贪心算法简单实践 -- 分糖果、钱币找零、最多区间覆盖、哈夫曼编解码
1. 贪心算法概览
贪心算法是一种算法思想。希望能够满足限制的情况下将期望值最大化。比如:Huffman编码,Dijkstra单源最短路径问题,Kruskal最小生成树 等问题都希望满足限制的情况下用最少的代价找到解决问题的办法。
这个办法就是贪心算法的思想。
实际用贪心算法解决问题可以有如下几步:
- 当看到这类问题时 我们能够联想到贪心算法:针对一组数据,我们定义了期望值和限制值,希望在满足限制值的情况下期望值最大。
比如最短路径中,限制值是每一次移动只能向下或向右,期望值是走到终点(某个顶点),期望用最少的步数走到目标顶点。 - 尝试使用贪心算法来解决问题:每一次做出选择时在对限制值同等贡献量的情况下,选择对期望值贡献最大的数据。
- 尝试在案例数据中举例,查看贪心方式的实验结果是否最优。
贪心算法适用的案例 是 每一次的选择都是独立事件,不会受到之前选择的影响。比如有权图中的最短路径的查找,当前的选择会对后续的选择造成影响,第一次选择最优的,后续可选的权值都是特别大的,则期望值并不是最优的。
可以看看如下几个简单实践。
2. 贪心算法实践
2.1 分糖果
我们有m个糖果和n个孩子。我们现在要把糖果分给这些孩子吃,但是糖果少,孩子多(m<n),所以糖果只能分配给一部分孩子。
每个糖果的大小不等,这m个糖果的大小分别是s1,s2,s3,…,sm。除此之外,每个孩子对糖果大小的需求也是不一样的,只有糖果的大小大于等于孩子的对 糖果大小的需求的时候,孩子才得到满足。假设这n个孩子对糖果大小的需求分别是g1,g2,g3,…,gn。如何分配糖果,能尽可能满足最多数量的孩子?
期望值:最多满足孩子的个数
限制值:糖果大小s >= g ,才视为该糖果满足该孩子。
满足限制值的情况下,不论用小糖果还是大糖果满足孩子,对期望值的贡献都是一样的,满足的孩子个数++ 而已。
贪心算法:
- 对于一个孩子,用较小的糖果能够满足,则没有必要用更大的糖果;更大的糖果可以用来满足更多需求的孩子。
- 对于一个糖果,从较小需求的孩子开始,越容易满足。
代码如下:
// simple greedy algorithm: distribute candies
// six childs' request: 1 1 3 2 2 8
// five candies size: 4 2 5 7 9
//
// Greedy algorithm is suitable to solve the problem.
// We can let the smaller candy's size to satisfy the
// smaller resquest of child.
int distributeCandy(vector<int> candies,vector<int> childs) {if(candies.size() == 0 || childs.size() == 0) {return 0;}// sort, we can compare from small to big requestsort(candies.begin(), candies.end());sort(childs.begin(), childs.end());int res = 0;int i, j;for (i = 0, j = 0;i < childs.size() && j < candies.size(); i++,j++) {if (childs[i] <= candies[j]) {res ++;}}return res;
}
完整测试代码:
https://github.com/BaronStack/DATA_STRUCTURE/blob/master/greedy/distribute_candies.cc
