Python数据清理终极指南(2020版)
作者 | Lianne & Justin
译者 | 陆离
出品 | AI科技大本营(ID:rgznai100)
一般来说,我们在拟合一个机器学习模型或是统计模型之前,总是要进行数据清理的工作。因为没有一个模型能用一些杂乱无章的数据来产生对项目有意义的结果。
数据清理或清除是指从一个记录集、表或是数据库中检测和修改(或删除)损坏或不准确的数据记录的过程,它用于识别数据中不完整的、不正确的、不准确的或者与项目本身不相关的部分,然后对这些无效的数据进行替换、修改或者删除等操作。
这是个很长的定义,不过描述的较为简单,容易理解。
为了简便起见,我们在Python中新创建了一个完整的、分步的指南,你将从中学习到如何进行数据查找和清理的一些方法:
缺失的数据;
不规则的数据(异常值);
不必要的数据——重复数据等;
不一致的数据——字母大小写、地址等。
在本文中,我们将使用Kaggle提供的俄罗斯房地产数据集(
https://www.kaggle.com/c/sberbank-russian-housing-market/overview/description),目标是要预测一下俄罗斯近期的房价波动。我们不会去清理整个数据集,因为本文只是会用到其中的一部分示例。
在对数据集开始进行清理工作之前,让我们先简单地看一下里面的数据。
从上述的结果中,我们了解到这个数据集总共有30471行和292列,还确定了特征是数值变量还是分类变量,这些对我们来说都是有用的信息。
现在可以查看一下“dirty”数据类型的列表,然后逐个进行修复。
让我们马上开始。
缺失的数据
处理缺失的数据是数据清理中最棘手但也是最常见的一种情况。虽然许多模型可以适应各种各样的情况,但大多数模型都不接受数据的缺失。
如何发现缺失的数据?
我们将为你介绍三种技术,可以进一步了解在数据集中的缺失数据。
1、缺失数据的热图
当特征数量较少的时候,我们可以通过热图来进行缺失数据的可视化工作。
下图显示了前30个特征的缺失数据样本。横轴表示特征的名称;纵轴显示观测的数量以及行数;黄色表示缺失的数据,而其它的部分则用蓝色来表示。
例如,我们看到特征life_sq在许多行中是有缺失值的。而特征floor在第7000行附近几乎就没有什么缺失值。
缺失数据热图
2、缺失数据的百分比列表
当在数据集中有足够多的特征时,我们可以为每个特征列出缺失数据的百分比。
这将在下面形成一个列表,用来显示每个特征的缺失值的百分比。
具体来说,我们看到特征life_sq缺失了21%的数据,特征floor则只缺失了1%。这个列表是一个较为有用的汇总,根据它就可以补充热图可视化了。
缺失数据的百分比列表——前30个特征
3、缺失数据的直方图
当我们有足够多特征的时候,缺失数据的直方图也是一种技术。
为了了解更多关于观测数据的缺失值样本的信息,我们可以使用直方图来对它进行可视化操作。
这个直方图有助于识别30471个观测数据中的缺失值情况。
例如,有6000多个没有缺失值的观测数据,而将近4000个观测数据中仅有一个缺失值。
缺失数据直方图
我们应该怎么做?
对于处理缺失的数据,没有任何一致的解决办法。我们必须在研究了特定的特征和数据集之后,来决定处理它们的最佳方式。
在下文中,分别介绍了四种处理缺失数据的常见方法。但是,如果遇到更复杂的情况,我们就需要利用一些相对更加复杂的方法,比如缺失数据建模等。
1、放弃观察
在统计学中,这种方法被称为列表删除技术。在这个方案中,只要包含了一个缺失值,我们就要删除整条的观测数据。
只有当我们确定所缺失的数据没有提供有用信息的时候,我们才能执行此操作。否则,我们应该考虑使用其它的办法。
当然,也可以使用其它标准来删除观察数据。
例如,从缺失数据的直方图中,我们可以看到总共缺失了至少35个以上的特征观测数据。我们可以创建一个新的数据集df_less_missing_rows,然后删除具有35个以上缺失特征的观测数据。
2、删除特征
与方案一比较类似,我们只有在确定当前特征没有提供任何有用信息的时候才能执行这个操作。
例如,从缺失数据百分比的列表中,我们注意到hospital_beds_raion的缺失值百分比高达47%。那么,我们就可以删除整个特征数据了。
3、填补缺失数据
当特征是一个数值变量的时候,可以进行缺失数据的填补。我们会将缺失的值替换为相同特征数据中已有数值的平均值或是中值。
当特征是一个分类变量的时候,我们可以通过模式(最频繁出现的值)来填补缺失的数据。
以life_sq为例,我们可以用它的中值来替换这个特征的缺失值。
此外,我们还可以同时对所有的数字特征使用相同的填补数据的方式。
