谷歌丰田联合成果ALBERT了解一下:新轻量版BERT,参数小18倍,性能依旧SOTA

【导读】这是来自Google和Toyota的新NLP模型,超越Bert,参数小了18倍。
你以前的NLP模型参数效率低下,而且有些过时。祝你有美好的一天。
谷歌Research和丰田技术研究所(Toyota Technological Institute)联合发布了一篇新论文,向全世界介绍了BERT的继任者——ALBERT。(“ALBERT:A Lite BERT for Self-supervised Learning of Language Representations”)。
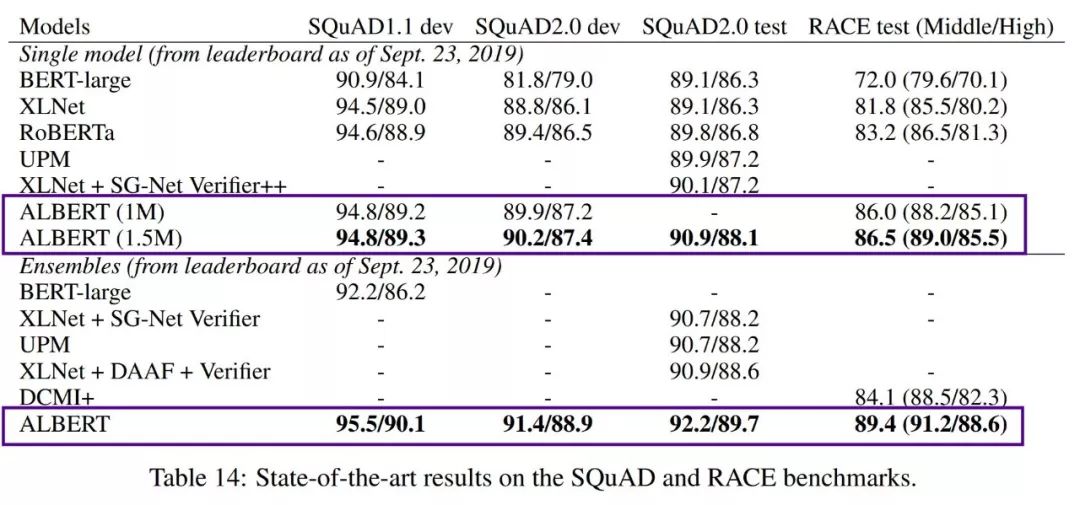
ALBERT在SQuAD和RACE测试上创造了新的SOTA,并在比赛中以+14.5%的优势击败BERT。
ALBERT的最终结果(为GLUE,RACE,SQuAD创造了新的SOTA)方面给人留下了深刻的印象,但是…真正令人惊讶的是模型/参数大小的显著减少。
两个关键架构的更改和一个训练更改的组合使ALBERT的表现都更好,并极大地减少了模型的大小。看看下面的模型大小的比较——BERT x-large有12.7亿个参数,而ALBERT x-large有5900万个参数!
