【Flink】官宣|Apache Flink 1.17 发布公告

1.概述
转载:官宣|Apache Flink 1.17 发布公告 仅供自己学习。因为我们开始用Flink 17了。
Apache Flink PMC(项目管理委员)很高兴地宣布发布 Apache Flink 1.17.0。Apache Flink 是领先的流处理标准,流批统一的数据处理概念在越来越多的公司中得到认可。得益于我们出色的社区和优秀的贡献者,Apache Flink 在 Apache 社区中一直保持着快速增长,并且是最活跃的社区之一。Flink 1.17 有 172 位贡献者热情参与,完成了 7 个 FLIP 和 600 多个 issue,为社区带来了许多令人兴奋的新功能和改进。
2.迈向 Streaming Warehouse
为了在 流式数仓 领域实现更高效的处理,Flink 1.17 对批处理和流处理的性能和语义都进行了实质性的改进。这些增强措施代表了朝着创建一个更高效、更简化的数据仓库,能够实时处理大量数据的目标迈进了一大步。
针对批处理,此次发布包含了下述几项新特性和改进。
Streaming Warehouse API: FLIP-282 在 Flink SQL 中引入了新的 Delete 和 Update API,它们可以在 Batch 模式下工作。在此基础上,外部存储系统比如 Flink Table Store 可以通过这些新的 API 实现行级删除和更新。同时对 ALTER TABLE 语法进行了增强,包括 ADD/MODIFY/DROP 列、主键和 watermark 的能力,这些增强使得用户更容易维护元数据。
Batch 性能优化: 在 Flink 1.17 中,批处理作业的执行在性能、稳定性和可用性方面都得到了显着改进。就性能而言,通过策略优化和算子优化,如新的 join-reorder 算法和自适应的本地哈希聚合优化、Hive 聚合函数改进以及混合 shuffle 模式优化,这些改进带来了 26% 的 TPC-DS 性能提升。就稳定性而言,Flink 1.17 预测执行可以支持所有算子,自适应的批处理调度可以更好的应对数据倾斜场景。就可用性而言,批处理作业所需的调优工作已经大大减少。自适应的批处理调度已经默认开启,混合 shuffle 模式现在可以兼容预测执行和自适应批处理调度,同时所需的各种配置都进行了简化。
SQL Client/Gateway: Apache Flink 1.17 支持了 SQL Client 的 gateway 模式,允许用户将 SQL 提交给远端的 SQL Gateway。同时,用户可以在 SQL Client 中使用 SQL 语句来管理作业,包括查询作业信息和停止正在运行的作业等。这表示 SQL Client/Gateway 已经演进为一个作业管理、提交工具。
针对流处理,Flink 1.17 完成了以下功能和改进:
Streaming SQL 语义增强: 非确定性操作可能会导致不正确的结果或异常,这在 Streaming SQL 中是一个极具挑战性的话题。Flink 1.17 修复了不正确的优化计划和功能问题,并且引入了实验性功能 PLAN_ADVICE,PLAN_ADVICE 可以为 SQL 用户提供潜在的正确性风险提示和 SQL 优化建议。