比较幸运的是,我们的数据集中并没有缺失分类特征的值。然而,我们可以对所有的分类特征进行一次性的模式填补操作。
4、替换缺失的数据
对于分类特征,我们可以添加一个类似于“_MISSING_”这样的值,这是一种新类型的值。对于数值特征,我们可以使用-999这样的特殊值来替换它。
这样,我们仍然可以保留缺失值作为有用的信息。
不规则的数据(异常值)
异常值是与其它的观测值截然不同的数据,它们可能是真正的异常值或者是错误值。
如何发现不规则的数据?
根据特征是数值的还是分类的,我们可以使用不同的技术来研究其分布特点用以检测它的异常值。
1、直方图和方框图
当特征是数值的时候,我们可以使用直方图或者是方框图来检测它的异常值。
下面是特征life_sq的直方图。
由于可能存在异常值,因此,数据准确性的差别看起来是异常显著的。
直方图
为了更深入地研究这个特征,下面我们来画一个方框图。
在这个图中,我们可以看到一个超过7000的异常值。
方框图
2、描述性统计数据
此外,对于数值特征,异常值可能过于明显,以致方框图无法对其进行可视化。相反地,我们可以看看它们的描述性统计数据。
例如,对于特征life_sq,我们可以看到最大值是7478,而75%的四分位数只有43。很明显,7478值是一个异常值。
3、条形图
对于分类特征,我们可以使用条形图来了解特征的类别以及分布的情况。
例如,特征ecology具有合理的分布,但是,如果有一个类别只有一个叫做“other”的值,那么这肯定就是一个异常值。
条形图
4、其它的技术
还有许多其它的技术也可以用来发现异常值,例如散点图、z-score和聚类等等,在这里将不会一一进行讲解。
我们应该怎么做?
虽然寻找异常值并不是什么难事,但是我们必须确定正确的解决办法来进行处理。它高度依赖于所使用的数据集和项目的目标。
处理异常值的方法有些类似于缺失数据的操作。我们要么放弃、要么调整、要么保留它们。对于可能的解决方案,我们可以参考本文的缺失数据部分。
不必要的数据
在对缺失数据和异常值进行了所有的努力之后,让我们看看关于不必要的数据,这就更简单了。
首先,所有输入到模型中的数据都应该为项目的目标服务。不必要的数据就是数据没有实际的数值。根据不同的情况,我们主要划分了三种类型的不必要数据。
1、无信息或者重复值
有时,一个特征没有有用的信息,因为太多的行具有相同的值。
如何发现无信息或者重复值?
我们可以创建一个具有相同数值的百分比较高的特征列表。
例如,我们在下面指定显示95%以上的具有相同值的行的特征。
我们可以一个一个地研究这些变量,看看它们是否具有有价值的信息,在这里就不显示细节了。
我们应该怎么做?
我们需要了解重复特征背后的原因,当它们真的缺少有用信息的时候,就可以把它们放弃了。
2、不相关的数据
同样,数据需要为项目提供有用的信息。如果这些特征数据与我们在项目中要解决的问题没什么关系,那么它们就是不相关的。
如何发现不相关的数据?
首先,我们需要浏览一下这些特征,以便之后能识别那些不相关的数据。
例如,一个记录多伦多天气的特征数据并不能为预测俄罗斯房价提供任何有用的信息。
我们应该怎么做?
当这些特征数据并不符合项目的目标时,我们就可以放弃它们了。
3、重复数据
重复数据是指存在多个相同的观测值。
重复数据主要包含两种类型。
(1)基于所有特征的重复数据
如何发现基于所有特征的重复数据?
当观察到的所有特征数据都相同的时候,就会发生这种重复现象,这是很容易发现的。
我们首先要去除数据集中的唯一标识符id,然后通过删除重复数据来创建一个名为df_dedupped的数据集。我们通过比较两个数据集(df和df_deduped),找出有多少个重复行。
得出,10行是完全重复的观察结果。
我们应该怎么做?
我们应该删除这些重复数据。
(2)基于关键特征的重复数据
如何发现基于关键特征的重复数据?
有时最好根据一组唯一的标识符来删除那些重复的数据。
例如,同一建筑面积、同一价格、同一建筑年份的两个房产交易同时发生的可能性几乎为零。
我们可以设置一组关键特征作为交易的唯一标识符,包括timestamp、 full_sq、life_sq、floor、build_year、num_room、price_doc,我们会检查是否有基于这些标识符的副本(重复记录)。
基于这组关键特征,共有16个副本,也就是重复数据。
我们应该怎么做?
我们可以根据关键特征删除这些重复数据。
我们在名为df_dedupped2的新数据集中删除了16个重复数据。
不一致的数据
