CUDA Samples: Image Process: BGR to Gray
在图像处理中,颜色变换BGR到Gray,常见的一般有两种计算方式,一种是基于浮点数计算,一种是基于性能优化的通过移位的整数计算。
浮点数计算公式为: gray = 0.1140 * B + 0.5870 * G + 0.2989 * R;
整数计算公式为: gray = (1868 * B + 9617 * G + 4899 * R) >> 14.
这里与OpenCV的实现方式一致,采用整数计算公式。
以下分别是C++和CUDA的BGR到Gray的实现测试代码:
bgr2gray.cpp:
#include "funset.hpp"
#include <chrono>
#include "common.hpp"int bgr2gray_cpu(const unsigned char* src, int width, int height, unsigned char* dst, float* elapsed_time)
{TIME_START_CPUconst int R2Y{ 4899 }, G2Y{ 9617 }, B2Y{ 1868 }, yuv_shift{ 14 };for (int y = 0; y < height; ++y) {for (int x = 0; x < width; ++x) {dst[y * width + x] = (unsigned char)((src[y*width * 3 + 3 * x + 0] * B2Y +src[y*width * 3 + 3 * x + 1] * G2Y + src[y*width * 3 + 3 * x + 2] * R2Y) >> yuv_shift);}}TIME_END_CPUreturn 0;
}#include "funset.hpp"
#include <iostream>
#include <chrono>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include "common.hpp"/* __global__: 函数类型限定符;在设备上运行;在主机端调用,计算能力3.2及以上可以在
设备端调用;声明的函数的返回值必须是void类型;对此类型函数的调用是异步的,即在
设备完全完成它的运行之前就返回了;对此类型函数的调用必须指定执行配置,即用于在
设备上执行函数时的grid和block的维度,以及相关的流(即插入<<< >>>运算符);
a kernel,表示此函数为内核函数(运行在GPU上的CUDA并行计算函数称为kernel(内核函
数),内核函数必须通过__global__函数类型限定符定义);*/
__global__ static void bgr2gray(const unsigned char* src, int B2Y, int G2Y, int R2Y, int shift, int width, int height, unsigned char* dst)
{/* gridDim: 内置变量,用于描述线程网格的维度,对于所有线程块来说,这个变量是一个常数,用来保存线程格每一维的大小,即每个线程格中线程块的数量.一个grid为三维,为dim3类型;blockDim: 内置变量,用于说明每个block的维度与尺寸.为dim3类型,包含了block在三个维度上的尺寸信息;对于所有线程块来说,这个变量是一个常数,保存的是线程块中每一维的线程数量;blockIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程块的索引;用于说明当前thread所在的block在整个grid中的位置,blockIdx.x取值范围是[0,gridDim.x-1],blockIdx.y取值范围是[0, gridDim.y-1].为uint3类型,包含了一个block在grid中各个维度上的索引信息;threadIdx: 内置变量,变量中包含的值就是当前执行设备代码的线程索引;用于说明当前thread在block中的位置;如果线程是一维的可获取threadIdx.x,如果是二维的还可获取threadIdx.y,如果是三维的还可获取threadIdx.z;为uint3类型,包含了一个thread在block中各个维度的索引信息 */int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;//if (x == 0 && y == 0) {// printf("%d, %d, %d, %d, %d, %d\n", width, height, B2Y, G2Y, R2Y, shift);//}if (x < width && y < height) {dst[y * width + x] = (unsigned char)((src[y*width * 3 + 3 * x + 0] * B2Y +src[y*width * 3 + 3 * x + 1] * G2Y + src[y*width * 3 + 3 * x + 2] * R2Y) >> shift);}
}int bgr2gray_gpu(const unsigned char* src, int width, int height, unsigned char* dst, float* elapsed_time)
{const int R2Y{ 4899 }, G2Y{ 9617 }, B2Y{ 1868 }, yuv_shift{ 14 };unsigned char *dev_src{ nullptr }, *dev_dst{ nullptr };// cudaMalloc: 在设备端分配内存cudaMalloc(&dev_src, width * height * 3 * sizeof(unsigned char));cudaMalloc(&dev_dst, width * height * sizeof(unsigned char));/* cudaMemcpy: 在主机端和设备端拷贝数据,此函数第四个参数仅能是下面之一:(1). cudaMemcpyHostToHost: 拷贝数据从主机端到主机端(2). cudaMemcpyHostToDevice: 拷贝数据从主机端到设备端(3). cudaMemcpyDeviceToHost: 拷贝数据从设备端到主机端(4). cudaMemcpyDeviceToDevice: 拷贝数据从设备端到设备端(5). cudaMemcpyDefault: 从指针值自动推断拷贝数据方向,需要支持统一虚拟寻址(CUDA6.0及以上版本)cudaMemcpy函数对于主机是同步的 */cudaMemcpy(dev_src, src, width * height * 3 * sizeof(unsigned char), cudaMemcpyHostToDevice);/* cudaMemset: 存储器初始化函数,在GPU内存上执行。