15篇论文全面概览BERT压缩方法
作者 | Mitchell A. Gordon
译者 | 孙薇
出品 | AI科技大本营(ID:rgznai100)
模型压缩可减少受训神经网络的冗余——由于几乎没有BERT或者BERT-Large模型可用于GPU及智能手机上,这一点就非常有用了。另外,内存与推理速度的提高也能节省大量成本。
本篇列出了作者所见过的BERT压缩论文,以下表格中对不同方法进行了分类。
论文1:Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning
链接:https://openreview.net/forum?id=SJlPOCEKvH
摘要:通用特征提取器,如用于自然语言处理的BERT,以及用于计算机视觉的VGG模型,都能在无需更多标记数据的情况下,有效地改善深度学习模型。常见范例包括使用大量数据对特征提取器进行预训练,之后在迁移学习之类的下游任务中微调,以优化深度学习模型。尽管有效,但类似BERT的功能提取器可能对于某些部署方案来说会显得过大。
在该论文中,我们针对BERT的权重修剪问题进行了研究和探讨:预训中的压缩是如何影响迁移学习的?我们发现,修剪对迁移学习的影响分三种情况:低水平修剪(30-40%)不会对预训练损失及迁移到下流任务产生影响;中水平修剪会增加预训练的损失,并会阻止有用的预训练迁移至下流任务;高水平修剪还会影响到模型拟合下游数据库,导致进一步降级。最终,根据观察,我们发现针对特定任务微调BERT并不会提高其可修剪能力,并得出结论,不影响性能的前提下,对BERT在预训练阶段进行单次修剪即可,无需针对各个任务分别修剪。
论文2:Are Sixteen Heads Really Better than One?
链接:http://arxiv.org/abs/1905.10650
摘要:注意力(attention)head非常强大,且普遍使用。有了attention head,神经模型在执行预测时,可通过平衡权重来着重于特定的重要信息。尤其multi-headed attention,更是近来许多最新NLP模型背后的推动力,比如Transformer-based MT模型,以及BERT。这些模型均用到了attention机制,且每个attention head都可能关注不同的输入片段,使得超出普通加权平均的方式,表达复杂功能成为可能。
本论文中,我们的观察令人惊讶:即便使用多表头(multiple head)来训练模型,在实际中,测试时移除大量注意力表头也不会对性能产生显著影响。事实上,一些层级甚至可以删成单表头。我们进一步研究了用于修剪模型的贪婪算法,以及从中可获得的潜在速度、内存效率及准确度改进。最终分析得出以下问题的结果:模型哪些部分在拥有多表头时更可靠。并且预测了multi-head attention收益中training dynamics所起到的重要作用。
论文3:Pruning a BERT-based Question Answering Model
链接:http://arxiv.org/abs/1910.06360
摘要:我们研究了如何通过修剪基础BERT模型中的参数,来压缩基于BERT的问答系统。初始训练模型是SQuAD 2.0,并引入gate(门)机制,令选中的transformer模块可被单独删除。具体步骤包括:(1)减少各个transformer的attention head数量;(2)减少各个transformer前馈子层的中间宽度;(3)减少嵌入维度。我们比较了确认这些gate值的一些方法,并发现结合修剪attention head和前馈层之后,解码速度提高了一倍,准确度损失仅有1.5 f point。
论文4:Reducing Transformer Depth on Demand with Structured Dropout
链接:https://openreview.net/forum?id=SylO2yStDr
摘要:过度参数化的transformer网络已在各种自然语言处理任务(如机器翻译、语言建模与问答)中取得了先进的成果。这些模型包含了数亿个参数,需要大量计算并使得它们易于拟合。
在本文中,我们研究了LayerDrop,它采用了结构化的dropout形式,在训练时具有正则化效应,并且允许我们在推理时进行有效修剪。我们特别展示了这样的可能性,从一个大型网络中选择任意深度的子网,无需对其微调,且对性能影响十分有限。通过改善机器翻译、语言建模、摘要、问答和语言理解基准方面的最先进技术,我们证明了所选方法的有效性。此外我们还展示了:使用我们的方法,可以生成质量更高的小型BERT类模型,而无需从头训练。
论文5:Reweighted Proximal Pruning for Large-Scale Language Representation
链接:https://openreview.net/forum?id=r1gBOxSFwr¬eId=r1gBOxSFwr
摘要:近来,预训练语言表征模型蓬勃发展,已成为自然语言理解社区(如BERT)的支柱。这些预训练语言表征模型可以在一系列下游任务上生成最先进的结果。随着持续显著的性能改善,这些预训练的神经模型持续在规模与复杂度上快速增长。压缩这些大型语言表征模型是否可能?修剪后的语言表征将如何影响下游多任务转移学习的主体?
