码农技术炒股之路——数据库管理器、正则表达式管理器
我选用的数据库是Mysql。选用它是因为其可以满足我的需求,而且资料多。因为作为第三方工具,难免有一些配置问题。所以本文也会讲解一些和Mysql配置及开发相关的问题。(转载请指明出于breaksoftware的csdn博客)
数据库管理器
Mysql的安装我就不说了。我先说说和我习惯相关的一个问题:我希望在我Windows系统上可以通过Navicat for Mysql连接到我Ubuntu上的Mysql服务器。这块问题的解决可以参见《允许ubuntu下mysql远程连接》。
然后需要准备Python下进行Mysql开发的一些环境
apt-get install python-dev
apt-get install libmysqld-dev
apt-get install libmysqlclient-dev
updatedb
locate mysql_config
pip install MySQL-python -i http://pypi.douban.com/simple
由于我们要进行分表,所以数据库连接数要进行增大。于是需要修改mysql的配置
max_connections=1000
基础环境配置好后,我们就可以开始进行数据库管理器的设计和实现了。
数据库连接类
数据库连接我们使用PooledDB连接池,使用这个库的最大好处是我们可以不用考虑很多底层的重连和多线程问题。
from DBUtils.PooledDB import PooledDB
class mysql_conn():def __init__(self, host_name, port_num, user_name, password, db_name, charset_name = "utf8"):self._host = host_nameself._port = int(port_num)self._user = user_nameself._passwd = passwordself._db = db_nameself._charset = charset_nameself._pool = Noneself._table_info = {}self.re_connect()re_connect方法要考虑数据库不存在的情况。
def re_connect(self):self._try_close_connect()try:self._pool = PooledDB(creator=MySQLdb, mincached=1, maxcached=20, maxconnections = 3, host = self._host, port = self._port, user = self._user, passwd = self._passwd, db = self._db, charset = self._charset)LOG_INFO("connect %s success" %(self._db))self.refresh_tables_info()returnexcept MySQLdb.Error, e :if e.args[0] == 1049:self._create_db()else:LOG_WARNING("%s connect error %s" % (self._db, str(e)))returnexcept Exception as e:LOG_WARNING("connect mysql %s:%d %s error" % (self._host, self._port, self._db))return 如果数据库不存在,MySQLdb.Error对象的值是1049,这种场景我们就需要创建数据库。如果发生其他错误,就直接报错
def _create_db(self):conn = Nonecursor = Nonetry:conn = MySQLdb.connect(host=self._host, port=self._port, user=self._user, passwd=self._passwd)cursor = conn.cursor()sql = """create database if not exists %s""" %(self._db)#LOG_INFO(sql)cursor.execute(sql)conn.select_db(self._db);conn.commit()except MySQLdb.Error, e :LOG_WARNING("%s execute error %s" % (sql, str(e)))finally:try:if cursor:cursor.close()if conn:conn.close()except:pass创建完数据后,要关闭连接。然后再走一遍数据库连接过程,但是这次就用不判断数据库是否存在了
try:self._pool = PooledDB(creator=MySQLdb, mincached=1, maxcached=20, maxconnections = 3, host = self._host, port = self._port, user = self._user, passwd = self._passwd, db = self._db, charset = self._charset)LOG_INFO("connect %s success" %(self._db))self.refresh_tables_info()returnexcept Exception as e:LOG_WARNING("connect mysql %s:%d %s error" % (self._host, self._port, self._db))returnif None == self._pool:LOG_WARNING("connect mysql %s:%d %s error" % (self._host, self._port, self._db))return连接完数据库后,我们需要通过refresh_tables_info获取该库中表的信息。为什么我们需要获取这个信息呢?因为我希望在调用数据库操作时,mysql_conn类已经知晓一些字段的类型和长度,这样就可以将用户传入的数据进行相应的格式化,而从让调用者不用太多关心表字段类型。
