基于神经网络——鸢尾花识别(Iris)
前言
鸢尾花识别是学习AI入门的案例,这里和大家分享下使用Tensorflow2框架,编写程序,获取鸢尾花数据,搭建神经网络,最后训练和识别鸢尾花。
鸢尾花识别——思路流程:
1)获取鸢尾花数据,分析处理。
2)整理数据位训练集,测试集。
3)搭建神经网络模型。
4)训练网络,优化网络模型参数。
5)保存最优的模型,进行鸢尾花识别。
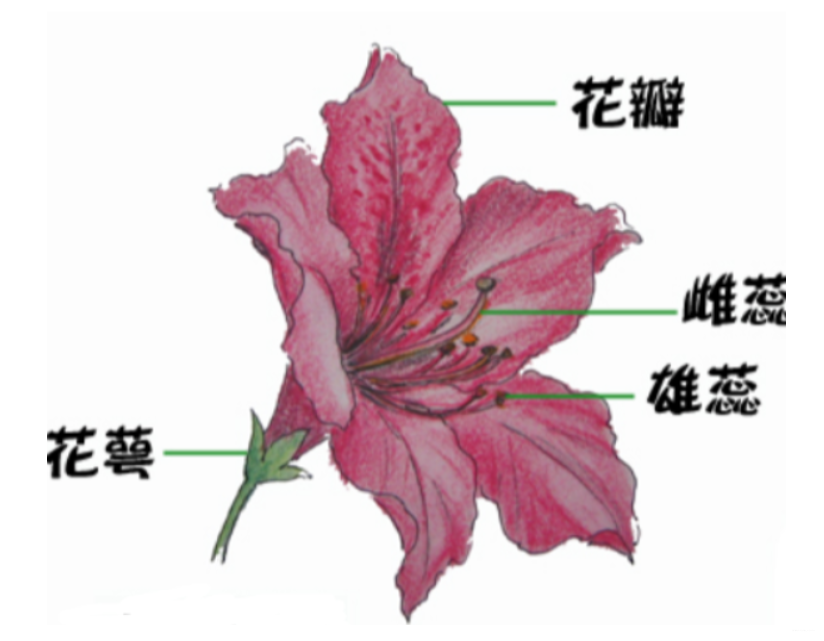
认识鸢尾花
我们先认识下什么是鸢尾花?
鸢尾花分类:狗尾草鸢尾、杂色鸢尾、弗吉尼亚鸢尾

鸢尾花的特征是什么呢?
鸢尾花花萼长、花萼宽、花瓣长、花瓣宽。我们通过对数据进行分析总结出了规律:通过测量花的花萼长、花萼宽、花瓣长、花瓣宽,可以得出鸢尾花的类别(如:花萼长>花萼宽且花瓣长/花瓣宽>2 ,则杂色鸢尾)
获取鸢尾花数据
4 个属性作为输入特征:花萼长、花萼宽、花瓣长、花瓣宽 ;
类别作为标签,0 代表狗尾草鸢尾,1 代表杂色鸢尾,2 代表弗吉尼亚鸢尾。
iris数据集 即鸢尾花数据。x_data 存放 iris数据集所有输入特征(4 种);y_data存放 iris数据集所有标签(3种)
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data = datasets.load_iris().data # .data返回iris数据集所有输入特征
y_data = datasets.load_iris().target # .target返回iris数据集所有标签
print("x_data from datasets: \n", x_data)
print("y_data from datasets: \n", y_data)
x_data = DataFrame(x_data, columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']) # 为表格增加行索引(左侧)和列标签(上方)
pd.set_option('display.unicode.east_asian_width', True) # 设置列名对齐
print("x_data add index: \n", x_data)
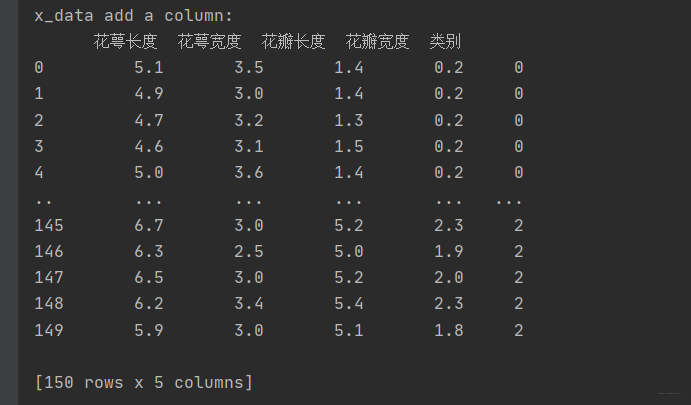
x_data['类别'] = y_data # 新加一列,列标签为‘类别’,数据为y_data
print("x_data add a column: \n", x_data)
在sklearn库中,x_data,y_data的原始数据:

在x_data[ ]数据中,新加一列,列标签为‘类别’,数据为y_data:
整理数据为训练集,测试集
把输入特征 和 标签 做成数据对,即每一行输入特征有与之对应的类别;得出一共150行数据;其中75%作为训练集,即120行;25%作为测试集,即后30行。
注意:训练集和测试集,没有交集,它们之间都没有一样的数据。
# 导入所需模块
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
# 导入数据,分别为输入特征和标签
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率)