Checkpoint 改进: 通用增量 Checkpoint(GIC)增强了 Checkpoint 的速度和稳定性,Unaligned Checkpoint (UC) 在作业反压时的稳定性也在 Flink 1.17 中提高至生产可用级别。此外,该版本新引入一个 REST API 使得用户可以触发自定义 Checkpoint 类型的 Checkpoint。
Watermark 对齐完善: 高效的 watermark 处理直接影响 event time 作业的执行效率,在 Flink 1.17 中, FLIP-217 通过对 Source 算子内部的 split 进行数据对齐发射,完善了 watermark 对齐功能。这一改进使得 Source 中 watermark 进度更加协调,从而减轻了下游算子的缓存过多数据,增强了流作业执行的整体效率。
StateBackend 升级: 此次发布将 FRocksDB 的版本升级到了 6.20.3-ververica-2.0,对 RocksDBStateBackend 带来了许多改进。同时,例如在插槽之间共享内存,并且现在支持 Apple Silicon 芯片组,如 Mac M1。Flink 1.17 版本还提供了参数扩大 TaskManager 的 slot 之间共享内存的范围,提升了 TaskManager 中 slot 内存使用不均是的效率。
3.批处理
作为的流批一体的计算引擎,Apache Flink 在流处理领域持续领先,为了进一步增强其批处理能力,Flink 社区贡献者在 Flink 1.17 版本的批处理的性能优化和生态完善方面付出了诸多努力。 这让用户可以更轻松地基于 Flink 构建 Streaming Warehouse。
4.预测执行
在此次发布中,预测执行支持了 Sink 算子。 在之前的版本中,为了避免不稳定性或不正确的结果,预测执行不会发生在 Sink 算子上。Flink 1.17 丰富了 Sink 的上下文信息,使得 新版 Sink 和 OutputFormat Sink 都能获取到当前执行实例的序号 (attempt number),根据这个序号,Sink 算子可以将同一子任务的多个不同实例生成的数据进行隔离,即使这些实例在同时运行。FinalizeOnMaster 接口也进行了改进,以便 OutputFormat Sink 可以知道哪些序号的实例成功产出了数据,从而正确地提交结果数据。当 Sink 的开发者确定该 Sink 可以正确的支持多个并发实例同时运行,就可以使其实现装饰性接口 SupportsConcurrentExecutionAttempts,从而允许其进行预测执行。一些内置 Sink 已经支持了预测执行,包括 DiscardingSink、PrintSinkFunction、PrintSink、FileSink、FileSystemOutputFormat 和 HiveTableSink。
此外,预测执行的慢任务的检测也获得了改进。在之前,在决定哪些任务是慢任务时只考虑了任务的执行时间。现在,慢任务检测器还会考虑了任务的输入数据量。执行时间较长的任务,如果消费了更多的数据,不一定会被视为慢任务。这一改进有助于消除数据倾斜对慢任务检测的负面影响。
5.自适应批处理调度器