def refresh_tables_info(self):self._table_info = self._get_tables_info()def _get_tables_info(self):tables_info = {}tables_sql = "show tables"tables_name = self.execute(tables_sql, select = True)for table_name_item in tables_name:table_name = table_name_item[0]if 0 == len(table_name):continuecolumns_sql = "show columns from " + table_name table_info = self.execute(columns_sql, select = True)table_name = table_name_item[0]columns_info = self._get_table_info(table_info)if len(columns_info):tables_info[table_name] = columns_inforeturn tables_infodef _get_table_info(self, table_info):columns_info = {}for item in table_info:column_name = item[0]column_type_info = item[1](type, len) = self._get_column_type_info(column_type_info)columns_info[column_name] = {"type":type, "length":len}return columns_infodef _get_column_type_info(self, type_info):re_str = '(\w*)\((\d*),?.*\)'kw = re.findall(re_str, type_info)if len(kw):if len(kw[0]) > 1:return (kw[0][0], kw[0][1])return (None, None)连接完数据库后,我们需要对表进行一系列操作,比如表查询
def select(self, table_name, fields_array, conditions, pre = "", extend = ""):fields_str = "," . join(fields_array)conds = []for (column_name, column_data_info) in conditions.items():column_type = self._get_column_type(table_name, column_name)column_data = column_data_info[0]operation = column_data_info[1]if isinstance(column_data, list):new_datas = []for item in column_data:new_data = self._conv_data(item, column_type)try:new_datas.append(new_data)except:LOG_WARNING("%s %s conv error" %(item, column_type))temp_str = "," . join(new_datas)cond = column_name + " " + operation + " (" + temp_str + ")"conds.append(cond)else:new_data = self._conv_data(column_data, column_type)try:cond = column_name + " " + operation + " " + new_dataconds.append(cond)except:LOG_WARNING("%s %s conv error" %(column_data, column_type))conds_str = " and " . join(conds)sql = "select " + pre + " " + fields_str + " from " + table_nameif len(conds_str) > 0:sql = sql + " where " + conds_strif len(extend) > 0:sql = sql + " " + extenddata_info = self.execute(sql, select = True)return data_infoselect方法中table_name是表名;fields_array是需要查询的字段数组;conditions是查询条件的Key/Value对,其中Key是字段名称,Value是个数组,数组的第一个元素是表达式右值,第二个元素是表达式的操作符。比如条件a>1 and b < 2,则conditions是{"a":["1",">"],"b":["2","<"] }。这儿需要考虑表达式右值是一个数组的场景,比如 a in (1,2,3)这样的条件,所以组装条件时做了特殊处理。
在处理表中数据的时候,比如查询语句的条件中有表中字段信息,再比如更新、插入数据语句中也有相关信息,这个时候都需要调用_get_column_type方法获取字段类型,然后通过_conv_data方法将数据进行格式化——当然目前这个函数还不能涵盖所有类型。
def _get_column_type(self, table_name, column_name):if 0 == len(self._table_info):self.refresh_tables_info()if table_name not in self._table_info.keys():LOG_WARNING("table_%s info in not exist" %(table_name))return "None"if column_name not in self._table_info[table_name].keys():LOG_WARNING("column name %s is not in table %s" % (column_name, table_name))return "None"return self._table_info[table_name][column_name]["type"]def _conv_data(self, data, type):if type == "varchar" or type == "char":return '"%s"' % (data)elif type == "float" or type == "double":try:conv_data = float(data)return "%.8f" % (conv_data)except Exception as e:LOG_WARNING("conv %s to %s error" % (data, type))return "0"elif type == "tinyint" or type == "bigint" or type == "int":return "%d" % (int(data))数据的更新操作和插入操作我就不把代码贴出来了。大家可以到之后公布的源码地址里看。
最后说明下操作执行的方法
def execute(self, sql, select = False, commit=False):try:data = ()conn = self._pool.connection()cursor = conn.cursor()data = cursor.execute(sql)if select:data = cursor.fetchall()if commit:conn.commit()cursor.close()except Exception as e:LOG_WARNING("excute sql error %s" % (str(e)))LOG_ERROR_SQL("%s" % (sql))finally:cursor.close()conn.close()return data一些操作我们需要数据库服务马上去执行,如创建数据库和创建表操作,因为我们在创建后立即会去使用或者查询相关信息。如果不及时执行,将影响之后的结果。这个场景下我们需要把commit参数设置为True。当然这种方式不要滥用,否则会影响数据库执行效率。
