Flink在美团的应用与实践听课笔记
本文系《Flink在美团的应用与实践》的听课笔记
原始视频视频资源已经在优酷公开:2018.8.11 Flink China Meetup·北京站-Flink在美团的应用与实践
作者:刘迪珊@美团
1.现状和背景
实时平台架构

最底层是数据缓存层,可以看到美团测的所有日志类的数据,都是通过统一的日志收集系统收集到Kafka。
Kafka作为最大的数据中转层,支撑了美团线上的大量业务,包括离线拉取,以及部分实时处理业务等。
在数据缓存层之上,是一个引擎层,这一层的左侧是我们目前提供的实时计算引擎,包括Storm和Flink。
Storm在此之前是 standalone 模式的部署方式,Flink由于其现在运行的环境,美团选择的是On YARN模式,除了计算引擎之外,我们还提供一些实时存储功能,用于存储计算的中间状态、计算的结果、以及维度数据等,目前这一类存储包含Hbase、Redis以及ES。
在计算引擎之上,是趋于五花八门的一层,这一层主要面向数据开发的同学。实时数据开发面临诸多问题,例如在程序的调试调优方面就要比普通的程序开发困难很多。在数据平台这一层,美团面向用户提供的实时计算平台,不仅可以托管作业,还可以实现调优诊断以及监控报警,此外还有实时数据的检索以及权限管理等功能。
除了提供面向数据开发同学的实时计算平台,美团现在正在做的事情还包括构建元数据中心。这也是未来我们想做SQL的一个前提,元数据中心是承载实时流系统的一个重要环节,我们可以把它理解为实时系统中的大脑,它可以存储数据的Schema,Meta。架构的最顶层就是我们现在实时计算平台支撑的业务,不仅包含线上业务日志的实时查询和检索,还涵盖当下十分热门的实时机器学习。
机器学习经常会涉及到搜索和推荐场景,这两个场景最显著特点:
一、会产生海量实时数据;
二、流量的QPS相当高。此时就需要实时计算平台承载部分实时特征的提取工作,实现应用的搜索推荐服务。
还有一类是比较常见的场景,包括实时的特征聚合,斑马Watcher(可以认为是一个监控类的服务),实时数仓等。
实时平台现状
美团实时计算平台的现状是作业量现在已经达到了近万,集群的节点的规模是千级别的,天级消息量已经达到了万亿级,高峰期的消息量能够达到千万条每秒。

痛点和问题

美团在调研使用Flink之前遇到了一些痛点和问题:
实时计算精确性问题:在调研使用Flink之前美团很大规模的作业是基于Storm去开发的,Storm主要的计算语义是At-Least-Once,这种语义在保证正确性上实际上是有一些问题的,在Trident之前Storm是无状态的处理。虽然Storm Trident提供了一个维护状态的精确的开发,但是它是基于串行的Batch提交的,那么遇到问题在处理性能上可能会有一点瓶颈。并且Trident是基于微批的处理,在延迟上没有达到比较高的要求,所以不能满足一些对延迟比较高需求的业务。
流处理中的状态管理问题:基于之前的流处理过程中状态管理的问题是非常大的一类问题。状态管理除了会影响到比如说计算状态的一致性,还会影响到实时计算处理的性能以及故障恢复时候的能力。而Flink最突出的一个优势就是状态管理。
实时计算表义能力的局限性:在实时计算之前很多公司大部分的数据开发还是面向离线的场景,近几年实时的场景也慢慢火热起来了。那与离线的处理不同的是,实时的场景下,数据处理的表意能力可能有一定的限制,比如说他要进行精确计算以及时间窗口都是需要在此之上去开发很多功能性的东西。
开发调试成本高:近千结点的集群上已经跑了近万的作业,分布式的处理的引擎,手工写代码的方式,给数据开发的同学也带来了很高开发和调试的成本,再去维护的时候,运维成本也比较高。
Flink探索关注点
在上面这些痛点和问题的背景下,美团从去年开始进行Flink的探索,关注点主要有以下4个方面:
1.ExactlyOnce计算能力
2.状态管理能力
3.窗口/Join/时间处理等等
4.SQL/TableAPI
2.Flink在美团的实践
稳定性实践
稳定性实践-资源隔离