在此次发布中,自适应批处理调度器成为了批作业的默认调度器。该调度器可以根据每个 job vertex 处理的数据量,自动为其设置合适的并行度。这也是唯一一个支持预测执行的调度器。
自适应批调度器的配置得到了改进,以提高其易用性。用户不再需要显式将全局默认并行度设置为 - 1 来开启自动推导并行度功能。现在,如果设置了全局默认并行度,其会被用做自动推导并行度的上界。一些配置项的名称也进行了改进,以便于用户理解。
此外,自适应批处理调度器的能力也得到了增强。现在它可以根据细粒度的数据分布信息,将数据更均匀的分配给下游任务。自动推导的并行度现在也不再被限制为 2 的幂。
6.混合 Shuffle 模式
此次发布中,混合 Shuffle 模式带来了多个重要改进:
混合 Shuffle 模式现在支持自适应批调度器和预测执行。
混合 Shuffle 模式现在支持重用中间数据,这带来了显着的性能改进。
提高了稳定性,避免了在大规模生产环境中出现的稳定性问题。
更多详细信息可以在 混合 Shuffle 部分找到。
7.TPC-DS
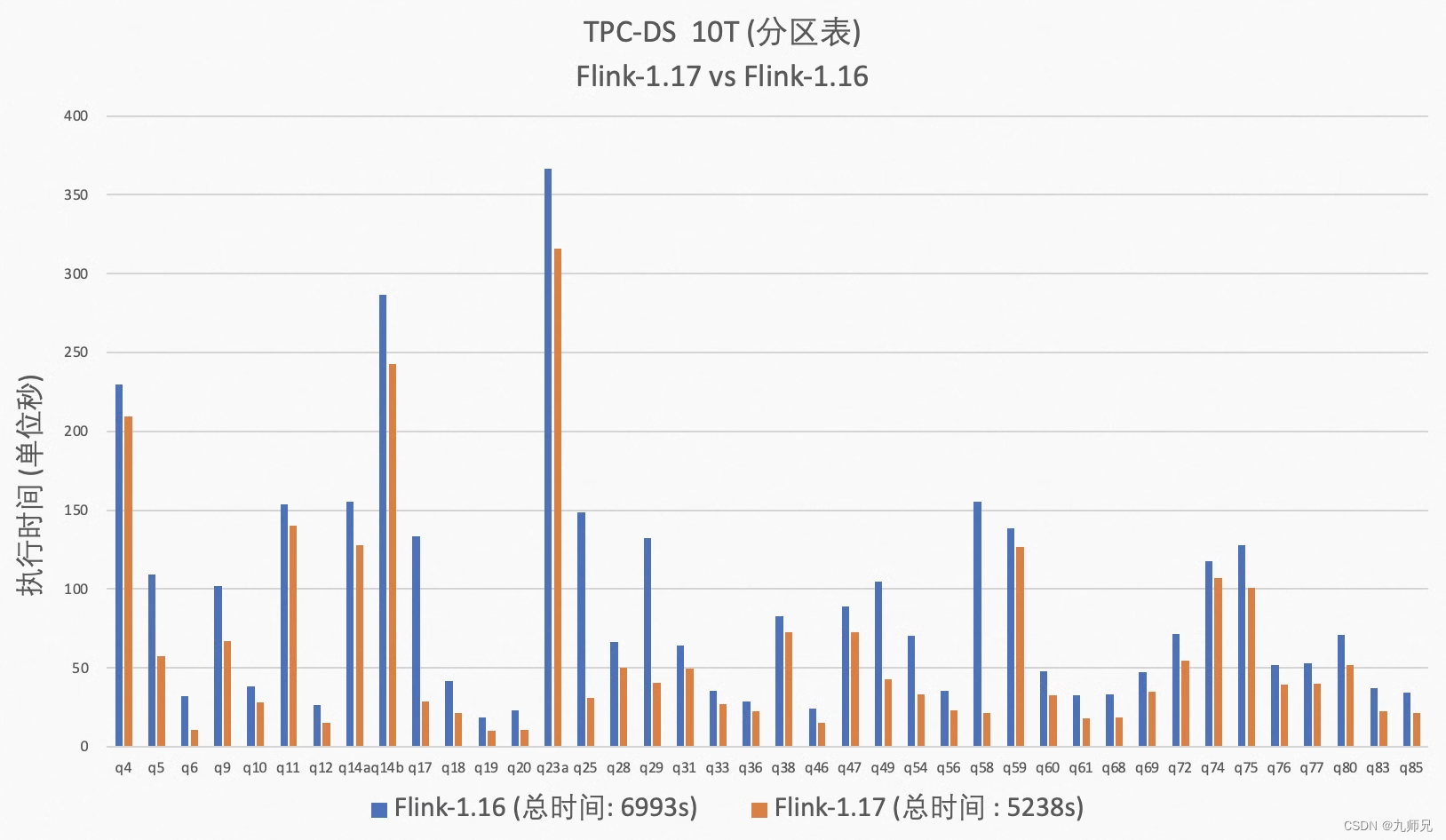
从 Flink 1.16 开始,Flink 社区持续优化批处理引擎的性能。在 Flink 1.16 中,引入了动态分区裁剪优化,但并非所有的 TPC-DS 查询都可以被优化。Flink 1.17 对该优化的算法进行了改进,使得大部分 TPC-DS 查询都可以被优化。此外,Flink 1.17 中引入了动态规划 join-reorder 算法,与之前版本的算法相比,该算法效果更好,但搜索空间更大。优化器可以根据查询中 join 个数自动选择合适的 join-reorder 算法,用户无需关心 join-reorder 算法的细节(注意:join-reorder 默认未开启,在运行 TPC-DS 时需要显式启用)。在算子层面,Flink 1.17 引入了动态 local hash aggregation 策略,可以根据数据的分布动态确定是否需要在本地进行聚合操作以提高性能。在运行时层面上,此次发布移除了一些不必要的虚拟函数调用,以加快执行速度。从整体测试结果上看,相比 Flink 1.16,对于分区表在 10T 数据集下 Flink 1.17 有 26% 的性能提升。
8.SQL Client/Gateway
Apache Flink 1.17 引入了一个名为 “gateway 模式” 的新功能,允许用户将 SQL 查询提交到远程的 SQL Gateway 从而像 embedded 模式一样来使用 Gateway 的各种功能。这种新模式为用户在使用 SQL Gateway 时提供了更多的便利。
此外,SQL Client/SQL Gateway 现在支持通过 SQL 语句来管理作业生命周期。用户可以使用 SQL 语句显示存储在 JobManager 中的所有作业信息,可以使用作业的唯一作业 ID 来停止运行中的作业。借助这个新功能,SQL Client/SQL Gateway 现在几乎拥有了与 Flink CLI 相同的功能,成为管理 Flink 作业的另一个更强大的工具。
9.SQL API