在本论文中,我们提出了重新加权近似度修剪(RPP)方法,这是一种专为大规模语言表征模型所设计的修剪方法。基于SQuAD及GLUE基准套件上的实验,我们表明了近似度修剪后的BERT无论是针对于预训练任务,还是下游多个高修剪比例的微调任务,都保持了较高的准确性。RPP方法为我们提供了全新的角度,帮助我们分析大型语言表征模型可能学习的内容。此外,有了这种方法,在一系列不同的设备(比如在线服务器、移动电话及边缘设备)上部署类似BERT这样的先进语言表征模型也成为可能。
论文6:Structured Pruning of Large Language Models
链接:http://arxiv.org/abs/1910.04732
摘要:近来,大型语言模型在各种自然语言任务中都达到了最先进的性能。与此同时,这些模型的大小与延迟也显著增长,令使用成本增加,并引发一个有趣的问题:语言模型是否需要很大?我们通过模型压缩的角度来研究这个问题,并提出了一种基于低秩矩阵分解与强化的拉格朗日L0范数正则化的新型结构化修剪方法。我们的结构化方法在任何稀疏度级别上都可以显著实现推理加速,并匹配甚至优于我们的非结构化基准。将该方法应用于enwiki8数据库的最新模型上,我们仅用5兆参数就获得了1.19的困惑度评分,远胜于从头开始训练的同大小模型。我们还在几个下游任务分类中修剪BERT模型,展示了使用该方法对语言模型进行微调。
论文7:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
链接:https://openreview.net/forum?id=H1eA7AEtvS
摘要:在预训练自然语言表征时增加模型大小,通常会增加下游任务的数量。然而,由于GPU/TPU内存的限制、训练时间更长以及意料之外的模型降级等问题,有些时候进一步提升模型变得更加困难。为了解决这些问题,我们提出了两种参数约简(parameter-reduction)技术,以降低内存消耗,同时提高BERT的训练速度。大量实验表明,相比原始BERT,我们提出的方法优化后的模型可扩展性更佳。我们还使用了一个专注于模拟句子间连贯性的自监督loss,表明它可以持续协助多句子输入的下游任务。最终,我们的最佳模型在GLUE、RACE以及SQuAD基准上达成了最先进的结果,与此同时参数却少于BERT-large。
论文8:Extreme Language Model Compression with Optimal Subwords and Shared Projections
链接:https://openreview.net/forum?id=S1x6ueSKPr
摘要:经过预训练的深度神经网络语言模型,如ELMo、GPT、BERT及XLNet,近来在各种语言理解任务上都达到了最先进的性能。然而,其体量使得在许多场景下,尤其是在移动设备与边缘设备(Edge devices) 上都无法使用。尤其是在输入词汇量和嵌入维数较大时,输入单词的嵌入矩阵会占用模型内存的很多比例。知识蒸馏技术(Knowledge distillation techniques )在压缩大型神经网络模型方面已经取得成功,但在词汇量与原始teacher模型不同的student模型)中效果不佳。
我们引入了一种全新的知识蒸馏技术,用以训练词汇量明显较小、嵌入与隐藏维度也较低的student模型。具体来讲,我们部署了一套双重训练机制,同时训练teacher模型和student模型,以获得针对student模型词汇量的最佳单词嵌入机制。将此方法与分享投影矩阵(shared projection matrices)的学习相结合,将分层知识自teacher模型传递至student模型。我们的方法可以将基于BERT的模型压缩60倍以上,而下游任务仅有极少降低,因此语言模型的占用空间仅不到7MB。实验结果还显示,与其他最先进的压缩技术相比,该方法具有更高的压缩效率与准确度。
论文9:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
链接:http://arxiv.org/abs/1910.01108
