字符串匹配数据结构 --Trie树 高效实现搜索词提示 / IDE自动补全
文章目录
- 1. 算法背景
- 2. Trie 树实现原理
- 2.1 Trie 树的构建
- 2.2 Trie树的查找
- 2.3 Trie树的遍历
- 2.4 Trie树的时间/空间复杂度
- 2.5 Trie 树 Vs 散列表/红黑树
- 3. Trie树的应用 -- 搜索词提示功能
1. 算法背景
之前我们了解过单模式串匹配的相关高效算法 – BM/KMP,虽难以理解,缺能够给予我们足够的宽度来扩展思维。
1. BF 和 RK 算法实现
2. BM 和 KMP 算法详解
但单模式串的匹配仅仅限于一个模式串从一个主串中查找,实际场景中我们却需要从多个主串中查找模式串,像IDE/文本编辑器甚至搜索引擎这样的庞大的数据量下多模式串中的高效查找却是单模式串查找效率无法满足的。
基于多模式串的高效搜索能力是需要我们重点关注的方向,也就是我们今天要推出的Tire 树 数据结构。
Trie 树能够比较友好得实现搜索词提示功能,接下来详细看看Trie树的原理。
2. Trie 树实现原理
Trie树 的核心目的是为了让拥有公共前缀的主串能够以一个树的形态存在。就像树有主干分支,有叶子分支一样,trie树让公共前缀的部分形成主干分支,没有公共前缀的部分就各自形成叶子分支。
这样的一个字符串树能够极大得方面模式串的查找,顺着主干分支直接移动模式串的下标匹配,非主干分支也能够快速匹配。而不需要像单模式串那样,为了加速匹配的过程还需要考虑前缀/后缀子串。
2.1 Trie 树的构建
Trie 树的大体形态如下:
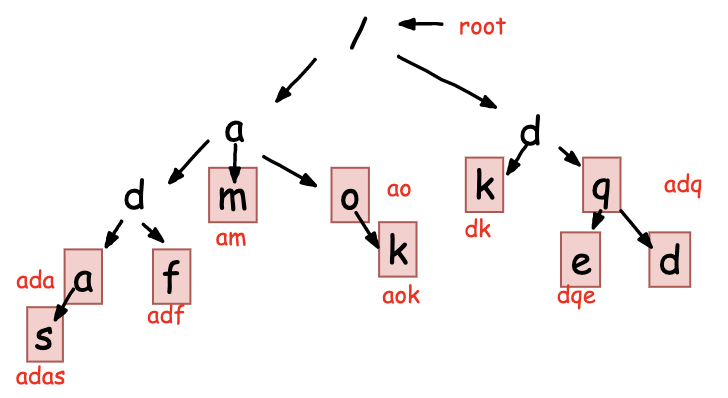
将:adas,ada,adf,am,ao,aok,dk,dqe,deq 这样的独立主串中的字符组织成一个个树的节点,从树的根节点开始,沿着主干分支即可能够快速确认模式串是否能够匹配。
Trie树中不一定是叶子结点才是一个字符串的结束字符,叶子节点中间也可能有结束字符。
所以构建trie树的过程需要为上下节点之间建立连接关系,从而保证查找能够从上一个节点准确得落到下一个节点。
构建形态如下:
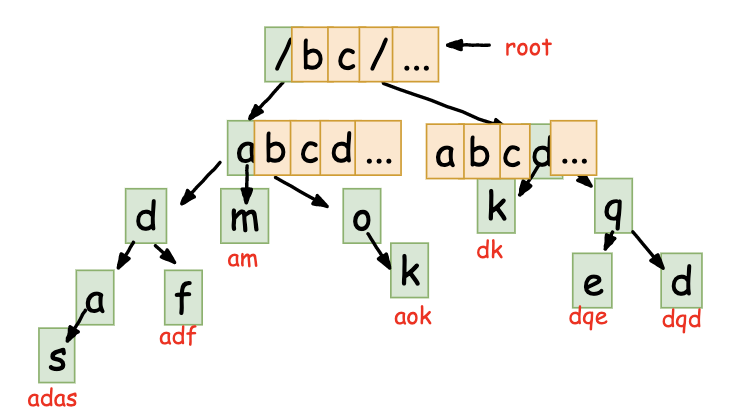
为每一个节点维护一个字符串全集的数组,比如 am这个字符串,在a节点处维护一个26长度的节点数组,其中a字符串所在下标不为空且指向下一个字符数组中的m,而b,c,d…等其他字符的数组为空即可。
ps : 这里大家也能够发现一个问题,就是构建Trie树的过程需要消耗大量的空间,虽然有公共前缀的公共存储,但是对于一个字符存储来说,需要26个额外的指针空间,所以Trie树的内存消耗问题显而易见。
定义TrieNode节点如下:
// Trie nodeinfo
class TrieNode {public:char data_;TrieNode *children_[26];bool isEndingChar_;TrieNode(char data='/') :data_(data),isEndingChar_(false){memset(children_, 0, sizeof(TrieNode *)* 26);};
};
构建的主要过程如下:
- 主串数组逐个交给初始化后的根节点
- 根节点逐个遍历输入主串的字符:
- 确认每个字符所处下一层的children_数组中的位置(因为这里是26个字母,index = input[i] - ‘a’)
- 核对下一层的children数组是否为空,不为空则表明是公共前缀,继续处理下一个输入字符
- 为空 则说明需要为当前input[i]构建一个新的TrieNode添加进来
- 完成将一个输入主串的所有字符添加到Trie树之后 更新结尾标记(表示当前位置为这个主串的结尾标记)。
void Trie::insert(string des) {if (des.size() <= 0) {return;}TrieNode *tmp = root_;int i;// Traverse every character in desfor (i = 0;i < des.size(); i++) {// The des[i] insert position at trie tree.int index = des[i] - 'a';if (tmp->children_[index] == nullptr) {TrieNode *newNode = new TrieNode(des[i]);tmp->children_[index] = newNode; }tmp = tmp->children_[index];}tmp->isEndingChar_ = true;
}
2.2 Trie树的查找
完成了Trie树的构建,剩下的查找就比较容易了。
