hive常用SQL函数及案例
1 函数简介
Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的函数。
好处:避免用户反复写逻辑,可以直接拿来使用。
重点:用户需要知道函数叫什么,能做什么。
Hive提供了大量的内置函数,按照其特点可大致分为如下几类:单行函数、聚合函数、炸裂函数、窗口函数。
以下命令可用于查询所有内置函数的相关信息。
(1)查看系统内置函数
show functions;
(2)查看内置函数用法
desc function upper;
(3)查看内置函数详细信息
desc function extended upper;
2 单行函数
单行函数的特点是一进一出,即输入一行,输出一行。
单行函数按照功能可分为如下几类: 日期函数、字符串函数、集合函数、数学函数、流程控制函数等。
(1)算术运算函数
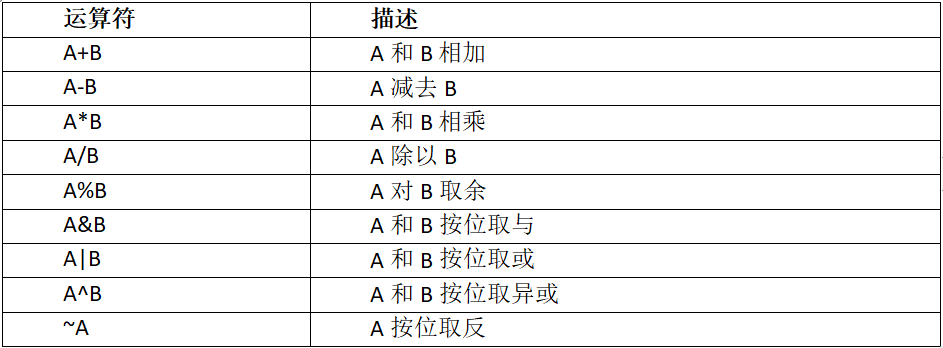
案例实操:查询出所有员工的薪水后加1显示
select sal + 1 from emp;
3 数值函数
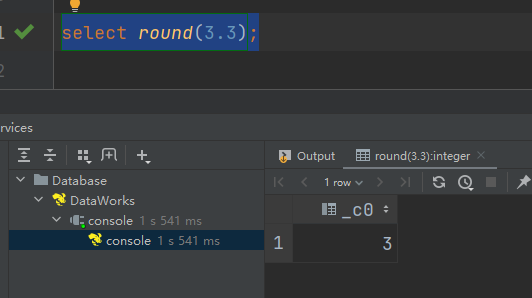
(1)round:四舍五入
select round(3.3);
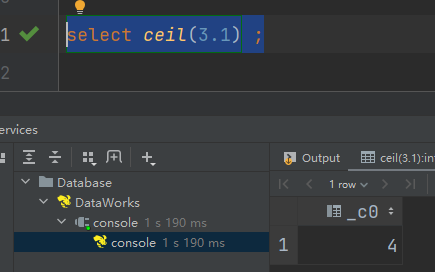
(2)ceil:向上取整
select ceil(3.1) ;
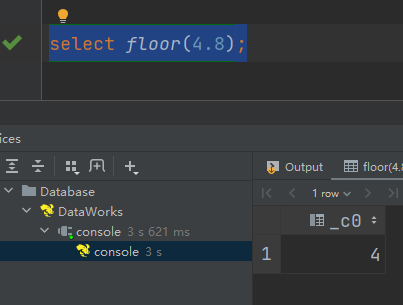
(3)floor:向下取整
select floor(4.8);
4 字符串函数
(1) substring:截取字符串
语法一:substring(string A, int start)
返回值:string
说明:返回字符串A从start位置到结尾的字符串
语法二:substring(string A, int start, int len)
返回值:string
说明:返回字符串A从start位置开始,长度为len的字符串
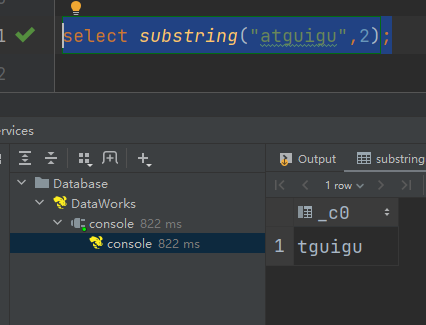
说明:获取第二个字符以后的所有字符:
说明:获取倒数第三个字符以后的所有字符
select substring("atguigu",-3);

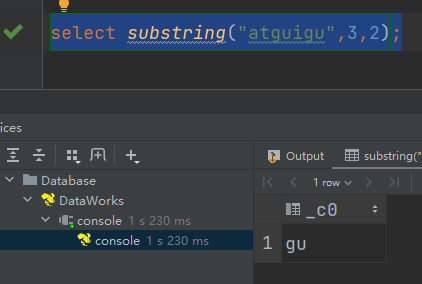
说明:从第3个字符开始,向后获取2个字符
select substring("atguigu",3,2);
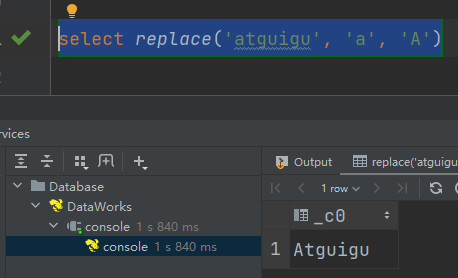
(2) replace :替换
语法:replace(string A, string B, string C)
返回值:string
说明:将字符串A中的子字符串B替换为C
select replace('atguigu', 'a', 'A')
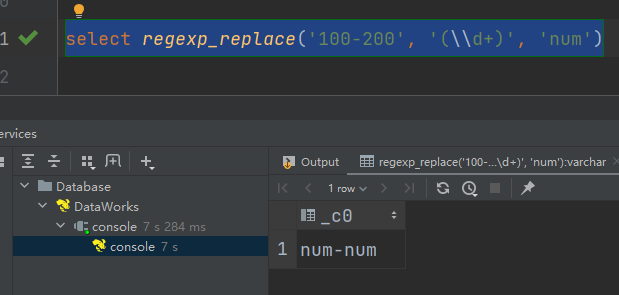
(3)regexp_replace:正则替换
语法:regexp_replace(string A, string B, string C)
返回值:string
说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符。
select regexp_replace('100-200', '(\\d+)', 'num')
(4)regexp:正则匹配
语法:字符串 regexp 正则表达式
返回值:boolean
说明:若字符串符合正则表达式,则返回true,否则返回false。
