手把手教你实现PySpark机器学习项目——回归算法

作者 | hecongqing
来源 | AI算法之心(ID:AIHeartForYou)
【导读】PySpark作为工业界常用于处理大数据以及分布式计算的工具,特别是在算法建模时起到了非常大的作用。PySpark如何建模呢?这篇文章手把手带你入门PySpark,提前感受工业界的建模过程!
train.head(5)"""[Row(User_ID=1000001, Product_ID='P00069042', Gender='F', Age='0-17', Occupation=10, City_Category='A', Stay_In_Current_City_Years='2', Marital_Status=0, Product_Category_1=3, Product_Category_2=None, Product_Category_3=None, Purchase=8370), Row(User_ID=1000001, Product_ID='P00248942', Gender='F', Age='0-17', Occupation=10, City_Category='A', Stay_In_Current_City_Years='2', Marital_Status=0, Product_Category_1=1, Product_Category_2=6, Product_Category_3=14, Purchase=15200), Row(User_ID=1000001, Product_ID='P00087842', Gender='F', Age='0-17', Occupation=10, City_Category='A', Stay_In_Current_City_Years='2', Marital_Status=0, Product_Category_1=12, Product_Category_2=None, Product_Category_3=None, Purchase=1422), Row(User_ID=1000001, Product_ID='P00085442', Gender='F', Age='0-17', Occupation=10, City_Category='A', Stay_In_Current_City_Years='2', Marital_Status=0, Product_Category_1=12, Product_Category_2=14, Product_Category_3=None, Purchase=1057), Row(User_ID=1000002, Product_ID='P00285442', Gender='M', Age='55+', Occupation=16, City_Category='C', Stay_In_Current_City_Years='4+', Marital_Status=0, Product_Category_1=8, Product_Category_2=None, Product_Category_3=None, Purchase=7969)]"""
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。6.6 折票限时特惠(立减1400元),学生票仅 599 元!

推荐阅读
相关文章:

mcDropdown使用方法
最近使用了mcDropdown插件,百度一查,资料较少,只看到了mcDropdown官网的英文说明文档,所以今天就写点,以便以后使用。 第一步:引用jquery库和css jQuery v1.2.6 (or higher)*jquery.mcdropdown.js Plug-inj…
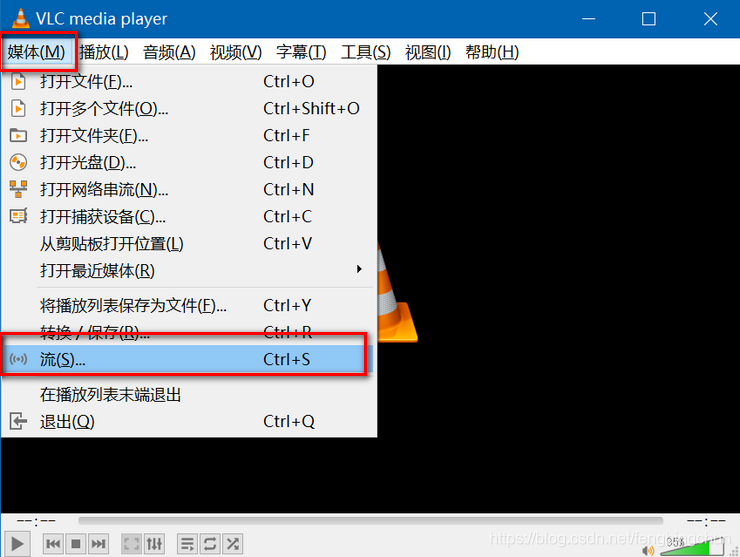
Windows上通过VLC播放器搭建rtsp流媒体测试地址操作步骤
1. 从https://www.videolan.org/index.zh.html 下载最新的windows 64bit 3.0.6版本并安装; 2. 打开VLC media player,依次点击按钮:”媒体” --> “流”,如下图所示: 3. 点击”添加”按钮,选择一个视频…

Swift - AppDelegate.swift类中默认方法的介绍
项目创建后,AppDelegate类中默认带有如下几个方法,具体功能如下: 1,应用程序第一次运行时执行这个方法只有在App第一次运行的时候被执行过一次,每次App从后台激活时都不会再执行该方法。(注:所有…

