今日头条李磊等最新论文:用于文本生成的核化贝叶斯Softmax

译者 | Raku
出品 | AI科技大本营(ID:rgznai100)
摘要
用于文本生成的神经模型需要在解码阶段具有适当词嵌入的softmax层,大多数现有方法采用每个单词单点嵌入的方式,但是一个单词可能具有多种意义,在不同的背景下,其中一些可能会有所不同。在本文中,研究者提出一种新颖的、学习更好的嵌入文本生成方法——KerBS。KerBS主要有两个优点:a)采用嵌入的贝叶斯组合多义词;b)它适应单词的语义变化,并且通过施加学习过的内核来捕获相似度,对少见语境嵌入空间中的单词(感官)数具有鲁棒性。实证研究表明,KerBS大大提高了一些文本生成任务的性能。
1、简介
借助[Bengio,2003;Mikolov,2010]的语言建模,[Sutskever,2014;Bahdanau,2015;Vaswani;2017]的机器翻译,[Sordoni;2015]的对话生成,文本生成已得到显着改善。这些模型都包括softmax最后一层以产生单词。softmax层采用上下文状态(h)来自上游网络(例如RNN单元)作为输入,并将h转换为具有线性投影(W·h)和指数激活的单词概率,W的每一行都可以视为嵌入一个词。实际上,softmax通过计算上下文向量h和词汇表中的词嵌入W之间的内积评分进行嵌入匹配。
softmax常用的设置在嵌入空间上有一个很强的假设,即每个单词对应一个单独的向量,解码网络中的上下文向量h必须在一定距离度量下不加区别地接近所需的单词嵌入向量。我们发现这样的假设与实际情况不符。
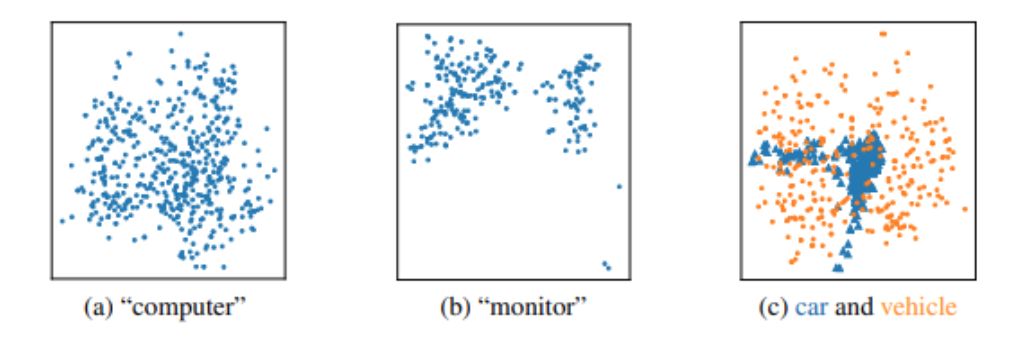
图 1 可视化包含所检查单词话语上下文向量的示例, 来自BERT模型Devlin [2019]。我们观察到3个有趣的现象:a)多义性:并非每个词的上下文向量构成一个单独的簇,而是由有多个簇的单词群构成(图1b)。b)变方差:上下文向量的方差在集群中存在显著差异,有些词对应较小的方差,有些词对应较大的方差(图1c)。c)鲁棒性:上下文空间存在异常值(图1b)。
这些现象解释了传统的softmax在训练中无效的原因,传统方法将单词嵌入到同一单词的所有上下文向量中,即使它们可能属于多个不同的簇。它也容易受到离群值的影响,因为一个单一的异常将导致嵌入这个词远离主集群。简而言之,softmax层没有足够的表达能力。
Yang[2018]提出了混合软max (MoS)来增强softmax的表达能力,它用M个softmax层的加权平均代替了单个softmax层。然而,所有的词都有相同数量的成分M和平均重量,这严重限制了MoS的容量。此外,上下文向量的方差也没有被考虑到。
“computer”
本文提出了一种新的文本嵌入生成方法——KerBS。KerBS通过引入多个嵌入的Bayesian组合和一个可学习的内核来度量嵌入之间的相似性,从而避免了上述softmax问题。KerBS不是一个单独的嵌入,而是用多个嵌入的加权组合显式地表示一个单词,每个嵌入的加权组合被视为一个意义,嵌入的数量也会自动从语料库中获得。我们设计了一组核心函数来代替softmax层中的嵌入匹配(即矩阵-向量点积),通过从文本中学习参数,每个单词(或意义)可以在其嵌入空间中享受个体差异。此外,与高斯核相比,核族对异常值具有更强的鲁棒性。
实证结果验证了该方法的有效性。消蚀研究(Ablation study,控制变量法)表明,KerBS的每个部分,包括贝叶斯组成和核函数,都是提高性能的必要条件。
2、相关工作
词嵌入(Word Embeddings):Word2Vec [Mikolov et al.,2013]与GloVe [Pennington et al.,2014]以非监督的方式从语料库中学习分布式单词表示,BERT [Devlin et al.,2019]使用深层双向转换器对掩蔽语言模型进行了预训练,并在各种NLP任务中实现了最好的性能。
多义词嵌入(Multi-Sense Word Embeddings):但是这些方法是不可扩展的,并且在参数调优方面花费了大量的努力[Reisinger和Mooney, 2010, Huang et al.,2012]。Tian等[2014]提出了一种概率模型,该模型使用一个变量来控制每个单词的词义选择,Liu等[2015]为每个单词添加一个topic变量,并在topic变量上嵌入条件词,然而,这些作品主要侧重于文本理解,而不是文本生成。
作为分布的词嵌入(Word Embedding as a Distribution):
3、背景知识
大多数文本生成模型通过嵌入匹配过程生成单词。直观地说,在每个步骤中,上游网络(如RNN解码器)根据来自输入和先前生成的单词的编码信息计算上下文向量h,上下文向量h用作查询,从预先计算的词汇表嵌入W中搜索最相似的匹配,在实践中,这是通过W和h之间的内积实现的,在推理过程中,选择概率最高的单词。
具体来说,给定一个话语![]() ,GRU译码器计算如下:
,GRU译码器计算如下:
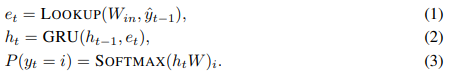
在第t时刻,通过查找单词嵌入矩阵 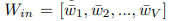 (式.(1))。这里
(式.(1))。这里 ![]() 是第i个单词在词汇表中的嵌入,V是词汇量,第t步的上下文嵌入
是第i个单词在词汇表中的嵌入,V是词汇量,第t步的上下文嵌入 ![]() 由GRU结合
由GRU结合 ![]() 和