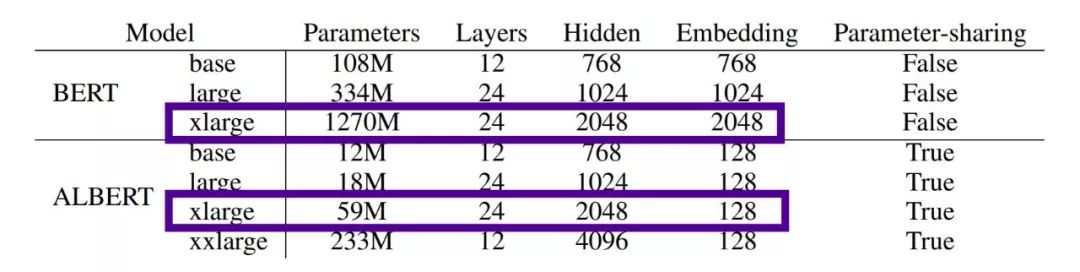
同样大小的网络(隐藏/层),BERT的参数是12.7亿,而ALBERT的参数是59M…缩小了~21.5x。
在这篇文章中有很多内容需要解释,我将尝试深入研究下面的所有重点。
对于NLP来说,更大的模型总是更好吗?不…
让我们从NLP的一个要点开始——过去的一年,NLP已经取得了进展,通过扩展transformer类型的模型,每一个较大的模型,通过简单地构建一个越来越大的预训练模型,逐步提高最终任务的准确性。在原始的BERT论文中,他们发现更大的隐藏尺寸、更多的隐藏层和更多的注意力头导致了渐进的改进,并测试了多达1024大小的隐藏层。
迄今为止最大的NLP模型是NVIDIA最近发布的Megatron,这是一个巨大的80亿参数模型,超过BERT的24倍,接近OpenAI的GPT-2的6倍。Megatron 在512个GPU的环境下接受了9天的训练。
然而,存在一个临界点或饱和点,即越大并不总是越好,ALBERT的作者表明,他们最大的模型BERT X-Large,隐藏层大小为2048以及4倍于原BERT large的参数,实际上性能下降了近20%。

越大并不总是越好——将隐藏层大小加倍,参数大小增加4倍,但是BERT在RACE数据集上的准确性降低了。
这类似于计算机视觉层深度的峰值效应。对计算机视觉来说,按比例增加层的深度可以提高到一定程度,然后下降。例如,ResNet -1000并不比ResNet152好,即使它有6.5倍数量的层。换句话说,存在一个饱和点,在这个点上,训练的复杂性压倒并降低了来自额外网络能力的收益。
因此,考虑到这一点,ALBERT的创造者开始改进架构和训练方法,以得到更好的结果,而不是仅仅构建一个“更大的BERT”。
什么是ALBERT?
ALBERT的核心架构类似于bert,因为它使用了transformer编码器架构,同时还有GELU激活。在论文中,他们也使用了与原BERT相同的30K的词汇量。(V = 30000)。然而,ALBERT做了三个重要的改变:
架构改进,更有效地使用参数:
1 — 嵌入分解参数化
ALBERT的作者注意到,对于BERT、XLNet和RoBERTa,WordPiece Embedding的大小(E)直接与隐含层大小(H)联系在一起。
然而,ALBERT的作者指出,WordPiece Embedding是用来学习上下文独立表示的。隐含层嵌入是为了学习上下文依赖表示的。
BERT的能力很大程度上依赖于通过隐藏层学习上下文相关的表示。如果你将H和E结合起来,并且NLP需要大V (vocab),那么你的嵌入矩阵E,实际上是V*E,必须与H(隐藏层)一起扩展,因此你最终得到的模型可以有数十亿个参数,但其中大多数在训练中很少更新。
因此,绑定在不同目的下工作的两个项目意味着低效的参数。
因此,将两者分开,可以更有效地使用参数,因此H(上下文相关)应该总是大于E(上下文无关)。
