Rocksdb 的优秀代码(二)-- 工业级 打点系统 实现分享
文章目录
- 前言
- 数据结构选型
- 打点代码设计
- 耗时打点
- 请求计数打点
- 打点总结
前言
一个完善的分布式系统一定是需要完善的打点统计,不论是对系统内核 还是 对系统使用者都是十分必要的。系统的客户需要直观得看到这个系统的性能相关的指标来决定是否使用以及如何最大化使用系统,同样 系统的开发者也需要直观的看到系统各个组件的各项指标,来进行性能调优 以及 稳定性保障(运维监控,failover)。
而打点 主要 是耗时相关 以及 请求数相关的统计,这一些统计需要对系统代码侵入即需要消耗系统的执行时间。而 分布式系统对性能的极致需求肯定是不允许额外增加核心代码之外的执行耗时的(计算平均值,最大值,不同的分位数),所以打点代码需要尽可能降低对系统本身性能的影响,这里面就需要有足够精巧的代码设计。
回到今天分享的Rocksdb 的打点设计,Rocksdb作为单机引擎,被广泛应用在了各个分布式系统之中,而引擎的性能是上层分布系统性能的基础。本身外部系统对引擎性能有极致需求 且 Rocksdb本身也在不断追求卓越的性能,这个时候rocksdb自己的打点系统就非常有借鉴意义,其已经经过无数系统 和 卓越的开发者们反复验证,是一个非常有参考价值的打点代码设计。
本次分享会从两方面开看Rocksdb 的打点设计,也是最传统的打点类型:
- 耗时统计(各个维度的耗时信息)
- 请求统计(各个维度的请求个数相关的信息)
以下描述的打点主要是全局统计的,就是通过打开options.statistics 参数获取的;对于perf_context和iostats_contxt这一些thread local指标并不提及;
数据结构选型
打点的目的希望对内(研发者)以及对外(用户)提供系统性能的参考 以及 系统问题的报警,这一些信息会涉及到计算。举一个例子,比如分位数,像p50,p99,p999 这样的指标是监控系统必不可少的,用来展示系统的延时/长尾延时情况,这一些指标的计算是需要对抓取的请求保存并排序才能取到的。对于一个集群百万/千万级每秒的请求,每次取分位数,都需要对百万级数据进行排序?显然不可能。
所以这里 对打点数据的保存需要有合理的数据结构才行,rocksdb 提供了如下细节:
保存各个指标都需要的数据结构
struct HistogramData {// 从media -- perceile99的 都是分位数double median; // P50double percentile95; // P95double percentile99; // P99double average; // 平均值double standard_deviation; // 方差// zero-initialize new members since old Statistics::histogramData()// implementations won't write them.double max = 0.0;uint64_t count = 0;uint64_t sum = 0;double min = 0.0; }计算分位数的核心数据结构,比如P999 表示到目前为止所有请求中从小到大 第0.1% 个请求的耗时指标。
而这个从小到大 不一定需要真正通过排序算法排序,第0.1% 也不一定精确的第0.1%个,可以在其上下10个请求内浮动。
所以这里针对分位数 的计算是维护了一个有序hash表,将统计的请求添加到对应所处范围的hash桶内,后续取P999这样的指标时排序只需统计从小桶的请求数到满足0.1%时请求数目 的桶 ,再进行更细粒度的取值。分位数算法细节比较多,有兴趣的可以看Rocksdb 的优秀代码(一) – 工业级分桶算法实现分位数p50,p99,p9999
总之,不需要排序,只需要添加到一个map里自动排序,维护每个map 元素bucket的请求数即可。
class HistogramBucketMapper {public:HistogramBucketMapper(); // 初始化耗时值和整个耗时区间// converts a value to the bucket index.size_t IndexForValue(uint64_t value) const;// number of buckets required.size_t BucketCount() const {return bucketValues_.size();}uint64_t LastValue() const {return maxBucketValue_;}uint64_t FirstValue() const {return minBucketValue_;}uint64_t BucketLimit(const size_t bucketNumber) const {assert(bucketNumber < BucketCount());return bucketValues_[bucketNumber];}private:std::vector<uint64_t> bucketValues_; // 初始化耗时值uint64_t maxBucketValue_; // 耗时最大uint64_t minBucketValue_; // 耗时最小// 初始化耗时区间,以[bucketValues_[i-1],bucketValues_[i]]std::map<uint64_t, uint64_t> valueIndexMap_; };保存每个指标的各个维度的data数据,比如请求总数,最大,最小,上面数据结构中 valueIndexMap_各个区间的请求数(方便计算分位数)等