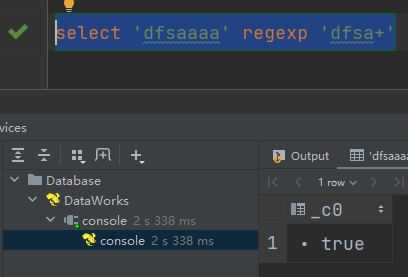
说明:正则匹配成功,输出true
select 'dfsaaaa' regexp 'dfsa+'
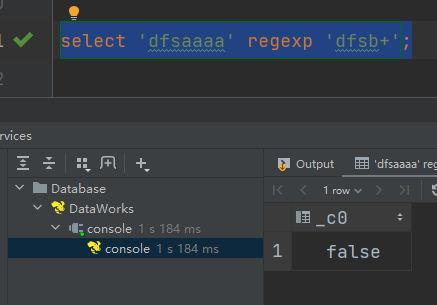
说明:正则匹配失败,输出false
select 'dfsaaaa' regexp 'dfsb+';
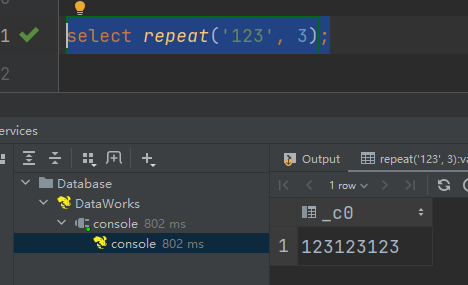
(5)repeat:重复字符串
语法:repeat(string A, int n)
返回值:string
说明:将字符串A重复n遍。
select repeat('123', 3);
(6)split :字符串切割
语法:split(string str, string pat)
返回值:array
说明:按照正则表达式pat匹配到的内容分割str,分割后的字符串,以数组的形式返回。
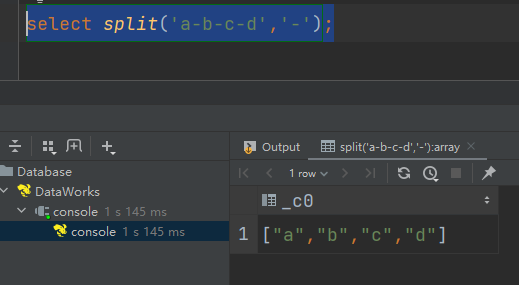
(7)nvl :替换null值
语法:nvl(A,B)
说明:若A的值不为null,则返回A,否则返回B。
select nvl(null,1);
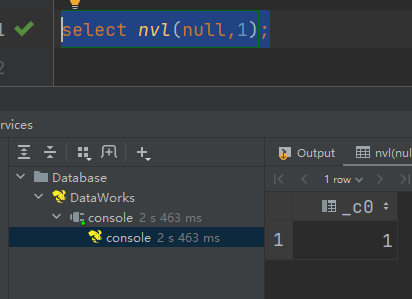
(8)concat :拼接字符串
语法:concat(string A, string B, string C, ……)
返回:string
说明:将A,B,C……等字符拼接为一个字符串
select concat('beijing','-','shanghai','-','shenzhen');
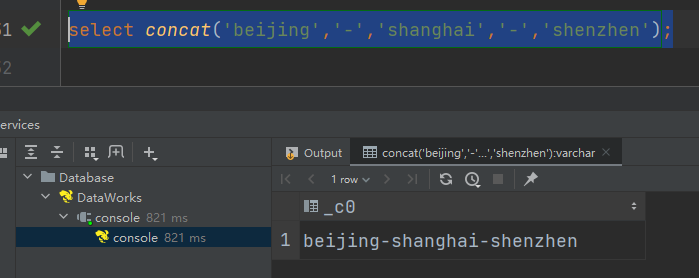
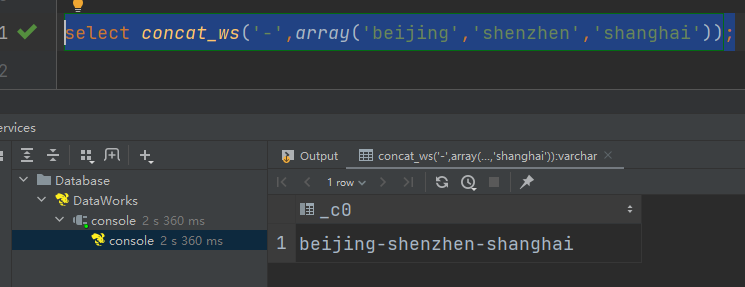
(9)concat_ws:以指定分隔符拼接字符串或者字符串数组
语法:concat_ws(string A, string…| array(string))
返回值:string
说明:使用分隔符A拼接多个字符串,或者一个数组的所有元素。
(10)get_json_object:解析json字符串
语法:get_json_object(string json_string, string path)
返回值:string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
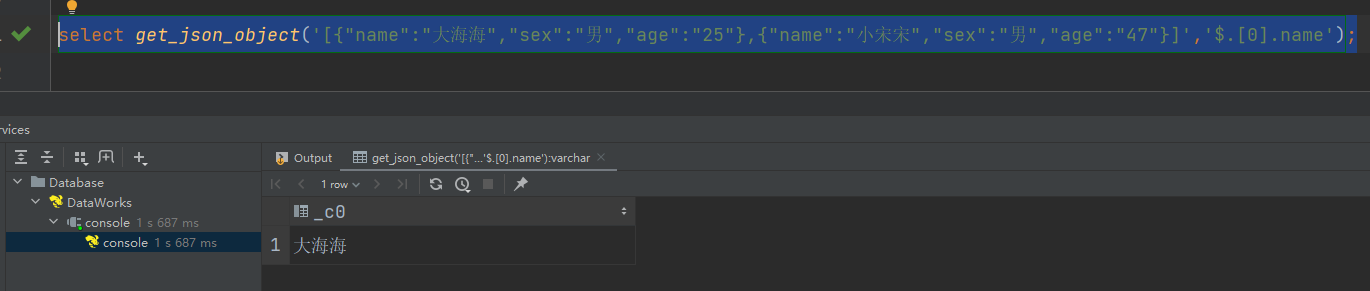
获取json数组里面的json具体数据
select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0].name');
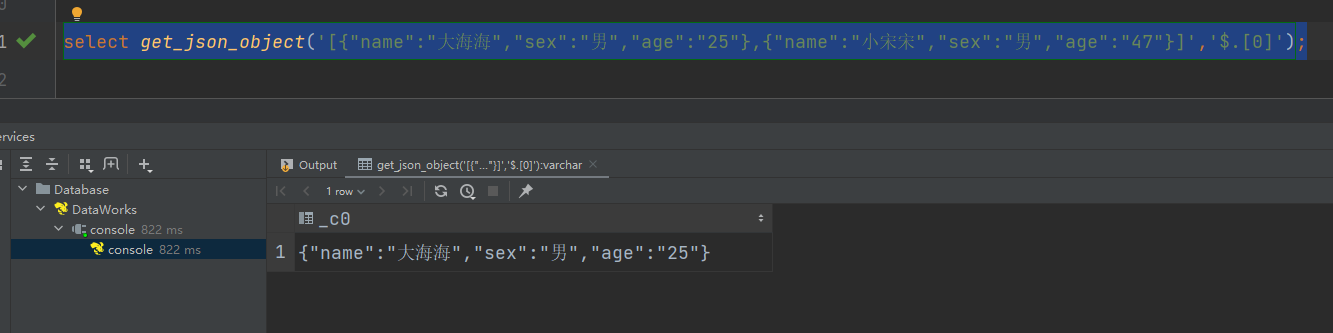
获取json数组里面的数据
select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0]');
5 日期函数
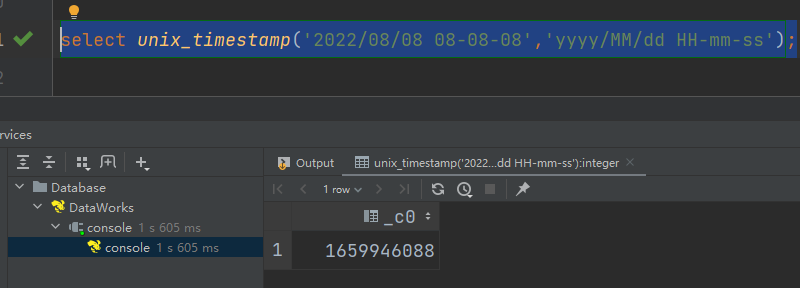
(1)unix_timestamp:返回当前或指定时间的时间戳
语法:unix_timestamp()
返回值:bigint
说明:-前面是日期后面是指,日期传进来的具体格式
select unix_timestamp('2022/08/08 08-08-08','yyyy/MM/dd HH-mm-ss');
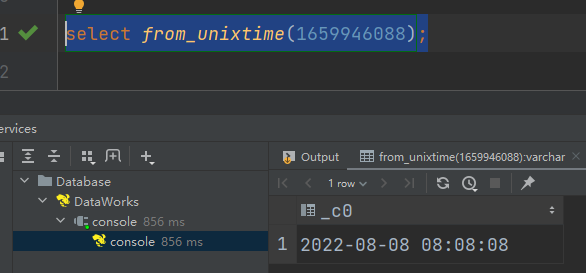