为此,ALBERT将嵌入参数分成两个更小的矩阵。因此,不是将独热向量直接投射到H中,而是将独热向量投射到一个更小、更低维的矩阵E中……然后投影到H隐藏空间。
因此,参数由大的O (V*H)简化为小的O (V*E + E*H)。
2 — 跨层参数共享
ALBERT通过跨层共享所有参数进一步提高了参数效率。这意味着前馈网络参数和注意力参数都是共享的。
因此,与BERT相比,ALBERT从一层到另一层的转换更平滑,作者注意到这种权值共享有助于稳定网络参数。
训练的变换 — SOP,句子顺序预测:
ALBERT确实使用了MLM(掩码语言模型),就像BERT一样,使用最多3个单词掩码(n-gram max 3)。
然而,BERT除了MLM,还使用了NSP,即下一句话预测。ALBERT开发了自己的训练方法,称为SOP。
为什么不用NSP?值得注意的是,RoBERTa的作者指出,原BERT中使用的下一个句子预测(NSP)损失不是非常有效,所以就不用了。ALBERT作者从理论上解释了为什么NSP不是那么有效,但是他们利用NSP开发了SOP -句子顺序预测。
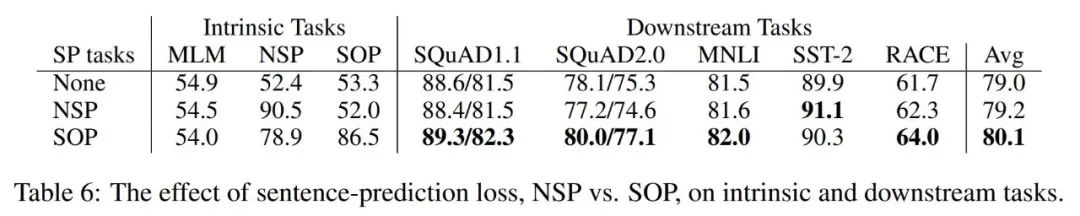
ALBERT认为,NSP(下一个句子预测)将话题预测和连贯预测混为一谈。作为参考,NSP使用了两个句子——正样本匹配是第二个句子来自同一个文档,负样本匹配是第二个句子来自另一个文档。
相比之下,ALBERT的作者认为句子间的连贯是真正需要关注的任务/损失,而不是主题预测,因此SOP是这样做的:
使用了两个句子,都来自同一个文档。正样本测试用例是这两句话的顺序是正确的。负样本是两个句子的顺序颠倒。
这避免了主题预测的问题,并帮助ALBERT学习更细粒度的语篇或句子间衔接。
当然,结果不言自明。
我们如何把ALBERT放大呢?
根据前面提到的关于扩展大小导致收益减小的注意事项,ALBERT的作者们进行了他们自己的ALBERT扩展测试,发现了层深度和宽度(隐藏大小)的峰值点。因此,作者推荐12层模型用于ALBERT风格的交叉参数共享。

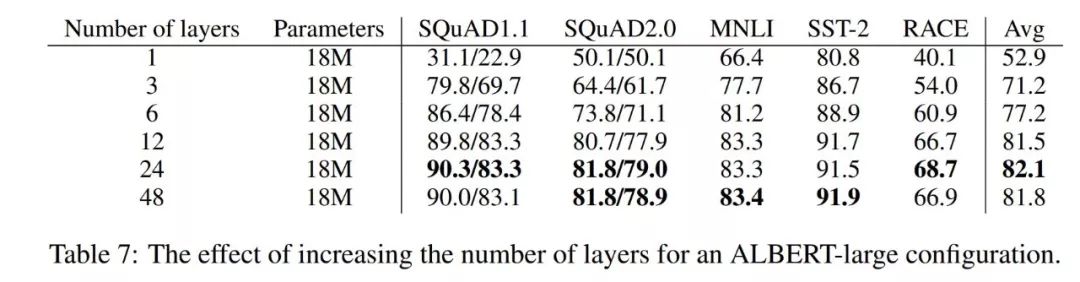
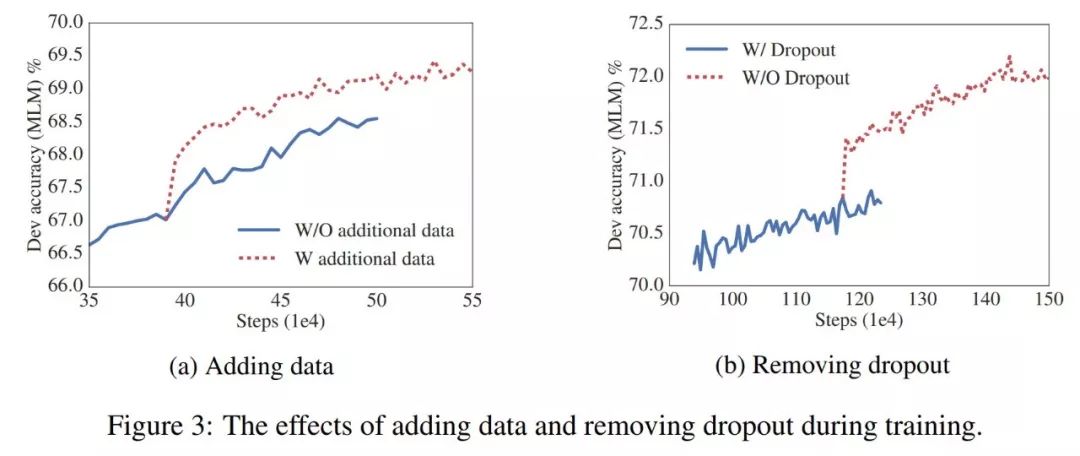
ALBERT发现删除dropout,增加数据可以提高性能:
这个非常符合计算机视觉已经发现的结论,ALBERT的作者报告说,不使用dropout得到了性能提升,当然,使用了更多的数据进行了训练。
总结
ALBERT在几个benchmarks上刷新了SOTA。这是一个惊人的突破,它建立在一年前BERT所做的伟大工作上,并在多个方面推进了NLP。尤其令人振奋的是,人工智能的未来不仅基于添加更多的GPU和简单地构建更大的训练模型,而且还将从改进的架构和参数效率方面取得进展。
作者指出,ALBERT未来的工作是提高其计算效率,可能是通过分散注意力或分块注意力。因此,希望在未来更多的来自ALBERT的进展 !
