你需要知道的高性能并发框架Disruptor原理
Disruptor的小史
现在要是不知道Disruptor真的已经很outer了,Disruptor是英国外汇交易公司LMAX开发的一款开源的高性能队列,LMAX Disruptor是一个高性能的线程间消息传递库,它源于LMAX对并发性,性能和非阻塞算法的研究,如今构成了其Exchange基础架构的核心部分。
稍后,包括Apache Storm、Camel、Log4j等在内的很多知名项目都集成了Disruptor。国内不少一线大厂技术团队也在用,或者借鉴了其优秀的架构思想。Disruptor通过无锁设计实现了高并发高性能,其设计思想可以扩展到分布式环境,通过无锁设计来提升服务的高性能。
Martin Fowler的布道
著名的软件设计模式专家Martin Fowler专门写了一篇文章来推广https://martinfowler.com/articles/lmax.html
LMAX是一个新的零售金融交易平台。因此,它必须以低延迟处理许多交易。该系统构建于JVM平台之上,并以业务逻辑处理器为中心,可在单个线程上处理每秒600万个订单。业务逻辑处理器使用事件源完全在内存中运行。业务逻辑处理器被Disruptors包围 - Disruptors是一个并发组件,它实现了一个无需锁定即可运行的队列网络。在设计过程中,团队得出结论,使用队列的高性能并发模型的最新方向与现代CPU设计基本不一致。
Disruptor数据结构
在原始级别,可以将Disruptor视为队列的多播图,其中生产者在其上放置对象,这些对象通过单独的下游队列发送给所有消费者以供并行使用。当你查看内部时,你会看到这个队列网络实际上是一个单一的数据结构 - 一个环形缓冲区。
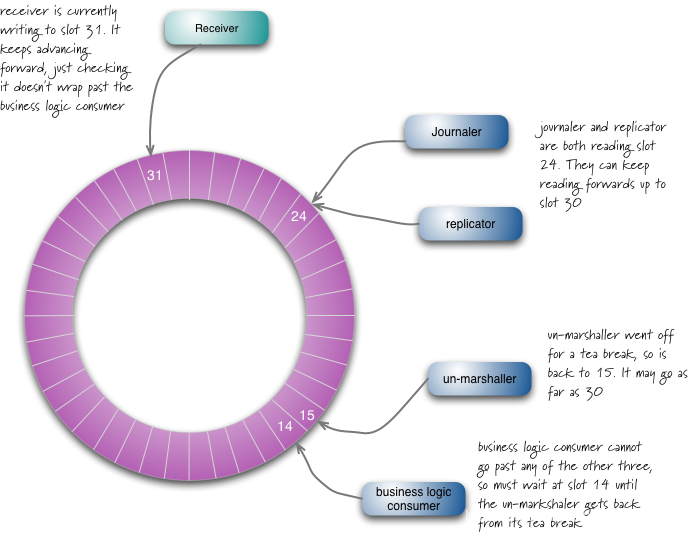
每个生产者和消费者都有一个序列计数器,用于指示它当前正在处理的缓冲区中的哪个槽。每个生产者/消费者编写自己的序列计数器,但可以读取其他序列计数器。通过这种方式,生产者可以读取消费者的计数器,以确保可以在没有计数器锁定的情况下使用它想要写入的插槽。类似地,消费者可以确保它只通过观察计数器一旦另一个消费者完成消息就处理消息。
输出Disruptor类似,但它们只有两个连续的消费者用于编组和输出。输出事件被组织成几个主题,因此消息只能发送给对它们感兴趣的接收者。每个主题都有自己的Disruptor。
我所描述的Disruptor以一种生产者和多种消费者的风格使用,但这并不是对Disruptor设计的限制。Disruptor也可以与多个生产者一起工作,在这种情况下它仍然不需要锁。
Disruptor设计的一个好处是,如果消费者遇到问题而落后,它可以让消费者更容易赶上。如果解组器在插槽15上处理时出现问题并且当接收器在插槽31上时返回,则它可以从一个批次中的插槽16-30读取数据以赶上。批量读取来自Disruptor的数据使得滞后的消费者更容易赶上,从而减少总体延迟。
环形缓冲区很大:输入缓冲区有2000万个插槽,每个输出缓冲区有400万个插槽。序列计数器是64位长整数,即使在环形槽缝合时也会单调增加。缓冲区设置为2的幂的大小,因此编译器可以执行有效的模运算以从序列计数器编号映射到槽号。与系统的其他部分一样,Disruptor在一夜之间被反弹。这种反弹主要用于擦除内存,以便在交易过程中发生昂贵的垃圾收集事件的可能性较小。(我也认为定期重启是一个好习惯,所以你要排练如何在紧急情况下这样做。)
Disruptor在哪里
https://github.com/LMAX-Exchange/disruptor/
理解Disruptor是什么的最好方法是将它与目前很好理解和非常相似的东西进行比较。可以把Disruptor类比成Java的阻塞队列BlockingQueue。像队列一样,Disruptor的目的是在同一进程内的线程之间移动数据(例如消息或事件)。但是,Disruptor提供了一些将其与队列区分开来的关键功能。他们是:
1)具有消费者依赖关系图的消费者多播事件。
2)为事件预分配内存。
3)可选择无锁模式。
Disruptor核心概念
在我们理解Disruptor是如何工作之前,需要先理解一些Disruptor团队定义的术语。
- Ring Buffer环形缓冲区:环形缓冲区通常被认为是Disruptor的核心,但是从3.0开始,环形缓冲区仅负责存储和更新通过Disruptor的数据(事件)。对于一些高级用例,可以完全由用户替换。
- Sequence序列:Disruptor使用Sequences作为识别特定组件所在位置的方法。每个消费者(EventProcessor)都像Disruptor本身一样维护一个Sequence。大多数并发代码依赖于这些Sequence值的移动,因此Sequence支持AtomicLong的许多当前功能。事实上,两者之间唯一真正的区别是序列包含额外的功能,以防止序列和其他值之间的共享错误。
