Redis源码解析——Zipmap
本文介绍的是Redis中Zipmap的原理和实现。(转载请指明出于breaksoftware的csdn博客)
基础结构
Zipmap是为了实现保存Pair(String,String)数据的结构,该结构包含一个头信息、一系列字符串对(之后把一个“字符串对”称为一个“元素”(ELE))和一个尾标记。用图形表示该结构就是:

Redis源码中并没有使用结构体来表达该结构。因为这个结构在内存中是连续的,而除了HEAD和红色背景的尾标记END(恒定是0xFF)是固定的8位,其他部分都是不定长的。
虽然HEAD信息是定长的,但是其内容表达却是两层意思。HEAD信息是用于保存元素个数信息的。比如该Zipmap只有0x12个元素,则HEAD的内容是0x12。而如果元素个数是0x1234,则内容是0xFE。那这种变化的分界岭是多少?是0xFE。如果元素个数小于0xFE,HEAD内容就是个数值。如果元素个数大于等于0xFE,HEAD内容是0xFE,表示该8位已经不表示元素个数,这个是否如果需要计算元素个数就需要遍历整个结构了。

元素的长度也是不确定的。这点比较好理解,因为元素保存的是一个字符串对,而字符串长度是无法确定的。那么我们再看看元素的结构

元素内容中一开始时记录的Key的长度信息——KeyLen Struct。如果长度小于0xFE,则该结构只有8位长,内容是长度值;如果大于等于0xFE,则该结构是40位长。其中前8位是0xFE,表示本位已经不能表示长度了。后32位则保存长度值

KeyData包含字符串的内容,其内容可以包含NULL,但是不会自动在末尾追加NULL。该规则也符合ValueData。
Key内容之后跟着的是Value的长度信息。其组织方式和Key长度信息的组织方式是一样的。

最后再来说说比较神奇的Free字段。因为Zipmap会提供一个接口,让用户可以通过Key去修改Value的值,如果Value的值被改短了,则会有一定的空余空间,这个空余空间的长度就是Free的值。但是Zipmap就给Free字段留了8位的空间,然而Value修改后空余的长度可能比0xFF还长。其实不用担心,因为如果Zipmap发现如果空余长度超过一定的值就会将之后的空间向前平移以节约空间,而这个阈值比0xFF小
#define ZIPMAP_VALUE_MAX_FREE 4明白上述结构后,阅读后面的代码就变得很简单了。
创建Zipmap
Redis提供了下面方法创建一个空的Zipmap结构。
unsigned char *zipmapNew(void) {unsigned char *zm = zmalloc(2);zm[0] = 0; /* Length */zm[1] = ZIPMAP_END;return zm;
}因为没有元素,所以长度信息为0。而紧跟其后的便是结尾标记

长度信息编码
Zipmap中元素的Key长度信息和Value长度信息都是需要根据值的大小而动态改变。如果值小于0xFE,则只有8位表示长度,且内容就是长度值。而如果长度大于0xFE,则有40位表示长度信息,其前8位内容是0xFE,后32位是值内容。
static unsigned int zipmapEncodeLength(unsigned char *p, unsigned int len) {if (p == NULL) {return ZIPMAP_LEN_BYTES(len);} else {if (len < ZIPMAP_BIGLEN) {p[0] = len;return 1;} else {p[0] = ZIPMAP_BIGLEN;memcpy(p+1,&len,sizeof(len));memrev32ifbe(p+1);return 1+sizeof(len);}}
}如果第一个参数传NULL,则该函数是用于根据第二个参数决定需要多长的空间去存储长度信息。如果第一个参数有值,则根据第二个参数决定在该地址的不同偏移位置设置相应的值。
#define ZIPMAP_BIGLEN 254
#define ZIPMAP_END 255
#define ZIPMAP_LEN_BYTES(_l) (((_l) < ZIPMAP_BIGLEN) ? 1 : sizeof(unsigned int)+1)长度信息解码
长度信息解码是对编码做的逆向操作。它判断传入的长度信息起始地址的内容是否小于0xFE。如果是则该8位就是长度值;否则后移8位,之后的32位才是长度值。
static unsigned int zipmapDecodeLength(unsigned char *p) {unsigned int len = *p;if (len < ZIPMAP_BIGLEN) return len;memcpy(&len,p+1,sizeof(unsigned int));memrev32ifbe(&len);return len;
}计算Key长度信息和Key内容的整体长度
对应于上图就是计算KeyLen Struct和KeyData的长度和
计算方法就是通过获取的KeyData长度计算出KeyLen Struct的长度,然后将两个长度相加