struct HistogramStat {......// 计算统计信息的代码,最大,最小等void Clear();bool Empty() const;void Add(uint64_t value);void Merge(const HistogramStat& other);inline uint64_t min() const { return min_.load(std::memory_order_relaxed); }inline uint64_t max() const { return max_.load(std::memory_order_relaxed); }inline uint64_t num() const { return num_.load(std::memory_order_relaxed); }inline uint64_t sum() const { return sum_.load(std::memory_order_relaxed); }inline uint64_t sum_squares() const {return sum_squares_.load(std::memory_order_relaxed);}inline uint64_t bucket_at(size_t b) const {return buckets_[b].load(std::memory_order_relaxed);}// 计算分位数相关的代码,p50,平均值,标准差double Median() const;double Percentile(double p) const;double Average() const;double StandardDeviation() const;// 通过这个函数,将获取到的各个数据给到上文最开始的数据结构HistogramData// 暴露给用户。void Data(HistogramData* const data) const;std::string ToString() const;// To be able to use HistogramStat as thread local variable, it// cannot have dynamic allocated member. That's why we're// using manually values from BucketMapperstd::atomic_uint_fast64_t min_;std::atomic_uint_fast64_t max_;std::atomic_uint_fast64_t num_;std::atomic_uint_fast64_t sum_;std::atomic_uint_fast64_t sum_squares_;std::atomic_uint_fast64_t buckets_[109]; // 109==BucketMapper::BucketCount()const uint64_t num_buckets_; };
到现在,基础的数据结构就这么多,接下来通过两种维度的数据来看一下rocksdb 如何利用以上数据结构,完成自己的打点代码设计的。
打点代码设计
以如下两个指标为例:
读请求耗时统计:rocksdb.db.get.micros
rocksdb.db.get.micros P50 : 0.000000 P95 : 0.000000 P99 : 0.000000 P99.9 : 0.000000 P99.99 : 0.000000 P100 : 0.000000 COUNT : 0 SUM : 0这是读指标数据,其中p99.9 和 p99.99是自己加的,原来并没有,可以看到总体的指标数据就是我们上文中数据结构中的指标。
Block_cache命中数统计:rocksdb.block.cache.hit
rocksdb.block.cache.hit COUNT : 0请求数相关的指标就是单纯的个数统计,不会有分位数的统计,毕竟分位数只在有延时需求的场景才会有用。
耗时打点
针对rocksdb.db.get.micros 指标,维护了一个直方图变量
enum Histograms : uint32_t {DB_GET = 0, // 读耗时DB_WRITE, // 写耗时COMPACTION_TIME, // compaction 耗时COMPACTION_CPU_TIME,SUBCOMPACTION_SETUP_TIME,...
}
按照我们的理解,一个函数的执行耗时 是 在函数开始时获取一个时间,函数运行结束后再获取一个时间,两个时间的差值就是这个函数的执行耗时,很简答。
而rocksdb 获取读耗时指标的代码如下:
Status DBImpl::GetImpl(const ReadOptions& read_options,ColumnFamilyHandle* column_family, const Slice& key,PinnableSlice* pinnable_val, bool* value_found,ReadCallback* callback, bool* is_blob_index) {assert(pinnable_val != nullptr);PERF_CPU_TIMER_GUARD(get_cpu_nanos, env_); // perf context的统计StopWatch sw(env_, stats_, DB_GET); // 统计读耗时......
