写给Python开发者:机器学习十大必备技能
作者 | Pratik Bhavsar
译者 | 明明如月,编辑 | 夕颜
来源 | CSDN(ID:CSDNnews)
有时候,作为一个数据科学家,我们常常忘记了初心。我们首先是一个开发者,然后才是研究人员,最后才可能是数学家。我们的首要职责是快速找到无 bug 的解决方案。
我们能做模型并不意味着我们就是神。这并不是编写垃圾代码的理由。
自从我开始学习机器学习以来,我犯了很多错误。因此我想把我认为机器学习工程中最常用的技能分享出来。在我看来,这也是目前这个行业最缺乏的技能。
我称他们为不懂软件的数据科学家,因为他们中很大一部分人都没有系统地学习过计算机科学课程。而我自己也是如此。
如果要选择雇佣一个伟大的数据科学家和一个伟大的机器学习工程师,我会选择雇佣后者。
下面开始我的分享。
学习编写抽象类
一旦开始编写抽象类,你就能体会到它给带来的好处。抽象类强制子类使用相同的方法和方法名称。许多人在同一个项目上工作, 如果每个人去定义不同的方法,这样做没有必要也很容易造成混乱。
1import os2from abc import ABCMeta, abstractmethod345class DataProcessor(metaclass=ABCMeta):6 """Base processor to be used for all preparation."""7 def __init__(self, input_directory, output_directory):8 self.input_directory = input_directory9 self.output_directory = output_directory
10
11 @abstractmethod
12 def read(self):
13 """Read raw data."""
14
15 @abstractmethod
16 def process(self):
17 """Processes raw data. This step should create the raw dataframe with all the required features. Shouldn't implement statistical or text cleaning."""
18
19 @abstractmethod
20 def save(self):
21 """Saves processed data."""
22
23
24class Trainer(metaclass=ABCMeta):
25 """Base trainer to be used for all models."""
26
27 def __init__(self, directory):
28 self.directory = directory
29 self.model_directory = os.path.join(directory, 'models')
30
31 @abstractmethod
32 def preprocess(self):
33 """This takes the preprocessed data and returns clean data. This is more about statistical or text cleaning."""
34
35 @abstractmethod
36 def set_model(self):
37 """Define model here."""
38
39 @abstractmethod
40 def fit_model(self):
41 """This takes the vectorised data and returns a trained model."""
42
43 @abstractmethod
44 def generate_metrics(self):
45 """Generates metric with trained model and test data."""
46
47 @abstractmethod
48 def save_model(self, model_name):
49 """This method saves the model in our required format."""
50
51
52class Predict(metaclass=ABCMeta):
53 """Base predictor to be used for all models."""
54
55 def __init__(self, directory):
56 self.directory = directory
57 self.model_directory = os.path.join(directory, 'models')
58
59 @abstractmethod
60 def load_model(self):
61 """Load model here."""
62
63 @abstractmethod
64 def preprocess(self):
65 """This takes the raw data and returns clean data for prediction."""
66
67 @abstractmethod
68 def predict(self):
69 """This is used for prediction."""
70
71
72class BaseDB(metaclass=ABCMeta):
73 """ Base database class to be used for all DB connectors."""
74 @abstractmethod
75 def get_connection(self):
76 """This creates a new DB connection."""
77 @abstractmethod
78 def close_connection(self):
79 """This closes the DB connection."""
固定随机数种子
实验的可重复性是非常重要的,随机数种子是我们的敌人。要特别注重随机数种子的设置,否则会导致不同的训练 / 测试数据的分裂和神经网络中不同权重的初始化。这些最终会导致结果的不一致。
1def set_seed(args):
2 random.seed(args.seed)
3 np.random.seed(args.seed)
4 torch.manual_seed(args.seed)
5 if args.n_gpu > 0:
6 torch.cuda.manual_seed_all(args.seed)
先加载少量数据
如果你的数据量太大,并且你正在处理比如清理数据或建模等后续编码时,请使用 `nrows `来避免每次都加载大量数据。当你只想测试代码而不是想实际运行整个程序时,可以使用此方法。
非常适合在你本地电脑配置不足以处理那么大的数据量, 但你喜欢用 Jupyter/VS code/Atom 开发的场景。
1f_train = pd.read_csv(‘train.csv’, nrows=1000)预测失败 (成熟开发人员的标志)
总是检查数据中的 NA(缺失值),因为这些数据可能会造成一些问题。即使你当前的数据没有,并不意味着它不会在未来的训练循环中出现。所以无论如何都要留意这个问题。
1print(len(df))
2df.isna().sum()
3df.dropna()
4print(len(df))显示处理进度
在处理大数据时,如果能知道还需要多少时间可以处理完,能够了解当前的进度非常重要。
方案1:tqdm
1from tqdm import tqdm2import time34tqdm.pandas()56df['col'] = df['col'].progress_apply(lambda x: x**2)78text = ""9for char in tqdm(["a", "b", "c", "d"]):
10 time.sleep(0.25)