2.2 钱币找零
这个问题在我们的日常生活中更加普遍。假设我们有1元、2元、5元、10元、20元、50元、100元这些面额的纸币,它们的张数分别是c1、c2、c5、c10、c20、c50、c100。我们现在要用这些钱来支付K元,最少要用多少张纸币呢?
在生活中,我们肯定是先用面值最大的来支付,如果不够,就继续用更小一点面值的,以此类推,最后剩下的用1元来补齐。
期望值:纸币数目最少
限制值:每种面额的张数
在满足限制值的情况下,希望用最少的纸币数目达成期望值。不论使用面额大的纸币还是面额小的纸币,期望值的纸币数目都会++,贡献一样。所以相同贡献值的情况下,使用更大面额的纸币更容易满足期望值。
代码如下:
int cmp(pair<int, int> a, pair<int, int> b) {return a.first > b.first;
}// Get the total num of papers that satisfy the K
// param1: nums of every coin
// param2: target number
// param3: cost of every coin in coins
void getCoinNums(vector<pair<int,int>> coins,int K, vector<pair<int,int>> &result) {if (coins.size() == 0) {return;}int i, tmp;// sort from biger to smallersort(coins.begin(), coins.end(), cmp);i = 0;tmp = 0;while(K && i < coins.size()) {tmp = K / coins[i].first;if (tmp != 0) {int real_nums;// defend the real coin nums overheadif (tmp <= coins[i].second) {real_nums = tmp;} else {real_nums = coins[i].second;}K -= real_nums * coins[i].first;result.push_back(make_pair(coins[i].first, real_nums));}i++;}
}
完整测试代码:
https://github.com/BaronStack/DATA_STRUCTURE/blob/master/greedy/coins_charge.cc
2.3 最多覆盖区间
假设我们有n个区间,区间的起始端点和结束端点分别是[l1, r1],[l2, r2],[l3, r3],…,[ln, rn]。我们从这n个区间中选出一部分区间,这部分区间满足两两不相 交(端点相交的情况不算相交),最多能选出多少个区间呢?
比如区间: [6,8], [2,4], [3,5], [1,5], [5,9], [8,10], 则最多不相交区间为 : [2,4], [6,8], [8,10]
我们将各个区间的右端点从小到大排序,每次选择区间时只需要确认当前区间的左端点比上一个区间的右端点大就可以了。之所以选择对右端点进行从小到大的排序,因为右端点决定的是一个区间的下界,我们每次选择尽可能选择下界小且和之前的区间没有相交的区间,则才能够得到最多的不相交区间。
实现代码如下:
int cmp(pair<int, int> a, pair<int, int> b) {if (a.second < b.second) {return 1;} else if (a.second == b.second &&a.first < b.first) {return 1;} else {return 0;}