(2)from_unixtime:转化UNIX时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式
语法:from_unixtime(bigint unixtime[, string format])
返回值:string
select from_unixtime(1659946088);
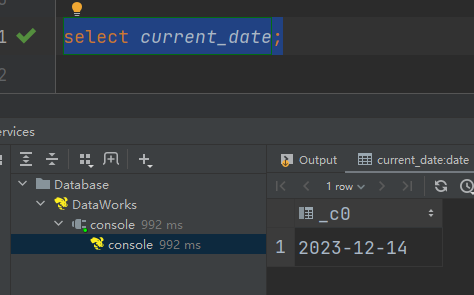
(3)current_date:当前日期
select current_date;
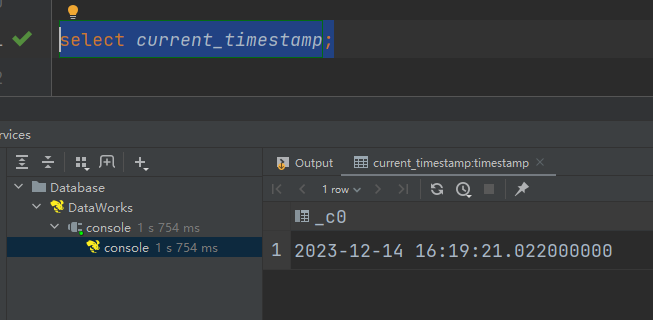
(4)current_timestamp:当前的日期加时间,并且精确的毫秒
select current_timestamp;
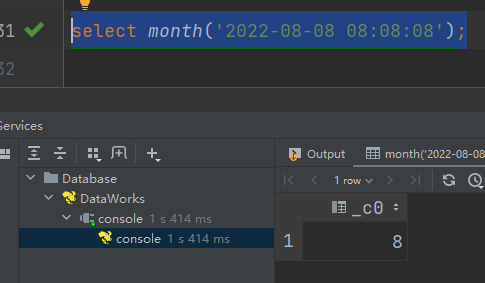
(5)month:获取日期中的月
语法:month (string date)
返回值:int
select month('2022-08-08 08:08:08');
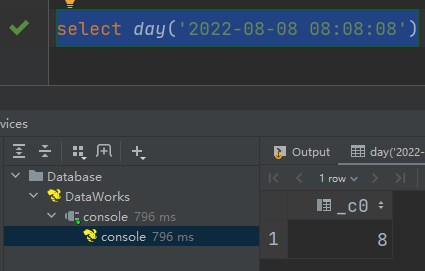
(6)day:获取日期中的日
语法:day (string date)
返回值:int
select day('2022-08-08 08:08:08')
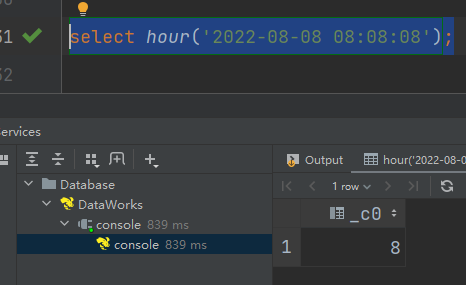
(7)hour:获取日期中的小时
语法:hour (string date)
返回值:int
select hour('2022-08-08 08:08:08');
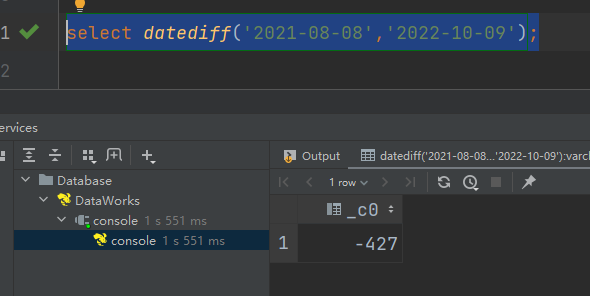
(8)datediff:两个日期相差的天数(结束日期减去开始日期的天数)
语法:datediff(string enddate, string startdate)
返回值:int
select datediff('2021-08-08','2022-10-09');
(9)date_add:日期加天数
语法:date_add(string startdate, int days)
返回值:string
说明:返回开始日期 startdate 增加 days 天后的日期
select date_add('2022-08-08',2);

(10)date_sub:日期减天数
语法:date_sub (string startdate, int days)
返回值:string
说明:返回开始日期startdate减少days天后的日期。
select date_sub('2022-08-08',2);

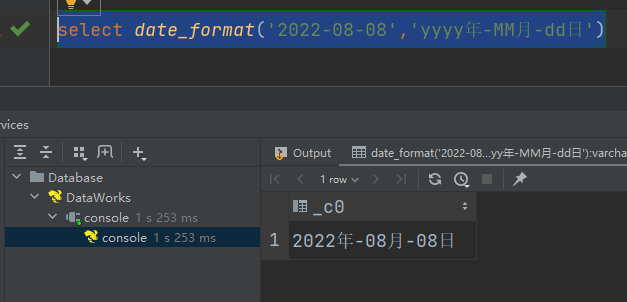
(11)date_format:将标准日期解析成指定格式字符串
select date_format('2022-08-08','yyyy年-MM月-dd日')
6 流程控制函数
(1)case when:条件判断函数
语法一:case when a then b [when c then d]* [else e] end
返回值:T
说明:如果a为true,则返回b;如果c为true,则返回d;否则返回 e
select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end from location;
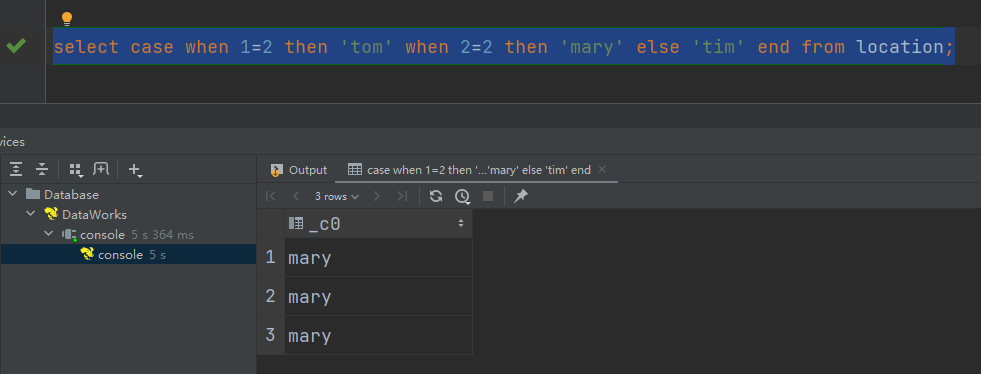
语法二: case a when b then c [when d then e]* [else f] end