11 text = text + char方案2:fastprogress
1from fastprogress.fastprogress import master_bar, progress_bar
2from time import sleep
3mb = master_bar(range(10))
4for i in mb:
5 for j in progress_bar(range(100), parent=mb):
6 sleep(0.01)
7 mb.child.comment = f'second bar stat'
8 mb.first_bar.comment = f'first bar stat'
9 mb.write(f'Finished loop {i}.')解决 Pandas 慢的问题
如果你用过 pandas,你就会知道有时候它的速度有多慢ーー尤其在团队合作时。与其绞尽脑汁去寻找加速解决方案,不如通过改变一行代码来使用 modin。
1import modin.pandas as pd记录函数的执行时间
并不是所有的函数都生来平等。
即使全部代码都运行正常,也并不能意味着你写出了一手好代码。一些软错误实际上会使你的代码变慢,因此有必要找到它们。使用此装饰器记录函数的时间。
1import time23def timing(f):4 """Decorator for timing functions5 Usage:6 @timing7 def function(a):8 pass9 """
10
11
12 @wraps(f)
13 def wrapper(*args, **kwargs):
14 start = time.time()
15 result = f(*args, **kwargs)
16 end = time.time()
17 print('function:%r took: %2.2f sec' % (f.__name__, end - start))
18 return result
19 return wrapp
不要在云上烧钱
没有人喜欢浪费云资源的工程师。
我们的一些实验可能会持续数小时。跟踪它并在完成后关闭云实例是很困难的。我自己也犯过错误,也看到过有些人会有连续几天不关机的情况。
这种情况经常会发生在我们周五上班,留下一些东西运行,直到周一回来才意识到????。
只要在执行结束时调用这个函数,你的屁股就再也不会着火了!
使用 `try` 和 `except` 来包裹 main 函数,一旦发生异常,服务器就不会再运行。我就处理过类似的案例????
让我们多一点责任感,低碳环保从我做起。????
1import os23def run_command(cmd):4 return os.system(cmd)56def shutdown(seconds=0, os='linux'):7 """Shutdown system after seconds given. Useful for shutting EC2 to save costs."""8 if os == 'linux':9 run_command('sudo shutdown -h -t sec %s' % seconds)
10 elif os == 'windows':
11 run_command('shutdown -s -t %s' % seconds)
创建和保存报告
在建模的某个特定点之后,所有的深刻见解都来自于对误差和度量的分析。确保为自己和上司创建并保存格式正确的报告。
不管怎样,管理层都喜欢报告,不是吗?????
1import json2import os34from sklearn.metrics import (accuracy_score, classification_report,5 confusion_matrix, f1_score, fbeta_score)67def get_metrics(y, y_pred, beta=2, average_method='macro', y_encoder=None):8 if y_encoder:9 y = y_encoder.inverse_transform(y)
10 y_pred = y_encoder.inverse_transform(y_pred)
11 return {
12 'accuracy': round(accuracy_score(y, y_pred), 4),
13 'f1_score_macro': round(f1_score(y, y_pred, average=average_method), 4),
14 'fbeta_score_macro': round(fbeta_score(y, y_pred, beta, average=average_method), 4),
15 'report': classification_report(y, y_pred, output_dict=True),
16 'report_csv': classification_report(y, y_pred, output_dict=False).replace('\n','\r\n')
17 }
18
19
20def save_metrics(metrics: dict, model_directory, file_name):
21 path = os.path.join(model_directory, file_name + '_report.txt')
22 classification_report_to_csv(metrics['report_csv'], path)
23 metrics.pop('report_csv')
24 path = os.path.join(model_directory, file_name + '_metrics.json')
25 json.dump(metrics, open(path, 'w'), indent=4)
写出一手好 API
结果不好,一切都不好。
你可以做很好的数据清理和建模,但是你仍然可以在最后制造巨大的混乱。通过我与人打交道的经验告诉我,许多人不清楚如何编写好的 api、文档和服务器设置。我将很快写另一篇关于这方面的文章,但是先让我简要分享一部分。
下面的方法适用于经典的机器学习 和 深度学习部署,在不太高的负载下(比如1000 / min)。
见识下这个组合: Fastapi + uvicorn + gunicorn
最快的ー用 fastapi 编写 API,因为这 是最快的,原因参见这篇文章。
文档ー在 fastapi 中编写 API 为我们提供了 http: url/docs 上的免费文档和测试端点,当我们更改代码时,fastapi 会自动生成和更新这些文档。
workerー使用 gunicorn 服务器部署 API,因为 gunicorn 具有启动多于1个 worker,而且你应该保留至少 2 个worker。
运行这些命令来使用 4 个 worker 部署。可以通过负载测试优化 worker 数量。
1pip install fastapi uvicorn gunicorn
2gunicorn -w 4 -k uvicorn.workers.UvicornH11Worker main:app
原文链接:
https://towardsdatascience.com/10-great-ml-practices-for-python-developers-b089eefc18fc
【end】
◆
原力计划
◆
《原力计划【第二季】- 学习力挑战》正式开始!即日起至 3月21日,千万流量支持原创作者!更有专属【勋章】等你来挑战
推荐阅读
Python数据清理终极指南(2020版)
口罩检测识别率惊人,这个Python项目开源了
谈论新型冠状病毒、比特币、苹果公司……沃伦•巴菲特受访中的 18 个金句,值得一看!
天猫超市回应大数据杀熟;华为Mate Xs被热炒至6万元;Elasticsearch7.6.1发布
一张图对比阿里、腾讯复工的区别
不看就亏系列!这里有完整的 Hadoop 集群搭建教程,和最易懂的 Hadoop 概念!| 附代码
你点的每个“在看”,我都认真当成了AI
相关文章:

