pmdk -- libpmemlog 介绍
文章目录
- 1. libpmemlog 应用背景
- 2. libpmemlog 使用方式
- 2.1 基本接口
- 2.2 接口使用
- 3. Libpmemlog 性能
- 3.1 write sys call 性能
- 3.2 libpmemlog 性能
1. libpmemlog 应用背景
本文介绍的是英特尔 傲腾持久化内存 pmdk中 的一个持久化日志的库。
我们正常系统中会将日志 形成一个LOG文件保存到磁盘中,这个过程在PMEM中也是类似的。尤其是基于PMEM构建自己的高性能应用时,使用传统的文件系统写日志的接口会降低PMEM本身的日志写入速度,从而间接影响系统性能,这方面后文会有两者的性能对比测试。
所以基于PMEM的系统开发,日志也建议使用PMEM的日志库来完成日志信息的持久化。
2. libpmemlog 使用方式
社区提供了对linux和windows系统的不同使用方式,这里也会有一些基本的区别。
2.1 基本接口
pmemlog_create 在PMEM上创建一个pmempool,用于存储数据。
Pmempool 是pmdk操作PMEM空间的一种形态,需要先从PMEM上划分一定的存储空间pmempool,然后通过类似文件的接口写入/删除数据。
PMEMlogpool *pmemlog_create(const char *path, size_t poolsize, mode_t mode);包括 指定。pmempool 的存储路径,pool大小,访问权限 。
该接口底层还是会使用pmemobj 来进行创建:
PMEMlogpool * pmemlog_create(const char *path, size_t poolsize, mode_t mode) {return (PMEMlogpool *)pmemobj_create(path, LAYOUT_NAME,poolsize, mode); }pmemlog_open 打开pmempool,打开成功并返回pool文件句柄。
PMEMlogpool *pmemlog_open(const char *path);只需要指定打开的pool文件路径即可
底层仍然会使用pmemobj相关接口创建,能够保证创建过程的一致性和原子性。
PMEMlogpool * pmemlog_open(const char *path) {return (PMEMlogpool *)pmemobj_open(path, LAYOUT_NAME); }pmemlog_append 向打开的pmempool中写入数据,追加方式,类似write
int pmemlog_append(PMEMlogpool *plp, const void *buf, size_t count);指定写入的pool的 pmempool 对象 plp,要写入的数据buf, 以及写入大小count
当然写入的过程仍然是通过pmemobj相关的事务接口保证写入的原子性:
int pmemlog_append(PMEMlogpool *plp, const void *buf, size_t count) {PMEMobjpool *pop = (PMEMobjpool *)plp;PMEMoid baseoid = pmemobj_root(pop, sizeof(struct base));struct base *bp = pmemobj_direct(baseoid);/* set the return point */jmp_buf env;if (setjmp(env)) {/* end the transaction */(void) pmemobj_tx_end();return 1;}/* begin a transaction, also acquiring the write lock for the log */if (pmemobj_tx_begin(pop, env, TX_PARAM_RWLOCK, &bp->rwlock,TX_PARAM_NONE))return -1;/* allocate the new node to be inserted */PMEMoid log = pmemobj_tx_alloc(count + sizeof(struct log_hdr),LOG_TYPE);struct log *logp = pmemobj_direct(log);logp->hdr.size = count;memcpy(logp->data, buf, count);logp->hdr.next = OID_NULL;/* add the modified root object to the undo log */pmemobj_tx_add_range(baseoid, 0, sizeof(struct base));if (bp->tail.off == 0) {/* update head */bp->head = log;} else {/* add the modified tail entry to the undo log */pmemobj_tx_add_range(bp->tail, 0, sizeof(struct log));((struct log *)pmemobj_direct(bp->tail))->hdr.next = log;}bp->tail = log; /* update tail */bp->bytes_written += count;pmemobj_tx_commit();(void) pmemobj_tx_end();return 0; }pmemlog_walk 从pmempool中遍历写入的数据
void pmemlog_walk(PMEMlogpool *plp, size_t chunksize,int (*process_chunk)(const void *buf, size_t len, void *arg),void *arg);其中 plp是pmemlogpool的对象,通过process_chunk 回调函数 来访问plp中起始到结束的所有数据,访问粒度是chunksize(代码中好像没啥用,根本没有用到这个变量)。
需要注意的是pmemlog_walk函数为了保证访问的原子性,会在处理过程中会加读锁,这个时候不能在process_chunk中再次调用pmemlog_append写入数据,可能会出现死锁。