摘要:随着自大型预训练模型执行的转移学习在自然语言处理(NLP)中愈发普遍,在实时与/或受限的计算训练中或推理预算下,操作这些大型模型仍然很有挑战性。在本文中,我们提出了一种名为DistilBERT的方法,预训练较小的通用语言表征模型,在将其用于较大任务(如较大的对应对象)时再对其进行微调。尽管之前的大多工作都在研究使用蒸馏来构建特定的任务模型,但是在预训练阶段,我们使用了知识蒸馏,证明了将BERT模型的大小减少40%,同时保留其97%的语言理解能力,并且增速60%是可行的。
为了利用预训练期间大型模型学习时的归纳偏差,我们引入了三重loss。这个更小、更快、更轻量级的模型在预训练时更便宜。我们在概念验证实验与比较性设备实体研究(on-device study)中证明了该模型的计算能力。
论文10:Distilling Transformers into Simple Neural Networks with Unlabeled Transfer Data
链接:http://arxiv.org/abs/1910.01769
摘要:近来,通过自我监督对大量文本执行大规模的模型预训练已经在各种自然语言处理任务中取得了先进成果。然而在实践中,这些模型庞大而昂贵,很难用于下游任务中。近期,我们使用知识蒸馏来压缩这些模型,却发现较小的student模型与较大的teacher模型之间存在着巨大的性能差异。
在本文中,我们将利用大量域内未标记的传输数据,以及少量标记过的训练实例来尝试弥补差异。实验证明,基于RNN的简单student模型在经过hard蒸馏的情况下,可以再次通过soft蒸馏,以及利用teacher模型的中间表示法获得提升。我们还证明了student模型可以将庞大的teacher模型压缩26倍,甚至在资源较少的情况下,仅有少量标记数据,也能媲美甚至超越teacher模型的表现。
论文11:Patient Knowledge Distillation for BERT Model Compression
链接:http://arxiv.org/abs/1908.09355
摘要:事实证明,类似BERT这样的预训练语言模型对于自然语言处理(NLP)任务非常有效。但这类模型在训练时对计算资源的高需求,阻碍了其实践中的应用。为了减轻大规模模型训练时的资源匮乏问题,我们提出了一种名为“耐心知识蒸馏”的方法,将原始的大模型(teacher)压缩成效果相等的轻量级浅层网络(student)。
与之前仅使用teacher网络最后一层的输出进行提炼的知识蒸馏方法不同,我们的student模型从teacher模型的多个中间层中学习,耐心进行增量知识提取,并遵循以下两种策略:(1)PKD-Last:从最后的k层开始学习;(2)PKD-Skip:从每个k层开始学习。这两种耐心知识蒸馏方案都能够利用teacher模型隐藏层的丰富信息,鼓励student模型通过多层蒸馏过程耐心向teacher模型学习和模仿。根据经验,多个NLP任务都获得了提升,且在不牺牲模型准确性的前提下,显著提高了训练效率。
论文12:TinyBERT: Distilling BERT for Natural Language Understanding
链接:https://openreview.net/forum?id=rJx0Q6EFPB
摘要:语言模型预训练(如BERT)极大地改善了许多自然语言处理任务的性能。但通常情况下,预训练语言模型计算量大、占用内存高,因此很难在资源受限的设备上有效执行。为了加快推理速度,并减少模型大小,且不损失精确度,我们首先提出了一种全新的Transformer蒸馏方法,这种方法是专为基于Transformer模型的知识蒸馏(KD)而设计。
借助这种全新的KD方法,我们可以将大型“teacher”BERT模型的知识转移到小型的“student”TinyBERT模型中。此外,我们为TinyBERT引入了一个全新的两阶段学习框架,在预训练阶段和特定任务学习阶段都会执行Transformer蒸馏方式,确保TinyBERT可以捕获BERT中的一般领域及特定任务领域。TinyBERT已被证实了效果,在GLUE基准测试中几可与BERT比拟,却比BERT要小7.5倍,推理速度达9.4倍。与BERT蒸馏的最前沿基准线相比,TinyBERT也要好得多,参数仅有前者的28%左右,推理时间也仅需31%左右。