让数据集遵循特定的标准来拟合模型也是至关重要的。我们需要用不同的方法去探索数据,这样就可以找出不一致的数据了。很多时候,这取决于细致的观察和丰富的经验,并没有固定的代码用来运行和修复不一致的数据。
下面我们将介绍四种不一致的数据类型。
1、大小写不一致
在分类值中存在着大小写不一致的情况,这是一个常见的错误。由于Python中的数据分析是区分大小写的,因此这就可能会导致问题的出现。
如何发现大小写不一致?
先让我们来看看特征sub_area。
它用来存储不同地区的名称,看起来已经非常的标准化了。
但是,有时候在同一个特征数据中存在着大小写不一致的情况。举个例子,“Poselenie Sosenskoe”和“pOseleNie sosenskeo”就可能指的是同一地区。
我们应该怎么做?
为了避免这种情况的发生,我们要么所有的字母用小写,要么全部用大写。
2、数据格式不一致
我们需要实行的另一个标准化是数据格式。这里有一个例子,是将特征从字符串(String)格式转换为日期时间(DateTime)格式。
如何发现不一致的数据格式?
特征timestamp是以字符串的格式来表示日期的。
我们应该怎么做?
我们可以使用下面的代码进行转换,并提取出日期或时间的值。之后,会更容易按年或月进行分组的交易量分析。
3、数据的分类值不一致
不一致的分类值是我们要讨论的最后一种不一致数据的类型。分类特征值的数量有限。有时候由于输入错误等原因,可能会存在其它的值。
如何发现不一致的分类值?
我们需要仔细观察一个特征来找出不一致的值,在这里,我们用一个例子来说明一下。
由于我们在房地产数据集中并不存在这样的问题,因此,我们在下面创建了一个新的数据集。例如,特征city的值被错误地定义为“torontoo”和“tronto”。但它们两个都指向了正确的值“toronto”。
一种简单的确认方法是模糊逻辑(或是编辑间隔,edit distance)。它衡量了我们需要更改一个值的拼写用来与另一个值进行匹配的字母差异数量(距离)。
我们知道这些类别应该只有“toronto”、“vancouver”、“montreal”以及“calgary”这四个值。我们计算了所有的值与单词“toronto”(和“vancouver”)之间的距离。可以看到,那些有可能是打字错误的单词与正确的单词之间的距离较小,因为它们之间只差了几个字母而已。
我们应该怎么做?
我们可以设置一个标准将这些错误的拼写转换为正确的值。例如,下面的代码将距离“toronto”2个字母以内的所有值都设置为“toronto”。
4、地址数据不一致
地址特征目前成为了我们许多人最头疼的问题。因为人们经常在不遵循标准格式的情况下,就将数据输入到数据库中了。
如何发现不一致的地址?
我们可以通过查看数据来找到难以处理的地址。即使有时候我们发现不了任何问题,但我们还可以运行代码,对地址数据进行标准化处理。
在我们的数据集中没有属于隐私的地址。因此,我们利用特征address创建了一个新的数据集df_add_ex。
正如我们所看到的那样,地址数据可是非常不规范的。
我们应该怎么做?
我们运行下面的代码,目的是将字母统一变成小写的、删除空格、删除空行以及进行单词标准化。
现在看起来好多了。
我们终于完成了,经过了一个很长的过程,清除了那些所有阻碍拟合模型的“dirty”数据。
原文链接:
https://towardsdatascience.com/data-cleaning-in-python-the-ultimate-guide-2020-c63b88bf0a0d
【end】
◆
原力计划
◆
《原力计划【第二季】- 学习力挑战》正式开始!即日起至 3月21日,千万流量支持原创作者!更有专属【勋章】等你来挑战
推荐阅读
2019年度CSDN博客之星TOP10榜单揭晓,你上榜了吗?
Javascript函数之深入浅出递归思想,附案例与代码!
不看就亏系列!这里有完整的 Hadoop 集群搭建教程,和最易懂的 Hadoop 概念!| 附代码
智能合约编写之Solidity的基础特性
微信七年「封链」史
计算机博士、加班到凌晨也要化妆、段子手……IT 女神驾到!
你点的每个“在看”,我都认真当成了AI
相关文章:
内存地址转换与分段
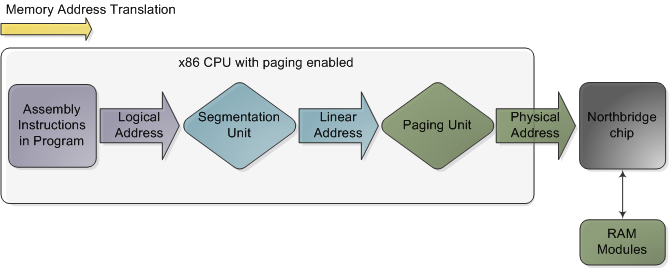
原文标题:Memory Translation and Segmentation 原文地址:http://duartes.org/gustavo/blog/ 翻译地址:http://blog.csdn.net/drshenlei/article/details/4261909 本文是Intel兼容计算机(x86)的内存与保护系列文章的第…