和 ![]() 的信息得到(式(2))。其他解码器和Transformer Vaswani等人[2017]工作类似。
的信息得到(式(2))。其他解码器和Transformer Vaswani等人[2017]工作类似。
式(3)在 ![]() 和W之间进行嵌入匹配,将所获得单词的概率通过softmax激活。直觉上来说,要生成正确的单词
和W之间进行嵌入匹配,将所获得单词的概率通过softmax激活。直觉上来说,要生成正确的单词 ![]() ,被嵌入
,被嵌入 ![]() 的上下文应该在所嵌入单词
的上下文应该在所嵌入单词 ![]() 的周围。
的周围。
4、KerBS方法
在本节中,我们首先介绍用于文本生成的KerBS,它是根据在引言中提到的三个观察结果设计的:多义性、变差性和鲁棒性。然后,针对直接学习每个单词的义数比较困难的问题,提出了一种动态分配义的训练方案。
4.1、模型架构
KerBS假设同一个单词的上下文向量空间由几个几何上独立的分量组成,每个部分都代表一种意义,有自己的差异。为了更好地模拟它们的分布,我们将式(3)代入以下方程:
在这里,![]() 是步骤t的意义索引,其值取
是步骤t的意义索引,其值取![]() ,对应于词汇表中第i个单词的第j个意义。
,对应于词汇表中第i个单词的第j个意义。 ![]() 是单词i的意义数量,不同单词的意义数量可能不同。KerBS不是直接计算单词的概率,而是先计算属于某个单词的所有意义的概率,然后将它们相加得到单词概率。
是单词i的意义数量,不同单词的意义数量可能不同。KerBS不是直接计算单词的概率,而是先计算属于某个单词的所有意义的概率,然后将它们相加得到单词概率。
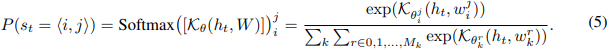
式(5)中输出感知 ![]() 的概率不是严格的高斯后验,因为高斯模型在高维空间的训练是数值不稳定的,相反,我们建议使用一个精心设计的核函数,来模拟每个意义的分布方差。具体来说,我们替换式(3)的内积核函数K,这取决于方差相关参数θ,
的概率不是严格的高斯后验,因为高斯模型在高维空间的训练是数值不稳定的,相反,我们建议使用一个精心设计的核函数,来模拟每个意义的分布方差。具体来说,我们替换式(3)的内积核函数K,这取决于方差相关参数θ,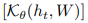 是一个简化符号包含所有成对的内核值
是一个简化符号包含所有成对的内核值 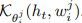 。对于
。对于![]() 的每个意义,我们可以分别对它们的分布的方差建模。
的每个意义,我们可以分别对它们的分布的方差建模。
4.1.1、嵌入的贝叶斯组合
在这一部分中,我们将详细介绍KerBS如何对单词的多义性进行建模。直观地说,我们在文本生成中使用了嵌入的贝叶斯组合,因为同一个单词可以有完全不同的含义,对于具有多个意义的单词,通常可以将其对应的上下文向量划分为单独的集群(参见图1)。如果我们使用单一嵌入模型(如传统的softmax)来拟合这些集群,则单词嵌入将收敛于这些集群的平均值,并且可能与所有集群都很远,这可能会导致文本生成性能变差。
如式(4)所示,我们可以为每个意义分配不同的嵌入。我们首先通过上下文向量h与意义嵌入矩阵w之间的权值匹配得到意义概率,然后将每个单词的意义概率相加得到单词概率。
我们采用了权值捆绑方案[Inan et al.,2017],其中解码嵌入和输入嵌入是共享的。由于W是一个意义嵌入矩阵,因此不能像式(1)那样直接用于下一步的解码网络。相反,我们根据意义嵌入的条件概率计算其加权和得到嵌入集。假设![]() 是第t步的输入字:
是第t步的输入字:
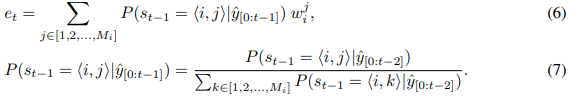
4.1.2、内核的嵌入匹配
为了计算每个意义的概率,在嵌入空间中引入高斯分布是非常简单的,然而,由于以下原因,在高维空间中很难学习嵌入的高斯分布。上下文向量通常分布在高维空间中嵌入的低维流形中,在低维流形中使用高斯分布来建模嵌入向量可能会导致严重的不稳定性,假设在一个采用空间, ![]() 的分布
的分布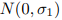 遵循d1维子空间,我们建立一个模型 去拟合嵌入点。但通常存在一些噪声异常值,假设这些异常值均匀分布在边长为1且以原点为中心的立方体中,离群点到原点的平均平方距离为d12,与d成线性关系:
遵循d1维子空间,我们建立一个模型 去拟合嵌入点。但通常存在一些噪声异常值,假设这些异常值均匀分布在边长为1且以原点为中心的立方体中,离群点到原点的平均平方距离为d12,与d成线性关系:
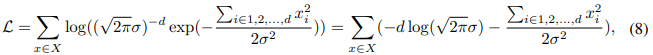
X中的离群值比例表示为α。由于 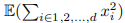 是随机生成的点集并且等于d1,
是随机生成的点集并且等于d1, ![]() 是离群值,所以当d较大时,L为离群值所主导。
是离群值,所以当d较大时,L为离群值所主导。 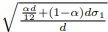 ,当d较大时,最优σ约等于
,当d较大时,最优σ约等于 ![]() ,并且独立于真实方差
,并且独立于真实方差 ![]() 。
。
具体来说,我们用一个核函数来代替可以看作是围绕整个空间的一个固定核的内积 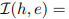
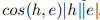 :
:

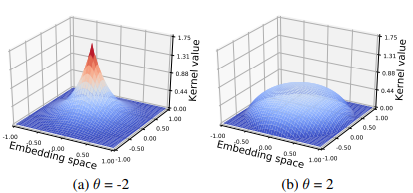
图2:不同θ下核的形状
θ是控制每个方向的嵌入方差的参数, 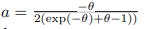 是一个归一化因子。当
是一个归一化因子。当 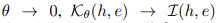 ,它退化为一个公共内积。最后,第i个单词的参数可以是
,它退化为一个公共内积。最后,第i个单词的参数可以是 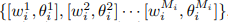 ,其中
,其中![]() 和
和![]() 是意义
是意义 ![]() 的嵌入与核参数。直观地说,在具有内积相似性的原始空间中,概率质量的密度是均匀分布的。但是
的嵌入与核参数。直观地说,在具有内积相似性的原始空间中,概率质量的密度是均匀分布的。但是![]() 扭曲了概率空间,使得上下文向量在不同意义上的方差不同。
扭曲了概率空间,使得上下文向量在不同意义上的方差不同。
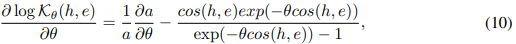
因 ,
,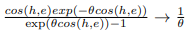 ,并当
,并当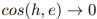 时,每个h的梯度都以一个固定的θ为界,这来自于
时,每个h的梯度都以一个固定的θ为界,这来自于 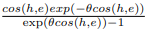 的连续性。因此,少量的异常值或噪声点不会对训练稳定性产生重大影响。
的连续性。因此,少量的异常值或噪声点不会对训练稳定性产生重大影响。
4.2、训练方案
很难从经验上确定每个词的意义数,这是一个非常大的超参数集,同样,同一个单词的属性在不同的语料库和任务中可能有所不同,为此,我们设计了一种包含动态感分配的路沿识别训练方案,我们不需要提供每个单词的意义数,只需要输入总意义数即可,算法会自动分配意义数量。
训练方案详见算法1。具体来说,获取参数对KerBS和上游网络 ![]() 上下文向量输出,整个过程包括分配和适应阶段。在训练之前,W和θ分别由随机矩阵和一个随机向量初始化,我们将
上下文向量输出,整个过程包括分配和适应阶段。在训练之前,W和θ分别由随机矩阵和一个随机向量初始化,我们将 ![]() 随机分配给单词。在步骤t,给定一个训练集中的序列
随机分配给单词。在步骤t,给定一个训练集中的序列 ![]() ,我们从
,我们从 ![]() 中得到上下文向量
中得到上下文向量![]() 。我们计算生成
。我们计算生成 ![]() 的对数概率
的对数概率 ![]() ,再通过微调W, θ 与φ最大化
,再通过微调W, θ 与φ最大化 ![]() :
:
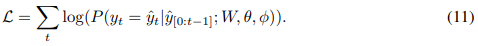
在适应阶段,KerBS学习意义嵌入向量 ![]() ,分布方差指标
,分布方差指标 ![]() 。
。
我们记录每个单词的log预测准确率log P与意义使用率U的变化的平均值:
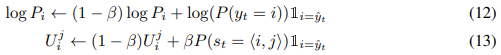
其中β是更新率。对于一个单词i,如果经过几个世纪后log P始终低于阈值,我们认为目前分配给i的意义数是不够的,然后我们删除最不常用的义并重新分配给i。我们交替地执行适应和重新分配直到收敛。

