MySQL是如何保证数据不丢失的?
前言
上篇文章《InnoDB在SQL查询中的关键功能和优化策略》对InnoDB的查询操作和优化事项进行了说明。但是,MySQL作为一个存储数据的产品,怎么确保数据的持久性和不丢失才是最重要的,感兴趣的可以跟随本文一探究竟。
Buffer Pool 和 DML 的关系
InnoDB中的「Buffer Pool」除了在查询时起到提高效率作用,同样,在insert、update、delete这些DML操作时为了减少和磁盘的频繁交互,也会将这些更新先在Buffer Pool中缓存的数据页进行操作,随后将这些有更新的「脏页」刷到磁盘中。
这个时候就涉及到一个问题:如果MySQL服务宕机了,这些在内存中更新的数据会不会丢失?
答案是一定会存在丢失现象的,只不过MySQL做到了尽量不让数据丢失。接下来来看一下MySQL是怎么做的。
这里还是把结构图贴一下,方便下面介绍时看图理解。
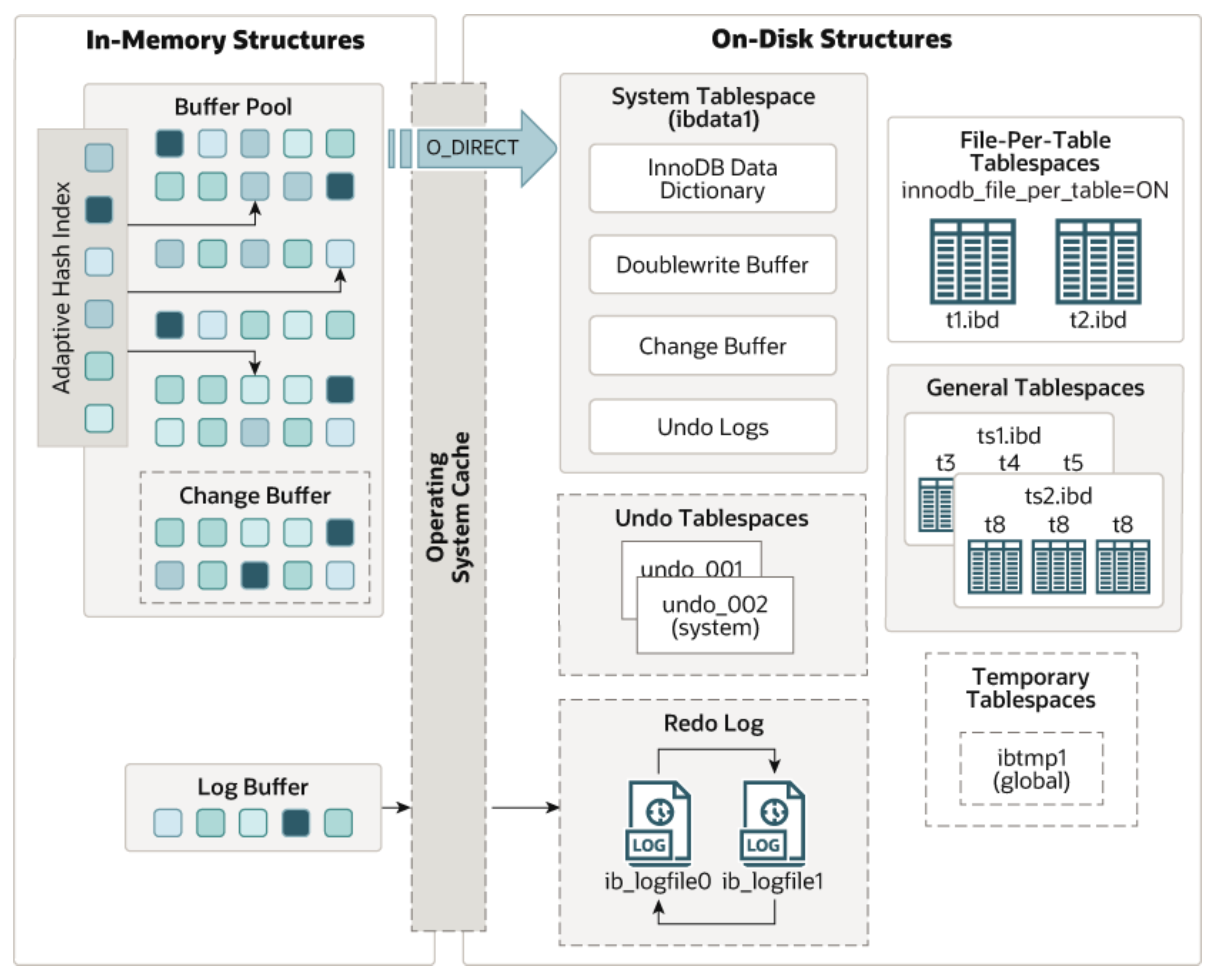
DML操作流程
加载数据页
通过上文可以知道,行记录是在数据页中,所以,当InnoDB接收到DML操作请求后,还是会去找「数据页」,查找的过程跟上文查询行记录流程是一样。这里说一下,insert的请求会根据主键索引去找数据页,update、delete根据查询条件去找数据页,总之「数据页」要加载到「Buffer Pool」之后才会进行下一步操作。
更新记录
定位到数据页后,insert操作就是往数据页中添加一行记录,delete是标记一下行记录的‘删除标记’,而update则是先删除再添加,这是因为存在可变长的字段类型,比如varchar,每次更新时,这种类型的数据占用内存是不固定的,所以先删除再添加。
这里的删除标记是行记录的字段,也就是除了业务字段数据,InnoDB默认为每行记录添加的字段,所以一个行记录大概如下图,这也是之前提到过的「行格式」。

找到数据页并且更新记录之后DML操作就算完成了,但是还没有落地到磁盘。
这个时候直接刷新到磁盘视为完成不可以吗?
