C++:stack、queue、priority_queue增删查改模拟实现、deque底层原理
C++:stack、queue、priority_queue增删查改模拟实现
前言
一、C++stack的介绍和使用
1.1 引言
我们先来看看
stack的相关接口有哪些:

从栈的接口,我们可以知道栈的接口是一种特殊的vector,所以我们完全可以使用vector来模拟实现stack。
1.2 satck模拟实现
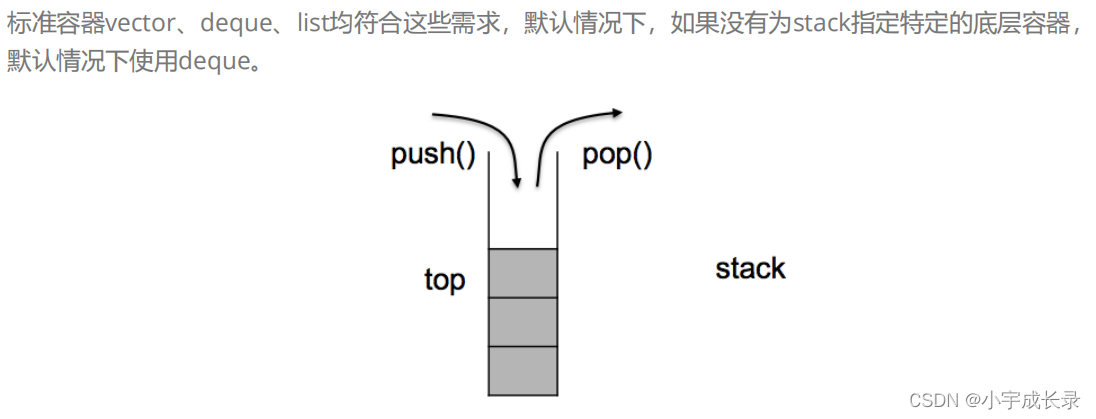
因此我们可以将底层容器定义成模板,然后将容器类变量作为成员变量进行封装。在实现satck的各种接口时,通过成员变量来调用底层容器的接口。(这就是容器适配器,将容器作为底层复用)
namespace achieveStack
{
//对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,
template<class T, class Container = deque<T>>//底层容器可以是: vector、list、deque(后续会说明)
class stack
{
public:
void push(const T& x)
{
//调用容器_con的尾插
_con.push_back(x);
}
void pop()
{
//调用容器_con的头删
_con.pop_back();
}
const T& top()
{
//调用容器_con的接口back
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
二、C++queue的介绍和使用
2.1 引言
同样,我们下来看看queue的接口究竟有哪些:

2.2 queue增删查改模拟实现
因为queue的接口中存在头删和尾插,因此使用vector来封装效率太低,故可以借助list来模拟实现queue。和stack一样,queue默认底层容器为deque(后续会介绍),此外还可以用list。
具体如下:

namespace achieveQueue
{
template<class T, class Container = deque<T>>
class queue
{
public:
void push(const T& x)//尾插
{
_con.push_back(x);
}
void pop()//头删
{
_con.pop_front();
}
const T& front()//首元素
{
return _con.front();
}
const T& back()//尾元素
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
三、STL标准库中stack和queue的底层结构:deque
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配
器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque,比如:

3.1 deque的简单介绍(了解)
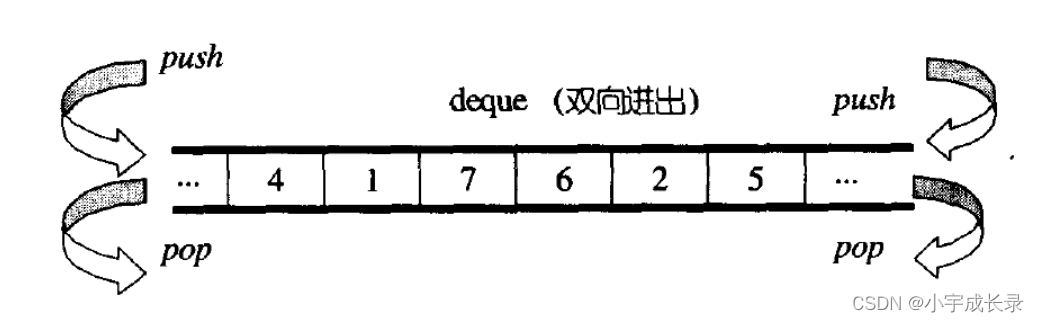
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
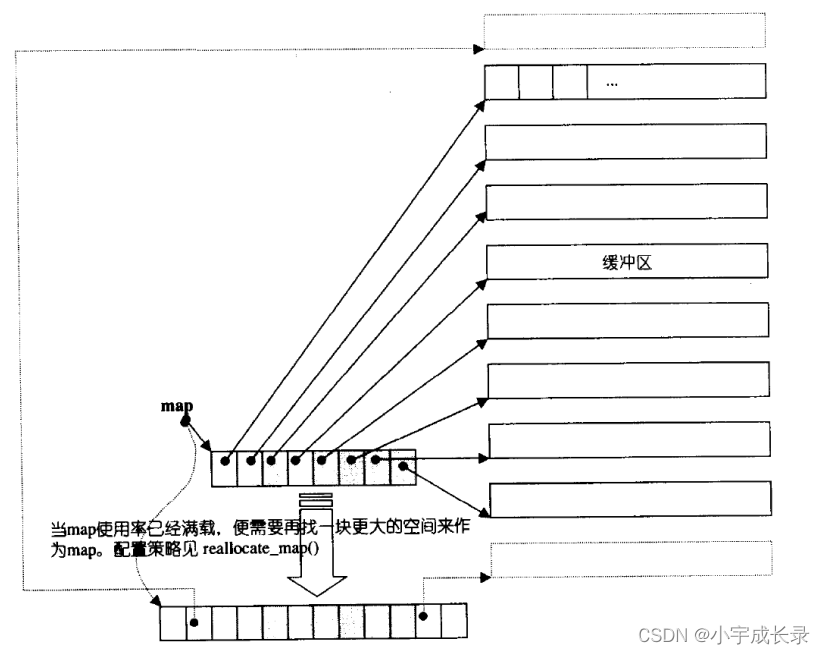
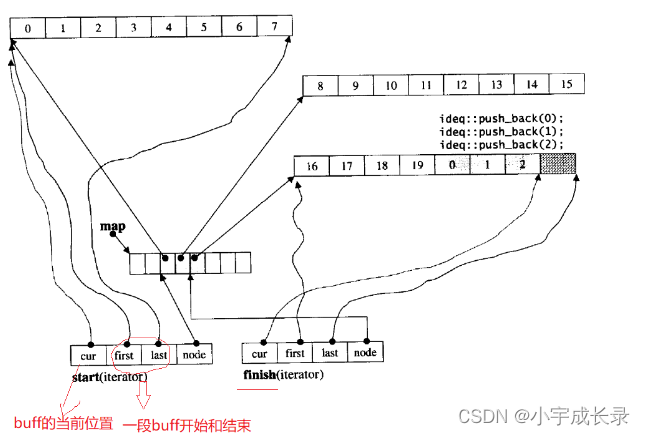
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
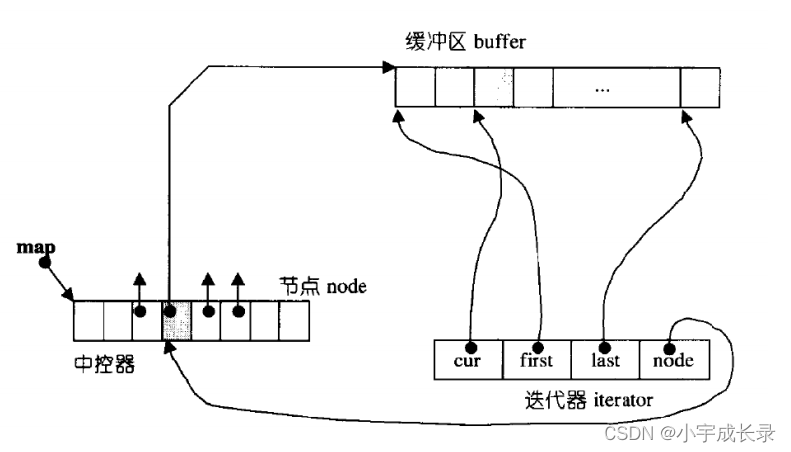
那deque是如何借助其迭代器维护其假想连续的结构呢?具体如下:
3.2 deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
3.3 为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可
以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有
push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和
queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长
时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷。
四、priority_queue的介绍和实现
4.1 priority_queue的介绍
和前面一样,我们先来看看priority_queue的接口。
priority_queue(优先级队列)默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意:默认情况下priority_queue是大堆(如需修改为小堆,可以将传入的默认仿函数less改为greater)。