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样(为方便教学,以保每位同学结果一致)
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
# 将打乱后的数据集分割为训练集和测试集,训练集为前120行,测试集为后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# from_tensor_slices函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
为了训练更高效,通常会把数据变成batch(包),例如,把32行数据为一个小包batch。
搭建神经网络模型
从数据中分析出,有4个输入特征,所以输入层有4个节点;鸢尾花3种类别,所以输出层有3个节点. 我们需要初始化网络中的参数(权值、偏置)。
通过前向传播计算,即从输入层到输出层迭代计算,预测出是那个类别的鸢尾花,对比是否预测正确(通过损失函数计算出 预测值和真实值的偏差,这个偏差越小代表预测越接近真实;最终选择最优的参数)。
输入层和输出层之间的映射关系接近正确的,模型基本训练好了。
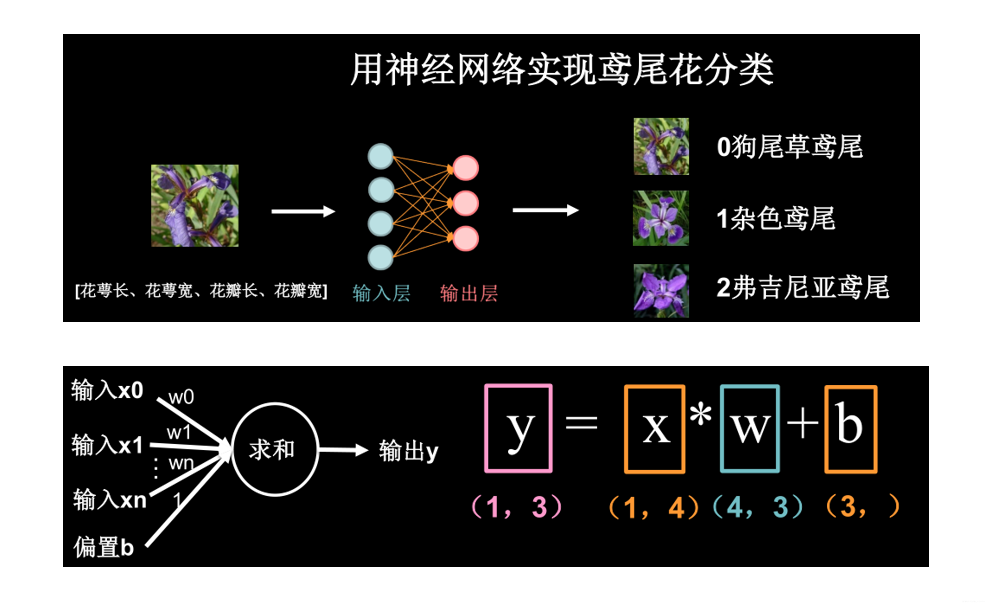
即所有的输入 x 乘以各自线上的权重 w 求和加上偏置项 b 得到输出 y 。
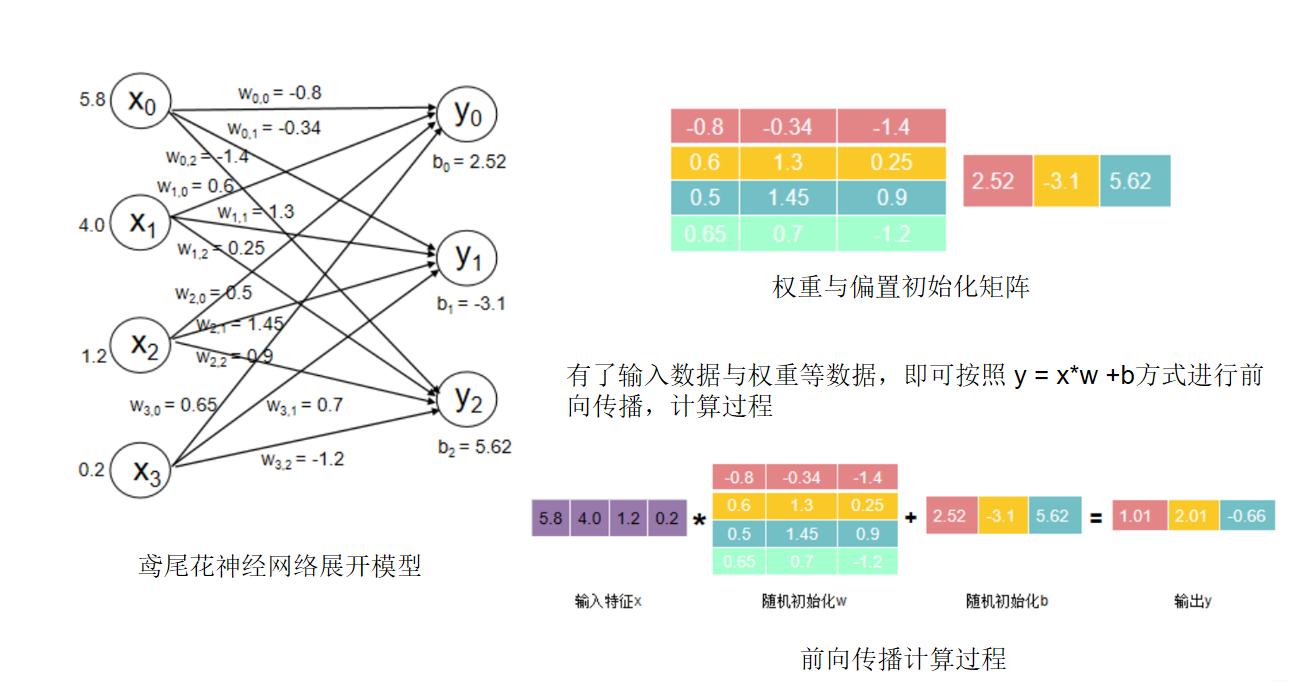
输出 y 中,1.01 代表 0 类鸢尾得分,2.01 代表 1 类鸢尾得分,-0.66 代表 2 类鸢尾得分。通过输出 y 可以看出数值最大(可能性最高)的是 1 类鸢尾,而5不是标签 0 类鸢尾。这是由于最初的参数 w 和 b 是随机产生的,现在输出的结果是不准确的。
为了修正这一结果,我们用 损失函数,定义预测值 y 和标准答案(标签)_y 的差距,损失函数可以定量的判断当前这组参数 w 和 b 的优劣,当损失函数最小时,即可得到最优 w 的值和 b 的值。
损失函数,其目的是寻找一组参数 w 和 b 使得损失函数最小。为达成这一目的,我们采用梯度下降的方法。
损失函数的梯度 表示损失函数对各参数求偏导后的向量,损失函数梯度下降的方向,就是是损失函数减小的方向。梯度下降法即沿着损失函数梯度下降的方向,寻找损失函数的最小值,从而得到最优的参数。
梯度下降的直观解释:(来自:梯度下降(Gradient Descent)小结 - 刘建平Pinard - 博客园)
首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
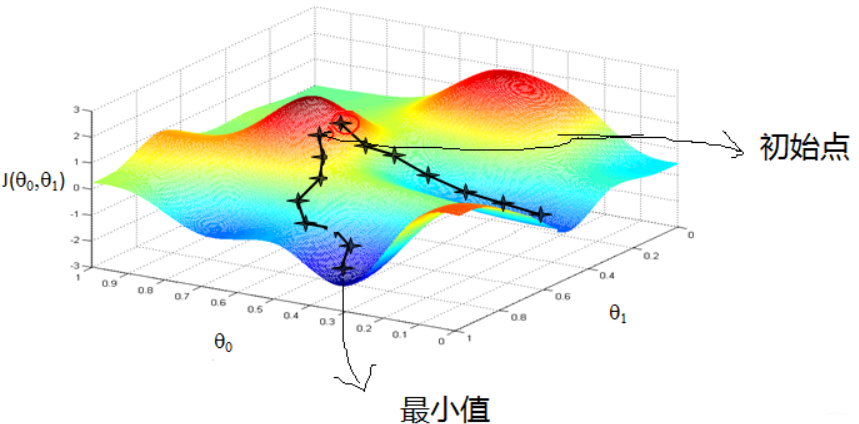
梯度下降参考:深入浅出–梯度下降法及其实现 - 简书
鸢尾花识别 完整代码:
# -*- coding: UTF-8 -*-
# 利用鸢尾花数据集,实现前向传播、反向传播,可视化loss曲线
# 导入所需模块
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
# 导入数据,分别为输入特征和标签
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率)
