大型网站架构演变和知识体系

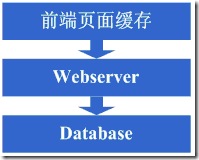
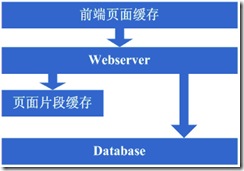
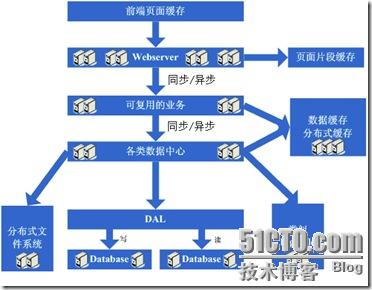
1、如何让访问分配到这两台机器上,这个时候通常会考虑的方案是Apache自带的负载均衡方案,或LVS这类的软件负载均衡方案;
2、如何保持状态信息的同步,例如用户session等,这个时候会考虑的方案有写入数据库、写入存储、cookie或同步session信息等机制等;
3、如何保持数据缓存信息的同步,例如之前缓存的用户数据等,这个时候通常会考虑的机制有缓存同步或分布式缓存;
4、如何让上传文件这些类似的功能继续正常,这个时候通常会考虑的机制是使用共享文件系统或存储等;
在解决了这些问题后,终于是把webserver增加为了两台,系统终于是又恢复到了以往的速度。
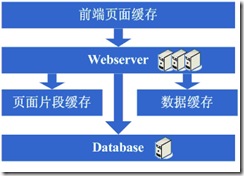
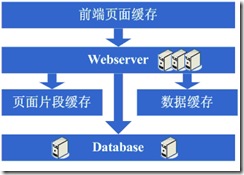
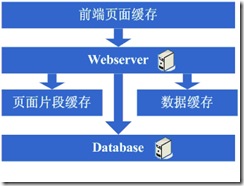
随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作,当然,这不可避免的会需要对程序 进行一些修改,也许在这个时候就会发现应用自己要关心分库分表的规则等,还是有些复杂的,于是萌生能否增加一个通用的框架来实现分库分表的数据访问,这个在ebay的架构中对应的就是DAL,这个演变的过程相对而言需要花费较长的时间,当然,也有可能这个通用的框架会等到分表做完后才开始做,同时,在这个阶段可 能会发现之前的缓存同步方案出现问题,因为数据量太大,导致现在不太可能将缓存存在本地,然后同步的方式,需要采用分布式缓存方案了,于是,又是一通考察和折磨,终于是将大量的数据缓存转移到分布式缓存上了。
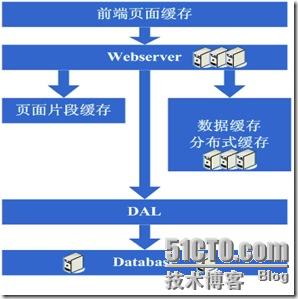
1、Apache的软负载或LVS软负载等无法承担巨大的web访问量(请求连接数、网络流量等)的调度了,这个时候如果经费允许的话,会采取的方案是购 买硬件负载,例如F5、Netsclar、Athelon之类的,如经费不允许的话,会采取的方案是将应用从逻辑上做一定的分类,然后分散到不同的软负载集群中;
2、原有的一些状态信息同步、文件共享等方案可能会出现瓶颈,需要进行改进,也许这个时候会根据情况编写符合网站业务需求的分布式文件系统等;
在做完这些工作后,开始进入一个看似完美的无限伸缩的时代,当网站流量增加时,应对的解决方案就是不断的添加webserver。
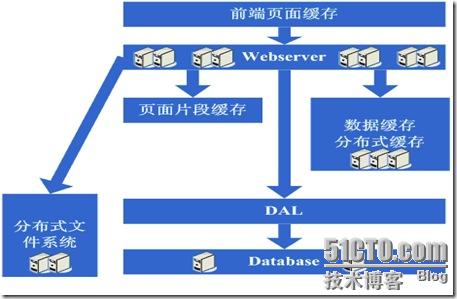
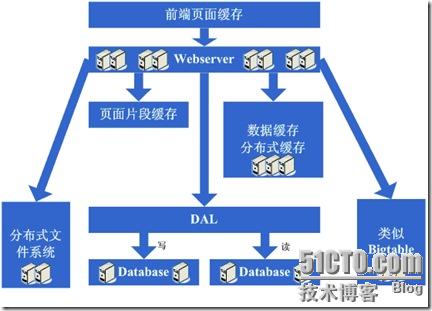
1、拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
2、将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
3、如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
经过这一步,差不多系统的架构进入相对稳定的阶段,同时也能开始采用大量的廉价机器来支撑着巨大的访问量和数据量,结合这套架构以及这么多次演变过程吸取的经验来采用其他各种各样的方法来支撑着越来越高的访问量。
从LiveJournal后台发展看大规模网站性能优化方法