- Sequencer:Sequencer是Disruptor真正的核心。该接口的两个实现(单生成者,多生产者)实现了所有并发算法,用于在生产者和消费者之间快速而又正确地传递数据。
- Sequence Barrier序列屏障:序列屏障由序列发生器产生,包含对序列发生器中主要发布的序列和任何依赖性消费者的序列的引用。它包含确定是否有任何可供消费者处理的事件的逻辑。
- Wait Strategy等待策略:等待策略确定消费者如何等待生产者将事件放入Disruptor。有关可选锁定的部分中提供了更多详细信息。
- Event事件:从生产者传递给消费者的数据单位。事件没有特定的代码表示,因为它完全由用户定义。
- EventProcessor:用于处理来自Disruptor的事件的主事件循环,并具有消费者序列的所有权。有一个名为 BatchEventProcessor的表示,它包含事件循环的有效实现,并将回调到使用的提供的EventHandler接口实现。
- EventHandler:由用户实现并代表Disruptor的使用者的接口。
- 生产者:这是调用Disruptor以将事件排入队列的用户代码。这个概念在代码中也没有表示。
为了将这些元素置于上下文中,下面是LMAX如何在其高性能核心服务(例如交换)中使用Disruptor的示例。
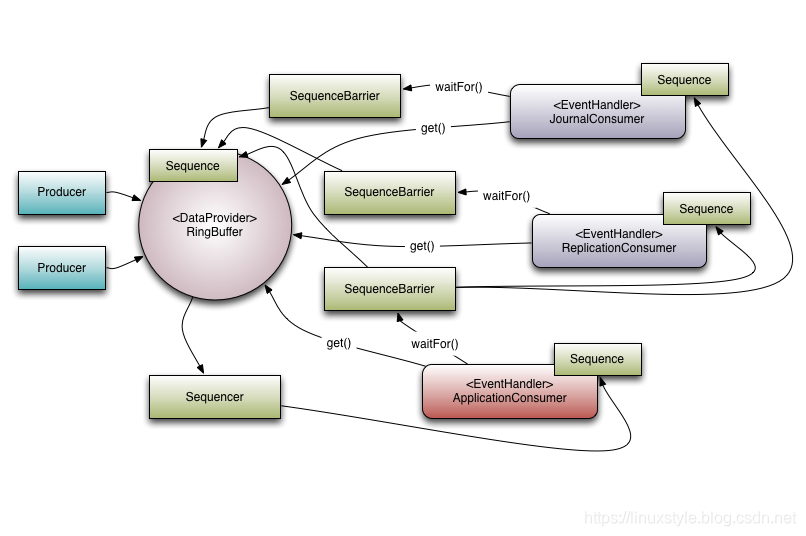
图1.具有一组依赖消费者的Disruptor
多播事件
这是普通队列和Disruptor之间最大的行为差异。当您有多个消费者在同一个Disruptor上监听时,所有事件都会发布给所有消费者,而不是一个事件只发送给单一消费者队列。Disruptor的行为旨在用于需要对同一数据进行独立多个并行操作的情况。
来自LMAX的规范示例是我们有三个操作,即日志记录(将输入数据写入持久性日志文件),复制(将输入数据发送到另一台机器以确保存在数据的远程副本)和业务逻辑(真正的处理工作)。
Executor风格的事件处理,通过在同一处并行处理不同的事件来找到比例,也可以使用WorkerPool。请注意,它是在现有的Disruptor类之上进行的,并且不会使用相同的第一类支持进行处理,因此它可能不是实现该特定目标的最有效方法。
查看图1可以看到有3个事件处理程序(JournalConsumer,ReplicationConsumer和ApplicationConsumer)监听Disruptor,这些事件处理程序中的每一个都将按相同的顺序接收Disruptor中可用的所有消息,允许每个消费者的工作并行进行。
消费者依赖图
为了支持并行处理行为的实际应用,有必要支持消费者之间的协调。返回参考上述示例,必须防止业务逻辑消费者在日志记录和复制消费者完成其任务之前取得进展。我们称这个概念为门控,或者更准确地说,这种行为的超集特征称为门控(concept gating)。
门控发生在两个地方。
首先,我们需要确保生产者不会超过消费者。这是通过调用RingBuffer.addGatingConsumers()将相关的使用者添加到Disruptor来处理的。
其次,先前提到的情况是通过从必须首先完成其处理的组件构造包含序列的SequenceBarrier来实现的。
参考图1有3个消费者正在收听来自Ring Buffer的事件。此示例中有一个依赖关系图。ApplicationConsumer依赖于JournalConsumer和ReplicationConsumer。这意味着JournalConsumer和ReplicationConsumer可以彼此并行的运行。从ApplicationConsumer的SequenceBarrier到JournalConsumer和ReplicationConsumer的序列的连接可以看到依赖关系。
值得注意的是Sequencer与下游消费者之间的关系。它的一个作用是确保发布不包装Ring Buffer。要做到这一点,下游消费者中没有一个可能具有低于环形缓冲区序列的序列,而不是环形缓冲区的大小。但是,使用依赖关系图可以进行优化。由于ApplicationConsumers Sequence保证小于或等于JournalConsumer和ReplicationConsumer(这是该依赖关系所确保的),因此Sequencer只需要查看ApplicationConsumer的Sequence。在更一般的意义上,Sequencer只需要知道作为依赖关系树中叶节点的使用者的序列。
事件预分配
Disruptor的设计目标之一是能在低延迟环境中使用。在低延迟系统中,必须减少或移除内存分配。在基于Java的系统中,目的是减少由于垃圾收集GC导致的系统停顿(在低延迟C / C ++系统中,由于存在于内存分配器上的争用,大量内存分配也存在问题)。
为了支持这一点,用户可以提前分配Disruptor中事件所需的存储空间。在构造期间,EventFactory由用户提供,并将在Disruptor的Ring Buffer中为每个条目调用。将新数据发布到Disruptor时,API将允许用户获取构造的对象,以便他们可以调用方法或更新该存储对象上的字段。Disruptor保证这些操作只要正确实现就是并发安全的。