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样(为方便教学,以保每位同学结果一致)
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
# 将打乱后的数据集分割为训练集和测试集,训练集为前120行,测试集为后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# from_tensor_slices函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1))
lr = 0.1 # 学习率为0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 500 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和
# 训练部分
for epoch in range(epoch): #数据集级别的循环,每个epoch循环一次数据集
for step, (x_train, y_train) in enumerate(train_db): #batch级别的循环 ,每个step循环一个batch
with tf.GradientTape() as tape: # with结构记录梯度信息
y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算
y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss)
y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy
loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确
# 计算loss对各个参数的梯度
grads = tape.gradient(loss, [w1, b1])
# 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad
w1.assign_sub(lr * grads[0]) # 参数w1自更新
b1.assign_sub(lr * grads[1]) # 参数b自更新
# 每个epoch,打印loss信息
print("Epoch {}, loss: {}".format(epoch, loss_all/4))
train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中
loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备
# 测试部分
# total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0
total_correct, total_number = 0, 0
for x_test, y_test in test_db:
# 使用更新后的参数进行预测
y = tf.matmul(x_test, w1) + b1
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类
# 将pred转换为y_test的数据类型
pred = tf.cast(pred, dtype=y_test.dtype)
# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
# 将每个batch的correct数加起来
correct = tf.reduce_sum(correct)
# 将所有batch中的correct数加起来
total_correct += int(correct)
# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数
total_number += x_test.shape[0]
# 总的准确率等于total_correct/total_number
acc = total_correct / total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("--------------------------")
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()
训练过程,一共迭代500次,最后得出 loss: 0.032300274819135666 Test_acc: 1.0
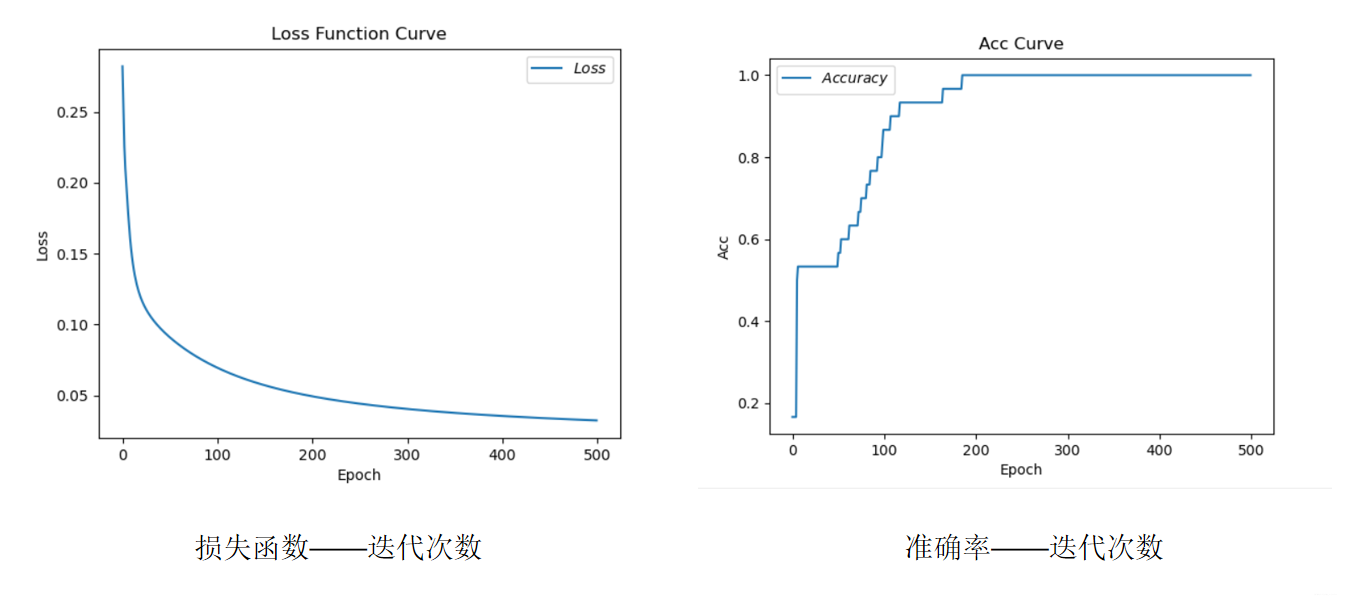
随着迭代次数的增加,损失率(预估值和真实值的偏差)在减少;准确率在不多提高,最终到达100%(即:1)
本博客参考:北京大学 课程“人工智能实践:Tensorflow笔记”;
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。
Springboot整合HBase——大数据技术之HBase2.x
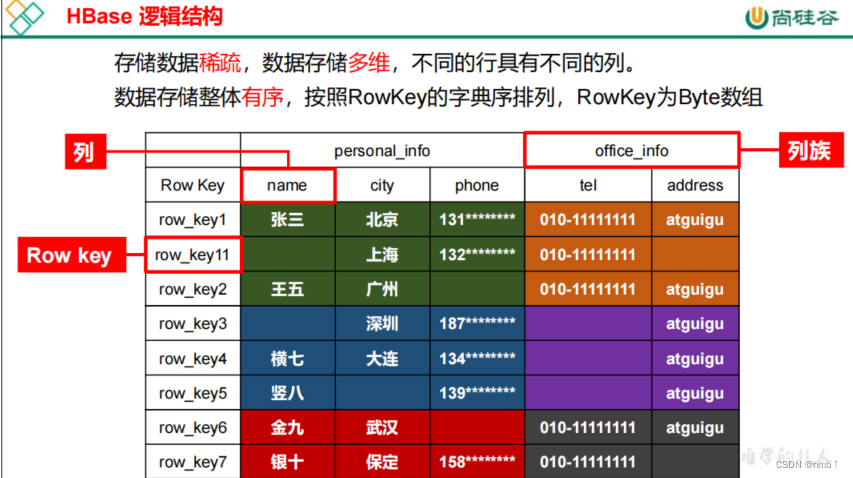
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

终于有人把Web 3.0和元宇宙讲明白了
分散的数据网络使个人数据(例如个人的健康数据、农民的作物数据或汽车的位置和性能数据)出售或交换成为可能,与此同时,不会失去对数据的所有权控制、放弃数据隐私或依赖第三方平台来管理数据。Web 3.0的目标是在创作者经济中取得更好的平衡。互联网第二次迭代(Web 2.0)的缺陷,加上公有区块链技术的诞生,帮助我们朝着更加去中心化的Web 3.0 迈进,元宇宙和更广泛的去中心化网络都是关于现实世界和虚拟世界的融合。此时的网络中不再是静态内容,而是动态的内容,用户现在可以与发布在网络上的内容进行交互。
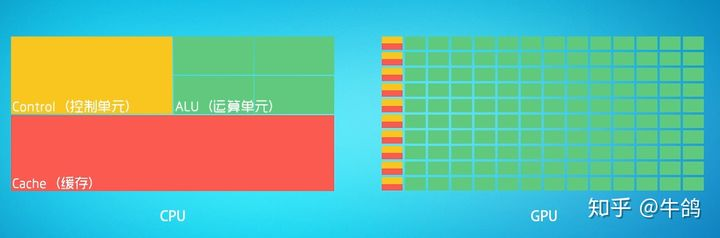
深度学习硬件基础:CPU与GPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。[^3]可以形象的理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)GPU:叫做图形处理器。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!