数据持久化方案
可以是可以,但是如果每次的DML操作都要将一个16KB的数据页刷到磁盘,其效率是极低的,估计也就没有人用MySQL了。但是如果不刷新到磁盘,就会发生MySQL服务宕机数据会丢失现象。MySQL在这里的处理方案是:
- 等待合适的时机将批量的「脏页」异步刷新到磁盘。
- 先快速将更新的记录以日志的形式刷新到磁盘。
先看第一点,什么时候是合适的时机?
合适的时机刷盘
当「脏页」在「Buffer Pool」中达到某个阈值的时候,InnoDB会将这些脏页刷新到磁盘中。这个阈值可以通过 innodb_max_dirty_pages_pct 这个参数查看或设置,相关命令如下:
-- 查看脏页刷新阈值
show variables like 'innodb_max_dirty_pages_pct'
-- 在线设置脏页刷新阈值,当脏页在Buffer Pool占用70%的时候刷新
SET GLOBAL innodb_max_dirty_pages_pct = 70
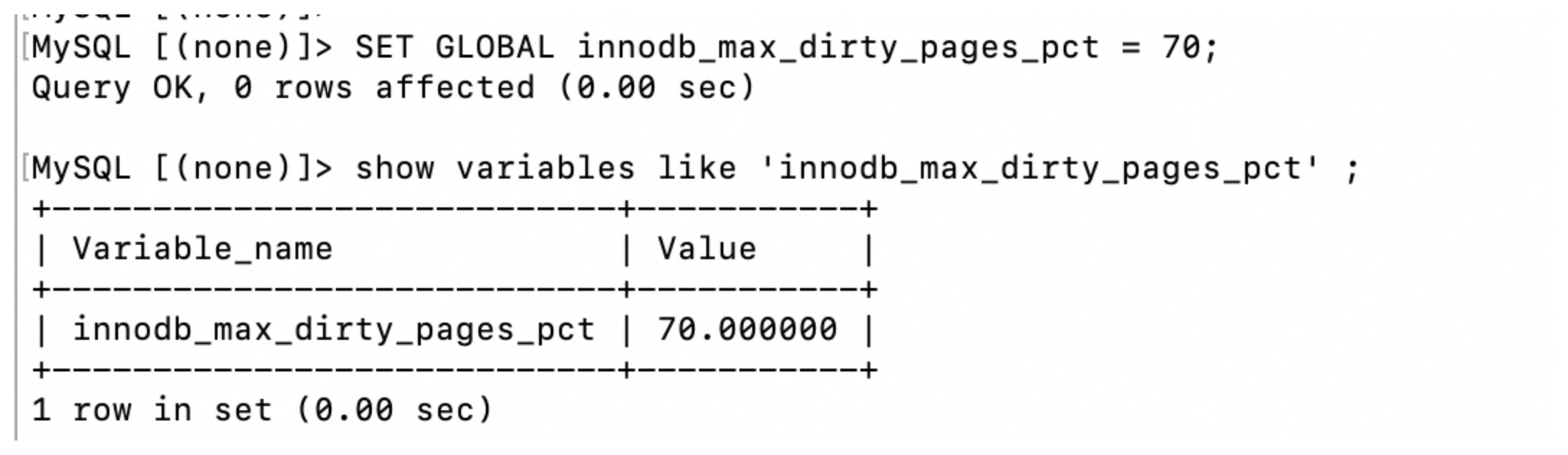
当然,这个合适的时机只是为了减少与磁盘的交互,用来提高性能的,并不能确保数据不丢失。
双写机制
在刷新「脏页」这里还有一个非常重要的注意事项就是:因为InnoDB的页大小为16KB,而一般操作系统的页大小为4KB。意味着InnoDB将这些「脏页」向磁盘刷新时,在操作系统层面会被分成4个4KB的页,这样的话,如果其中有一页因为MySQL宕机或者其他异常导致没有成功刷新到磁盘,就会出现「页损坏现象」,数据也就不完整了。
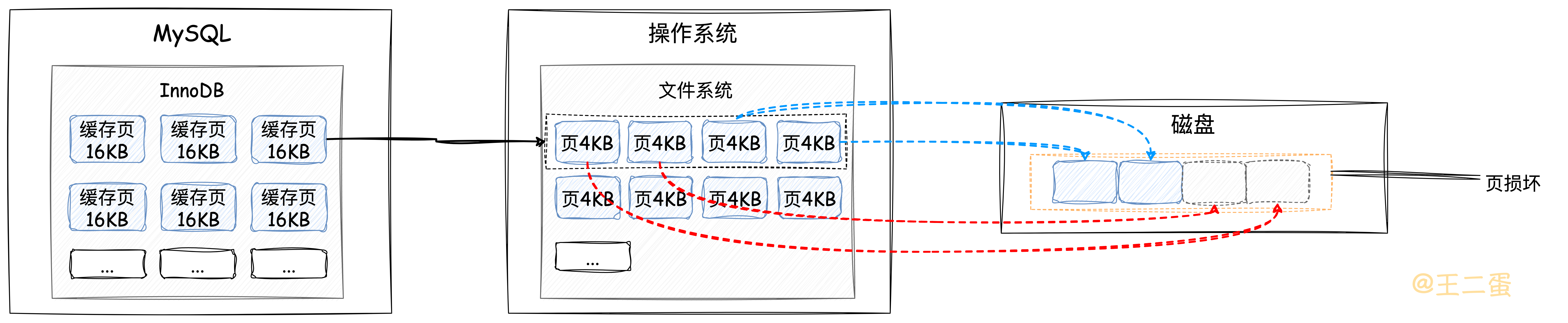