4.3、理论分析
在这一部分中,我们将解释为什么KerBS能够学习上下文向量的复杂分布。我们只对下面的引理做了简单的介绍,在附录中留下了更详细的证明。
引理4.1:KerBS具有学习多义性的能力。如果上下文向量的实际分布由几个不相连的集群组成,那么KerBS将学习尽可能多地表示集群。
证明:每一组词的上下文向量都吸引着它KerBS意义的嵌入,以使这些嵌入更靠近 ![]() 。
。
引理4.2:KerBS具有学习嵌入分布方差的能力,对于方差较大的分布,KerBS学习更大的θ。
证明:优化的θ是方程 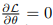 的解。我们只需要解释,当h的方差增大时,方程的解变大。
的解。我们只需要解释,当h的方差增大时,方程的解变大。
5、实验
在本节中,我们通过实证验证了KerBS的有效性。我们先建立实验,然后在5.2部分给出实验结果。
我们在几个文本生成任务上测试kerb,包括:
•
•
• Dialog
Dialog
对于LM,我们使用Perplexity (PPL)来测试性能。对于MT和Dialog,我们使用BLEU-4和BLEU-1评分来衡量生成质量[Papineni et al.,2002]。对话中还包括人工评估。在人工评价过程中,要求3名志愿者标注包含50组句子的对话数据,每个集合包含输入语句以及由KerBS和基线模型生成的输出响应,志愿者被要求根据回答的流利程度和与相应问题的相关性对回答进行评分(具体评分见附录)。在标记完回答后,我们计算每种方法的平均分数,然后进行t检验以拒绝KerBS不优于基线方法的假设。
5.1、实现细节
(hidden size, embedding dimension对于Transformer的MT和Dialog,设置与Lee等[2018]相同:(hidden size, embedding dim, dropout, layer num, head num)设置为(288,507,0.1,5,2)。
5.2、文本生成结果
我们在表1和表2中列出了使用KerBS的结果,然后进行了分析。
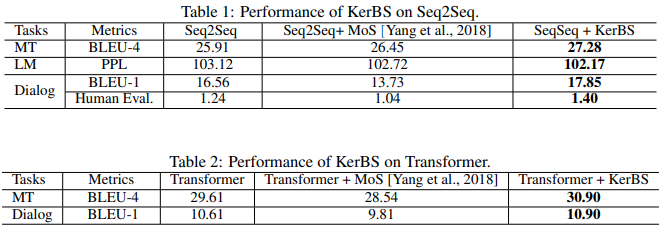
机器翻译:然而,MoS的性能增益并不显著,甚至不如vanilla Transformer模型,Transformer上MT的情况如表3所示。

语言建模:
对话生成:
5.3、消蚀研究(Ablation Study)
KerBS w/o内核从KerBS中删除内核函数,这样分布方差就不再被显式控制。KerBS 单意义下的KerBS替代了多意义模式,也导致了性能的下降,w/o

5.4、细节分析
在本部分中,我们验证KerBS学习合理数M和方差参数θ的例子,对此我们有以下结论:
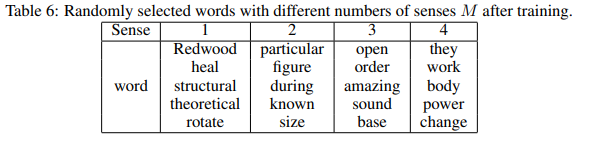
首先,KerBS可以学习多义性。从表6中我们可以发现,具有单一含义的单词,包括一些专有名词,只具有一种意义,但是对于意义更复杂的词,比如代词,需要更多的意义项来表示(在我们的实验中,为了保持训练的稳定性,我们将每个单词的义数限制在1到4之间)。此外,我们发现有四种意义的词有几种不同的含义。例如,“change”意味着转变和小额货币。