static unsigned int zipmapRawKeyLength(unsigned char *p) {unsigned int l = zipmapDecodeLength(p);return zipmapEncodeLength(NULL,l) + l;
}计算Value长度信息,Free和Value内容的整体长度
对应于上图就是计算ValueLen Struct、Free、FreeData和ValueData的长度和

static unsigned int zipmapRawValueLength(unsigned char *p) {unsigned int l = zipmapDecodeLength(p);unsigned int used;used = zipmapEncodeLength(NULL,l);used += p[used] + 1 + l;return used;
}used参数第一次赋值时,它代表ValueLen Struct的长度。于是p[used]取出的就是Free的内容,即FreeData的长度。计算和的操作中再加上1,是Free字段的长度——sizeof(char)。
计算元素长度
只要把上面两个方法一叠加便是元素长度。唯一要做变通的是计算Value相关长度时要让指针指向Value信息的首地址

static unsigned int zipmapRawEntryLength(unsigned char *p) {unsigned int l = zipmapRawKeyLength(p);return l + zipmapRawValueLength(p+l);
}
通过Key和Value长度计算保存该元素时需要的最短长度
因为KeyLen Struct和ValueLen Struct的最低长度是一个字节,Free字段占一个字节。于是至少需要如下算法的长度
static unsigned long zipmapRequiredLength(unsigned int klen, unsigned int vlen) {unsigned int l;l = klen+vlen+3;但是如果Key或Value的长度大于等于0xFE,则还需要4字节表示真实长度
if (klen >= ZIPMAP_BIGLEN) l += 4;if (vlen >= ZIPMAP_BIGLEN) l += 4;return l;
}查找元素、计算Zipmap总长
Zipmap提供了一个方法来完成两个功能。因为这两种方法都需要进行遍历操作,所以索性放在一块。
static unsigned char *zipmapLookupRaw(unsigned char *zm, unsigned char *key, unsigned int klen, unsigned int *totlen) {unsigned char *p = zm+1, *k = NULL;unsigned int l,llen;如果Key字段指向一个待对比的字符串,则之后会通过对比查找Key对应的元素首地址。如果totlen不为NULL,则会顺带计算出Zipmap结构的总长。一开始时,p在Zipmap首地址上前进8位是为了过掉HEAD结构,直接指向元素首地址。相似的方法还有
unsigned char *zipmapRewind(unsigned char *zm) {return zm+1;
}之后要获取Key长度。如果Key长度和传入的klen不一样,则可以肯定的是Key不同,则不需要进行之后的字符串对比。着算是一种优化
while(*p != ZIPMAP_END) {unsigned char free;/* Match or skip the key */l = zipmapDecodeLength(p);llen = zipmapEncodeLength(NULL,l);对比操作要看Key长度和内容是否都一致。如果一致,则视totlen是否为NULL,决定是否继续遍历。因为totlen为NULL,则说明不需要计算Zipmap总长,这个时候直接返回元素首地址即可。如果不为NULL,则要记录下当前找到的元素首地址到k变量中,这样在之后遍历中,就可以通过变量k知道元素已经找到,不需要进行对比操作了。
if (key != NULL && k == NULL && l == klen && !memcmp(p+llen,key,l)) {/* Only return when the user doesn't care* for the total length of the zipmap. */if (totlen != NULL) {k = p;} else {return p;}}如果没有匹配上,则计算Value相关信息的长度。然后跳到下个元素的首地址。
p += llen+l;/* Skip the value as well */l = zipmapDecodeLength(p);p += zipmapEncodeLength(NULL,l);free = p[0];p += l+1+free; /* +1 to skip the free byte */}最后根据totlen是否为NULL,计算Zipmap总长。计算时加1是为了把之前过掉HEAD结构的长度给补上。
if (totlen != NULL) *totlen = (unsigned int)(p-zm)+1;return k;
}Zipmap还提供了下面的方法计算结构总长,当然它只是对zipmapLookupRaw的封装
size_t zipmapBlobLen(unsigned char *zm) {unsigned int totlen;zipmapLookupRaw(zm,NULL,0,&totlen);return totlen;
}检测元素是否存在
检测的方法也是封装了zipmapLookupRaw,然后判断其是否找到元素的首地址
int zipmapExists(unsigned char *zm, unsigned char *key, unsigned int klen) {return zipmapLookupRaw(zm,key,klen,NULL) != NULL;
}通过Key获取Value值
首先通过zipmapLookupRaw方法确定该Key在Zipmap中。如果不存在则返回NULL,如果存在则让指针指向Value信息处
int zipmapGet(unsigned char *zm, unsigned char *key, unsigned int klen, unsigned char **value, unsigned int *vlen) {unsigned char *p;if ((p = zipmapLookupRaw(zm,key,klen,NULL)) == NULL) return 0;p += zipmapRawKeyLength(p);*vlen = zipmapDecodeLength(p);*value = p + ZIPMAP_LEN_BYTES(*vlen) + 1;return 1;
}注意这个函数也返回了Value的长度,所以说Value可以存储包含NULL的数据。
遍历Zipmap
遍历前需要调用zipmapRewind让指针指向元素首地址,然后调用下面方法
unsigned char *zipmapNext(unsigned char *zm, unsigned char **key, unsigned int *klen, unsigned char **value, unsigned int *vlen) {if (zm[0] == ZIPMAP_END) return NULL;if (key) {*key = zm;*klen = zipmapDecodeLength(zm);*key += ZIPMAP_LEN_BYTES(*klen);}zm += zipmapRawKeyLength(zm);if (value) {*value = zm+1;*vlen = zipmapDecodeLength(zm);*value += ZIPMAP_LEN_BYTES(*vlen);}zm += zipmapRawValueLength(zm);return zm;
}上述方法通过用于接收Key和Value的指针是否为NULL决定是否需要把它们的信息返回出去。其中第10行加1操作实则是过掉Free占用的一个字节。