Github和ALBERT的官方来源?我找不到ALBERT的官方版本发布到github,或者通过开源方式发布,这篇文章也没有提到。希望在不久的将来能够实现。
非官方的TensorFlow版本:https://github.com/brightmart/albert_zh?source=post_page-----df8f7b58fa28----------------------
论文链接:https://arxiv.org/abs/1909.11942v1
英文原文:
https://medium.com/@lessw/meet-albert-a-new-lite-bert-from-google-toyota-with-state-of-the-art-nlp-performance-and-18x-df8f7b58fa28
◆
精彩推荐
◆

推荐阅读
大规模1.4亿中文知识图谱数据,我把它开源了
快速适应性很重要,但不是元学习的全部目标
太鸡冻了!我用Python偷偷查到暗恋女生的名字
刷爆了!GitHub标星1.6W,这个Python项目太实用!
巨头垂涎却不能染指,loT 数据库风口已至
【建议收藏】数据中心服务器基础知识大全
从4个维度深度剖析闪电网络现状,在CKB上实现闪电网络的理由 | 博文精选
2019 年诺贝尔物理学奖揭晓!三得主让宇宙“彻底改观”
不服!身边程序员同事竟说自己敲代码速度快!Ctrl+C、Ctrl+V ?

你点的每个“在看”,我都认真当成了AI
相关文章:

C++中extern C的使用
C程序有时需要调用其它语言编写的函数,最常见的是调用C语言编写的函数。像所有其它名字一样,其它语言中的函数名字也必须在C中进行声明,并且该声明必须指定返回类型和形参列表。对于其它语言编写的函数来说,编译器检查…
Linux之tmpwatch命令
1、tmpwatch命令功能简介[rootvms002 /]# whatis tmpwatch tmpwatch (8) - removes files which havent been accessed for a period of... #删除一段时间内未被访问的文件tmpwatch删除最近一段时间内没有被访问的文件,时间以小时为单位,节省磁盘空间。…

你不得不知道的Visual Studio 2012(1)- 每日必用功能
2019独角兽企业重金招聘Python工程师标准>>> Visual Studio 2012已经正式发布,有很多花哨的新特性,也有很多方便使用者的新功能,当然也有负面声音。对于我们程序员,最关心的还是如何快速掌握VS2012,用于平时…
C++11中std::unique_lock的使用
std::unique_lock为锁管理模板类,是对通用mutex的封装。std::unique_lock对象以独占所有权的方式(unique owership)管理mutex对象的上锁和解锁操作,即在unique_lock对象的声明周期内,它所管理的锁对象会一直保持上锁状态;而unique…
为何Google将几十亿行源代码放在一个仓库?| CSDN博文精选
作者 | Rachel Potvin,Josh Levenberg译者 | 张建军编辑 | apddd【AI科技大本营导读】与大多数开发者的想象不同,Google只有一个代码仓库——全公司使用不同语言编写的超过10亿文件,近百TB源代码都存放在自行开发的版本管理系统Piper中&#…