可选择无锁
低延迟期望推动的另一个关键实现细节是广泛使用无锁算法来实现Disruptor。
所有内存可见性和正确性保证都是使用内存屏障(memory barriers)和CAS操作实现的。只有一个用例需要实际锁定并且在BlockingWaitStrategy中。这仅仅是为了使用条件,以便在等待新事件到达时停放消耗线程。许多低延迟系统将使用忙等待来避免使用条件可能引起的性能抖动,但是在系统忙等待操作的数量可能导致性能显着下降,尤其是在CPU资源严重受限的情况下。例如,虚拟化环境中的Web服务器。
获得Disruptor的Jar
Disruptor jar文件可从Maven,可以从那里集成到您选择的依赖管理器中。

<dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.4.2</version>
</dependency>
为了开始使用Disruptor,我们将考虑一个非常简单的例子,一个将生产者传递给消费者的Long值,消费者只需打印出该值。
首先,我们将定义携带数据的事件。
public class LongEvent
{private long value;public void set(long value){this.value = value;}
}为了让Disruptor为我们预先分配这些事件,我们需要一个将执行构造的EventFactory
import com.lmax.disruptor.EventFactory;public class LongEventFactory implements EventFactory<LongEvent>
{public LongEvent newInstance(){return new LongEvent();}
}一旦我们定义了事件,我们需要创建一个处理这些事件的消费者。在我们的例子中,我们要做的就是从控制台中打印出值。
import com.lmax.disruptor.EventHandler;public class LongEventHandler implements EventHandler<LongEvent>
{public void onEvent(LongEvent event, long sequence, boolean endOfBatch){System.out.println("Event: " + event);}
}我们需要这些事件的来源,为了举例,我将假设数据来自某种I/O设备,例如网络或ByteBuffer形式的文件。
使用翻译器发布
使用Disruptor的3.0版本,添加了更丰富的Lambda风格的API,以帮助开发人员将这种复杂性封装在Ring Buffer中,因此3.0之后发布消息的首选方法是通过API的Event Publisher / Event Translator部分。例如
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.EventTranslatorOneArg;public class LongEventProducerWithTranslator
{private final RingBuffer<LongEvent> ringBuffer;public LongEventProducerWithTranslator(RingBuffer<LongEvent> ringBuffer){this.ringBuffer = ringBuffer;}private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR =new EventTranslatorOneArg<LongEvent, ByteBuffer>(){public void translateTo(LongEvent event, long sequence, ByteBuffer bb){event.set(bb.getLong(0));}};public void onData(ByteBuffer bb){ringBuffer.publishEvent(TRANSLATOR, bb);}
}这种方法的另一个优点是翻译器代码可以被拉入一个单独的类中,并可以轻松地单独进行单元测试。
Disruptor提供了许多不同的接口(EventTranslator,EventTranslatorOneArg,EventTranslatorTwoArg等),可以实现这些接口来提供翻译。原因是允许转换器被表示为静态类或非实例捕获lambda(non-capturing lambda)(当Java 8 rolls around)作为转换方法的参数通过Ring Buffer上的调用传递给转换器。
使用旧版API发布
我们也可以使用更“原始”的方法。
import com.lmax.disruptor.RingBuffer;public class LongEventProducer