返回值: T
说明:如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from location;
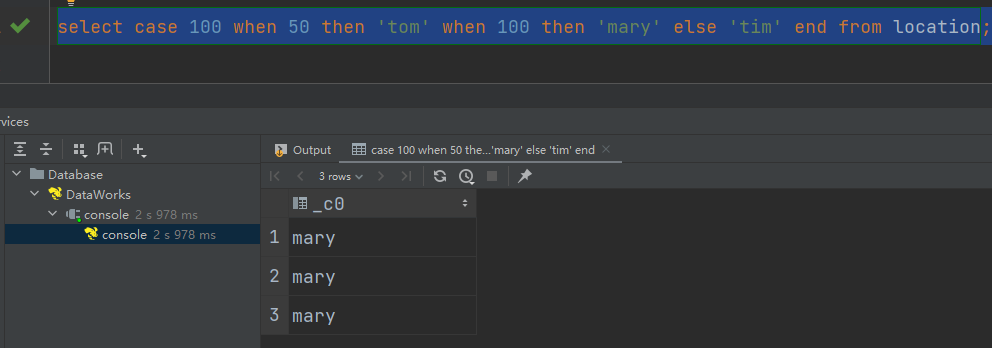
(2)if: 条件判断,类似于Java中三元运算符
语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值:T
说明:当条件testCondition为true时,返回valueTrue;否则返回valueFalseOrNull
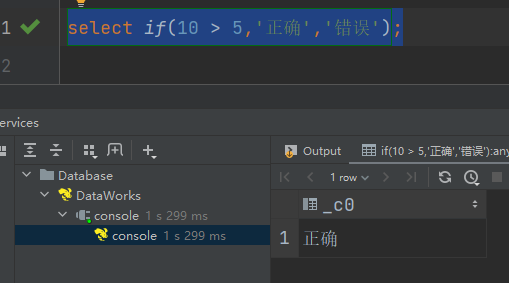
条件满足,输出正确
select if(10 > 5,'正确','错误');
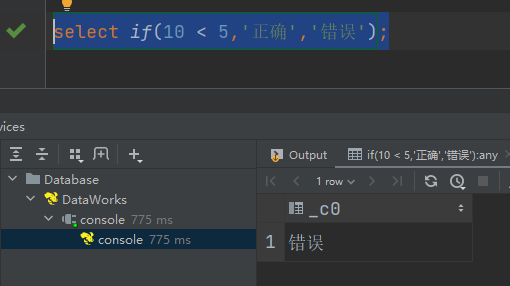
条件满足,输出错误
select if(10 < 5,'正确','错误');
7 集合函数
(1)size:集合中元素的个数
select size(array('beijing','shenzhen','shanghai')) from location;

(2)map:创建map集合
语法:map (key1, value1, key2, value2, …)
说明:根据输入的key和value对构建map类型
select map('xiaohai',1,'dahai',2);
(3)map_keys: 返回map中的key
select map_keys(map('xiaohai',1,'dahai',2));
(4)map_values: 返回map中的value
select map_values(map('xiaohai',1,'dahai',2));

(5)array 声明array集合
语法:array(val1, val2, …)
说明:根据输入的参数构建数组array类
select array('1','2','3','4');

(6)array_contains: 判断array中是否包含某个元素
select array_contains(array('a','b','c','d'),'a');
(7)sort_array:将array中的元素排序
select sort_array(array('a','d','c'));
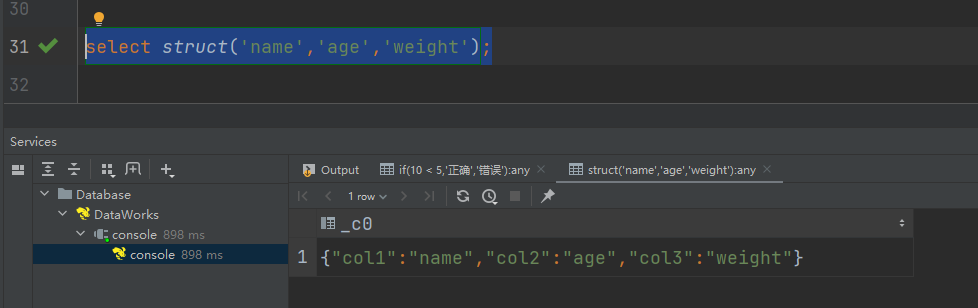
(8)struct声明struct中的各属性
语法:struct(val1, val2, val3, …)
说明:根据输入的参数构建结构体struct类
select struct('name','age','weight');
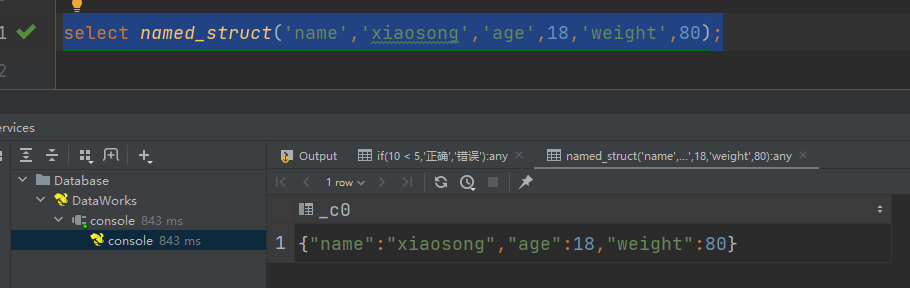
(9)named_struct声明struct的属性和值
select named_struct('name','xiaosong','age',18,'weight',80);
8 高级聚合函数
(1)collect_list 收集并形成list集合,结果不去重
select
sex,
collect_list(job)
from
employee
group by
sex
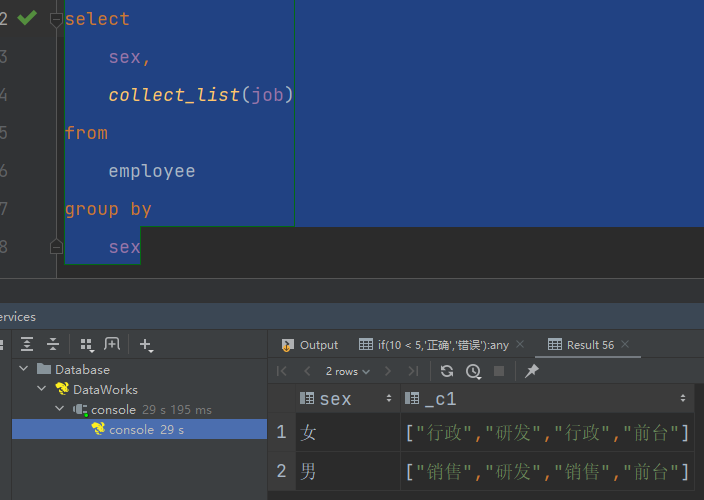
(2) collect_set 收集并形成set集合,结果去重
select
sex,
collect_set(job)
from
employee
group by
sex

9 常用窗口函数
参考以下文章:
开窗函数的使用详解(聚合函数图文详解)