用指定的值初始化或设置设备内存 */cudaMemset(dev_dst, 0, width * height * sizeof(unsigned char));TIME_START_GPU/* dim3: 基于uint3定义的内置矢量类型,相当于由3个unsigned int类型组成的结构体,可表示一个三维数组,在定义dim3类型变量时,凡是没有赋值的元素都会被赋予默认值1 */// Note:每一个线程块支持的最大线程数量为1024,即threads.x*threads.y必须小于等于1024dim3 threads(32, 32);dim3 blocks((width + 31) / 32, (height + 31) / 32);/* <<< >>>: 为CUDA引入的运算符,指定线程网格和线程块维度等,传递执行参数给CUDA编译器和运行时系统,用于说明内核函数中的线程数量,以及线程是如何组织的;尖括号中这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码,传递给设备代码本身的参数是放在圆括号中传递的,就像标准的函数调用一样;不同计算能力的设备对线程的总数和组织方式有不同的约束;必须先为kernel中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界等 ;使用运行时API时,需要在调用的内核函数名与参数列表直接以<<<Dg,Db,Ns,S>>>的形式设置执行配置,其中:Dg是一个dim3型变量,用于设置grid的维度和各个维度上的尺寸.设置好Dg后,grid中将有Dg.x*Dg.y*Dg.z个block;Db是一个dim3型变量,用于设置block的维度和各个维度上的尺寸.设置好Db后,每个block中将有Db.x*Db.y*Db.z个thread;Ns是一个size_t型变量,指定各块为此调用动态分配的共享存储器大小,这些动态分配的存储器可供声明为外部数组(extern __shared__)的其他任何变量使用;Ns是一个可选参数,默认值为0;S为cudaStream_t类型,用于设置与内核函数关联的流.S是一个可选参数,默认值0. */// Note: 核函数不支持传入参数为vector的data()指针,需要cudaMalloc和cudaMemcpy,因为vector是在主机内存中bgr2gray << <blocks, threads >> >(dev_src, B2Y, G2Y, R2Y, yuv_shift, width, height, dev_dst);/* cudaDeviceSynchronize: kernel的启动是异步的, 为了定位它是否出错, 一般需要加上cudaDeviceSynchronize函数进行同步; 将会一直处于阻塞状态,直到前面所有请求的任务已经被全部执行完毕,如果前面执行的某个任务失败,将会返回一个错误;当程序中有多个流,并且流之间在某一点需要通信时,那就必须在这一点处加上同步的语句,即cudaDeviceSynchronize;异步启动reference: https://stackoverflow.com/questions/11888772/when-to-call-cudadevicesynchronize */cudaDeviceSynchronize();TIME_END_GPUcudaMemcpy(dst, dev_dst, width * height * sizeof(unsigned char), cudaMemcpyDeviceToHost);// cudaFree: 释放设备上由cudaMalloc函数分配的内存cudaFree(dev_dst);cudaFree(dev_src);return 0;
}#include "funset.hpp"
#include <random>
#include <iostream>
#include <vector>
#include <memory>
#include <string>
#include <algorithm>
#include "common.hpp"int test_image_process_bgr2gray()
{const std::string image_name{ "E:/GitCode/CUDA_Test/test_data/images/lena.png" };cv::Mat mat = cv::imread(image_name);CHECK(mat.data);const int width{ 1513 }, height{ 1473 };cv::resize(mat, mat, cv::Size(width, height));std::unique_ptr<unsigned char[]> data1(new unsigned char[width * height]), data2(new unsigned char[width * height]);float elapsed_time1{ 0.f }, elapsed_time2{ 0.f }; // millisecondsCHECK(bgr2gray_cpu(mat.data, width, height, data1.get(), &elapsed_time1) == 0);CHECK(bgr2gray_gpu(mat.data, width, height, data2.get(), &elapsed_time2) == 0);cv::Mat dst(height, width, CV_8UC1, data1.get());cv::imwrite("E:/GitCode/CUDA_Test/test_data/images/bgr2gray_cpu.png", dst);cv::Mat dst2(height, width, CV_8UC1, data2.get());cv::imwrite("E:/GitCode/CUDA_Test/test_data/images/bgr2gray_gpu.png", dst2);fprintf(stdout, "image bgr to gray: cpu run time: %f ms, gpu run time: %f ms\n", elapsed_time1, elapsed_time2);CHECK(compare_result(data1.get(), data2.get(), width*height) == 0);return 0;
}
GitHub: https://github.com/fengbingchun/CUDA_Test
相关文章:

CYQ.Data 数据框架系列索引
2019独角兽企业重金招聘Python工程师标准>>> 索引基础导航: 1:下载地址:http://www.cyqdata.com/download/article-detail-426 2:入门教程:http://www.cyqdata.com/cyqdata/article-cate-33 3:购…
Tesseract 3 语言数据的训练方法
OCR,光学字符识别 光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可以快速的将纸质资料…

Windows C++中__declspec(dllexport)的使用
__declspec是Microsoft VC中专用的关键字,它配合着一些属性可以对标准C/C进行扩充。__declspec关键字应该出现在声明的前面。 __declspec(dllexport)用于Windows中的动态库中,声明导出函数、类、对象等供外面调用,省略给出.def文件。即将函数…

图灵奖得主LeCun力推无监督学习:要重视基于能量的学习方法
作者 | Tiernan Ray译者 | 夕颜出品 | AI科技大本营(ID:rgznai100)导语:图灵奖得主深度学习大牛 Yann LeCun 表示,人工智能的下一个发展方向可能是放弃深度学习的所有概率技巧,转而掌握一系列转移能量值的方法。据说&a…
html5小游戏Untangle
2019独角兽企业重金招聘Python工程师标准>>> 今天介绍一个HTML5的小游戏,让大家体验到HTML5带来的乐趣。这个小游戏很简单,只要用鼠标拖动 蓝点,让图上的所有线都不相交,游戏时间就会停止,是动用大家头脑的…

【VMCloud云平台】SCCM(四)域内推送代理
继上一篇云平台完成SCCM部署篇之后,SCCM篇正式开始,今天将开始介绍SCCM为域内机器推送代理(紫色为完成实施,红色为实施中): 1、 点击站点: 2、 右键属性,点击客户端安装设置&#…
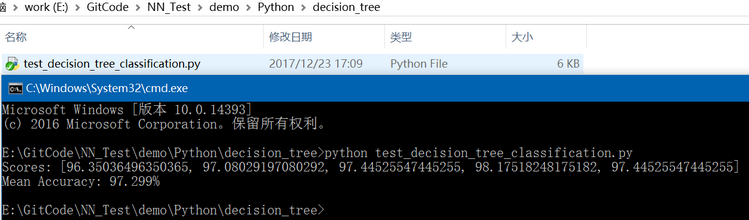
Python实现决策树(Decision Tree)分类
关于决策树的简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78880934在 https://machinelearningmastery.com/implement-decision-tree-algorithm-scratch-python/ 中给出了CART(Classification and Regression Trees,分类回归树算法,简称CART…

顶尖技术专家严选,15场前沿论坛思辨,2019中国大数据技术大会邀您共赴
扫码了解2019中国大数据技术大会(https://t.csdnimg.cn/IaHb)更多详情。2019中国大数据技术大会(BDTC 2019)将于12月5日-7日在北京长城饭店举办,本届大会将聚焦智能时代,大数据技术的发展曲线以及大数据与社…
jQuery 加法计算 使用+号即强转类型
1 var value1 $("#txt1").val(); 2 var value2 $("#txt2").val(); 3 //数值前添加号 number加号和数值加号需要用空格隔开 即实现加法运算 4 $("#txt3").val(value1 value2); 转载于:https://www.cnblogs.com/xiemin-minmin/p/11026784.…