}
后面再没有其他的耗时计算了。是不是有点诧异,也就是rocksdb 通过读请求函数开始StopWatch对象的初始化,完成了整个读函数的耗时统计。
StopWatch的代码如下,大家就能够看到Rocksdb 代码的设计精妙了。
构造StopWatch对象需要传入 基本的三个参数:
- env_ , rocksdb维护的全局共享的环境变量
- Stats_ ,statistics ,将获取到的时间添加到上文的三种数据结构中,参与运算
- DB_GET, 直方图变量,表示读请求的指标;类似的还有DB_WRITE等
// 初始化代码如下
StopWatch(Env* const env, Statistics* statistics, const uint32_t hist_type,uint64_t* elapsed = nullptr, bool overwrite = true,bool delay_enabled = false): env_(env), // 全局环境变量,用来提供一个便捷的函数,后续主要用来调用时间函数 NowMicros() statistics_(statistics), // 需要通过options.statistics初始化,否则默认为空,就不打开rocksdb的打点系统了hist_type_(hist_type), // 直方图变量,DB_GET, DB_WRITE...elapsed_(elapsed),overwrite_(overwrite),stats_enabled_(statistics &&statistics->get_stats_level() >=StatsLevel::kExceptTimers &&statistics->HistEnabledForType(hist_type)),delay_enabled_(delay_enabled),total_delay_(0),delay_start_time_(0),start_time_((stats_enabled_ || elapsed != nullptr) ? env->NowMicros()// 起始时间: 0) {}
也就是在StopWatch对象初始化完成时记录下了起始时间:
start_time_((stats_enabled_ || elapsed != nullptr) ? env->NowMicros()// 起始时间
因为StopWatch 是在GetImpl函数中创建的,属于函数局部变量,那想要获取到结束时间,只要这个函数退出,StopWatch的析构函数会被自动调用,也就是只需要在析构函数中调用获取结束时间即可。
~StopWatch() {......if (stats_enabled_) {//计算结束时间,并将DB_GET和结束时间添加到直方图中statistics_->reportTimeToHistogram(hist_type_, (elapsed_ != nullptr)? *elapsed_: (env_->NowMicros() - start_time_));}}
到此已经拿到了Get请求的准确耗时了,简洁且优雅!!!
接下来就是拿着耗时,和请求类型添加到直方图中即可。
先看一下直方图中的原始数据形态:
** Level 0 read latency histogram (micros):
Count: 1805800 Average: 1.4780 StdDev: 8.70
Min: 0 Median: 0.8399 Max: 4026
Percentiles: P50: 0.84 P75: 1.40 P99: 2.32 P99.9: 5.10 P99.99: 9.75
------------------------------------------------------
[ 0, 1 ] 1075022 59.532% 59.532% ############
( 1, 2 ] 706790 39.140% 98.672% ########
( 2, 3 ] 18280 1.012% 99.684%
( 3, 4 ] 2601 0.144% 99.828%
( 4, 6 ] 2357 0.131% 99.958%
......