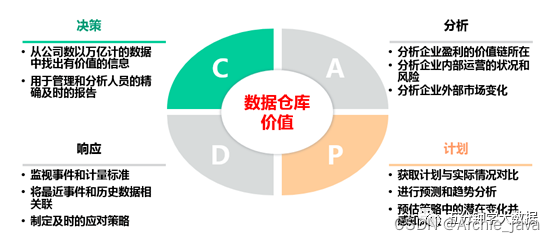
万字详解数据仓库、数据湖、数据中台和湖仓一体
数字化转型浪潮卷起各种新老概念满天飞,数据湖、数据仓库、数据中台轮番在朋友圈刷屏,有人说“数据中台算个啥,数据湖才是趋势”,有人说“再见了数据湖、数据仓库,数据中台已成气候”……企业还没推开数字化大门,先被各种概念绊了一脚。那么它们 3 者究竟有啥区别?别急,先跟大家分享两个有趣的比喻。1、图书馆VS地摊如果把数据仓库比喻成“图书馆”,那么数据湖就是“地摊”。去图书馆借书(数据),书籍质量有保障,但你得等,等什么?等管理员先查到这本书属于哪个类目、在哪个架子上,你才能精准拿到自己想要的书;
什么是数据中台?
说完了数据中台诞生的历史背景,现在,我们应该对数据中台有了一定的了解,那我们现在给数据中台下个定义。自2016年,数据中台被提出以来,不同的人对数据中台有不同的理解,就像一千个读者心中有一千个哈姆雷特,因此也有许多不同的定义,以下是我从一些文章、书籍中搜集到的关于数据中台的定义:数据中台是DT时代的大背景下,为实现数据快(快速)、准(准确)、省(低成本)赋能业务发展的目标,将企业的数据统一整合起来,基于Onedata方法论借助大数据平台完成数据的统一加工处理,对外提供数据服务的一套机制。

基于深度学习的细胞感染性识别与判定
通过引入深度学习技术,我们能够更精准地识别细胞是否受到感染,为医生提供更及时的信息,有助于制定更有效的治疗方案。基于深度学习的方法通过学习大量样本,能够自动提取特征并进行准确的感染性判定,为医学研究提供了更高效和可靠的手段。通过引入先进的深度学习技术,我们能够实现更快速、准确的感染性判定,为医学研究和临床实践提供更为可靠的工具。其准确性和效率将为医学研究带来新的突破,为疾病的早期诊断和治疗提供更可靠的支持。通过大规模的训练,模型能够学到细胞感染的特征,并在未知数据上做出准确的预测。

Git 的基本概念、使用方式及常用命令
Git的基本概念、使用方式及常用命令

windows安装conda环境,开发openai应用准备,运行第一个ai程序
作者开发第一个openai应用的环境准备、第一个openai程序调用成功,做个记录,希望帮助新来的你。第一次能成功运行的openai程序,狠开心。
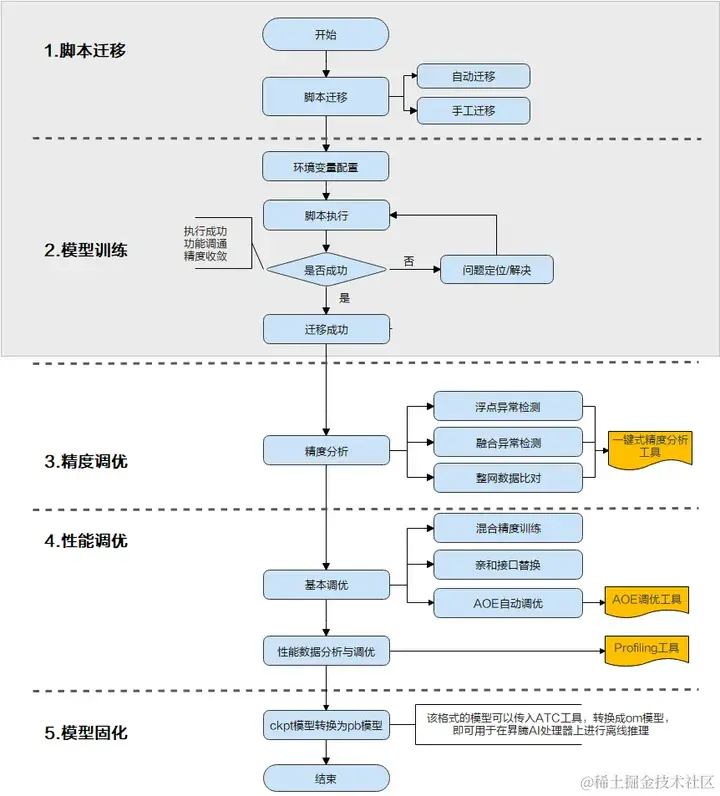
一文详解TensorFlow模型迁移及模型训练实操步骤
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。
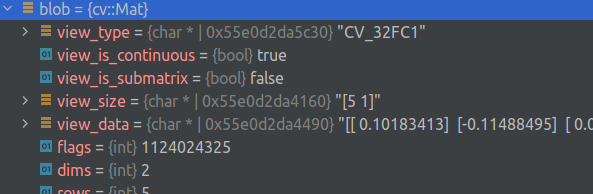
将 OpenCV 与 gdb 驱动的 IDE 结合使用
能力这个漂亮的打印机可以显示元素类型、标志和(可能被截断的)矩阵。众所周知,它可以在 Clion、VS Code 和 gdb 中工作。Clion 示例安装移入 .放在方便的地方,重命名并移动到您的个人文件夹中。将“source”行更改为指向您的路径。如果系统中安装的 python 3 版本与 gdb 中的版本不匹配,请使用完全相同的版本创建一个新的虚拟环境,相应地安装并更改 python3 的路径。用法调试器中以前缀为前缀的字段是为方便起见而添加的伪字段,其余字段保持原样。

改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)
改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)2021.10.30 复现TPH-YOLOv52021.10.31 完成替换backbone为Ghostnet2021.11.02 完成替换backbone为Shufflenetv22021.11.05 完成替换backbone为Mobilenetv3Small2021.11.10 完成EagleEye对YOLOv5系列剪枝支持2021.11.14 完成MQBench对YOLOv5系列量

怎么选择数据安全交换系统,能够防止内部员工泄露数据?
