《mybatis》--大数据量查询解决方案
阿丹-需求/场景:
之前写百万以及千万的导出数据的时候,对于将数据写道csv文件并压缩这里没有什么大问题了,但是出现了其他问题为:
1、我们需要将数据从数据库中拿出来,并且在进行装配的时候出现了一些问题。
2、对于整体内存安全来说,如果直接将数据从数据库中拿出来百万级别以上的数据对于内存是非常不友好的。当问题出现比较大的时候会直接触发GC,造成瘫痪。
目前开发以及项目测试的是更多的使用mybatis来进行开发的,所以本文章讨论以及解决的的就是如何使用mybaits来解决流式查询并单条处理的问题。
解决方案:
使用MyBatis查询超大数据时,为了避免内存溢出(OOM, OutOfMemoryError)问题,可以采用以下几种解决方案:
流式查询 (Stream Result)
- MyBatis 提供了
<select>标签的resultType="void"配合<resultMap>和useResultHandler="true"属性来实现流式查询。通过定义一个ResultHandler接口的实现类,MyBatis会在遍历结果集的过程中逐行调用处理方法,这样每处理一行就释放一行的数据,从而避免一次性加载所有数据到内存中。
<select id="streamingQuery" statementType="CALLABLE" resultType="void"> {your_query_here} </select>在Java代码中:
sqlSession.select("streamingQuery", parameter, new ResultHandler() { @Override public void handleResult(ResultContext context) { Object object = context.getResultObject(); // 处理单行数据并确保及时释放资源 } });- MyBatis 提供了
分页查询 (Pagination)
- 如果业务允许,对数据进行分页查询是最常见的做法,每次仅从数据库获取一部分数据。
- 在MyBatis中可以通过动态SQL或者参数绑定实现分页,例如使用PageHelper等第三方分页插件。
游标查询 (Cursor)
- 对于支持游标的数据库(如Oracle、PostgreSQL等),可以利用数据库层面的游标特性,在不关闭连接的情况下逐步读取结果集。
- MyBatis 3.4.6版本及更高版本直接支持JDBC