其次,在KerBS中,θ是一个单词的语义范围指标,在图3中,我们比较了3组名词的 θ 。对于它们的每一组,我们发现更大概念的词组(如汽车、动物和地球)拥有更大的 θ 。
5.5、时间复杂度
与baseline相比,将KerBS合并到文本生成中的计算成本主要取决于更大的嵌入匹配词汇量,而这只是整个文本生成计算的一部分。根据经验,当我们设置总意义数为词汇量的3倍左右时,KerBS花费的时间是vanilla softmax的两倍。
6、结论
文本生成需要适当的单词嵌入空间。在这篇论文中,我们提出了KerBS来学习更好的文本生成嵌入。与传统的Softmax不同,KerBS包含一个多义词嵌入的贝叶斯组合和一个可学习的内核来捕获词之间的相似性,将KerBS合并到文本生成中可以提高几个文本生成任务的性能,特别是对话生成任务。未来的工作包括提出更好的内核去生成和设计一个元学习机器来动态地重新分配意义数。
附录A 证明
引理A.1:KerBS具有学习多义性的能力。如果上下文向量的实际分布是由几个不相连的部分组成的,那么KerBS组件将学习表示这些部分的数量。
证明:我们还假设第1部分已经由第1部分中h1的意义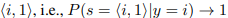 表示,
表示,![]() ,我们发现:
,我们发现:
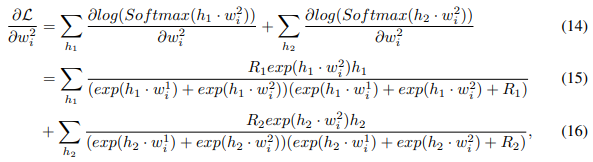
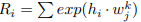 代表除了
代表除了 ![]() 和
和 ![]() 之外的所有意义,第1部分已经用意义很好地表达了
之外的所有意义,第1部分已经用意义很好地表达了 ![]() ,
,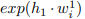 应该比
应该比 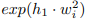 大得多。然后有:
大得多。然后有:
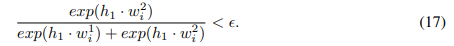
因此,第一部分对 ![]() 的吸引力(第15行)比第二部分(第16行)要小得多,
的吸引力(第15行)比第二部分(第16行)要小得多,![]() 将向第二部分移动。
将向第二部分移动。
引理A.2:KerBS具有学习模型方差的能力,对于方差更大的分布,KerBS学习更大的θ。
证明:
根据 ![]() 的定义:
的定义:

其中, ![]() 为
为![]() 的期望输出,并暂时隐藏其他参数。
的期望输出,并暂时隐藏其他参数。
我们可以推出 ![]() 对
对 ![]() 的偏导数:
的偏导数:
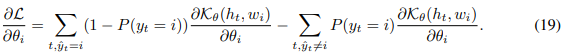
当θ很小时,我们可以大致由以下方程:
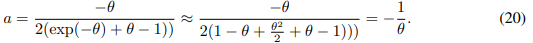
大约得到:
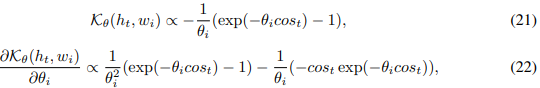
其中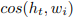 被缩写成
被缩写成 ![]() 。
。
因为对于 ![]() , 通常很小,我们可以忽略式(19)的第二部分,所以最优值θ近似式(23)的一个解:
, 通常很小,我们可以忽略式(19)的第二部分,所以最优值θ近似式(23)的一个解:
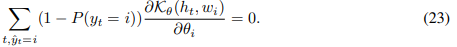
然后有:
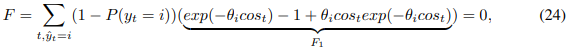
由于当 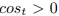 时
时 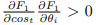 ,并且当
,并且当![]() 时
时![]() 恒正,故当
恒正,故当 ![]() 越来越小,
越来越小,![]() 有增长的趋势。因此,当分布方差增加时,
有增长的趋势。因此,当分布方差增加时,![]() 趋于下降,因为上下文向量离均值向量较远,所以,
趋于下降,因为上下文向量离均值向量较远,所以,![]() 将会增长。
将会增长。
附录B 实验细节
人工评分标准 -
•
• 1
• 2
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。6.6 折票限时特惠(立减1400元),学生票仅 599 元!

推荐阅读
相关文章:
FFmpeg中RTSP客户端拉流测试代码
之前在https://blog.csdn.net/fengbingchun/article/details/91355410中给出了通过LIVE555实现拉流的测试代码,这里通过FFmpeg来实现,代码量远小于LIVE555,实现模块在libavformat。 在4.0及以上版本中,FFmpeg有了些变动ÿ…

虚拟机下运行linux通过nat模式与主机通信、与外网连接
首先:打开虚拟机的编辑菜单下的虚拟网络编辑器,选中VMnet8 NAT模式。通过NAT设置获取网关IP,通过DHCP获取可配置的IP区间。同时,将虚拟机的虚拟机菜单的设置选项中的网络适配器改为NAT模式。即可! 打开linux࿰…
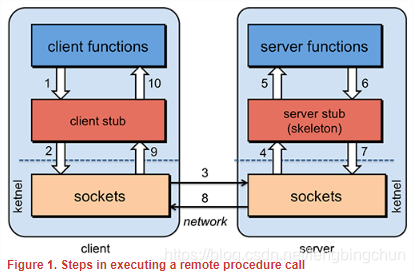
远程过程调用RPC简介
RPC(Remote Procedure Call, 远程过程调用):是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的思想。 RPC是一种技术思想而非一种规范或协议,常见RPC技术和框架有: (1). 应用级的服务框架:阿里的…

iOS开发:沙盒机制以及利用沙盒存储字符串、数组、字典等数据
iOS开发:沙盒机制以及利用沙盒存储字符串、数组、字典等数据 1、初识沙盒:(1)、存储在内存中的数据,程序关闭,内存释放,数据就会丢失,这种数据是临时的。要想数据永久保存,将数据保存成文件&am…
支撑亿级用户“刷手机”,百度Feed流背后的新技术装备有多牛?
导读:截止到2018年底,我国网民使用手机上网的比例已高达98.6%,移动互联网基本全方位覆盖。智能手机的操作模式让我们更倾向于通过简单的“划屏”动作,相对于传统的文本交互方式来获取信息,用户更希望一拿起手机就能刷到…

