 if no maximum number is required.** This method should be overridden to return a non-negative value if your* layer expects some maximum number of top blobs.*/
// 获得layer所需的top blobs的最多个数virtual inline int MaxTopBlobs() const { return -1; }/*** @brief Returns true if the layer requires an equal number of bottom and* top blobs.** This method should be overridden to return true if your layer expects an* equal number of bottom and top blobs.*/
// 判断layer所需的bottom blobs和top blobs的个数是否相等virtual inline bool EqualNumBottomTopBlobs() const { return false; }/*** @brief Return whether "anonymous" top blobs are created automatically* by the layer.** If this method returns true, Net::Init will create enough "anonymous" top* blobs to fulfill the requirement specified by ExactNumTopBlobs() or* MinTopBlobs().*/
// 判断layer所需的的top blobs是否需要由Net::Init来创建virtual inline bool AutoTopBlobs() const { return false; }/*** @brief Return whether to allow force_backward for a given bottom blob* index.** If AllowForceBackward(i) == false, we will ignore the force_backward* setting and backpropagate to blob i only if it needs gradient information* (as is done when force_backward == false).*/
// 判断layer指定的bottom blob是否需要强制梯度返回,因为有些layer其实不需要梯度信息virtual inline bool AllowForceBackward(const int bottom_index) const { return true; }/*** @brief Specifies whether the layer should compute gradients w.r.t. a* parameter at a particular index given by param_id.** You can safely ignore false values and always compute gradients* for all parameters, but possibly with wasteful computation.*/
// 判断layer指定的blob是否应该计算梯度inline bool param_propagate_down(const int param_id) {return (param_propagate_down_.size() > param_id) ?param_propagate_down_[param_id] : false;}/*** @brief Sets whether the layer should compute gradients w.r.t. a* parameter at a particular index given by param_id.*/
// 设置layer指定的blob是否应该计算梯度inline void set_param_propagate_down(const int param_id, const bool value) {if (param_propagate_down_.size() <= param_id) {param_propagate_down_.resize(param_id + 1, true);}param_propagate_down_[param_id] = value;}protected:
// Caffe中类的成员变量名都带有后缀"_",这样就容易区分临时变量和类成员变量/** The protobuf that stores the layer parameters */
// 配置的layer参数,创建layer对象时,通过调用构造函数从上层传入,
// 关于LayerParameter类的具体参数可参考caffe.proto中的message LayerParameterLayerParameter layer_param_;/** The phase: TRAIN or TEST */
// layer状态:指定参与网络的是train还是test,Phase phase_;/** The vector that stores the learnable parameters as a set of blobs. */
// 用于存储layer的学习的参数如权值和偏置vector<shared_ptr<Blob<Dtype> > > blobs_;/** Vector indicating whether to compute the diff of each param blob. */
// 标志是否为layer指定的blob计算梯度值vector<bool> param_propagate_down_;/** The vector that indicates whether each top blob has a non-zero weight in* the objective function. */
// 标志layer指定的top blob是否有一个非0权值vector<Dtype> loss_;/** @brief Using the CPU device, compute the layer output. */
// CPU实现layer的前向传播virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) = 0;/*** @brief Using the GPU device, compute the layer output.* Fall back to Forward_cpu() if unavailable.*/
// GPU实现layer的前向传播virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {// LOG(WARNING) << "Using CPU code as backup.";return Forward_cpu(bottom, top);}/*** @brief Using the CPU device, compute the gradients for any parameters and* for the bottom blobs if propagate_down is true.*/