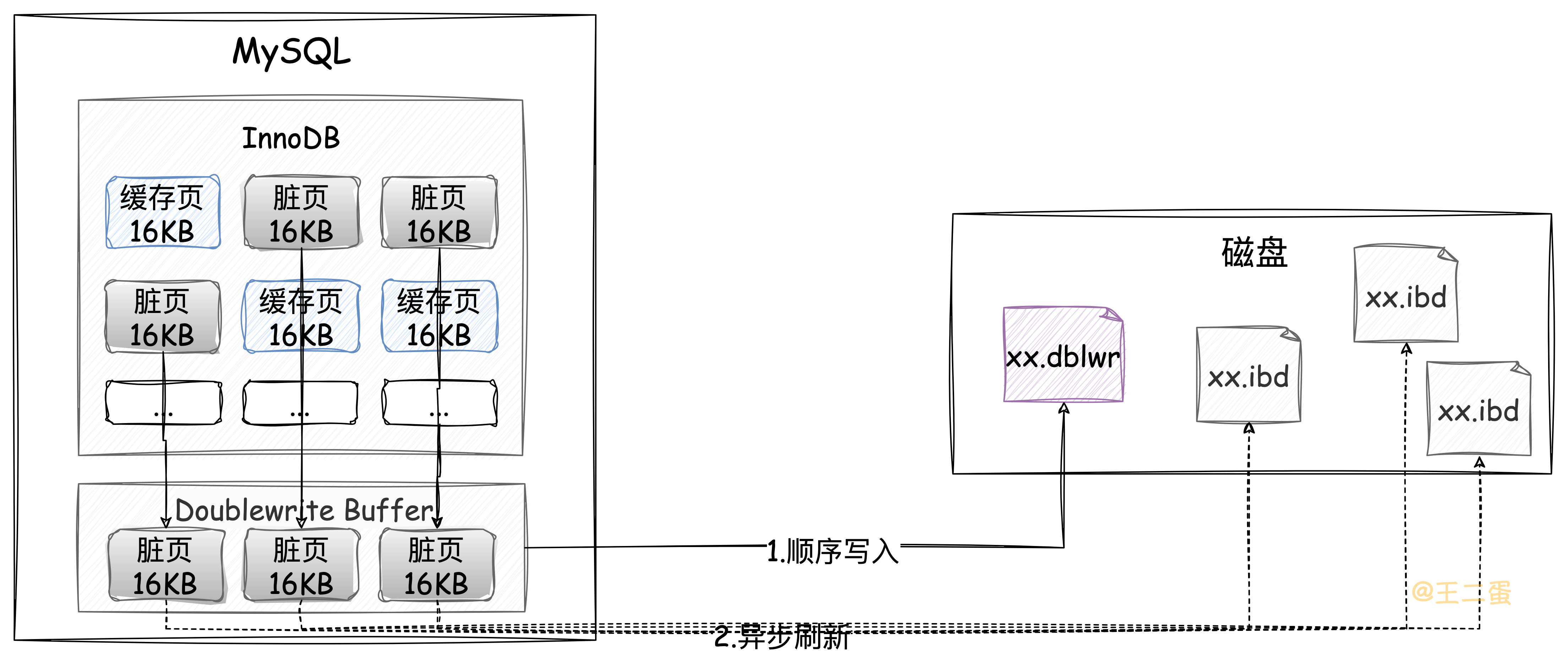
所以InnoDB在这里采用的双写机制,在将这些「脏页」刷新到磁盘之前先会往结构图中的「Doublewrite Buffer」中写入,随后再刷新到对应的表空间中,当出现故障时就可以通过双写缓冲区进行恢复。
向「Doublewrite Buffer」就不会发生「页损坏现象」?
「Doublewrite Buffer」的大小是独立且固定的,不是基于页的大小来划分的。所以不受操作系统中的页大小限制,也不会发生「页损坏现象」。并且先以顺序IO的方式向「Doublewrite Buffer」写入数据页,再以随机IO异步刷新到表空间这种方式还可以提高写入性能。
再看第二点,为什么以日志的形式先刷新到磁盘?
日志先行机制
在「Buffer Pool」中更新完数据页后,由于不会及时将这些「脏页」刷新到磁盘,为了避免数据丢失,会将本次的DML操作向「Log Buffer」中写一份并且刷新到磁盘中,相比16KB的数据页来说,这个数据量会小很多,而且写入日志文件时是追加操作,属于顺序IO,效率较高。如下图,哪种方式写入效率更高是显而易见的。
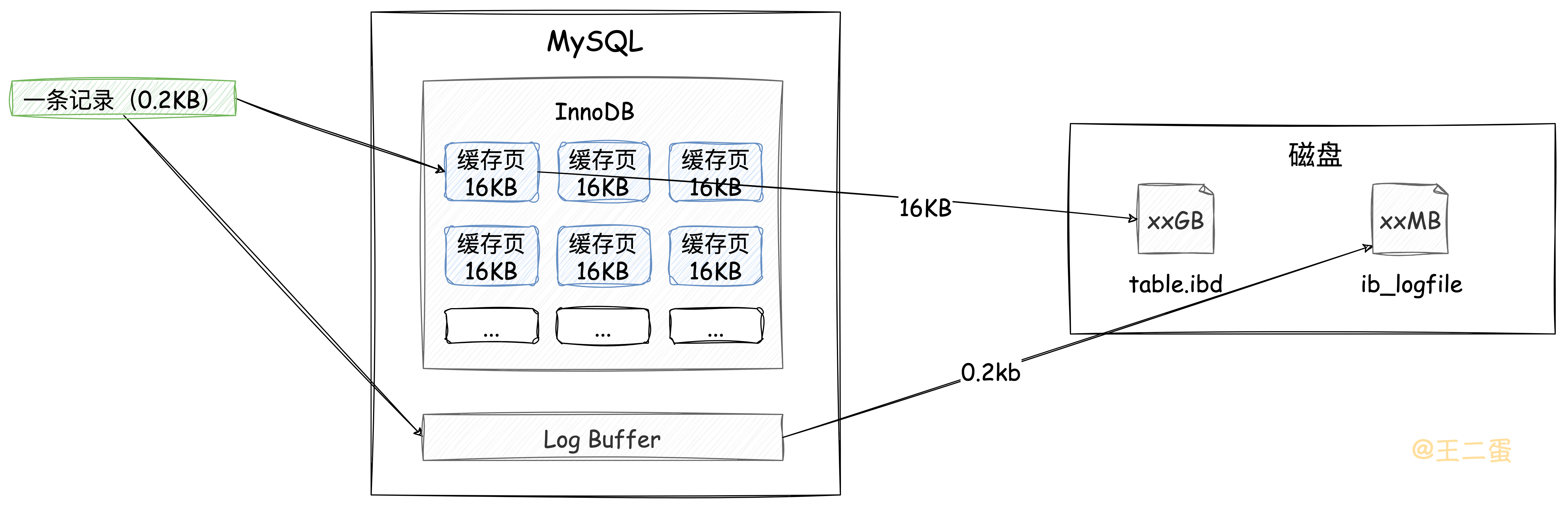
这里说的日志文件就是经常会听到的「Redo Log」,即使MySQL宕机了,通过磁盘的redolog,也可以在MySQL启动时尽可能的将数据恢复到宕机之前样子。当然,还有「Undo Log」,因为对本文重点没有直接影响,所以不对此展开说明。
这种日志先行(WAL)的机制也是MySQL用于提高效率和保障数据可靠的一种方式。
为什么是尽可能的恢复?