横线之上的指标很明显,之下的指标简单说一下,它就是我们数据结构选型中的HistogramBucketMapper数据结构。
在Percentiles之下 总共有四列(这里将做括号和右方括号算作一列,是一个hash桶)
- 第一列 : 看作一个hash桶,这个hash桶表示一个耗时区间,单位是us
- 第二列:一秒内产生的请求耗时命中当前耗时区间的有多少个
- 第三列:一秒内产生的请求耗时命中当前耗时区间的个数占总请求个数的百分比
- 第四列:累加之前所有请求的百分比
耗时打点会简化输出如下:

回到我们拿着DB_GET和time 汇报到直方图中,通过如下函数
virtual void reportTimeToHistogram(uint32_t histogramType, uint64_t time) {//表示禁止打开直方图,也就是上文中说的options.statistics参数未初始化,使用默认的。if (get_stats_level() <= StatsLevel::kExceptTimers) { return;}// 添加直方图recordInHistogram(histogramType, time);
}
最终调用到StatisticsImpl::recordInHistogram函数, 更新直方图中HistogramStat数据结构中的各个指标。
void StatisticsImpl::recordInHistogram(uint32_t histogramType, uint64_t value) {assert(histogramType < HISTOGRAM_ENUM_MAX);if (get_stats_level() <= StatsLevel::kExceptHistogramOrTimers) {return;}// 将指标添加到histogram_中,并计算该时间在直方图所属bucket,将bucket计数自增。// 除了添加到直方图bucket,还会更新总时间,总请求数等指标。per_core_stats_.Access()->histograms_[histogramType].Add(value); if (stats_ && histogramType < HISTOGRAM_ENUM_MAX) {// 留给用户态的接口,如果用户不继承实现针对该指标的处理,则不会做任何事情。stats_->recordInHistogram(histogramType, value);}
}
如果用户想要自己做一些请求统计,比如统计总共的打点次数。可以通过如下方式,用户态继承statistics类即可:
class DummyOldStats : public Statistics {public:......void measureTime(uint32_t /*histogram_type*/, uint64_t /*count*/) override {num_mt++;}... }
再看一下per_core_stats_.Access()->histograms_[histogramType].Add(value); 中的Add函数,很简单的指标更新。
这个函数处于所有指标调用的必经路径,可以看到这里设计的时无锁方式执行逻辑。也就是认为 并发Get场景下的直方图更新,其实顺序性并没有那么重要,因为耗时会置放到它所属的时间bucket中,请求数自增,并不是严格排序方式获取分位数指标的。
void HistogramStat::Add(uint64_t value) {// 获取value-time 以及 耗时时间所处的直方图索引// 拿着index,更新对应的buckets的个数const size_t index = bucketMapper.IndexForValue(value);assert(index < num_buckets_);buckets_[index].store(buckets_[index].load(std::memory_order_relaxed) + 1,std::memory_order_relaxed);// 更新最小值uint64_t old_min = min();if (value < old_min) {min_.store(value, std::memory_order_relaxed);}// 更新最大值uint64_t old_max = max();if (value > old_max) {max_.store(value, std::memory_order_relaxed);}// 更新总的请求个数num_.store(num_.load(std::memory_order_relaxed) + 1,std::memory_order_relaxed);// 更新总耗时sum_.store(sum_.load(std::memory_order_relaxed) + value,std::memory_order_relaxed);sum_squares_.store(sum_squares_.load(std::memory_order_relaxed) + value * value,std::memory_order_relaxed);
}
到此,一次Get请求的耗时信息已经添加到了直方图中。需要注意的是,此时并没有计算对应的分位数指标,仅仅更新了buckets_。
当调用 输出直方图的函数时,会进行分位数的计算,DBImpl::PrintStaistics()函数中
void DBImpl::PrintStatistics() {auto dbstats = immutable_db_options_.statistics.get();if (dbstats) {// 打印直方图ROCKS_LOG_INFO(immutable_db_options_.info_log, "STATISTICS:\n %s",dbstats->ToString().c_str());}