ResultSet类型的返回值,结合Statement#setFetchSize()方法可以实现类似游标的效果,有效地控制内存占用。
优化SQL查询
- 减少不必要的字段查询,只取出需要的列。
- 使用JOIN或子查询时,注意是否能进一步优化SQL语句以减少结果集大小。
- 避免在应用层做大量计算和数据转换,尽量让数据库完成复杂过滤和聚合操作。
分布式处理或批处理
- 如果数据量实在太大,可以考虑将任务分解为多个小任务,每个任务处理部分数据,然后汇总结果。
数据库端缓存与分片策略
- 在数据库层面对大表进行分区或索引优化,减少单次查询的数据量。
选择哪种方案取决于具体的应用场景、数据库类型以及系统架构设计。流式查询通常是在内存限制严格且必须一次性处理大量数据时的最佳实践。
相关文章:
MySQL慢查询日志slowlog
慢速查询日志记录的是执行时间超过秒和检查的行数超过的SQL语句,这些语句通常是需要进行优化的。官方参考文档:https://dev.mysql.com/doc/refman/8.0/en/slow-query-log.html。
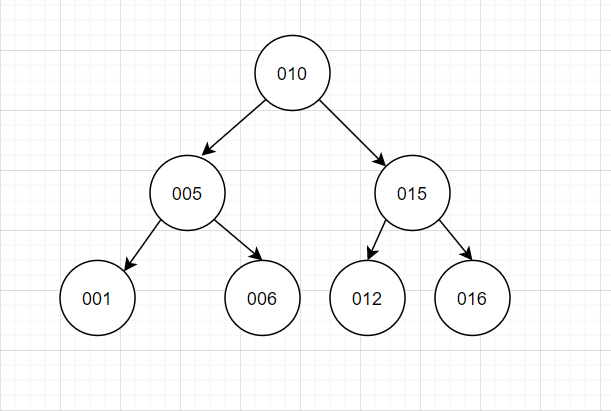
一文搞懂MySQL索引
官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。
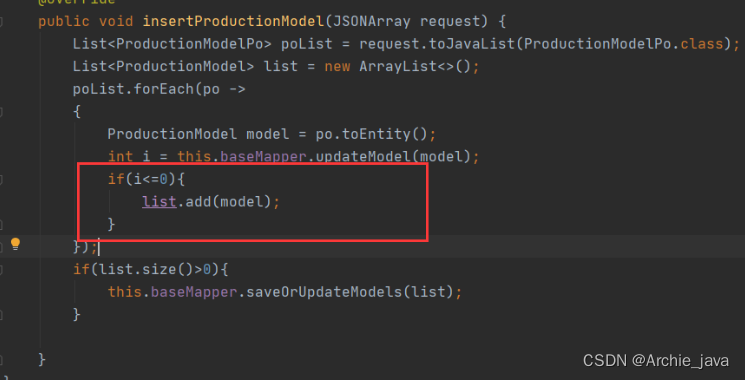
ON DUPLICATE KEY UPDATE 导致mysql自增主键ID跳跃增长
具体解决方案可以根据项目来选择,如果项目不大,可以考虑1和2。如果不考虑高并发问题,可以考虑3。
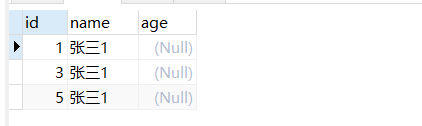
mysql唯一索引与null
根据NULL的定义,NULL表示的是未知,因此两个NULL比较的结果既不相等,也不不等,结果仍然是未知。根据这个定义,多个NULL值的存在应该不违反唯一约束,所以是合理的,在oracel也是如此。在mysql 的innodb引擎中,是允许在唯一索引的字段中出现多个null值的。有上面的表和数据可以看出,查询多条数据。

详解mybatis的insert,update,delete返回值
为什么要提数据的事呢,是因为据说这个save返回的就是插入的数据的条数。但是遗憾的是,我们的这个user怎么能没有id呢,没有id有怎么查,怎么删,怎么改。进来的是没有id的user,出去的是有id的user,真是太厉害了,没想到不仅把返回值改变了,连参数都发生了改变,真是太神奇了。keyProperty=“id” 这是id就是绑定的id,那我就疑惑了,这绑定的哪个id啊。这样一搞,如果插入成功的话返回的是1,如果不成功的话返回的是-1。我让你删id是222222的,我还没创建呢,看你怎么删。