void pmemlog_walk(PMEMlogpool *plp, size_t chunksize,int (*process_chunk)(const void *buf, size_t len, void *arg), void *arg) {PMEMobjpool *pop = (PMEMobjpool *)plp;// 创建一个obj root对象,如果已经有了,就直接返回。// 用于后续对pool中数据的读取。struct base *bp = pmemobj_direct(pmemobj_root(pop,sizeof(struct base)));//加读锁, 加失败则返回,说明有其他进程在访问if (pmemobj_rwlock_rdlock(pop, &bp->rwlock) != 0)return;/* process all chunks */// 返回root对象的头指针,依次访问所有的数据// 因为之前数据的存放也是这样追加链表尾的方式写入的。struct log *next = pmemobj_direct(bp->head);while (next != NULL) {(*process_chunk)(next->data, next->hdr.size, arg);next = pmemobj_direct(next->hdr.next);}// 读取完毕,释放读锁pmemobj_rwlock_unlock(pop, &bp->rwlock); }pmemlog_rewind 清理pmemlogpool中的所有数据,事务方式清理
pmemlog_close 关闭pmempool 的对象
2.2 接口使用
如下代码,功能是 使用pmemlog相关接口 写入持久化数据,并打印出来。
#include <stdio.h>
#include <fcntl.h>
#include <errno.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <libpmemlog.h>/* size of the pmemlog pool -- 1 GB */
#define POOL_SIZE ((size_t)(1 << 30))/** printit -- log processing callback for use with pmemlog_walk()*/
int
printit(const void *buf, size_t len, void *arg)
{fwrite(buf, len, 1, stdout);return 0;
}int
main(int argc, char *argv[])
{const char path[] = "./pmem";PMEMlogpool *plp;size_t nbyte;char *str;/* create the pmemlog pool or open it if it already exists */plp = pmemlog_create(path, POOL_SIZE, 0666);if (plp == NULL)plp = pmemlog_open(path);if (plp == NULL) {perror(path);exit(1);}/* how many bytes does the log hold? */nbyte = pmemlog_nbyte(plp);printf("log holds %zu bytes\n", nbyte);/* append to the log... */str = "This is the first string appended\n";if (pmemlog_append(plp, str, strlen(str)) < 0) {perror("pmemlog_append");exit(1);}str = "This is the second string appended\n";if (pmemlog_append(plp, str, strlen(str)) < 0) {perror("pmemlog_append");exit(1);}/* print the log contents */printf("log contains:\n");pmemlog_walk(plp, 0, printit, NULL);pmemlog_close(plp);
}
编译:
g++ libpmemlog_walk.cc -o log_walk -lpmem -lpmemlog
输出如下:
$ ./log_walk
log holds 1073733632 bytes
log contains:
This is the first string appended
This is the second string appended
可以看到在当前PMEM 挂载的文件系统中有一个pmem pool的data 类型的文件,可以通过pmempool工具查看写入的内容:
$ ls -l pmem
-rw-rw-rw- 1 server server 1073741824 Jan 29 11:50 pmem
$ file pmem
pmem: data
$ pmempool dump pmem
00000000 54 68 69 73 20 69 73 20 74 68 65 20 66 69 72 73 |This is the firs|
00000010 74 20 73 74 72 69 6e 67 20 61 70 70 65 6e 64 65 |t string appende|
00000020 64 0a 54 68 69 73 20 69 73 20 74 68 65 20 73 65 |d.This is the se|
00000030 63 6f 6e 64 20 73 74 72 69 6e 67 20 61 70 70 65 |cond string appe|
00000040 6e 64 65 64 0a |nded. |
3. Libpmemlog 性能
文章前言有说过,当我们使用PMEM 硬件构建我们的存储系统时,日志记录方式的选择在PMEM上会一定程度得影响性能。使用传统的vfs的系统调用来写日志文件 和 pmdk提供的libpmemlog 性能之间有多少差异,这一些差异需要在使用前来验证,以便指导我们完成系统日志方案的选型评估。
3.1 write sys call 性能
如下测试代码,通过write 写入20*64M 大小的数据。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>#include <sys/time.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>#include <libpmemlog.h>#define POOL_SIZE ((uint64_t)(64 << 20))using namespace std;const uint64_t file_op = 20;
const uint64_t write_size=(4*1024*1024);
const uint64_t read_size=(1024*1024);