论文13:MobileBERT: Task-Agnostic Compression of BERT by Progressive Knowledge Transfer
链接:https://openreview.net/forum?id=SJxjVaNKwB
摘要:近来,使用包含数亿参数的大量预训练模型,自然语言处理(NLP)取得了巨大成功。不过这些模型无论大小还是延迟都太过差强人意,我们无法将其直接部署到资源受限的移动设备上。本论文提出了将MobileBERT用于压缩和加速大热的BERT模型。与BERT一样,MobileBERT也是任务无偏(task-agnostic)的,即可以通过微调将其普遍应用在各种下游NLP任务之上。MobileBERT是BERT-LARGE的精简版,增加了瓶颈结构,并在self-attention和前馈网络间做了精细的平衡设计。
为了训练MobileBERT,我们使用了自上而下的渐进方案,用专门设计的反向瓶颈BERT-LARGE teacher模型将其中知识传递给MobileBERT。研究表明,MobileBERT比原始的BERT-BASE小4.3倍,推理速度要快4倍,且在知名的NLP基准测试中获得了具有竞争力的成果。在GLUE的自然语言推理任务上,MobileBERT在Pixel 3手机上实现了0.6 GLUE评分性能下降和367毫秒延迟的成绩。在SQuAD v1.1/v2.0的问答任务中,MobileBERT获得90.0/79.2 dev F1的分数,高于BERT-BASE的1.5/2.1。
论文14:Q8BERT: Quantized 8Bit BERT
链接:http://arxiv.org/abs/1910.06188
摘要:近来,经过预训练、以Transformer为基础的语言模型,如BERT和GPT在许多自然语言处理(NLP)任务中已经展现出极大的优化。但是,这些模型包含有大量参数。更大、更准确的模型,如GPT2和Megatron的出现,预示着预训练Transforemer模型的大型化趋势。然而,使用这些大型模型在生产环境中太过复杂,需要大量的计算,还会耗费大量内存和电力资源。本文展示了如何在BERT的微调阶段执行量化感知训练,以便以最小的精度损失将BERT压缩4倍。此外,如果针对8位支持硬件进行优化,则生成的量化模型可以加快推理速度。
论文15:Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
链接:http://arxiv.org/abs/1909.05840
摘要:基于Transformer的架构已成为一系列自然语言处理任务的实际模型。尤其,基于BERT的模型在GLUE、CoNLL-03和SQuAD中都取得了明显的准确度提高。但基于BERT的模型在内存占用和延迟方面都令人不甚满意。因此,在资源受限的环境中,部署基于BERT的模型已成为一项具有挑战性的任务。
本文中,我们使用了二阶Hessian信息,对微调的BERT模型进行了广泛的分析,我们根据结果提出了一种将BERT模型量化为超低精度的新方法。尤其我们还提出了一种新的逐组量化方案,并使用基于Hessian的混合精度方法进一步压缩模型。我们在SST-2、MNLI、CoNLL-03和SQuAD的下游任务上都测试了上述方法,可以达到与基准相当的性能,最多性能下降不超过2.3%,即便在超低精度量化中降到2位,模型参数压缩达13倍,以及嵌入表最大4倍的压缩。所有任务中,我们发现在SQuAD上微调的BERT性能损失最高,通过研究基于Hessian的分析与可视化,结果证明这与目前BERT训练/微调方案无法聚集到SQuAD有关。
原文链接:
http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
(*本文为AI科技大本营编译文章,转载请微信联系1092722531)
◆
精彩推荐
◆
开幕倒计时11天|2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。6.6 折票限时特惠(立减1400元),学生票仅 599 元!