}// algorithm:
// 1. Sort the array with right node increase
// 2. Maintain a num e, if rest of the interval's left node
// bigger than e, then the interval will be choosen
//
// example:
// Befor sort: [6,8], [2,4], [3,5], [1,5], [5,9], [8,10]
// After sort: [2,4], [1,5], [3,5], [6,8], [5,9], [8,10]
//
// result : [2,4], [6,8], [8,10]
void intervalCoverage(vector<pair<int,int>> intervals,vector<pair<int,int>> &result) {if (intervals.size() == 0) {return;}int i, e, count;sort(intervals.begin(), intervals.end(), cmp);e = -1;count = 0;for (i = 0;i < intervals.size(); i++) {if(intervals[i].first >= e) {count ++;e = intervals[i].second;result.push_back(make_pair(intervals[i].first,intervals[i].second));}}
}
完整测试代码:
https://github.com/BaronStack/DATA_STRUCTURE/blob/master/greedy/interval_coverage.cc
2.4 哈夫曼编解码
哈夫曼编码是一种针对数据高效压缩的编码方式,能够达到20%-90%的压缩比。
比如:
- 1000长度的字符串 需要1000bytes = 8000 bit的存储空间。
- 优化:如果1000长度的字符串中总共有8个不同的字符,则这八个字符可以用三个bit位就能表示(000-111),1000长度的字符串只需要3000 bit的存储空间
- 进一步优化:haffman编码,每个字符的bit位表示可以不定长(解码会复杂一些),总长度不会超过3位(1000字符不会超过3000bit的存储空间)。haffman编码为了满足不定长的要求,不会出现针对某一个字符的编码是另一个字符编码前缀的情况。
比如如下字符表,huffman编码 以及 其对应的总二进制位数 ,最后1000字符总共也只有2100的bit存储空间。
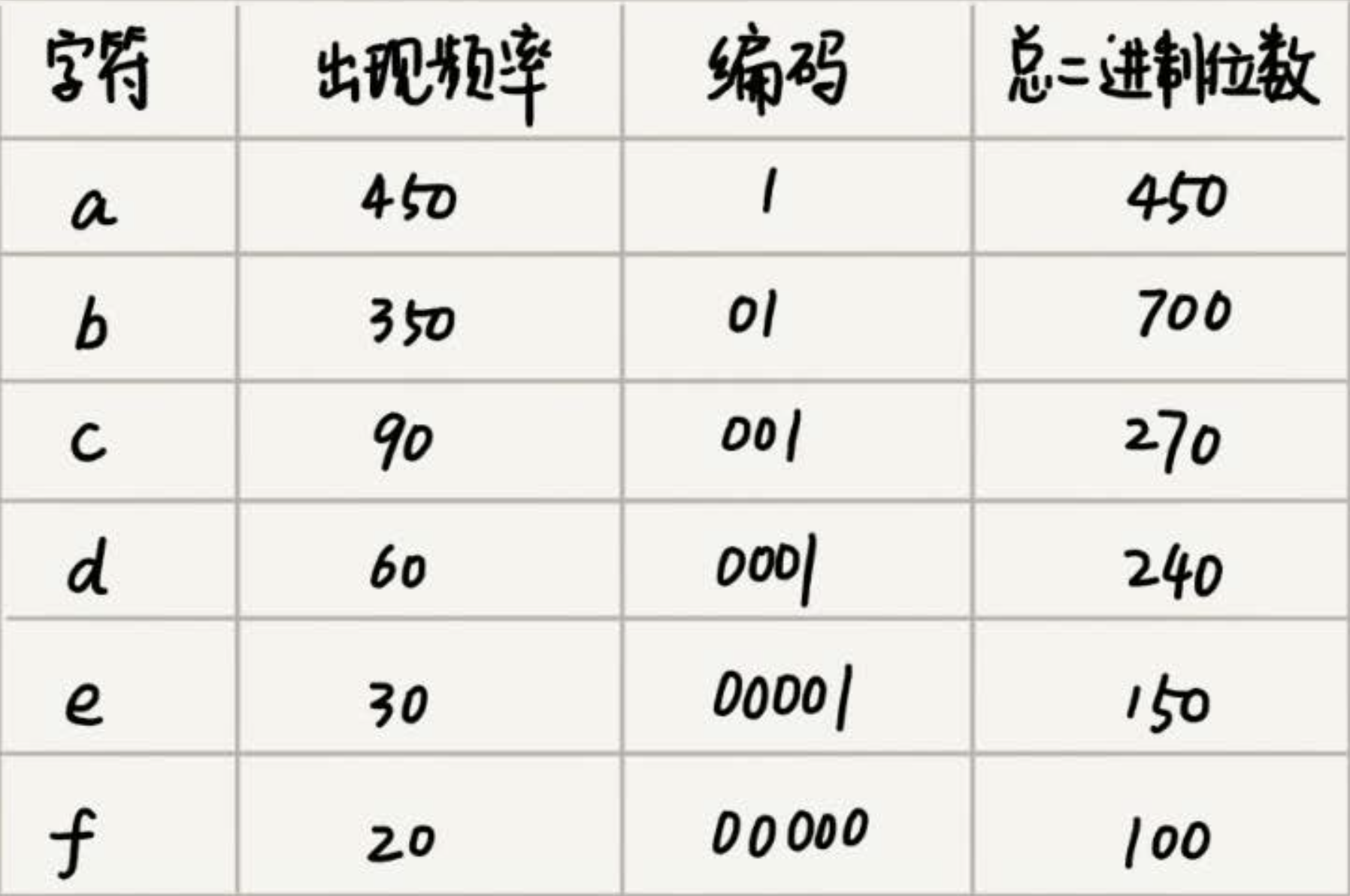
所以这里根据频率构建huffman 编码的过程就用到了贪心的思想。
构建huffman树的过程 选择两个小频率的字符开始构建的父节点作为一个新节点,再选择一个次小的与该新节点一起构建一个新的父节点,依次由下向上构建。最终出现频率越高的字符串越靠近根节点。
构建过程如下:
void huffmanTree(priority_queue<Node> &q) {// root node is store in proiority_queue// when the q size is 1while (q.size() != 1) {Node *left = new Node(q.top()); q.pop();Node *right = new Node(q.top()); q.pop();// father's node and it's left and right childNode node('R', left->frequency + right->frequency, left, right);q.push(node);}
