OpenCV3.3中决策树(Decision Tree)接口简介及使用
OpenCV 3.3中给出了决策树Decision Tres算法的实现,即cv::ml::DTrees类,此类的声明在include/opencv2/ml.hpp文件中,实现在modules/ml/src/tree.cpp文件中。其中:
(1)、cv::ml::DTrees类:继承自cv::ml::StateModel,而cv::ml::StateModel又继承自cv::Algorithm;
(2)、create函数:为static,new一个DTreesImpl对象用来创建一个DTrees对象;
(3)、setMaxCategories/getMaxCategories函数:设置/获取最大的类别数,默认值为10;
(4)、setMaxDepth/getMaxDepth函数:设置/获取树的最大深度,默认值为INT_MAX;
(5)、setMinSampleCount/getMinSampleCount函数:设置/获取最小训练样本数,默认值为10;
(6)、setCVFolds/getCVFolds函数:设置/获取CVFolds(thenumber of cross-validation folds)值,默认值为10,如果此值大于1,用于修剪构建的决策树;
(7)、setUseSurrogates/getUseSurrogates函数:设置/获取是否使用surrogatesplits方法,默认值为false;
(8)、setUse1SERule/getUse1SERule函数:设置/获取是否使用1-SE规则,默认值为true;
(9)、setTruncatePrunedTree/getTruncatedTree函数:设置/获取是否进行剪枝后移除操作,默认值为true;
(10)、setRegressionAccuracy/getRegressionAccuracy函数:设置/获取回归时用于终止的标准,默认值为0.01;
(11)、setPriors/getPriors函数:设置/获取先验概率数值,用于调整决策树的偏好,默认值为空的Mat;
(12)、getRoots函数:获取根节点索引;
(13)、getNodes函数:获取所有节点索引;
(14)、getSplits函数:获取所有拆分索引;
(15)、getSubsets函数:获取分类拆分的所有bitsets;
(16)、load函数:load已序列化的model文件。
关于决策树算法的简介可以参考:http://blog.csdn.net/fengbingchun/article/details/78880934
以下是从数据集MNIST中提取的40幅图像,0,1,2,3四类各20张,每类的前10幅来自于训练样本,用于训练,后10幅来自测试样本,用于测试,如下图:

关于MNIST的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/49611549
测试代码如下:
#include "opencv.hpp"
#include <string>
#include <vector>
#include <memory>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
#include "common.hpp"/ Decision Tree
int test_opencv_decision_tree_train()
{const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);CHECK(tmp.data != nullptr);const int train_samples_number{ 40 };const int every_class_number{ 10 };cv::Mat train_data(train_samples_number, tmp.rows * tmp.cols, CV_32FC1);cv::Mat train_labels(train_samples_number, 1, CV_32FC1);float* p = (float*)train_labels.data;for (int i = 0; i < 4; ++i) {std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });}// train datafor (int i = 0; i < 4; ++i) {static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };static const std::string suffix{ ".jpg" };for (int j = 1; j <= every_class_number; ++j) {std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;cv::Mat image = cv::imread(image_name, 0);CHECK(!image.empty() && image.isContinuous());image.convertTo(image, CV_32FC1);image = image.reshape(0, 1);tmp = train_data.rowRange(i * every_class_number + j - 1, i * every_class_number + j);image.copyTo(tmp);}}cv::Ptr<cv::ml::DTrees> dtree = cv::ml::DTrees::create();dtree->setMaxCategories(4);dtree->setMaxDepth(10);dtree->setMinSampleCount(10);dtree->setCVFolds(0);dtree->setUseSurrogates(false);dtree->setUse1SERule(false);dtree->setTruncatePrunedTree(false);dtree->setRegressionAccuracy(0);dtree->setPriors(cv::Mat());dtree->train(train_data, cv::ml::ROW_SAMPLE, train_labels);const std::string save_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsonsdtree->save(save_file);return 0;
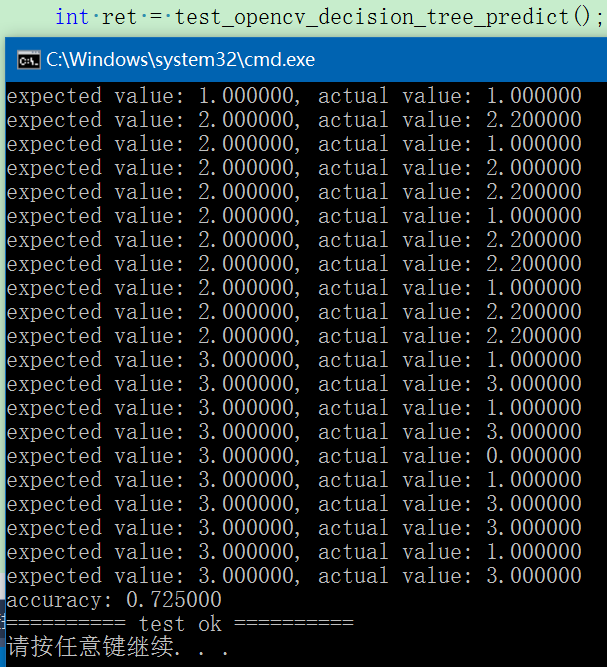
}int test_opencv_decision_tree_predict()
{const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };const std::string load_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsonsconst int predict_samples_number{ 40 };const int every_class_number{ 10 };cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);CHECK(tmp.data != nullptr);// predict dattacv::Mat predict_data(predict_samples_number, tmp.rows * tmp.cols, CV_32FC1);for (int i = 0; i < 4; ++i) {static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };static const std::string suffix{ ".jpg" };for (int j = 11; j <= every_class_number + 10; ++j) {std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;cv::Mat image = cv::imread(image_name, 0);CHECK(!image.empty() && image.isContinuous());image.convertTo(image, CV_32FC1);image = image.reshape(0, 1);tmp = predict_data.rowRange(i * every_class_number + j - 10 - 1, i * every_class_number + j - 10);image.copyTo(tmp);}}cv::Mat result;cv::Ptr<cv::ml::DTrees> dtrees = cv::ml::DTrees::load(load_file);dtrees->predict(predict_data, result);CHECK(result.rows == predict_samples_number);cv::Mat predict_labels(predict_samples_number, 1, CV_32FC1);float* p = (float*)predict_labels.data;for (int i = 0; i < 4; ++i) {std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });}int count{ 0 };for (int i = 0; i < predict_samples_number; ++i) {float value1 = ((float*)predict_labels.data)[i];float value2 = ((float*)result.data)[i];fprintf(stdout, "expected value: %f, actual value: %f\n", value1, value2);if (int(value1) == int(value2)) ++count;}fprintf(stdout, "accuracy: %f\n", count * 1.f / predict_samples_number);return 0;
}
GitHub: https://github.com/fengbingchun/NN_Test
相关文章:
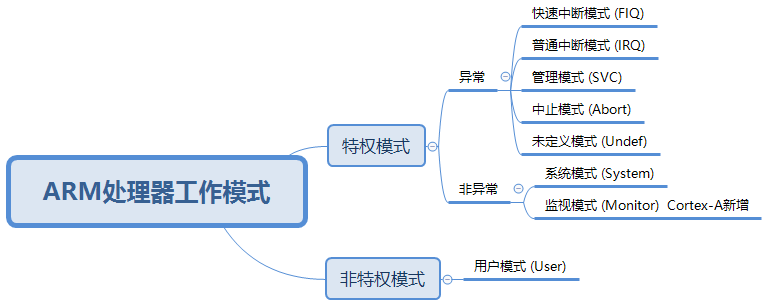
ARM 寄存器 和 工作模式了解
一. ARM 工作模式 1. ARM7,ARM9,ARM11,处理器有 7 种工作模式;Cortex-A 多了一个监视模式(Monitor) 2. 用户模式:非特权模式,大部分任务执行在这种模式,它运行在操作系…

