码农技术炒股之路——抓取日线数据、计算均线和除权数据
日线数据是股票每日收盘后的信息。这块数据不用实时抓取,所以并不占用宝贵的交易时间的资源。于是我们抓取完数据后直接往切片后的数据库中保存。(转载请指明出于breaksoftware的csdn博客)
抓取日线数据
我们先要获取今天有交易信息的股票代码。因为存在股票停牌的情况,所以不需要这类股票信息
def _get_all_share_ids(self):date_info = time.strftime('%Y_%m_%d')trade_table_name = "trade_info_%s" % (date_info)share_ids = fetch_data.get_data(fetch_data.select_db("daily_temp", trade_table_name, ["share_id"],{}, pre = "distinct"))return share_ids然后通过股票ID从股票基本信息表中获取股票代码和市场类型等数据
def _get_all_share_ids_market_type(self):share_ids = self._get_all_share_ids()ids = []for share_id in share_ids:ids.append(share_id[0])share_ids = fetch_data.get_data(fetch_data.select_db("stock_db", "share_base_info", ["share_id", "market_type"],{"share_id":[ids, "in"]}))return share_ids然后就是抓取和保存数据
class update_stock_daily_info(job_base):def __init__(self):passdef run(self):share_id_market_type = self._get_all_share_ids_market_type()for id_market_type in share_id_market_type:share_id = id_market_type[0]market_type = id_market_type[1]self._query_save_data(share_id, market_type) LOG_INFO("run update_stock_daily_info")这次我们数据从网易抓取。这儿要非常感谢网易,它提供一个通过指定起始和截止日期的接口拉取历史日线数据。如果起始和截止选择今天,则拉取的是今天的数据。
def _get_data(self, market_type, id, start_time, end_time):url_format = """http://quotes.money.163.com/service/chddata.html?code=%d%s&start=%s&end=%s&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;PCHG;TURNOVER;VOTURNOVER;VATURNOVER"""url = url_format % (market_type, id, start_time, end_time)res = fetch_data.get_data(fetch_data.query_http(url))#res = res.decode("gbk").encode("utf-8")return res最开始时,我们是一条数据都没有的,于是我们选择从1990年1月1日开始。之后我们有数据了,则从有数据的最后一天开始算起。
def _get_start_time(self, share_id, table_name):stock_conn_manager_obj = stock_conn_manager()conn_name = stock_conn_manager_obj.get_conn_name(share_id)last_time = fetch_data.get_data(fetch_data.select_db(conn_name, table_name, ["time"], {}, extend="order by time desc limit 1"))if len(last_time) > 0:last_day = last_time[0][0]tz = pytz.timezone('Asia/Shanghai')last_day_obj = datetime.datetime.fromtimestamp(last_day, tz)while True:next_day_obj = last_day_obj + datetime.timedelta(days = 1)if next_day_obj.weekday() < 5:breaklast_day_obj = next_day_objtime_str = next_day_obj.strftime("%Y%m%d")else:time_str = "19900101"return time.mktime(time.strptime(time_str, '%Y%m%d'))获取一个区间的数据后,我们通过正则表达式对结果进行拆分
def _filter_data(self, data):data = data.replace("None", "0")filter_data = fetch_data.get_data(fetch_data.regular_split("quotes_money_163", data))if len(filter_data) > 0:del filter_data[0]useful_data = []for item in filter_data:if int(item[-2]) == 0:continuetime_str = item[0]time_int = time.mktime(time.strptime(time_str,'%Y-%m-%d'))item.insert(0, time_int)del item[2]del item[2]useful_data.append(item)return useful_data最后将数据保存到对应的表中