在现代大数据工作流中,SQL 引擎的行级删除和更新能力变得越来越重要。应用场景包括为了符合监管要求而删除特定一组数据、为了进行数据订正而更新一行数据等。许多流行的计算引擎比如 Trino、Hive 等已经提供了这类支持。Flink 1.17 为 Batch 模式引入了新的 Delete 和 Update API,并将其暴露给连接器,这样外部存储系统便可以基于这个 API 实现行级更新和删除。此外,此次发布还扩展了 ALTER TABLE 语法,包括 ADD/MODIFY/DROP 列、主键和 Watermark 的能力。这些功能增强提升了用户按需维护元数据的灵活性。
Apache Flink 1.17 支持了 SQL Client 的 gateway 模式,允许用户将 SQL 查询提交给 SQL Gateway 来使用 Gateway 的各种功能。用户可以使用 SQL 语句来管理作业的生命周期,包括显示作业信息和停止正在运行的作业,这为管理 Flink 作业提供了一个强大的工具。
10.Hive 兼容
Apache Flink 1.17 对 Hive connector 进行了一系列改进,使其更加生产可用。在之前的版本中,对于 Hive 的写入,只支持在流模式下自动地进行文件合并,而不支持批模式。从 Flink 1.17 开始,在批模式下也能自动地进行文件合并,这个特性可以大大减少小文件的数量。同时,对于通过加载 HiveModule 来使用 Hive 内置函数的场景,此次发布引入了一些原生的 Hive 聚合函数如 SUM/COUNT/AVG/MIN/MAX 进 HiveModule 中,这些函数可以在基于哈希的聚合算子上执行,从而带来显著的性能提升。
11.流处理
Flink 1.17 解决了一些棘手的 Streaming SQL 语义和正确性问题,优化了 Checkpoint 性能,完善了 watermark 对齐机制,扩展了 Streaming FileSink,升级了 Calcite 和 FRocksDB 到更新的版本。这些提升进一步巩固了 Flink 在流处理领域的领先地位。
12 Streaming SQL 语义完善
为了解决正确性问题并完善 Streaming SQL 语义,Flink 1.17 引入了一个实验性功能叫 PLAN_ADVICE ,该功能可以检测用户 SQL 潜在的正确性风险,并提供优化建议。例如,如果用户通过 EXPLAIN PLAN_ADVICE 命令发现查询存在 NDU (非确定性更新) 问题,优化器会在物理计划输出的末尾追加建议,建议会标记到对应操作节点上,并提示用户更新查询和配置。通过提供这些具体的建议,优化器可以帮助用户提高查询结果的准确性。
== Optimized Physical Plan With Advice == ... advice[1]: [WARNING] The column(s): day(generated by non-deterministic function: CURRENT_TIMESTAMP ) can not satisfy the determinism requirement for correctly processing update message('UB'/'UA'/'D' in changelogMode, not 'I' only), this usually happens when input node has no upsertKey(upsertKeys=[{}]) or current node outputs non-deterministic update messages. Please consider removing these non-deterministic columns or making them deterministic by using deterministic functions.