Android Volley 库通过网络获取 JSON 数据
本文内容 什么是 Volley 库 Volley 能做什么 Volley 架构 环境 演示 Volley 库通过网络获取 JSON 数据 参考资料 Android 关于网络操作一般都会介绍 HttpClient 以及 HttpConnection 这两个包。前者是 Apache 开源库,后者是 Android 自带 API。企业级应用࿰…
哪些开发问题最让程序员“头秃”?我们分析了Stack Overflow的11000个问题
作者 | Nick Roberts编译 | AI科技大本营(ID:rgznai100)自 2008 年成立以来,Stack Overflow 一直在拯救所有类型的开发人员。自那时以来,开发人员提出了数百万个关于开发领域的问题。但是,迫使开发者转向 Stack Overfl…

OpenCV3.3中决策树(Decision Tree)接口简介及使用
OpenCV 3.3中给出了决策树Decision Tres算法的实现,即cv::ml::DTrees类,此类的声明在include/opencv2/ml.hpp文件中,实现在modules/ml/src/tree.cpp文件中。其中:(1)、cv::ml::DTrees类:继承自cv::ml::StateModel&…
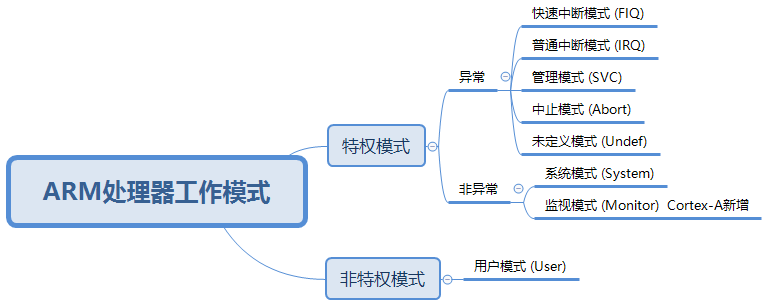
ARM 寄存器 和 工作模式了解
一. ARM 工作模式 1. ARM7,ARM9,ARM11,处理器有 7 种工作模式;Cortex-A 多了一个监视模式(Monitor) 2. 用户模式:非特权模式,大部分任务执行在这种模式,它运行在操作系…
英文版PDF不能显示中文PDF文件的解决方法
首先,PDF如果是英文版本的话,先装一个与之对应的PDF中文包。装上之后要检查的两项:1、PDF本身打开Adobe pdf选择“edit”"Preference""Internet"将"internet"下的三个勾全部勾上"OK"2、IE设置打开IE…
Linux下__attribute__((visibility (default)))的使用
在Linux下动态库(.so)中,通过GCC的C visibility属性可以控制共享文件导出符号。在GCC 4.0及以上版本中,有个visibility属性,可见属性可以应用到函数、变量、模板以及C类。 限制符号可见性的原因:从动态库中尽可能少地输出符号是一…
java web学习项目20套源码完整版
java web学习项目20套源码完整版 自己收集的各行各业的都有,这一套源码吃遍所有作业项目! 1、BBS论坛系统(jspsql)2、ERP管理系统(jspservlet)3、OA办公自动化管理系统(Struts1.2Hibernate3.0Spring2DWR)4、…