- 拿着输入的字符串逐个字符遍历,确认每一个字符的index
- 如果这个字符index对应的TrieNode为空,且这个字符不是整个字符串的最后一个字符,则说明不匹配
- 如果不为空,则说明Trie树中有这个节点,那表示当前字符匹配,继续后续字符的处理
- 当最后一个字符对应的TrieNode中的End标记为真,则说明字符串匹配;否则不匹配
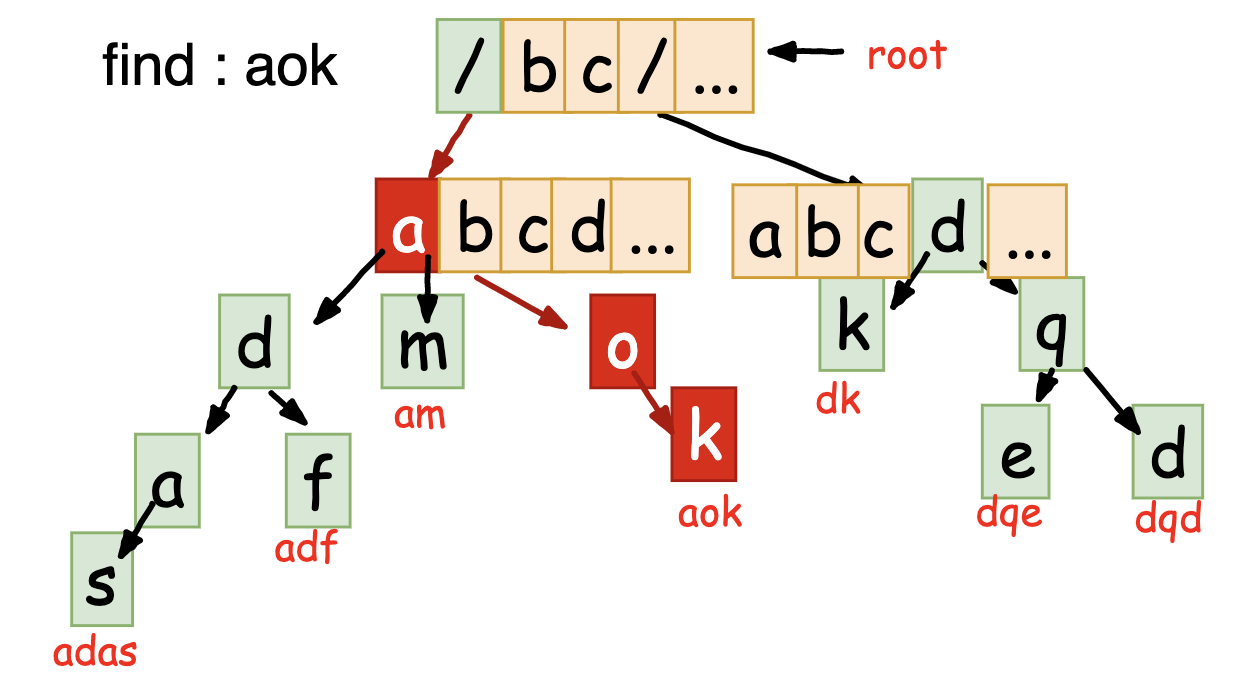
代码如下:
// Judge if a string is match with Trie tree
bool Trie::find(string des) {if (des.size() == 0) {return false;}TrieNode *tmp = root_;int i;for (i = 0;i < des.size(); i++) {// The index of the current char's positionint index = des[i] - 'a';if (tmp->children_[index] == nullptr) {return false;}// Move the tmp to the next linetmp = tmp->children_[index];}// End position to ensure wether the input str is match.if (tmp->isEndingChar_ == false) {return false;}return true;
}
2.3 Trie树的遍历
Trie树的遍历就是一个深搜的过程,沿着一个方向直接找到最后一个节点即可。
// Traverse the trie tree recursion
// para1: TrieNode
// Para2: prefix string
// para3: result vector
void Trie::dfs_traverse(TrieNode *p, string buf, vector<string> &tmp_str) {if (p == nullptr) {return;}// if match, just and the result to vectorif (p->isEndingChar_ == true) {tmp_str.push_back(buf);}for (int i = 0; i < 26; i++) {if (p->children_[i] != nullptr) {// Just add the prefix every timedfs_traverse(p->children_[i], buf+(p->children_[i]->data_), tmp_str);}}
}// Print the all trie tree string with dictionary order
void Trie::printTrie() {vector<string> tmp_str;int i, j;for (i = 0;i < 26; i++) {string buff = "";if (root_->children_[i] != nullptr) {// Will be called recursion.// Input with TrieNode, the prefix character and the result vectordfs_traverse(root_->children_[i], buff + root_->children_[i]->data_, tmp_str);}}cout << "Trie string: " << tmp_str.size() << endl;for (j = 0;j < tmp_str.size(); j++) {cout << tmp_str[j] << endl;}
}
2.4 Trie树的时间/空间复杂度
- 空间复杂度:空间消耗不用说,对于总共n个字符的所有主串来说,上仅仅是26个字母,以上为每一个字符都实现了一个26位的指针数组。64位机器下的最坏空间消耗:(26*8 + 1)*n B,显然Trie树的空间消耗是一个非常大的问题。当然对于公共前缀比较多的场景,构建Trie的空间会一定程度的降低。
- 时间复杂度:构建Trie树需要遍历 n个字符中的每一个字符 消耗O(n);构建好Trie树之后,每一个模式串的匹配同样只需要遍历一次 消耗O(k),整个时间复杂度是O(k+n)。
2.5 Trie 树 Vs 散列表/红黑树
| Trie树(26字符) | 散列表/红黑树 | |
|---|---|---|
| 内存消耗 | 26*8*n | O(n) |
| 查找效率 | O(n+k) | O(1) |
