通俗易懂:8大步骤图解注意力机制
【导读】这是一份用图片和代码详解自注意力机制的指南,请收好。
图解 代码 拓展到 Transformer
0.什么是自注意力?
1.图解
准备输入 初始化权重 派生密钥,查询和值 计算输入 1 的注意力得分 计算 softmax 将分数与值相乘 总和加权值以获得输出 1 对输入 2 和输入 3 重复步骤4–7
注意:实际上,数学运算是矢量化的,即所有输入都经过数学运算。我们稍后会在“代码”部分中看到这一点。
输入1:[1,0,1,0]输入2:[0,2,0,2]输入3:[1,1,1,1]
注意:我们稍后将看到值的维数也是输出的维数。
[[0,0,1],[1,1,0],[0,1,0],[1,1,0]]
[[1,0,1],[1,0,0],[0,0,1],[0,1,1]]
[[0,2,0],[0,3,0],[1,0,3],[1,1,0]]
注意:在神经网络设置中,这些权重通常是小数,使用适当的随机分布(如高斯,Xavier和Kaiming分布)随机初始化。
[0,0,1][1,0,1,0] x [1,1,0] = [0,1,1] [0,1,0] [1,1,0] [0,0,1][0,2,0,2] x [1,1,0] = [4,4,0] [0,1,0] [1,1,0] [0,0,1][1,1,1,1] x [1,1,0] = [2,3,1] [0,1,0] [1,1,0] [0,0,1][1,0,1,0] [1,1,0] [0,1,1][0,2,0,2] x [0,1,0] = [4 ,4,0][1,1,1,1] [1,1,0] [2,3,1] [0,2,0][1,0,1,0] [0,3,0] [1,2,3][0,2,0,2] x [1,0,3] = [2 ,8,0][1,1,1,1] [1,1,0] [2,6,3] [1,0,1][1,0,1,0] [1,0,0] [1,0,2][0,2,0,2] x [0,0,1] = [2 ,2,2][1,1,1,1] [0,1,1] [2,1,3]

注意:实际上,可以将偏差向量添加到矩阵乘法的乘积中。
[0,4,2][1,0,2] x [1,4,3] = [2,4,4] [1,0,1]注意:以上操作被称为点产品注意,它是几种评分功能其中之一。其他评分功能包括缩放点积和添加/合并数组。
softmax([2,4,4])= [0.0,0.5,0.5]
1:0.0 * [1、2、3] = [0.0、0.0、0.0]2:0.5 * [2、8、0] = [1.0、4.0、0.0]3:0.5 * [2、6、3] = [1.0、3.0、1.5] [0.0,0.0,0.0]+ [1.0,4.0,0.0]+ [1.0,3.0,1.5]-----------------= [2.0,7.0,1.5]
注意:由于点积分数功能,查询和键的维必须始终相同。但是,值的维数可能不同于 查询和键。结果输出将遵循值的维度。
2.代码
import torch
x = [ [1, 0, 1, 0], # Input 1 [0, 2, 0, 2], # Input 2 [1, 1, 1, 1] # Input 3 ] x = torch.tensor(x, dtype=torch.float32)
w_key = [ [0, 0, 1], [1, 1, 0], [0, 1, 0], [1, 1, 0] ] w_query = [ [1, 0, 1], [1, 0, 0], [0, 0, 1], [0, 1, 1] ] w_value = [ [0, 2, 0], [0, 3, 0], [1, 0, 3], [1, 1, 0] ] w_key = torch.tensor(w_key, dtype=torch.float32) w_query = torch.tensor(w_query, dtype=torch.float32) w_value = torch.tensor(w_value, dtype=torch.float32)
keys = x @ w_key querys = x @ w_query values = x @ w_value
print(keys) # tensor([[0., 1., 1.], # [4., 4., 0.], # [2., 3., 1.]])
print(querys) # tensor([[1., 0., 2.], # [2., 2., 2.], # [2., 1., 3.]])