c++ 普通高精减
//c 普通高精减 //codevs 3115 高精度练习之减法 //内容简单,就不注释了。 //注意下,&&优先级高于||。 #include<cstdio>#include<cstring>char s1[600],s2[600];int a1[600],a2[600],len1,len2,i;int main(){scanf("%s",…
腾讯提超强少样本目标检测算法,公开1000类检测训练集FSOD | CVPR 2020
作者 | VincentLee来源 | 晓飞的算法工程笔记不同于正常的目标检测任务,few-show目标检测任务需要通过几张新目标类别的图片在测试集中找出所有对应的前景。为了处理好这个任务,论文主要有两个贡献:提出一个通用的few-show目标检测算法&#…
Linux加入到Windows域 收藏
一、实验环境: AD server:windows server 2003samba:redhat as5AD server的hostname和IP地址:turbomai-c<?xml:namespace prefix st1 ns "urn:schemas-microsoft-com:office:smarttags" />89f91.test.com 192…

哈希函数原理及实现
哈希解决冲突 1000以内的素数 一般的hash实现已经总结出一些比较重要的素数: static unsigned int table_size[] {7,13,31, 61, 127, 251, 509, 1021,2039, 4093, 8191, 16381, 32749, 65521,1310…

基于Virtual DOM与Diff DOM的测试代码生成
尽管是在年末,并且也还没把书翻译完,也还没写完书的第一稿。但是,我还是觉得这是一个非常不错的话题——测试代码生成。当我们在写一些UI测试的时候,我们总需要到浏览器去看一下一些DOM的变化。比如,我们点击了某个下拉…

Win32 环境下的堆栈
原文已经找不到,作者应该是:http://blog.csdn.net/slimak 但是没有找到此文,其中丢了2幅图 简介 在Win32环境下利用调试器调试应用程序的时候经常要和堆栈(Stack)打交道,尤其是在需要手工遍历堆栈(Manually Walking Stack)的时候我们需要…

在VMWare中配置SQLServer2005集群 Step by Step(四)——集群安装
在VMWare 中配置集群 1. 进入command 命令窗口执行以下命令,创建仲裁磁盘和共享数据磁盘 vmware-vdiskmanager.exe -c -s 200Mb -a lsilogic -t 2 F:\VM\Share\Windows\SQLServer\quorum.vmdk vmware-vdiskmanager.exe -c -s 4Gb -a lsilogic -t 2 F:\VM\Share\Wind…
口罩检测识别率惊人,这个Python项目开源了
作者 | 一颗小树x,CSDN 博主编辑 | 唐小引来源 | CSDN 博客昨天在 GitHub 上看到一个有趣的开源项目,它能检测我们是否有戴口罩,跑起程序测试后,发现识别率挺高的,也适应不同环境,于是分享给大家。首先感谢…
CentOS搭建msmtp+mutt实现邮件发送
1:搭建配置msmtp下载msmtp包:官方地址:http://msmtp.sourceforge.net/download.html编译,安装(官方下载的包为tar.xz格式):#xz -d msmtp-1.6.3.tar.xz #tar -xvf msmtp-1.6.3.tar #cd msmtp-1.6.3 #./configure --prefix /opt/app…