// CPU实现layer的反向传播virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,const vector<bool>& propagate_down,const vector<Blob<Dtype>*>& bottom) = 0;/*** @brief Using the GPU device, compute the gradients for any parameters and* for the bottom blobs if propagate_down is true.* Fall back to Backward_cpu() if unavailable.*/
// GPU实现layer的反向传播virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,const vector<bool>& propagate_down,const vector<Blob<Dtype>*>& bottom) {// LOG(WARNING) << "Using CPU code as backup.";Backward_cpu(top, propagate_down, bottom);}/*** Called by the parent Layer's SetUp to check that the number of bottom* and top Blobs provided as input match the expected numbers specified by* the {ExactNum,Min,Max}{Bottom,Top}Blobs() functions.*/
// 检查bottom 和top blobs个数是否匹配virtual void CheckBlobCounts(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {if (ExactNumBottomBlobs() >= 0) {CHECK_EQ(ExactNumBottomBlobs(), bottom.size())<< type() << " Layer takes " << ExactNumBottomBlobs()<< " bottom blob(s) as input.";}if (MinBottomBlobs() >= 0) {CHECK_LE(MinBottomBlobs(), bottom.size())<< type() << " Layer takes at least " << MinBottomBlobs()<< " bottom blob(s) as input.";}if (MaxBottomBlobs() >= 0) {CHECK_GE(MaxBottomBlobs(), bottom.size())<< type() << " Layer takes at most " << MaxBottomBlobs()<< " bottom blob(s) as input.";}if (ExactNumTopBlobs() >= 0) {CHECK_EQ(ExactNumTopBlobs(), top.size())<< type() << " Layer produces " << ExactNumTopBlobs()<< " top blob(s) as output.";}if (MinTopBlobs() >= 0) {CHECK_LE(MinTopBlobs(), top.size())<< type() << " Layer produces at least " << MinTopBlobs()<< " top blob(s) as output.";}if (MaxTopBlobs() >= 0) {CHECK_GE(MaxTopBlobs(), top.size())<< type() << " Layer produces at most " << MaxTopBlobs()<< " top blob(s) as output.";}if (EqualNumBottomTopBlobs()) {CHECK_EQ(bottom.size(), top.size())<< type() << " Layer produces one top blob as output for each "<< "bottom blob input.";}}/*** Called by SetUp to initialize the weights associated with any top blobs in* the loss function. Store non-zero loss weights in the diff blob.*/
// 设置top blobs中diff值inline void SetLossWeights(const vector<Blob<Dtype>*>& top) {const int num_loss_weights = layer_param_.loss_weight_size();if (num_loss_weights) {CHECK_EQ(top.size(), num_loss_weights) << "loss_weight must be ""unspecified or specified once per top blob.";for (int top_id = 0; top_id < top.size(); ++top_id) {const Dtype loss_weight = layer_param_.loss_weight(top_id);if (loss_weight == Dtype(0)) { continue; }this->set_loss(top_id, loss_weight);const int count = top[top_id]->count();Dtype* loss_multiplier = top[top_id]->mutable_cpu_diff();caffe_set(count, loss_weight, loss_multiplier);}}}private:/** Whether this layer is actually shared by other nets*/
//标志当前layer是否被其它net共享bool is_shared_;/** The mutex for sequential forward if this layer is shared */
// 声明boost::mutex对象,互斥锁变量shared_ptr<boost::mutex> forward_mutex_;/** Initialize forward_mutex_ */
// 初始化互斥锁void InitMutex();/** Lock forward_mutex_ if this layer is shared */
// 如果layer是共享的则加锁void Lock();/** Unlock forward_mutex_ if this layer is shared */
// 如果layer是共享的则解锁void Unlock();// 禁止使用Layer类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(Layer);
}; // class Layer// Forward and backward wrappers. You should implement the cpu and
// gpu specific implementations instead, and should not change these
// functions.