日志刷盘机制
因为「Log Buffer」中的日志数据什么时候向磁盘刷新则是由 innodb_flush_log_at_trx_commit 和 innodb_flush_log_at_timeout 这两个参数决定的。
innodb_flush_log_at_trx_commit默认为1,也就是每次事务提交后就会刷新到磁盘。- 当
innodb_flush_log_at_trx_commit设置为0时,则不会根据事务提交来刷新,而是根据innodb_flush_log_at_timeout设置的时间定时刷新,这个时间默认为1秒。 - 当
innodb_flush_log_at_trx_commit设置为2时,仅将日志写入操作系统中的缓存中,随后跟随根据innodb_flush_log_at_timeout定时刷新。
如果在MySQL服务宕机的时候,「Log Buffer」中的日志没有刷新到磁盘,这部分数据也是会丢失的,在重启后也不会恢复。所以如果不想丢失数据,在性能还可以的情况下,尽量将innodb_flush_log_at_trx_commit设置为1。
「redo log」是怎么恢复数据的?
Redo Log 恢复数据
首先,redo log会记录DML的操作类型、数据的表空间、数据页以及具体操作内容,以 insert into t1(1,'hi')为例,对应的redo log内容大概这样的

假如 innodb_flush_log_at_trx_commit 的值为1,那么当该DML操作事务提交后,就会将 redo log 刷新到磁盘。成功刷新到磁盘后,就可以视为数据被写入成功。
此时如果「脏页」还没刷新到磁盘便宕机,那么在下次MySQL启动时便去加载redo log,如果redo log存在数据则意味着需要恢复数据。这个时候就可以通过redo log中的内容重新构建「脏页」,从而恢复到宕机之前的状态。
怎么构建「脏页」呢?
其实在每次的redo log写入时都会记录一个「LSN(log sequence number)」,同时这个值在「数据页」中记录最后一次被修改的日志序列位置。MySQL在启动时通过LSN来对比 redo log 和数据页,如果数据页中的LSN小于 redo log 的LSN,则会将该数据页加载到「Buffer Pool」,然后根据 redo log 的内容构建出「脏页」,等待下次刷新到磁盘,数据也就恢复了。如下图
注意:这个恢复的过程重点在redo上,实际上还涉及到「Change Buffer」、「Undo Log」等操作,这里没有展开说明。
「Doublewrite Buffer」和「redo log」都是恢复数据的,不冲突吗?