}
构建完huffman树之后,进行各个字符的编码,这里仅仅将所有的左子树权值设置为0,又子树权值设置为1就可以了
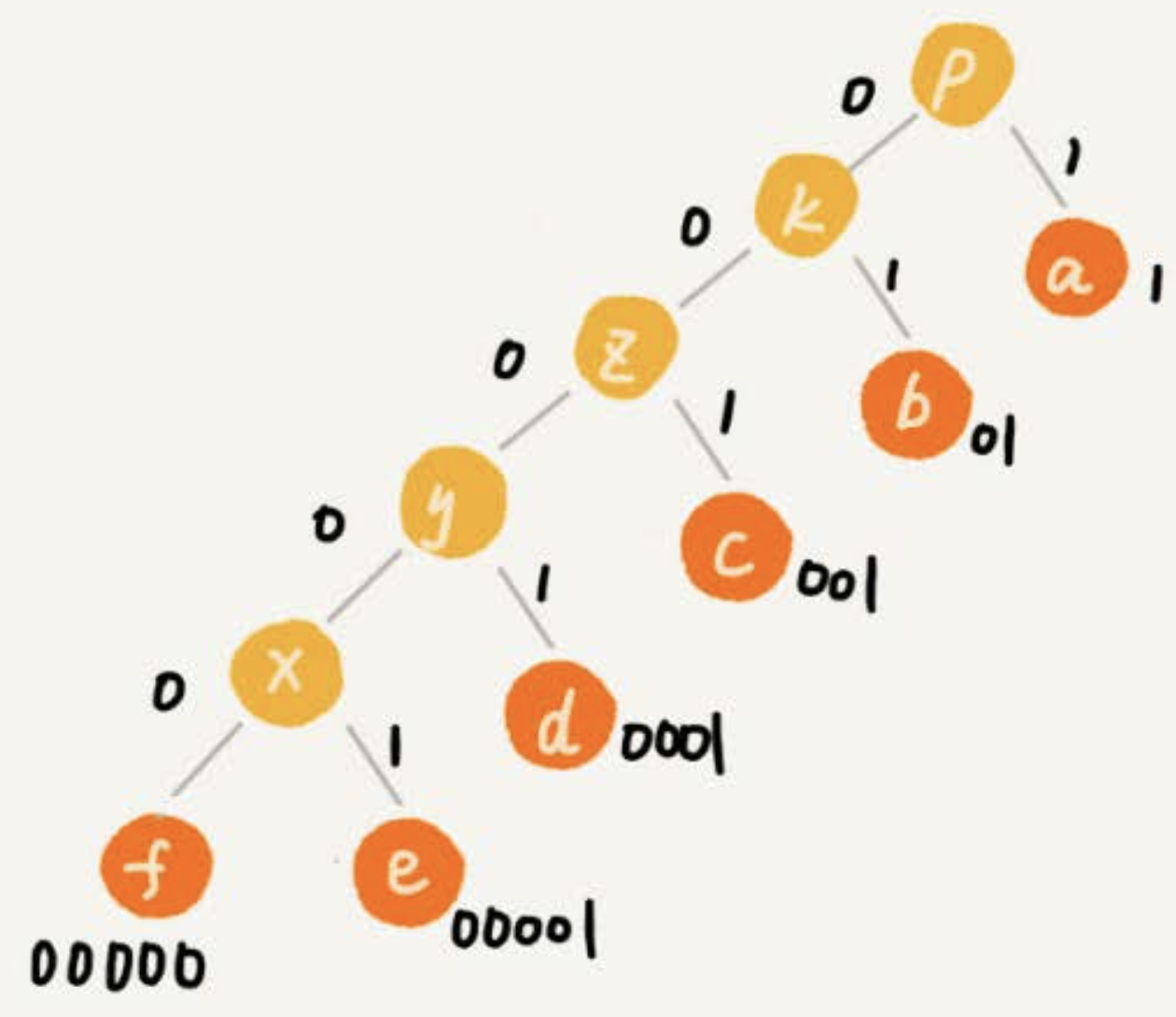
huffman编码过程如下:
// Huffman encode function
// param1: Root is the huffman tree's root node
// param2: prefix is the encode result per char
// param3: a map with 'char' and it's huffman's encode
void huffmanEncode(Node *root, string &prefix,map<char, string> &result) {string m_prefix = prefix;if (root->left == nullptr)return;// set the left weight recursionprefix += "0";if (root->left->left == nullptr) {// find the char's result in the leaf noderesult[root->left->c] = prefix;} else {huffmanEncode(root->left, prefix, result);}// back to the begin node to set the right weightprefix = m_prefix;prefix += "1";if (root->right->right == nullptr) {result[root->right->c] = prefix;} else {huffmanEncode(root->right, prefix, result);}
}
huffman解码如下:
// Huffman decode function
// param1: des is the input string to be decode
// param2: res is the map between char and huffman's
// encode string
// param3: decode string
bool huffmanDecode(string des, map <char, string> res,string &result) {if (des == "") {return false;}int i;map<char,string>::const_iterator it;string buf_str = "";for (i = 0; i < des.size(); i ++) {buf_str += des[i];for (it = res.begin() ; it != res.end(); it++ ) {if (it->second == buf_str) {result += it->first; buf_str = "";break;}}if(i == des.size() - 1 && it == res.end()) {return false;}}return true;
}
完整测试代码:
https://github.com/BaronStack/DATA_STRUCTURE/blob/master/greedy/haffman.cc
相关文章:

Java项目:个人博客系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:文章展示、热门文章、文章分类、标签云用户登录评论、匿名评论用户留言、匿名留言评论管理、文章发布、文章管理文章数据统计等等. 二、项目运行 环境…

第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器
第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器 原文:第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器 前言:在前一章已经演示了如何使用SSMS来配置资源调控器。但是作为DBA&a…

Android_开源框架_Volley实例
2019独角兽企业重金招聘Python工程师标准>>> 1.自定义相关类在 Android_开源框架_Volley(Google IO 2013)源代码及内部实现过程分析一文中,简单概述了Volley框架内部实现过程。如想理解彻底应该熟悉 android多线程通信机制( Android_Thread多线程_Handle…
maven的配置-2019-4-13
一.Maven的优点 1. 依赖管理 jar 包管理 2.一键构建 (编译-----测试------打包-----安装-----部署 ) 什么是项目构建? 指的是项目从编译-----测试------打包-----安装-----部署 整个过程都交给maven进行管理,这个过程称为构建 一…

WiredTiger引擎编译 及 LT_PREREQ(2.2.6)问题解决
近期需要为异构引擎做准备, wiredtiger 以其优异的性能(B-tree和LSM-tree都支持)和稳定性(Mongodb的默认存储引擎) 被我们备选为异构引擎里的一个子引擎,后续将深入wiredtiger 引擎原理。这里简单记录一下Wiredtiger 存储引擎的编译记录。 Environment …
Java项目:员工管理系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:分为前端翻后端部分,包括用户,区分晋通用户以及誉里员用户,包括首页展示,部门管理,人事管理,…

缺陷重点内容分析
1.缺陷优先级 序号优先级描述1低暂时不影响继续测试,可以在方便时解决2中部分功能测试无法继续测试;需要优先解决3高测试暂停,无法进行,必须立即解决2.缺陷的状态(图片来自云测视频) 3.缺陷生命周期与管理流…
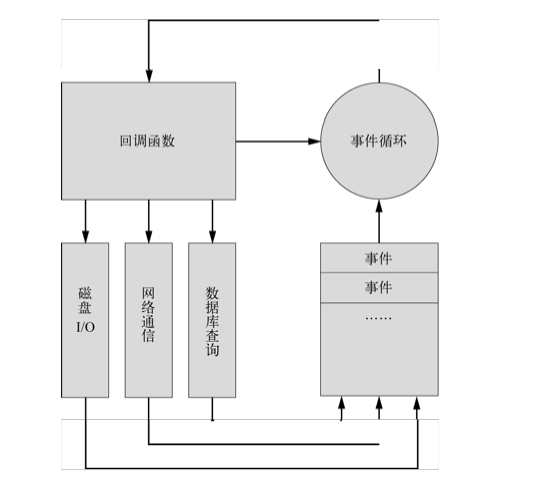
关于node.js的误会
昨天写了篇博客,介绍了一下我对node.js的第一次亲密接触后的感受,以为node.js很小众,出乎我意料很多人感兴趣,并且对博客中的细节问题做了评论,最多的是围绕node.js的异步与单线程展开的,当然还有很多关于n…
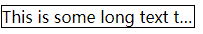
文本相关CSS
文本相关CSS 属性 word-breakoverflow-wrap(word-wrap)white-spacetext-overflowtext-wrap(目前主流浏览器都不支持)应用 一般断行需求实现文本不换行,以省略号表示超出的部分参考资料属性 word-break 作用:指定非CJK(中日韩)文本的断行规则。࿰…
Rocksdb 的优秀代码(三)-- 工业级 线程池实现分享
文章目录前言1. Rocksdb线程池概览2. Rocksdb 线程池实现2.1 基本数据结构2.2 线程池创建2.3 线程池 调度线程执行2.4 线程池销毁线程2.5 线程池优先级调度2.6 动态调整线程池 线程数目上限3. 总结前言 Rocksdb 作为一个第三方库的形态嵌入到各个存储系统之中存储元数据&#…
Java项目:网上电商项目(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 一款基于SpringbootVue的电商项目,前后端分离项目,前台后台都有,前台商品展示购买,购物车分类,订 单查…
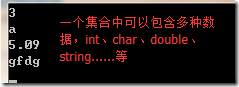
3月7日 ArrayList集合
ArrayList与数组的区别: 数组是连续的、同一类型数据的一块区域,而集合可以是不连续的、多种数据类型的。 1.ArrayList ArrayList al new ArrayList(); al.Add(3); al.Add(5.09); al.Add("gfdg"); al.Inse…
什么时候出生好?
从年龄来说,女人头一胎的怀孕时间最好在35岁以前,因为过了35岁后不孕和头胎生育缺陷的比例会大幅度升高。那么,从孩子的角度,什么时候出生好?很多人不考虑这个问题,能不能怀上还难说那。迷信的人则追求出生…