Linux环境下的堆栈--调试C程序
完整的调试过程,跟踪堆栈变化,32位下。 注意64位和此不同。 a.c代码: #include <stdio.h> int main() { AFunc(5,6);return 0; } int BFunc(int i,int j) {int m 1;int n 2;m i;n j; return m; }int AFunc(int i,int j) {…
听说过代码洁癖,Bug洁癖怎么解?
来源 | Python编程时光(ID: Cool-Python)当我们写的一个脚本或程序发生各种不可预知的异常时,如果我们没有进行捕获处理的时候,通常都会致使程序崩溃退出,并且会在终端打印出一堆 密密麻麻 的 traceback 堆栈信息来告诉…
POJO、VO、PO、FormBean区别:
首先讲一下四者的概念 POJO:Pure Old Java Object,符合Java Bean属性规范的简单Java对象,通常也称为VO(Value Object,值对象)。 VO:就是POJO; PO: Persistent Object,持久化对…
oracle中的sql%rowcount,sql%found、sql%notfound、sql%rowcount和sql%isopen
Oracle 存储过程 删除表记录时删除不存在的记录也是显示删除成功 create or replace procedure delDept(p_deptno in dept.deptno%type) is begindelete from dept where deptnop_deptno;dbms_output.put_line(部门删除成功...);exception when others thendbms_output.put_lin…

linux平台的链接与加载
原文是上下两篇 链接与加载(上) — 静态链接链接与加载(下) — 动态链接 为观看方便,现在合并起来。 一.静态链接 示例程序 我们先看一个简单的示例程序,代码如下: /*main.c*/int u 333;int sum(int, int);int main(int argc, char* argv…
预训练模型ProphetNet:根据未来文本信息进行自然语言生成
作者 | 刘大一恒、齐炜祯、晏宇、宫叶云、段楠、周明来源 | 微软研究院AI头条(ID:MSRAsia)编者按:微软亚洲研究院提出新的预训练模型 ProphetNet,提出了一种新的自监督学习目标——同时预测多个未来字符,在序列到序列的…

模拟进程管理小结,编码规范的重要性
废话不多说了,省的又有衰人找我麻烦。希望我讨厌的,和讨厌我的少来骚扰我,由衷的感谢它们。 我不回那些骚扰,是因为我见到名字就直接删了,看都懒的看了。也别怪我粗鲁,因为我一向是对什么人说什么话 的&…

JSPServlet路径问题
2019独角兽企业重金招聘Python工程师标准>>> 如果带WebRoot,那么js、css、img都应该放到WebRoot目录下,否则访问会有问题。千万不要放在WEB-INF下,因为WEB-INF下的内容只有服务器转发可以访问到,出于安全考虑。 如果不…
Git学习教程(六)Git日志
第六课 Git 日志 内容提要:浏览项目历史,查询指定提交内容,图形化显示分枝和合并...git log是git中最常用的一个命令,执行之后,会显示该项目的提交历史。如果命令不加任何参数,那么就会显示目前所在分枝上&…
汇编包含C代码
反汇编的时候带上C代码便于观察 比较三元表达式和if else的差异 a1.c #include <stdio.h> int main(void) { int a1;int b2;int c0;a (b>c)?1:0;return 0;} a2.c #include <stdio.h> int main(void) { int a1;int b2;int c0;if(b>c){a1;}else{a0;…
无需3D运动数据训练,最新人体姿势估计方法达到SOTA | CVPR 2020
作者 | Muhammed Kocabas译者 | 刘畅出品 | AI科技大本营(ID:rgznai100)人体的运动对于理解人的行为是非常重要的。尽管目前已经在单图像3D姿势和动作估计方面取得了进展,但由于缺少用于训练的真实的3D运动数据,因此现有的基于视频…

Linux内核跟踪之trace框架分析【转】
转自:http://blog.chinaunix.net/uid-20543183-id-1930846.html------------------------------------------本文系本站原创,欢迎转载!转载请注明出处:http://ericxiao.cublog.cn/------------------------------------------一: 前言本文主要是对trace的框架做详尽…
写给Python开发者:机器学习十大必备技能
作者 | Pratik Bhavsar译者 | 明明如月,编辑 | 夕颜来源 | CSDN(ID:CSDNnews)有时候,作为一个数据科学家,我们常常忘记了初心。我们首先是一个开发者,然后才是研究人员,最后才可能是数学家。我…