还有一些操作我们需要关心返回结果,比如select指令。这个时候就需要通过fetchall获取全部数据并返回。而创建表等操作则不需要fetchall结果。
连接管理类
因为我们数据库是分库的,而上述每个连接只管理一个数据库的操作,所以我们需要一个连接管理器去管理这些连接。
连接管理类是个单例,它通过modify_conns方法连接每个数据库
@singleton
class mysql_manager():def __init__(self):self._conns = {}def modify_conns(self, conns_info):for (conn_name, conn_info) in conns_info.items():conn_info_hash = frame_tools.hash(json.dumps(conn_info))if conn_name in self._conns.keys():if conn_info_hash in self._conns[conn_name].conns_dict.keys():continueelse:self._conns[conn_name] = mysql_conn_info()for key in conf_keys.mysql_conn_keys:if key not in conn_info.keys():continueconn_obj = mysql_conn(conn_info["host"], conn_info["port"], conn_info["user"], conn_info["passwd"], conn_info["db"], conn_info["charset"])self._conns[conn_name].conns_dict[conn_info_hash] = conn_objself._conns[conn_name].valid = 1self._print_conns()如果数据库连接信息发生改变,则需要将发生改变的数据库连接置为无效,然后再重新连接并记录
def add_conns(self, conns_info):self.modify_conns(conns_info)def remove_conns(self, conns_info):for (conn_name, conn_info) in conns_info.items():conn_info_hash = frame_tools.hash(json.dumps(conn_info))if conn_name in self._conns.keys():if conn_info_hash in self._conns[conn_name].conns_dict.keys():self._conns[conn_name].valid = 0self._print_conns()连接管理类通过get_mysql_conn方法暴露连接对象
def get_mysql_conn(self, conn_name):if conn_name not in self._conns.keys():return Noneconn_info = self._conns[conn_name]valid = self._conns[conn_name].validif 0 == valid:return Noneconns_dict_keys = self._conns[conn_name].conns_dict.keys()if len(conns_dict_keys) == 0:return Nonekey = conns_dict_keys[-1]ret_conn = self._conns[conn_name].conns_dict[key]return ret_conn它还暴露了一个刷新所有数据库中表信息的方法,用于在系统任务中定期更新内存中信息,保证数据稳定写入。
def refresh_all_conns_tables_info(self):for (conn_name, conn_info) in self._conns.items():conn = self.get_mysql_conn(conn_name)if None != conn:conn.refresh_tables_info()连接管理配置
我共设计了三种数据库。一种是保存股票基础数据的数据库,其配置是
[stock_db]
host=127.0.0.1
port=3306
user=root
passwd=fangliang
db=stock
charset=utf8一个是保存每日实时数据的数据库
[daily_temp]
host=127.0.0.1
port=3306
user=root
passwd=fangliang
db=daily_temp
charset=utf8最后一种是按股票代码分类的库,这种库有300个,设计原因我在《码农技术炒股之路——架构和设计》有说明
[stock_part]
host=127.0.0.1
port=3306
user=root
passwd=fangliang
db=stock_part
charset=utf8
range_max=300注意range_max这个参数,如果配置中有该参数,则代表其是一个数据库组
class mysql_conf_parser:def parse(self, job_conf_path):cp = ConfigParser.SafeConfigParser()cp.read(job_conf_path)sections = cp.sections()conns_info = {}for section in sections:conn_info = {}for key in conf_keys.mysql_conn_keys:if False == cp.has_option(section, key):LOG_WARNING()continueconn_info[key] = cp.get(section, key)if cp.has_option(section, "range_max"):range_max = int(cp.get(section, "range_max"))db_name_base = conn_info["db"] for index in range(0, range_max):conn_info["db"] = db_name_base + "_" + str(index)section_index_name = section + "_" + str(index)conns_info[section_index_name] = copy.deepcopy(conn_info)else:conns_info[section] = conn_inforeturn conns_info最终我们将建成下图所示数据库

正则表达式管理器