| 工业实现 | 无,需手动实现 | 有且完备 |
| 适用场景 | 搜索词提示/IDE自动补全 | 字符串精确查找 |
综上,如果需要多模式串的精确功能,红黑树/散列表等工业实现会更合适;如果需要搜索词提示这样的功能,则Trie树的结构天然适合。
以上完整测试代码:
#include <iostream>
#include <string>
#include <vector>using namespace std;// Trie nodeinfo
class TrieNode {public:char data_;TrieNode *children_[26];bool isEndingChar_;TrieNode(char data='/') :data_(data),isEndingChar_(false){memset(children_, 0, sizeof(TrieNode *)* 26);};
};// Trie tree info with a root node
class Trie {
public: Trie() {root_ = new TrieNode();}~Trie() {destory(root_);}void insert(string des);bool find(string des);void printTrie();void destory(TrieNode *p);void dfs_traverse(TrieNode *p, string buf, vector<string> &tmp_str);private:TrieNode *root_;
};// Delete the TrieNode, and release the space
void Trie::destory(TrieNode *p) {if (p == nullptr) {return;}for (int i = 0;i < 26; i++) {destory(p->children_[i]);}delete p;p = nullptr;
}void Trie::insert(string des) {if (des.size() <= 0) {return;}TrieNode *tmp = root_;int i;for (i = 0;i < des.size(); i++) {// The des[i] insert position at trie tree.int index = des[i] - 'a';if (tmp->children_[index] == nullptr) {TrieNode *newNode = new TrieNode(des[i]);tmp->children_[index] = newNode; }tmp = tmp->children_[index];}tmp->isEndingChar_ = true;
}// Traverse the trie tree recursion
void Trie::dfs_traverse(TrieNode *p, string buf, vector<string> &tmp_str) {if (p == nullptr) {return;}// if match, just and the result to vectorif (p->isEndingChar_ == true) {tmp_str.push_back(buf);}for (int i = 0; i < 26; i++) {if (p->children_[i] != nullptr) {// Just add the prefix every timedfs_traverse(p->children_[i], buf+(p->children_[i]->data_), tmp_str);}}
}// Print the trie tree with dictionary order
void Trie::printTrie() {vector<string> tmp_str;int i, j;for (i = 0;i < 26; i++) {string buff = "";if (root_->children_[i] != nullptr) {// Will be called recursiondfs_traverse(root_->children_[i], buff + root_->children_[i]->data_, tmp_str);}}cout << "Trie string: " << tmp_str.size() << endl;for (j = 0;j < tmp_str.size(); j++) {cout << tmp_str[j] << endl;}