PLAN_ADVICE 功能还可以帮助用户提高查询的性能和效率。例如,如果检测到聚合操作可以优化为更高效的 local-global 聚合操作,优化器会提供相应的优化建议。通过应用这些具体的建议,优化器可以帮用户提高其查询的性能和效率。
== Optimized Physical Plan With Advice == ... advice[1]: [ADVICE] You might want to enable local-global two-phase optimization by configuring ('table.optimizer.agg-phase-strategy' to 'AUTO').
此外 Flink 1.17 还修复了多个可能影响数据正确性的 plan 优化问题,如: FLINK-29849 , FLINK-30006 , 和 FLINK-30841 等。
13.Watermark 对齐增强
在早期版本中, FLIP-182 提出了一种称为 watermark 对齐的解决方案,以解决 event time 作业中的源数据倾斜问题。但是,该方案存在一个限制,即 Source 并行度必须和分区数匹配。这是因为具有多个分区的 Source 算子中,如果一个分区比另一个分区更快地发出数据,此时需要缓存大量数据。为了解决这个限制,Flink 1.17 引入了 FLIP-217 ,它增强了 watermark 对齐考虑 watermark 边界的情况下对 Source 算子内的多个分区进行数据发射对齐。这个增强功能确保了 Source 中的 Watermark 前进更加协调,避免了下游算子缓存过多的数据,从而提高了流作业的执行效率。
14.Streaming FileSink 扩展
在添加 ABFS 支持之后,Streaming FileSink 现在可以支持五种不同的文件系统:HDFS、S3、OSS、ABFS 和 Local。这个扩展有效地覆盖了主流文件系统,为用户提供了更多的选择和更高的灵活性。
15.Checkpoint 改进
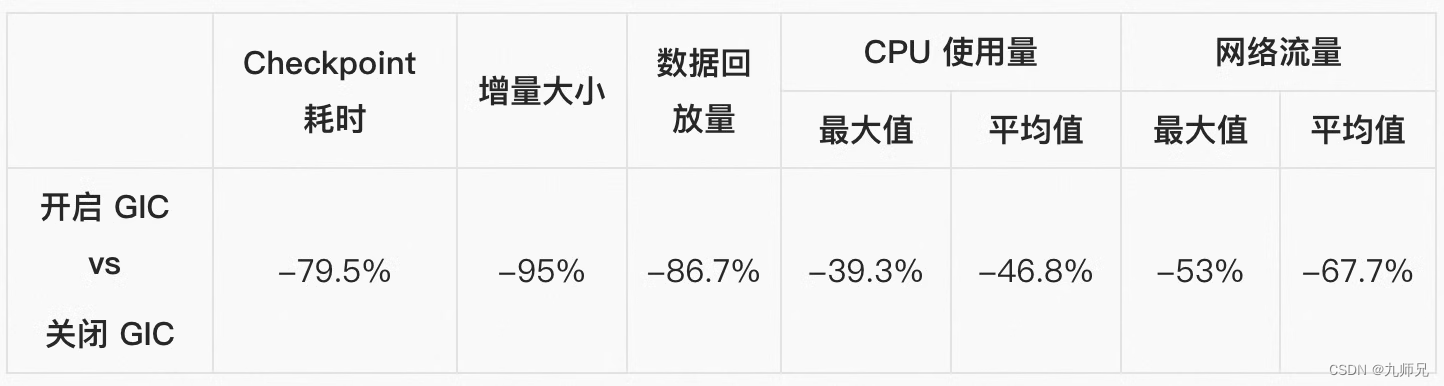
通用增量 Checkpoint(Generic Incremental Checkpont,简称 GIC)旨在提高 Checkpoint 过程的速度和稳定性。WordCount 案例中的一些实验结果如下所示。 请参考这篇 性能测评文章 获取更多详细信息,该文结合理论分析和实践结果展示了 GIC 的收益和成本。
表格 - 1: 在 WordCount 中开启 GIC 后的收益
表格 - 2: 在 WordCount 中开启 GIC 后的开销

Unaligned Checkpoint (UC) 可以大大提高反压下 Checkpoint 的完成率。 之前版本的 UC 会写入过多的小文件,进一步可能会导致 HDFS 的 namenode 负载过高。社区在 1.17 版本中解决了该问题,使 UC 在生产环境中更加可用。