当我们从数据源获取数据后,需要使用一系列正则将原始数据转换成一组数据。然后才可以将这些数据写入数据库。举个例子,我们先看下正则管理器的配置
[string_comma_regular]
regular_expression_0 = data:\[(.*)\]
regular_expression_1 = "[^"]+"
regular_expression_2 = [^,"]+[hq_sinajs_cn_list]
regular_expression_0 = var hq_str_([^;]*);
regular_expression_1 = ([^,="shz]+)[quotes_money_163]
regular_expression_0 = ([^\r\n]+)
regular_expression_1 = ([^,'\r\n]+)
每一节都是一个正则名称,其下都是以“regular_expression_”开始的关键字。正则执行的顺序从序号小的向序号大的方向执行。我们通过下面的配置解释器读取配置
import ConfigParserclass regulars_manager_conf_parser:def parse(self, regulars_conf_path):cp = ConfigParser.SafeConfigParser()cp.read(regulars_conf_path)sections = cp.sections()regulars_info = {}for section in sections:regular_info = []regular_name_pre = "regular_expression_"for index in range(0, len(cp.options(section))):regular_name = regular_name_pre + str(index)if cp.has_option(section, regular_name):regular_info.append(cp.get(section, regular_name))else:breakregulars_info[section] = regular_inforeturn regulars_info正则表达式管理通过下面方法维护信息
@singleton
class regular_split_manager():def __init__(self):self._regulars = {}def modify_regulars(self, regulars_info):for (regular_name, regular_info) in regulars_info.items():self._regulars[regular_name] = regulars_infodef add_regulars(self, regulars_info):for (regular_name, regular_info) in regulars_info.items():self._regulars[regular_name] = regular_infodef remove_regulars(self, regulars_info):for (regular_name, regular_info) in regulars_info.items():if regular_name in self._regulars.keys():del self._regulars[regular_name]通过get_split_data方法可以将数据通过指定的正则名称进行分解,且分解到最后一步
def get_split_data(self, data, regular_name):data_array = []self._recursion_regular(data, regular_name, 0, data_array) return data_arraydef _get_regular(self, regular_name, deep):if regular_name not in self._regulars.keys():LOG_WARNING("regular manager has no %s" % (regular_name))return ""if deep >= len(self._regulars[regular_name]):return ""return self._regulars[regular_name][deep]def _recursion_regular(self, data, regular_name, deep, data_array):regular_str = self._get_regular(regular_name, deep)split_data = re.findall(regular_str, data)regualer_next_str = self._get_regular(regular_name, deep + 1)split_array = []if len(regualer_next_str) > 0:for item in split_data:self._recursion_regular(item, regular_name, deep + 1, data_array)else:for item in split_data:split_array.append(item)if len(split_array) > 0:data_array.append(split_array)有了上述各种管理器,我们已经把主要的准备工作做好。下一篇我将介绍最核心的任务调取管理器,它才是上述管理器最终的使用方。
相关文章:

Overview of ISA and TMG Networking and ISA Networking Case Study (Part 1)
老方说:此篇文章摘自ISASERVER.ORG网站,出自Thomas Shinder达人之手。严重建议ISA爱好者看看。Published: Dec 16, 2008 Updated: Jan 21, 2009 Author: Thomas Shinder What ISA/TMG firewall Networks are about and how the firewall uses these ne…
阿里云免费开放一切AI算力,加速新型冠状病毒新药和疫苗研发
近日,阿里云宣布,为了帮助加速新药和疫苗研发,将向全球公共科研机构免费开放一切AI算力。目前,中国疾控中心已成功分离病毒,疫苗研发和药物筛选仍在争分夺秒地进行。新药和疫苗研发期间,需要进行大量的数据…

ASP.net(C#)批量上传图片(完整版)
来自:http://blog.itpub.net/9869521/viewspace-667955/ 这篇关于ASP.Net批量上传图片的文章写得非常好,偶尔在网上看到想转载到这里,却费劲了周折。为了更新这篇文章,我用了近半个小时,网上的转载都残缺不全ÿ…
码农技术炒股之路——任务管理器
系统任务和普通任务都是通过任务管理器调度的。它们的区别是:系统任务在程序运行后即不会被修改,而普通任务则会被修改。(转载请指明出于breaksoftware的csdn博客) 为什么要有这样的设计?因为我希望它是一个可以不用停…
面对新型肺炎疫情,AI能做什么?