def _save_data(self, share_id, table_name, data):into_db_columns = ["time","time_str","today_close","today_high","today_low","today_open","yesterday_close","pchg","turnover_rate","volume","turnover"]columns_count = len(into_db_columns)for item in data:if len(item) != columns_count:LOG_INFO("%s length is not match for column length %d" %(str(item), columns_count))continuedel itemif 0 == len(data):returnstock_conn_manager_obj = stock_conn_manager()conn = stock_conn_manager_obj.get_conn(share_id)conn.insert_data(table_name, into_db_columns, data)计算均线数据
均线数据按类型分可以分为成交量均线和价格均线。按时间分可以分为5日、10日、20日、30日、60日、90日、120日、180日和360日均线。
为了方便计算,我引入了talib库
pip install TA-Lib -i http://pypi.douban.com/simple
首先获取所有股票代码以便之后枚举
class update_stock_daily_average_info(job_base):def __init__(self):passdef run(self):share_ids = self._get_all_share_ids()for share_id_item in share_ids:share_id = share_id_item[0]self._update_average(share_id) LOG_INFO("run update_stock_daily_average_info")def _get_all_share_ids(self):date_info = time.strftime('%Y_%m_%d')trade_table_name = "trade_info_%s" % (date_info)share_ids = fetch_data.get_data(fetch_data.select_db("daily_temp", trade_table_name, ["share_id"],{}, pre = "distinct"))return share_ids然后查询每支股票最后一次计算均线的日期。判断规则就是查看价格5日均线值是否为0。因为均线计算量非常大,所以我们不能野蛮的全部重算。每次都要基于上次计算成果进行增量计算。
def _get_ma_empty_start_time(self, share_id, table_name):stock_conn_manager_obj = stock_conn_manager()conn_name = stock_conn_manager_obj.get_conn_name(share_id)last_time = fetch_data.get_data(fetch_data.select_db(conn_name, table_name, ["time"], {"close_ma5":[0, "="]}, extend="order by time asc limit 1"))if len(last_time) > 0:last_day = last_time[0][0]tz = pytz.timezone('Asia/Shanghai')last_day_obj = datetime.datetime.fromtimestamp(last_day, tz)time_str = last_day_obj.strftime("%Y%m%d")return time.mktime(time.strptime(time_str, '%Y%m%d'))else:return 0因为我们代码中最多分析180日均线数据,所以日期要从上面函数得到的日前前推180日;如果之前没有180日数据,则返回最早的那天。如果是新股,则返回当日。
def _get_start_time(self, share_id, table_name, ma_empty_start_time):stock_conn_manager_obj = stock_conn_manager()conn_name = stock_conn_manager_obj.get_conn_name(share_id)last_time = fetch_data.get_data(fetch_data.select_db(conn_name, table_name, ["time"], {"time":[ma_empty_start_time, "<="]}, extend="order by time desc limit 180"))if len(last_time) > 0:last_day = last_time[-1][0]tz = pytz.timezone('Asia/Shanghai')last_day_obj = datetime.datetime.fromtimestamp(last_day, tz)time_str = last_day_obj.strftime("%Y%m%d")return time.mktime(time.strptime(time_str, '%Y%m%d'))else:return ma_empty_start_time下一步就是计算各个日期的均值
def _get_ma_data(self, ori_data, periods):ret_data = {}float_data = [float(x) for x in ori_data]for period in periods:data = talib.MA(numpy.array(float_data), timeperiod = period)data_list = data.tolist()data_list = self._filter_data(data_list)ret_data["%d" % period] = data_listreturn ret_data然后将计算结果保存到数组中并保存