const uint64_t read_op=1000;static uint64_t get_now_micros(){struct timeval tv;gettimeofday(&tv, NULL);return (tv.tv_sec) * 1000000 + tv.tv_usec;
}int main(int argc, char *argv[]) {char *filename;// 文件名获取if (argc == 2) {filename = argv[1];printf("filename : %s \n", filename);} else {printf("args is not valid\n");return 1;}uint64_t ret,start_time,end_time,do_time,next_report_;void *buf;void *cp_buf;int buf_num=sizeof(char)*write_size;char namebuf[100];int fd;int i,j;bool error = false;buf=(void *)malloc(buf_num);cp_buf=(void *)malloc(buf_num);memset(buf,'1',buf_num); // 构建写入数据,单次写入大小为4M// 起始时间start_time=get_now_micros();next_report_=0;// 总共写入file_op 20次for (i = 0;i < file_op; i++) {snprintf(namebuf, sizeof(namebuf), "%s_vfs_%03d.log",filename, i);fd = open(namebuf, O_CREAT|O_RDWR|O_APPEND);if (fd == -1) {perror(namebuf);return 1;}// 每次写入4Mfor (j = 0;j < (POOL_SIZE / write_size); j++ ) {size_t x = write(fd, buf, write_size);if (x < 0) {printf("ret: %d, write failed! \n", x);error = true;break;}}// 保证数据落盘fsync(fd);if (error) {break;}close(fd);if (i >= next_report_) {if (next_report_ < 1000) next_report_ += 100;else if (next_report_ < 5000) next_report_ += 500;else if (next_report_ < 10000) next_report_ += 1000;else if (next_report_ < 50000) next_report_ += 5000;else if (next_report_ < 100000) next_report_ += 10000;else if (next_report_ < 500000) next_report_ += 50000;else next_report_ += 100000;fprintf(stderr, "... finished %d ops%30s\r", i, "");fflush(stderr);}}// 结束时间end_time=get_now_micros();do_time=end_time-start_time;printf("file_size:%ld MB file_op:%ld write_size:%ld K\n",POOL_SIZE/1048576,file_op,write_size/1024);printf("%11.3f micros/op %6.1f MB/s\n",(1.0*do_time)/(file_op*((POOL_SIZE/write_size))),(POOL_SIZE*file_op/1048576.0)/(do_time*1e-6));free(buf);free(cp_buf);return 0;
}
编译:g++ -std=c++11 vfs_log.cc -o vfs_log
运行性能如下:
$ ./vfs_log test
filename : test
file_size:64 MB file_op:20 write_size:4096 K8976.303 micros/op 445.6 MB/s
3.2 libpmemlog 性能
同样,写入20*64M的数据,变更相关文件系统接口为pmemlog接口如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>#include <sys/time.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>#include <libpmemlog.h>#define POOL_SIZE ((uint64_t)(64 << 20))using namespace std;const char filename[]="./pmem";
const uint64_t file_op = 20;
const uint64_t write_size=(4*1024*1024);
const uint64_t read_size=(1024*1024);
const uint64_t read_op=1000;static uint64_t get_now_micros(){struct timeval tv;gettimeofday(&tv, NULL);return (tv.tv_sec) * 1000000 + tv.tv_usec;
}int main(int argc, char **argv)
{uint64_t ret,start_time,end_time,do_time,next_report_;void *buf;void *cp_buf;int buf_num=sizeof(char)*write_size;buf=(void *)malloc(buf_num);cp_buf=(void *)malloc(buf_num);memset(buf,'1',buf_num);PMEMlogpool *plp;char namebuf[100];start_time=get_now_micros();next_report_=0;int i,j;bool error_flag=false;for(i=0;i<file_op;i++){snprintf(namebuf,sizeof(namebuf),"%sceshi%04d.pool",filename,i);plp = pmemlog_create(namebuf, POOL_SIZE, 0666);if (plp == NULL)plp = pmemlog_open(namebuf);if (plp == NULL) {perror(namebuf);return 1;}pmemlog_rewind(plp);for(j=0;j<(POOL_SIZE/write_size);j++){ret=pmemlog_append(plp, buf, write_size);if(ret<0){printf("ret:%ld append falid!