原文链接:https://blog.csdn.net/m0_52606060/article/details/129150481
开窗函数的使用详解(窗口范围ROWS与RANGE图文详解)
原文链接:https://blog.csdn.net/m0_52606060/article/details/129132985
10 自定义函数
参考以下文章:
hive自定义函数及案例
原文链接:https://blog.csdn.net/m0_52606060/article/details/134826464
相关文章:
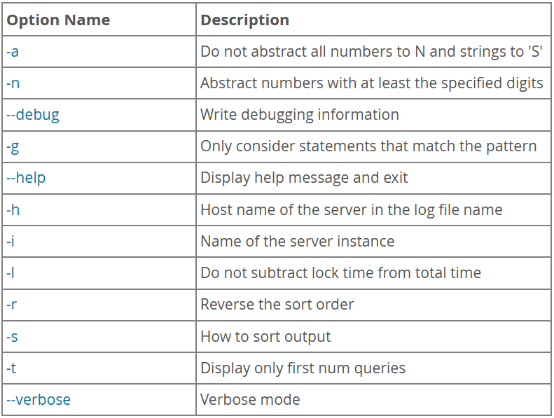
MySQL慢查询日志slowlog
慢速查询日志记录的是执行时间超过秒和检查的行数超过的SQL语句,这些语句通常是需要进行优化的。官方参考文档:https://dev.mysql.com/doc/refman/8.0/en/slow-query-log.html。
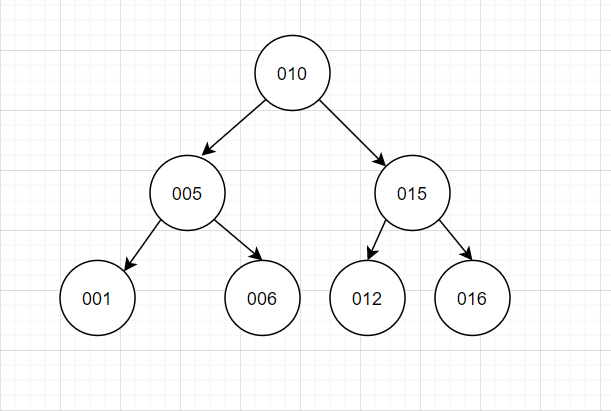
一文搞懂MySQL索引
官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。
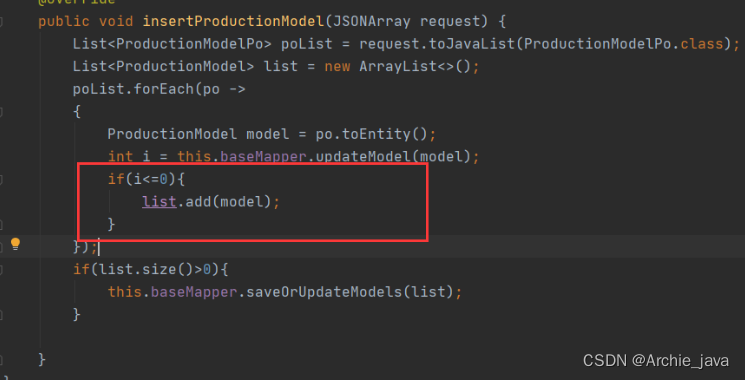
ON DUPLICATE KEY UPDATE 导致mysql自增主键ID跳跃增长
具体解决方案可以根据项目来选择,如果项目不大,可以考虑1和2。如果不考虑高并发问题,可以考虑3。
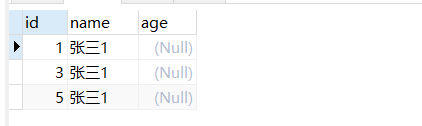
mysql唯一索引与null
根据NULL的定义,NULL表示的是未知,因此两个NULL比较的结果既不相等,也不不等,结果仍然是未知。根据这个定义,多个NULL值的存在应该不违反唯一约束,所以是合理的,在oracel也是如此。在mysql 的innodb引擎中,是允许在唯一索引的字段中出现多个null值的。有上面的表和数据可以看出,查询多条数据。
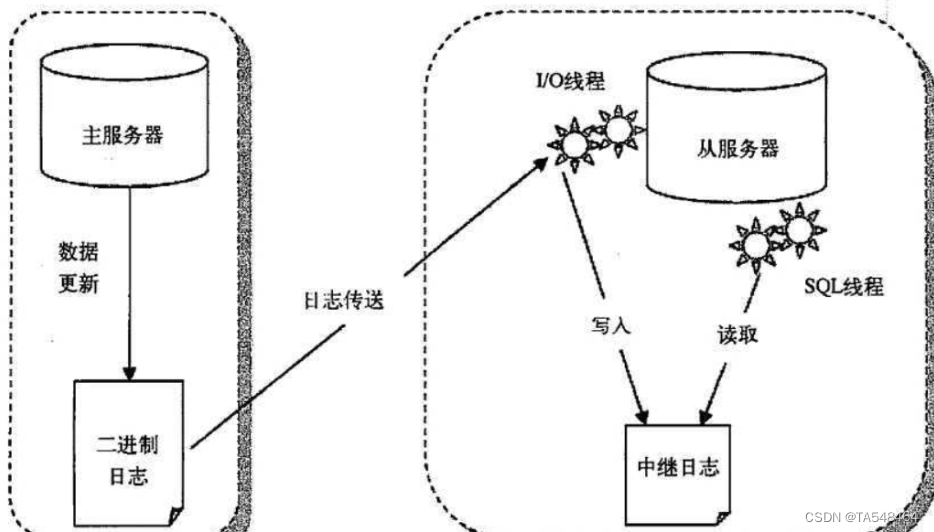
MySQL主从复制(基于binlog日志方式)
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。主从复制的作用1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。3.读写分离,使数据库能支撑更大的并发。a.从服务器可以执行查询工作(就是我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
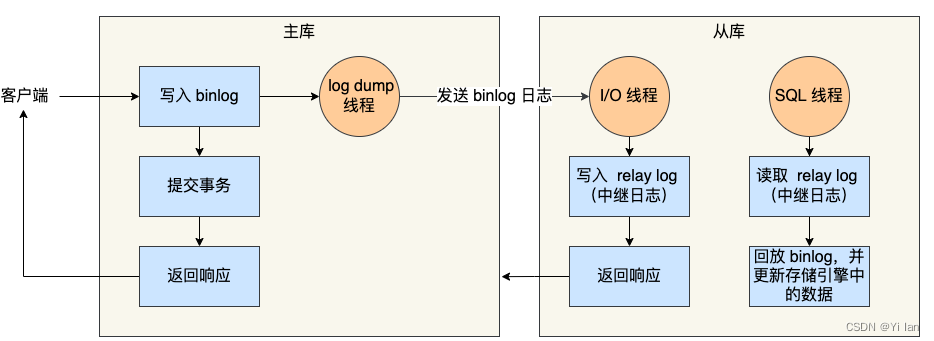
MYSQL 主从复制 --- binlog
在 Master 端并不 Care 有多少个 Slave 连上了自己,只要有 Slave 的 IO 线程通过了连接认证,向他请求指定位置之后的 Binary Log 信息,他就会按照该 IO 线程的要求,读取自己的 Binary Log 信息,返回给 Slave 的 IO 线程。默认MySQL是未开启该日志的。如果读压力加大,就需要更多的 slave 来解决,但是如果slave的复制全部从 master 复制,势必会加大 master 的复制IO的压力,所以就出现了级联复制,减轻 master 压力。
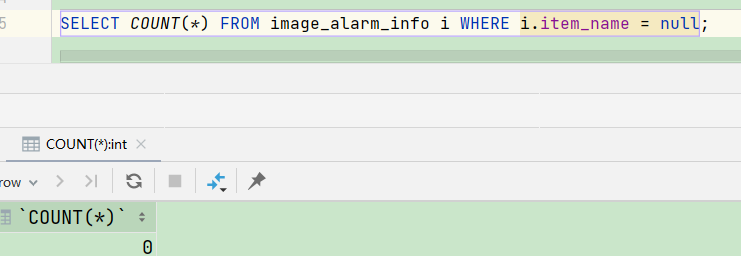
MySQL 中 is null 和 =null 的区别