小小hanoi
为什么80%的码农都做不了架构师?>>> View Code #include " iostream " using namespace std; int k 0 ; void hanoi( int m , char a , char b, char c){ if (m 1 ) { k ; printf( " %c->%c " ,a , c); return…
Unity3D心得分享
本篇文章的内容以各种tips为主,不间断更新 2019/05/10 最近更新: 使用Instantiate初始化参数去实例对象 Unity DEMO学习 Unity3D Adam Demo的学习与研究 Unity3D The Blacksmith Demo部分内容学习 Viking Village维京村落demo中的地面积水效果 Viking V…
django搭建示例-ubantu环境
python3安装--------------------------------------------------------------------------- 最新的django依赖python3,同时ubantu系统默认自带python2与python3,这里单独安装一套python3,并且不影响原来的python环境 django demo使用sqlite3,…
C++11中std::lock_guard的使用
互斥类的最重要成员函数是lock()和unlock()。在进入临界区时,执行lock()加锁操作,如果这时已经被其它线程锁住,则当前线程在此排队等待。退出临界区时,执行unlock()解锁操作。更好的办法是采用”资源分配时初始化”(RAII)方法来加…
OpenAI机械手单手轻松解魔方,背靠强化学习+新技术ADR
编译 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】10月15日,人工智能研究机构OpenAI发布了一条机械手单手解魔方的视频。这个自学式的类人机器人手臂名为 Dactyl,不仅可以单手解魔方,甚至能在外加各种干扰&#x…
AMD and CMD are dead之js模块化黑魔法
缘由 在2013-03-06 13:58的时候,曾甩下一片文章叫:《为什么不使用requirejs和seajs》,并放下豪言说发布一款完美的模块化库,再后来就把那篇文章删了,再然后就没有然后。该用seajs还用seajs,甚至我码的SCJ都…
一文了解Python常见的序列化操作
关于我 编程界的一名小小程序猿,目前在一个创业团队任team lead,技术栈涉及Android、Python、Java和Go,这个也是我们团队的主要技术栈。 联系:hylinux1024gmail.com 0x00 marshal marshal使用的是与Python语言相关但与机器无关的二…
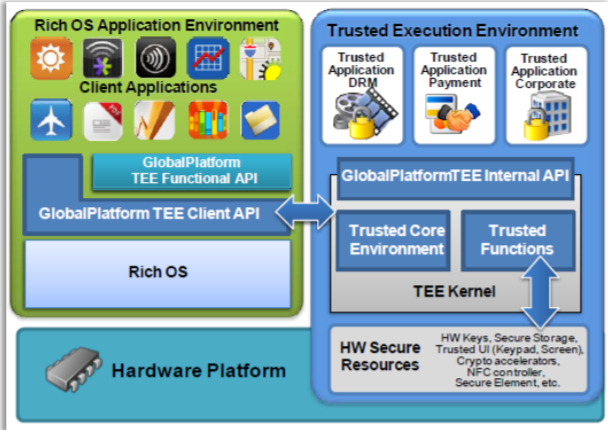
TEE(Trusted Execution Environment)简介