}
主要是就是直方图的ToString函数中,计算分位数,并将计算的结果填充到HistogramData数据结构中,后续直接打印。
std::string StatisticsImpl::ToString() const {MutexLock lock(&aggregate_lock_);......// 打印所有指标的耗时数据for (const auto& h : HistogramsNameMap) {assert(h.first < HISTOGRAM_ENUM_MAX);char buffer[kTmpStrBufferSize];HistogramData hData;// 计算分位数getHistogramImplLocked(h.first)->Data(&hData);// don't handle failures - buffer should always be big enough and arguments// should be provided correctlyint ret =snprintf(buffer, kTmpStrBufferSize,"%s P50 : %f P95 : %f P99 : %f P100 : %f COUNT : %" PRIu64" SUM : %" PRIu64 "\n",h.second.c_str(), hData.median, hData.percentile95,hData.percentile99, hData.max, hData.count, hData.sum);if (ret < 0 || ret >= kTmpStrBufferSize) {assert(false);continue;}res.append(buffer);}if (event_tracer_) res.append(event_tracer_->ToString());res.shrink_to_fit();return res;
}
其中getHistogramImplLocked(h.first)->Data(&hData);计算分位数,并将结果添加到HistogramData数据结构。
void HistogramStat::Data(HistogramData * const data) const {assert(data);data->median = Median();data->percentile95 = Percentile(95);data->percentile99 = Percentile(99);data->max = static_cast<double>(max());data->average = Average();data->standard_deviation = StandardDeviation();data->count = num();data->sum = sum();data->min = static_cast<double>(min());
}
关于分位数计算 细节可以看 上文中提到的Rocksdb分位数实现链接 。Rocksdb 的优秀代码(一) – 工业级分桶算法实现分位数p50,p99,p9999
请求计数打点
这里就比较简单了,针对计数打点,同样维护了一个直方图枚举类型:
enum Tickers : uint32_t {// total block cache misses// REQUIRES: BLOCK_CACHE_MISS == BLOCK_CACHE_INDEX_MISS +// BLOCK_CACHE_FILTER_MISS +// BLOCK_CACHE_DATA_MISS;BLOCK_CACHE_MISS = 0,// total block cache hit// REQUIRES: BLOCK_CACHE_HIT == BLOCK_CACHE_INDEX_HIT +// BLOCK_CACHE_FILTER_HIT +// BLOCK_CACHE_DATA_HIT;BLOCK_CACHE_HIT,// # of blocks added to block cache.BLOCK_CACHE_ADD,......
}
其中BLOCK_CACHE_HIT属于其中计数类型的一种,主要是在更新Cache的代码中使用RecordTick函数来更新请求计数。
void BlockBasedTable::UpdateCacheHitMetrics(BlockType block_type,GetContext* get_context,size_t usage) const {......// 命中BlockCache,这里进行BLOCK_CACHE_HIT 更新指标// 默认使用RecordTick,即使用户配置了get_context,也会用RecordTick来更新指标if (get_context) {++get_context->get_context_stats_.num_cache_hit;get_context->get_context_stats_.num_cache_bytes_read += usage;} else {RecordTick(statistics, BLOCK_CACHE_HIT);RecordTick(statistics, BLOCK_CACHE_BYTES_READ, usage);}