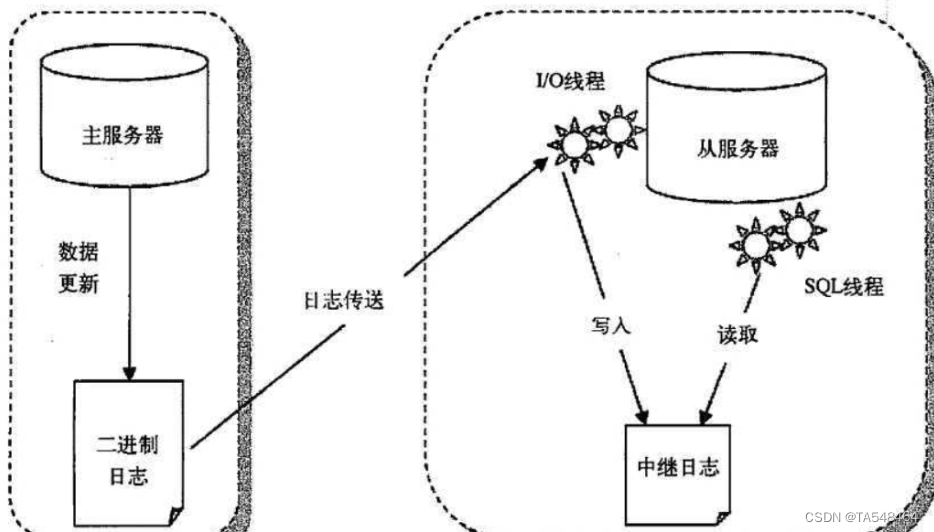
MySQL主从复制(基于binlog日志方式)
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。主从复制的作用1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。3.读写分离,使数据库能支撑更大的并发。a.从服务器可以执行查询工作(就是我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
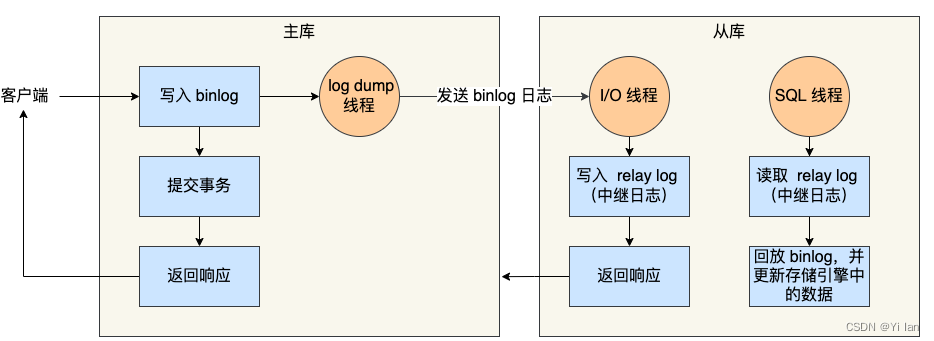
MYSQL 主从复制 --- binlog
在 Master 端并不 Care 有多少个 Slave 连上了自己,只要有 Slave 的 IO 线程通过了连接认证,向他请求指定位置之后的 Binary Log 信息,他就会按照该 IO 线程的要求,读取自己的 Binary Log 信息,返回给 Slave 的 IO 线程。默认MySQL是未开启该日志的。如果读压力加大,就需要更多的 slave 来解决,但是如果slave的复制全部从 master 复制,势必会加大 master 的复制IO的压力,所以就出现了级联复制,减轻 master 压力。
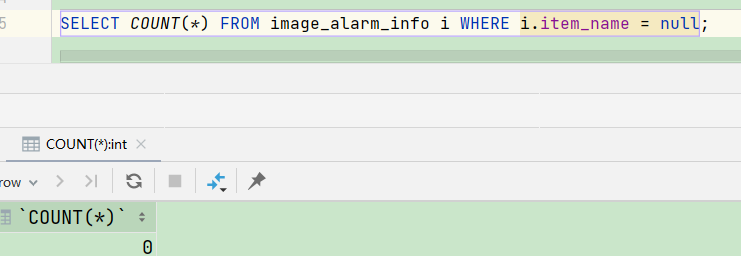
MySQL 中 is null 和 =null 的区别
如果 set ANSI_NULLS为 ON 时,表示SQL语句遵循SQL-92标准;如果 set ANSI_NULLS 为 OFF 时,表示不遵从 SQL-92 标准。但SQL-92 标准要求对null的 = 或不等于 (!= ,) 比较取值都为 false,也就是 =null 或者 null,返回的都是false。null 在MySQL中不代表任何值,通过运算符是得不到任何结果的,因此只能用 is null(默认情况)MySQL 中 null 不代表任务实际的值,类似于一个未知数。
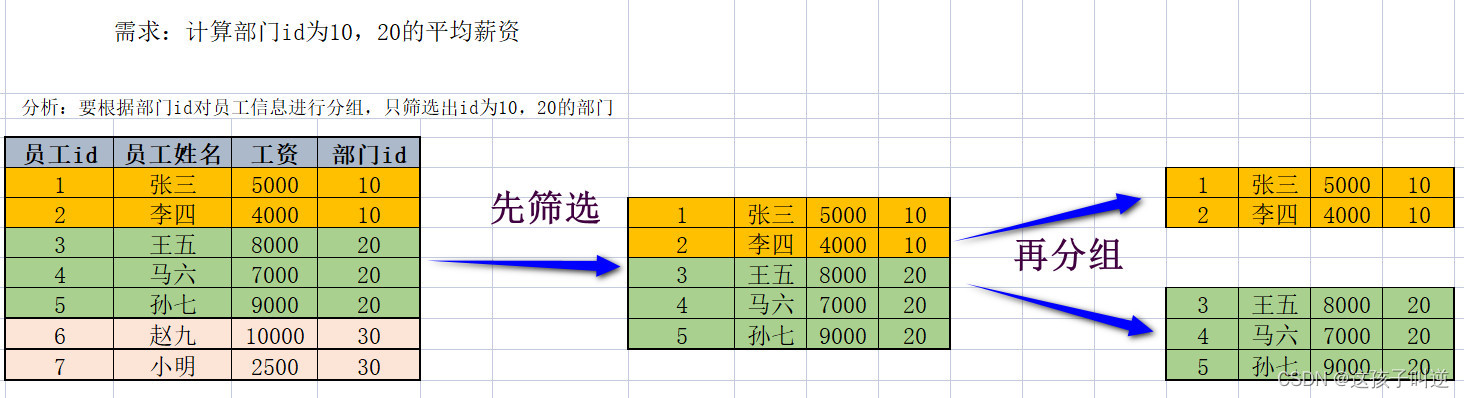
MySQL数据库查询语句之组函数,子查询语句