{private final RingBuffer<LongEvent> ringBuffer;public LongEventProducer(RingBuffer<LongEvent> ringBuffer){this.ringBuffer = ringBuffer;}public void onData(ByteBuffer bb){long sequence = ringBuffer.next(); // Grab the next sequencetry{LongEvent event = ringBuffer.get(sequence); // Get the entry in the Disruptor// for the sequenceevent.set(bb.getLong(0)); // Fill with data}finally{ringBuffer.publish(sequence);}}
}显而易见的是,事件发布变得比使用简单队列更复杂。这是由于对事件预分配的需求。它需要(在最低级别)消息发布的两阶段方法,即声明环形缓冲区中的插槽然后发布可用数据。还必须将发布包装在try/finally块中。如果我们在Ring Buffer中声明一个插槽(调用RingBuffer.next()),那么我们必须发布这个序列。如果不这样做可能会导致Disruptor状态的变坏。具体而言,在多生产者的情况下,这将导致消费者停滞并且在没有重启的情况下无法恢复。因此,建议使用EventTranslator API。
最后一步是将整个事物连接在一起。可以手动连接所有组件,但是它可能有点复杂,因此提供DSL以简化构造。一些更复杂的选项不能通过DSL获得,但它适用于大多数情况。
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;public class LongEventMain
{public static void main(String[] args) throws Exception{// The factory for the eventLongEventFactory factory = new LongEventFactory();// Specify the size of the ring buffer, must be power of 2.int bufferSize = 1024;// Construct the DisruptorDisruptor<LongEvent> disruptor = new Disruptor<>(factory, bufferSize, DaemonThreadFactory.INSTANCE);// Connect the handlerdisruptor.handleEventsWith(new LongEventHandler());// Start the Disruptor, starts all threads runningdisruptor.start();// Get the ring buffer from the Disruptor to be used for publishing.RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();LongEventProducer producer = new LongEventProducer(ringBuffer);ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++){bb.putLong(0, l);producer.onData(bb);Thread.sleep(1000);}}
}使用Java 8
Disruptor API的设计影响之一是Java 8将依赖功能接口的概念作为Java Lambdas的类型声明。Disruptor API中的大多数接口定义符合功能接口的要求,因此可以使用Lambda而不是自定义类,这可以减少所需的boiler place。
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;public class LongEventMain