不冲突,「Doublewrite Buffer」是对「页损坏现象」的整个数据页进行恢复,Redo Log只能对某次的DML操作进行恢复。
总结
InnoDB通过以上的操作可以尽可能的保证MySQL不丢失数据,最后再总结一下MySQL是如何保障数据不丢失的:
- 为了避免频繁与磁盘交互,每次DML操作先在「Buffer Pool」中的缓存页中执行,缓存页有更新之后便成为「脏页」,随后根据
innodb_max_dirty_pages_pct这个参数将「脏页」刷新到磁盘。 - 因为「脏页」在刷新到磁盘之前可能会存在MySQL宕机等异常行为导致数据丢失,所以MySQL采用日志先行(WAL)机制,将DML操作以日志的形式进行记录到「Redo Log」中,随后根据
innodb_flush_log_at_trx_commit和innodb_flush_log_at_timeout这两个参数将「Redo Log」刷新到磁盘,以便恢复。 - 在向磁盘刷新「脏页」时,为了避免发生「页损坏」现象,InnoDB采用双写机制,先将这些脏页顺序写入「Doublewrite Buffer」中,随后再将数据页异步刷新到各个表空间中,这种方式既能提高写入效率,又可以保障数据的完整性。
- 如果在「脏页」刷新到磁盘之前,MySQL宕机了,那么会在下次启动时通过 redo log 将脏页构建出来,做到数据恢复。
- 通过以上步骤,MySQL做到了尽可能的不丢失数据。
相关文章:

【Mongdb之数据同步篇】什么是Oplog、Mongodb 开启oplog,java监听oplog并写入关系型数据库、Mongodb动态切换数据源
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。Oplog 可以说是Mongodb Replication的纽带了。

Windows下安装和配置Redis
下载版本Redis-x64-5.0.14.1.zip。(可能需要开代理)
MySQL慢查询日志slowlog
慢速查询日志记录的是执行时间超过秒和检查的行数超过的SQL语句,这些语句通常是需要进行优化的。官方参考文档:https://dev.mysql.com/doc/refman/8.0/en/slow-query-log.html。
一文搞懂MySQL索引
官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。
ON DUPLICATE KEY UPDATE 导致mysql自增主键ID跳跃增长
具体解决方案可以根据项目来选择,如果项目不大,可以考虑1和2。如果不考虑高并发问题,可以考虑3。
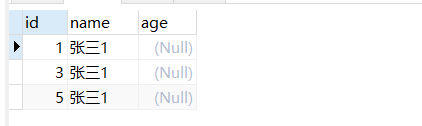
mysql唯一索引与null
根据NULL的定义,NULL表示的是未知,因此两个NULL比较的结果既不相等,也不不等,结果仍然是未知。根据这个定义,多个NULL值的存在应该不违反唯一约束,所以是合理的,在oracel也是如此。在mysql 的innodb引擎中,是允许在唯一索引的字段中出现多个null值的。有上面的表和数据可以看出,查询多条数据。

详解mybatis的insert,update,delete返回值
为什么要提数据的事呢,是因为据说这个save返回的就是插入的数据的条数。但是遗憾的是,我们的这个user怎么能没有id呢,没有id有怎么查,怎么删,怎么改。进来的是没有id的user,出去的是有id的user,真是太厉害了,没想到不仅把返回值改变了,连参数都发生了改变,真是太神奇了。keyProperty=“id” 这是id就是绑定的id,那我就疑惑了,这绑定的哪个id啊。这样一搞,如果插入成功的话返回的是1,如果不成功的话返回的是-1。我让你删id是222222的,我还没创建呢,看你怎么删。
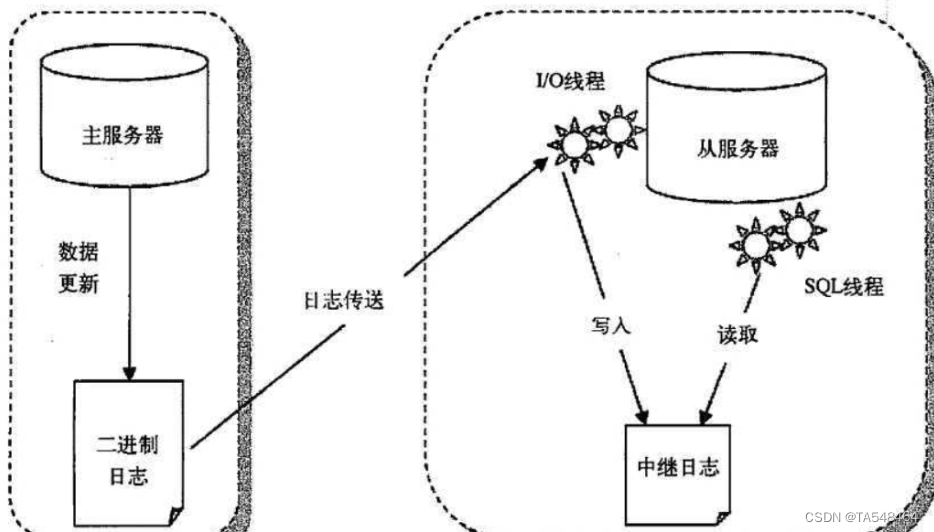
MySQL主从复制(基于binlog日志方式)
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。主从复制的作用1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。3.读写分离,使数据库能支撑更大的并发。a.从服务器可以执行查询工作(就是我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
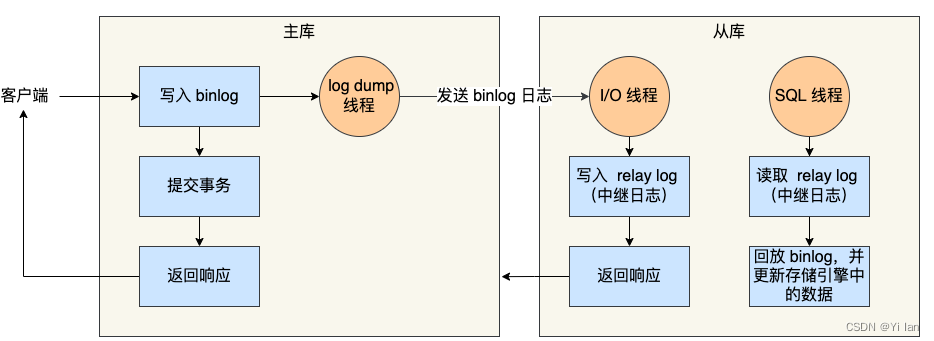
MYSQL 主从复制 --- binlog