Flink 1.17 版本提供了一个 REST API ,用户基于该 API 可以在作业运行时手动触发具有自定义 Checkpoint 类型的 Checkpoint。 例如,对于使用增量 Checkpoint 运行的作业,用户可以定期或手动触发全量 Checkpoint 来去除多个增量 Checkpoint 之间的关联关系,从而避免引用很久以前的文件。
16.RocksDBStateBackend 升级
Flink 1.17 版本将 FRocksDB 的版本升级到 6.20.3-ververica-2.0,为 RocksDBStateBackend 带来了一些改进:
支持在 Apple 芯片上构建 FRocksDB Java
通过避免昂贵的 ToString () 操作提高 Compaction Filter 的性能
升级 FRocksDB 的 ZLIB 版本,避免 Memory Corruption
为 RocksJava 添加 periodic_compaction_seconds 选项
可以参考 FLINK-30836 了解更多详细信息。
Flink 1.17 版本还提供了参数扩大 TaskManager 的 slot 之间共享内存的范围,这种方式可以在 TaskManager 中 slot 内存使用不均匀时提高内存效率。基于此在调整参数后可以以资源隔离为代价来降低整体内存消耗。请参考 state.backend.rocksdb.memory.fixed-per-tm 了解更多相关信息。
17.Calcite 升级
Flink 1.17 将 Calcite 版本升级到 1.29.0 以提高 Flink SQL 系统的性能和效率。Flink 1.16 使用的是 Calcite 1.26.0 版本,该版本存在 SEARCH 操作符引发的 RexNode 简化等严重问题,这些问题会导致查询优化后产生错误的数据,如 CALCITE-4325 和 CALCITE-4352 所报告的案例。通过升级到该版本的 Calcite,Flink 可以在 Flink SQL 中利用其功能改进和新特性。这不仅修复了多个 bug,同时加快了查询处理速度。
18.其他
PyFlink
在 Flink 1.17 中,PyFlink 也完成了若干功能,PyFlink 是 Apache Flink 的 Python 语言接口。PyFlink 中,一些比较重要的改进包括支持 Python 3.10、支持在 Mac M1 和 M2 电脑上运行 PyFlink 等。此外,在该版本中还完成了一些小的功能优化,比如改进了 Java 和 Python 进程之间的跨进程通信的稳定性、支持以字符串的方式声明 Python UDF 的结果类型、支持在 Python UDF 中访问作业参数等。总体来说,该版本主要专注于改进 PyFlink 的易用性,而不是引入一些新的功能,期望通过这些易用性改进,改善用户的使用体验,使得用户可以更高效地进行数据处理。
性能监控 Benchmark
这个版本周期中,我们也在 Slack 频道( #flink-dev-benchmarks )中加入了性能日常监控汇报来帮助开发者快速发现性能回退问题,这对代码质量保证非常有意义。 通过 Slack 频道或 Speed Center 发现性能回退后,开发者可以按照 Benchmark’s wiki 中方式处理它。