Linux环境程序栈溢出原理
当在缓冲区中输入过多的数据时,缓冲区溢出就会发生,C语言提供了多种方法,可以使在缓冲区中输入的数据比预期的多。 局部变量可以被分配到栈上。这就意味着在栈的某个地方有一个固定大小的缓冲区。 而栈是向下增长的,而且一些重要…
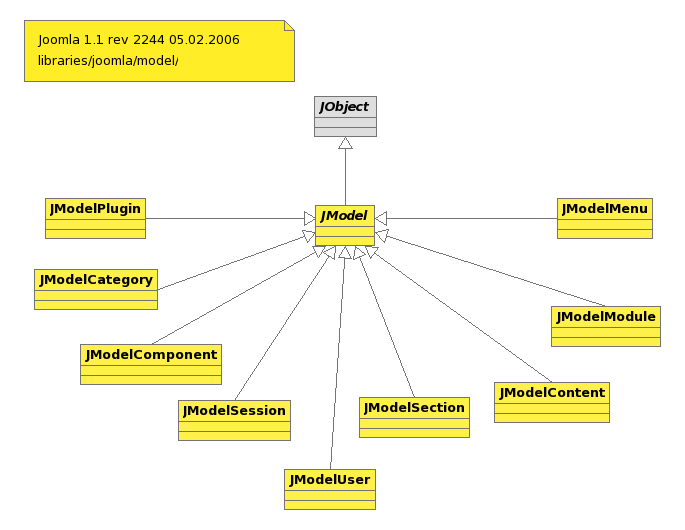
[翻译]Joomla 1.5架构(十一) model 包
这个包包含了跟数据表交互的所有相关类 JModel This abstract class is the base class for all Joomla! data access objects. 所有数据访问类的抽象基类。 以下的类都分别实现对不同表的访问,不再翻译了。 Adapter Folder JModelCategory This is a data access …
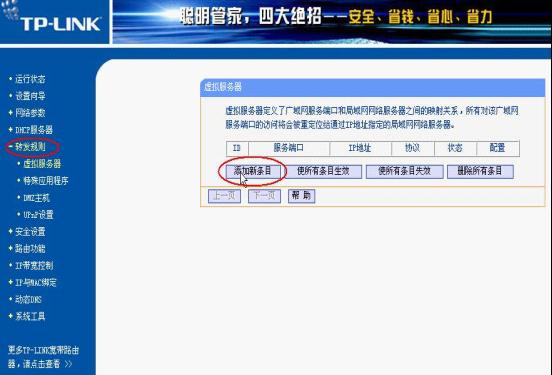
度量快速开发平台端口映射的介绍
度量快速开发平台在客户中部署的时候,可能会想内网与外网用户同时使用。一般情况下,服务端都是部署在内网的,那外网用户要访问,就可能用到端口映射的功能。端口映射基本都是在路由器上进行。下面就是几个常用的路由器上的设置方法…
为什么栈和堆的生长方向不一样
栈的生长方向 8051的栈是向高地址增长,INTEL的8031、8032、8048、8051系列使用向高地址增长的堆栈;但同样是INTEL,在x86系列中全部使用向低地址增长的堆栈。其他公司的CPU中除ARM的结构提供向高地址增长的堆栈选项外,多数都是使用…
简单粗暴理解与实现机器学习之逻辑回归:逻辑回归介绍、应用场景、原理、损失以及优化...
作者 | 汪雯琦责编 | Carol来源 | CSDN 博客出品 | AI科技大本营(ID:rgznai100)学习目标知道逻辑回归的损失函数知道逻辑回归的优化方法知道sigmoid函数知道逻辑回归的应用场景应用LogisticRegression实现逻辑回归预测知道精确率、召回率指标的区别知道如…

生命的脆弱——悼念朋友
生命的脆弱让我们敲希望的钟啊多少祈祷在心中让大家看不到失败叫成功永远在让地球忘记了转动啊四季少了夏秋冬让宇宙关不了天窗叫太阳不西沉让欢喜代替了哀愁啊微笑不会再害羞让时光懂得去倒流叫青春不开溜让贫穷开始去逃亡啊快乐健康留四方让世界找不到黑暗幸福像花开放让大家…
VMware Tools手动下载
2019独角兽企业重金招聘Python工程师标准>>> VMware自己下载VMware Tools非常慢。你可以自己手动下载它。 下载地址为: version: 8.8.2 http://softwareupdate.vmware.com/cds/vmw-desktop/ws/8.0.3/ 选择最新的build,例如: http:…