\n",ret);error_flag = true;break;}}if(error_flag){break;}pmemlog_close(plp);if (i >= next_report_) {if (next_report_ < 1000) next_report_ += 100;else if (next_report_ < 5000) next_report_ += 500;else if (next_report_ < 10000) next_report_ += 1000;else if (next_report_ < 50000) next_report_ += 5000;else if (next_report_ < 100000) next_report_ += 10000;else if (next_report_ < 500000) next_report_ += 50000;else next_report_ += 100000;fprintf(stderr, "... finished %d ops%30s\r", i, "");fflush(stderr);}}end_time=get_now_micros();do_time=end_time-start_time;printf("file_size:%ld MB file_op:%ld write_size:%ld K\n",POOL_SIZE/1048576,file_op,write_size/1024);printf("%11.3f micros/op %6.1f MB/s\n",(1.0*do_time)/(file_op*((POOL_SIZE/write_size))),(POOL_SIZE*file_op/1048576.0)/(do_time*1e-6));free(buf);free(cp_buf);return 0;}
编译:
g++ libpmemlog_test.cc -o t2 -lpmemlog -lpmem -pthread
运行如下:
$ ./t2
file_size:64 MB file_op:20 write_size:4096 K4772.434 micros/op 838.1 MB/s
相比于vfs write的性能,延时上还是有很大的优势的(write需要走操作系统内核vfs接口)。
相关文章:
Java项目:家庭财务管理系统(java+Springboot+ssm+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 家庭财务管理系统,具有收入统计,支出统计,汇总报 表,工资录入,其他收入等录入开支信息,echart图标插 …

(原创)c++primer(第五版)--1.3 注释简介
注释可以帮助人类读者理解程序。注释通常用于概述算法,确定变量的用途,或者结束晦涩难懂的代码段。编译器会忽略注释,因此注释对程序的行为或者性能不会有任何影响。 虽然编辑器会忽略注释,但读者并不会。即使系统文档的其他部分已…
BZOJ 1503 郁闷的出纳员(splay)
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id1503 题意:给出一个数列(初始为空),给出一个最小值Min,当数列中的数字小于Min时自动删除。四种操作:(1)数列…
javascript ES6 新特性之 扩展运算符 三个点 ...
对于 ES6 新特性中的 ... 可以简单的理解为下面一句话就可以了: 对象中的扩展运算符(...)用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中。 作用类似于 Object.assign() 方法,我们先来看一下 Object.assign() 方法: Obje…
字符串匹配算法 -- BM(Boyer-Moore) 和 KMP(Knuth-Morris-Pratt)详细设计及实现
文章目录1. 算法背景2. BM(Boyer-Moore)算法2.1 坏字符规则(bad character rule)2.2 好后缀规则(good suffix shift)2.3 复杂度及完整代码3. KMP(Knuth Morris Pratt)算法3.1 好前缀 和 坏字符规则3.2 高效构建 失效函数3.3 复杂度…

Java项目:中小医院信息管理系统(java+Springboot+ssm+mysql+maven+jsp)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:实现了挂号收费,门诊管理,划价收 费,药房取药,体检管理,药房管理,系统维护等各个模块功能&a…
DB2load遇到SQL3508N错误
SQL3508N装入或装入查询期间,当存取类型为 "<文件类型>" 的文件或路径时出错。原因码:"<原因码>"。路径:"<路径/ 文件>"。 [more]解释: 装入或装入查询处理期间,在尝…
【cocos2d-x 手游研发小技巧(3)Android界面分辨率适配方案】
先感叹一下吧~~android的各种分辨率各种适配虐我千百遍,每次新项目我依旧待它如初恋 每家公司都有自己项目工程适配的方案,这种东西就是没有最好,只有最适合!!! 这次新项目专项针对android,目的…
git submodule 使用场景汇总
文章目录1. 前言2. 基础命令介绍2.1 场景一:已有仓库,添加一个子模块2.2 场景二:已有仓库,添加一个子模块的特定分支2.3 场景三:已有仓库,更新子模块内容2.4 场景四:已有仓库,变更子…
Java项目:在线商城系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 前台展示后台管理,包括最基本的用户登录注册,下单, 购物车,购买,结算,订单查询,…

自定义参数解析器,减少10%的代码
*** 赋值调用方法* 如果为空,默认调用name()方法* 该方法必须是一个不含参数的方法,否则将会调用失败* @return*/value() : value用于绑定请求参数和方法参数名一致时的对应关系。比如user?statusNo=1。方法的参数写法如下:getUser(@EnumParam(value=“statusNo”) int status) 或者 getUser(@EnumParam() int statusNo)valueMethod() : 赋值时调用枚举中的方法。

微服务全做错了!谷歌提出新方法,成本直接降9倍!