上热搜了!“学了Python6个月,竟然找不到工作!”
在编程界,Python是一种神奇的存在。有人认为,只有用Python才能优雅写代码,提高代码效率;但另一部分人恨不能把Python喷成筛子。那么,Python到底有没有用,为什么用Python找不到工作?CSDN小姐姐带…
Linux0.00内核为什么要自己设置0x80号陷阱门来调用write_char过程?
我一开始没注意这个问题,只是通过陷阱门觉得很绕弯子,为何不在3级用户代码里直接调用write_char,今天自己写程序想用call调用代码段,才发现了大问题。我写了个类似于write_char的过程,代码如下:dividing_li…

iOS支付宝(Alipay)接入详细流程,比微信支付更简单,项目实战中的问题分析
最近在项目中接入了微信支付和支付宝支付,总的来说没有那么坑,很多人都说文档不全什么的,确实没有面面 俱到,但是认真一步一步测试下还是妥妥的,再配合懂得后台,效率也是很高的,看了这篇文章&a…
LIVE555简介及在Windows上通过VS2013编译操作步骤
LIVE555是使用开放标准协议(RTP/RTCP, RTSP, SIP)形成的一组用于多媒体流C库。这些库支持的平台包括Unix(包括Linux和Mac OS X)、Windows和QNX(以及其它符号POSIX的系统)。这些库已经被用于实现的应用例如LIVE555媒体服务器、LIVE555代理服务器(RTSP服务器应用)以及vobStreamer…
GitHub App终于来了,iPhone用户可尝鲜,「同性交友」更加便捷
整理 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】据外媒 VentureBeat 报道,在 11 月 13 日举行的 GitHub Universe 上,微软宣布了面向程序员和开发人员的一系列升级,包括针对 iOS 智能手机和 iPad 推出的 GitHub…

[NHibernate]代码生成器的使用
目录 写在前面 文档与系列文章 代码生成器的使用 总结 写在前面 前面的文章介绍了nhibernate的相关知识,都是自己手敲的代码,有时候显得特别的麻烦,比如你必须编写持久化类,映射文件等等,举得例子比较简单,…
RapidJSON简介及使用
RapidJSON是腾讯开源的一个高效的C JSON解析器及生成器,它是只有头文件的C库。RapidJSON是跨平台的,支持Windows, Linux, Mac OS X及iOS, Android。它的源码在https://github.com/Tencent/rapidjson/,稳定版本为2016年发布的1.1.0版本。 Rap…
高德地图关键字搜索oc版
.h文件 // MapSearchViewController.h // JMT // // Created by walker on 16/10/11. // Copyright © 2016年 BOOTCAMP. All rights reserved. // #import <UIKit/UIKit.h> #import <AMapNaviKit/MaMapKit.h> #import <AMapSearchKit/AMapSearchKit.h&…

同一个内容,对比Java、C、PHP、Python的代码量,结局意外了
为什么都说Python容易上手!是真的吗?都说Python通俗易懂,容易上手,甚至不少网友表示「完成同一个任务,C 语言要写 1000 行代码,Java 只需要写 100 行,而 Python 可能只要 20 行」到底是真的还是…
图片存储思考:
http://blog.csdn.net/liuruhong/article/details/4072386
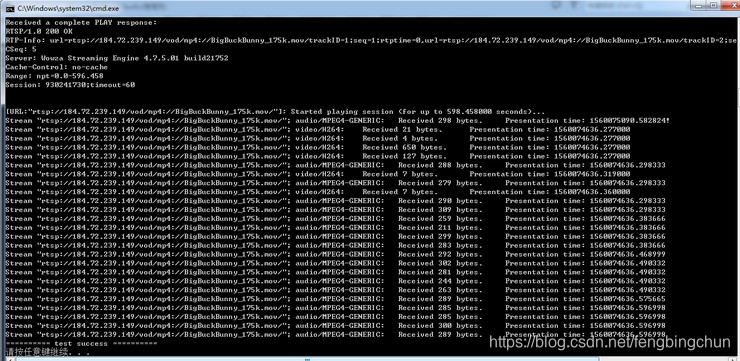
LIVE555中RTSP客户端接收媒体流分析及测试代码
LIVE555中testProgs目录下的testRTSPClient.cpp代码用于测试接收RTSP URL指定的媒体流,向服务器端发送的命令包括:DESCRIBE、SETUP、PLAY、TERADOWN。 1. 设置使用环境:new一个BasicTaskScheduler对象;new一个BasicUsageEnvironm…
swift代理传值
比如我们这个场景,B要给A传值,那B就拥有代理属性, A就是B的代理,很简单吧!有代理那就离不开协议,所以第一步就是声明协议。在那里声明了?谁拥有代理属性就在那里声明,所以代码就是这…