Linux环境程序栈溢出原理
当在缓冲区中输入过多的数据时,缓冲区溢出就会发生,C语言提供了多种方法,可以使在缓冲区中输入的数据比预期的多。 局部变量可以被分配到栈上。这就意味着在栈的某个地方有一个固定大小的缓冲区。 而栈是向下增长的,而且一些重要…
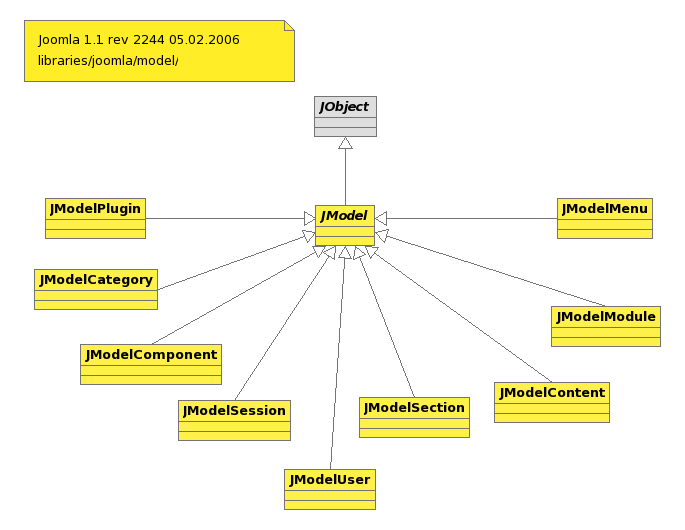
[翻译]Joomla 1.5架构(十一) model 包
这个包包含了跟数据表交互的所有相关类 JModel This abstract class is the base class for all Joomla! data access objects. 所有数据访问类的抽象基类。 以下的类都分别实现对不同表的访问,不再翻译了。 Adapter Folder JModelCategory This is a data access …
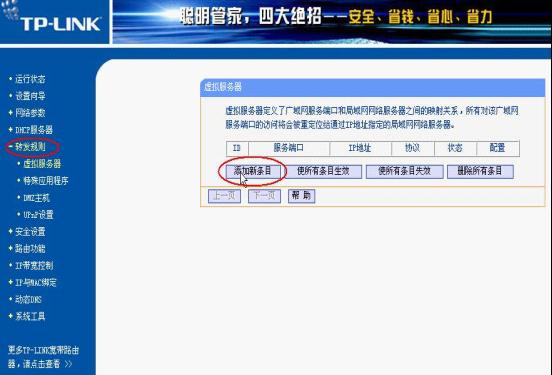
度量快速开发平台端口映射的介绍
度量快速开发平台在客户中部署的时候,可能会想内网与外网用户同时使用。一般情况下,服务端都是部署在内网的,那外网用户要访问,就可能用到端口映射的功能。端口映射基本都是在路由器上进行。下面就是几个常用的路由器上的设置方法…