http://blog.zhangjianfeng.com/article/743
另外从这里:http://www.danga.com/words/大家可以找到更多关于现在LiveJournal网站架构的介绍。
1)通过对特定领域应用软件进行分析,提炼出其中的稳定需求和易变需求,建立可重用的领域模型。依据领域模型和用户需求,产生应用系统的需求规格说明。
2)在领域模型的基础上,根据需求规格说明提炼出特定领域的软件体系结构。这是系统的高层设计,其目标是通过重用领域体系结构库中已有的高质量的体系结构,或生成最适合该用户需求的体系结构,并加以提炼入库,以备将来的重用,并在此体系结构的指导下,把系统逐步分解成相应的组件和连接件,直至组件
和连接件可以被设计模式和面向对象方法处理为止。
3)这个阶段主要解决具体组件和连接件的设计问题。通过重用可重用组件库中模式、对象和其它可重用的设计件,或重新设计的组件,并提炼入库;然后通过具体的编程实现,就可得到可运行的程序
我最近也在作相关方面的研究,不清楚对应到你上面阶段的那个部分,但是我的实现可能别有洞天。
我做web已经7年多了,最不能忍受的就是重复重复再重复,用了.net java之后我总于返回到了c时代,归结web应用其实就是数据+格式化,而xml+xslt恰恰就是这个模型,所以我的应用就是基于xml+xslt,并且做了一整套的技术论证,从SEO到换肤、多语言等高级特性都有了合理的解决方法,并且可以模块重用,做到数据跟界面的彻底分离,这样更有利于静态化,数据重用。
当然,实现的过程有阻碍,我已经做这套系统做了3年,废弃了一套java做得半成品的东西(我重写了jsp,还做了一个webserver和解释器,但是发现静态处理性能不行),现在总于有点眉目了,我的web server静态处理性能能大到nginx的120%,apache的200%(均是在300用户负载的测试下),数据库应用服务能达到 15000RPS/S(静态文件23000左右,测试是在单机情况下,cpu Q6600 4核,2G内存,1个主线程,4个应用线程测试),代理性能是静态性能的接近50%,这几乎成为极限了,这为我的模型奠定了基础。
完成后系统本身就自带分布式文件系统、负载均衡、缓存系统,应用是基于配置的数据管理器,可以将数据库、静态文件、prama、服务器变量等等通过数据管理器按照用户权限发送给可解析xml的客户端,对于SEO、非xslt解析支持的浏览器等等全部采用在服务器端合成输出。界面则全部由xslt完成。
这样就能保证90%的请求能到到亚静态文件的处理速度,系统还在完善中,采用c在linux下编写的,希望有空共同探讨。
转载于:https://blog.51cto.com/lovely/235762
相关文章:
Python数据清理终极指南(2020版)
作者 | Lianne & Justin译者 | 陆离出品 | AI科技大本营(ID:rgznai100)一般来说,我们在拟合一个机器学习模型或是统计模型之前,总是要进行数据清理的工作。因为没有一个模型能用一些杂乱无章的数据来产生对项目有意义的结果。…
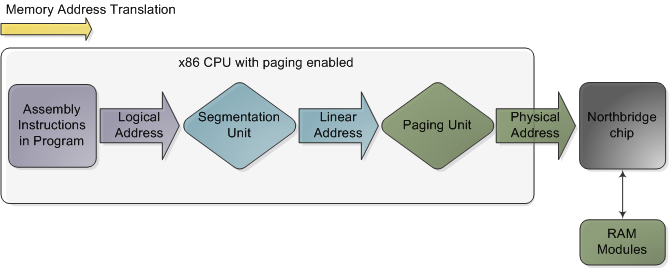
内存地址转换与分段
原文标题:Memory Translation and Segmentation 原文地址:http://duartes.org/gustavo/blog/ 翻译地址:http://blog.csdn.net/drshenlei/article/details/4261909 本文是Intel兼容计算机(x86)的内存与保护系列文章的第…