在 Master 端并不 Care 有多少个 Slave 连上了自己,只要有 Slave 的 IO 线程通过了连接认证,向他请求指定位置之后的 Binary Log 信息,他就会按照该 IO 线程的要求,读取自己的 Binary Log 信息,返回给 Slave 的 IO 线程。默认MySQL是未开启该日志的。如果读压力加大,就需要更多的 slave 来解决,但是如果slave的复制全部从 master 复制,势必会加大 master 的复制IO的压力,所以就出现了级联复制,减轻 master 压力。
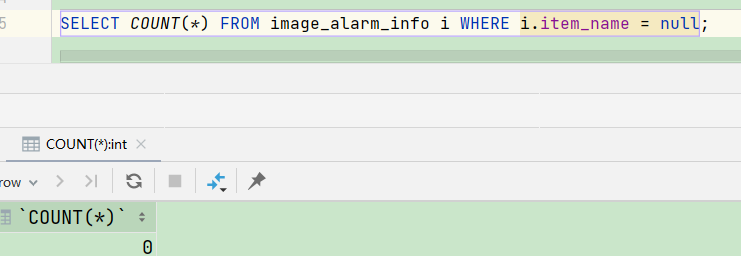
MySQL 中 is null 和 =null 的区别
如果 set ANSI_NULLS为 ON 时,表示SQL语句遵循SQL-92标准;如果 set ANSI_NULLS 为 OFF 时,表示不遵从 SQL-92 标准。但SQL-92 标准要求对null的 = 或不等于 (!= ,) 比较取值都为 false,也就是 =null 或者 null,返回的都是false。null 在MySQL中不代表任何值,通过运算符是得不到任何结果的,因此只能用 is null(默认情况)MySQL 中 null 不代表任务实际的值,类似于一个未知数。

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。

配置nginx+keepalived高可用代理数据库ip端口
需求:配置nginx+keepalived高可用反向代理数据库ip端口(数据库服务器无法增加新SCAN IP或者需要隐藏数据库IP的情况下适用)本机ip为:192.168.20.10和192.168.20.11。2.任意节点关机或重启系统,浮动ip也会自动漂移到另外节点。1.任意节点停nginx:浮动ip会自动漂移到另外节点。安装依赖包和nginx和keepalived。浮动IP为:192.168.20.20。配置keepalived.conf。两台centos7.9。
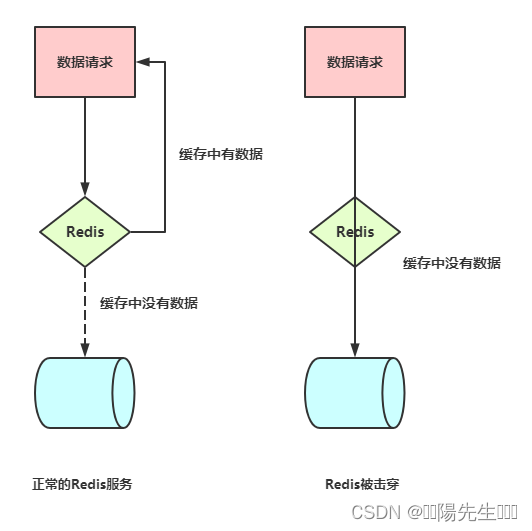
Redis 击穿、穿透、雪崩产生原因解决思路
也就是在设定的时间里数据没有取出来,但是锁由过期了,常见的思路是,锁过期时间值递增,但是想想不靠谱,因为第一个请求可能超时,如果后面的也超时呢,接连多次超时之后,锁过期时间值势必特别大了,这样做弊端太多。雪崩,和击穿类似,不同的是击穿是一个热点Key某时刻失效,而雪崩是大量的热点Key在一瞬间失效,网络上很多博客都在强调解决雪崩的策略是随机过期时间,这个非常不准确,举个例子,银行做活动,之前这个利息系数为2%,过了零点系数改为3%,这种情况能将用户的对应的key改为随机过期吗?如果用的过去的数据叫脏数据。
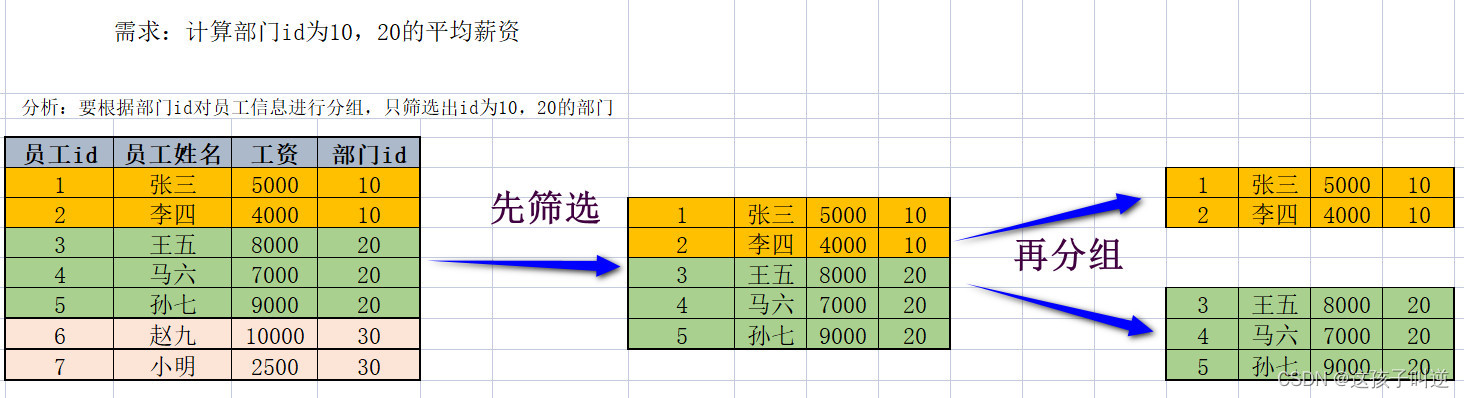
MySQL数据库查询语句之组函数,子查询语句
当一个SQL的执行需要借助另一个SQL的执行结果时,则需要进行SQL嵌套,该语法结构称之为子查询。先筛选出符合要求的数据,再对符合要求的数据进行分组时,分组的工作量会被减少,效率更高。先确定从哪张表进行操作-->对表中数据进行分组-->基于分组结果进行查询操作。执行顺序:优先执行小括号内的子SQL,根据子SQL的执行结果再执行外层SQL。执行顺序:from-->where-->group by-->select。执行顺序:from-->group by-->select。
mysql开启可以使用IP有权限访问
为实际的IP地址和你想要设置的密码。请小心操作,并确保你了解每个命令的作用。如果你对此有任何疑问,最好咨询经验丰富的数据库管理员。来设置或修改用户的密码。相反,你需要分两步来完成这个过程:首先创建或修改用户,并设置密码;然后授予相应的权限。用户应该能够从指定的内网IP地址访问MySQL服务器。用户已存在并且你只是想更改其密码或允许从另一个地址访问,使用。在MySQL 8.0及更高版本中,语句的语法有所变化。替换为你的内网IP地址,
鸿蒙harmony--数据库sqlite详解
今天是1月20号星期六,早安,岁末大寒至,静后春归来。愿他乡故人,漂泊有归宿,前程有奔赴,愿人间不寒,温暖常伴,诸事顺利,喜乐长安。
Redis的key过期策略是怎么实现的