// 前向传播,通过输入bottom blobs,计算输出top blobs和loss值
template <typename Dtype>
inline Dtype Layer<Dtype>::Forward(const vector<Blob<Dtype>*>& bottom,const vector<Blob<Dtype>*>& top) {// Lock during forward to ensure sequential forwardLock();Dtype loss = 0;Reshape(bottom, top);switch (Caffe::mode()) {case Caffe::CPU:Forward_cpu(bottom, top);for (int top_id = 0; top_id < top.size(); ++top_id) {if (!this->loss(top_id)) { continue; }const int count = top[top_id]->count();const Dtype* data = top[top_id]->cpu_data();const Dtype* loss_weights = top[top_id]->cpu_diff();loss += caffe_cpu_dot(count, data, loss_weights);}break;case Caffe::GPU:Forward_gpu(bottom, top);
#ifndef CPU_ONLYfor (int top_id = 0; top_id < top.size(); ++top_id) {if (!this->loss(top_id)) { continue; }const int count = top[top_id]->count();const Dtype* data = top[top_id]->gpu_data();const Dtype* loss_weights = top[top_id]->gpu_diff();Dtype blob_loss = 0;caffe_gpu_dot(count, data, loss_weights, &blob_loss);loss += blob_loss;}
#endifbreak;default:LOG(FATAL) << "Unknown caffe mode.";}Unlock();return loss;
}// 反向传播,通过给定top blob误差梯度,计算bottom blob误差梯度
template <typename Dtype>
inline void Layer<Dtype>::Backward(const vector<Blob<Dtype>*>& top,const vector<bool>& propagate_down,const vector<Blob<Dtype>*>& bottom) {switch (Caffe::mode()) {case Caffe::CPU:Backward_cpu(top, propagate_down, bottom);break;case Caffe::GPU:Backward_gpu(top, propagate_down, bottom);break;default:LOG(FATAL) << "Unknown caffe mode.";}
}// Serialize LayerParameter to protocol buffer
// 序列化函数,将layer参数写入protobuf文件
template <typename Dtype>
void Layer<Dtype>::ToProto(LayerParameter* param, bool write_diff) {param->Clear();param->CopyFrom(layer_param_);param->clear_blobs();for (int i = 0; i < blobs_.size(); ++i) {blobs_[i]->ToProto(param->add_blobs(), write_diff);}
}} // namespace caffe#endif // CAFFE_LAYER_H_enum Phase { // layer状态:train、testTRAIN = 0;TEST = 1;
}// NOTE
// Update the next available ID when you add a new LayerParameter field.
//
// LayerParameter next available layer-specific ID: 137 (last added: reduction_param)