4.1 priority_queue的介绍增删查改模拟实现
接下来如向下调整、向上调整等都是堆的知识,不懂的参考:【数据结构入门指南】二叉树顺序结构: 堆及实现(全程配图,非常经典)
前言
由于优先队列是一种容器适配器,所以我们可以使用模板将容器作为其成员变量,根据实际传入的容器生成实例化出具体版本。同时我们不仅要实现小堆还有大队,所以我们可以增加一个比较函数的模板参数,根据传入的函数来决定是大队还是小堆。
大致如下:
namespace achievePriority_queue//命名空间
{
template<class T, class Container=vector<T>,class Compare = less<T>>
class priority_queue
{
public:
priority_queue()//默认构造
{}
private:
Compare com;
Container _con;
};
}
4.1.1 push()
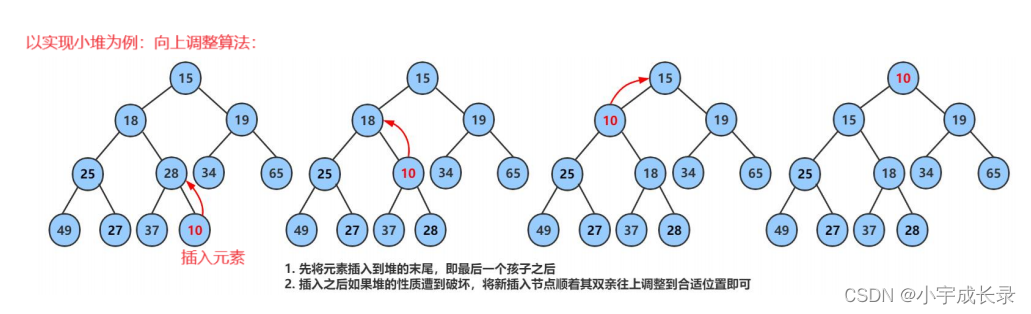
【分析】:我们可以先尾插数据,由于priority_queue的数据是一个堆结构,还需要将数据调整到合适位置。而插入的数据影响的只是当前元素到祖先之间父子节点关系,所以我们可以采用向上调整算法。
【例子】:
【代码如下】:
//向上调整
void adjust_up(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);//调用_con对于容器尾插接口
adjust_up(_con.size() - 1);//向上调整
}
4.1.2 pop()
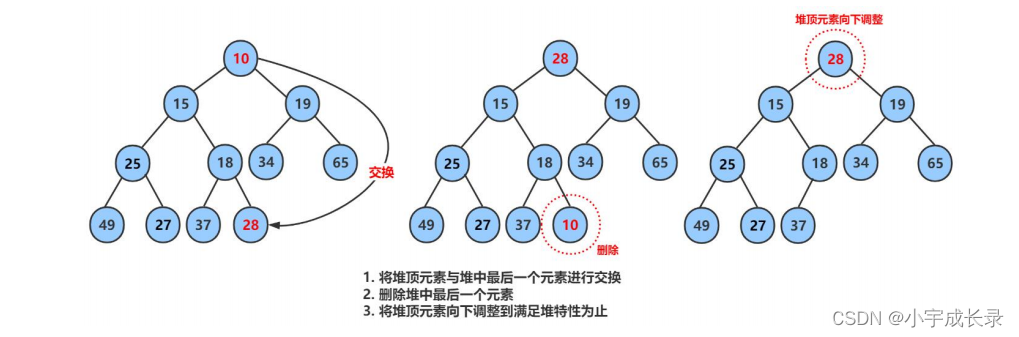
【分析】:删除元素,即删除堆顶元素。我们可以先将堆顶元素和堆尾元素交换,在将堆尾元素删除(这样可以防止大量挪动数据)。但交换后的元素还需要调整到合适位置,即采用向下调整算法。
【例子】:
【代码如下】:
void adjust_down(int parent)//向下调整算法
{
int child = 2 * parent + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
child++;
}
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);//堆顶和堆尾元素交换
_con.pop_back();//调用_con对于容器的尾删接口
adjust_down(0);//向下调整算法
}
4.3 top()、size()、empty()
这些接口比较简单就不一一介绍了,具体代码如下:
const T& top()
{
return _con[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
4.1 priority_queue(优先级队列)增删查改模拟实现
五、所有代码
相关文章:

软件开发生命周期的四种模型
螺旋模型和编写边改模型有点类似,螺旋模型从刚开始就定义了重要功能,相当于有主线任务,按照主线任务去开发,但是编写边改模型开始时只有粗略的想法,然后才逐步去完善。所以可以依据开始条件的不同选择不同的模型,有主线任务的就选螺旋模型,没有主线任务的就选编写边改模型。螺旋模型、编写边改模型和瀑布模型的区别在于,瀑布模型迭代不够快,每个环节开始时必须等待上一个环节完全结束,最后才进行整体测试,效率比较低。而螺旋模型和边写边改模型在研发的各个阶段都会进行测试,迭代速度更快。