重磅:腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
整理 | 唐小引 来源 | CSDN(ID:CSDNnews)腾讯开源进化 8 年,进入爆发期。 继刚刚连续开源 TubeMQ、Tencent Kona JDK、TBase、TKEStack 四款重点开源项目后,腾讯开源再次迎来重磅项目!北京时间 11 月 14 日…

类似ngnix的多进程监听用例
2019独角兽企业重金招聘Python工程师标准>>> 多进程监听适合于短连接,且连接间无交集的应用。前两天简单写了一个,在这里保存一下。 #include <sys/types.h>#include <stdarg.h>#include <signal.h>#include <unistd.h&…
今日头条李磊等最新论文:用于文本生成的核化贝叶斯Softmax
译者 | Raku 出品 | AI科技大本营(ID:rgznai100)摘要用于文本生成的神经模型需要在解码阶段具有适当词嵌入的softmax层,大多数现有方法采用每个单词单点嵌入的方式,但是一个单词可能具有多种意义,在不同的背景下&#…
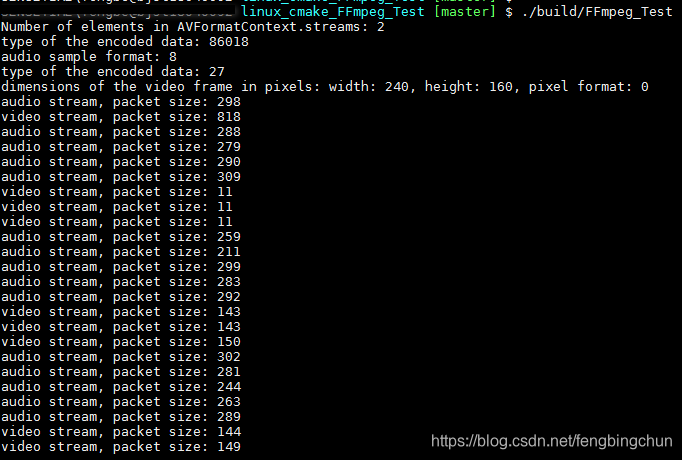
FFmpeg中RTSP客户端拉流测试代码
之前在https://blog.csdn.net/fengbingchun/article/details/91355410中给出了通过LIVE555实现拉流的测试代码,这里通过FFmpeg来实现,代码量远小于LIVE555,实现模块在libavformat。 在4.0及以上版本中,FFmpeg有了些变动ÿ…

虚拟机下运行linux通过nat模式与主机通信、与外网连接
首先:打开虚拟机的编辑菜单下的虚拟网络编辑器,选中VMnet8 NAT模式。通过NAT设置获取网关IP,通过DHCP获取可配置的IP区间。同时,将虚拟机的虚拟机菜单的设置选项中的网络适配器改为NAT模式。即可! 打开linux࿰…
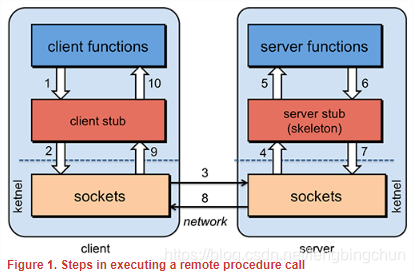
远程过程调用RPC简介
RPC(Remote Procedure Call, 远程过程调用):是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的思想。 RPC是一种技术思想而非一种规范或协议,常见RPC技术和框架有: (1). 应用级的服务框架:阿里的…