作者 | 马超出品 | AI科技大本营(ID:rgznai100)根据最新的新型冠状病毒疫情通报,截至1月30日24时,国家卫生健康委公布确诊病例9692例,重症病例1527例,累计死亡病例213例,另有疑似病例15238例。为…
大家帮忙.谢谢!..(急急急急急)
大家帮忙.谢谢!..(急急急急急) Delphi / Windows SDK/APIhttp://www.delphi2007.net/DelphiDB/html/delphi_20061218224617231.htmlprocedure TForm1.Button4Click(Sender: TObject); var P : pstring; i, j : integer; begin GetMem(p, sizeof(stri…
HDU4866 Shooting (要持久段树)
意甲冠军: 给你一些并行x行轴。总是询问坐标x的顶部之前,k一个段高度,。标题是必须在线。思路: 首先要会可持久化线段树(又称主席树和函数式线段树)。不会的能够去做下POJ 2104。 把全部线段高度离散化,作为结点建线段…
C++过去的这一年
作者 | Bartek译者 | 苏本如,责编 | 屠敏出品 | CSDN(ID:CSDNnews)【导读】本文旨在让我们回顾 C 2019年里的变化和发展!我们将重点关注本年度里 C 上发生的重大事件,标准的发展,工具的变化等等…

码农技术炒股之路——抓取股票基本信息、实时交易信息、主力动向信息
从本节开始,我们开始介绍各个抓取和备份业务。(转载请指明出于breaksoftware的csdn博客) 因为我们数据库很多,数据库中表也很多,所以我们需要一个自动检测并创建数据库和表的功能。在《码农技术炒股之路——数据库管理…
TemplateBuilder
http://msdn.microsoft.com/zh-cn/vstudio/system.web.ui.templatebuilder_members(VS.85).aspx TemplateBuilder 成员TemplateBuilder 成员支持在生成模板及其包含的子控件时使用的页分析器。 下表列出了由 TemplateBuilder 类型公开的成员。 公共构造函数 名称 说明 Templat…
【iOS UI】iOS 9 GUI 资源分享
分享的内容包括一个【DesignCode-iOS-9-GUI】Sketch 文件, 和苹果官方释出的【SF-UI、SF-Compact】两种字体的安装包。 以上内容是正版、免费的 <a href "https://itunes.apple.com/cn/app/sketch-3/id852320343?mt12">Sketch</a> 是收费软…
反向R?削弱显著特征为细粒度分类带来提升 | AAAI 2020
作者 | VincentLee来源 | 晓飞的算法工程笔记导读:论文提出了类似于dropout作用的diversification block,通过抑制特征图的高响应区域来反向提高模型的特征提取能力,在损失函数方面,提出专注于top-k类别的gradient-boosting loss来…

C#初学——doWhile
继续上面的学习,这次的是流程控制,用dowhile,代码如下,还是用语言选择来作为事例的。using System; using System.Collections.Generic; using System.Text; namespace ConsoleApplication9 { class Program { static void Main(s…
码农技术炒股之路——实时交易信息、主力动向信息分库备份
一般来说,一个股票信息应该保存在一张表中。但是由于我机器资源限制,且我希望尽快频率的抓取数据。所以每天我将所有股票的实时交易信息放在daily_temp库中的一个以日期命名的表中。主力动向信息也是如此。但是盘后分析股票时,我们会以单只股…
数据预处理(完整步骤)
原文:http://dataunion.org/5009.html 一:为什么要预处理数据?(1)现实世界的数据是肮脏的(不完整,含噪声,不一致)(2)没有高质量的数据,…
码农技术炒股之路——抓取日线数据、计算均线和除权数据
日线数据是股票每日收盘后的信息。这块数据不用实时抓取,所以并不占用宝贵的交易时间的资源。于是我们抓取完数据后直接往切片后的数据库中保存。(转载请指明出于breaksoftware的csdn博客) 抓取日线数据 我们先要获取今天有交易信息的股票代…
茫茫碌碌的日子
一连很好多天,都在为公司数据库基础构架升级的事情忙活着。升级的事情还是比较棘手的。需要升级硬件服务器,相关的存储,操作系统,数据库产品,涉及面非常多。当然烦心的事情就很多。作为线上生产系统,升级和…
Python PK C++,究竟谁更胜一筹?