基于虚拟机ubuntu的linux和shell脚本的学习,以及SSH远程登陆实战
是一款操作系统,跟windows,macos一样,有下面的特点简单和高效,一切皆文件,所有配置都通过修改文件解决,不需要繁琐的权限和设置权限高,把所有细节都交给用户,可完全自定义安全,所有程序只有自己执行才会启动。

thinkphp操作mongo数据的三种方法
'hostname' => '10.10.10.10', // MongoDB服务器地址。'hostport' => 2017, // MongoDB服务器端口。'database' => 'chatname', // 数据库名称。后面接着就可以任意使用Connection各类方法。后面接着就可以任意使用Collection各类方法。使用MongoDB PHP驱动程序,方法三。后面接着就可以任意使用db下的增删改查。使用tp中的db类,方法二。使用tp中的扩展,方法一。
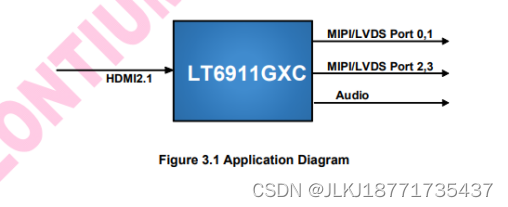
HDMI2.1输入转4Port MIPI/LVDS输出,嵌入式SPI闪存固件存储,VR和AR应用首选国产芯片方案-LT6911GXC
HDMI2.1输入转4Port MIPI/LVDS输出,嵌入式SPI闪存固件存储,VR和AR应用首选方案
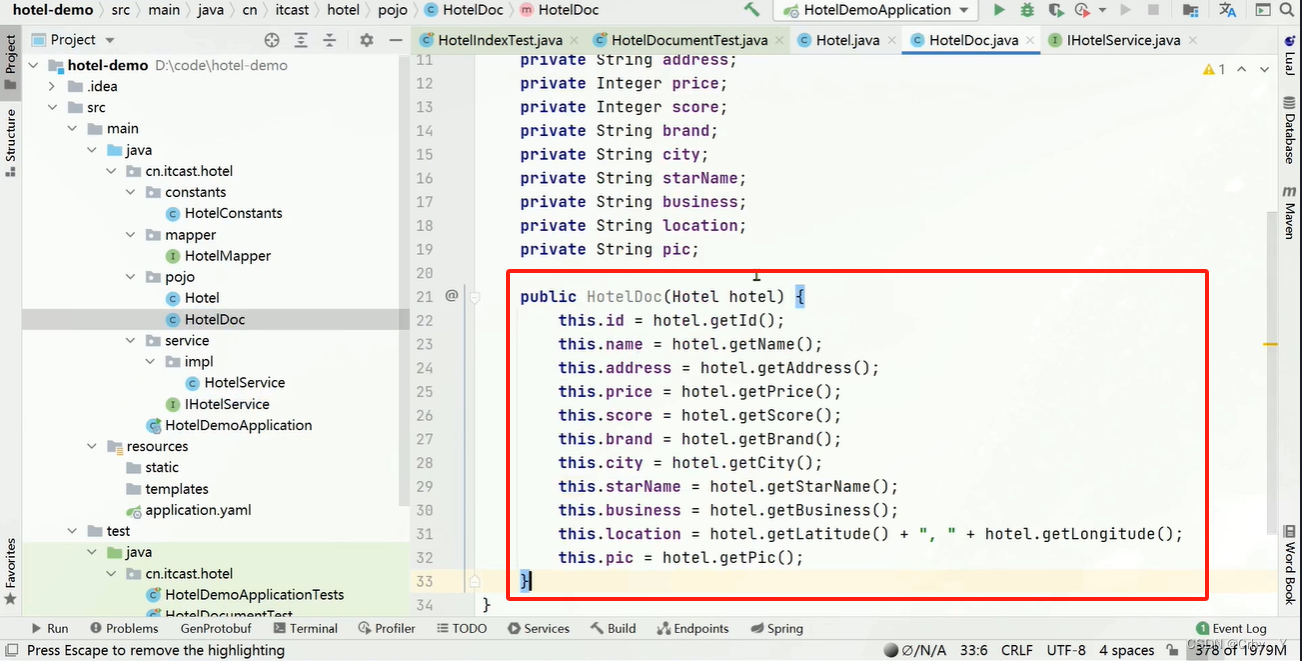
java中如何使用elasticsearch—RestClient操作文档(CRUD)
去数据库查询酒店数据,导入到hotel索引库,实现酒店数据的CRUD基本步骤如下。新建一个测试类,实现文档相关操作,并且完成JavaRestClient的初始化。方式一(全量更新):再次写入id一样的文档,就会删除旧文档,添加新文档。根据id查询到的文档数据是json,需要反序列化为java对象。(2)根据id查询数据库数据,并转换。方式二(局部更新):只更新部分字段。(1)创建文档对应实体。修改文档数据有两种方式。
获得JD商品评论 API 如何实现实时数据获取
随着互联网的快速发展,电商平台如雨后春笋般涌现,其中京东(JD)作为中国最大的自营式电商平台之一,拥有庞大的用户群体和丰富的商品资源。为了更好地了解用户对商品的反馈,京东开放了商品评论的API接口,允许开发者实时获取商品评论数据。本文将介绍如何通过JD商品评论API实现实时数据获取,并给出相应的代码示例。JD商品评论API提供了一系列的接口,允许开发者根据需要获取不同维度的评论数据。通过该API,开发者可以获取到商品的详细评论信息、评论的统计数据以及用户的评论行为数据等。