print(values) # tensor([[1., 2., 3.], # [2., 8., 0.], # [2., 6., 3.]
attn_scores = querys @ keys.T
# tensor([[ 2., 4., 4.], # attention scores from Query 1 # [ 4., 16., 12.], # attention scores from Query 2 # [ 4., 12., 10.]]) # attention scores from Query 3步骤5:计算softmax
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1) # tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01], # [6.0337e-06, 9.8201e-01, 1.7986e-02], # [2.9539e-04, 8.8054e-01, 1.1917e-01]])
# For readability, approximate the above as follows attn_scores_softmax = [ [0.0, 0.5, 0.5], [0.0, 1.0, 0.0], [0.0, 0.9, 0.1] ] attn_scores_softmax = torch.tensor(attn_scores_softmax
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
# tensor([[[0.0000, 0.0000, 0.0000], # [0.0000, 0.0000, 0.0000], # [0.0000, 0.0000, 0.0000]], # # [[1.0000, 4.0000, 0.0000], # [2.0000, 8.0000, 0.0000], # [1.8000, 7.2000, 0.0000]], # # [[1.0000, 3.0000, 1.5000], # [0.0000, 0.0000, 0.0000], # [0.2000, 0.6000, 0.3000]]])
outputs = weighted_values.sum(dim=0)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1 # [2.0000, 8.0000, 0.0000], # Output 2 # [2.0000, 7.8000, 0.3000]]) # Output 3
注意:PyTorch 为此提供了一个 API nn.MultiheadAttention。但是,此 API 要求你输入键、查询并估算 PyTorch 张量。此外,该模块的输出经过线性变换。
3.扩展到 Transfomers
尺寸 Bias
嵌入模块 位置编码 截断 掩蔽
多头 层堆叠
线性变换 层范数
参考文献
Attention Is All You Need https://arxiv.org/abs/1706.03762
Transfomer 图解:https://jalammar.github.io/illustrated-transformer/(jalammar.github.io)
(*本文为AI科技大本营翻译文章,转载请微信联系1092722531)
◆
精彩推荐
◆
开幕倒计时10天|2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。6.6 折票限时特惠(立减1400元),学生票仅 599 元!
高三学生发表AI论文,提出针对网络暴力问题的新模型AdaGCN
15篇论文全面概览BERT压缩方法
敲代码月薪 4 万?真相使我差点丢了性命!
这段 Python 代码让程序员赚 300W,公司已确认!网友:神操作!
2097352GB地图数据,AI技术酷炫渲染,《微软飞行模拟器》游戏即将上线
用Go重构C语言系统,这个抗住春晚红包的百度转发引擎承接了万亿流量
日均350000亿接入量,腾讯TubeMQ性能超过Kafka
看完这篇还不了解Nginx,那我就哭了!
网易患病员工被保安赶出公司,程序员该如何应对中年危机?
2019 年,C# 还值得学习吗?
区块链世界里不能信什么?