当一个SQL的执行需要借助另一个SQL的执行结果时,则需要进行SQL嵌套,该语法结构称之为子查询。先筛选出符合要求的数据,再对符合要求的数据进行分组时,分组的工作量会被减少,效率更高。先确定从哪张表进行操作-->对表中数据进行分组-->基于分组结果进行查询操作。执行顺序:优先执行小括号内的子SQL,根据子SQL的执行结果再执行外层SQL。执行顺序:from-->where-->group by-->select。执行顺序:from-->group by-->select。

mysql开启可以使用IP有权限访问
为实际的IP地址和你想要设置的密码。请小心操作,并确保你了解每个命令的作用。如果你对此有任何疑问,最好咨询经验丰富的数据库管理员。来设置或修改用户的密码。相反,你需要分两步来完成这个过程:首先创建或修改用户,并设置密码;然后授予相应的权限。用户应该能够从指定的内网IP地址访问MySQL服务器。用户已存在并且你只是想更改其密码或允许从另一个地址访问,使用。在MySQL 8.0及更高版本中,语句的语法有所变化。替换为你的内网IP地址,
雪花算法生成ID、UUID生成ID和MySql自增ID优缺点分析
综上所述,UUID适用于分布式系统和需要保密的场景,雪花ID适用于分布式系统和高并发环境,MySQL自增ID适用于单机系统和高效查询的场景。根据具体的业务需求和系统架构,选择合适的主键类型。通过本文的介绍和对比,希望读者能够更好地理解在MySQL中不推荐使用UUID或者雪花ID作为主键的原因,并能够根据实际情况做出明智的选择。在MySQL中,使用自增整数作为主键是一种常见的做法,因为它具有较小的存储空间、高效的索引和自动增长的特性。然而,具体选择何种主键类型还是要根据具体的业务需求和数据特点来决定。
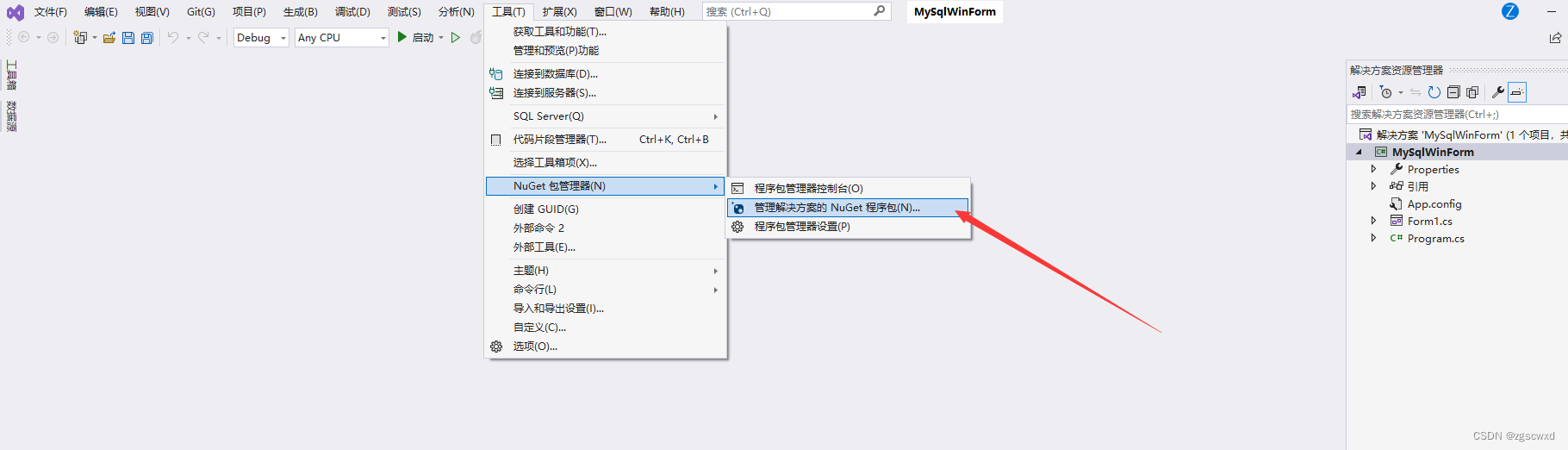
【小白专用】C# 连接 MySQL 数据库
C# 连接 MySQL 数据库
Mybatis-Plus 自动属性填充与自定义Insert into语句顺序&MyBatisPlus中使用 @TableField完成字段自动填充
TableField注解是MyBatisPlus提供的用于实体类字段的注解,用于配置字段的属性和行为。其中,我们可以通过设置fill属性来实现字段自动填充的功能。通过使用@TableField注解和自定义的MetaObjectHandler填充处理器,我们可以很方便地实现字段的自动填充功能。在MyBatisPlus中,这个功能可以简化我们的开发工作,提高代码的可维护性和可读性。希望本文对大家在使用MyBatisPlus进行开发时有所帮助!