树莓派(linux)使用Motion动作捕捉或实时获取视频
在浏览器输入ip:8081,查看第1个摄像头视频,如果有多个摄像头,访问不同端口号即可,如ip:8082,ip:8083。已知的,最大可以支持3个。修改/etc/motion/motion.conf,如下图所示,去掉cameraX前的注释,即启用该摄像头配置,motion会自动读取配置文件,启动多个摄像头。stream_maxrate 70 #默认为1,图像会比较卡,将这个参数设置为 100 或者小点的(可以自行观察后配置),之后发现视频流非常流畅树莓派(linux)使用Motion动作捕捉或实时获取视频

基于huffman编解码的图像压缩算法matlab仿真
Huffman编码是一种用于无损数据压缩的熵编码算法。由David A. Huffman在1952年提出。该算法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码。

nginx下载安装 | mac | 前端项目在nginx上运行
大家好,我是星恒,今天给大家带来的是nginx的安装配置,以及如何在nginx运行前端项目的教程,话不多说,我们直接开始。
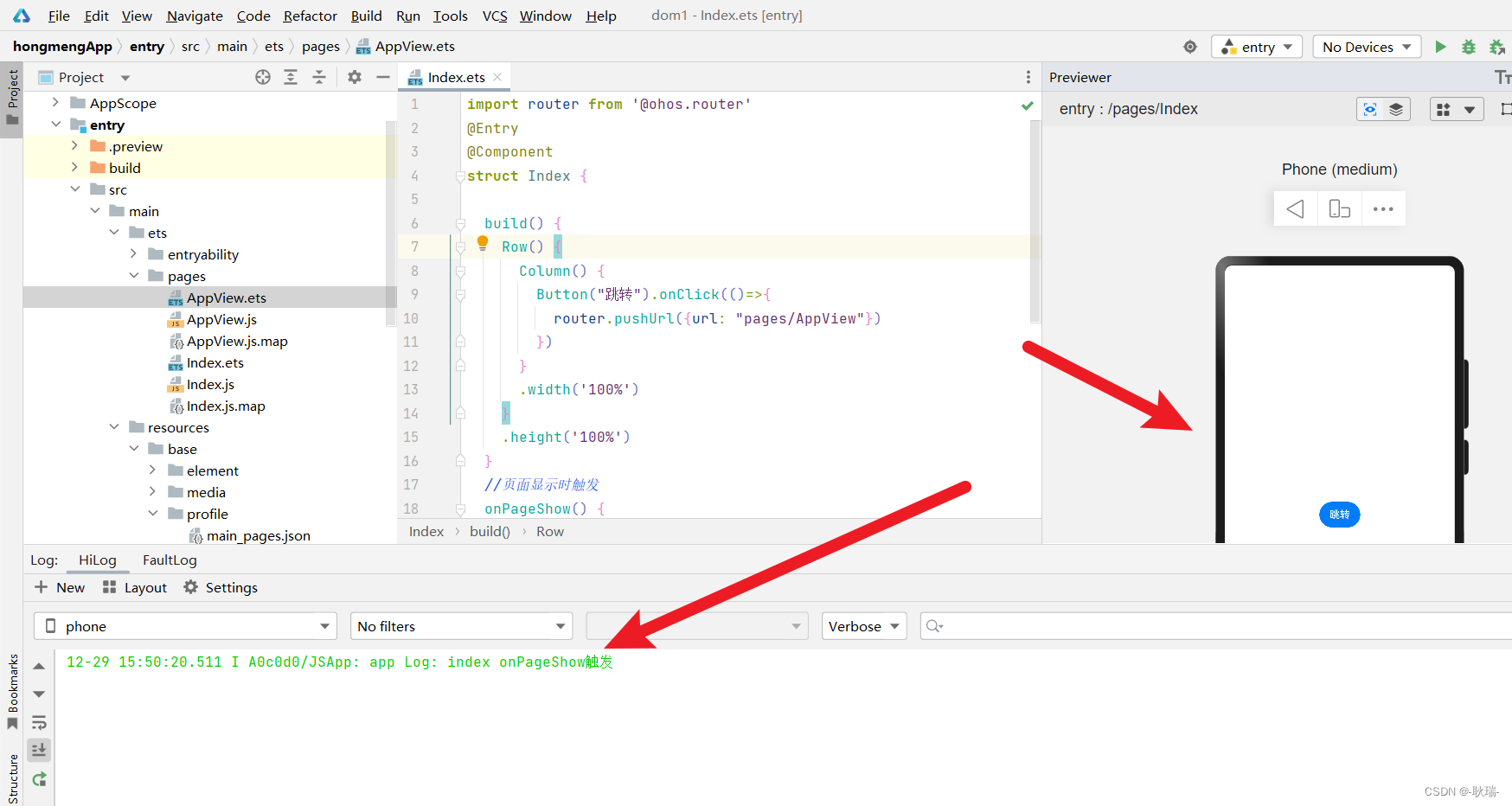
HarmonyOS page生命周期函数讲解
因为已经跳转 index 组件隐藏 onPageHide 触发 然后 AppView 页面显示 onPageShow触发。然后 我们打开预览器 运行index组件 然后 index 组件 被显示 onPageShow生命周期随之触发。然后 设置了一个button按钮 点击跳转向 pages/AppView页面。这个函数是页面返回时 触发 这里所说的返回不是说 router.back。调回 index界面 AppView被隐藏 触发onPageHide。