作者 | Farhad Malik译者 | 弯月,编辑 | 屠敏来源 | CSDN(ID:CSDNnews)在编程生涯的早期阶段,我参与过一款C数学优化应用程序的开发,这个程序对性能的要求很高。至今我依然记得那段艰难的经历。在那个项目中…

oracle--查看表空间大小以及修改表空间大小
为什么80%的码农都做不了架构师?>>> 一.修改表空间大小 解决以上问题的办法:通过增大表空间即可解决,如下: Sql代码 使用dba用户登陆 sqlplus / as sysdba; 执行如下命令: SQL >…
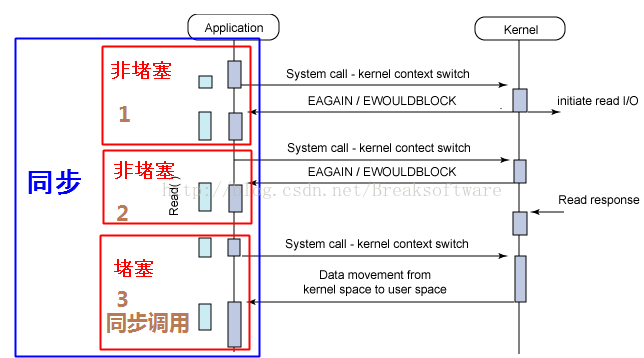
同步、异步、堵塞、非堵塞和函数调用及I/O之间的组合概念
在我们工作和学习中,经常会接触到“同步”、“异步”、“堵塞”和“非堵塞”这些概念,但是并不是每个人都能将它们的关系和区别说清楚。本文将对这些基本概念进行讨论,以期让大家有更清楚的认识。(转载请指明出于breaksoftware的c…
“抗击”新型肺炎!阿里达摩院研发AI算法,半小时完成疑似病例基因分析
利用技术辅助抗击疫情,阿里巴巴、百度等科技巨头各显身手。此前,AI科技大本营采访报道了阿里达摩院《数十名工程师作战5天,阿里达摩院连夜研发智能疫情机器人》一文,后者为了解决客服人力不足的局面,快速响应政府需求开…
反编译工具jad简单用法
反编译工具jad简单用法 下载地址:[url]http://58.251.57.206/down1?cidB99584EFA6154A13E5C0B273C3876BD4CC8CE672&t2&fmt&usrinput[/url]反编译工具jad &dt2002000一. 不用安装,只要解压就行(有这样两个文件jad.exe&#x…
ubuntu 系统设置bugzilla制
随着时间的推移。在大脑中形成的记忆总会慢慢的淡去。人的记忆力就是这样。所以最好的办法就是形成博客去记录下来,一方面给自己以后回想用。一方面也算是自己的一个积累。所以一旦选择了一个行业,最好不要轻 易转行,由于非常多知识须要不断的…
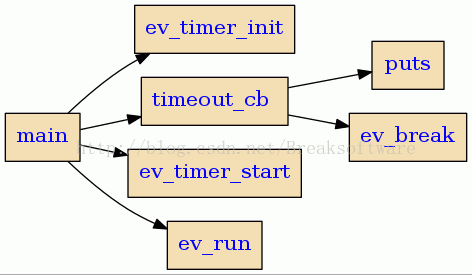
静态分析C语言生成函数调用关系的利器——cflow
除了《静态分析C语言生成函数调用关系的利器——calltree》一文中介绍的calltree,我们还可以借助cflow辅助我们阅读理解代码。(转载请指明出于breaksoftware的csdn博客) cflow的说明和安装cflow是一款静态分析C语言代码的工具,通过…
我在MongoDB年终大会上获二等奖文章:由数据迁移至MongoDB导致的数据不一致问题及解决方案...
作者 | 上海小胖来源 | Python专栏(ID:xpchuiit)故事背景企业现状2019年年初,我接到了一个神秘电话,电话那头竟然准确的说出了我的昵称:上海小胖。我想这事情不简单,就回了句:您好,我是小胖&…
注意String.Split的几个重载形式
String.Split应该是经常用到的一个函数了,经常的有下面两种形式 public string[] Split(char[] separator, StringSplitOptions options); public string[] Split(string[] separator, StringSplitOptions options); 1. 多数情况下我们会使用第一种,代码里可能这…
如何让猎头找到你
如何让猎头找到你
libev源码解析——总览
libev是个非常优秀的基于事件的循环库,很多开源软件,比如nodejs就是使用其实现基础功能。本系列将对该库进行源码分析。(转载请指明出于breaksoftware的csdn博客) 不知道是被墙了还是网站不再维护,它的官网(…
GPT-2仅是“反刍”知识,真正理解语言还要改弦更张
作者 | Gary Marcus译者 | 泓技编辑 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】OpenAI的GPT-2正被广泛地讨论,无论是《纽约客》还是《经济学人》,我们都能看到有关它的话题。关于自然和人工智能,它想…
sap business one 笑谈
Sap Business .e 出生在以色列,生下来的时候父母给起了个小名叫SBO,据说他的亲生父母是SAP家庭里的一个重要成员,后来SAP家族里的长老认为SBO长得不错,挺好看的。毕竟SAP家族里生下来的儿子都是胖胖的,想要个瘦点长相好…