c++ 普通高精减
//c 普通高精减 //codevs 3115 高精度练习之减法 //内容简单,就不注释了。 //注意下,&&优先级高于||。 #include<cstdio>#include<cstring>char s1[600],s2[600];int a1[600],a2[600],len1,len2,i;int main(){scanf("%s",…
腾讯提超强少样本目标检测算法,公开1000类检测训练集FSOD | CVPR 2020
作者 | VincentLee来源 | 晓飞的算法工程笔记不同于正常的目标检测任务,few-show目标检测任务需要通过几张新目标类别的图片在测试集中找出所有对应的前景。为了处理好这个任务,论文主要有两个贡献:提出一个通用的few-show目标检测算法&#…
Linux加入到Windows域 收藏
一、实验环境: AD server:windows server 2003samba:redhat as5AD server的hostname和IP地址:turbomai-c<?xml:namespace prefix st1 ns "urn:schemas-microsoft-com:office:smarttags" />89f91.test.com 192…

哈希函数原理及实现
哈希解决冲突 1000以内的素数 一般的hash实现已经总结出一些比较重要的素数: static unsigned int table_size[] {7,13,31, 61, 127, 251, 509, 1021,2039, 4093, 8191, 16381, 32749, 65521,1310…

基于Virtual DOM与Diff DOM的测试代码生成
尽管是在年末,并且也还没把书翻译完,也还没写完书的第一稿。但是,我还是觉得这是一个非常不错的话题——测试代码生成。当我们在写一些UI测试的时候,我们总需要到浏览器去看一下一些DOM的变化。比如,我们点击了某个下拉…

Win32 环境下的堆栈
原文已经找不到,作者应该是:http://blog.csdn.net/slimak 但是没有找到此文,其中丢了2幅图 简介 在Win32环境下利用调试器调试应用程序的时候经常要和堆栈(Stack)打交道,尤其是在需要手工遍历堆栈(Manually Walking Stack)的时候我们需要…

在VMWare中配置SQLServer2005集群 Step by Step(四)——集群安装
在VMWare 中配置集群 1. 进入command 命令窗口执行以下命令,创建仲裁磁盘和共享数据磁盘 vmware-vdiskmanager.exe -c -s 200Mb -a lsilogic -t 2 F:\VM\Share\Windows\SQLServer\quorum.vmdk vmware-vdiskmanager.exe -c -s 4Gb -a lsilogic -t 2 F:\VM\Share\Wind…
口罩检测识别率惊人,这个Python项目开源了
作者 | 一颗小树x,CSDN 博主编辑 | 唐小引来源 | CSDN 博客昨天在 GitHub 上看到一个有趣的开源项目,它能检测我们是否有戴口罩,跑起程序测试后,发现识别率挺高的,也适应不同环境,于是分享给大家。首先感谢…
CentOS搭建msmtp+mutt实现邮件发送
1:搭建配置msmtp下载msmtp包:官方地址:http://msmtp.sourceforge.net/download.html编译,安装(官方下载的包为tar.xz格式):#xz -d msmtp-1.6.3.tar.xz #tar -xvf msmtp-1.6.3.tar #cd msmtp-1.6.3 #./configure --prefix /opt/app…