资源隔离的考虑:分场景、按业务
高峰期不同,运维时间不同;
可靠性、延迟需求不同;
应用场景,重要性不同;
资源隔离的策略:
1YARN打标签,节点物理隔离:
按照场景和业务维度考虑资源分配的问题和滴滴类似是yarn打标签的模式进行独立的队列的隔离。
重要业务的运行时的作业会独立在某一批机器上,避免其他业务的影响。
2离线DataNode与实时计算节点的隔离:
之前都是on yarn为了节约成本计算和存储节点就混布,发现离线DataNode某一段时间数据量大导致出现毛刺现象。
这时会对实时计算的稳定性造成影响。
稳定性实践-智能调度

yarn基于CPU和内存去调度
智能调度目的也是为了解决资源不均的问题,现在普通的调度策略就是基于CPU,基于内存去调度的。除此之外,在生产过程中也发现了一些其他的问题,比如说Flink是会依赖本地磁盘,进行依赖本地磁盘做本地的状态的存储,所以磁盘IO,还有磁盘的容量,也是一类考虑的问题点,除此之外还包括网卡流量,因为每个业务的流量的状态是不一样的,分配进来会导致流量的高峰,把某一个网卡打满,从而影响其他业务,所以期望的话是说做一些智能调度化的事情。目前暂时能做到的是从cpu和内存两方面,未来会从其他方面做一些更优的调度策略。
稳定性实践-故障容错

1.节点/网络故障
JobManagerHA,自动拉起
与Storm不同的是,知道Storm在遇到异常的时候是非常简单粗暴的,比如说有发生了异常,可能用户没有在代码中进行比较规范的异常处理,但是没有关系,因为worker会重启作业还会继续执行,并且他保证的是At-Least-Once这样的语义,比如说一个网络超时的异常对他而言影响可能并没有那么大,
Flink不同的是他对异常的容忍度是非常的苛刻的,那时候就考虑的是比如说会发生节点或者是网络的故障,那JobManager单点问题可能就是一个瓶颈,JobManager那个如果挂掉的话,那么可能对整个作业的影响就是不可回复的,所以考虑了做HA,另外一个就是会去考虑一些由于运维的因素而导致的,还有除此之外,可能有一些用户作业是没有开启CheckPoint,但如果是因为节点或者是网络故障导致挂掉,希望会在平台那一层做一些自动拉起的策略,去保证作业运行的稳定性。
2.上下游容错
FlinkKafka 08异常重试
我们的数据源主要是Kafka,读写Kafka是一类非常常见的实时流处理避不开的一个内容,而Kafka本身的集群规模是非常比较大的,因此节点的故障出现是一个常态问题,在此基础上我们对节点故障进行了一些容错,比如说节点挂掉或者是数据均衡的时候,Leader会切换,那本身Flink的读写对Leader的切换容忍度没有那么高,在此基础上我们对一些特定场景的,以及一些特有的异常做的一些优化,进行了一些重试。这是影响作业稳定性的一个点。
3.容灾
多机房,流热备
Flink平台化-作业管理
容灾可能大家对考虑的并不多,比如说有没有可能一个机房的所有的节点都挂掉了,或者是无法访问了,虽然它是一个小概率的事件,但它也是会发生的。所以现在也会考虑做多机房的一些部署,包括还有Kafka流的一些热备。

在实践过程中,为了解决作业管理的一些问题,减少用户开发的一些成本,我们做了一些平台化的工作,下图是一个作业提交的界面展示,包括作业的配置,作业生命周期的管理,报警的一些配置,延迟的展示,都是集成在实时计算平台的。
Flink平台化-监控报警
在监控上我们也做了一些事情,对于实时作业来讲,对监控的要求会更高,比如说在作业延迟的时候对业务的影响也比较大,所以做了一些延迟的报警,包括作业状态的报警,比如说作业存活的状态,以及作业运行的状态,还有未来会做一些自定义Metrics的报警。自定义Metrics是未来会考虑基于作业处理本身的内容性,做一些可配置化的一些报警。