马斯克发首款会上火星的电动皮卡:28万起,可防弹,造型相当“赛博朋克”
YC中国被撤,陆奇独立运营个人新品牌「奇绩创坛」
5种小型设备上深度学习推理的高效算法
中国工程院院士评选结果公布,阿里王坚当选
2097352GB地图数据,AI技术酷炫渲染,《微软飞行模拟器》游戏即将上线
用Go重构C语言系统,这个抗住春晚红包的百度转发引擎承接了万亿流量
日均350000亿接入量,腾讯TubeMQ性能超过Kafka
揭秘支撑双 11 买买买背后的硬核黑科技
假如有人把支付宝存储服务器炸了
乔布斯的简历 120 万被拍卖,HR 看了想打人
区块链+“中国制造”:一文看懂区块链如何提升供应链金融活力与效能
你点的每个“在看”,我都认真当成了AI
相关文章:

iOS下JS与OC互相调用(七)--Cordova 基础
Cordova 简介 在介绍Cordova之前,必须先提一下PhoneGap。PhoneGap 是Nitobi软件公司2008年推出的一个框架,旨在弥补web 和iOS 之间的不足,使得web 和 iPhone SDK 之间的交互更容易。后来又加入了Android SDK 和BlackBerry SDK,再然…

在linux上MySQL的三种安装方式
安装MySQL的方式常见的有三种:方式一:rpm安装(1) 操作系统发行商提供的(2) MySQL官方提供的(版本更新,修复了更多常见BUG)www.mysql.com/downloads关于MySQL中rpm包类型的介绍:MySQL-client 客户端…

通过libjpeg-turbo实现对jpeg图像的解码
之前在https://blog.csdn.net/fengbingchun/article/details/89715416中介绍过通过libjpeg-turbo接口实现将数据编码或压缩成jpeg数据并通过FILE的fwrite接口将其直接保存成*.jpg图像,当时用的是libjpeg的接口,其实还可以使用turbojpeg api的接口即tjCom…
AI+大数据顶级技术盛会开幕在即,6.6折特惠票限时抢购
2019年12月5-7日,由中国计算机学会主办,CCF 大数据专家委员会承办,CSDN、中科天玑数据科技股份有限公司协办的中国大数据技术大会(BDTC 2019)将于北京长城饭店隆重举行。届时,超过百位顶尖技术专家将齐聚于…

iOS下JS与OC互相调用(八)--Cordova详解+实战
1.新建工程,添加Cordova 关键类 我这里用Xcode 8 新建了一个工程,叫 JS_OC_Cordova,然后将Cordova关键类添加进工程。 有哪些关键类呢? 这里添加config.xml 、Private 和 Public 两个文件夹里的所有文件。工程目录结构如下: 然后…

iOS多线程编程之NSOperation和NSOperationQueue的使用
使用 NSOperation的方式有两种, 一种是用定义好的两个子类: NSInvocationOperation 和 NSBlockOperation。 另一种是继承NSOperation 如果你也熟悉Java,NSOperation就和java.lang.Runnable接口很相似。和Java的Runnable一样,NSOpe…

Swift - 使用SwiftHTTP通过HTTPS进行网络请求,及证书的使用
(本文代码已升级至Swift3)一,证书的生成,以及服务器配置参考我前面写的这篇文章:Tomcat服务器配置https双向认证(使用keytool生成证书)文章详细介绍了HTTPS,SSL/TLS。还有使用key to…
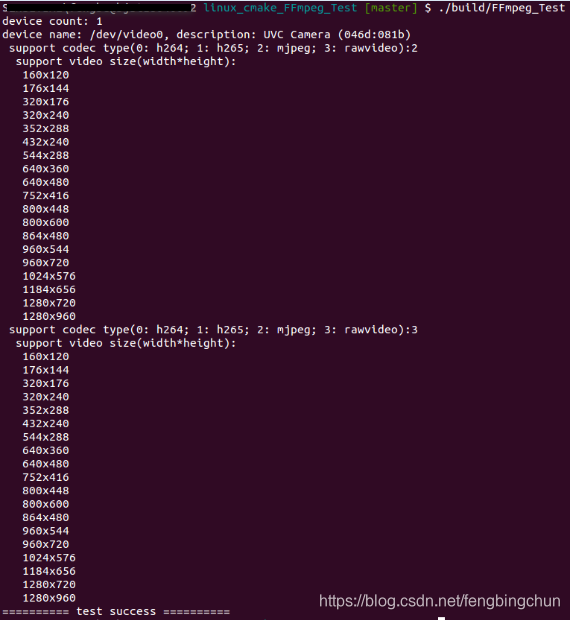
Linux下通过v4l2获取视频设备名、支持的编解码及视频size列表实现
早些时候给出了在Windows下通过dshow获取视频设备信息的实现,包括获取视频设备名、获取每种视频设备支持的编解码格式列表、每种编解码格式支持的video size列表,见:https://blog.csdn.net/fengbingchun/article/details/102806822 下面给出…
12种主流编程语言输出“ Hello World ”,把我给难住了!