{public static void main(String[] args) throws Exception{// Specify the size of the ring buffer, must be power of 2.int bufferSize = 1024;// Construct the DisruptorDisruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);// Connect the handlerdisruptor.handleEventsWith((event, sequence, endOfBatch) -> System.out.println("Event: " + event));// Start the Disruptor, starts all threads runningdisruptor.start();// Get the ring buffer from the Disruptor to be used for publishing.RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++){bb.putLong(0, l);ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);Thread.sleep(1000);}}
}注意不再需要许多类(例如处理程序,翻译器)。还要注意lambda如何publishEvent()仅用于引用传入的参数。
如果我们要将该代码编写为:
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{bb.putLong(0, l);ringBuffer.publishEvent((event, sequence) -> event.set(bb.getLong(0)));Thread.sleep(1000);
}这将创建一个捕获lambda,这意味着它需要实例化一个对象来保存ByteBuffer bb变量,因为它将lambda传递给publishEvent()调用。这将产生额外的(不必要的)垃圾,因此如果要求低GC压力,则应首选将参数传递给lambda的调用。
给那个方法引用可以用来代替匿名lamdbas,可以用这种方式重写这个例子。
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;public class LongEventMain
{public static void handleEvent(LongEvent event, long sequence, boolean endOfBatch){System.out.println(event);}public static void translate(LongEvent event, long sequence, ByteBuffer buffer){event.set(buffer.getLong(0));}public static void main(String[] args) throws Exception{// Specify the size of the ring buffer, must be power of 2.int bufferSize = 1024;// Construct the DisruptorDisruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);// Connect the handlerdisruptor.handleEventsWith(LongEventMain::handleEvent);// Start the Disruptor, starts all threads runningdisruptor.start();// Get the ring buffer from the Disruptor to be used for publishing.RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++){bb.putLong(0, l);ringBuffer.publishEvent(LongEventMain::translate, bb);Thread.sleep(1000);}}
}Disruptor通过精巧的无锁设计实现了在高并发情形下的高性能。
在美团内部,很多高并发场景借鉴了Disruptor的设计,减少竞争的强度。其设计思想可以扩展到分布式场景,通过无锁设计,来提升服务性能。
/*** @description disruptor代码样例。每10ms向disruptor中插入一个元素,消费者读取数据,并打印到终端*/
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;import java.util.concurrent.ThreadFactory;public class DisruptorMain