数据泄露可能给企业带来诸多风险:财产损失、身份盗窃、骚扰和诈骗、经济利益受损、客户信任度下降、法律风险和责任等,《2021年度数据泄漏态势分析报告》中显示,在数据泄露的主体中,内部人员导致的数据泄漏事件占比接近60%。飞驰云联文件安全交换系统,可以满足企业多场景下的文件交换需求,帮助企业终结多工具、 多系统并行使用的局面,减少因文件交换行为分散带来的数据管理不集中、难以管控的问题, 帮助企业内部构建统一、安全的企业数据流转通道。对于不能下载保存的数据,使用截屏、录屏的方式窃取并外泄数据;
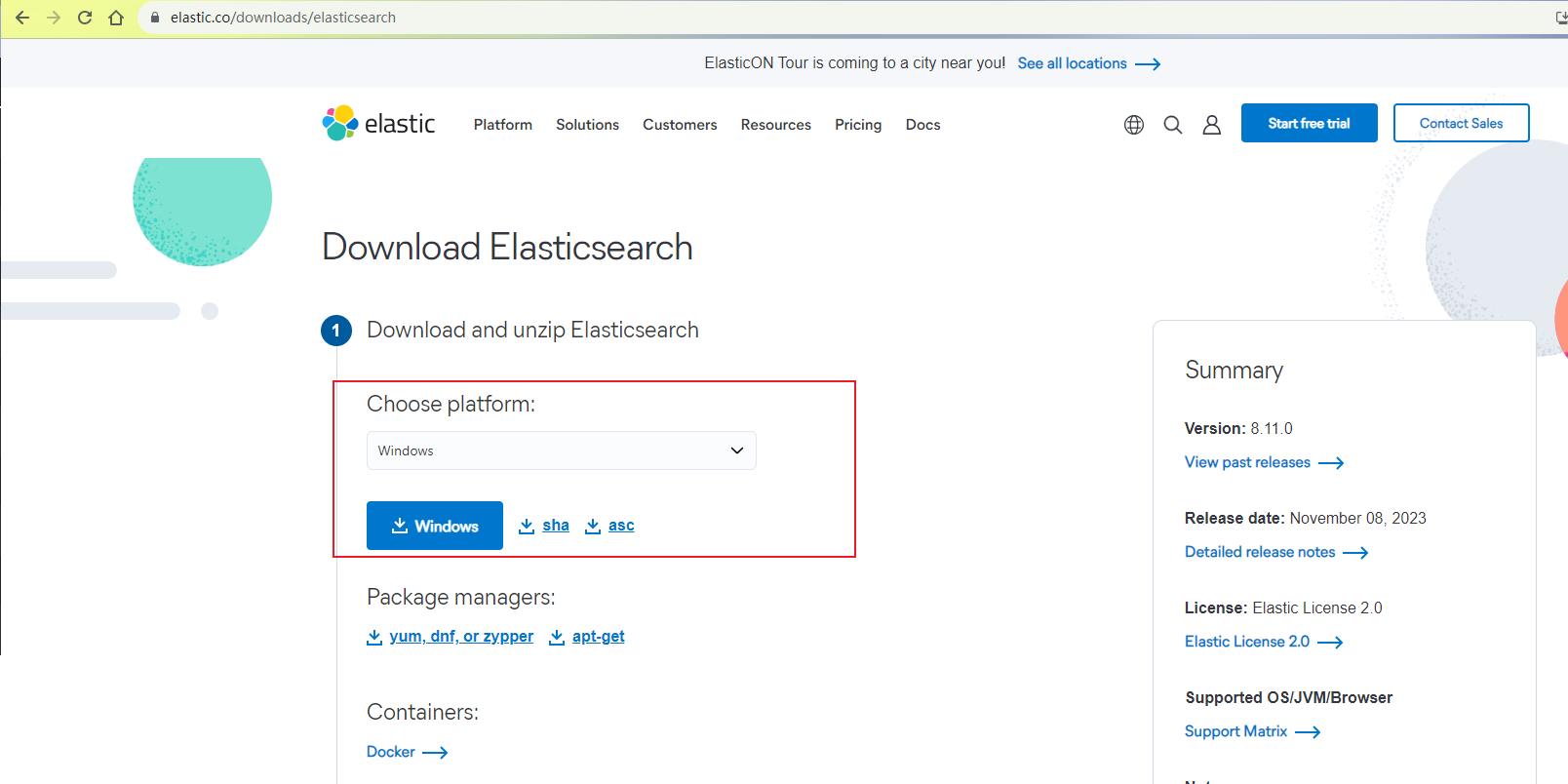
弹性搜索引擎Elasticsearch:本地部署与远程访问指南
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问。
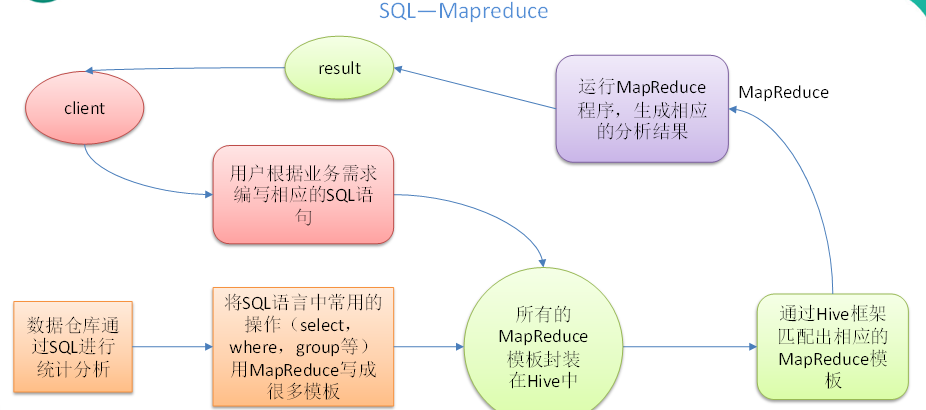
Hive(总)看完这篇,别说你不会Hive!