} // Judge if a string is match with Trie tree
bool Trie::find(string des) {if (des.size() == 0) {return false;}TrieNode *tmp = root_;int i;for (i = 0;i < des.size(); i++) {// The index of the current char's positionint index = des[i] - 'a';if (tmp->children_[index] == nullptr) {return false;}// Move the tmp to the next linetmp = tmp->children_[index];}// End position to ensure wether the input str is match.if (tmp->isEndingChar_ == false) {return false;}return true;
}int main() {string s[5] = {"adafs", "dfgh", "amkil", "doikl", "aop"};Trie *trie = new Trie();for (int i = 0; i < 5; i++) {trie->insert(s[i]);}trie->printTrie();string in_str;cout << "Inpunt a string :" << endl;cin >> in_str;if (trie->find(in_str)) {cout << "Trie tree has the str: " << in_str << endl;} else {cout << "Trie tree doesn't have the str : " << in_str << endl;}return 0;
}
输出如下:
> ./trie_alg
Trie string: 5
adafs
amkil
aop
dfgh
doiklInpunt a string :
aoe
Trie tree doesn't have the str : aoe
3. Trie树的应用 – 搜索词提示功能
想要实现搜索词提升这样的功能,需要基于Trie树实现做一些逻辑的添加。比如 用户输入h,则能够返回h为开头的字符串;输入he,则能够返回he开头的字符。。。
类似如下:
source code: https://github.com/BaronStack/DATA_STRUCTURE/blob/master/string/trie_alg.cc
实现逻辑如下:
// Traverse the trie tree recursion
void Trie::dfs_traverse(TrieNode *p, string buf, vector<string> &tmp_str) {if (p == nullptr) {return;}// if match, just and the result to vectorif (p->isEndingChar_ == true) {tmp_str.push_back(buf);}for (int i = 0; i < 26; i++) {if (p->children_[i] != nullptr) {// Just add the prefix every timedfs_traverse(p->children_[i], buf+(p->children_[i]->data_), tmp_str);}}
}// Input the prefix, and search the prefix related string
void Trie::printTrieWithPrefix(string start) {vector<string> tmp_str;int i, j;TrieNode *tmp = root_;// Ensure prefix is existfor (int i = 0;i < start.size(); i++) {int index = start[i] - 'a';if (tmp->children_[index] == nullptr) {cout << "No prefix with " << start << endl;return;} tmp = tmp->children_[index];}// Prefix is a matched stringtmp_str.push_back(start);for (i = 0;i < 26; i++) {string buff = start;if (tmp->children_[i] != nullptr) {// Will be called recursiondfs_traverse(tmp->children_[i], buff + tmp->children_[i]->data_, tmp_str);}}cout << "Trie string: " << tmp_str.size() << endl;for (j = 0;j < tmp_str.size(); j++) {cout << tmp_str[j] << endl;}