Flink平台化-调优诊断
实时计算引擎提供统一日志和Metrics方案
为业务提供按条件过滤的日志检索
为业务提供自定义时间跨度的指标查询
基于日志和指标,为业务提供可配置的报警
另外就是刚刚提到说在开发实时作业的时候,调优和诊断是一个比较难的痛点,就是用户不是很难去查看分布式的日志,所以也提供了一套统一的解决方案。这套解决方案主要是针对日志和Metrics,会在针对引擎那一层做一些日志和Metrics的上报,那么它会通过统一的日志收集系统,将这些原始的日志,还有Metrics汇集到Kafka那一层。今后Kafka这一层大家可以发现它有两个下游,
一方面:是做日志到ES的数据同步,目的的话是说能够进入日志中心去做一些日志的检索,
另外一方面:是通过一些聚合处理流转到写入到OpenTSDB把数据做依赖,这份聚合后的数据会做一些查询,一方面是Metrics的查询展示,另外一方面就是包括实做的一些相关的报警。

下图是当前某一个作业的一个可支持跨天维度的Metrics的一个查询的页面。可以看到说如果是能够通过纵向的对比,可以发现除了作业在某一个时间点是因为什么情况导致的?比如说延迟啊这样容易帮用户判断一些他的做作业的一些问题。除了作业的运行状态之外,也会先就是采集一些节点的基本信息作为横向的对比

下图是当前的日志的一些查询,它记录了,因为作业在挂掉之后,每一个ApplicationID可能会变化,那么基于作业唯一的唯一的主键作业名去搜集了所有的作业,从创建之初到当前运行的日志,那么可以允许用户的跨Application的日志查询。

生态建设
Flink落地做了一些生态的建设,
线上的MQ和面向生产环境的Kafka,虽然他们底层都是依赖kafka但是面向的场景是不同的。
线上MQ的特点是单集群的规模比较小,但是对延迟的要求合需求比较高。
生产类的kafka的特点是规模比较大,需要承担离线+实时的生产,要求这个集群要高吞吐。
为了适配这两类MQ做了不同的事情:
对于线上的MQ,期望去做一次同步,多次消费,目的是避免对线上的业务造成影响。
对于的生产类的Kafka就是线下的Kafka,做了一些地址的屏蔽,还有基础的一些配置,包括一些权限的管理,还有指标的采集。

3.Flink在美团的应用
下面会给大家讲两个Flink在美团的真实使用的案例。
第一个是Petra,Petra其实是一个实时指标的一个聚合的系统,它其实是面向公司的一个统一化的解决方案。它主要面向的业务场景就是基于业务的时间去统计,还有计算一些实时的指标,要求的话是低时延,他还有一个就是说,因为它是面向的是通用的业务,由于业务可能是各自会有各自不同的维度,每一个业务可能包含了包括应用,通道,机房,还有其他的各自应用各个业务特有的一些维度,而且这些维度可能涉及到比较多,另外一个就是说它可能是就是业务需要去做一些复合的指标的计算,比如说最常见的交易成功率,他可能需要去计算支付的成功数,还有和下单数的比例。
另外一个就是说统一化的指标聚合可能面向的还是一个系统,比如说是一些B端或者是R段的一些监控类的系统,那么系统对于指标系统的诉求,就是说我希望指标聚合能够最实时最精确的能够产生一些结果,数据保证说它的下游系统能够真实的监控到当前的信息。右边图是我当一个Metrics展示的一个事例。可以看到其他其实跟刚刚讲也是比较类似的,就是说包含了业务的不同维度的一些指标汇聚的结果。