{public static void main(String[] args) throws Exception{// 队列中的元素class Element {private int value;public int get(){return value;}public void set(int value){this.value= value;}}// 生产者的线程工厂ThreadFactory threadFactory = new ThreadFactory(){@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "simpleThread");}};// RingBuffer生产工厂,初始化RingBuffer的时候使用EventFactory<Element> factory = new EventFactory<Element>() {@Overridepublic Element newInstance() {return new Element();}};// 处理Event的handlerEventHandler<Element> handler = new EventHandler<Element>(){@Overridepublic void onEvent(Element element, long sequence, boolean endOfBatch){System.out.println("Element: " + element.get());}};// 阻塞策略BlockingWaitStrategy strategy = new BlockingWaitStrategy();// 指定RingBuffer的大小int bufferSize = 16;// 创建disruptor,采用单生产者模式Disruptor<Element> disruptor = new Disruptor(factory, bufferSize, threadFactory, ProducerType.SINGLE, strategy);// 设置EventHandlerdisruptor.handleEventsWith(handler);// 启动disruptor的线程disruptor.start();RingBuffer<Element> ringBuffer = disruptor.getRingBuffer();for (int l = 0; true; l++){// 获取下一个可用位置的下标long sequence = ringBuffer.next();try{// 返回可用位置的元素Element event = ringBuffer.get(sequence);// 设置该位置元素的值event.set(l);}finally{ringBuffer.publish(sequence);}Thread.sleep(10);}}
}
输出截图:

参考:
https://martinfowler.com/articles/lmax.html
https://tech.meituan.com/2016/11/18/disruptor.html

相关文章:

c++11 多线程 1c++ concurrency in action
一、并行、多线程 1、计算机中的并行有两种方式:任务切换、利用多处理器多核。 纯粹的任务切换: 纯粹的多处理器多核: 任务切换与多处理器多核结合: 实际应用中是“任务切换与多处理器多核结合”方式,首先现在硬件偏移…

芯片刀片服务器,使用“刀片服务器”其实不难
刀片服务器已经轰轰烈烈地吵了将近两年的时间,市场上的刀片服务器产品也越来越多,所使用的芯片种类也逐渐发展为intel、amd、power等几种,支持的平台也包括了unix和ia架构。2005年底,hp还推出了基于安腾2平台的bl60p产品ÿ…

Prometheus 对比 Zabbix
公司要上监控,Prometheus 是最热门的监控解决方案,作为喜新厌旧的程序员,我当然是选择跟风了,但上级更倾向于 Zabbix,那没办法,只能好好对比一番,给出几个靠谱的理由了。 但稍稍深入一点&#x…

好理解的Java内存虚假共享(False Sharing)性能损耗以及解决方案
虚假共享(False Sharing)也有人翻译为伪共享 参考 https://en.wikipedia.org/wiki/False_sharing 在计算机科学中,虚假共享是一种性能降低的使用模式,它可能出现在具有由高速缓存机制管理的最小资源块大小的分布式一致高速缓存的系统中。当系统参与者将…
delphi xe 文件服务器,DelphiXE7中创建WebService(服务端+客户端)
相关资料:http://www.2ccc.com/news/Html/?1507.htmlhttp://www.dfwlt.com/forum.php?modviewthread&tid922DelphiXE7新建WebService具体操作:1.打开“DelphiXE7”->“File”->“New”->“Other”2.“New Items”->“Delph…
Android app 别用中文名
/************************************************************************** Android app 别用中文名* 说明:* 本来想分析一下这份源代码,结果发现因为项目名中有中文不能自动生成R* 文件,于是不想分析了。** …