你点的每个“在看”,我都认真当成了AI
相关文章:
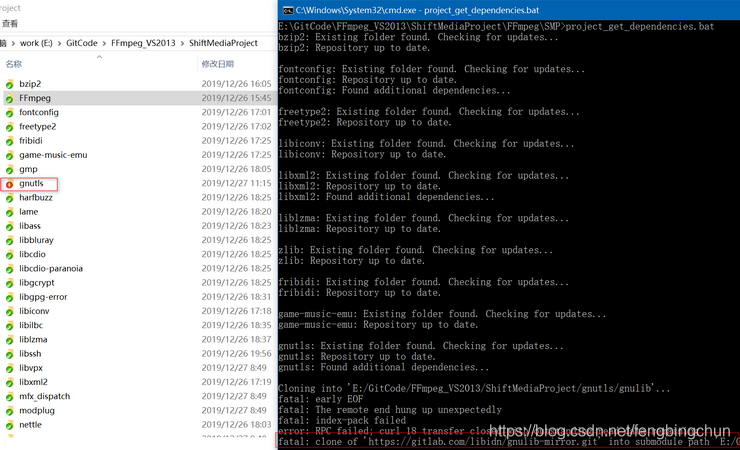
Windows上VS2017单步调试FFmpeg源码的方法
之前在https://blog.csdn.net/fengbingchun/article/details/90114411 介绍过如何在Windows7/10上通过MinGW方式编译FFmpeg 4.1.3源码生成库的步骤,那时只能生成最终的库,却不能产生vs工程,无法进行单步调试。GitHub上有个项目ShiftMediaProj…

ormlite 多表联合查询
ormlite 多表联合查询 QueryBuilder shopBrandQueryBuilder shopBrandDao.queryBuilder(); QueryBuilder shopQueryBuilder shopDao.queryBuilder();Where shopBrandWhere shopBrandQueryBuilder.where(); shopBrandWhere .eq(ShopBrand.SHOP_NO, shopNo);Where shopWhere …
C++中关键字volatile和mutable用法
C/C中的volatile关键字和const对应,用来修饰变量,用于告诉编译器该变量值是不稳定的,可能被更改。使用volatile注意事项: (1). 编译器会对带有volatile关键字的变量禁用优化(A volatile specifier is a hint to a compiler that …
基于生成对抗网络(GAN)的人脸变形(附链接) | CSDN博文精选
扫码参与CSDN“原力计划”翻译 | 张一豪校对 | 吴金笛来源 | 数据派THU*点击阅读原文,查看「CSDN原力计划」详细说明。本文详细介绍了生成对抗网络(GAN)的知识,并用其变换人脸,并探寻如何利用StyleGAN生成不同属性&…
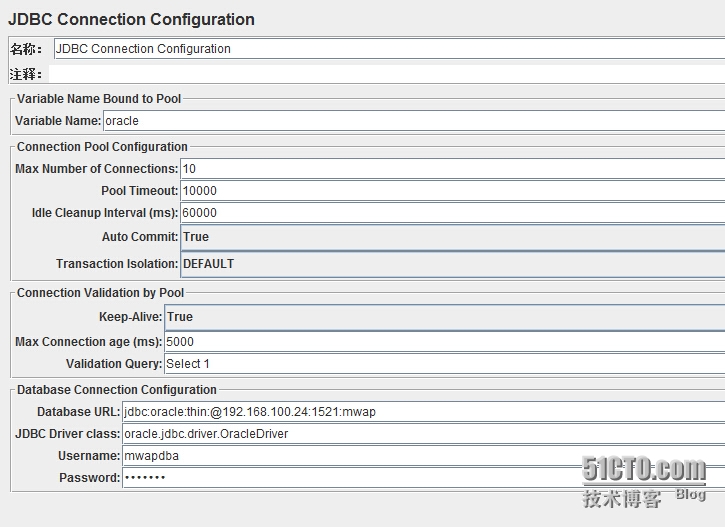
Jmeter连接Oracle数据库
一、Jmeter要连接oracle数据库,就必须复制JDBC驱动jar包文件ojdbc14.jar到Jmeter的lib目录下二、进入Jmeter的bin目录运行Jmeter.bat,启动Jmeter三、Jmeter软件配置如下:1、添加线程组右击线程组,选择“添加--配置元件--JDBC Conn…

swift3.0友盟分享
经过(一)的讲解,大家应该可以按照友盟提供的测试账号可以集成友盟分享了,友盟目前集合了18个APP共27种分享,可以授权的有10个App:微信、QQ、新浪微博、腾讯微博、人人网、豆瓣、Facebook、Twitter、Linkedi…
C++11中std::future的使用
C11中的std::future是一个模板类。std::future提供了一种用于访问异步操作结果的机制。std::future所引用的共享状态不能与任何其它异步返回的对象共享(与std::shared_future相反)( std::future references shared state that is not shared with any other asynchronous retur…
给算法工程师和研究员的「霸王餐」| 附招聘信息
现在的算法工程师真的是太难了!要让AI会看人眼都分辨不清的医疗影像!数据又不够,还得用前沿技术!好不容易学会看片,还要让AI会分析病理!然后模型搞出来了,还要把几十种模型,做N次计算…