在用Flink去做实时指标复核的系统的时候,着重从这几方面去考虑了。
第一个方面是说精确的计算,包括使用了FLink和CheckPoint的机制去保证说我能做到不丢不重的计算,第一个首先是由统一化的Metrics流入到一个预聚合的模块,预聚合的模块主要去做一些初始化的一些聚合,其中的为什么会分预聚合和全量聚合主要的解决一类问题,包括就刚刚那位同学问的一个问题,就是数据倾斜的问题,比如说在热点K发生的时候,当前的解决方案也是通过预聚合的方式去做一些缓冲,让尽量把K去打散,再聚合全量聚合模块去做汇聚。那其实也是只能解决一部分问题,所以后面也考虑说在性能的优化上包括去探索状态存储的性能。
下面的话还是包含晚到数据的容忍能力,因为指标汇聚可能刚刚也提到说要包含一些复合的指标,那么复合的指标所依赖的数据可能来自于不同的流,即便来自于同一个流,可能每一个数据上报的时候,可能也会有晚到的情况发生,那时候需要去对数据关联做晚到的容忍,容忍的一方面是说可以设置晚到的Lateness的延迟,另一方面是可以设置窗口的长度,但是其实在现实的应用场景上,其实还有一方面考虑就是说除了去尽量的去拉长时间,还要考虑真正的计算成本,所以在这方面也做了一些权衡,那么指标基本就是经过全量聚合之后,聚合结果会回写Kafka,经过数据同步的模块写到OpenTSDB去做,最后去grafana那做指标的展示,另一方面可能去应用到通过Facebook包同步的模块去同步到报警的系统里面去做一些指标,基于指标的报警。
指标---全量聚合---kafka---OpenTSDB---grafana

下图是现在提供的产品化的Petra的一个展示的机示意图,可以看到目前的话就是定义了某一些常用的算子,以及维度的配置,允许用户进行配置话的处理,直接去能够获取到他期望要的指标的一个展示和汇聚的结果。目前还在探索说为Petra基于Sql做一些事情,因为很多用户也比较就是在就是习惯上也可以倾向于说我要去写Sql去完成这样的统计,所以也会基于此说依赖Flink的本身的对SQl还有TableAPI的支持,也会在Sql的场景上进行一些探索。
MLX机器学习平台
第二类应用就是机器学习的一个场景,机器学习的场景可能会有依赖离线的特征数据和实时的特征数据。
一个是基于现有的离线场景下的特征提取,经过批处理,流转到离线的集群。
另一个就是近线模式,近线模式出的数据就是现有的从日志收集系统流转过来的统一的日志,经过Flink的处理,就是包括流的关联以及特征的提取,再做模型训练,流转到最终训练集群,训练集群会产出P的特征,还有都是Delta的特征,最终将这些特征影响到线上的线上的特征的一个训练的一个服务上。

相关文章:

[LeetCode]题解(python):150-Evaluate Reverse Polish Notation
题目来源: https://leetcode.com/problems/evaluate-reverse-polish-notation/ 题意分析: 给定一个数组,用这个数组来表示加减乘除,例如 ["2", "1", "", "3", "*"] -> ((2 …