为什么栈和堆的生长方向不一样
栈的生长方向 8051的栈是向高地址增长,INTEL的8031、8032、8048、8051系列使用向高地址增长的堆栈;但同样是INTEL,在x86系列中全部使用向低地址增长的堆栈。其他公司的CPU中除ARM的结构提供向高地址增长的堆栈选项外,多数都是使用…
简单粗暴理解与实现机器学习之逻辑回归:逻辑回归介绍、应用场景、原理、损失以及优化...
作者 | 汪雯琦责编 | Carol来源 | CSDN 博客出品 | AI科技大本营(ID:rgznai100)学习目标知道逻辑回归的损失函数知道逻辑回归的优化方法知道sigmoid函数知道逻辑回归的应用场景应用LogisticRegression实现逻辑回归预测知道精确率、召回率指标的区别知道如…

生命的脆弱——悼念朋友
生命的脆弱让我们敲希望的钟啊多少祈祷在心中让大家看不到失败叫成功永远在让地球忘记了转动啊四季少了夏秋冬让宇宙关不了天窗叫太阳不西沉让欢喜代替了哀愁啊微笑不会再害羞让时光懂得去倒流叫青春不开溜让贫穷开始去逃亡啊快乐健康留四方让世界找不到黑暗幸福像花开放让大家…

VMware Tools手动下载
2019独角兽企业重金招聘Python工程师标准>>> VMware自己下载VMware Tools非常慢。你可以自己手动下载它。 下载地址为: version: 8.8.2 http://softwareupdate.vmware.com/cds/vmw-desktop/ws/8.0.3/ 选择最新的build,例如: http:…

Linux查看多核CPU利用率
1.top 使用权限:所有使用者 使用方式:top [-] [d delay] [q] [c] [S] [s] [i] [n] [b] 说明:即时显示process的动态 d :改变显示的更新速度,或是在交谈式指令列( interactive command)按s q :没有任何延迟的显示速度…

仓央嘉措《那一天,那一月,那一年,那一世》
那一天, 我闭目在经殿的香雾中, 蓦然听见你颂经中的真言; 那一月, 我摇动所有的经筒, 不为超度, 只为触摸你的指尖; 那一年, 磕长头匍匐在…
AI+大数据助力抗疫,带你认识百度地图的新玩法!
作者 | Aholiab责编 | Carol出品 | AI科技大本营(ID:rgznai100)“喂,你好,我是百度地图的客服,请问是xx店铺对吗?”“嗯,什么事?”“您家在疫情期间还照常营业,对吗&…
Coursera Machine Learning 作业提交问题
关于作业提交问题的解决办法 Octave 4.0.0无法正常提交 解决办法:打两个补丁 补丁1:平台通用补丁2:Win,Linux or Mac 注:补丁文件中有安装说明

Linux查看进程内存状况
查看全部进程 通过top或ps -ef | grep 进程名 得到进程的PID。该命令可以提供进程状态、文件句柄数、内存使用情况等信息。 #pa aux 先查看进程 nginx的工作进程是5757 pmap命令 可以显示一个或多个进程所使用的内存数量。你可以使用这个工具来了解服务器上的某个进程分配…
用于小型图形挖掘研究的瑞士军刀:空手道俱乐部的图表学习Python库
作者 | Benedek Rozemberczki译者 | 天道酬勤 责编 | Carol出品 | AI科技大本营(ID:rgznai100)空手道俱乐部(Karate Club)是NetworkX Python软件包的无监督机器学习扩展库。详细可以参阅此处的文档:https://github.com…
电子商务创造的第二次产业机会
即将迎来冬至节气的这个周末,天寒地冻,却是电子商务的饕餮之季。淘宝网商交易大会刚刚在成都落下帷幕,而比网货交易会更令业界期待的“2009中国电子商务创新发展高峰论坛”也在北京顺利召开。大会由国内最大的电子商务软件及服务提供商ShopEx…
C#趣味程序---个位数为6,且能被3整出的五位数
using System;namespace ConsoleApplication1 {class Program{static void Main(string[] args){int count 0;int k;for (int i 1000; i < 9999; i){k i * 10 6;if (k % 3 0){Console.WriteLine(k);count;}}Console.WriteLine(count); }} }
c# winform 用子窗体刷新父窗体,子窗体改变父窗体控件的值
第一种方法: 用委托,Form2和Form3是同一组 Form2 usingSystem; usingSystem.Collections.Generic; usingSystem.ComponentModel; usingSystem.Data; usingSystem.Drawing; usingSystem.Text; usingSystem.Windows.Forms; namespaceTestMouseMove { pub…
TCMalloc
tcmalloc 业界最有名的内存分配库,当数google 的tcmalloc。Tcmalloc 在管理小 内存块时非常有效,而且能够避免在大内存分配时的mmap()系统调用。它在多 线程中的表现也不错能很好的减少锁碰撞(glibc 致命的问题)。Tcmalloc 现在基 本上成了mysql DBA 的标…
前沿技术探秘:知识图谱构建流程及方法
作者 | 郑毅封图| CSDN│下载于视觉中国出品 | CSDN云计算(ID:CSDNcloud)随着AI技术的发展和普及,当今社会已经进入了智能化时代。与以往不同的是,在这一波浪潮中,企业不仅是向数字化转型,更是向…
【HDOJ】3275 Light
这就是个简单线段树延迟标记。因为对bool使用了~而不是!,wa了一下午找不到原因。 1 /* 3275 */2 #include <iostream>3 #include <sstream>4 #include <string>5 #include <map>6 #include <queue>7 #include <set>…