玩转高性能超猛防火墙nf-HiPAC
中华国学,用英文讲的,稀里糊涂听了个大概,不得不佩服西方人的缜密的逻辑思维,竟然把玄之又玄的道家思想说的跟牛顿定律一般,佩服。归家,又收到了邮件,还是关于nf-hipac的,不知不觉就…

ios 沙盒 plist 数据的读取和存储
plist 只能存储基本的数据类型 和 array 字典 [objc] view plaincopy - (void)saveArray { // 1.获得沙盒根路径 NSString *home NSHomeDirectory(); // 2.document路径 NSString *docPath [home stringByAppendingPathComponent:"Document…
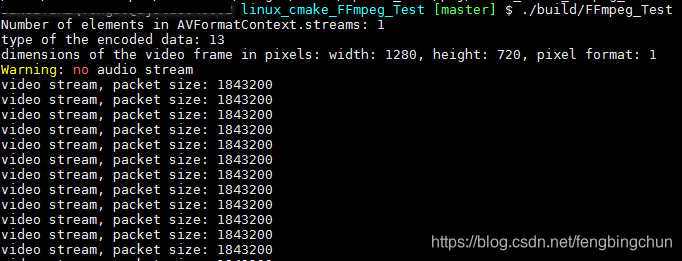
FFmpeg实现获取USB摄像头视频流测试代码
通过USB摄像头(注:windows7/10下使用内置摄像头,linux下接普通的usb摄像头(Logitech))获取视频流用到的模块包括avformat和avdevice。头文件仅include avdevice.h即可,因为avdevice.h中会include avformat.h。libavdevice库是libavformat的一…

重磅!明略发布数据中台战略和三大解决方案
11月15日,明略科技在上海举办以“FASTER 聚变增长新动力”为主题的2019数据智能峰会,宣布“打造智能时代的企业中台”新战略,同时推出了两大新产品“新一代数据中台”和“营销智能平台”,以及三大行业解决方案,分别是“…

Android程序完全退出的三种方法
1. Dalvik VM的本地方法 android.os.Process.killProcess(android.os.Process.myPid()) //获取PID,目前获取自己的也只有该API,否则从/proc中自己的枚举其他进程吧,不过要说明的是,结束其他进程不一定有权限,不然就…
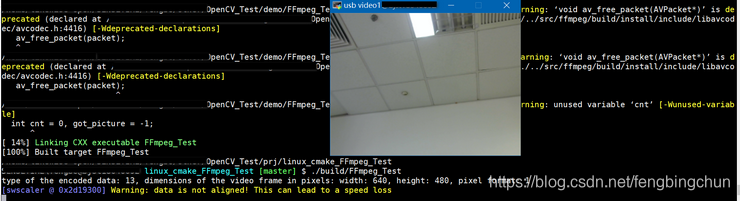
FFmpeg通过摄像头实现对视频流进行解码并显示测试代码(旧接口)
这里通过USB摄像头(注:windows7/10下使用内置摄像头,linux下接普通的usb摄像头(Logitech))获取视频流,然后解码,最后再用opencv显示。用到的模块包括avformat、avcodec和avdevice。libavdevice库是libavformat的一个补充库(comple…