360金融携手上海交大共建AI实验室,开启人才战略新布局
10月16日,上海交通大学计算机科学系—360金融人工智能联合实验室成立仪式在上海交通大学闵行校区举行,联合实验室致力于AI技术在新金融领域的应用探索。成立仪式上,360金融CEO吴海生宣布了“未来科学家”计划,这是360金融在人工智…
wxWidgets刚開始学习的人导引(3)——wxWidgets应用程序初体验
wxWidgets刚開始学习的人导引全文件夹 PDF版及附件下载1 前言2 下载、安装wxWidgets3 wxWidgets应用程序初体验4 wxWidgets学习资料及利用方法指导5 用wxSmith进行可视化设计附:学习材料清单3 wxWidgets应用程序初体验本文中全部的体验,在Code::Blocks…
C++中extern的使用
在C中,extern主要有两个作用:(1)、extern声明一个变量或函数;(2)、extern与”C”一起连用,用于链接指定。关于extern “C”的使用可以参考: http://blog.csdn.net/fengbingchun/article/details/78634831 ,…
Python识别文字,实现看图说话 | CSDN博文精选
作者 | 张小腿来源 | CSDN博客现在写文件很多网站都不让复制了,所以每次都是截图然后发到QQ上然后用手机QQ的文字识别再发回电脑。感觉有点小麻烦了,所以想自己写一个小软件方便方便自己,就有了这篇了:首先语言是Python࿰…
Oracle Hints具体解释
在向大家具体介绍Oracle Hints之前,首先让大家了解下Oracle Hints是什么,然后全面介绍Oracle Hints,希望对大家实用。基于代价的优化器是非常聪明的,在绝大多数情况下它会选择正确的优化器,减轻了DBA的负担。但有时它也…
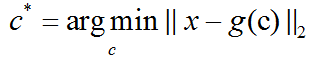
主成分分析(PCA)简介
主成分分析(Principal Components Analysis, PCA)是一个简单的机器学习算法,可以通过基础的线性代数知识推导。假设在Rn空间中我们有m个点{x(1),…,x(m)},我们希望对这些点进行有损压缩。有损压缩表示我们使用更少的内存,但损失一些精度去存储…
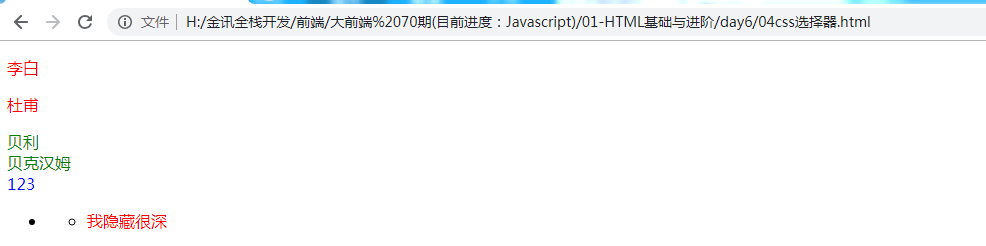
01-HTML基础与进阶-day6-录像281
04css选择器.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Document</title><style type"text/css">/* p div 标签选择器*/p {color: red; /* k:v color表示样式属性 颜…
百度CTO王海峰:深度学习如何大规模产业化?
编者按:10月17日-19日,2019年中国计算机大会(CNCC2019)在苏州举办。百度首席技术官王海峰在会上发表题为《深度学习平台支撑产业智能化》的演讲,分享了百度关于深度学习技术推动人工智能发展及产业化应用的思考。以下为…
Kali Linux***测试
Kali Linux***测试实战 第一章http://drops.wooyun.org/tips/826 1.1 Kali Linux简介如果您之前使用过或者了解BackTrack系列Linux的话,那么我只需要简单的说,Kali是BackTrack的升级换代产品,从Kali开始,BackTrack将成为历史。如果…
一站式解决:隐马尔可夫模型(HMM)全过程推导及实现
作者 | 永远在你身后转载自知乎用户永远在你身后【导读】隐马尔可夫模型(Hidden Markov Model,HMM)是关于时许的概率模型,是一个生成模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态序列,每个状态生…

CUDA Samples: Image Process: BGR to BGR565
图像像素格式BGR565是每一个像素占2个字节,其中Blue占5位,Green占6位,Red占5位。在OpenCV中,BGR到BGR565的每一个像素的计算公式是:unsigned short dst (unsigned short)((B >> 3) | ((G & ~3) << 3)…
NoSQL数据库探讨 - 为什么要用非关系数据库?
源地址:http://robbin.javaeye.com/blog/524977 随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。而传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类…
手机内存RAM、ROM简介
手机内存包含两个:一个是运行内存(RAM),一个是机身内存(ROM)。两者的功能有所不同,运行内存是对手机操作系统和其它程序运行过程中,产生的临时数据进行存储的媒介。如果手机运行的程序比较多,占用运行内存空间较大&…

一个月入门Python爬虫,轻松爬取大规模数据
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样一个月入门Python爬虫,轻松爬的编程语言提供越来越多的优秀工具&#x…