调用上面函数遍历的方法是:
unsigned char *i = zipmapRewind(my_zipmap);while((i = zipmapNext(i,&key,&klen,&value,&vlen)) != NULL) {printf("%d bytes key at $p\n", klen, key);printf("%d bytes value at $p\n", vlen, value);}获取元素个数
之前我们介绍基础结构时说过。如果元素个数少于0xFE,则结构首地址保存的数值就是元素个数值。如果大于等于0xFE,则要遍历整个结构
unsigned int zipmapLen(unsigned char *zm) {unsigned int len = 0;if (zm[0] < ZIPMAP_BIGLEN) {len = zm[0];} else {unsigned char *p = zipmapRewind(zm);while((p = zipmapNext(p,NULL,NULL,NULL,NULL)) != NULL) len++;/* Re-store length if small enough */if (len < ZIPMAP_BIGLEN) zm[0] = len;}return len;
}重分配Zipmap空间
重分配操作除了重新分配空间外,还要将结尾符设置。
static inline unsigned char *zipmapResize(unsigned char *zm, unsigned int len) {zm = zrealloc(zm, len);zm[len-1] = ZIPMAP_END;return zm;
}删除元素
删除元素前先需要找到该元素的起始地址
unsigned char *zipmapDel(unsigned char *zm, unsigned char *key, unsigned int klen, int *deleted) {unsigned int zmlen, freelen;unsigned char *p = zipmapLookupRaw(zm,key,klen,&zmlen);if (p) {如果找到,则计算这个元素的长度
freelen = zipmapRawEntryLength(p);然后将该元素之后的内容,除了结尾符0xFE,向前移动到该元素的起始地址
memmove(p, p+freelen, zmlen-((p-zm)+freelen+1));接着重分配Zipmap结构的空间,以节约空间。zipmapResize方法还辅助性的把结尾符给设置上了。
zm = zipmapResize(zm, zmlen-freelen);接着判断元素个数是否在0xFE之内。如果在,则让Zipmap结构首地址对应的数值减少1
/* Decrease zipmap length */if (zm[0] < ZIPMAP_BIGLEN) zm[0]--;if (deleted) *deleted = 1;} else {if (deleted) *deleted = 0;}return zm;
}增加、修改元素
如果通过zipmapSet方法传入的Key在Zipmap中,则是要求修改该Key对应的Value值;如果不在Zipmap中,则是新增元素。
首先通过Key和Value的长度计算出存储该字符串对最少需要多少空间
unsigned char *zipmapSet(unsigned char *zm, unsigned char *key, unsigned int klen, unsigned char *val, unsigned int vlen, int *update) {unsigned int zmlen, offset;unsigned int freelen, reqlen = zipmapRequiredLength(klen,vlen);unsigned int empty, vempty;unsigned char *p;然后判断Key是否在Zipmap中,并计算出Zipmap的结构总长
freelen = reqlen;if (update) *update = 0;p = zipmapLookupRaw(zm,key,klen,&zmlen);如果Key不存在,则需要新增元素。这个时候需要重新给Zipmap分配更大的空间,并将需要新增元素的位置指针指向结尾符——即在尾部追加元素。还要让元素个数自增
if (p == NULL) {/* Key not found: enlarge */zm = zipmapResize(zm, zmlen+reqlen);p = zm+zmlen-1;zmlen = zmlen+reqlen;/* Increase zipmap length (this is an insert) */if (zm[0] < ZIPMAP_BIGLEN) zm[0]++;}如果Key存在,则是更新Value。这个时候需要计算找到的元素的总长,如果总长比修改后需要的最短长度要短,则需要重新分配Zipmap空间。并把原来元素之后的内容向后平移。
else {/* Key found. Is there enough space for the new value? *//* Compute the total length: */if (update) *update = 1;freelen = zipmapRawEntryLength(p);if (freelen < reqlen) {/* Store the offset of this key within the current zipmap, so* it can be resized. Then, move the tail backwards so this* pair fits at the current position. */offset = p-zm;zm = zipmapResize(zm, zmlen-freelen+reqlen);p = zm+offset;/* The +1 in the number of bytes to be moved is caused by the* end-of-zipmap byte. Note: the *original* zmlen is used. */memmove(p+reqlen, p+freelen, zmlen-(offset+freelen+1));zmlen = zmlen-freelen+reqlen;freelen = reqlen;}}如果当前元素的总长度比修改后需要的最短长度要长,则说明是Value字符串长度要变短。这个时候要计算空余出来的空间是否大于ZIPMAP_VALUE_MAX_FREE,如果大于则要缩减Zipmap结构空间。
empty = freelen-reqlen;if (empty >= ZIPMAP_VALUE_MAX_FREE) {/* First, move the tail <empty> bytes to the front, then resize* the zipmap to be <empty> bytes smaller. */offset = p-zm;memmove(p+reqlen, p+freelen, zmlen-(offset+freelen+1));zmlen -= empty;zm = zipmapResize(zm, zmlen);p = zm+offset;vempty = 0;} else {vempty = empty;}如果空余出来的空间很短,就不要做内存重分配的工作了。这样就是之前结构中Free和FreeData的由来。这也说明FreeData中的数据是不确定的——即它是之前内容的一部分。
最后将Key,Value和Free字段放入相应的空间中
/* Just write the key + value and we are done. *//* Key: */p += zipmapEncodeLength(p,klen);memcpy(p,key,klen);p += klen;/* Value: */p += zipmapEncodeLength(p,vlen);*p++ = vempty;memcpy(p,val,vlen);return zm;
}相关文章:

IIS7入门之旅:(3)CGI application和FastCGI application的区别
前言: 一如既往地,IIS支持通过提供pluggable module来提供对第3方script的支持,例如php等。在IIS7中,对于CGI的支持有了一个新的变化,就是同时提供了2种CGI支持模块,分别为:CGIModule (cgi.dll)和FastCGIMo…

抗击疫情!阿里云为加速新药疫苗研发提供免费AI算力
1月29日,阿里云正式宣布:疫情期间,向全球公共科研机构免费开放一切AI算力,以加速本次新型肺炎新药和疫苗研发。 目前,中国疾控中心已成功分离病毒,疫苗研发和药物筛选仍在争分夺秒地进行。新药和疫苗研发期…
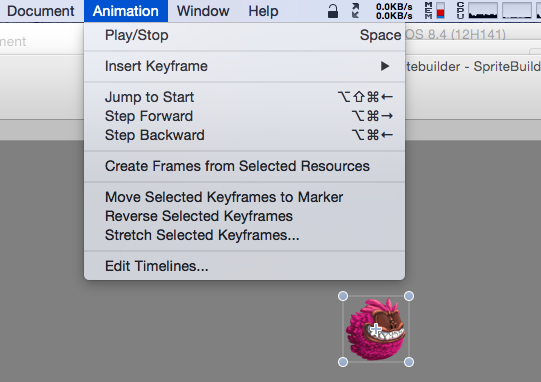
SpriteBuilder中如何平均拉伸精灵帧动画的距离
首先要在Timeline中选中所有的精灵帧,可以通过如下2种的任意一种办法达成: 1按下Shift键的同时鼠标单击它们 2鼠标在Timeline空白区拖拽直到拉出的矩形包围住所有精灵帧方块后放开鼠标。 你可以通过查看Timeline中精灵帧方块上是否有阴影来辨识是否选中…
C++拾趣——类构造函数的隐式转换
之前看过一些批判C的文章,大致意思是它包含了太多的“奇技淫巧”,并不是一门好的语言。我对这个“奇技淫巧”的描述颇感兴趣,因为按照批判者的说法,C的一些特性恰巧可以让一些炫耀技术的同学有了炫耀的资本——毕竟路人皆知的东西…
数十名工程师作战5天,阿里达摩院连夜研发智能疫情机器人
作者 | Just出品 | AI科技大本营(ID:rgznai100)新型肺炎疫情防控战在各大互联网科技公司拉响,阿里、百度等公司陆续对外提供相应技术和产品。当前,疫情当前防控一线人员紧缺,多地政务热线迎来大波问询市民,…