IOS数据存储之文件沙盒存储
前言: 之前学习了数据存储的NSUserDefaults,归档和解档,对于项目开发中如果要存储一些文件,比如图片,音频,视频等文件的时候就需要用到文件存储了。文件沙盒存储主要存储非机密数据,大的数据。 …
剖析Focal Loss损失函数: 消除类别不平衡+挖掘难分样本 | CSDN博文精选
作者 | 图像所浩南哥来源 | CSDN博客论文名称:《 Focal Loss for Dense Object Detection 》论文下载:https://arxiv.org/pdf/1708.02002.pdf论文代码:https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines…
windows下mysql开启慢查询
mysql在windows系统中的配置文件一般是my.ini,我的路径是c:\mysql\my.ini,你根据自己安装mysql路径去查找[mysqld]#The TCP/IP Port the MySQL Server will listen onport3306#开启慢查询log-slow-queries E:\Program Files\MySQL\MySQL Server 5.5\mysql_slow_query.loglong_…
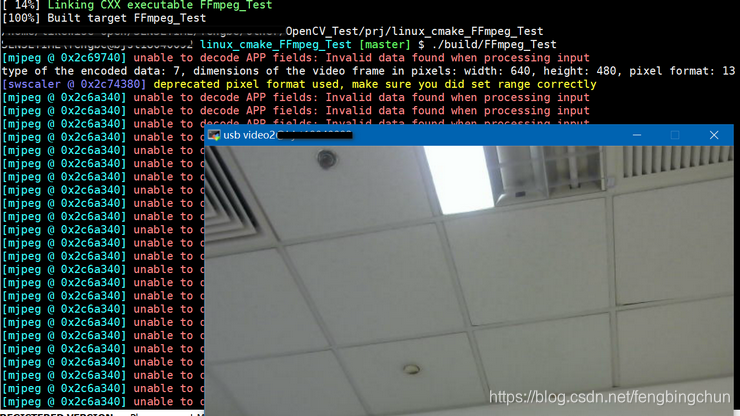
FFmpeg通过摄像头实现对视频流进行解码并显示测试代码(新接口)
在https://blog.csdn.net/fengbingchun/article/details/93975325 中给出了通过旧接口即FFmpeg中已废弃的接口实现通过摄像头获取视频流然后解码并显示的测试代码,这里通过使用FFmpeg中的新接口再次实现通过的功能,主要涉及到的接口函数包括:…
iOS经典讲解之获取沙盒文件路径写入和读取简单对象
#import "RootViewController.h" interface RootViewController () end 实现文件: implementation RootViewController - (void)viewDidLoad { [super viewDidLoad]; [self path]; [self writeFile]; [self readingFi…
Google最新论文:Youtube视频推荐如何做多目标排序
作者 | 深度传送门来源 | 深度传送门(ID:deep_deliver)导读:本文是“深度推荐系统”专栏的第十五篇文章,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要介绍下Google在RecSys …
Jmeter 笔记
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试但后来扩展到其他测试领域。 它可以用于测试静态和动态资源例如静态文件、Java 小服务程序、CGI 脚本、Java 对象、数据库, FTP 服务器&#…
王贻芳院士:为什么中国要探究中微子实验?
演讲嘉宾 | 王贻芳(中国科学院院士、中科院高能物理研究所所长)整理 | 德状出品 | AI科技大本营(ID:rgznai100)日前,在2019腾讯科学WE大会期间,中国科学院院士、高能物理研究所所长王贻芳分享了中微子与光电…
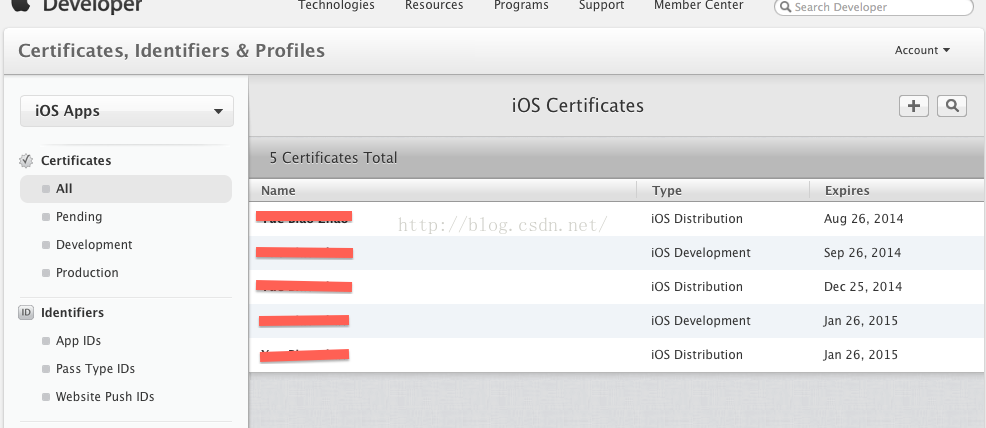
一个苹果证书供多台电脑开发使用——导出p12文件
摘要 在苹果开发者网站申请的证书,是授权mac设备的开发或者发布的证书,这意味着一个设备对应一个证书,但是99美元账号只允许生成3个发布证书,两个开发证书,这满足不了多mac设备的使用,使用p12文件可以解决这…
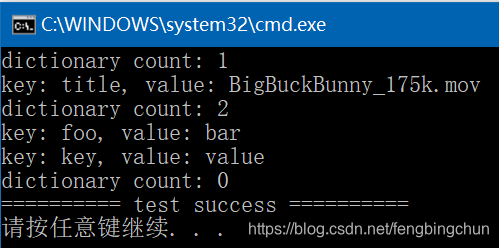
FFmpeg中AVDictionary介绍
FFmpeg中的AVDictionary是一个结构体,简单的key/value存储,经常使用AVDictionary设置或读取内部参数,声明如下,具体实现在libavutil模块中的dict.c/h,提供此结构体是为了与libav兼容,但它实现效率低下&…
RocketMQ3.2.2生产者发送消息自动创建Topic队列数无法超过4个
问题现象RocketMQ3.2.2版本,测试时尝试发送消息时自动创建Topic,设置了队列数量为8:producer.setDefaultTopicQueueNums(8);同时设置broker服务器的配置文件broker.properties:defaultTopicQueueNums16但实际创建后从控制台及后台…
iOS各种宏定义
#ifndef MacroDefinition_h #define MacroDefinition_h //************************ 获取设备屏幕尺寸********************************************** //宽度 #define SCREEN_WIDTH [UIScreen mainScreen].bounds.size.width //高度 #define SCREENH_HEIGHT [UIScree…
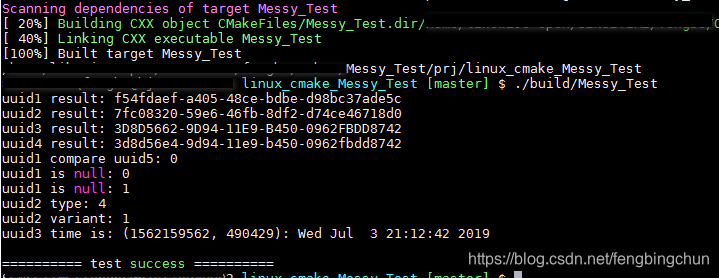
开源库libuuid简介及使用
libuuid是一个开源的用于生成UUID(Universally Unique Identifier,通用唯一标识符)的库,它的源码可从https://sourceforge.net/projects/libuuid/ 下载,最新版本为1.0.3,更新于2013年4月27日,此库仅支持在类Linux下编译…