swift3.0三种反向传值
一 :通知 1.通知传值所用方法 // MARK: - private methods(内部接口) let NotifMycation NSNotification.Name(rawValue:"MyNSNotification") func tempbuttonAction() { //这个方法可以传一个值 NotificationCenter.default.post(name: NotifMycation, object: &q…
C++11中std::shared_future的使用
C11中的std::shared_future是个模板类。与std::future类似,std::shared_future提供了一种访问异步操作结果的机制;不同于std::future,std::shared_future允许多个线程等待同一个共享状态;不同于std::future仅支持移动操作…
聊聊抖音、奈飞、Twitch、大疆、快手、B站的多媒体关键技术
随着5G牌照发放,5G终端正在迎来集中上市潮,对于5G带来的变革一触即发。目前互联网上超过七成的流量来自多媒体,未来这个比例将超过八成。音视频就像空气和水一样普及,深度到每个人的生活和工作中。同时,深度学习技术则…
Linux安全事件应急响应排查方法总结
Linux安全事件应急响应排查方法总结 Linux是服务器操作系统中最常用的操作系统,因为其拥有高性能、高扩展性、高安全性,受到了越来越多的运维人员追捧。但是针对Linux服务器操作系统的安全事件也非常多的。攻击方式主要是弱口令攻击、远程溢出攻击及其他…
C++11中std::packaged_task的使用
C11中的std::packaged_task是个模板类。std::packaged_task包装任何可调用目标(函数、lambda表达式、bind表达式、函数对象)以便它可以被异步调用。它的返回值或抛出的异常被存储于能通过std::future对象访问的共享状态中。 std::packaged_task类似于std::function,…

Swift3.0和OC桥接方法
1.直接在工程中commandn,出现如图,点击Header File创建桥接文件Bridging-Header.h,如图: 2.点击next,出现如图画面,一定要记得勾选第一项,再点击create创建完成。 3.配置桥接文件,点击target - …

量子算命,在线掷筊:一个IBM量子云计算机的应用实践,代码都有了
整理 | Jane 出品| AI科技大本营(ID:rgznai100) “算命”,古今中外,亘古不衰的一门学问,哪怕到了今天,大家对算命占卜都抱着一些”敬畏“的信任心理,西方流行塔罗牌,国…
rails应用ajax之二:使用rails自身支持
考虑另一种情况: 1. 页面上半部分显示当前的所有用户,页面下半部分是输入新用户的界面; 2. 每当输入新用户时,页面上半部分会动态更新新加用户的内容; 我们还是用ajax实现,不过这次用rails内部对ajax的支持…
C++11中std::async的使用
C11中的std::async是个模板函数。std::async异步调用函数,在某个时候以Args作为参数(可变长参数)调用Fn,无需等待Fn执行完成就可返回,返回结果是个std::future对象。Fn返回的值可通过std::future对象的get成员函数获取。一旦完成Fn的执行&…
BAT数据披露:缺人!110万AI人才缺口,两者矛盾,凉凉了!