如果 set ANSI_NULLS为 ON 时,表示SQL语句遵循SQL-92标准;如果 set ANSI_NULLS 为 OFF 时,表示不遵从 SQL-92 标准。但SQL-92 标准要求对null的 = 或不等于 (!= ,) 比较取值都为 false,也就是 =null 或者 null,返回的都是false。null 在MySQL中不代表任何值,通过运算符是得不到任何结果的,因此只能用 is null(默认情况)MySQL 中 null 不代表任务实际的值,类似于一个未知数。
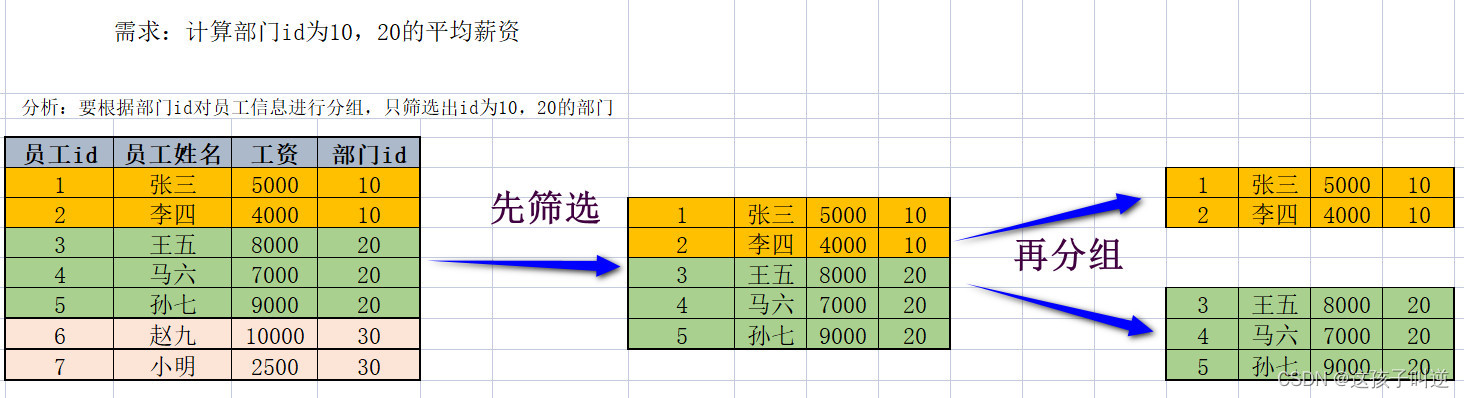
MySQL数据库查询语句之组函数,子查询语句
当一个SQL的执行需要借助另一个SQL的执行结果时,则需要进行SQL嵌套,该语法结构称之为子查询。先筛选出符合要求的数据,再对符合要求的数据进行分组时,分组的工作量会被减少,效率更高。先确定从哪张表进行操作-->对表中数据进行分组-->基于分组结果进行查询操作。执行顺序:优先执行小括号内的子SQL,根据子SQL的执行结果再执行外层SQL。执行顺序:from-->where-->group by-->select。执行顺序:from-->group by-->select。

mysql开启可以使用IP有权限访问
为实际的IP地址和你想要设置的密码。请小心操作,并确保你了解每个命令的作用。如果你对此有任何疑问,最好咨询经验丰富的数据库管理员。来设置或修改用户的密码。相反,你需要分两步来完成这个过程:首先创建或修改用户,并设置密码;然后授予相应的权限。用户应该能够从指定的内网IP地址访问MySQL服务器。用户已存在并且你只是想更改其密码或允许从另一个地址访问,使用。在MySQL 8.0及更高版本中,语句的语法有所变化。替换为你的内网IP地址,
鸿蒙harmony--数据库sqlite详解
今天是1月20号星期六,早安,岁末大寒至,静后春归来。愿他乡故人,漂泊有归宿,前程有奔赴,愿人间不寒,温暖常伴,诸事顺利,喜乐长安。
Centos系统上安装PostgreSQL和常用PostgreSQL功能
PostgreSQL安装成功之后,会默认创建一个名为postgres的Linux用户,初始化数据库后,会有名为postgres的数据库,来存储数据库的基础信息,例如用户信息等等,相当于MySQL中默认的名为mysql数据库。权限代码:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、USAGE。为了方便我们使用postgres账号进行管理,我们可以修改该账号的密码。
【PostgreSQL】函数与操作符-网络地址函数和操作符
下表展示了可以用于cidr和inet类型的操作符。操作符=和&&测试用于子网包含。它们只考虑两个地址的网 络部分(忽略任何主机部分),然后判断其中一个网络部分是等于另外一个或者是 另外一个的子网。cidr。
雪花算法生成ID、UUID生成ID和MySql自增ID优缺点分析
综上所述,UUID适用于分布式系统和需要保密的场景,雪花ID适用于分布式系统和高并发环境,MySQL自增ID适用于单机系统和高效查询的场景。根据具体的业务需求和系统架构,选择合适的主键类型。通过本文的介绍和对比,希望读者能够更好地理解在MySQL中不推荐使用UUID或者雪花ID作为主键的原因,并能够根据实际情况做出明智的选择。在MySQL中,使用自增整数作为主键是一种常见的做法,因为它具有较小的存储空间、高效的索引和自动增长的特性。然而,具体选择何种主键类型还是要根据具体的业务需求和数据特点来决定。
【小白专用】C# 连接 MySQL 数据库
C# 连接 MySQL 数据库
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