}
输出如下:
Trie string: 5
adafs
amkil
aop
dfgh
doikl
Input a prefix :
a
Trie string: 3
adafs
amkil
aop
同样,如果想要为每个字符串增加更多的指标 – 比如公共前缀重合度 这样的属性可以增加到TrieNode数据结构中,在构建Trie树的过程中为每一个TrieNode的这个属性做对应的变更即可。
相关文章:
Java项目:成绩管理系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 超豪华成绩管理系统,学生,教师,管理员三类用户集 成,课程表管理,成绩查询,成绩详情数据统计…

NSThread 多线程相关
1.下面的代码,有2点需要注意,1>就是 就是thread:所传得参数,这里传得的是nsarray 当然也可以传其他的类型。2> [self performSelectorOnMainThread:selector(update) withObject:nil waitUntilDone:YES]; 这个函数的作用是通知主线程进…

Windows Phone 8初学者开发—第19部分:设置RecordAudio.xaml页面
原文地址: http://channel9.msdn.com/Series/Windows-Phone-8-Development-for-Absolute-Beginners/Part-19-Setting-up-the-RecordAudioxaml-Page 系列地址: http://channel9.msdn.com/Series/Windows-Phone-8-Development-for-Absolute-Beginners 源代码: http://aka.ms/abs…
9.path Sum III(路径和 III)
Level: Easy 题目描述: You are given a binary tree in which each node contains an integer value. Find the number of paths that sum to a given value. The path does not need to start or end at the root or a leaf, but it must go downwards…
字符串匹配算法 -- AC自动机 基于Trie树的高效的敏感词过滤算法
文章目录1. 算法背景2. AC自动机实现原理2.1 构建失败指针2.2 依赖失败指针过滤敏感词3. 复杂度及完整代码1. 算法背景 之前介绍过单模式串匹配的高效算法:BM和KMP 以及 基于多模式串的匹配数据结构Trie树。 1. BM和KMP 单模式串匹配算法细节 2. Trie树 多模式串的高效匹配数…
Java项目:仿小米商城系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 基于vue Springboot前后端分离项目精简版仿小米商城 系统,注册登录,首页展示,商品展示,商品购买,下单…
vb socket的使用
说明:原本在 csdn 博客 写博客的,因为使用的移动宽带,csdn的 博客无法访问,所以先暂时到博客园写博客了 有能解决移动宽带 有部分网站不能访问的问题,请联系我,QQ 809775607 /***************************/ 下面写wins…
不吹牛会死!国内音乐平台进入“大逃杀”
日前,一篇《看看海洋与腾讯音乐将如何“血洗”独立音乐应用》的文章引起了广泛关注。文中海洋声称长期独家签约的音乐及版权代理公司达40多家,占市场份额超过15%,一时间名不见经传的海洋音乐仿佛成了一匹跃然网上的“黑马”。然而据音乐圈深喉…
leetcode网学习笔记(1)
https://leetcode-cn.com/problems/reverse-linked-list/submissions/ 206 反转链表 错误原因:没有考虑到链表为空以及链表只有一个元素的情况 https://leetcode-cn.com/problems/swap-nodes-in-pairs/comments/ 24 两两交换链表 原方法:使用4个指针遍历…