路由器互联端口处于不同网段的路由方法和原理
如下图:两台cisco路由器相连接的两个端口不在同一个网络,如何实现两台路由器的互联?初看似乎绝对不可能,但是这是可行的,而且我已经把这个变成了现实。这里讲述配置的方法,以及解释原理。这个就要讲到路由原…

上网行为管理产品选型简单考量
信息化浪潮汹涌向前,人们的生活、工作、学习越来越离不开IT,离不开网络。 对于很多组织来讲,网络就意味着效率、甚至生产力,协同办公、决策、科研、资金划拨等等都对网络有了前所未有的依赖。网络应用日益复杂、多变、动态特征发展…

码农技术炒股之路——配置管理器、日志管理器
配置管理器和日志管理器是项目中最为独立的模块。我们可以很方便将其剥离出来供其他Python工程使用。文件的重点将是介绍Python单例和logging模块的使用。(转载请指明出于breaksoftware的csdn博客) 配置管理器 在《码农技术炒股之路——架构和设计》中我…
“数学不好,干啥都不行!”资深程序员:别再瞎努力了!
之前很多程序员读者向我们反馈:1)做算法优化时,只能现搬书里的算法,遇到不一样的问题,就不会了。2)面试一旦涉及到算法和数据结构,如果数学不行,面试基本就凉凉了。3)算法…

受限列表 队列与栈
2019独角兽企业重金招聘Python工程师标准>>> 队列与栈为受限列表,队列为先入先出型列表,而栈为先入后出型列表,有关列表的实现可以查看 http://my.oschina.net/u/2011113/blog/514713 。 结构图为 Queue实现了IQueue接口ÿ…

码农技术炒股之路——数据库管理器、正则表达式管理器
我选用的数据库是Mysql。选用它是因为其可以满足我的需求,而且资料多。因为作为第三方工具,难免有一些配置问题。所以本文也会讲解一些和Mysql配置及开发相关的问题。(转载请指明出于breaksoftware的csdn博客) 数据库管理器 Mysq…

Overview of ISA and TMG Networking and ISA Networking Case Study (Part 1)
老方说:此篇文章摘自ISASERVER.ORG网站,出自Thomas Shinder达人之手。严重建议ISA爱好者看看。Published: Dec 16, 2008 Updated: Jan 21, 2009 Author: Thomas Shinder What ISA/TMG firewall Networks are about and how the firewall uses these ne…
阿里云免费开放一切AI算力,加速新型冠状病毒新药和疫苗研发
近日,阿里云宣布,为了帮助加速新药和疫苗研发,将向全球公共科研机构免费开放一切AI算力。目前,中国疾控中心已成功分离病毒,疫苗研发和药物筛选仍在争分夺秒地进行。新药和疫苗研发期间,需要进行大量的数据…
ASP.net(C#)批量上传图片(完整版)
来自:http://blog.itpub.net/9869521/viewspace-667955/ 这篇关于ASP.Net批量上传图片的文章写得非常好,偶尔在网上看到想转载到这里,却费劲了周折。为了更新这篇文章,我用了近半个小时,网上的转载都残缺不全ÿ…
码农技术炒股之路——任务管理器
系统任务和普通任务都是通过任务管理器调度的。它们的区别是:系统任务在程序运行后即不会被修改,而普通任务则会被修改。(转载请指明出于breaksoftware的csdn博客) 为什么要有这样的设计?因为我希望它是一个可以不用停…
面对新型肺炎疫情,AI能做什么?
作者 | 马超出品 | AI科技大本营(ID:rgznai100)根据最新的新型冠状病毒疫情通报,截至1月30日24时,国家卫生健康委公布确诊病例9692例,重症病例1527例,累计死亡病例213例,另有疑似病例15238例。为…
大家帮忙.谢谢!..(急急急急急)
大家帮忙.谢谢!..(急急急急急) Delphi / Windows SDK/APIhttp://www.delphi2007.net/DelphiDB/html/delphi_20061218224617231.htmlprocedure TForm1.Button4Click(Sender: TObject); var P : pstring; i, j : integer; begin GetMem(p, sizeof(stri…
HDU4866 Shooting (要持久段树)
意甲冠军: 给你一些并行x行轴。总是询问坐标x的顶部之前,k一个段高度,。标题是必须在线。思路: 首先要会可持久化线段树(又称主席树和函数式线段树)。不会的能够去做下POJ 2104。 把全部线段高度离散化,作为结点建线段…
C++过去的这一年
作者 | Bartek译者 | 苏本如,责编 | 屠敏出品 | CSDN(ID:CSDNnews)【导读】本文旨在让我们回顾 C 2019年里的变化和发展!我们将重点关注本年度里 C 上发生的重大事件,标准的发展,工具的变化等等…