message LayerParameter { // Layer参数optional string name = 1; // the layer name, layer名字,可由自己任意制定optional string type = 2; // the layer type, layer类型,在具体层中写定,可以通过type()函数获得repeated string bottom = 3; // the name of each bottom blob, bottom名字,可有多个repeated string top = 4; // the name of each top blob,top名字,可有多个// The train / test phase for computation.optional Phase phase = 10; // layer状态:enum Phase {TRAIN = 0; TEST = 1;}// The amount of weight to assign each top blob in the objective.// Each layer assigns a default value, usually of either 0 or 1,// to each top blob.repeated float loss_weight = 5; // 个数必须与top blob一致// Specifies training parameters (multipliers on global learning constants,// and the name and other settings used for weight sharing).repeated ParamSpec param = 6; // train时用到的参数// The blobs containing the numeric parameters of the layer.repeated BlobProto blobs = 7; // blobs个数// Specifies on which bottoms the backpropagation should be skipped.// The size must be either 0 or equal to the number of bottoms.repeated bool propagate_down = 11; // 长度或者是0或者与bottoms个数一致// Rules controlling whether and when a layer is included in the network,// based on the current NetState. You may specify a non-zero number of rules// to include OR exclude, but not both. If no include or exclude rules are// specified, the layer is always included. If the current NetState meets// ANY (i.e., one or more) of the specified rules, the layer is// included/excluded.repeated NetStateRule include = 8; // net state rulerepeated NetStateRule exclude = 9; // net state rule// Parameters for data pre-processing.optional TransformationParameter transform_param = 100; // 对data进行预处理包括缩放、剪切等// Parameters shared by loss layers.optional LossParameter loss_param = 101; // loss parameters// Layer type-specific parameters.//// Note: certain layers may have more than one computational engine// for their implementation. These layers include an Engine type and// engine parameter for selecting the implementation.// The default for the engine is set by the ENGINE switch at compile-time.