人工智能到底有多火?近日国内首份《BAT人工智能领域人才发展报告》新鲜出炉,此次报告是针对国内人工智能领域的人才争夺情况进行了梳理。并把研究对象锁定在BAT三大巨头的身上。来源:《BAT人工智能领域人才发展报告》其中得出最为核心的结论&…
swift3.0最新拨打电话方法
let alertVC : UIAlertController UIAlertController.init(title: "是否拨打报警电话:10086", message: "", preferredStyle: .alert) let falseAA : UIAlertAction UIAlertAction.init(title: "取消", style: .cancel, handler: nil) let tr…
关于手机已处理里重复单据的处理办法
更新视图 VWFE_TASK去掉 union TWFE_TASK_BAK 的部分,原因是因为后面做了流程预演导致的问题转载于:https://blog.51cto.com/iderun/1602828
swiftswift3.0自己封装的快速构建页面的方法
//#param mark 控件 func creatLabel(frame:CGRect,text:String,textColor:UIColor,textFont:CGFloat,textAlignment:NSTextAlignment) -> UILabel { let label UILabel.init(frame: frame) label.text text label.textColor textColor label.font UIFont.systemFont(of…
Google是如何做Code Review的?| CSDN原力计划
作者 | 帅昕 xindoo 编辑 | 屠敏出品 | CSDN 博客我和几个小伙伴一起翻译了Google前一段时间放出来的Google’s Engineering Practices documentation(https://github.com/google/eng-practices),翻译后的GitHub仓库:https://gith…
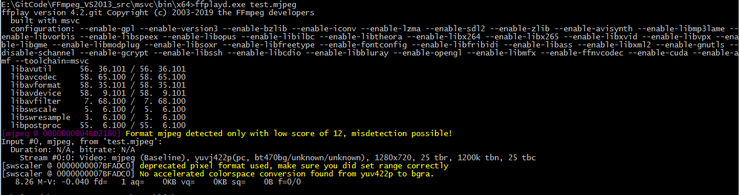
从FFmpeg 4. 2源码中提取dshow mjpeg code步骤
之前在https://blog.csdn.net/fengbingchun/article/details/103735560 中介绍过在Windows上通过vs2017编译FFmpeg源码进行单步调试的步骤,为了进一步熟悉FFmpeg这里以提取FFmpeg dshow mjpeg源码为例介绍其实现过程及注意事项: FFmpeg是用C实现的&…
ControlButton按钮事件
#ifndef __HControlButton_H__#define __HControlButton_H__#include "cocos2d.h"#include "cocos-ext.h"USING_NS_CC;USING_NS_CC_EXT; //用于标识当前按钮的状态typedef enum{ touch_begin, touch_down, touch_up,}tagForTouch;class HControlB…
swift3.0UIAlertController使用方法
let alertVC : UIAlertController UIAlertController.init(title: "添加照片", message: "", preferredStyle: .actionSheet) let cleanAction UIAlertAction(title: "取消", style: UIAlertActionStyle.cancel,handler:nil) let photoActi…

Doxygen使用介绍
Doxygen的主页为http://doxygen.nl/,它的license为GPL,最新发布版本为1.8.17,源代码存放在https://github.com/doxygen/doxygen,它支持的语言包括C、C、Objective-C、C#、Java、Python等,它支持的系统平台包括Winodws、…
云计算软件生态圈:摸到一把大牌
作者 | 老姜编辑 | 阿秃出品 | CSDN云计算(ID:CSDNcloud)“我觉得我摸着了一把大牌。”软件领域的新锐企业——有赞公司创始人兼CEO白鸦在转向SaaS领域的一个细分市场时,曾对天使投资人这样说。而老牌软件企业金蝶创始人徐少春在2…

iOS封装HTTPS双向和单向验证
1.HttpsUtil (1) 对双向和单向验证的封装 #import <Foundation/Foundation.h> #import "AFNetworking.h" interface HttpsUtil : NSObject // 双向认证 (void)configHTTPSessionManager:(AFHTTPSessionManager *)manager serverCers:(NSArray *) serverCerNam…
开源库BearSSL介绍及使用
BearSSL是用C语言实现的SSL/TLS协议,它的源码可直接通过git clone https://www.bearssl.org/git/BearSSL 下载,它的license是MIT,最新版本为0.6。 BearSSL的主要特性是: (1). 正确且安全:对不安全的协议版本和算法选…