深度学习会议论文不好找?这个ConfTube网站全都有
BDTC大会官网:https://t.csdnimg.cn/q4TY作者 | 刘畅 出品 | AI科技大本营(ID:rgznai1000)最近跟身边的硕士生、博士生聊天,发现有一个共同话题,大家都想要知道哪款产品能防止掉头发?养发育发已经成了茶余饭…

Java用for循环Map
为什么80%的码农都做不了架构师?>>> 根据JDK5的新特性,用For循环Map,例如循环Map的Key for(String dataKey : paraMap.keySet()) { System.out.println(dataKey ); } 注意的是,paraMap 是怎么样定义的,如果是简单的Map paraMap new …

iOS 应用发布到AppStore流程
iOS开发者,把开发出来的App上传到App Store是必须的。下面就来详细介绍下具体流程。 方法/步骤 1打开苹果开发者中心 打开后点击:Member Center 2如果你的电脑没有保存密码,则会提示你输入开发者帐号和密码,因为我的电脑已经保存了…

FFmpeg中编码类型为rawvideo无须解码直接显示测试代码
在 https://blog.csdn.net/fengbingchun/article/details/93975325 中介绍过通过FFmpeg可以直接获取usb视频流并解码显示的测试代码,当时通过usb获取到的视频流编码类型为AV_CODEC_ID_RAWVIDEO,像素格式为AV_PIX_FMT_YUYV422,其实编码类型为r…

一场高质量的技术盛会怎样炼成?「2019中国大数据技术大会」蓄势待发,还不快上车?...
2019年12月,一场轰动国内产业界、学术界、科研界及投资领域的顶级科技盛会即将拉开帷幕,它涵盖大数据、人工智能、云计算、AIoT、金融科技、智能制造等十几个前沿领域的热门话题。在过去十二年里,这场盛会从最初仅 60 余人参加的技术沙龙到如…
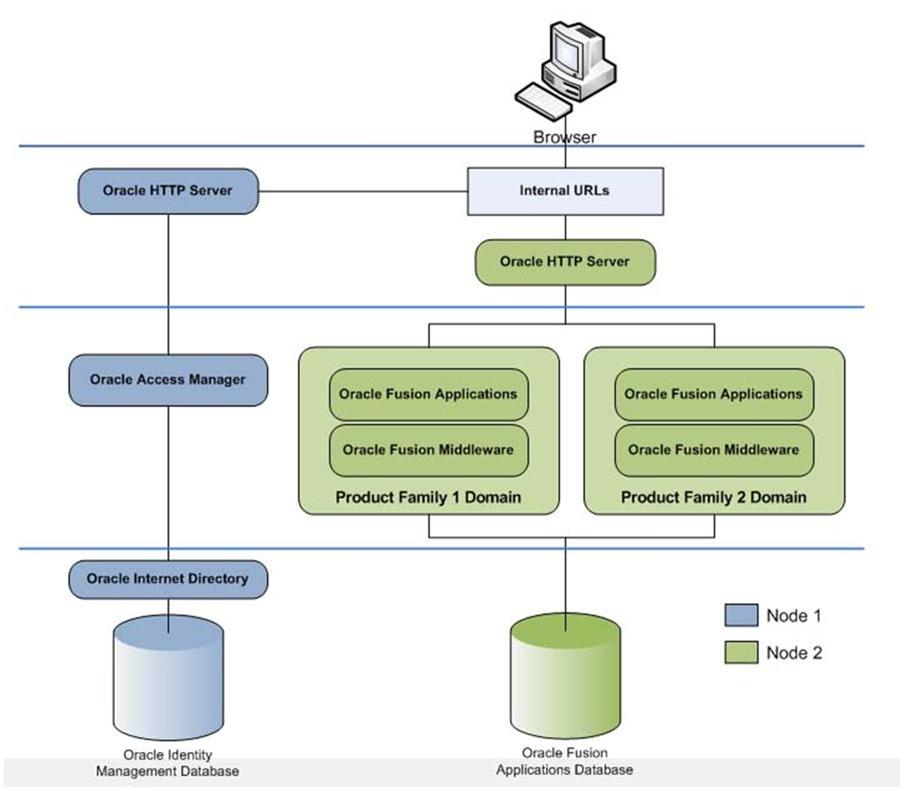
融合应用11.1.8安装,一步一步的引导
融合应用11.1.8安装,一步一步的引导 融合应用11.1.8 安装并不是简单的与电子商务套件11 i / R12安装。 所以我们需要安装划分为许多步骤。 请注意,11.1.8 11.1.7总统发布供应是几乎相同的。 在同一时间的步骤和一些组件11.1.6和11.1.5相比有所不同。 这里我们有实际使用同一个…