C语言字符串处理提取时间(ffmpeg返回的时间字符串)
讲解字符串数据提取案例。

应对服务器CPU占用持续性变高的解决办法
在服务器的使用过程中,高CPU使用率是一个常见的问题,一般是由于遇到大量流量,进程需要更多时间来执行或通过网络发送和接收大量网络数据包时,CPU使用率可能会急剧增加,严重时可能会影响到网络的性能和稳定性。通过任务管理器识别资源密集型进程中哪些资源占用过多,哪些是不必要运行的应用程序,再停止不必要进程,考虑优化一些进程,比如采取优化数据库访问方式,缓存数据等操作,以减少 CPU 负担。另外,如果网络设备持续遇到高 CPU 使用率,请考虑升级到更强大的硬件,以更好地处理网络负载。5.虚拟化技术问题。

智慧工地解决方案,智慧工地项目管理系统源码,支持大屏端、PC端、手机端、平板端
智慧工地解决方案依托计算机技术、物联网、云计算、大数据、人工智能、VR&AR等技术相结合,为工程项目管理提供先进技术手段,构建工地现场智能监控和控制体系,弥补传统方法在监管中的缺陷,最线实现项目对人、机、料、法、环的全方位实时监控。内部的视频监控综合管理平台,包括数据库服务模块、管理服务模块、接入服务模块、报警服务模块、流媒体服务模块、存储管理服务模块、Web 服务模块等。是执行日常监控、系统管理、应急指挥的场所,集形象展示,监控指挥,视频监控显示、工地大脑展示为一体。通过访问web端,自定义题库内容。
抓包工具Charles安装及使用
Charles 是在 Mac 下常用的网络封包截取工具,在做 移动开发时,我们为了调试与服务器端的网络通讯协议,常常需要截取网络封包来分析。Charles 通过将自己设置成系统的网络访问代理服务器,使得所有的网络访问请求都通过它来完成,从而实现了网络封包的截取和分析。截取 Http 和 Https 网络封包。支持重发网络请求,方便后端调试。支持修改网络请求参数。支持网络请求的截获并动态修改。支持模拟慢速网络。。
web安全,常见的攻击以及如何防御
XSS即Cross Site Scripting(跨站脚本攻击),攻击者通过各种方式将恶意代码注入到用户的页面中,这样就可以通过脚本进行一些操作。以后,基本就杜绝了 CSRF 攻击。当然,前提是用户浏览器支持 SameSite 属性。(1)为了防止这种攻击,表单一般都带有一个随机 token,告诉服务器这是真实请求。CSRF即Cross-site request forgery(跨站请求伪造)
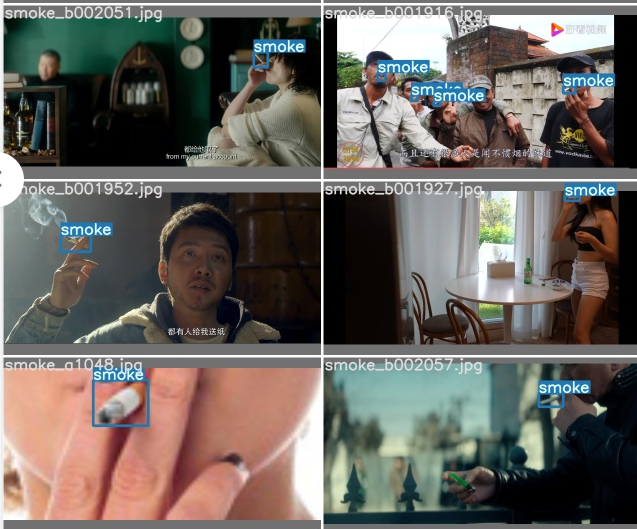
大创项目推荐 深度学习YOLO抽烟行为检测 - python opencv
🔥 优质竞赛项目系列,今天要分享的是🚩基于深度学习YOLO抽烟行为检测该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!🥇学长这里给一个题目综合评分(每项满分5分)难度系数:3分工作量:3分创新点:4分🧿YOLO系列是基于深度学习的回归方法。该系列陆续诞生出YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5。YOLOv5算法,它是一种单阶段目标检测的算法,该算法可以根据落地要求灵活地通过chaneel和layer的控制因子来配置和调节模型,所以在比赛和落地中应用比较多。