贪心算法简单实践 -- 分糖果、钱币找零、最多区间覆盖、哈夫曼编解码
1. 贪心算法概览 贪心算法是一种算法思想。希望能够满足限制的情况下将期望值最大化。比如:Huffman编码,Dijkstra单源最短路径问题,Kruskal最小生成树 等问题都希望满足限制的情况下用最少的代价找到解决问题的办法。 这个办法就是贪心算法…

Java项目:个人博客系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:文章展示、热门文章、文章分类、标签云用户登录评论、匿名评论用户留言、匿名留言评论管理、文章发布、文章管理文章数据统计等等. 二、项目运行 环境…

第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器
第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器 原文:第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器 前言:在前一章已经演示了如何使用SSMS来配置资源调控器。但是作为DBA&a…

Android_开源框架_Volley实例
2019独角兽企业重金招聘Python工程师标准>>> 1.自定义相关类在 Android_开源框架_Volley(Google IO 2013)源代码及内部实现过程分析一文中,简单概述了Volley框架内部实现过程。如想理解彻底应该熟悉 android多线程通信机制( Android_Thread多线程_Handle…
maven的配置-2019-4-13
一.Maven的优点 1. 依赖管理 jar 包管理 2.一键构建 (编译-----测试------打包-----安装-----部署 ) 什么是项目构建? 指的是项目从编译-----测试------打包-----安装-----部署 整个过程都交给maven进行管理,这个过程称为构建 一…
WiredTiger引擎编译 及 LT_PREREQ(2.2.6)问题解决
近期需要为异构引擎做准备, wiredtiger 以其优异的性能(B-tree和LSM-tree都支持)和稳定性(Mongodb的默认存储引擎) 被我们备选为异构引擎里的一个子引擎,后续将深入wiredtiger 引擎原理。这里简单记录一下Wiredtiger 存储引擎的编译记录。 Environment …
Java项目:员工管理系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:分为前端翻后端部分,包括用户,区分晋通用户以及誉里员用户,包括首页展示,部门管理,人事管理,…

缺陷重点内容分析
1.缺陷优先级 序号优先级描述1低暂时不影响继续测试,可以在方便时解决2中部分功能测试无法继续测试;需要优先解决3高测试暂停,无法进行,必须立即解决2.缺陷的状态(图片来自云测视频) 3.缺陷生命周期与管理流…
关于node.js的误会
昨天写了篇博客,介绍了一下我对node.js的第一次亲密接触后的感受,以为node.js很小众,出乎我意料很多人感兴趣,并且对博客中的细节问题做了评论,最多的是围绕node.js的异步与单线程展开的,当然还有很多关于n…
文本相关CSS
文本相关CSS 属性 word-breakoverflow-wrap(word-wrap)white-spacetext-overflowtext-wrap(目前主流浏览器都不支持)应用 一般断行需求实现文本不换行,以省略号表示超出的部分参考资料属性 word-break 作用:指定非CJK(中日韩)文本的断行规则。࿰…
Rocksdb 的优秀代码(三)-- 工业级 线程池实现分享
文章目录前言1. Rocksdb线程池概览2. Rocksdb 线程池实现2.1 基本数据结构2.2 线程池创建2.3 线程池 调度线程执行2.4 线程池销毁线程2.5 线程池优先级调度2.6 动态调整线程池 线程数目上限3. 总结前言 Rocksdb 作为一个第三方库的形态嵌入到各个存储系统之中存储元数据&#…
Java项目:网上电商项目(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 一款基于SpringbootVue的电商项目,前后端分离项目,前台后台都有,前台商品展示购买,购物车分类,订 单查…
3月7日 ArrayList集合
ArrayList与数组的区别: 数组是连续的、同一类型数据的一块区域,而集合可以是不连续的、多种数据类型的。 1.ArrayList ArrayList al new ArrayList(); al.Add(3); al.Add(5.09); al.Add("gfdg"); al.Inse…
什么时候出生好?