微软苹果服务器宕机,苹果服务器宕机,iPhone用户别做这两项操作,微软特斯拉也中招...
原标题:苹果服务器宕机,iPhone用户别做这两项操作,微软特斯拉也中招虽然苹果一直都以安全来标榜自己,而事实上也确实如此。IOS封闭的环境,相对与安卓这个开放的环境确实要更加安全一些。苹果可以很好的抵御外来的风险&…
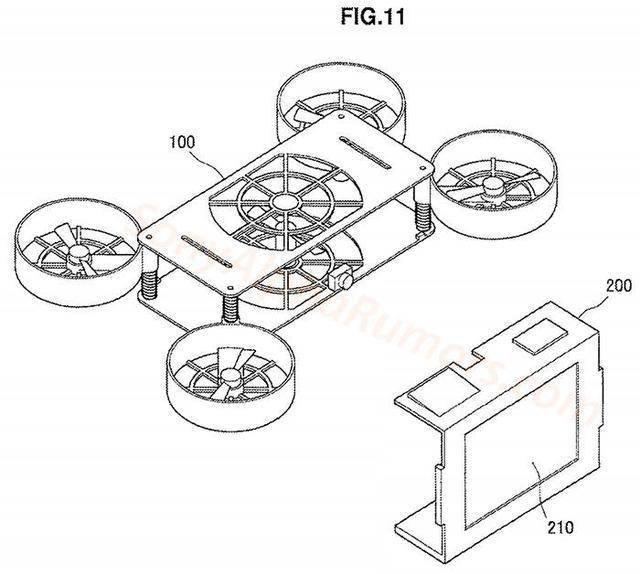
索尼发布无人机相机专利,支持眼部对焦
无人机将采用可折叠式设计,无需使用手机就能操控。 目前消费级无人机的行业霸主自然是大疆无疑,前段时间推出的Mavic 2再次让我们领略了大疆无人机的实力。不过近日,索尼在日本公布了其首个无人机相机专利技术,似乎在向大疆发起挑…
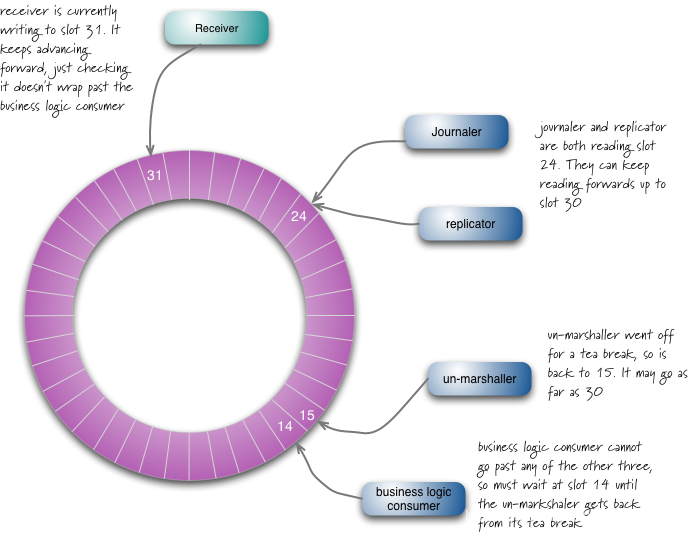
你需要知道的高性能并发框架Disruptor原理
Disruptor的小史 现在要是不知道Disruptor真的已经很outer了,Disruptor是英国外汇交易公司LMAX开发的一款开源的高性能队列,LMAX Disruptor是一个高性能的线程间消息传递库,它源于LMAX对并发性,性能和非阻塞算法的研究࿰…

c++11 多线程 1c++ concurrency in action
一、并行、多线程 1、计算机中的并行有两种方式:任务切换、利用多处理器多核。 纯粹的任务切换: 纯粹的多处理器多核: 任务切换与多处理器多核结合: 实际应用中是“任务切换与多处理器多核结合”方式,首先现在硬件偏移…

芯片刀片服务器,使用“刀片服务器”其实不难
刀片服务器已经轰轰烈烈地吵了将近两年的时间,市场上的刀片服务器产品也越来越多,所使用的芯片种类也逐渐发展为intel、amd、power等几种,支持的平台也包括了unix和ia架构。2005年底,hp还推出了基于安腾2平台的bl60p产品ÿ…

Prometheus 对比 Zabbix
公司要上监控,Prometheus 是最热门的监控解决方案,作为喜新厌旧的程序员,我当然是选择跟风了,但上级更倾向于 Zabbix,那没办法,只能好好对比一番,给出几个靠谱的理由了。 但稍稍深入一点&#x…

好理解的Java内存虚假共享(False Sharing)性能损耗以及解决方案
虚假共享(False Sharing)也有人翻译为伪共享 参考 https://en.wikipedia.org/wiki/False_sharing 在计算机科学中,虚假共享是一种性能降低的使用模式,它可能出现在具有由高速缓存机制管理的最小资源块大小的分布式一致高速缓存的系统中。当系统参与者将…
delphi xe 文件服务器,DelphiXE7中创建WebService(服务端+客户端)
相关资料:http://www.2ccc.com/news/Html/?1507.htmlhttp://www.dfwlt.com/forum.php?modviewthread&tid922DelphiXE7新建WebService具体操作:1.打开“DelphiXE7”->“File”->“New”->“Other”2.“New Items”->“Delph…
Android app 别用中文名
/************************************************************************** Android app 别用中文名* 说明:* 本来想分析一下这份源代码,结果发现因为项目名中有中文不能自动生成R* 文件,于是不想分析了。** …
一线互联网常见的14个Java面试题,你颤抖了吗程序员
跳槽不算频繁,但参加过不少面试(电话面试、face to face面试),面过大/小公司、互联网/传统软件公司,面糊过(眼高手低,缺乏实战经验,挂掉),也面过人࿰…
复化梯形公式,Newton-Cotes公式,变量代换后的复化梯形公式,Gauss-Legendre公式,Gauss-Jacobi公式插值积分的精确度比较
1.问题 分别计算积分 Ic∫01cosxxdx1.809048475800...I_c\int_0^1\frac{\cos{x}}{\sqrt{x}}dx1.809048475800... Ic∫01xcosxdx1.809048475800... Is∫01sinxxdx0.620536603446I_s\int_0^1\frac{\sin{x}}{\sqrt{x}}dx0.620536603446 Is∫01xsinxdx0.62053…