Task 级别火焰图
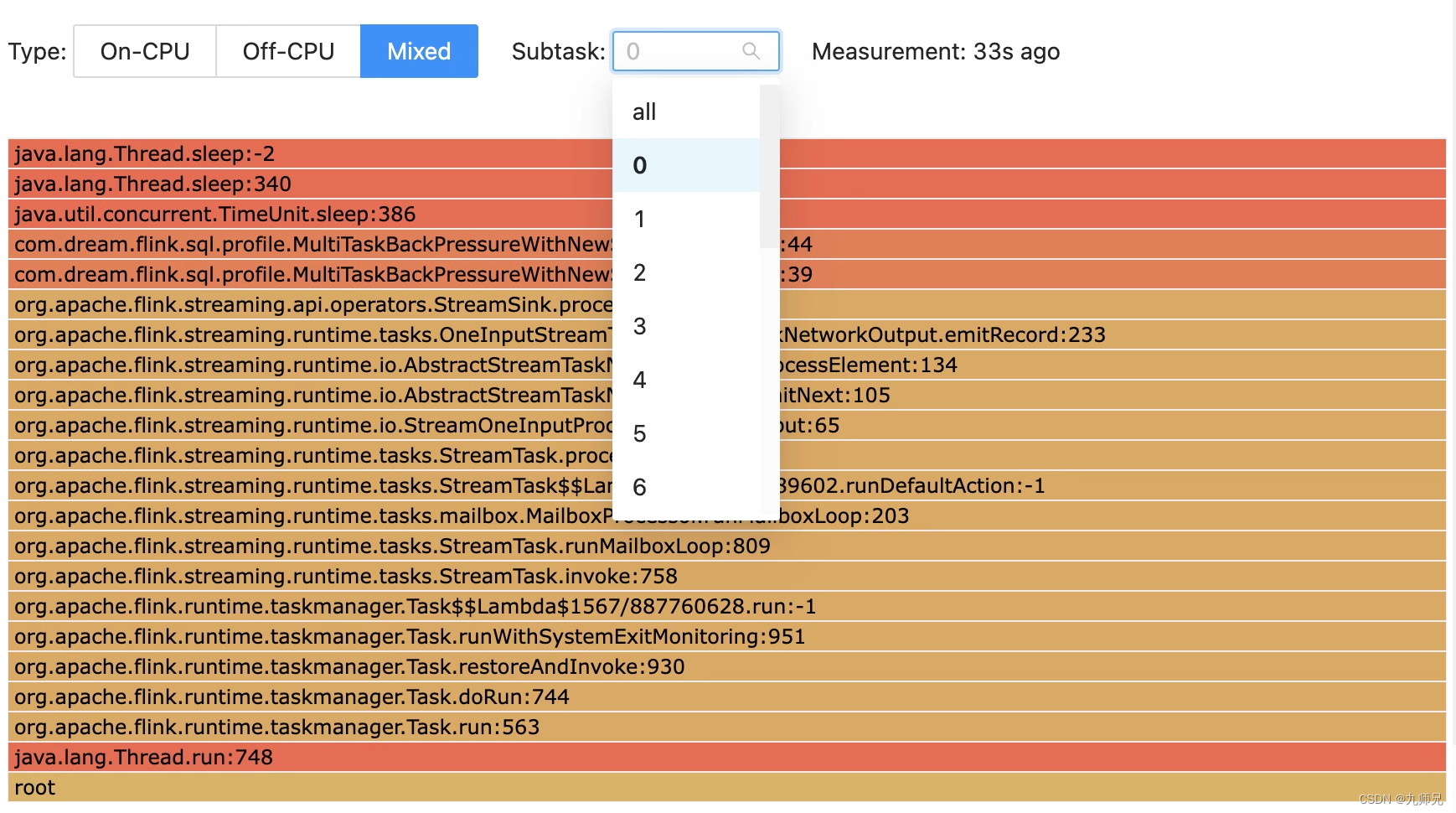
从 Flink 1.17 版本开始,Flame Graph 功能提供了针对 task 级别的可视化支持,使得用户可以更详细地了解各个 task 的性能。该功能是相比于之前版本的 Flame Graph 的重大改进,因为它可以让用户选择感兴趣的 subtask 并查看相应的火焰图。通过这种方式,用户可以确定任务可能出现性能问题的具体区域,然后采取措施加以解决。这可以显著提高用户数据处理管道的整体效率。
通用的令牌机制
在 Flink 1.17 之前,Flink 只支持 Kerberos 认证和基于 Hadoop 的令牌。随着 FLIP-272 的实现,Flink 的委托令牌框架更加通用,使其认证协议不再局限于 Hadoop。这将允许贡献者在未来可以添加对非 Hadoop 框架的支持,这些框架的认证协议可以不用基于 Kerberos。此外, FLIP-211 改进了 Flink 与 Kerberos 的交互,减少了在 Flink 中交换委托令牌所需的请求数量。
升级说明
Apache Flink 社区努力确保升级过程尽可能平稳,但是升级到 1.17 版本可能需要用户对现有应用程序做出一些调整。请参考 Release Notes 获取更多的升级时需要的改动与可能的问题列表细节。
相关文章:
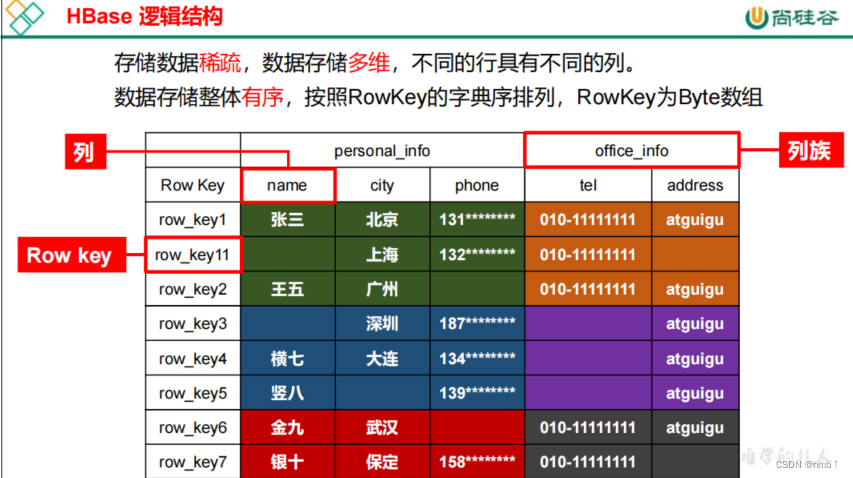
Springboot整合HBase——大数据技术之HBase2.x
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

终于有人把Web 3.0和元宇宙讲明白了
分散的数据网络使个人数据(例如个人的健康数据、农民的作物数据或汽车的位置和性能数据)出售或交换成为可能,与此同时,不会失去对数据的所有权控制、放弃数据隐私或依赖第三方平台来管理数据。Web 3.0的目标是在创作者经济中取得更好的平衡。互联网第二次迭代(Web 2.0)的缺陷,加上公有区块链技术的诞生,帮助我们朝着更加去中心化的Web 3.0 迈进,元宇宙和更广泛的去中心化网络都是关于现实世界和虚拟世界的融合。此时的网络中不再是静态内容,而是动态的内容,用户现在可以与发布在网络上的内容进行交互。
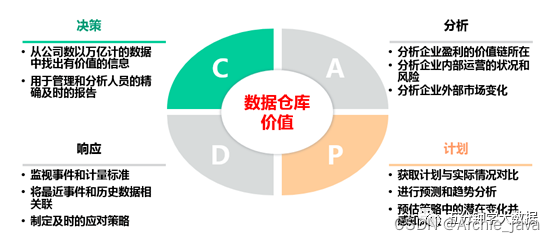
万字详解数据仓库、数据湖、数据中台和湖仓一体
数字化转型浪潮卷起各种新老概念满天飞,数据湖、数据仓库、数据中台轮番在朋友圈刷屏,有人说“数据中台算个啥,数据湖才是趋势”,有人说“再见了数据湖、数据仓库,数据中台已成气候”……企业还没推开数字化大门,先被各种概念绊了一脚。那么它们 3 者究竟有啥区别?别急,先跟大家分享两个有趣的比喻。1、图书馆VS地摊如果把数据仓库比喻成“图书馆”,那么数据湖就是“地摊”。去图书馆借书(数据),书籍质量有保障,但你得等,等什么?等管理员先查到这本书属于哪个类目、在哪个架子上,你才能精准拿到自己想要的书;
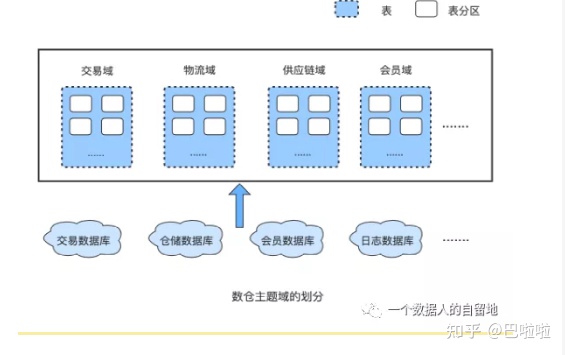
什么是数据中台?