一位DataDog的客户收到6500万美元的云监控账单的消息,也再次让业界无数人惊到了。事实上有些团队在将集中式单体应用拆分为微服务时,首先进行的往往不是建立领域模型,而只是按照业务功能将原来单体应用的一个软件包拆分成多个所谓的“微服务”软件包,而这些“微服务”内的代码高度耦合,逻辑边界不清晰,长期以来,不管大厂还是小厂,微服务都被认为是云原生服务应用程序架构的事实标准,然而2023,不止那位37signals的DHH决心下云,放弃微服务,就连亚马逊和谷歌等这些云巨头,正在带头开始革了微服务的命。
简述nodejs、npm及其模块在windows下的安装与配置
nodejs的安装 登陆官网http://nodejs.org/,自行安装,不需配置环境变量,安装中自动配置了。 检测是否安装成功,使用cmd输入 node -v 即可查看。 npm的安装 如果是最新版nodejs其实不用装npm,它集成了npm,验证…
discuz,ecshop的伪静态规则(apache+nginx)
discuz(nginx): (备注:该规则也适用于二级目录) rewrite ^([^\.]*)/topic-(.)\.html$ $1/portal.php?modtopic&topic$2 last; rewrite ^([^\.]*)/article-([0-9])-([0-9])\.html$ $1/portal.php?modview&aid$2&page$3 last; rewrite ^([^\.]*)/forum-…
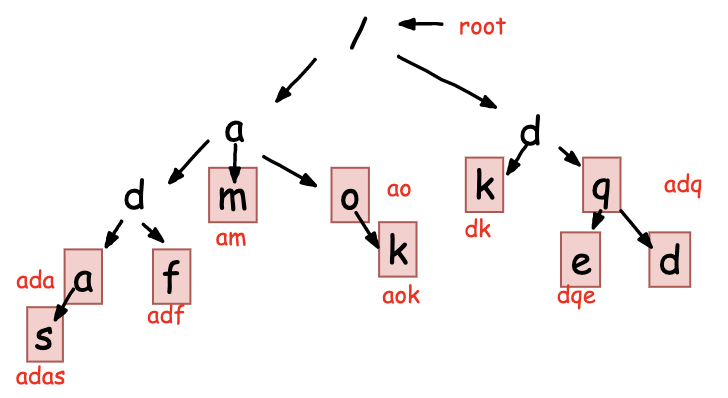
字符串匹配数据结构 --Trie树 高效实现搜索词提示 / IDE自动补全
文章目录1. 算法背景2. Trie 树实现原理2.1 Trie 树的构建2.2 Trie树的查找2.3 Trie树的遍历2.4 Trie树的时间/空间复杂度2.5 Trie 树 Vs 散列表/红黑树3. Trie树的应用 -- 搜索词提示功能1. 算法背景 之前我们了解过单模式串匹配的相关高效算法 – BM/KMP,虽难以理…
Java项目:成绩管理系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 超豪华成绩管理系统,学生,教师,管理员三类用户集 成,课程表管理,成绩查询,成绩详情数据统计…
NSThread 多线程相关
1.下面的代码,有2点需要注意,1>就是 就是thread:所传得参数,这里传得的是nsarray 当然也可以传其他的类型。2> [self performSelectorOnMainThread:selector(update) withObject:nil waitUntilDone:YES]; 这个函数的作用是通知主线程进…

Windows Phone 8初学者开发—第19部分:设置RecordAudio.xaml页面