// 具体layer参数optional AccuracyParameter accuracy_param = 102;optional ArgMaxParameter argmax_param = 103;optional ConcatParameter concat_param = 104;optional ContrastiveLossParameter contrastive_loss_param = 105;optional ConvolutionParameter convolution_param = 106;optional DataParameter data_param = 107;optional DropoutParameter dropout_param = 108;optional DummyDataParameter dummy_data_param = 109;optional EltwiseParameter eltwise_param = 110;optional ExpParameter exp_param = 111;optional FlattenParameter flatten_param = 135;optional HDF5DataParameter hdf5_data_param = 112;optional HDF5OutputParameter hdf5_output_param = 113;optional HingeLossParameter hinge_loss_param = 114;optional ImageDataParameter image_data_param = 115;optional InfogainLossParameter infogain_loss_param = 116;optional InnerProductParameter inner_product_param = 117;optional LogParameter log_param = 134;optional LRNParameter lrn_param = 118;optional MemoryDataParameter memory_data_param = 119;optional MVNParameter mvn_param = 120;optional PoolingParameter pooling_param = 121;optional PowerParameter power_param = 122;optional PReLUParameter prelu_param = 131;optional PythonParameter python_param = 130;optional ReductionParameter reduction_param = 136;optional ReLUParameter relu_param = 123;optional ReshapeParameter reshape_param = 133;optional SigmoidParameter sigmoid_param = 124;optional SoftmaxParameter softmax_param = 125;optional SPPParameter spp_param = 132;optional SliceParameter slice_param = 126;optional TanHParameter tanh_param = 127;optional ThresholdParameter threshold_param = 128;optional WindowDataParameter window_data_param = 129;
}GitHub: https://github.com/fengbingchun/Caffe_Test
相关文章:

全球首个软硬件推理平台 :NVDLA编译器正式开源
作者 | 神经小姐姐来源 | HyperAI超神经(ID:HyperAI)【导读】为深度学习设计新的定制硬件加速器,是目前的一个趋势,但用一种新的设计,实现最先进的性能和效率却具有挑战性。近日,英伟达开源了软硬件推理平台…

【leetcode】1018. Binary Prefix Divisible By 5
题目如下: Given an array A of 0s and 1s, consider N_i: the i-th subarray from A[0] to A[i] interpreted as a binary number (from most-significant-bit to least-significant-bit.) Return a list of booleans answer, where answer[i]is true if and only …
php中magic_quotes_gpc对unserialize的影响
昨天朋友让我帮他解决下他网站的购物车程序的问题,程序用的是PHPCMS,换空间前是好的(刚换的空间),具体问题是提示成功加入购物车后跳转到购物车页面,购物车里为空。 我看了下代码,大致的原理就是…

值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(上)
作者 | 黄浴转载自知乎专栏自动驾驶的挑战和发展【导读】上周,我们在激光雷达,马斯克看不上,却又无可替代?》一文中对自动驾驶中广泛使用的激光雷达进行了简单的科普,今天,这篇文章将各大公司和机构基于激光…