Vue开发中使用Element UI过程中遇到的问题及解决方案Missing required prop: “value”
通过给 type=index 的列传入 index 属性,可以自定义索引。该属性传入数字时,将作为索引的起始值。也可以传入一个方法,它提供当前行的行号(从 0 开始)作为参数,返回值将作为索引展示。methods: {
单例模式的双重检查锁定是什么?
单例模式是一种常见的设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。双重检查锁定(Double-Checked Locking)是一种在单例模式中使用的性能优化技术。在传统的单例模式实现中,我们通常通过将构造函数设为私有,再提供一个静态方法来返回类的唯一实例。而双重检查锁定则是在这个基础上增加了线程安全的考虑,避免在多线程环境下出现性能问题和错误结果。双重检查锁定的基本思想是在获取单例对象时进行双重检查,即先检查实例是否已经创建,如果尚未创建,再进行同步操作来确保只有一个线程创建实例。
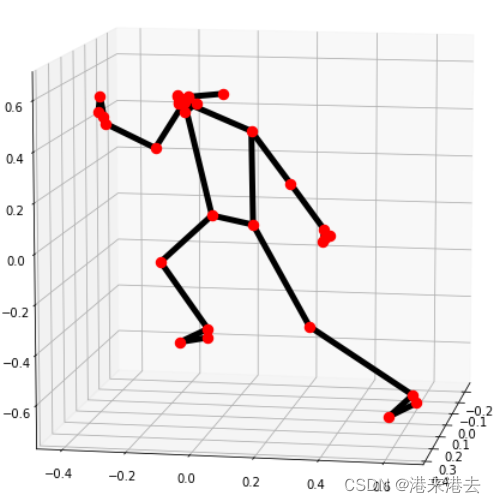
Mediapipe绘制实时3d铰接骨架图——Mediapipe实时姿态估计
使用Mediapipe绘制实时3d骨架铰接图;使用Mediapipe、matplotlib进行3d姿态估计、绘制实时3d坐标

共享办公兴起背后:创新引擎或风口浪尖?
这些用户的需求和偏好也各不相同,有的需要灵活的租期和价格,有的需要专业的服务和支持,有的需要丰富的社交和活动,有的需要私密的空间和安全。共享办公的困境,还因为共享办公的市场空间和增长潜力有限,由于共享办公的核心资源是办公场地,而办公场地的供给受到土地、房产、政策等因素的制约,难以大规模扩张。共享办公的困境,其次是共享办公的用户体验和服务质量难以保证,由于共享办公空间的使用者多为中小企业和自由职业者,他们的需求和偏好各不相同,而共享办公空间往往缺乏个性化、智能化、便捷化的服务,难以满足用户的多元化需求。

基于神经网络——鸢尾花识别(Iris)
鸢尾花识别是学习AI入门的案例,这里和大家分享下使用Tensorflow2框架,编写程序,获取鸢尾花数据,搭建神经网络,最后训练和识别鸢尾花。

科普:什么是“东数西算”?
数”指数据,“算”是算力,即对数据的处理能力,“东数西算”是通过构建数据中心、云计算、大数据一体化的新型算力网络体系,将东部算力需求有序引导到西部,优化数据中心建设布局,促进东西部协同联动。简单说就是把东边产生的数据拿到西边来储存,在西边进行数据分析和计算,然后再把结果传到东边。那“东数”为什么要“西算”呢?1.数据的储存和计算是需要大量的设备的,这东西就会占用大量的地,众所周知,东边经济发展的块,这占地成本很高,因此把储存和计算中心放到西部,可以降低成本,增加西部的就业和发展。
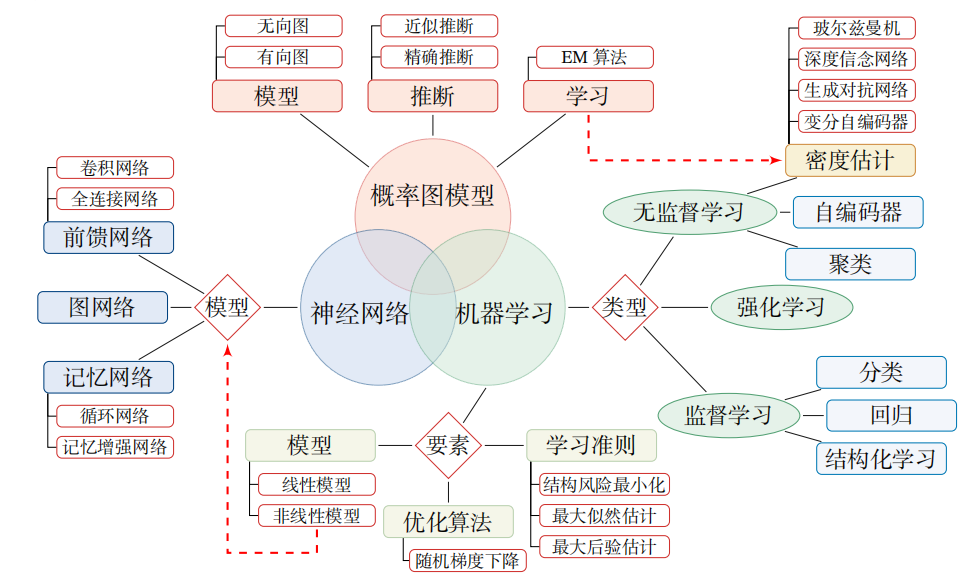
深度学习知识点全面总结
深度学习定义:一般是指通过训练多层网络结构对未知数据进行分类或回归深度学习分类:有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等; 无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。神经网络的计算主要有两种:前向传播(foward propagation, FP)作用于每一层的输入,通过逐层计算得到输出结果;