Elasticsearch 知识点目录
2019独角兽企业重金招聘Python工程师标准>>> 经过一段时间的编写,完成了第一个版本的Elasticsearch书籍的编写,目录结构如下: 1 Elasticsearch入门 7 1.1 Elasticsearch是什么 7 1.1.1 Elasticsearch是什么 7 1.1.2 Elasticsearch…

不要千言万语,一组漫画让你秒懂最终一致性
直接上图 如果你以前看过最终一致性的定义那么你一定会为这幅精彩漫画拍手叫好。 你要是不知道什么是最终一致性你可以看看下面的权威定义,当然了网上关于什么是最终一致性的帖子铺天盖地,也许你已经很明白了,即使这样你是不是依然为此图欢呼…
Feign实现服务调用
上一篇博客我们使用ribbonrestTemplate实现负载均衡调用服务,接下来我们使用feign实现服务的调用,首先feign和ribbon的区别是什么呢? ribbon根据特定算法,从服务列表中选取一个要访问的服务; RoundRobinRule:轮询RandomRule:随机Availability…

度量,跟踪和日志记录
今天,我有幸参加了2017年的分布式追踪峰会,其中有很多来自AWS / X-Ray,OpenZipkin,OpenTracing,Instana,Datadog,Librato等公司的人员,我很遗憾我忘记了这一点。有一次讨论转向了项目…
python 第六章 函数 pta(1)
1.Multiple-Choice 1.print(type(lambda:3))的输出结果是____。 A.<class ‘function’> B.<class ‘int’> C.<class ‘NoneType’> D.<class ‘float’> 答案:A 2.在Python中,对于函数定义代码的理解,正确的理解…
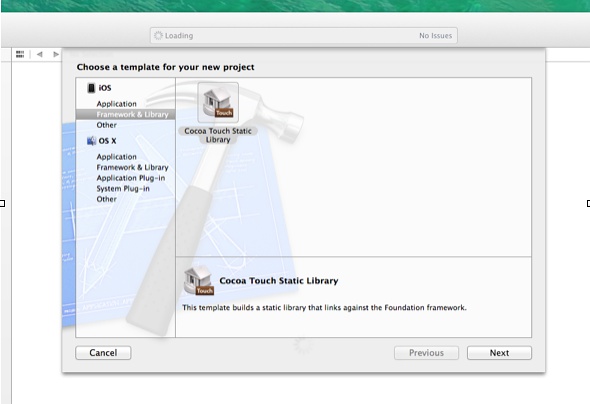
生成.a文件步骤
1.新建一个Project 选择 iOS->Framework & Library ->Cocoa Touch Static Library点击Next-> 输入Product Name 2.删除自动生成的文件 替换成我们需要的文件 如:原本自定生成的文件为继承自NSObject的,而你需要的为继承自UIView的ÿ…
机器学习之优雅落地线性回归法
在统计学中,线性回归(Linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析维基百科。简单线性回归当只有一个自变量的时候,成为简单线性回归。简单线性回归模型的思…
SpringBoot整合Grpc实现跨语言RPC通讯
什么是gRPC gRPC是谷歌开源的基于go语言的一个现代的开源高性能RPC框架,可以在任何环境中运行。它可以有效地连接数据中心内和跨数据中心的服务,并提供可插拔的支持,以实现负载平衡,跟踪,健康检查和身份验证。它还适用…
python 第六章 函数
1.函数的定义 def 名称(形参): 函数体 2.函数的调用 名称(实参) 单独文件:模块 调用方式——模块.名称 3.函数的参数类型 1.位置参数: def add(a,b):add(2,3) #顺序,个数,数据类型都要相同!!…
C++简单使用Jsoncpp来读取写入json文件
一、源码编译 C操作json字符串最好的库应该就是jsoncpp了,开源并且跨平台。它可以从这里下载。 下载后将其解压到任意目录,它默认提供VS2003和VS2010的工程文件,使用VS2010可以直接打开makefiles\msvc2010目录下的sln文件。 工程文件提供Json…
BZOJ 3420: Poi2013 Triumphal arch