Hive:由Facebook开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。本质是:将HQL转化成MapReduce程序1)Hive处理的数据存储在HDFS2)Hive分析数据底层的实现是MapReduce3)执行程序运行在Yarn上创建一个数据库,数据库在HDFS上的默认存储路径是/opt/hive/warehouse/*.db避免要创建的数据库已经存在错误,增加if not exists判断。
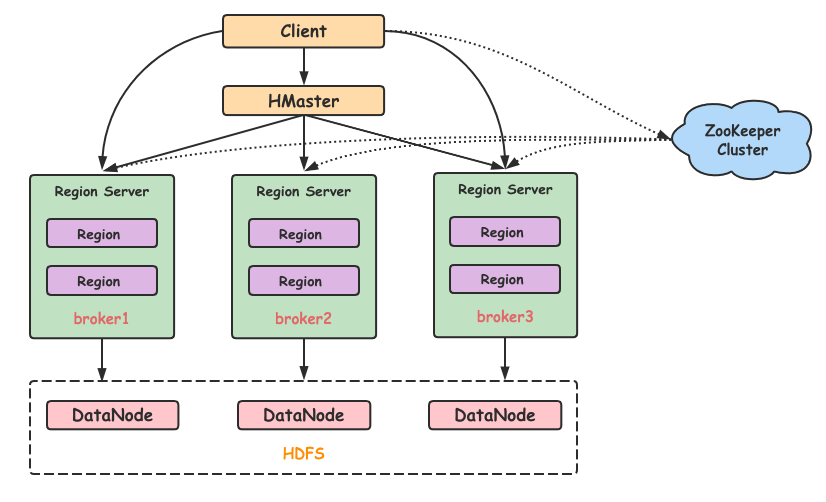
什么是HBase?终于有人讲明白了
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
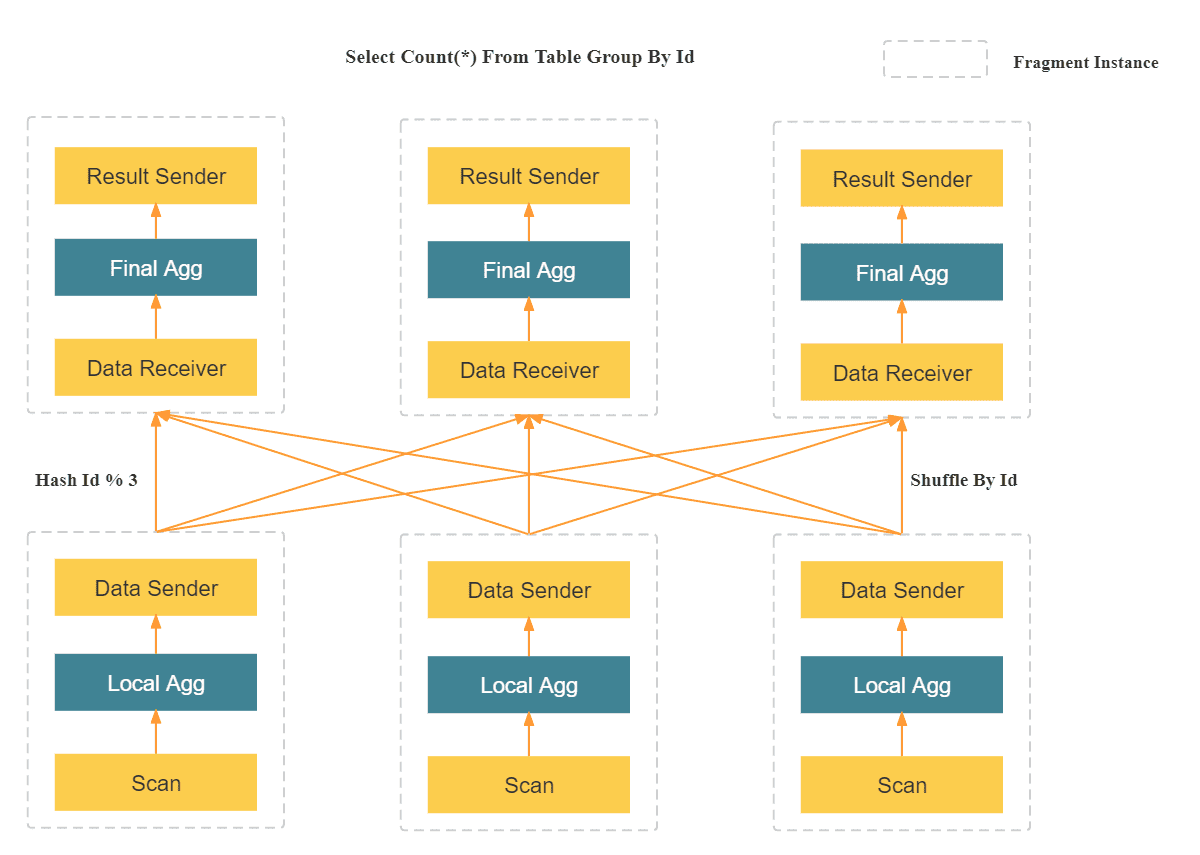
数据仓库系列:StarRocks 入门培训教程
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。提供千亿级大数据的在线多维分析和分布式存储。新一代极速全场景 MPP (Massively Parallel Processing) 数据库是forkdoris后独立运营的商业化版本StarRocks。

ClickHouse & StarRocks 使用经验分享
总结一下,如果是需要分析日志流数据,更加推荐 ClickHouse ,因为 ClickHouse 单机强悍,可以支撑亿级别数据量,架构简单,相比于 StarRocks 也更加稳定,相比集群,更推荐单机 ClickHouse。如果是分析业务流数据,更加推荐 StarRocks ,因为 StarRocks 对于更新场景性能更加,而且 JOIN 性能更好,而且更加推荐部署 StarRocks 集群,可以充分发挥 StarRocks 的性能。

大数据Hadoop、HDFS、Hive、HBASE、Spark、Flume、Kafka、Storm、SparkStreaming这些概念你是否能理清?