lighttpd+PHP安装
lighttpd版本:1.4.32 php版本:5.4.11 2013.2.3第一次 php版本:5.4.12 2013.3.14第二次修改 1.lighttpd官网地址 http://www.lighttpd.net 2.下载安装lighttpd #wget http://download.lighttpd.net/lighttpd/releases-1.4.x/lighttp…

描述C#多线程中 lock关键字
本文介绍C# lock关键字,C#提供了一个关键字lock,它可以把一段代码定义为互斥段(critical section),互斥段在一个时刻内只允许一个线程进入执行,而其他线程必须等待。 每个线程都有自己的资源,但…
从样本处理到决策模型,如何用NLP识别盗版资源?
作者 | 阿里文娱高级开发工程师千起出品 | AI科技大本营(ID:rgznai100)背景随着5G时代来临,新媒体行业快速发展,盗版传播平台多样化、形式多样化,版权方难以通过有限的人力实现最大限度的维权。根据MUSO报告显示2017年…
利用.htaccess绑定子域名到子目录(亲测万网可用)
http://www.xmgho.com/archives/783.html 利用.htaccess绑定域名到子目录,前提你的空间服务器必须支持apache的rewrite功能,只有这样才能使用.htaccess。如果你的空间是Linux服务器 一般默认都开启了的。绑定域名 登陆域名管理台(如DNSPod) 把…

Memcached内存池分析
针对Memcacged1.4.15代码 1.完整slabs内存池图 这是我画的memcached的slabs内存池对象关系图: 2.内存池数据结构 typedef struct {unsigned int size; /* 每个item的大小 */unsigned int perslab; /* 每个page中包含多少个item */void *slots; …
Google重磅发布开源库TFQ,快速建立量子机器学习模型
整理 | 弯月编辑 | 郭芮出品 | AI科技大本营(ID:rgznai100)近日,Google 与滑铁卢大学、大众汽车等联合发布 TensorFlow Quantum(TFQ),一个可快速建立量子机器学习模型原型的开源库。TFQ提供了必…
.net3.5的安装与修复
<?xml:namespace prefix o ns "urn:schemas-microsoft-com:office:office" />.net3.5的安装与修复.net3.5正常安装的顺序是先安装windows IIS组件,然后再安装.net3.5安装包,而.net3.5安装包的下载地址可以去百度和google上搜一下&…

jquery easy ui 简单字段选择搜索实现
写的比较粗糙,望见谅。 要实现的效果: 代码如下: <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>jQuery EasyUI Application Demo</title><link rel"stylesheet" t…
训练数据也外包?这家公司“承包”了不少注释训练数据,原来是这样做的……...
作者 | Lionbridge AI译者 | 天道酬勤 责编 | 徐威龙封图| CSDN│下载于视觉中国出品 | AI科技大本营(ID:rgznai100)在机器学习领域,训练数据准备是最重要且最耗时的任务之一。实际上,许多数据科学家声称数据科学的很…
JavaScript Switch 语句
avaScript Switch 语句如果希望选择执行若干代码块中的一个,你可以使用 switch 语句:语法:switch(n){case 1:执行代码块 1breakcase 2:执行代码块 2breakdefault:如果n即不是1也不是2,则执行此代码}工作原理:switch 后…

参观Speedy Cloud 有感
上周老男孩的所有学生参观了Speedy Cloud ,在这里我首先感谢Speedy Cloud的邀请和服务,我们每一个同学的收获都很大,不管是在以后的发展,还是现在的学习,都给了我很大的推动作用,帮助我去了解计算机的发展的…