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
MySQL索引优化实战
对于这种varchar(255)的大字段可能会比较占用磁盘空间,可以稍微优化下,比如针对这个字段的前20个 字符建立索引,就是说,对这个字段里的每个值的前20个字符放在索引树里,类似于 KEY index(name(20),age,position)。此时你在where条件里搜索的时候,如果是根据name字段来搜索,那么此时就会先到索引树里根据name 字段的前20个字符去搜索,定位到之后前20个字符的前缀匹配的部分数据之后,再回到聚簇索引提取出来 完整的name字段值进行比对。
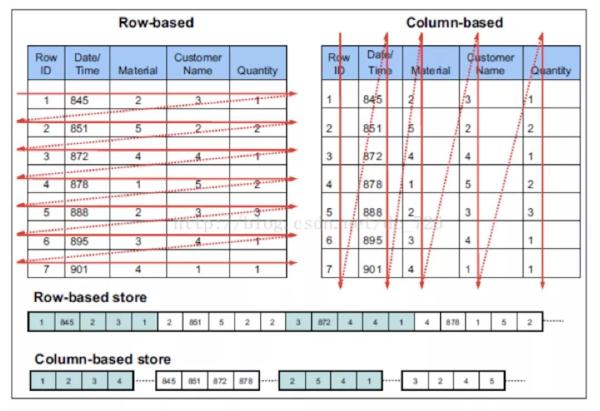
ClickHouse 与mysql等关系型数据库对比
先用一张图帮助理解两者的本质上的区。
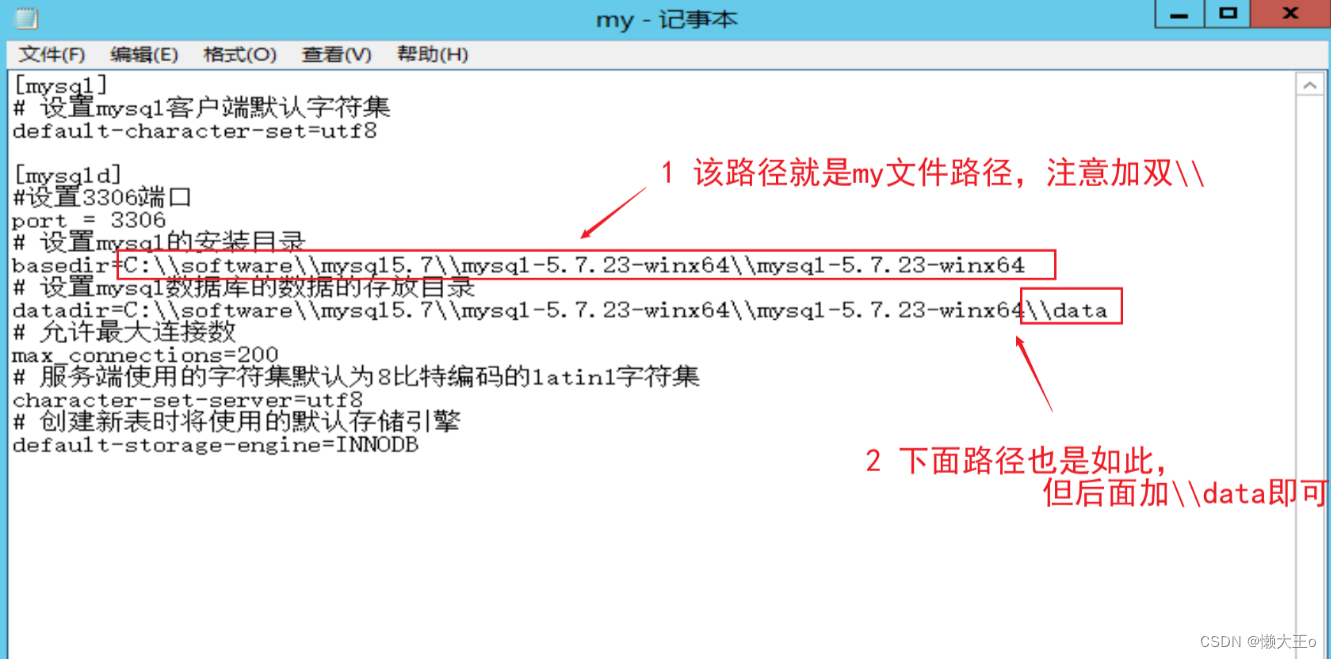
Windows安装MySQL及网络配置
向日葵软件是一种远程控制软件,可以让用户在不同设备之间进行远程桌面访问和文件传输。用户可以通过向日葵软件,在任何具有互联网连接的设备上远程控制其他设备,包括计算机、智能手机和平板电脑。用户只需安装向日葵软件,并使用登录凭据连接到目标设备,就可以实时控制目标设备上的屏幕、键盘和鼠标。向日葵软件还提供了一些辅助功能,如文件传输、远程打印和远程会议等。这使得向日葵软件成为一个方便实用的远程协助工具,适用于个人用户、技术支持人员和企业用户等各种场景。

深入理解Mysql事务隔离级别与锁机制