英文版PDF不能显示中文PDF文件的解决方法
首先,PDF如果是英文版本的话,先装一个与之对应的PDF中文包。装上之后要检查的两项:1、PDF本身打开Adobe pdf选择“edit”"Preference""Internet"将"internet"下的三个勾全部勾上"OK"2、IE设置打开IE…
Linux下__attribute__((visibility (default)))的使用
在Linux下动态库(.so)中,通过GCC的C visibility属性可以控制共享文件导出符号。在GCC 4.0及以上版本中,有个visibility属性,可见属性可以应用到函数、变量、模板以及C类。 限制符号可见性的原因:从动态库中尽可能少地输出符号是一…
java web学习项目20套源码完整版
java web学习项目20套源码完整版 自己收集的各行各业的都有,这一套源码吃遍所有作业项目! 1、BBS论坛系统(jspsql)2、ERP管理系统(jspservlet)3、OA办公自动化管理系统(Struts1.2Hibernate3.0Spring2DWR)4、…

360金融携手上海交大共建AI实验室,开启人才战略新布局
10月16日,上海交通大学计算机科学系—360金融人工智能联合实验室成立仪式在上海交通大学闵行校区举行,联合实验室致力于AI技术在新金融领域的应用探索。成立仪式上,360金融CEO吴海生宣布了“未来科学家”计划,这是360金融在人工智…
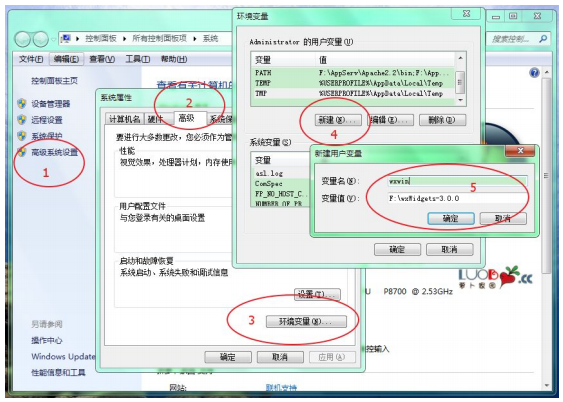
wxWidgets刚開始学习的人导引(3)——wxWidgets应用程序初体验
wxWidgets刚開始学习的人导引全文件夹 PDF版及附件下载1 前言2 下载、安装wxWidgets3 wxWidgets应用程序初体验4 wxWidgets学习资料及利用方法指导5 用wxSmith进行可视化设计附:学习材料清单3 wxWidgets应用程序初体验本文中全部的体验,在Code::Blocks…
C++中extern的使用
在C中,extern主要有两个作用:(1)、extern声明一个变量或函数;(2)、extern与”C”一起连用,用于链接指定。关于extern “C”的使用可以参考: http://blog.csdn.net/fengbingchun/article/details/78634831 ,…

Python识别文字,实现看图说话 | CSDN博文精选
作者 | 张小腿来源 | CSDN博客现在写文件很多网站都不让复制了,所以每次都是截图然后发到QQ上然后用手机QQ的文字识别再发回电脑。感觉有点小麻烦了,所以想自己写一个小软件方便方便自己,就有了这篇了:首先语言是Python࿰…
Oracle Hints具体解释
在向大家具体介绍Oracle Hints之前,首先让大家了解下Oracle Hints是什么,然后全面介绍Oracle Hints,希望对大家实用。基于代价的优化器是非常聪明的,在绝大多数情况下它会选择正确的优化器,减轻了DBA的负担。但有时它也…
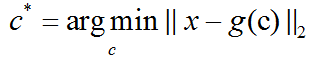
主成分分析(PCA)简介
主成分分析(Principal Components Analysis, PCA)是一个简单的机器学习算法,可以通过基础的线性代数知识推导。假设在Rn空间中我们有m个点{x(1),…,x(m)},我们希望对这些点进行有损压缩。有损压缩表示我们使用更少的内存,但损失一些精度去存储…
01-HTML基础与进阶-day6-录像281
04css选择器.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Document</title><style type"text/css">/* p div 标签选择器*/p {color: red; /* k:v color表示样式属性 颜…
百度CTO王海峰:深度学习如何大规模产业化?
编者按:10月17日-19日,2019年中国计算机大会(CNCC2019)在苏州举办。百度首席技术官王海峰在会上发表题为《深度学习平台支撑产业智能化》的演讲,分享了百度关于深度学习技术推动人工智能发展及产业化应用的思考。以下为…
Kali Linux***测试
Kali Linux***测试实战 第一章http://drops.wooyun.org/tips/826 1.1 Kali Linux简介如果您之前使用过或者了解BackTrack系列Linux的话,那么我只需要简单的说,Kali是BackTrack的升级换代产品,从Kali开始,BackTrack将成为历史。如果…
一站式解决:隐马尔可夫模型(HMM)全过程推导及实现
作者 | 永远在你身后转载自知乎用户永远在你身后【导读】隐马尔可夫模型(Hidden Markov Model,HMM)是关于时许的概率模型,是一个生成模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态序列,每个状态生…