这是一道经典的Redis面试题,一个Redis中可能存在很多很多的key,这些key中可能有很大一部分都有过期时间,此时Redis服务器咋知道哪些key已经过期,哪些还没过期呢?如果直接遍历所有的key,这显然是行不通的,效率非常低!!Redis整体的策略是定期删除和惰性删除相结合。举个栗子:假如我去小卖铺买东西,付款的时候,发现东西过期了。就告知老板,于是老板下架此产品。消费者发现过期了,才去下架,这就叫。小卖铺老板主动定期抽取一部分商品,进行筛查,这就叫定期删除。
雪花算法生成ID、UUID生成ID和MySql自增ID优缺点分析
综上所述,UUID适用于分布式系统和需要保密的场景,雪花ID适用于分布式系统和高并发环境,MySQL自增ID适用于单机系统和高效查询的场景。根据具体的业务需求和系统架构,选择合适的主键类型。通过本文的介绍和对比,希望读者能够更好地理解在MySQL中不推荐使用UUID或者雪花ID作为主键的原因,并能够根据实际情况做出明智的选择。在MySQL中,使用自增整数作为主键是一种常见的做法,因为它具有较小的存储空间、高效的索引和自动增长的特性。然而,具体选择何种主键类型还是要根据具体的业务需求和数据特点来决定。
【小白专用】C# 连接 MySQL 数据库
C# 连接 MySQL 数据库
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
Springboot支付宝沙箱支付---完整详细步骤
两种方式进行配置。这里我采取的是默认方式: 开发者如需使用系统默认密钥/证书,可在开发信息中选择系统默认密钥。注意:使用API在线调试工具调试OpenAPI必须使用系统默认密钥。
MySQL索引优化实战
对于这种varchar(255)的大字段可能会比较占用磁盘空间,可以稍微优化下,比如针对这个字段的前20个 字符建立索引,就是说,对这个字段里的每个值的前20个字符放在索引树里,类似于 KEY index(name(20),age,position)。此时你在where条件里搜索的时候,如果是根据name字段来搜索,那么此时就会先到索引树里根据name 字段的前20个字符去搜索,定位到之后前20个字符的前缀匹配的部分数据之后,再回到聚簇索引提取出来 完整的name字段值进行比对。
Linux安装MongoDB教程
将解压后的 mongodb-linux-x86_64-rhel70-4.2.23 中的所有文件全部移动到 /usr/local/mongodb 中 :注意/*是所有子文件。也可以不用设置环境变量进行启动,但是不设置环境变量启动的话要每次启动写很多启动参数,比较麻烦,所以做好配置环境变量。在 mongodb 下创建 data 和 logs 目录,以及日志文件mongodb.log。在 /usr/local 目录中创建 mongodb 文件夹。启动 MongoDB(-conf 使用配置文件方式启动)
《mybatis》--大数据量查询解决方案
之前写百万以及千万的导出数据的时候,对于将数据写道csv文件并压缩这里没有什么大问题了,但是出现了其他问题为:1、我们需要将数据从数据库中拿出来,并且在进行装配的时候出现了一些问题。2、对于整体内存安全来说,如果直接将数据从数据库中拿出来百万级别以上的数据对于内存是非常不友好的。当问题出现比较大的时候会直接触发GC,造成瘫痪。目前开发以及项目测试的是更多的使用mybatis来进行开发的,所以本文章讨论以及解决的的就是如何使用mybaits来解决流式查询并单条处理的问题。
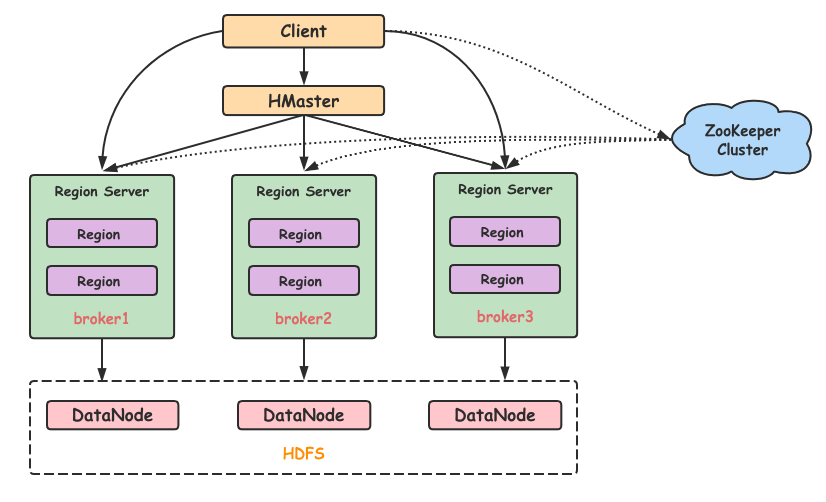
什么是HBase?终于有人讲明白了
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
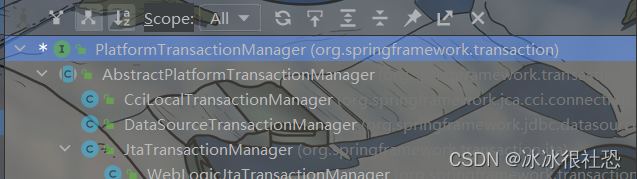
Spring中事务控制的API介绍(PlatformTransactionManager和TransactionDefinition)
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。例如:methodA事务方法调用methodB事务方法时,methodB是继续在调用者methodA的事务中运行呢,还是为自己开启一个新事务运行,这就是由methodB的事务传播行为决定的。属性,同时,Spring 还为我们提供了一个默认的实现类:DefaultTransactionDefinition,该类适用于大多数情况。作用:是一个事务管理器,负责开启、提交或回滚事务。
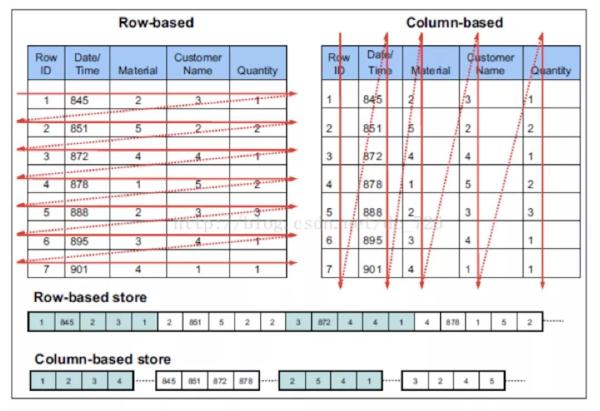
ClickHouse 与mysql等关系型数据库对比
先用一张图帮助理解两者的本质上的区。

Redis 除了用作缓存还能干吗?