Linux环境下的堆栈--调试C程序
完整的调试过程,跟踪堆栈变化,32位下。 注意64位和此不同。 a.c代码: #include <stdio.h> int main() { AFunc(5,6);return 0; } int BFunc(int i,int j) {int m 1;int n 2;m i;n j; return m; }int AFunc(int i,int j) {…
听说过代码洁癖,Bug洁癖怎么解?
来源 | Python编程时光(ID: Cool-Python)当我们写的一个脚本或程序发生各种不可预知的异常时,如果我们没有进行捕获处理的时候,通常都会致使程序崩溃退出,并且会在终端打印出一堆 密密麻麻 的 traceback 堆栈信息来告诉…
POJO、VO、PO、FormBean区别:
首先讲一下四者的概念 POJO:Pure Old Java Object,符合Java Bean属性规范的简单Java对象,通常也称为VO(Value Object,值对象)。 VO:就是POJO; PO: Persistent Object,持久化对…
oracle中的sql%rowcount,sql%found、sql%notfound、sql%rowcount和sql%isopen
Oracle 存储过程 删除表记录时删除不存在的记录也是显示删除成功 create or replace procedure delDept(p_deptno in dept.deptno%type) is begindelete from dept where deptnop_deptno;dbms_output.put_line(部门删除成功...);exception when others thendbms_output.put_lin…

linux平台的链接与加载
原文是上下两篇 链接与加载(上) — 静态链接链接与加载(下) — 动态链接 为观看方便,现在合并起来。 一.静态链接 示例程序 我们先看一个简单的示例程序,代码如下: /*main.c*/int u 333;int sum(int, int);int main(int argc, char* argv…
预训练模型ProphetNet:根据未来文本信息进行自然语言生成
作者 | 刘大一恒、齐炜祯、晏宇、宫叶云、段楠、周明来源 | 微软研究院AI头条(ID:MSRAsia)编者按:微软亚洲研究院提出新的预训练模型 ProphetNet,提出了一种新的自监督学习目标——同时预测多个未来字符,在序列到序列的…

模拟进程管理小结,编码规范的重要性
废话不多说了,省的又有衰人找我麻烦。希望我讨厌的,和讨厌我的少来骚扰我,由衷的感谢它们。 我不回那些骚扰,是因为我见到名字就直接删了,看都懒的看了。也别怪我粗鲁,因为我一向是对什么人说什么话 的&…

JSPServlet路径问题
2019独角兽企业重金招聘Python工程师标准>>> 如果带WebRoot,那么js、css、img都应该放到WebRoot目录下,否则访问会有问题。千万不要放在WEB-INF下,因为WEB-INF下的内容只有服务器转发可以访问到,出于安全考虑。 如果不…
Git学习教程(六)Git日志
第六课 Git 日志 内容提要:浏览项目历史,查询指定提交内容,图形化显示分枝和合并...git log是git中最常用的一个命令,执行之后,会显示该项目的提交历史。如果命令不加任何参数,那么就会显示目前所在分枝上&…
汇编包含C代码
反汇编的时候带上C代码便于观察 比较三元表达式和if else的差异 a1.c #include <stdio.h> int main(void) { int a1;int b2;int c0;a (b>c)?1:0;return 0;} a2.c #include <stdio.h> int main(void) { int a1;int b2;int c0;if(b>c){a1;}else{a0;…
无需3D运动数据训练,最新人体姿势估计方法达到SOTA | CVPR 2020
作者 | Muhammed Kocabas译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)人体的运动对于理解人的行为是非常重要的。尽管目前已经在单图像3D姿势和动作估计方面取得了进展,但由于缺少用于训练的真实的3D运动数据,因此现有的基于视频…

Linux内核跟踪之trace框架分析【转】
转自:http://blog.chinaunix.net/uid-20543183-id-1930846.html------------------------------------------本文系本站原创,欢迎转载!转载请注明出处:http://ericxiao.cublog.cn/------------------------------------------一: 前言本文主要是对trace的框架做详尽…
写给Python开发者:机器学习十大必备技能
作者 | Pratik Bhavsar译者 | 明明如月,编辑 | 夕颜来源 | CSDN(ID:CSDNnews)有时候,作为一个数据科学家,我们常常忘记了初心。我们首先是一个开发者,然后才是研究人员,最后才可能是数学家。我…