我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。这些问题的本质都是数据库的多事务并发问题,为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制,用一整套机制来解决多事务并发问题。接下来,我们会深入讲解这些机制,让大家彻底理解数据库内部的执行原理。
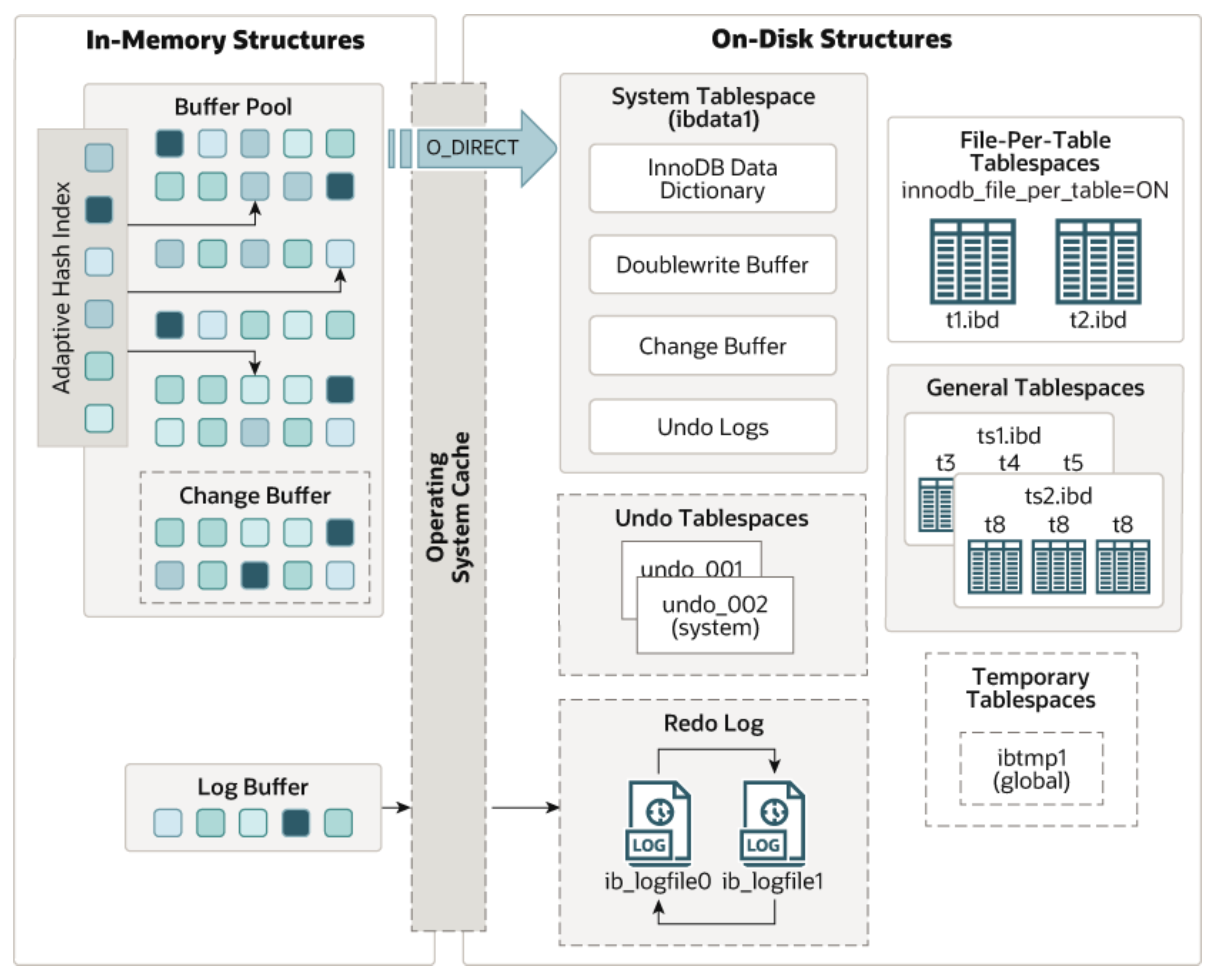
MySQL是如何保证数据不丢失的?
上篇文章《InnoDB在SQL查询中的关键功能和优化策略》对InnoDB的查询操作和优化事项进行了说明。但是,MySQL作为一个存储数据的产品,怎么确保数据的持久性和不丢失才是最重要的,感兴趣的可以跟随本文一探究竟。
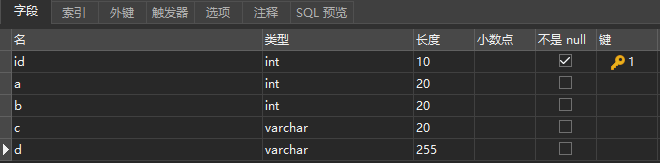
where查询条件的字段顺序打乱会影响命中索引吗?
答案是:不影响我们的where后边条件字段打乱会影响命中索引吗?先来进行下边的实验:可以看到实验结果,where条件字段顺序没有按照索引的字段顺序,依然不影响命中索引。因为Mysql中有查询优化器,会自动优化查询顺序。

MySQL删除会走索引吗
MySQL是关系型数据库管理系统的一种, 网站在进行数据的增删改查的时候,我们往往需要使用 MySQL 数据库。而删除操作就是在 MySQL 数据库中删除指定的数据或者表格的操作。

Mybatis练习