void StatisticsImpl::recordTick(uint32_t tickerType, uint64_t count) {assert(tickerType < TICKER_ENUM_MAX);// 对直方图变量中的类型使用 松散内存序 进行自增per_core_stats_.Access()->tickers_[tickerType].fetch_add(count, std::memory_order_relaxed);if (stats_ && tickerType < TICKER_ENUM_MAX) {stats_->recordTick(tickerType, count);}
}
后续打印的话也是使用类似耗时打印的StatisticsImpl::ToString()函数进行打印。
以上除了关键路径的耗时以及请求统计,后续的直方图相关的指标的计算都是通过后台thread_dump_stats_ 进行异步更新。
打点总结
Rocksdb 的打点系统 中核心是耗时打点,使用了巧妙的类的构造和析构 完成轻量耗时统计,并通过异步线程完成直方图的计算和更新。
尤其是分位数的计算,使用hash桶方式仅仅统计 耗时时间段的请求计数 来完成分位数的预估。整个打点系统经历过大量工业级应用的锤炼,可以说是非常优雅的系统代码设计,值得学习借鉴。
相关文章:

JVM中可生成的最大Thread数量
最近想测试下Openfire下的最大并发数,需要开大量线程来模拟客户端。对于一个JVM实例到底能开多少个线程一直心存疑惑,所以打算实际测试下,简单google了把,找到影响线程数量的因素有下面几个: -Xms intial java heap s…

Java项目:在线电影售票系统设计和实现(java+Springboot+ssm+mysql+jsp+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 前台: 1、正在上映的电影浏览查看。 2、影院信息浏览查看。 3、新闻咨询信息浏览查看。 4、地域信息查看切换。 5、用户注册登录。 6、电影排期查看。 7、在线选座生成…
matlab正态分布
normrnd(mu, sigma, m,n) 返回m x n的随机数,正态分布均值mu,标准差sigma。 mvnrnd(mu, sigma, m) 返回m个随机数(点),是多元正太分布,mu是均值向量,sigma是协方差。 x normrnd(0,4,1,100000);…
MYSQL语句
-- 一、管理数据库-- 1.1 创建数据库CREATE DATABASE day15; SHOW DATABASES; CREATE TABLE student( id INT, NAME VARCHAR(20), age INT); -- 查看表SHOW TABLES; -- 二、管理数据-- 1.1插入数据(insert into)-- 需求: 往学生表插入数据INS…
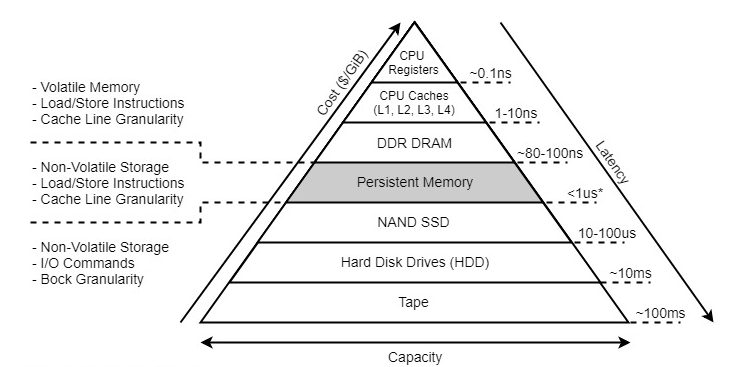
Intel Optane PMEM 概览
文章目录前言基本架构编程模型PMDK接口架构接口概览pmdk 安装开发文档汇总PMEM性能官方性能实测性能前言 随着以PCM 为存储单元的3D XPoint 非易失存储介质 不断精进的工艺,以及 上层硬件协议栈的飞速发展,为非易失内存这样硬件的出现提供了技术工艺基础…

Java项目:新闻发布系统(java+Springboot+ssm+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 区分为管理员用户和普通用户,管理员用户能删除评论, 调整新闻显示/隐藏,修改新闻,删除普通用户,普通用户能 登陆浏…

Linux下搭建Lotus Domino集群
Linux下搭建Lotus Domino 集群本文内容是Linux平台下Lotus Domino服务器部署案例(http://chenguang.blog.51cto.com/350944/1334595)的另一个模块,所以大家首先要有以上基础之后然后继续实验。集群是 Lotus Domino Server 提供的最重要特性之…

Centos下卸载openjdk并安装自定义jdk
1、查看是否安装了openjdk java -version 2、查看需要卸载的openjdk信息,其中只需要删除红色框标记的地方 rpm -qa | grep java 3、删除openjdk rpm -e --nodeps 需要删除的java组件 4、创建文件夹java mkdir java 5、到官网下载linux版本的jdk(如果不能…
pmdk -- libpmemlog 介绍
文章目录1. libpmemlog 应用背景2. libpmemlog 使用方式2.1 基本接口2.2 接口使用3. Libpmemlog 性能3.1 write sys call 性能3.2 libpmemlog 性能1. libpmemlog 应用背景 本文介绍的是英特尔 傲腾持久化内存 pmdk中 的一个持久化日志的库。 我们正常系统中会将日志 形成一个…
Java项目:家庭财务管理系统(java+Springboot+ssm+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 家庭财务管理系统,具有收入统计,支出统计,汇总报 表,工资录入,其他收入等录入开支信息,echart图标插 …
(原创)c++primer(第五版)--1.3 注释简介
注释可以帮助人类读者理解程序。注释通常用于概述算法,确定变量的用途,或者结束晦涩难懂的代码段。编译器会忽略注释,因此注释对程序的行为或者性能不会有任何影响。 虽然编辑器会忽略注释,但读者并不会。即使系统文档的其他部分已…
BZOJ 1503 郁闷的出纳员(splay)
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id1503 题意:给出一个数列(初始为空),给出一个最小值Min,当数列中的数字小于Min时自动删除。四种操作:(1)数列…
javascript ES6 新特性之 扩展运算符 三个点 ...