原文地址: http://channel9.msdn.com/Series/Windows-Phone-8-Development-for-Absolute-Beginners/Part-19-Setting-up-the-RecordAudioxaml-Page 系列地址: http://channel9.msdn.com/Series/Windows-Phone-8-Development-for-Absolute-Beginners 源代码: http://aka.ms/abs…
9.path Sum III(路径和 III)
Level: Easy 题目描述: You are given a binary tree in which each node contains an integer value. Find the number of paths that sum to a given value. The path does not need to start or end at the root or a leaf, but it must go downwards…
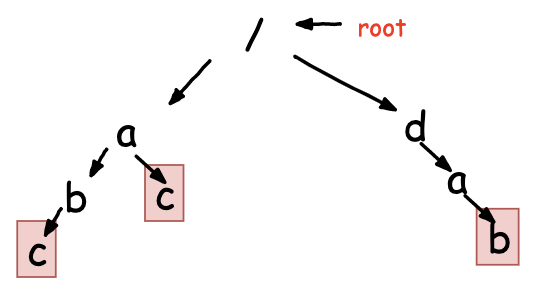
字符串匹配算法 -- AC自动机 基于Trie树的高效的敏感词过滤算法
文章目录1. 算法背景2. AC自动机实现原理2.1 构建失败指针2.2 依赖失败指针过滤敏感词3. 复杂度及完整代码1. 算法背景 之前介绍过单模式串匹配的高效算法:BM和KMP 以及 基于多模式串的匹配数据结构Trie树。 1. BM和KMP 单模式串匹配算法细节 2. Trie树 多模式串的高效匹配数…
Java项目:仿小米商城系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括: 基于vue Springboot前后端分离项目精简版仿小米商城 系统,注册登录,首页展示,商品展示,商品购买,下单…
vb socket的使用
说明:原本在 csdn 博客 写博客的,因为使用的移动宽带,csdn的 博客无法访问,所以先暂时到博客园写博客了 有能解决移动宽带 有部分网站不能访问的问题,请联系我,QQ 809775607 /***************************/ 下面写wins…
不吹牛会死!国内音乐平台进入“大逃杀”
日前,一篇《看看海洋与腾讯音乐将如何“血洗”独立音乐应用》的文章引起了广泛关注。文中海洋声称长期独家签约的音乐及版权代理公司达40多家,占市场份额超过15%,一时间名不见经传的海洋音乐仿佛成了一匹跃然网上的“黑马”。然而据音乐圈深喉…
leetcode网学习笔记(1)