文章目录配置文件实现CRUD环境准备查询所有数据编写接口方法编写SQL语句编写测试方法起别名解决上述问题使用resultMap解决上述问题小结查询详情编写接口方法编写SQL语句编写测试方法参数占位符parameterType使用SQL语句中特殊字段处理多条件查询编写接口方法编写SQL语句编写测试方法动态SQL单个条件(动态SQL)编写接口方法编写SQL语句编写测试方法添加数据编写接口方法编写SQL语句编写测试方法添加-主键返回修改编写接口方法编写SQL语句编写测试方法删除一行数据编写接口方法编写SQL语句编

Mybatis 代理开发和核心配置文件
之前我们写的代码是基本使用方式,它也存在硬编码的问题,如下:这里调用方法传递的参数是映射配置文件中的 namespace.id值。这样写也不便于后期的维护。如果使用 Mapper 代理方式(如下图)则不存在硬编码问题。解决原生方式中的硬编码简化后期执行SQLMybatis 官网也是推荐使用 Mapper 代理的方式。

Mybatis概述和快速入门
(1)Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。程序员直接编写原生态sql,可以严格控制sql执行性能,灵活度高。(2)MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
Linux多种方法安装MySQL
源码安装:优点是安装包比较小,只有十多M,缺点是安装依赖的库多,安装编译时间长,安装步骤复杂容易出错。使用官方编译好的二进制文件安装:优点是安装速度快,安装步骤简单,缺点是安装包很大,300M左右。yum安装。rpm安装。

Linux中mysql 默认安装位置&Linux 安装 MySQL