作为一名程序员,在初步学习编程想必都绕不开一个最为基础的入门级示例“Hello World”,那么,你真的了解各个语言“Hello World”的正确写法吗?在我们刚开始打开编程世界的时候,往往写的第一个程序都是简单的文本输出&a…
军哥lnmp一键安装包nginx支持pathinfo配置
ssh里执行:cat > /usr/local/nginx/conf/pathinfo.conf << EOF set $real_script_name $fastcgi_script_name; if ($fastcgi_script_name ~ "(.?\.php)(/.*)") { set $real_script_name $1; set $path_info $2; } fastcgi_param SCRIPT_FILENAM…
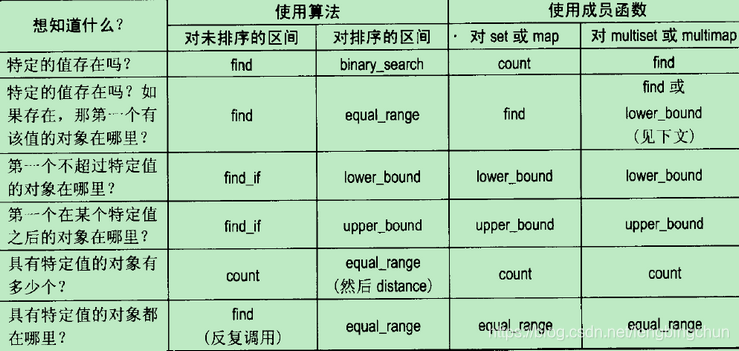
Effective STL 50条有效使用STL的经验笔记
Scott Meyers大师Effective三部曲:Effective C、More Effective C、Effective STL,这三本书出版已很多年,后来又出版了Effective Modern C。 Effective C的笔记见:https://blog.csdn.net/fengbingchun/article/details/102761542…
HTTPS网络加密双向验证-使用AFNetworking封装
1.首先使用OC封装请求头 #import <Foundation/Foundation.h> #import "AFNetworking.h" interface HttpsHandler : NSObject (AFHTTPSessionManager *)setHttpsMange; end 2.实现方法 (AFHTTPSessionManager *)setHttpsMange; { NSString *certFilePath […
30分钟搞定数据竞赛刷分夺冠神器LightGBM!