码农技术炒股之路——抓取股票基本信息、实时交易信息、主力动向信息
从本节开始,我们开始介绍各个抓取和备份业务。(转载请指明出于breaksoftware的csdn博客) 因为我们数据库很多,数据库中表也很多,所以我们需要一个自动检测并创建数据库和表的功能。在《码农技术炒股之路——数据库管理…
TemplateBuilder
http://msdn.microsoft.com/zh-cn/vstudio/system.web.ui.templatebuilder_members(VS.85).aspx TemplateBuilder 成员TemplateBuilder 成员支持在生成模板及其包含的子控件时使用的页分析器。 下表列出了由 TemplateBuilder 类型公开的成员。 公共构造函数 名称 说明 Templat…
【iOS UI】iOS 9 GUI 资源分享
分享的内容包括一个【DesignCode-iOS-9-GUI】Sketch 文件, 和苹果官方释出的【SF-UI、SF-Compact】两种字体的安装包。 以上内容是正版、免费的 <a href "https://itunes.apple.com/cn/app/sketch-3/id852320343?mt12">Sketch</a> 是收费软…
反向R?削弱显著特征为细粒度分类带来提升 | AAAI 2020
作者 | VincentLee来源 | 晓飞的算法工程笔记导读:论文提出了类似于dropout作用的diversification block,通过抑制特征图的高响应区域来反向提高模型的特征提取能力,在损失函数方面,提出专注于top-k类别的gradient-boosting loss来…

C#初学——doWhile
继续上面的学习,这次的是流程控制,用dowhile,代码如下,还是用语言选择来作为事例的。using System; using System.Collections.Generic; using System.Text; namespace ConsoleApplication9 { class Program { static void Main(s…
码农技术炒股之路——实时交易信息、主力动向信息分库备份
一般来说,一个股票信息应该保存在一张表中。但是由于我机器资源限制,且我希望尽快频率的抓取数据。所以每天我将所有股票的实时交易信息放在daily_temp库中的一个以日期命名的表中。主力动向信息也是如此。但是盘后分析股票时,我们会以单只股…
数据预处理(完整步骤)
原文:http://dataunion.org/5009.html 一:为什么要预处理数据?(1)现实世界的数据是肮脏的(不完整,含噪声,不一致)(2)没有高质量的数据,…
码农技术炒股之路——抓取日线数据、计算均线和除权数据
日线数据是股票每日收盘后的信息。这块数据不用实时抓取,所以并不占用宝贵的交易时间的资源。于是我们抓取完数据后直接往切片后的数据库中保存。(转载请指明出于breaksoftware的csdn博客) 抓取日线数据 我们先要获取今天有交易信息的股票代…
茫茫碌碌的日子
一连很好多天,都在为公司数据库基础构架升级的事情忙活着。升级的事情还是比较棘手的。需要升级硬件服务器,相关的存储,操作系统,数据库产品,涉及面非常多。当然烦心的事情就很多。作为线上生产系统,升级和…
Python PK C++,究竟谁更胜一筹?
作者 | Farhad Malik译者 | 弯月,编辑 | 屠敏来源 | CSDN(ID:CSDNnews)在编程生涯的早期阶段,我参与过一款C数学优化应用程序的开发,这个程序对性能的要求很高。至今我依然记得那段艰难的经历。在那个项目中…