CUDA Samples: Image Process: BGR to BGR565
图像像素格式BGR565是每一个像素占2个字节,其中Blue占5位,Green占6位,Red占5位。在OpenCV中,BGR到BGR565的每一个像素的计算公式是:unsigned short dst (unsigned short)((B >> 3) | ((G & ~3) << 3)…
NoSQL数据库探讨 - 为什么要用非关系数据库?
源地址:http://robbin.javaeye.com/blog/524977 随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。而传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类…
手机内存RAM、ROM简介
手机内存包含两个:一个是运行内存(RAM),一个是机身内存(ROM)。两者的功能有所不同,运行内存是对手机操作系统和其它程序运行过程中,产生的临时数据进行存储的媒介。如果手机运行的程序比较多,占用运行内存空间较大&…

一个月入门Python爬虫,轻松爬取大规模数据
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样一个月入门Python爬虫,轻松爬的编程语言提供越来越多的优秀工具&#x…

软件包管理 之 软件在线升级更新yum 图形工具介绍
作者:北南南北来自:LinuxSir.Org提要:yum 是Fedora/Redhat 软件包管理工具,包括文本命令行模式和图形模式;图形模式的yum也是基于文本模式的;目前yum图形前端程序主要有 yumex和kyum ; 正文一、…

[PHPUnit]自动生成PHPUnit测试骨架脚本-提供您的开发效率【2015升级版】
2019独角兽企业重金招聘Python工程师标准>>> 场景 在编写PHPUnit单元测试代码时,其实很多都是对各个类的各个外部调用的函数进行测试验证,检测代码覆盖率,验证预期效果。为避免增加开发量,可以使用PHPUnit提供的phpuni…

ORL Faces Database介绍
ORL人脸数据集共包含40个不同人的400张图像,是在1992年4月至1994年4月期间由英国剑桥的Olivetti研究实验室创建。此数据集下包含40个目录,每个目录下有10张图像,每个目录表示一个不同的人。所有的图像是以PGM格式存储,灰度图&…
张俊林:BERT和Transformer到底学到了什么 | AI ProCon 2019
演讲嘉宾 | 张俊林(新浪微博机器学习团队AI Lab负责人)编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】BERT提出的这一年,也是NLP领域迅速发展的一年。学界不断提出新的预训练模型,刷新各…
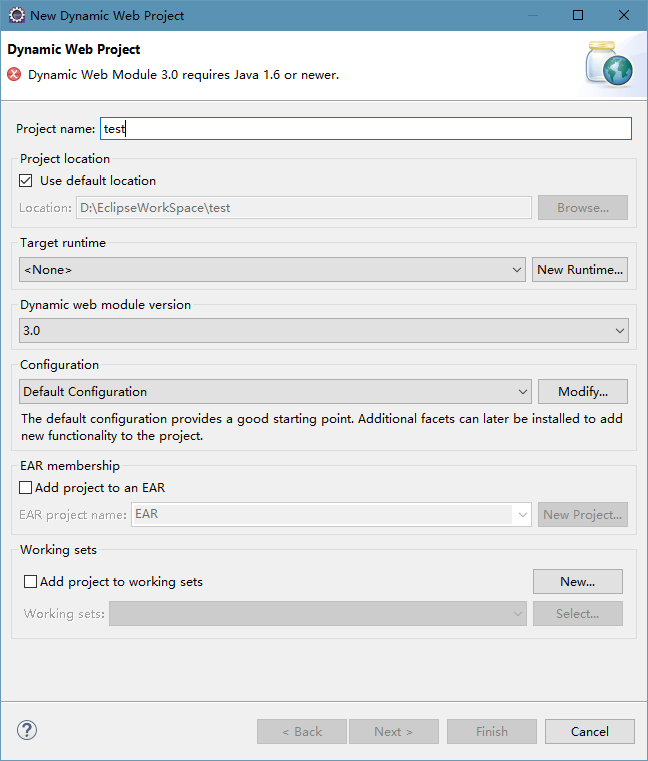
Eclipse创建web工程时,报错Dynamic Web Module 3.0 requires Java 1.6 or newer.
报错: 解决方案: 1.打开eclipse工具栏window->preferences 2.打开java->compiler 3.选择compiler compliance level在1.6以上版本(此处选择1.8) 4.点击apply and close保存修改,即可 转载于:https://www.cnblogs…
Maven学习总结(八)——使用Maven构建多模块项目
2019独角兽企业重金招聘Python工程师标准>>> Maven学习总结(八)——使用Maven构建多模块项目 在平时的Javaweb项目开发中为了便于后期的维护,我们一般会进行分层开发,最常见的就是分为domain(域模型层)、dao࿰…