二分答案 第二个人不会走回头路 那么F[i]表示在i的子树内(不包括i)所需要的额外步数 F[1]0表示mid可行 k可能为0 #include<cstdio> #include<algorithm> using namespace std; int cnt,n,mid,F[300005],last[300005]; struct node{int to,next; }e[600005]; void a…
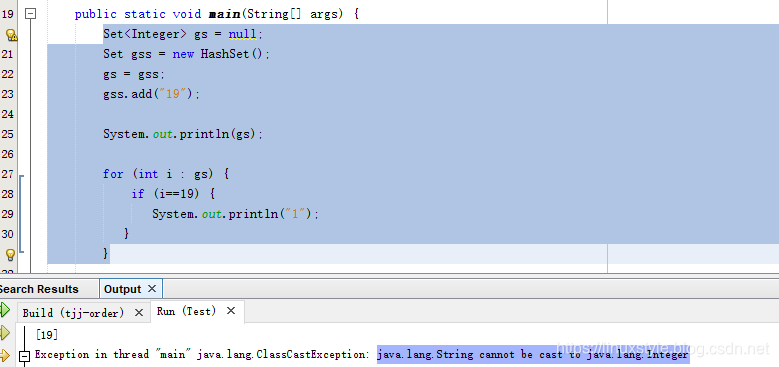
Java泛型使用需要小心
这是源自实际开发的一个坑,只是被我简化了。 Set<Integer> gs null;Set gss new HashSet();gs gss;gss.add("19");System.out.println(gs);for (int i : gs) {if (i19) {System.out.println("1");}} 代码经过一些转换你如果不注意以…
证明实对称正定矩阵A的Gauss-Seidel法必定收敛(完整过程)
Solution: \quad将nnn阶实对称矩阵AAA设为D−L−LTD-L-L^TD−L−LT,其中DDD是AAA的所有主对角元素构成对角矩阵,−L-L−L是AAA的所有主对角线以下的元素构成的严格下三角矩阵。 \quad此时Gauss−SeidelGauss-SeidelGauss−Seidel法的迭代矩阵为(D−L)−1LT(…
5月中旬的一些总结
考完英语口语了,最大的帮助就是找到了练习的方法和思路。 周三晚上有谷歌的全球IO大会。 ******** 写吴斌老师的课程作业,这才发现winedt过期了。用了rept之后本来是解决问题了,可是一联网就又不行了。总要关上再打开。用防火墙阻断却找不到选…
项目总结10:通过反射解决springboot环境下从redis取缓存进行转换时出现ClassCastException异常问题...
通过反射解决springboot环境下从redis取缓存进行转换时出现ClassCastException异常问题 关键字 springboot热部署 ClassCastException异常 反射 redis 前言 最近项目出现一个很有意思的问题,用户信息(token)储存在redis中;在获取token,反序列…
Rouche Theorem(Stein复分析)
Rouche Theorem: \quadIffandgareholomorphicfunctionsinaregionΩcontainingacircleCanditsinterior,and∣f(z)∣≥∣g(z)∣forz∈C,fandfghavethesamenumbersofzerosinsidethecircleC.If\quad f\quad and\quad g\quad are\quad holomorphic\quad functions\quad i…

Java线上程序频繁JVM FGC问题排障与启示
线上Java程序的JVM频繁FGC,现象如图所示: 一直持续FGC 5次左右,每次耗时1秒多不等。 FGC的原因实际上是内存不够用,但是运维反映堆内存是2G,从运维提供的参数看也是。 内存实际上一直只用到1G以内。 这时候可以自己写…

python常用数据结构的常用操作
作为基础练习吧。列表LIST,元组TUPLE,集合SET,字符串STRING等等,显示,增删,合并。。。 #List shoplist [apple,mango,carrot,banana] print I have ,len(shoplist), items to purchase. print These items are: for …