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn只负责资 源 的 调 度。当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;
HDFS对比HBase、Hive对比Hbase
Hive和Hbase是两种基于Hadoop的不同技术Hive是一种类SQL的引擎,并且运行MapReduce任务Hbase是一种在Hadoop之上的NoSQL的Key/value数据库这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也 可以从Hive写到HBase,或者从HBase写回Hive。
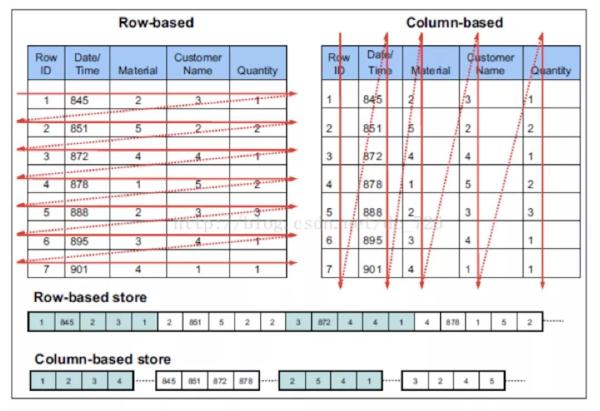
ClickHouse 与mysql等关系型数据库对比
先用一张图帮助理解两者的本质上的区。
PyTorch中nn.Module的继承类中方法foward是自动执行的么?
在 PyTorch的 nn.Module中,forward方法并不是自动执行的,但它是在模型进行前向传播时必须调用的一个方法。当你实例化一个继承自torch.nn.Module的自定义类并传入输入数据时,需要通过调用该实例来实现前向传播计算,这实际上会隐式地调用forward方法。
文本挖掘的几种常用的方法
1. 文本预处理:首先对文本数据进行清洗和预处理,如去除停用词(如“的”、“是”等常用词)、标点符号和特殊字符,并进行词干化或词形还原等操作,以减少数据噪声和提取更有意义的特征。3. 文本分类:将文本数据分为不同的类别或标签。文本挖掘是一种通过自动化地发现、提取和分析大量文本数据中的有趣模式、关联和知识的技术。这些示例代码只是简单的演示了各种方法的使用方式,具体的实现还需要根据具体的需求和数据进行适当的调整和优化。8. 文本生成:使用统计模型或深度学习模型生成新的文本,如机器翻译、文本摘要和对话系统等。

牢牢把握“心价比”,徕芬的业绩爆发是一种必然?
业绩突破背后也有消费复苏的激励作用,但具体到电吹风市场,竞争态势在持续加剧,且有戴森这样的国外品牌盘踞于此。徕芬究竟是如何越走越稳的?
智能革命:揭秘AI如何重塑创新与效率的未来
智能革命:揭秘AI如何重塑创新与效率的未来
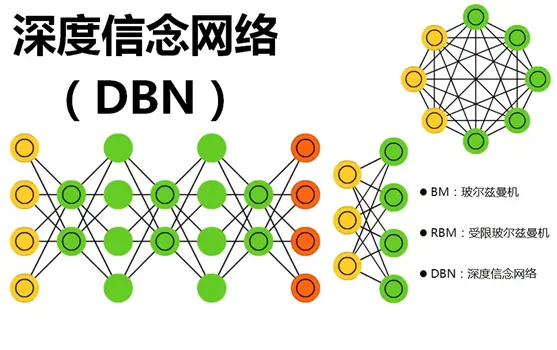
一文搞懂深度信念网络!DBN概念介绍与Pytorch实战
深度信念网络(Deep Belief Networks, DBNs)是一种深度学习模型,代表了一种重要的技术创新,具有几个关键特点和突出能力。首先,DBNs是由多层受限玻尔兹曼机(Restricted Boltzmann Machines, RBMs)堆叠而成的生成模型。这种多层结构使得DBNs能够捕获数据中的高层次抽象特征,对于复杂的数据结构具有强大的表征能力。其次,DBNs采用无监督预训练的方式逐层训练模型。