MySQL索引优化实战
对于这种varchar(255)的大字段可能会比较占用磁盘空间,可以稍微优化下,比如针对这个字段的前20个 字符建立索引,就是说,对这个字段里的每个值的前20个字符放在索引树里,类似于 KEY index(name(20),age,position)。此时你在where条件里搜索的时候,如果是根据name字段来搜索,那么此时就会先到索引树里根据name 字段的前20个字符去搜索,定位到之后前20个字符的前缀匹配的部分数据之后,再回到聚簇索引提取出来 完整的name字段值进行比对。
《mybatis》--大数据量查询解决方案
之前写百万以及千万的导出数据的时候,对于将数据写道csv文件并压缩这里没有什么大问题了,但是出现了其他问题为:1、我们需要将数据从数据库中拿出来,并且在进行装配的时候出现了一些问题。2、对于整体内存安全来说,如果直接将数据从数据库中拿出来百万级别以上的数据对于内存是非常不友好的。当问题出现比较大的时候会直接触发GC,造成瘫痪。目前开发以及项目测试的是更多的使用mybatis来进行开发的,所以本文章讨论以及解决的的就是如何使用mybaits来解决流式查询并单条处理的问题。
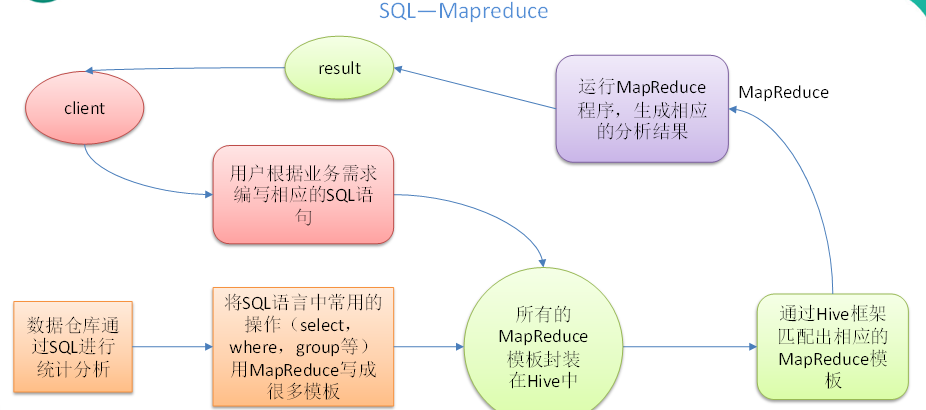
Hive(总)看完这篇,别说你不会Hive!
Hive:由Facebook开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。本质是:将HQL转化成MapReduce程序1)Hive处理的数据存储在HDFS2)Hive分析数据底层的实现是MapReduce3)执行程序运行在Yarn上创建一个数据库,数据库在HDFS上的默认存储路径是/opt/hive/warehouse/*.db避免要创建的数据库已经存在错误,增加if not exists判断。
Spring中事务控制的API介绍(PlatformTransactionManager和TransactionDefinition)
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。例如:methodA事务方法调用methodB事务方法时,methodB是继续在调用者methodA的事务中运行呢,还是为自己开启一个新事务运行,这就是由methodB的事务传播行为决定的。属性,同时,Spring 还为我们提供了一个默认的实现类:DefaultTransactionDefinition,该类适用于大多数情况。作用:是一个事务管理器,负责开启、提交或回滚事务。
maven的scop作用域依赖问题导致idea社区版报错
所以,对于你提到的这个例子,在专业版中强制去掉 provided 作用域是不必要的,而在社区版中可能需要去掉 provided 作用域,以便将相应的依赖包含在构建结果中。问题应该是tomcat的依赖出现问题了,参考了教程的第五种解决方案,没能解决我的问题,猜测应该是这个作用域的问题,把原pom文件中的scop直接删了,问题解决。对于这个错误,查阅了网上的教程反馈为:1.启动类的位置不对,2.配置文件是否存在且位置是否对,以及内容是否有错误。虽然教程没解决我的问题,但是给了我思路。

大数据Hadoop、HDFS、Hive、HBASE、Spark、Flume、Kafka、Storm、SparkStreaming这些概念你是否能理清?
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn只负责资 源 的 调 度。当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;