对于 ES6 新特性中的 ... 可以简单的理解为下面一句话就可以了: 对象中的扩展运算符(...)用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中。 作用类似于 Object.assign() 方法,我们先来看一下 Object.assign() 方法: Obje…
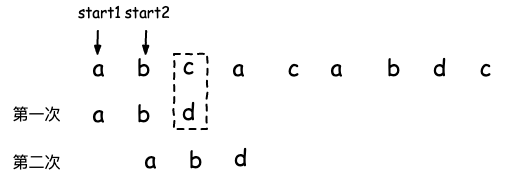
字符串匹配算法 -- BM(Boyer-Moore) 和 KMP(Knuth-Morris-Pratt)详细设计及实现
文章目录1. 算法背景2. BM(Boyer-Moore)算法2.1 坏字符规则(bad character rule)2.2 好后缀规则(good suffix shift)2.3 复杂度及完整代码3. KMP(Knuth Morris Pratt)算法3.1 好前缀 和 坏字符规则3.2 高效构建 失效函数3.3 复杂度…

Java项目:中小医院信息管理系统(java+Springboot+ssm+mysql+maven+jsp)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:实现了挂号收费,门诊管理,划价收 费,药房取药,体检管理,药房管理,系统维护等各个模块功能&a…
DB2load遇到SQL3508N错误
SQL3508N装入或装入查询期间,当存取类型为 "<文件类型>" 的文件或路径时出错。原因码:"<原因码>"。路径:"<路径/ 文件>"。 [more]解释: 装入或装入查询处理期间,在尝…
【cocos2d-x 手游研发小技巧(3)Android界面分辨率适配方案】
先感叹一下吧~~android的各种分辨率各种适配虐我千百遍,每次新项目我依旧待它如初恋 每家公司都有自己项目工程适配的方案,这种东西就是没有最好,只有最适合!!! 这次新项目专项针对android,目的…
git submodule 使用场景汇总
文章目录1. 前言2. 基础命令介绍2.1 场景一:已有仓库,添加一个子模块2.2 场景二:已有仓库,添加一个子模块的特定分支2.3 场景三:已有仓库,更新子模块内容2.4 场景四:已有仓库,变更子…
Java项目:在线商城系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 前台展示后台管理,包括最基本的用户登录注册,下单, 购物车,购买,结算,订单查询,…

自定义参数解析器,减少10%的代码
*** 赋值调用方法* 如果为空,默认调用name()方法* 该方法必须是一个不含参数的方法,否则将会调用失败* @return*/value() : value用于绑定请求参数和方法参数名一致时的对应关系。比如user?statusNo=1。方法的参数写法如下:getUser(@EnumParam(value=“statusNo”) int status) 或者 getUser(@EnumParam() int statusNo)valueMethod() : 赋值时调用枚举中的方法。

微服务全做错了!谷歌提出新方法,成本直接降9倍!