一线互联网常见的14个Java面试题,你颤抖了吗程序员
跳槽不算频繁,但参加过不少面试(电话面试、face to face面试),面过大/小公司、互联网/传统软件公司,面糊过(眼高手低,缺乏实战经验,挂掉),也面过人࿰…
复化梯形公式,Newton-Cotes公式,变量代换后的复化梯形公式,Gauss-Legendre公式,Gauss-Jacobi公式插值积分的精确度比较
1.问题 分别计算积分 Ic∫01cosxxdx1.809048475800...I_c\int_0^1\frac{\cos{x}}{\sqrt{x}}dx1.809048475800... Ic∫01xcosxdx1.809048475800... Is∫01sinxxdx0.620536603446I_s\int_0^1\frac{\sin{x}}{\sqrt{x}}dx0.620536603446 Is∫01xsinxdx0.62053…

Elasticsearch 知识点目录
2019独角兽企业重金招聘Python工程师标准>>> 经过一段时间的编写,完成了第一个版本的Elasticsearch书籍的编写,目录结构如下: 1 Elasticsearch入门 7 1.1 Elasticsearch是什么 7 1.1.1 Elasticsearch是什么 7 1.1.2 Elasticsearch…

不要千言万语,一组漫画让你秒懂最终一致性
直接上图 如果你以前看过最终一致性的定义那么你一定会为这幅精彩漫画拍手叫好。 你要是不知道什么是最终一致性你可以看看下面的权威定义,当然了网上关于什么是最终一致性的帖子铺天盖地,也许你已经很明白了,即使这样你是不是依然为此图欢呼…
Feign实现服务调用
上一篇博客我们使用ribbonrestTemplate实现负载均衡调用服务,接下来我们使用feign实现服务的调用,首先feign和ribbon的区别是什么呢? ribbon根据特定算法,从服务列表中选取一个要访问的服务; RoundRobinRule:轮询RandomRule:随机Availability…

度量,跟踪和日志记录
今天,我有幸参加了2017年的分布式追踪峰会,其中有很多来自AWS / X-Ray,OpenZipkin,OpenTracing,Instana,Datadog,Librato等公司的人员,我很遗憾我忘记了这一点。有一次讨论转向了项目…
python 第六章 函数 pta(1)
1.Multiple-Choice 1.print(type(lambda:3))的输出结果是____。 A.<class ‘function’> B.<class ‘int’> C.<class ‘NoneType’> D.<class ‘float’> 答案:A 2.在Python中,对于函数定义代码的理解,正确的理解…
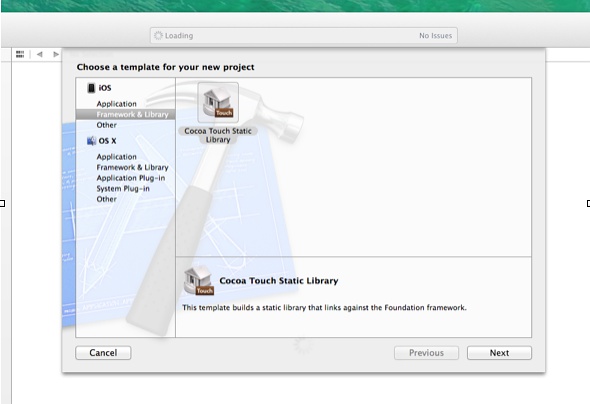
生成.a文件步骤
1.新建一个Project 选择 iOS->Framework & Library ->Cocoa Touch Static Library点击Next-> 输入Product Name 2.删除自动生成的文件 替换成我们需要的文件 如:原本自定生成的文件为继承自NSObject的,而你需要的为继承自UIView的ÿ…
机器学习之优雅落地线性回归法
在统计学中,线性回归(Linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析维基百科。简单线性回归当只有一个自变量的时候,成为简单线性回归。简单线性回归模型的思…
SpringBoot整合Grpc实现跨语言RPC通讯
什么是gRPC gRPC是谷歌开源的基于go语言的一个现代的开源高性能RPC框架,可以在任何环境中运行。它可以有效地连接数据中心内和跨数据中心的服务,并提供可插拔的支持,以实现负载平衡,跟踪,健康检查和身份验证。它还适用…
python 第六章 函数
1.函数的定义 def 名称(形参): 函数体 2.函数的调用 名称(实参) 单独文件:模块 调用方式——模块.名称 3.函数的参数类型 1.位置参数: def add(a,b):add(2,3) #顺序,个数,数据类型都要相同!!…
C++简单使用Jsoncpp来读取写入json文件
一、源码编译 C操作json字符串最好的库应该就是jsoncpp了,开源并且跨平台。它可以从这里下载。 下载后将其解压到任意目录,它默认提供VS2003和VS2010的工程文件,使用VS2010可以直接打开makefiles\msvc2010目录下的sln文件。 工程文件提供Json…
BZOJ 3420: Poi2013 Triumphal arch