HDFS对比HBase、Hive对比Hbase
Hive和Hbase是两种基于Hadoop的不同技术Hive是一种类SQL的引擎,并且运行MapReduce任务Hbase是一种在Hadoop之上的NoSQL的Key/value数据库这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也 可以从Hive写到HBase,或者从HBase写回Hive。
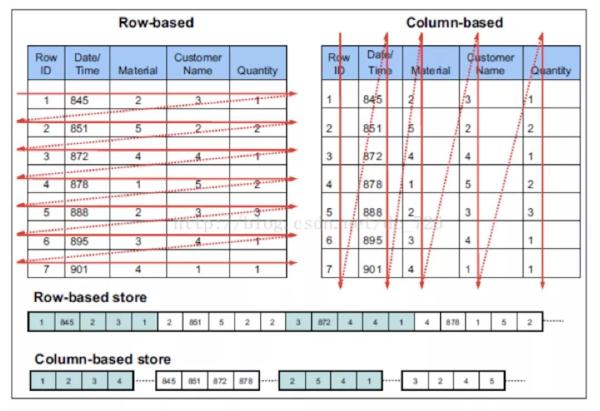
ClickHouse 与mysql等关系型数据库对比
先用一张图帮助理解两者的本质上的区。
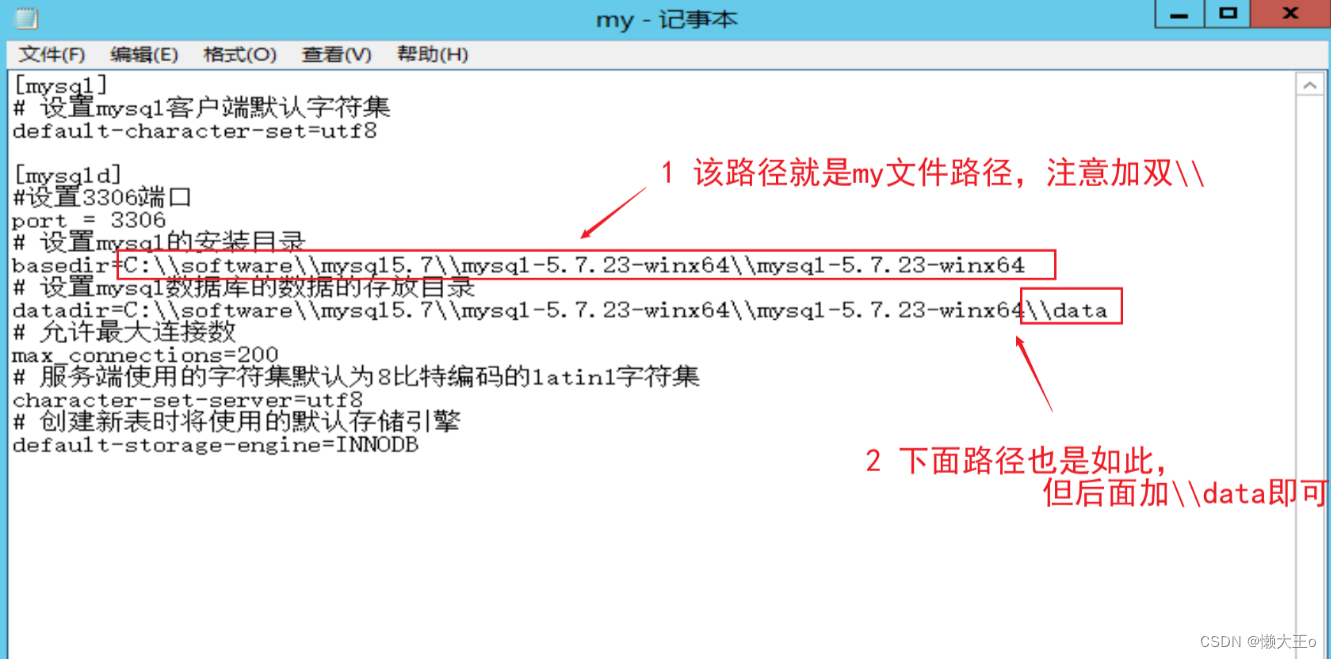
Windows安装MySQL及网络配置
向日葵软件是一种远程控制软件,可以让用户在不同设备之间进行远程桌面访问和文件传输。用户可以通过向日葵软件,在任何具有互联网连接的设备上远程控制其他设备,包括计算机、智能手机和平板电脑。用户只需安装向日葵软件,并使用登录凭据连接到目标设备,就可以实时控制目标设备上的屏幕、键盘和鼠标。向日葵软件还提供了一些辅助功能,如文件传输、远程打印和远程会议等。这使得向日葵软件成为一个方便实用的远程协助工具,适用于个人用户、技术支持人员和企业用户等各种场景。
Web数据库基本知识,SQL基本语法
SQL(Structured Query Language)是一种用于管理和操作关系型数据库管理系统(RDBMS)的特定领域语言。它是一种标准化的语言,用于定义和操作关系型数据库中的数据。SQL允许用户执行诸如查询数据、插入新数据、更新现有数据和删除数据等操作。分为四种DDL:数据库定义语言(define)DML:数据库操作管理语言(manage)DQL:数据库查询语言(query)DCL:数据库控制语言(control)

深入理解Mysql事务隔离级别与锁机制
我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。这些问题的本质都是数据库的多事务并发问题,为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制,用一整套机制来解决多事务并发问题。接下来,我们会深入讲解这些机制,让大家彻底理解数据库内部的执行原理。
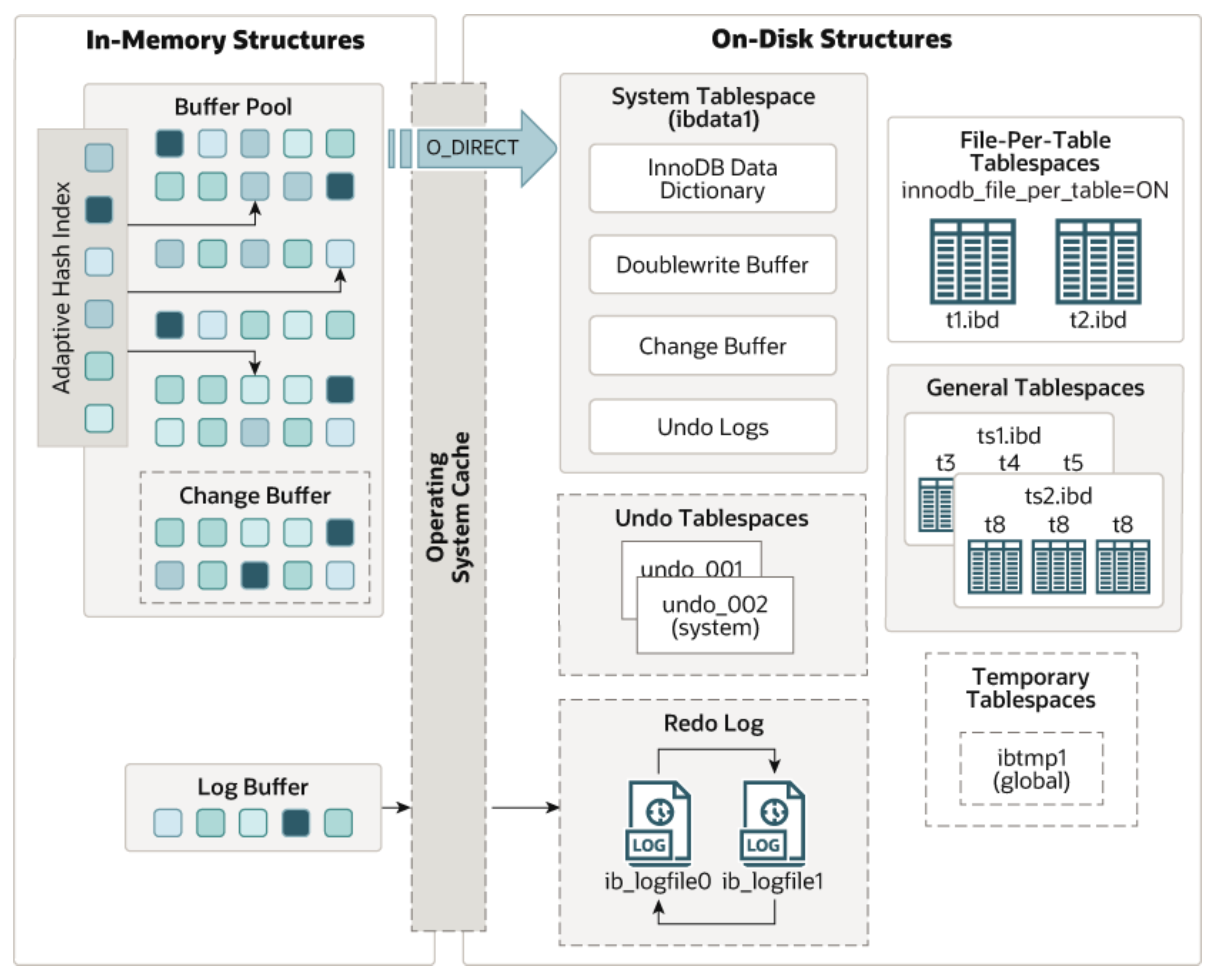
MySQL是如何保证数据不丢失的?
上篇文章《InnoDB在SQL查询中的关键功能和优化策略》对InnoDB的查询操作和优化事项进行了说明。但是,MySQL作为一个存储数据的产品,怎么确保数据的持久性和不丢失才是最重要的,感兴趣的可以跟随本文一探究竟。
where查询条件的字段顺序打乱会影响命中索引吗?
答案是:不影响我们的where后边条件字段打乱会影响命中索引吗?先来进行下边的实验:可以看到实验结果,where条件字段顺序没有按照索引的字段顺序,依然不影响命中索引。因为Mysql中有查询优化器,会自动优化查询顺序。

MySQL删除会走索引吗
MySQL是关系型数据库管理系统的一种, 网站在进行数据的增删改查的时候,我们往往需要使用 MySQL 数据库。而删除操作就是在 MySQL 数据库中删除指定的数据或者表格的操作。
Linux多种方法安装MySQL
源码安装:优点是安装包比较小,只有十多M,缺点是安装依赖的库多,安装编译时间长,安装步骤复杂容易出错。使用官方编译好的二进制文件安装:优点是安装速度快,安装步骤简单,缺点是安装包很大,300M左右。yum安装。rpm安装。