作者 | 梁云1991来源 | Python与算法之美(ID:Python_Ai_Road)【导读】LightGBM可以看成是XGBoost的升级加强版本,2017年经微软推出后,便成为各种数据竞赛中刷分夺冠的神兵利器。一,LightGBM和XGBoost对比正如其名字中的Light所蕴含…
js模块化例子
最近在看一本书,里面提到js的模块化,觉得很有必要,所以记录下来 Game.js /*** This is the main class that handles the game life cycle. It initializes* other components like Board and BoardModel, listens to the DOM events and* tr…
swift3.0提示框新用法
var alert: UIAlertController! alert UIAlertController(title: "提示", message: "添加照片", preferredStyle: UIAlertControllerStyle.actionSheet) let cleanAction UIAlertAction(title: "取消", style: UIAlertActionStyle.cancel,han…
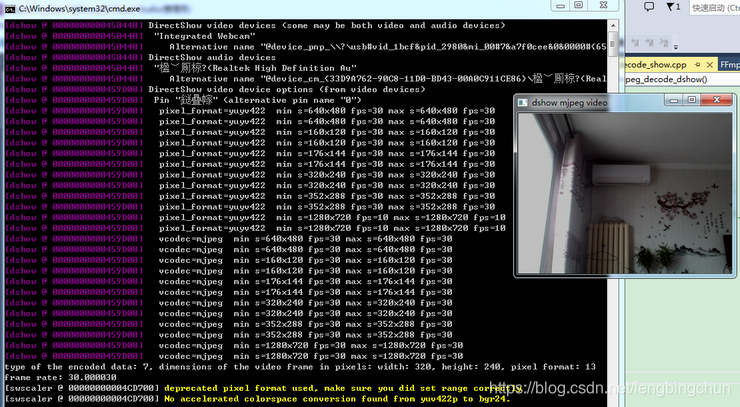
FFmpeg在Windows上通过dshow编解码方式设置为mjpeg并实时显示测试代码
Windows上默认的内置摄像头一般支持两种编解码格式:rawvideo和mjpeg。在调用FFmpeg接口时默认的采用rawvideo。这里通过DirectShow实现为mjpeg进行编解码。 通过命令行调用FFmpeg可执行文件: (1). 可获取Windows上连接的视频设备,命令如下&…
基于深度学习的低光照图像增强方法总结(2017-2019)| CSDN博文精选
扫码参与CSDN“原力计划”作者 | hyk_1996来源 | CSDN博客精选之前在做光照对于高层视觉任务的影响的相关工作,看了不少基于深度学习的低光照增强(low-light enhancement)的文章[3,4,5,7,8,9,10],于是决定简单梳理一下。光照估计&…
ios多线程和进程的区别(转载)
很想写点关于多进程和多线程的东西,我确实很爱他们。但是每每想动手写点关于他们的东西,却总是求全心理作祟,始终动不了手。 今天终于下了决心,写点东西,以后可以再修修补补也无妨。 一.为何需要多进程(或者…
OC封装的轮播图-只用调用即可
先来使用方法 1.//创建显示本地图片view UIView *imageScorll[WTImageScroll ShowLocationImageScrollWithFream:CGRectMake(0, 0, SCREENWIDTH, 200) andImageArray:array andBtnClick:^(NSInteger tagValue) { NSLog("点击的图片----%",(tagValue)); self.didSele…
多核时代,并行编程为何“臭名昭著”?
作者 | Yan Gu来源 | 转载自知乎用户Yan Gu【导读】随着计算机技术的发展,毫无疑问现代计算机的处理速度和计算能力也越来越强。然而细心的同学们可能早已注意到,从2005年起,单核的 CPU 性能就没有显著的提升了。究其原因,是人们发…
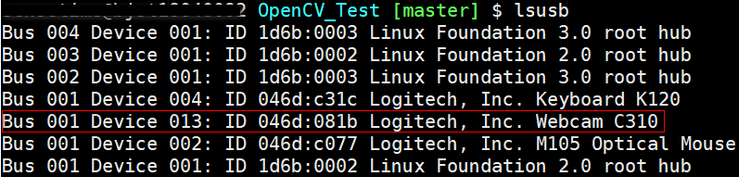
Linux下获取usb视频设备vendor id和product id的8种方法
在使用usb摄像头获取视频时,有时需要获取此摄像头供应商ID(vendor id, vid)和产品ID(product id, pid),这里在Linux下提供获取vid和pid的8种方法: 1. 通过v4l2中结构体v4l2_capability的成员变量card:此变量中会包含设备名、vid、…
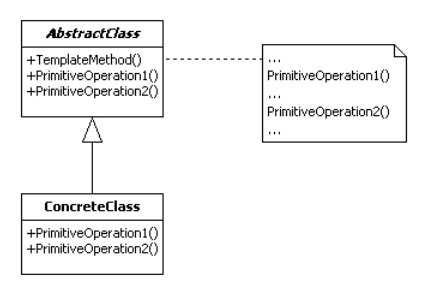