iOS开发:沙盒机制以及利用沙盒存储字符串、数组、字典等数据
iOS开发:沙盒机制以及利用沙盒存储字符串、数组、字典等数据 1、初识沙盒:(1)、存储在内存中的数据,程序关闭,内存释放,数据就会丢失,这种数据是临时的。要想数据永久保存,将数据保存成文件&am…
支撑亿级用户“刷手机”,百度Feed流背后的新技术装备有多牛?
导读:截止到2018年底,我国网民使用手机上网的比例已高达98.6%,移动互联网基本全方位覆盖。智能手机的操作模式让我们更倾向于通过简单的“划屏”动作,相对于传统的文本交互方式来获取信息,用户更希望一拿起手机就能刷到…

玩转高性能超猛防火墙nf-HiPAC
中华国学,用英文讲的,稀里糊涂听了个大概,不得不佩服西方人的缜密的逻辑思维,竟然把玄之又玄的道家思想说的跟牛顿定律一般,佩服。归家,又收到了邮件,还是关于nf-hipac的,不知不觉就…

ios 沙盒 plist 数据的读取和存储
plist 只能存储基本的数据类型 和 array 字典 [objc] view plaincopy - (void)saveArray { // 1.获得沙盒根路径 NSString *home NSHomeDirectory(); // 2.document路径 NSString *docPath [home stringByAppendingPathComponent:"Document…
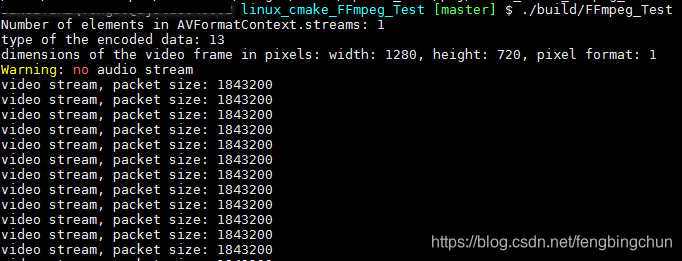
FFmpeg实现获取USB摄像头视频流测试代码
通过USB摄像头(注:windows7/10下使用内置摄像头,linux下接普通的usb摄像头(Logitech))获取视频流用到的模块包括avformat和avdevice。头文件仅include avdevice.h即可,因为avdevice.h中会include avformat.h。libavdevice库是libavformat的一…

重磅!明略发布数据中台战略和三大解决方案
11月15日,明略科技在上海举办以“FASTER 聚变增长新动力”为主题的2019数据智能峰会,宣布“打造智能时代的企业中台”新战略,同时推出了两大新产品“新一代数据中台”和“营销智能平台”,以及三大行业解决方案,分别是“…
Android程序完全退出的三种方法
1. Dalvik VM的本地方法 android.os.Process.killProcess(android.os.Process.myPid()) //获取PID,目前获取自己的也只有该API,否则从/proc中自己的枚举其他进程吧,不过要说明的是,结束其他进程不一定有权限,不然就…
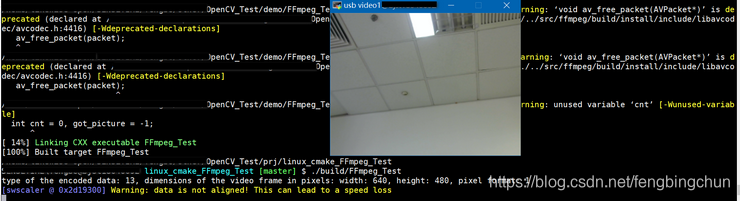
FFmpeg通过摄像头实现对视频流进行解码并显示测试代码(旧接口)
这里通过USB摄像头(注:windows7/10下使用内置摄像头,linux下接普通的usb摄像头(Logitech))获取视频流,然后解码,最后再用opencv显示。用到的模块包括avformat、avcodec和avdevice。libavdevice库是libavformat的一个补充库(comple…

IOS数据存储之文件沙盒存储
前言: 之前学习了数据存储的NSUserDefaults,归档和解档,对于项目开发中如果要存储一些文件,比如图片,音频,视频等文件的时候就需要用到文件存储了。文件沙盒存储主要存储非机密数据,大的数据。 …