def _calc_average_data(self, share_id, table_name):ma_empty_start_time_int = self._get_ma_empty_start_time(share_id, table_name)if ma_empty_start_time_int == 0:return []start_time_int = self._get_start_time(share_id, table_name, ma_empty_start_time_int)stock_info = self._get_close_volume(share_id, table_name, start_time_int)periods = [5, 10, 20, 30, 60, 90, 120, 150, 180]#periods = [90, 180]close_data = self._get_ma_data(stock_info["close"], periods)volume_data = self._get_ma_data(stock_info["volume"], periods)if len(stock_info["time"]) == len(close_data["180"]) and len(close_data["180"]) == len(volume_data["180"]):passelse:LOG_WARNING("calc %s daily average error" % share_id)returninfos = []data_len = len(stock_info["time"])for index in range(data_len):info = {}time_int = stock_info["time"][index]if time_int < ma_empty_start_time_int:continueinfo["time"] = time_intfor period in periods:info["close_ma%s" % period] = close_data["%s" % period][index]info["volume_ma%s" % period] = volume_data["%s" % period][index]infos.append(info)return infosdef _filter_data(self, data):for index in range(len(data)):if math.isnan(data[index]):data[index] = 0.01else:breakreturn datadef _save_data(self, share_id, table_name, data):if len(data) < 2:return stock_conn_manager_obj = stock_conn_manager()conn = stock_conn_manager_obj.get_conn(share_id)conn.update(table_name, data, ["time"])计算除权后均线数据
之前算的那些均值理论上来说是没什么用的!因为没有除权!这是我在对比我的数据和同花顺的数据之后得出的。于是只能再改改。
基本思路是要计算一个因子,因子=前一日数据中收盘价/今日数据中昨日收盘价。然后把除权日之前的价格都“乘以”该因子得出向后复权的价格,相应的把除权日之前的成交量都“除以”该因子得出向后复权的成交量。这样就会导致整个表进行一次更新(从后向前)。
有意思的是同花顺将成交量也“乘以”该因子,其实这个算法是错误的。举个例子,比如昨日股票收盘10元,成交量100股,则成交金额是1000元。今天除权,于是拉取数据中昨日的收盘价是5元。这样相当于单股价值缩水一半。那么因子是5/10=0.5。那么向后复权计算,昨日的股票收盘价是10*0,5=5元。成交量应该是100/0,5=200股。这样昨日的成交金额是5*200=1000。但是同花顺的算法昨日成交量100*0.5=50股,这明显是错误的。
最后贴上向后复权的算法
def _dividend_ori_data(self, share_id, from_table, to_table, start_time, compare = ">", yesterday_close = 0):ori_data = self._get_daily_info(share_id, from_table, start_time, compare)if 0 == len(ori_data):return 0if ori_data[0][6] == yesterday_close:return 0ex_dividend_ori = []pre_div_value = 1for item in ori_data:if 0 == yesterday_close:ex_dividend_ori.append(item)yesterday_close = item[6]continueif len(ex_dividend_ori) > 0:yesterday_close = ex_dividend_ori[-1][6]ori_close = item[2]if ori_close == 0 or yesterday_close == 0:div_value = pre_div_valueelse:if yesterday_close == ori_close:ex_dividend_ori.append(item)continuediv_value = yesterday_close/ori_closepre_div_value = div_valueex_dividend_ori.append([item[0], item[1], item[2] * div_value, item[3] * div_value,item[4] * div_value,item[5] * div_value,item[6] * div_value,item[7],item[8],item[9] / div_value,item[10]])stock_conn_manager_obj = stock_conn_manager()conn = stock_conn_manager_obj.get_conn(share_id)if from_table != to_table:conn.insert_data(to_table, self._table_keys, ex_dividend_ori)else:for info_value in ex_dividend_ori:infos = {}for index in range(len(self._table_keys)):infos[self._table_keys[index]] = info_value[index]conn.insert_onduplicate(to_table, infos, ["time"])conn.insert_onduplicate(to_table, {"close_ma5":0, "time":ex_dividend_ori[-1][0]}, ["time"])last_yesterday_close = ex_dividend_ori[-1][6]return last_yesterday_close 相关文章:

茫茫碌碌的日子
一连很好多天,都在为公司数据库基础构架升级的事情忙活着。升级的事情还是比较棘手的。需要升级硬件服务器,相关的存储,操作系统,数据库产品,涉及面非常多。当然烦心的事情就很多。作为线上生产系统,升级和…
Python PK C++,究竟谁更胜一筹?
作者 | Farhad Malik译者 | 弯月,编辑 | 屠敏来源 | CSDN(ID:CSDNnews)在编程生涯的早期阶段,我参与过一款C数学优化应用程序的开发,这个程序对性能的要求很高。至今我依然记得那段艰难的经历。在那个项目中…

oracle--查看表空间大小以及修改表空间大小
为什么80%的码农都做不了架构师?>>> 一.修改表空间大小 解决以上问题的办法:通过增大表空间即可解决,如下: Sql代码 使用dba用户登陆 sqlplus / as sysdba; 执行如下命令: SQL >…
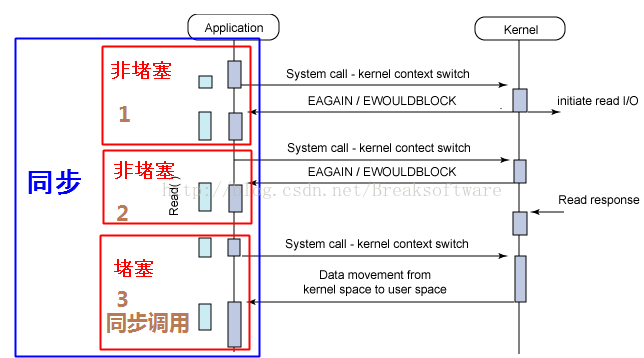
同步、异步、堵塞、非堵塞和函数调用及I/O之间的组合概念
在我们工作和学习中,经常会接触到“同步”、“异步”、“堵塞”和“非堵塞”这些概念,但是并不是每个人都能将它们的关系和区别说清楚。本文将对这些基本概念进行讨论,以期让大家有更清楚的认识。(转载请指明出于breaksoftware的c…
“抗击”新型肺炎!阿里达摩院研发AI算法,半小时完成疑似病例基因分析
利用技术辅助抗击疫情,阿里巴巴、百度等科技巨头各显身手。此前,AI科技大本营采访报道了阿里达摩院《数十名工程师作战5天,阿里达摩院连夜研发智能疫情机器人》一文,后者为了解决客服人力不足的局面,快速响应政府需求开…
反编译工具jad简单用法
反编译工具jad简单用法 下载地址:[url]http://58.251.57.206/down1?cidB99584EFA6154A13E5C0B273C3876BD4CC8CE672&t2&fmt&usrinput[/url]反编译工具jad &dt2002000一. 不用安装,只要解压就行(有这样两个文件jad.exe&#x…
ubuntu 系统设置bugzilla制
随着时间的推移。在大脑中形成的记忆总会慢慢的淡去。人的记忆力就是这样。所以最好的办法就是形成博客去记录下来,一方面给自己以后回想用。一方面也算是自己的一个积累。所以一旦选择了一个行业,最好不要轻 易转行,由于非常多知识须要不断的…
静态分析C语言生成函数调用关系的利器——cflow
除了《静态分析C语言生成函数调用关系的利器——calltree》一文中介绍的calltree,我们还可以借助cflow辅助我们阅读理解代码。(转载请指明出于breaksoftware的csdn博客) cflow的说明和安装cflow是一款静态分析C语言代码的工具,通过…
我在MongoDB年终大会上获二等奖文章:由数据迁移至MongoDB导致的数据不一致问题及解决方案...
作者 | 上海小胖来源 | Python专栏(ID:xpchuiit)故事背景企业现状2019年年初,我接到了一个神秘电话,电话那头竟然准确的说出了我的昵称:上海小胖。我想这事情不简单,就回了句:您好,我是小胖&…
注意String.Split的几个重载形式
String.Split应该是经常用到的一个函数了,经常的有下面两种形式 public string[] Split(char[] separator, StringSplitOptions options); public string[] Split(string[] separator, StringSplitOptions options); 1. 多数情况下我们会使用第一种,代码里可能这…
如何让猎头找到你
如何让猎头找到你
libev源码解析——总览
libev是个非常优秀的基于事件的循环库,很多开源软件,比如nodejs就是使用其实现基础功能。本系列将对该库进行源码分析。(转载请指明出于breaksoftware的csdn博客) 不知道是被墙了还是网站不再维护,它的官网(…
GPT-2仅是“反刍”知识,真正理解语言还要改弦更张
作者 | Gary Marcus译者 | 泓技编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】OpenAI的GPT-2正被广泛地讨论,无论是《纽约客》还是《经济学人》,我们都能看到有关它的话题。关于自然和人工智能,它想…
sap business one 笑谈
Sap Business .e 出生在以色列,生下来的时候父母给起了个小名叫SBO,据说他的亲生父母是SAP家庭里的一个重要成员,后来SAP家族里的长老认为SBO长得不错,挺好看的。毕竟SAP家族里生下来的儿子都是胖胖的,想要个瘦点长相好…
来51学院的第一天
【来51学院的第一天】转载于:https://blog.51cto.com/10801189/1703279