二分答案 第二个人不会走回头路 那么F[i]表示在i的子树内(不包括i)所需要的额外步数 F[1]0表示mid可行 k可能为0 #include<cstdio> #include<algorithm> using namespace std; int cnt,n,mid,F[300005],last[300005]; struct node{int to,next; }e[600005]; void a…
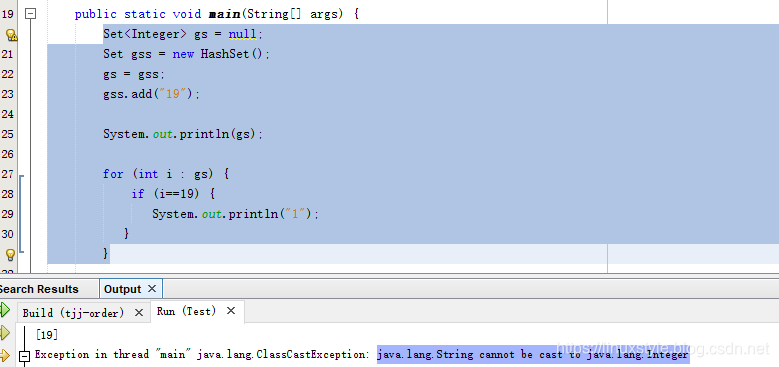
Java泛型使用需要小心
这是源自实际开发的一个坑,只是被我简化了。 Set<Integer> gs null;Set gss new HashSet();gs gss;gss.add("19");System.out.println(gs);for (int i : gs) {if (i19) {System.out.println("1");}} 代码经过一些转换你如果不注意以…
证明实对称正定矩阵A的Gauss-Seidel法必定收敛(完整过程)
Solution: \quad将nnn阶实对称矩阵AAA设为D−L−LTD-L-L^TD−L−LT,其中DDD是AAA的所有主对角元素构成对角矩阵,−L-L−L是AAA的所有主对角线以下的元素构成的严格下三角矩阵。 \quad此时Gauss−SeidelGauss-SeidelGauss−Seidel法的迭代矩阵为(D−L)−1LT(…
5月中旬的一些总结
考完英语口语了,最大的帮助就是找到了练习的方法和思路。 周三晚上有谷歌的全球IO大会。 ******** 写吴斌老师的课程作业,这才发现winedt过期了。用了rept之后本来是解决问题了,可是一联网就又不行了。总要关上再打开。用防火墙阻断却找不到选…
项目总结10:通过反射解决springboot环境下从redis取缓存进行转换时出现ClassCastException异常问题...
通过反射解决springboot环境下从redis取缓存进行转换时出现ClassCastException异常问题 关键字 springboot热部署 ClassCastException异常 反射 redis 前言 最近项目出现一个很有意思的问题,用户信息(token)储存在redis中;在获取token,反序列…
Rouche Theorem(Stein复分析)
Rouche Theorem: \quadIffandgareholomorphicfunctionsinaregionΩcontainingacircleCanditsinterior,and∣f(z)∣≥∣g(z)∣forz∈C,fandfghavethesamenumbersofzerosinsidethecircleC.If\quad f\quad and\quad g\quad are\quad holomorphic\quad functions\quad i…

Java线上程序频繁JVM FGC问题排障与启示
线上Java程序的JVM频繁FGC,现象如图所示: 一直持续FGC 5次左右,每次耗时1秒多不等。 FGC的原因实际上是内存不够用,但是运维反映堆内存是2G,从运维提供的参数看也是。 内存实际上一直只用到1G以内。 这时候可以自己写…

python常用数据结构的常用操作
作为基础练习吧。列表LIST,元组TUPLE,集合SET,字符串STRING等等,显示,增删,合并。。。 #List shoplist [apple,mango,carrot,banana] print I have ,len(shoplist), items to purchase. print These items are: for …
h5 和native 交互那些事儿
前端菜菜一枚,写下关于h5 和native 交互那些事情。偏前端,各种理论知识,不在赘述。之前有各位大牛已经写过。我只写代码,有问题,下面留言/* 关于h5 和native 之间的交互 JSBridge 解决问题,偏向前端* 使用U…

手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫
系列教程 手把手教你写电商爬虫-第一课 找个软柿子捏捏 如果没有看过第一课的朋友,请先移步第一课,第一课讲了一些基础性的东西,通过软柿子"切糕王子"这个电商网站好好的练了一次手,相信大家都应该对写爬虫的流程有了一…
Python程序设计 第六章 函数(续
复习 1. 10进制 ⇒\Rightarrow⇒ 2进制 除2取余,从低位到高位存储到字符串中,从高位到低位def d2b(n):if n>1:d2b(n//2)print(n%2,end)d2b(4)出口: 条件,值确定 (一)return (二)函数体执行结…
K8S的横向自动扩容的功能Horizontal Pod Autoscaling
K8S 作为一个集群式的管理软件,自动化、智能化是免不了的功能。Google 在 K8S v1.1 版本中就加入了这个 Pod 横向自动扩容的功能(Horizontal Pod Autoscaling,简称 HPA)。 HPA 与之前的 Deployment、Service 一样,也属…