TEE(Trusted Execution Environment),可信执行环境,该环境可以保证不被常规操作系统干扰的计算,因此称为”可信”。这是通过创建一个可以在TrustZone的”安全世界”中独立运行的小型操作系统实现的,该操作系统以系统调用(由TrustZ…
自动驾驶关键环节:行人的行为意图建模和预测(上)
作者 | 黄浴出品 | AI科技大本营(ID:rgznai100)【导读】介绍一下最近行人行为意图建模和预测的研究工作,还是分上下两部分,本文为上半部分。Social LSTM: Human Trajectory Prediction in Crowded Spaces比较早的是斯坦福大学 201…

自定义windows下自动清除文件夹或者文件的只读属性的脚本
脚本内容入下:其中脚本中 ”/d"作用 (可以用来改变当前驱动器目录)例如: 我现在是在D盘,现在我要切换到C:\windows目录 脚本参数中 ATTRIB -R /S /D 解释内容如下:(上述脚本参数中的 cd …
C++11容器中新增加的emplace相关函数的使用
C11中,针对顺序容器(如vector、deque、list),新标准引入了三个新成员:emplace_front、emplace和emplace_back,这些操作构造而不是拷贝元素。这些操作分别对应push_front、insert和push_back,允许我们将元素放置在容器头…
Silverlight+WCF 新手实例 象棋 主界面-棋谱-获取列表(三十八)
2019独角兽企业重金招聘Python工程师标准>>> 在线演示地址:SilverlightWCF 新手实例 象棋 在线演示 在SilverlightWCF 新手实例 象棋 主界面-棋谱-布局写谱(三十六)中,我们完成下棋双方的棋谱显示,这节,我们为观众增加…
确认!语音识别大牛Daniel Povey将入职小米,曾遭霍普金斯大学解雇,怒拒Facebook
整理 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 【导读】10 月 17 日,语音界传奇 Daniel Povey 发布推特,宣布自己 2019 年末将要入职小米,目前正在签订合同阶段,入职后,他将带领一支团队研发…
软链接与硬链接
$ ln f1 f2 #创建f1的一个硬连接文件f2$ ln -s f1 f3 #创建f1的一个符号连接文件f3$ ls -li # -i参数显示文件的inode节点信息转载于:https://www.cnblogs.com/zhizouxiao/p/3794668.html
一文读懂Python复杂网络分析库networkx | CSDN博文精选
作者 | yyl424525来源 | CSDN博客文章目录1. 简介安装支持四种图绘制网络图基本流程2. Graph-无向图节点边属性有向图和无向图互转3. DiGraph-有向图一些精美的图例子环形树状图权重图Giant ComponentRandom Geometric Graph 随机几何图节点颜色渐变边的颜色渐变Atlas画个五角星…
C++11多线程中std::call_once的使用
C11中的std::call_once函数位于<mutex>头文件中。在多线程编程中,有时某个任务只需要执行一次,此时可以用C11中的std::call_once函数配合std::once_flag来实现。如果多个线程需要同时调用某个函数,std::call_once可以保证多个线程对该函…