JAVA 设计模式 模板方法模式
定义 模板方法模式 (Template Method) 定义了一个操作中的算法的骨架,而将部分步骤的实现在子类中完成。模板方法模式使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。模板方法模式是所有模式中最为常见的几个模式之一,是基于继承的代…
这类程序员成华为宠儿,分分钟秒杀众应届毕业生
近日,华为20亿奖励员工的新闻频频刷屏。其中20亿奖金不是面向所有的华为员工,20亿奖金包涉及到的是研发体系、造AI芯片和建设生态的员工。从5G开始部署以来,华为获得了来自全球各地运营商的订单,签订了40多个5G商用合同。另外华为…
Swift 使用CoreLocation获取定位与位置信息
大多数情况下APP会在开启应用的时候获取当前的位置,所以我写在APPDelegate里第一步 import CoreLocationvar locationManager CLLocationManager() 第二步func application(application: UIApplication, didFinishLaunchingWithOptions launchOptions: [NSObject: …
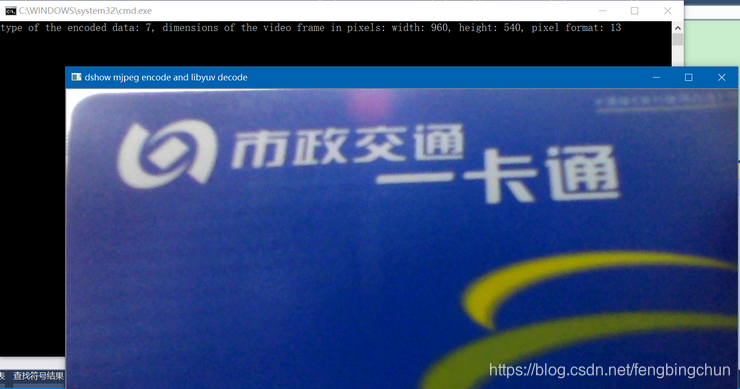
FFmpeg在Windows上设置dshow mjpeg编码+libyuv解码显示测试代码
之前在https://blog.csdn.net/fengbingchun/article/details/103444891中介绍过在Windows上通过ffmpeg dshow设置为mjpeg编解码方式进行实时显示的测试代码。这里测试仅调用ffmpeg的mjpeg编码接口,获取到packet后,通过libyuvlibjpeg-turbo对mjpeg进行解码…
转:浅谈Linux的内存管理机制
一 物理内存和虚拟内存 我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。 物理内存就是系统硬件提…
swift3.0阿里百川反馈
闲言少叙 直接上不熟 1.导入自己工程阿里百川demo中的Util文件,并引用其中的头文件 2.剩余就是swift3.0代码.在自己需要的地方书写 (前提是你已经申请了APPKey) 3.代码 //调用意见反馈 func actionOpenFeedback(){ //key self.appKey "此处填写自己申请的key" s…
通俗易懂:8大步骤图解注意力机制
作者 | Raimi Karim译者 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】这是一份用图片和代码详解自注意力机制的指南,请收好。BERT、RoBERTa、ALBERT、SpanBERT、DistilBERT、SesameBERT、SemBERT、MobileBERT、TinyBERT和CamemBERT的共同…
Windows上VS2017单步调试FFmpeg源码的方法
之前在https://blog.csdn.net/fengbingchun/article/details/90114411 介绍过如何在Windows7/10上通过MinGW方式编译FFmpeg 4.1.3源码生成库的步骤,那时只能生成最终的库,却不能产生vs工程,无法进行单步调试。GitHub上有个项目ShiftMediaProj…
ormlite 多表联合查询
ormlite 多表联合查询 QueryBuilder shopBrandQueryBuilder shopBrandDao.queryBuilder(); QueryBuilder shopQueryBuilder shopDao.queryBuilder();Where shopBrandWhere shopBrandQueryBuilder.where(); shopBrandWhere .eq(ShopBrand.SHOP_NO, shopNo);Where shopWhere …