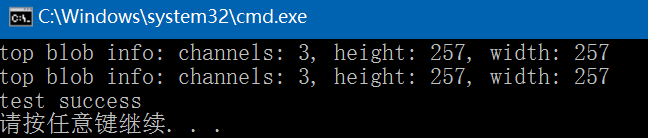
Caffe源码中Pooling Layer文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/vision_layers文件中PoolingLayer类,在最新版caffe中,PoolingLayer类被单独放在了include/caffe/layers/pooling_layer.hpp文件中…
手持终端以物联网的模式
近年来,物联宇手持终端以物联网的模式,开启了信息化的管理模式,迸发了新的自我提升和业务新商机。手持终端是一款智能的电子设备,它的核心功能为用户速带来业务效率的提升,如快递行业,每天的工作量需求大&a…
Linux系统基础-管理之用户、权限管理
Linux用户、权限管理一、如何实现"用户管理"1.什么是用户 "User" : 是一个使用者获取系统资源的凭证,是权限的结合,为了识别界定每一个用户所能访问的资源及其服务的。只是一种凭证。会有一个表示数字,计算机会首…
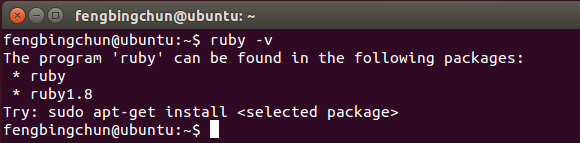
Ubuntu14.04 LTS中安装Ruby 2.4源码操作步骤
(1)、查看是否已安装ruby,执行命令,如下图,可见机子上还没有安装ruby,即使通过apt-get install命令安装也只能安装1.8版本;(2)、从 http://www.ruby-lang.org/en/downloads/ 下载最新稳定版2.4即ruby-2.4.0.tar.gz&a…

图森未来完成2.15亿美元D轮融资,将拓展无人驾驶运输服务
AI科技大本营消息,9月17日,图森未来宣布获得1.2亿美元的D2轮投资,并完成总额为2.15亿美元的D轮融资。D2轮的投资方除了此前已宣布的UPS外,还包括新的投资方鼎晖资本,以及一级供应商万都(Mando Corporation&…
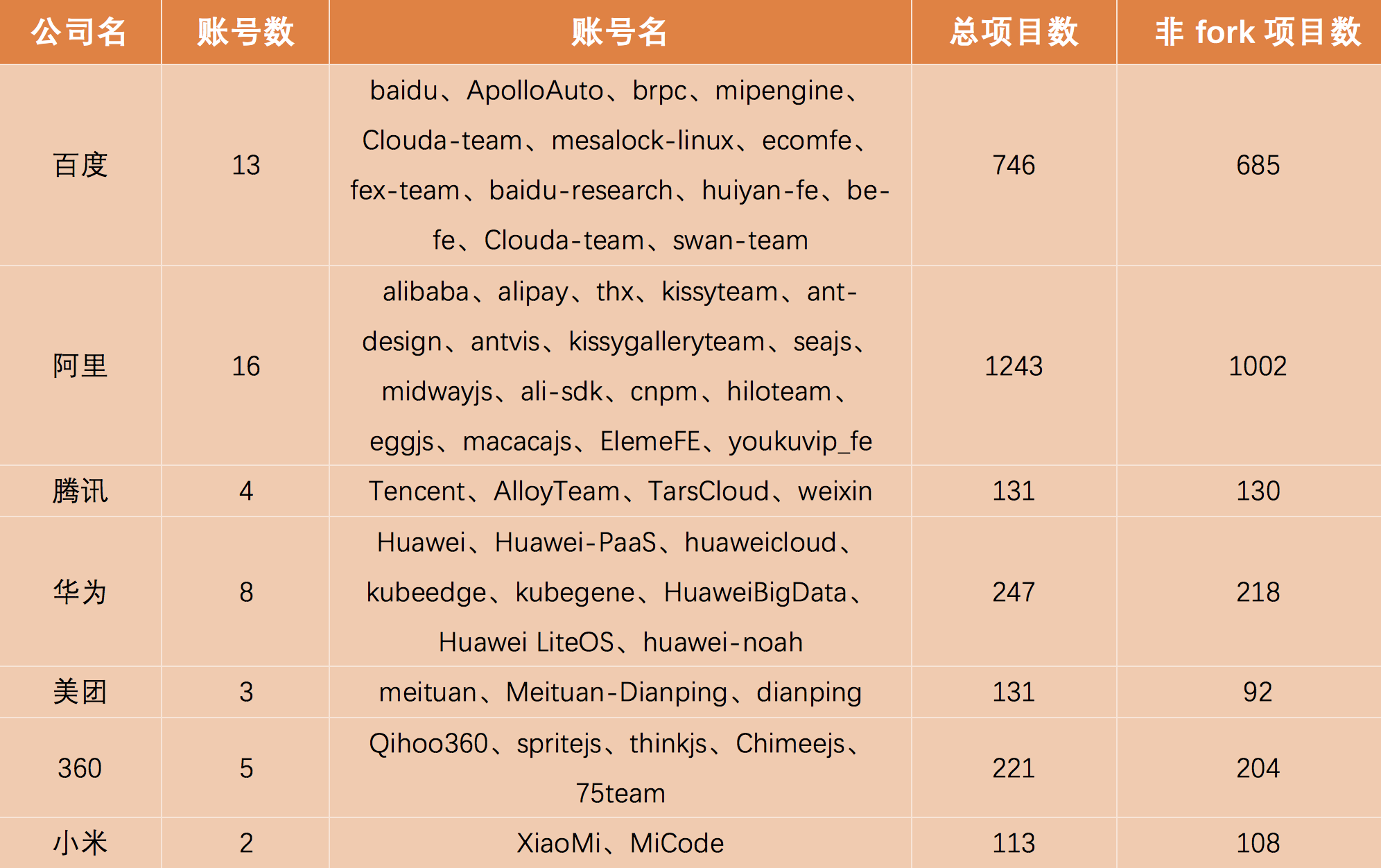
中国互联网公司开源项目调研报告
近年来,开源技术得到越来越多的重视,微软收购GitHub、IBM收购红帽,都表明了开源的价值。国内公司也越来越多的参与开源,加入开源基金会/贡献开源项目。但是,它们到底做得如何呢?为此InfoQ统计了国内在GitHu…

ReSharper 配置及用法
1:安装后,Resharper会用他自己的英文智能提示,替换掉 vs2010的智能提示,所以我们要换回到vs2010的智能提示 2:快捷键。是使用vs2010的快捷键还是使用 Resharper的快捷键呢?我是使用re的快捷键 3: Resharper安装后,会做…
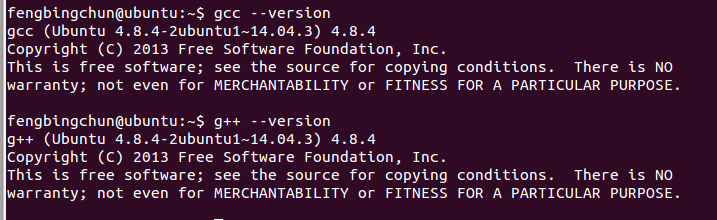
Ubuntu14.04 LTS中升级gcc/g++版本到4.9.4的操作步骤
Ubuntu14.04 LTS中默认的gcc/g版本为4.8.4,如下图,在C11中增加了对正则表达式的支持,但是好像到gcc/g 4.9.2版本才会对正则表达式能很好的支持,这里介绍下Ubuntu14.04 LTS升级gcc/g版本到4.9.4的操作步骤: 1࿰…

华为全球最快AI训练集群Atlas 900诞生
作者 | 胡巍巍来源 | CSDN(ID:CSDNnews)你,和计算有什么关系?早上,你打开手机App,查看天气预报,和计算有关;中午,你打开支付宝人脸支付,买了份宫保…
rabbitmq可靠发送的自动重试机制 --转
原贴地址 https://www.jianshu.com/p/6579e48d18ae https://www.jianshu.com/p/4112d78a8753 git项目代码地址 https://github.com/littlersmall/rabbitmq-access 转载于:https://www.cnblogs.com/hmpcly/p/10641688.html

在Linux下如何安装配置SVN服务
2019独角兽企业重金招聘Python工程师标准>>> Linux下在阿里云上架一个svn centos上安装:yum install subversion 安装成功 键入命令 svnserve --version 有版本信息则进行下一步 1、新建版本库目录 mkdir -p /opt/svndata/repos 2、设置此目录为…
201671030129 周婷 《英文文本统计分析》结对项目报告
项目内容这个作业属于哪个课程软件工程这个作业的要求在哪里软件工程结对项目课程学习目标熟悉软件开发整体流程及结对编程,提升自身能力本次作业在哪个具体方面帮助我们实现目标体验组队编程,体验一个完整的工程任务一: 作业所点评博客GetHu…
C++/C++11中std::string用法汇总
C/C11中std::string是个模板类,它是一个标准库。使用string类型必须首先包含<string>头文件。作为标准库的一部分,string定义在命名空间std中。std::string是C中的字符串。字符串对象是一种特殊类型的容器,专门设计来操作字符序列。str…