从年龄来说,女人头一胎的怀孕时间最好在35岁以前,因为过了35岁后不孕和头胎生育缺陷的比例会大幅度升高。那么,从孩子的角度,什么时候出生好?很多人不考虑这个问题,能不能怀上还难说那。迷信的人则追求出生…

数据库搜索与索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。 索引的一个主要目的就是加快检索表中数据&#x…
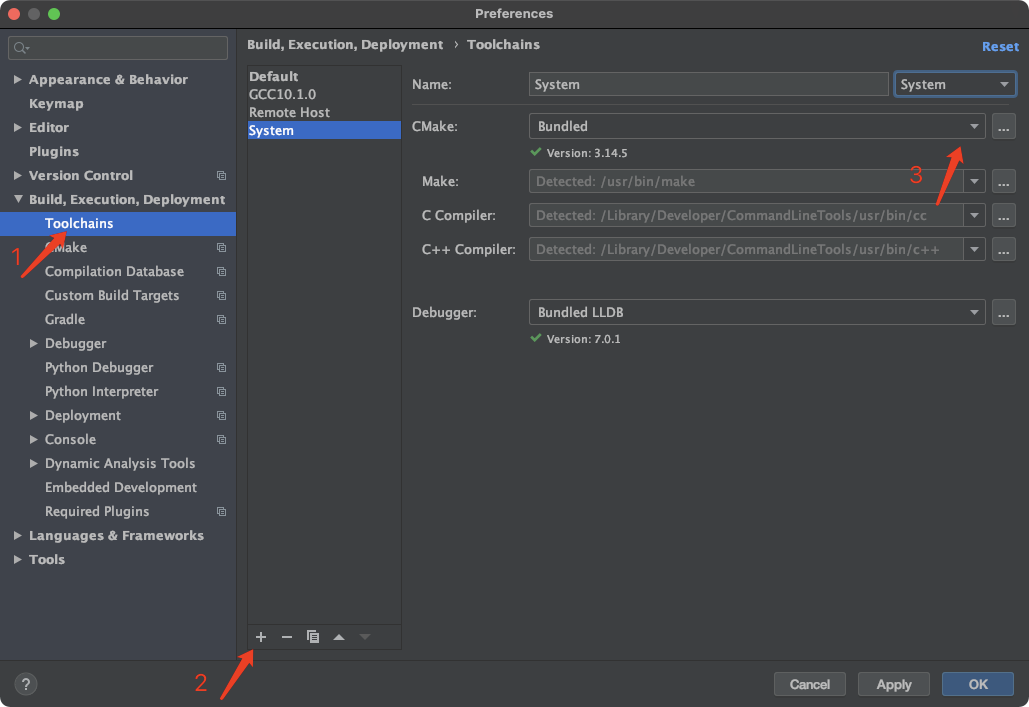
Clion 远程开发 配置
文章目录1. 增加远端服务工具2. 配置远端服务器3. 配置编译选项4. 设置远端开发路径Clion作为C/C语言友好的IDE,除了高效的代码索引 以及 基本的本地开发 能力之外还需要有远程开发能力,即我们工作中的代码处于远端linux服务器之上,通过在本地…
Java项目:朴素风个人博客系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 基于vue Springboo痼J后端分离项目个人博客系统,注册 登录,首页展示,喜爰图书展示,后台图书维护,个人…

NodeJS+Mongodb+Express做CMS博客系统
楼主正在用业余时间开发中…… ,目前的版本仅支持会员系统,尝鲜一下吧~ hi-blog 一个 nodejsexpressmongodb 的 cms 系统怎么启动 默认你已经安装了 mongodb ;那么你得这样操作:安装项目 -> 初始化管理员 -> 运行项目 1、请…

Piranha实验总结
操作系统:rhel5.8分别在DirectorMaster和DirectorBackup上部署浮动资源(VIP IPVS策略)测试2个Director在DR模式下是否都可以正常工作。测试完成后都撤掉浮动资源。DirectorMaster[rootlocalhost ~]#yum install piranha[rootlocalhost ~]#piranha-passwdNew Passwor…
虚IP切换原理
高可用性HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。HA系统是目前企业防止核心计算机系统因故障停机的…
vim 键盘宏操作 -- 大道至简
最近利用vim做一些文本处理时 发现vim 支持的键盘宏是一个好东西啊,高效优雅得处理大量需要重复性操作的文本,让人爱不释手!!! 希望接下来对键盘宏的分享能够实际帮助到大家。 后文中描述的一些vim操作会汇集成指令字…