Redis 是一种内存键值数据库。它支持多种数据结构,如 String, Hash, List, Set 和 SortedSet。
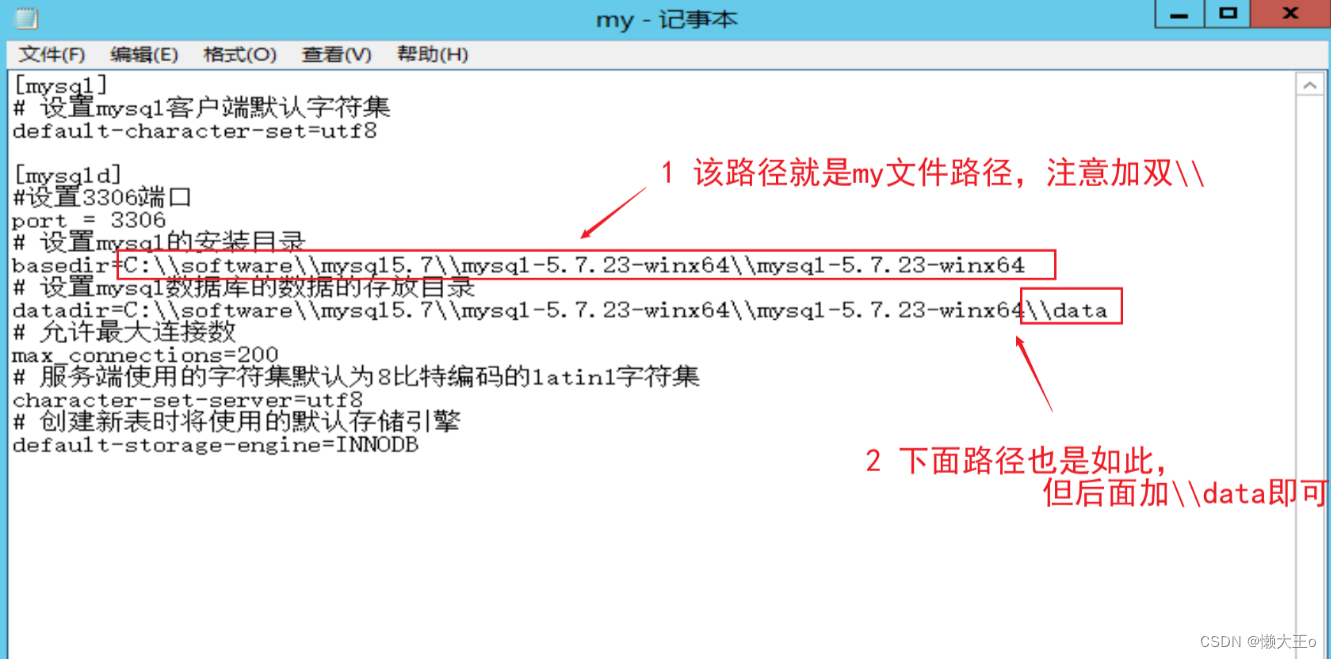
Windows安装MySQL及网络配置
向日葵软件是一种远程控制软件,可以让用户在不同设备之间进行远程桌面访问和文件传输。用户可以通过向日葵软件,在任何具有互联网连接的设备上远程控制其他设备,包括计算机、智能手机和平板电脑。用户只需安装向日葵软件,并使用登录凭据连接到目标设备,就可以实时控制目标设备上的屏幕、键盘和鼠标。向日葵软件还提供了一些辅助功能,如文件传输、远程打印和远程会议等。这使得向日葵软件成为一个方便实用的远程协助工具,适用于个人用户、技术支持人员和企业用户等各种场景。
Web数据库基本知识,SQL基本语法
SQL(Structured Query Language)是一种用于管理和操作关系型数据库管理系统(RDBMS)的特定领域语言。它是一种标准化的语言,用于定义和操作关系型数据库中的数据。SQL允许用户执行诸如查询数据、插入新数据、更新现有数据和删除数据等操作。分为四种DDL:数据库定义语言(define)DML:数据库操作管理语言(manage)DQL:数据库查询语言(query)DCL:数据库控制语言(control)