你在付费听《说好不哭》,我在这里免费看直播还送书 | CSDN新书发布会
周一的时候,我拖着疲惫的身体回到家中,躺倒床上刷刷朋友圈,什么?周杰伦出新歌了?朋友圈都是在分享周杰伦的新歌《说好不哭》,作为周杰伦的粉丝,我赶紧打开手机上的QQ音乐,准备去听&a…
解决Mysql:unrecognized service错误的方法(CentOS)附:修改用户名密码
2019独角兽企业重金招聘Python工程师标准>>> service mysql start出错,mysql启动不了,解决mysql: unrecognized service错误的方法如下: [rootctohome.com ~]# service mysql startmysql: unrecognized service [rootctohome.co…
Caffe源码中Net文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/net.hpp文件的内容:1. include文件:(1)、<caffe/blob.hpp>:此文件的介绍可以参考:http://blo…
满满干货的硬核技术沙龙,免费看直播还送书 | CSDN新书发布会
周一的时候,我拖着疲惫的身体回到家中,躺倒床上刷刷朋友圈,什么,周杰伦出新歌了?朋友圈都是在分享周杰伦的新歌《说好的不哭》,作为周杰伦的粉丝,我赶紧打开我手机上的QQ音乐,准备去…
【重磅上线】思维导图工具XMind:ZEN基础问题详解合集
XMind是XMind Ltd公司旗下一款出色的思维导图和头脑风暴软件。黑暗的UI设计、独特的ZEN模式、丰富的风格和主题、多分支的颜色等等功能会让你的工作更加便捷与高效。在视觉感官上也会给你带来最佳的体验感。 对于初学者来说,肯定会遇到各种各样的问题,有…

Linux内置的审计跟踪工具:last命令
这个命令是last。它对于追踪非常有用。让我们来看一下last可以为你做些什么。last命令的功能是什么last显示的是自/var/log/wtmp文件创建起所有登录(和登出)的用户。这个文件是二进制文件,它不能被文本编辑器浏览,比如vi、Joe或者其他软件。这是非常有用…
C++/C++11中std::set用法汇总
一个容器就是一些特定类型对象的集合。顺序容器(sequential container)为程序员提供了控制元素存储和访问顺序的能力。这种顺序不依赖于元素的值,而是与元素加入容器时的位置相对应。与之相对的,有序和无序关联容器,则根据关键字的值来存储元…

值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(下)
作者 | 黄浴来源 | 转载自知乎专栏自动驾驶的挑战和发展【导读】在近日发布的《值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(上)》一文中,作者介绍了一部分各大公司和机构基于激光雷达的目标检测所做的工作࿰…
java B2B2C源码电子商务平台 -commonservice-config配置服务搭建
2019独角兽企业重金招聘Python工程师标准>>> Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持。使用Config Server,您可以在所有环境中管理应用程序的外部属性。客户端和服务器上的概念映射与Spring Environment和PropertySource抽象…
Topshelf:一款非常好用的 Windows 服务开发框架
背景 多数系统都会涉及到“后台服务”的开发,一般是为了调度一些自动执行的任务或从队列中消费一些消息,开发 windows service 有一点不爽的是:调试麻烦,当然你还需要知道 windows service 相关的一些开发知识(也不难&…
C++中nothrow的介绍及使用
在C中,使用malloc等分配内存的函数时,一定要检查其返回值是否为”空指针”,并以此作为检查内存操作是否成功的依据,这种Test-for-NULL代码形式是一种良好的编程习惯,也是编写可靠程序所必需的。在C中new在申请内存失败…
你猜猜typeof (typeof 1) 会返回什么值(类型)?!
typeof typeof操作符返回一个字符串,表示未经计算的操作数的类型。 语法: var num a; console.log(typeof (num)); 或console.log(typeof num) 复制代码typeof 可以返回的类型为:number、string、boolean、undefined、null、object、functi…

阿里云智能运维的自动化三剑客
整理 | 王银出品 | AI科技大本营(ID:rgznai100)近日,2019 AI开发者大会在北京举行。会上,近百位中美顶尖AI专家、知名企业代表以及千余名AI开发者进行技术解读和产业论证。而在AIDevOps论坛上,阿里巴巴高级技术专家滕圣…