Linux环境程序栈溢出原理
当在缓冲区中输入过多的数据时,缓冲区溢出就会发生,C语言提供了多种方法,可以使在缓冲区中输入的数据比预期的多。 局部变量可以被分配到栈上。这就意味着在栈的某个地方有一个固定大小的缓冲区。 而栈是向下增长的,而且一些重要…
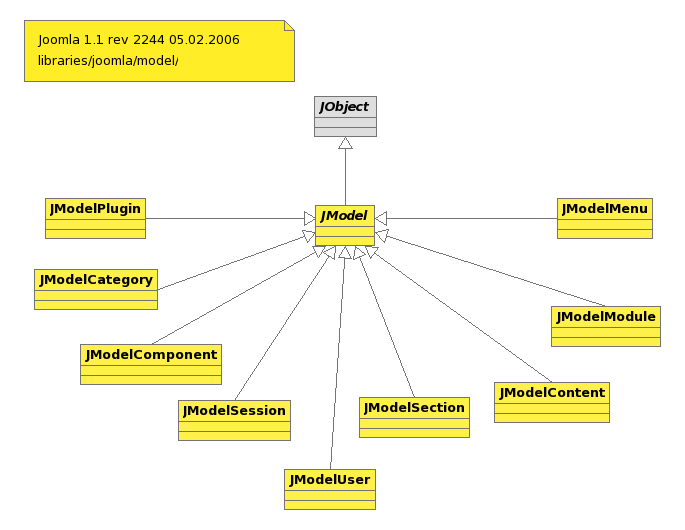
[翻译]Joomla 1.5架构(十一) model 包
这个包包含了跟数据表交互的所有相关类 JModel This abstract class is the base class for all Joomla! data access objects. 所有数据访问类的抽象基类。 以下的类都分别实现对不同表的访问,不再翻译了。 Adapter Folder JModelCategory This is a data access …
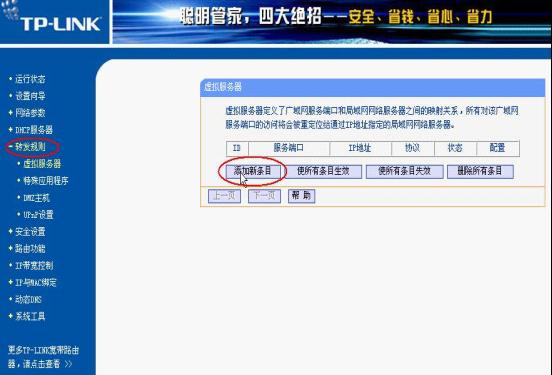
度量快速开发平台端口映射的介绍
度量快速开发平台在客户中部署的时候,可能会想内网与外网用户同时使用。一般情况下,服务端都是部署在内网的,那外网用户要访问,就可能用到端口映射的功能。端口映射基本都是在路由器上进行。下面就是几个常用的路由器上的设置方法…
为什么栈和堆的生长方向不一样
栈的生长方向 8051的栈是向高地址增长,INTEL的8031、8032、8048、8051系列使用向高地址增长的堆栈;但同样是INTEL,在x86系列中全部使用向低地址增长的堆栈。其他公司的CPU中除ARM的结构提供向高地址增长的堆栈选项外,多数都是使用…
简单粗暴理解与实现机器学习之逻辑回归:逻辑回归介绍、应用场景、原理、损失以及优化...
作者 | 汪雯琦责编 | Carol来源 | CSDN 博客出品 | AI科技大本营(ID:rgznai100)学习目标知道逻辑回归的损失函数知道逻辑回归的优化方法知道sigmoid函数知道逻辑回归的应用场景应用LogisticRegression实现逻辑回归预测知道精确率、召回率指标的区别知道如…

生命的脆弱——悼念朋友
生命的脆弱让我们敲希望的钟啊多少祈祷在心中让大家看不到失败叫成功永远在让地球忘记了转动啊四季少了夏秋冬让宇宙关不了天窗叫太阳不西沉让欢喜代替了哀愁啊微笑不会再害羞让时光懂得去倒流叫青春不开溜让贫穷开始去逃亡啊快乐健康留四方让世界找不到黑暗幸福像花开放让大家…