MySQL在Linux系统上的默认安装位置是目录。这是MySQL服务器的数据目录,包含所有数据库文件。通过检查MySQL二进制文件的路径,我们可以确认MySQL是否正确安装。在目录中,MySQL使用一系列文件和子目录来组织和存储数据。确保理解MySQL数据目录的结构对于管理和维护MySQL数据库至关重要。按照顺序安装即可解决。

MySQL数据库索引以及使用唯一索引实现幂等性
一次和多次请求某一个资源对于资源本身应该具有同样的结果任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
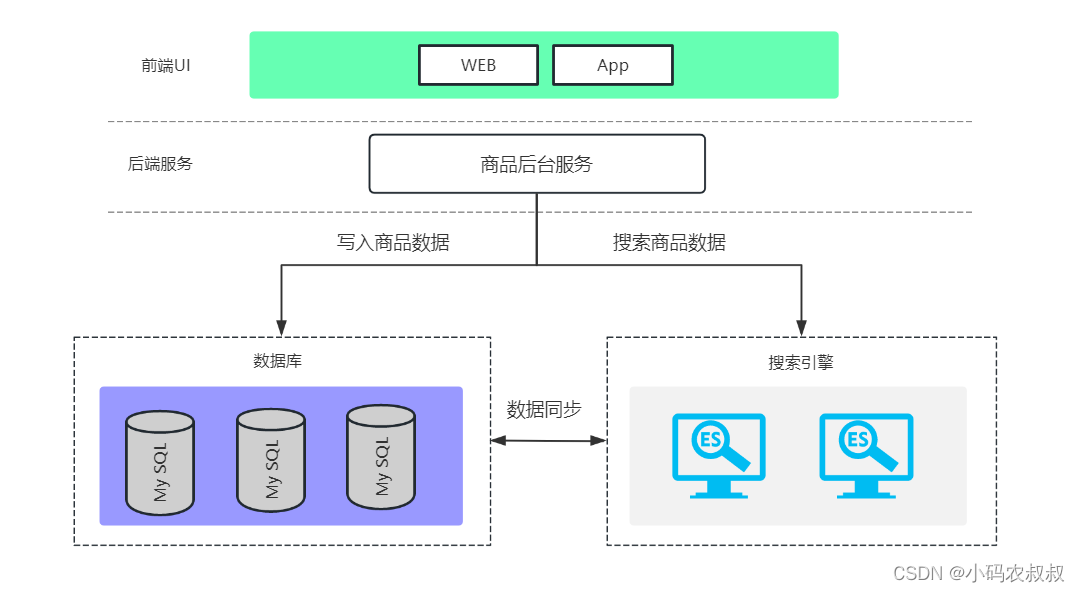
【微服务】mysql + elasticsearch数据双写设计与实现
在很多电商网站中,对商品的搜索要求很高,主要体现在页面快速响应搜索结果。这就对服务端接口响应速度提出了很高的要求。

基于 MySQL 多通道主主复制的机房容灾方案
文章中介绍了多种 MySQL 高可用技术,并介绍了根据自身需求选择多通道主主复制技术的过程和注意事项。

MySQL中的 增 删 查 改(CRUD)
文章浏览阅读1.8k次,点赞60次,收藏56次。insert into 表名 value(数据,数据),.......;可以单行,多行插入。为查询结果的列取别名select 表达式/列名as 别名 from 表名;去重:DISTINCTselect distinct 单列/多列 from 表名;会去除查询结果中的重复项(只保留一项)select 条件查询的执行顺序遍历表中的每个记录把当前记录的值带入条件,根据条件进行筛选如果这条记录满足条件,保留并进行列上的表达式的计算如果有 order by 会在所有行都被获取到之后(表