数据库搜索与索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。 索引的一个主要目的就是加快检索表中数据&#x…
Clion 远程开发 配置
文章目录1. 增加远端服务工具2. 配置远端服务器3. 配置编译选项4. 设置远端开发路径Clion作为C/C语言友好的IDE,除了高效的代码索引 以及 基本的本地开发 能力之外还需要有远程开发能力,即我们工作中的代码处于远端linux服务器之上,通过在本地…
Java项目:朴素风个人博客系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 基于vue Springboo痼J后端分离项目个人博客系统,注册 登录,首页展示,喜爰图书展示,后台图书维护,个人…

NodeJS+Mongodb+Express做CMS博客系统
楼主正在用业余时间开发中…… ,目前的版本仅支持会员系统,尝鲜一下吧~ hi-blog 一个 nodejsexpressmongodb 的 cms 系统怎么启动 默认你已经安装了 mongodb ;那么你得这样操作:安装项目 -> 初始化管理员 -> 运行项目 1、请…

Piranha实验总结
操作系统:rhel5.8分别在DirectorMaster和DirectorBackup上部署浮动资源(VIP IPVS策略)测试2个Director在DR模式下是否都可以正常工作。测试完成后都撤掉浮动资源。DirectorMaster[rootlocalhost ~]#yum install piranha[rootlocalhost ~]#piranha-passwdNew Passwor…
虚IP切换原理
高可用性HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。HA系统是目前企业防止核心计算机系统因故障停机的…
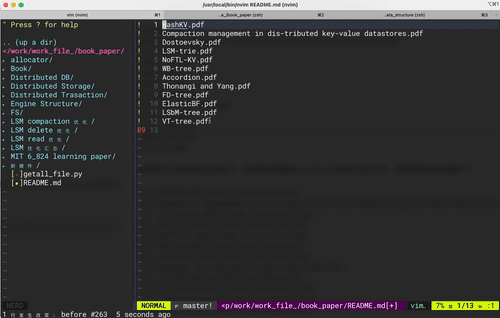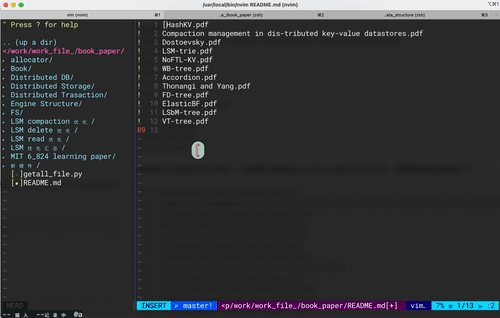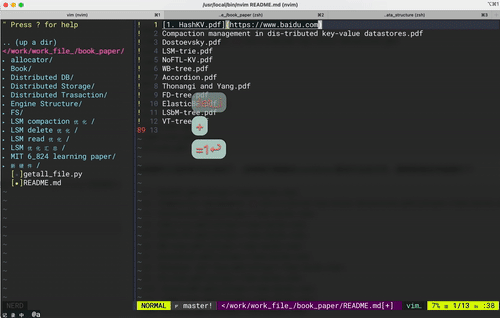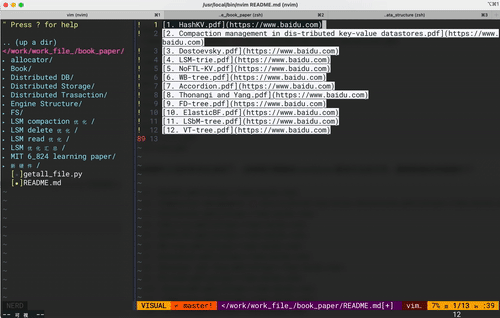
vim 键盘宏操作 -- 大道至简
最近利用vim做一些文本处理时 发现vim 支持的键盘宏是一个好东西啊,高效优雅得处理大量需要重复性操作的文本,让人爱不释手!!! 希望接下来对键盘宏的分享能够实际帮助到大家。 后文中描述的一些vim操作会汇集成指令字…
Java项目:家居购物商城系统(java+html+jdbc+mysql)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: Java Web精品项目源码,家居商城分类展示,商品展示, 商品下单,购物车,个人中心,后台管理,用…
leetcode:Search in Rotated Sorted Array
题目要求: Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 might become 4 5 6 7 0 1 2). You are given a target value to search. If found in the array return its index, otherwise return -1. You may a…