一位DataDog的客户收到6500万美元的云监控账单的消息,也再次让业界无数人惊到了。事实上有些团队在将集中式单体应用拆分为微服务时,首先进行的往往不是建立领域模型,而只是按照业务功能将原来单体应用的一个软件包拆分成多个所谓的“微服务”软件包,而这些“微服务”内的代码高度耦合,逻辑边界不清晰,长期以来,不管大厂还是小厂,微服务都被认为是云原生服务应用程序架构的事实标准,然而2023,不止那位37signals的DHH决心下云,放弃微服务,就连亚马逊和谷歌等这些云巨头,正在带头开始革了微服务的命。
简述nodejs、npm及其模块在windows下的安装与配置
nodejs的安装 登陆官网http://nodejs.org/,自行安装,不需配置环境变量,安装中自动配置了。 检测是否安装成功,使用cmd输入 node -v 即可查看。 npm的安装 如果是最新版nodejs其实不用装npm,它集成了npm,验证…
discuz,ecshop的伪静态规则(apache+nginx)
discuz(nginx): (备注:该规则也适用于二级目录) rewrite ^([^\.]*)/topic-(.)\.html$ $1/portal.php?modtopic&topic$2 last; rewrite ^([^\.]*)/article-([0-9])-([0-9])\.html$ $1/portal.php?modview&aid$2&page$3 last; rewrite ^([^\.]*)/forum-…
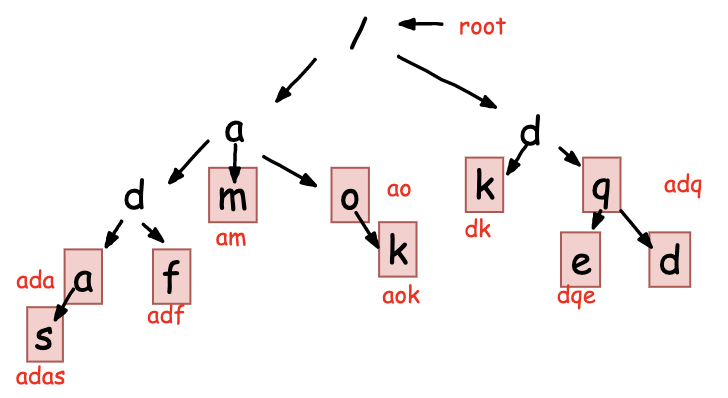
字符串匹配数据结构 --Trie树 高效实现搜索词提示 / IDE自动补全
文章目录1. 算法背景2. Trie 树实现原理2.1 Trie 树的构建2.2 Trie树的查找2.3 Trie树的遍历2.4 Trie树的时间/空间复杂度2.5 Trie 树 Vs 散列表/红黑树3. Trie树的应用 -- 搜索词提示功能1. 算法背景 之前我们了解过单模式串匹配的相关高效算法 – BM/KMP,虽难以理…
Java项目:成绩管理系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 超豪华成绩管理系统,学生,教师,管理员三类用户集 成,课程表管理,成绩查询,成绩详情数据统计…
NSThread 多线程相关
1.下面的代码,有2点需要注意,1>就是 就是thread:所传得参数,这里传得的是nsarray 当然也可以传其他的类型。2> [self performSelectorOnMainThread:selector(update) withObject:nil waitUntilDone:YES]; 这个函数的作用是通知主线程进…

Windows Phone 8初学者开发—第19部分:设置RecordAudio.xaml页面
原文地址: http://channel9.msdn.com/Series/Windows-Phone-8-Development-for-Absolute-Beginners/Part-19-Setting-up-the-RecordAudioxaml-Page 系列地址: http://channel9.msdn.com/Series/Windows-Phone-8-Development-for-Absolute-Beginners 源代码: http://aka.ms/abs…
9.path Sum III(路径和 III)
Level: Easy 题目描述: You are given a binary tree in which each node contains an integer value. Find the number of paths that sum to a given value. The path does not need to start or end at the root or a leaf, but it must go downwards…
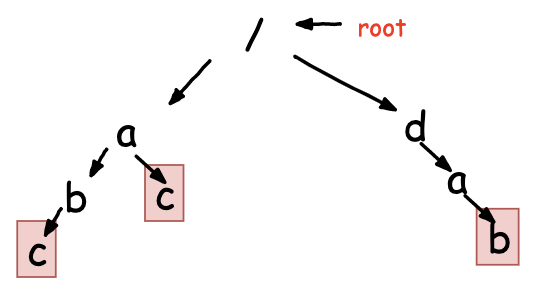
字符串匹配算法 -- AC自动机 基于Trie树的高效的敏感词过滤算法
文章目录1. 算法背景2. AC自动机实现原理2.1 构建失败指针2.2 依赖失败指针过滤敏感词3. 复杂度及完整代码1. 算法背景 之前介绍过单模式串匹配的高效算法:BM和KMP 以及 基于多模式串的匹配数据结构Trie树。 1. BM和KMP 单模式串匹配算法细节 2. Trie树 多模式串的高效匹配数…
Java项目:仿小米商城系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 基于vue Springboot前后端分离项目精简版仿小米商城 系统,注册登录,首页展示,商品展示,商品购买,下单…