Solaris 上网配置
2019独角兽企业重金招聘Python工程师标准>>> 早上装solaris10系统的时候,没选默认,选了desk-session模式安装。全英文无界面安装,中间还跑出几个乱码。 靠着随便选随便F2,终于安装完了。 就在那设完分辨率后࿰…
Configure,Makefile.am, Makefile.in, Makefile文件之间关系
为什么80%的码农都做不了架构师?>>> 1.autoscan (autoconf): 扫描源代码以搜寻普通的可移植性问题,比如检查编译器,库,头文件等,生成文件configure.scan,它是configure.ac的一个雏形。 your source files…

这款耳机一点不输千元级的AirPods
你如果问我:生活中你觉得必不可少的一件电子产品是什么?那么我会毫不犹豫的回答你:是耳机!出门忘带耳机是绝对不能忍听不听没关系,但是有它比较安心我觉得生活中不仅是我很多人都对耳机有一种依赖因为很多人都喜欢音乐…

CUDA Samples: Image Process: BGR to Gray
在图像处理中,颜色变换BGR到Gray,常见的一般有两种计算方式,一种是基于浮点数计算,一种是基于性能优化的通过移位的整数计算。浮点数计算公式为: gray 0.1140 * B 0.5870 * G 0.2989 * R;整数计算公式为࿱…
CYQ.Data 数据框架系列索引
2019独角兽企业重金招聘Python工程师标准>>> 索引基础导航: 1:下载地址:http://www.cyqdata.com/download/article-detail-426 2:入门教程:http://www.cyqdata.com/cyqdata/article-cate-33 3:购…
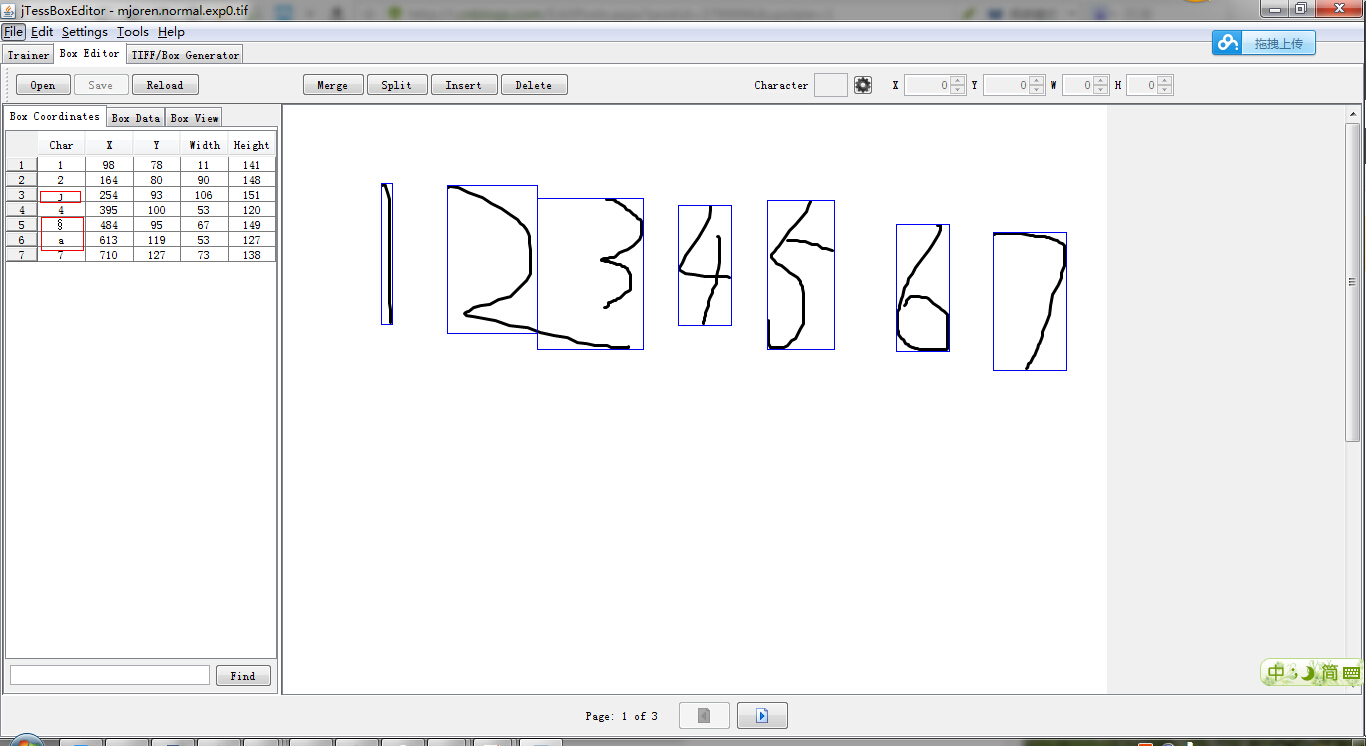
Tesseract 3 语言数据的训练方法
OCR,光学字符识别 光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可以快速的将纸质资料…
Windows C++中__declspec(dllexport)的使用
__declspec是Microsoft VC中专用的关键字,它配合着一些属性可以对标准C/C进行扩充。__declspec关键字应该出现在声明的前面。 __declspec(dllexport)用于Windows中的动态库中,声明导出函数、类、对象等供外面调用,省略给出.def文件。即将函数…
图灵奖得主LeCun力推无监督学习:要重视基于能量的学习方法
作者 | Tiernan Ray译者 | 夕颜出品 | AI科技大本营(ID:rgznai100)导语:图灵奖得主深度学习大牛 Yann LeCun 表示,人工智能的下一个发展方向可能是放弃深度学习的所有概率技巧,转而掌握一系列转移能量值的方法。据说&a…
html5小游戏Untangle
2019独角兽企业重金招聘Python工程师标准>>> 今天介绍一个HTML5的小游戏,让大家体验到HTML5带来的乐趣。这个小游戏很简单,只要用鼠标拖动 蓝点,让图上的所有线都不相交,游戏时间就会停止,是动用大家头脑的…