解决Debian-7.1下Chrome浏览器字体难看的问题
首先在 Advance Setting 的 font 标签页下做如下配置: 然后在用户目录下创建 .fonts.conf 文件,内容如下: <?xml version1.0?> <!DOCTYPE fontconfig SYSTEM fonts.dtd> <fontconfig><match target"font"&g…

HDU.4903.The only survival(组合 计数)
题目链接 惊了 \(Description\) 给定\(n,k,L\),表示,有一张\(n\)个点的无向完全图,每条边的边权在\([1,L]\)之间。求有多少张无向完全图满足,\(1\)到\(n\)的最短路为\(k\)。\(n,k\leq 12,\ L\leq10^9\)。 \(Solution\) 考虑暴力&a…
Rocksdb 写入数据后 GetApproximateSizes 获取的大小竟然为0?
项目开发中需要从引擎 获取一定范围的数据大小,用作打点上报,测试过程中竟然发现写入了一部分数据之后通过GetApproximateSizes 获取写入的key的范围时取出来的数据大小竟然为0。。。难道发现了一个bug?(欣喜) 因为写入的数据是…

Java项目:在线婚纱摄影预定系统(java+javaweb+SSM+springboot+mysql)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 前后用户的登录注册,婚纱照片分类,查看,摄影师预 订,后台订单管理,图片管理等等。 二、项目运行 环境配置&am…
Linux Terminal 控制终端的使用
1. Open new Terminal:Ctrl Alt T 或者 Ctrl Shift N 2. Open Tab:Ctrl Shift T 3. Close Tab:Ctrl Shift W 4. Close Window:Ctrl Shift Q 5. Copy : Ctrl Shift C 6. Paste: Ctrl Shift V 7. Full Screen: F11 8.…

如何防止代码腐烂
http://blog.jobbole.com/5643/ 很多团队都有这个问题,一个项目的代码本来开始设计得好好的,一段时间以后,代码就会变得难以理解,难以维护,难以修改。为什么?我一直在思考这个问题。 让我们先看一个人的情况…

CORS在Spring中的实现
CORS: 通常情况下浏览器禁止AJAX从外部获取资源,因此就衍生了CORS这一标准体系,来实现跨域请求。 CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。它允许浏览器向跨源(协议 域名…

从BloomFilter到Counter BloomFilter
文章目录前言1. Traditional BloomFilter2. Counter BloomFilter本文traditional bloomfilter 和 counter bloomfilter的C实现 均已上传至: https://github.com/BaronStack/BloomFilter 前言 Bloomfilter 是一个老生常谈的数据结构,应用在存储领域的各…