哈工大、清华、CSDN、嵌入式视觉联盟合办的 AIoT 盛会,你怎么舍得错过?!
2019 嵌入式智能国际大会即将来袭!随着物联网和人工智能技术的飞速发展与相互渗透,万物智联的新赛道已经开始显现。据中商产业研究院《2016—2021年中国物联网产业市场研究报告》显示,预计到2020年,中国物联网的整体规模将达2.2万…

OpenCV3.3中主成分分析(Principal Components Analysis, PCA)接口简介及使用
OpenCV3.3中给出了主成分分析(Principal Components Analysis, PCA)的实现,即cv::PCA类,类的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/pca.cpp文件中,其中:(1)、cv::PCA::PCA:构造函数࿱…
Spring MVC配置
为什么80%的码农都做不了架构师?>>> 一、传统方式配置Spring MVC (1)导入jar包 需要导入如下的jar包 junit-3.8.1.jar spring-core-3.0.5.RELEASE.jar commons-logging-1.1.1.jar spring-context-3.0.5.REL…
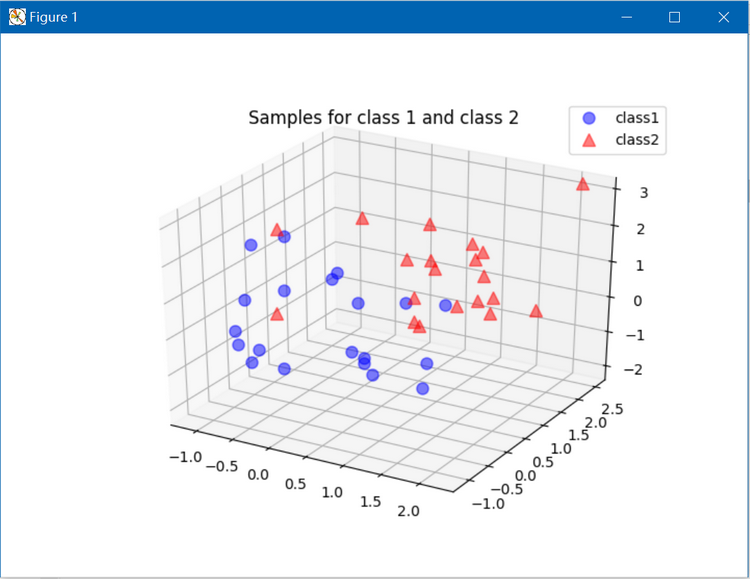
主成分分析(PCA)Python代码实现
主成分分析(Principal Components Analysis, PCA)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/78977202 这里是参照 http://sebastianraschka.com/Articles/2014_pca_step_by_step.html 文章中的code整理的Python代码,实现过程为…
AI发展这一年:不断衍生的技术丑闻与抵制声潮
作者 | AI Now学院译者 | Raku编辑 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】10月2日,纽约大学AI Now学院在纽约大学斯克博剧院(Skirball Theatre)组织召开了第四届年度AI Now研讨会。研讨会邀请了业内组织者…
Distributed Configuration Management Platform(分布式配置管理平台)
2019独角兽企业重金招聘Python工程师标准>>> 专注于各种 分布式系统配置管理 的通用组件/通用平台, 提供统一的配置管理服务。 主要目标: 部署极其简单:同一个上线包,无须改动配置,即可在 多个环境中(RD/QA/PRODUCTION…