ios环境搭建_xcode安装及运行源码
Xcode 是运行在操作系统Mac OS X上的集成开发工具(IDE),由Apple Inc开发。Xcode是开发 macOS 和 iOS 应用程序的最快捷的方式。Xcode 具有统一的用户界面设计,编码、测试、调试都在一个简单的窗口内完成。

车载工业路由器:连接智能化未来的关键
其次是强大的数据处理能力,车载工业路由器具备高性能的处理器和大容量的内存,能够对海量数据进行快速处理和存储。此外,车载工业路由器还支持多种通信协议,如Wi-Fi、蓝牙、RS232等,实现与车载设备的互联互通。同时,车载工业路由器具备丰富的安全防护功能,能够抵御网络攻击、保护车辆数据的安全。另一方面,随着5G网络的普及,车载工业路由器将能够提供更快速、更稳定的网络连接,满足用户对高速互联的需求。在智能交通领域,计讯物联车载工业路由器可以实现车辆之间、车辆与交通设施之间的高效通信,提升交通运输的智能化水平。

Flutter配置Android和IOS允许http访问
Android和IOS允许http访问
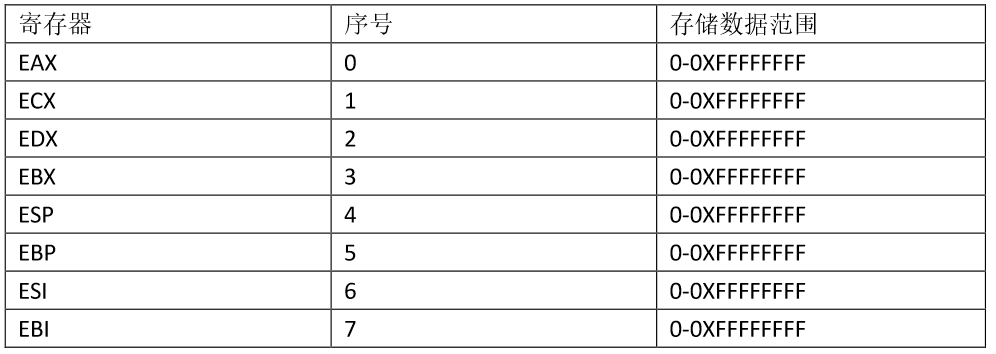
【汇编笔记】初识汇编-内存读写
CPU是计算机的核心,由于计算机只认识二进制,所以CPU执行的指令是二进制。我们要想让CPU工作,就得给他提供它认识的指令,这一系列的指令的集合,称之为指令集。指令集:不同的体系的CPU使用的是不同的指令集,常见的有intel、AMD的X86结构CPU使用的是X86/X64指令集,ARM结构CPU使用的是ARM指令集。汇编指令和机器指令的差别在于指令的表示方法上,汇编指令与机器指令是一一对应的。

数字时代跨境电商营销大变革:海外网红营销的力量与影响
随着全球化的推进和数字技术的不断发展,跨境电商行业迎来了一场营销变革的浪潮。在这个过程中,一种新的营销方式崭露头角——海外网红营销。海外网红以其独特的个人魅力和影响力,成为跨境电商推广的重要力量,为品牌打开了新的市场,改变了传统的营销模式。

使用 Django 的异步特性提升 I/O 类操作的性能
通过使用 Django 的异步特性,可以显著提高 I/O 类操作的性能。通过使用异步 ORM、异步中间件和异步视图等特性,以及协程和缓存等手段,可以帮助开发人员构建高性能的 Web 应用程序。在使用异步特性时,需要注意代码的可读性和可维护性,以及正确处理并发和异常情况。同时,也需要了解目标硬件和网络环境的限制和瓶颈,以便更好地优化应用程序的性能。