https://leetcode-cn.com/problems/reverse-linked-list/submissions/ 206 反转链表 错误原因:没有考虑到链表为空以及链表只有一个元素的情况 https://leetcode-cn.com/problems/swap-nodes-in-pairs/comments/ 24 两两交换链表 原方法:使用4个指针遍历…
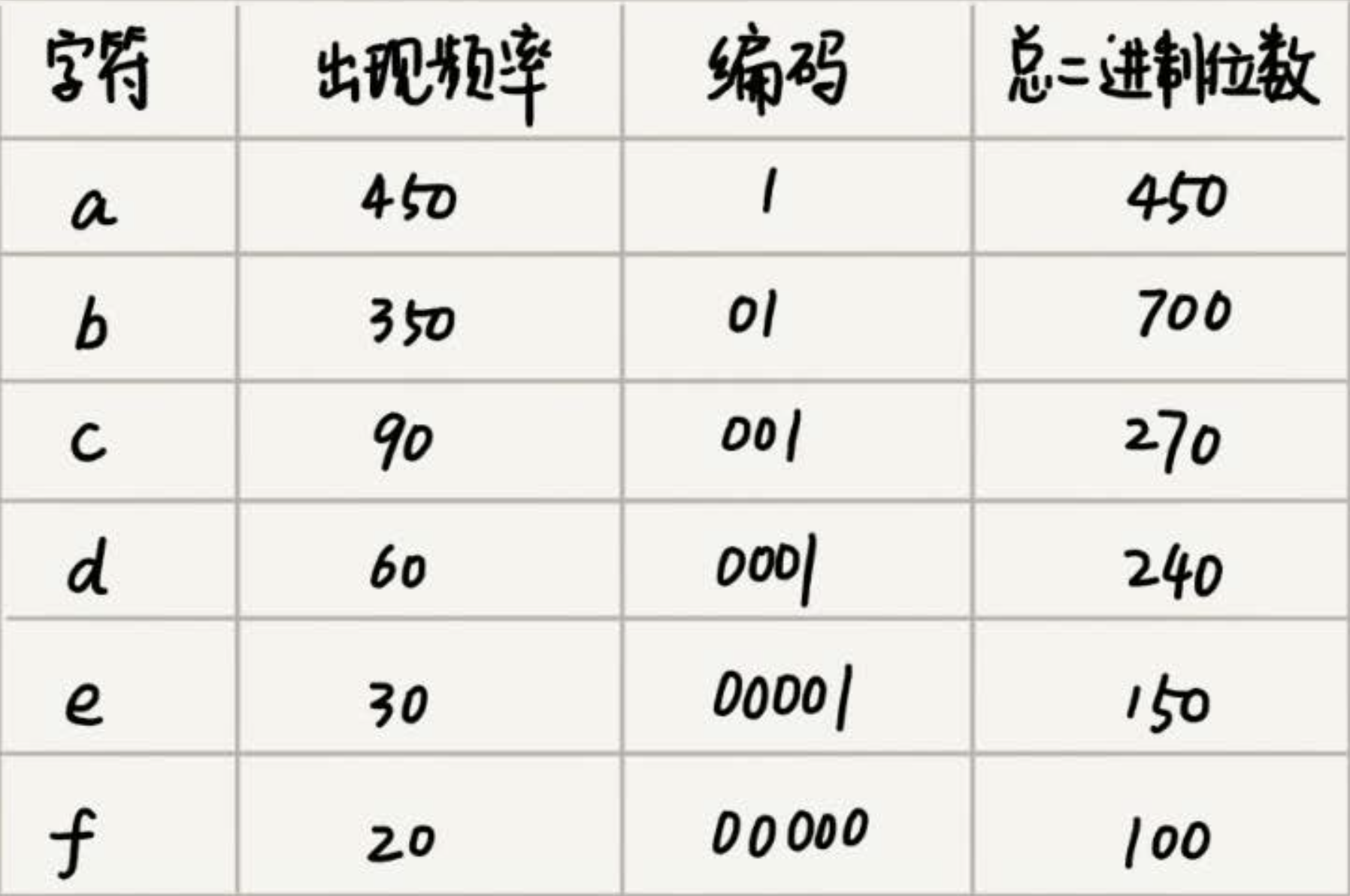
贪心算法简单实践 -- 分糖果、钱币找零、最多区间覆盖、哈夫曼编解码
1. 贪心算法概览 贪心算法是一种算法思想。希望能够满足限制的情况下将期望值最大化。比如:Huffman编码,Dijkstra单源最短路径问题,Kruskal最小生成树 等问题都希望满足限制的情况下用最少的代价找到解决问题的办法。 这个办法就是贪心算法…

Java项目:个人博客系统(前后端分离+java+vue+Springboot+ssm+mysql+maven+redis)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统功能包括:文章展示、热门文章、文章分类、标签云用户登录评论、匿名评论用户留言、匿名留言评论管理、文章发布、文章管理文章数据统计等等. 二、项目运行 环境…

第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器
第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器 原文:第十九章——使用资源调控器管理资源(2)——使用T-SQL配置资源调控器 前言:在前一章已经演示了如何使用SSMS来配置资源调控器。但是作为DBA&a…

Android_开源框架_Volley实例
2019独角兽企业重金招聘Python工程师标准>>> 1.自定义相关类在 Android_开源框架_Volley(Google IO 2013)源代码及内部实现过程分析一文中,简单概述了Volley框架内部实现过程。如想理解彻底应该熟悉 android多线程通信机制( Android_Thread多线程_Handle…
maven的配置-2019-4-13
一.Maven的优点 1. 依赖管理 jar 包管理 2.一键构建 (编译-----测试------打包-----安装-----部署 ) 什么是项目构建? 指的是项目从编译-----测试------打包-----安装-----部署 整个过程都交给maven进行管理,这个过程称为构建 一…
WiredTiger引擎编译 及 LT_PREREQ(2.2.6)问题解决
近期需要为异构引擎做准备, wiredtiger 以其优异的性能(B-tree和LSM-tree都支持)和稳定性(Mongodb的默认存储引擎) 被我们备选为异构引擎里的一个子引擎,后续将深入wiredtiger 引擎原理。这里简单记录一下Wiredtiger 存储引擎的编译记录。 Environment …