libev源码解析——监视器(watcher)结构和组织形式
在《libev源码解析——总览》中,我们介绍了libev的一些重要变量在不同编译参数下的定义位置。由于这些变量在多线程下没有同步问题,所以我们将问题简化,所提到的变量都是线程内部独有的,不用考虑任何多线程问题。(转载…

《评人工智能如何走向新阶段》后记(再续16)
由AI科技大本营下载自视觉中国181.5种常见的机器学习方法。 (1)线性回归linear regression: 一种流行的回归算法,从样本特征的线性组合,linear combination中学习模型。 (2)负数几率回归,logis…
怎么样才能快速的把淘宝店铺推广出去
我来到淘宝近一个月了,目前顺利地得到了两颗心心.感触颇多.其中店铺的推广显得尤其重要,应很多淘友的提问,我把一些店铺推广技巧介绍如下,你如果觉得有益,就回一下贴,以示支持.在这里先谢谢了!先看第一板斧:一、修练内功ÿ…
linux的ftp服务器
2019独角兽企业重金招聘Python工程师标准>>> ftp服务器在网上较为常见,Linux ftp命令的功能是用命令的方式来控制在本地机和远程机之间传送文件,这里详细介绍Linux ftp命令的一些经常使用的命令,相信掌握了这些使用Linux 进行ftp操…
使用Forms Authentication实现用户注册、登录 (二)用户注册与登录
从这一部分开始,我们将通过一个实际的完整示例来看一下如何实现用户注册与登录。在介绍注册与登录之前,我们首先介绍一下如何判断用户是否已登录,并未后面的示例编写一些基础代码。 判断用户是否已经登录首先,在Web站点项目中添加…

libev源码解析——调度策略
在《libev源码解析——监视器(watcher)结构和组织形式》中介绍过,监视器分为[2,-2]区间5个等级的优先级。等级为2的监视器最高优,然后依次递减。不区分监视器类型和关联的文件描述符的值,权限高的要优先于权限低的执行…
特斯拉AI团队招兵买马:“英雄不问出处”
2月3日,特斯拉创始人兼CEO埃隆•马斯克发布推特,贴出了Autopilot AI团队招聘人才的信息。马斯克在推特中表示,特斯拉AI团队将直接向马斯克回报,他几乎每天都会与团队保持沟通和交流,并透露团队base在德州奥斯汀。据特斯…
java中重载与重写的区别
最近了解一下重载和重写 一、重载(Overloading) (1) 方法重载是让类以统一的方式处理不同类型数据的一种手段。多个同名函数同时存在,具有不同的参数个数/类型。 重载Overloading是一个类中多态性的一种表现。 (2) Ja…

libev源码解析——I/O模型
在《libev源码解析——总览》一文中,我们介绍过,libev是一个基于事件的循环库。本文将介绍其和事件及循环之间的关系。(转载请指明出于breaksoftware的csdn博客) 目前ibev支持如下IO事件模型: select模型。对应文件是…
“数学不好,干啥都不行!”骨灰级程序员:其实你们都是瞎努力
之前有很多程序员读者向我们抱怨:1)做算法优化时,只能现搬书里的算法,遇到不一样的问题,就不会了。2)面试一旦涉及到算法和数据结构,如果数学不行,面试基本就凉凉了。3)一…

VISTA中注册表项LEGACY_****的删除
在VISTA中如果你错误安装了某个驱动软件,而如果这个驱动安装软件考虑不周,无法卸载,那么你就麻烦了!比如我的U盘以前一直使用优易U盘加密软件1.2来做一个隐蔽的U盘。某天我在VISTA上运行了这个U盘加密软件,这个软件运行…

nodejs这个过程POST求
下面是一个web登陆模拟过程。当我们问一个链接,你得到一个表格,然后填写相应的表格值,然后提交登陆。 var http require(http); var querystring require(querystring); http.createServer(function (request, response) {var responseStri…
FTP、HTTP断点续传和多线程的协议基础
使用FTP或HTTP协议的下载软件支持断点续传和多线程的协议基础是:FTP用的是REST和SIZE;HTTP用的是Range。1、FTP实现断点续传的协议基础REST(有的服务器可能不支持此命令)Syntax: REST positionSets the point at which a file tra…

libev源码解析——定时器原理
本文将回答《libev源码解析——I/O模型》中抛出的两个问题。(转载请指明出于breaksoftware的csdn博客) 对于问题1:为什么backend_poll函数需要指定超时?我们让其一直等待到有事件发生不是更好么? 答案是“必须要指定超…
AI颠覆经济世界作用被夸大?影响远比媒体头条报道更加复杂
来源 | The Gradient译者 | 刘畅编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100) 【导读】每天我们都听到有人声称人工智能将改变经济体系,造成大量的失业和垄断。但是,经济学家是如何看待的呢?在第三届AI经…