说完了数据中台诞生的历史背景,现在,我们应该对数据中台有了一定的了解,那我们现在给数据中台下个定义。自2016年,数据中台被提出以来,不同的人对数据中台有不同的理解,就像一千个读者心中有一千个哈姆雷特,因此也有许多不同的定义,以下是我从一些文章、书籍中搜集到的关于数据中台的定义:数据中台是DT时代的大背景下,为实现数据快(快速)、准(准确)、省(低成本)赋能业务发展的目标,将企业的数据统一整合起来,基于Onedata方法论借助大数据平台完成数据的统一加工处理,对外提供数据服务的一套机制。

Git 的基本概念、使用方式及常用命令
Git的基本概念、使用方式及常用命令

怎么选择数据安全交换系统,能够防止内部员工泄露数据?
数据泄露可能给企业带来诸多风险:财产损失、身份盗窃、骚扰和诈骗、经济利益受损、客户信任度下降、法律风险和责任等,《2021年度数据泄漏态势分析报告》中显示,在数据泄露的主体中,内部人员导致的数据泄漏事件占比接近60%。飞驰云联文件安全交换系统,可以满足企业多场景下的文件交换需求,帮助企业终结多工具、 多系统并行使用的局面,减少因文件交换行为分散带来的数据管理不集中、难以管控的问题, 帮助企业内部构建统一、安全的企业数据流转通道。对于不能下载保存的数据,使用截屏、录屏的方式窃取并外泄数据;
弹性搜索引擎Elasticsearch:本地部署与远程访问指南
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问。
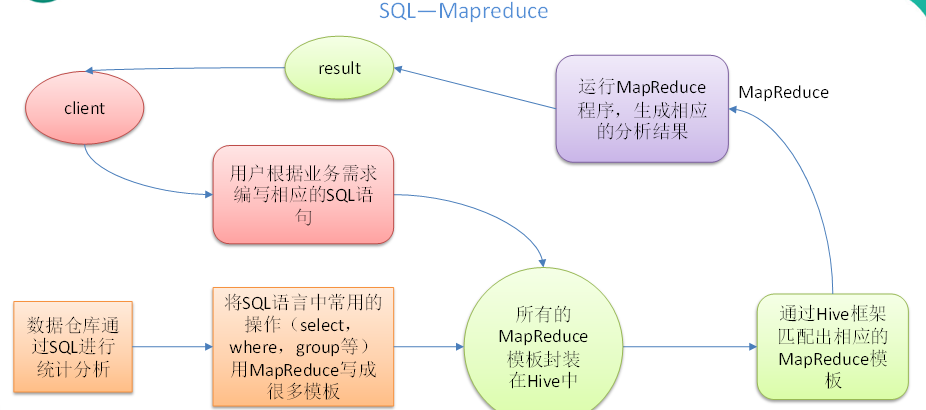
Hive(总)看完这篇,别说你不会Hive!
Hive:由Facebook开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。本质是:将HQL转化成MapReduce程序1)Hive处理的数据存储在HDFS2)Hive分析数据底层的实现是MapReduce3)执行程序运行在Yarn上创建一个数据库,数据库在HDFS上的默认存储路径是/opt/hive/warehouse/*.db避免要创建的数据库已经存在错误,增加if not exists判断。
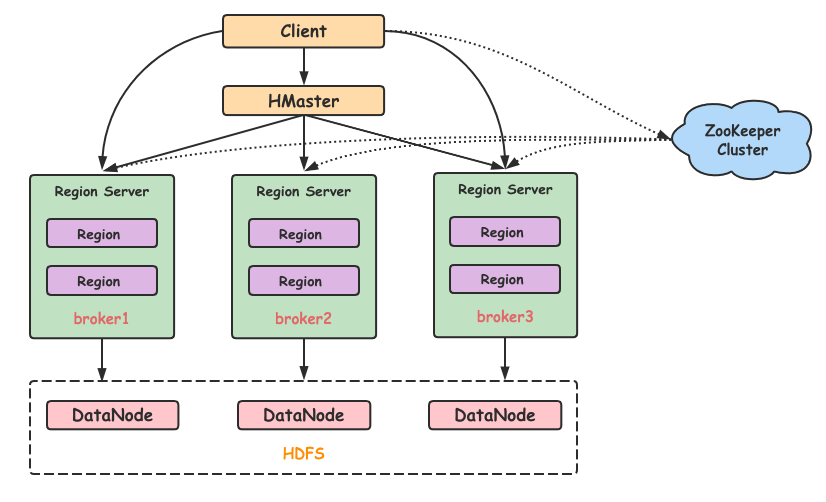
什么是HBase?终于有人讲明白了
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
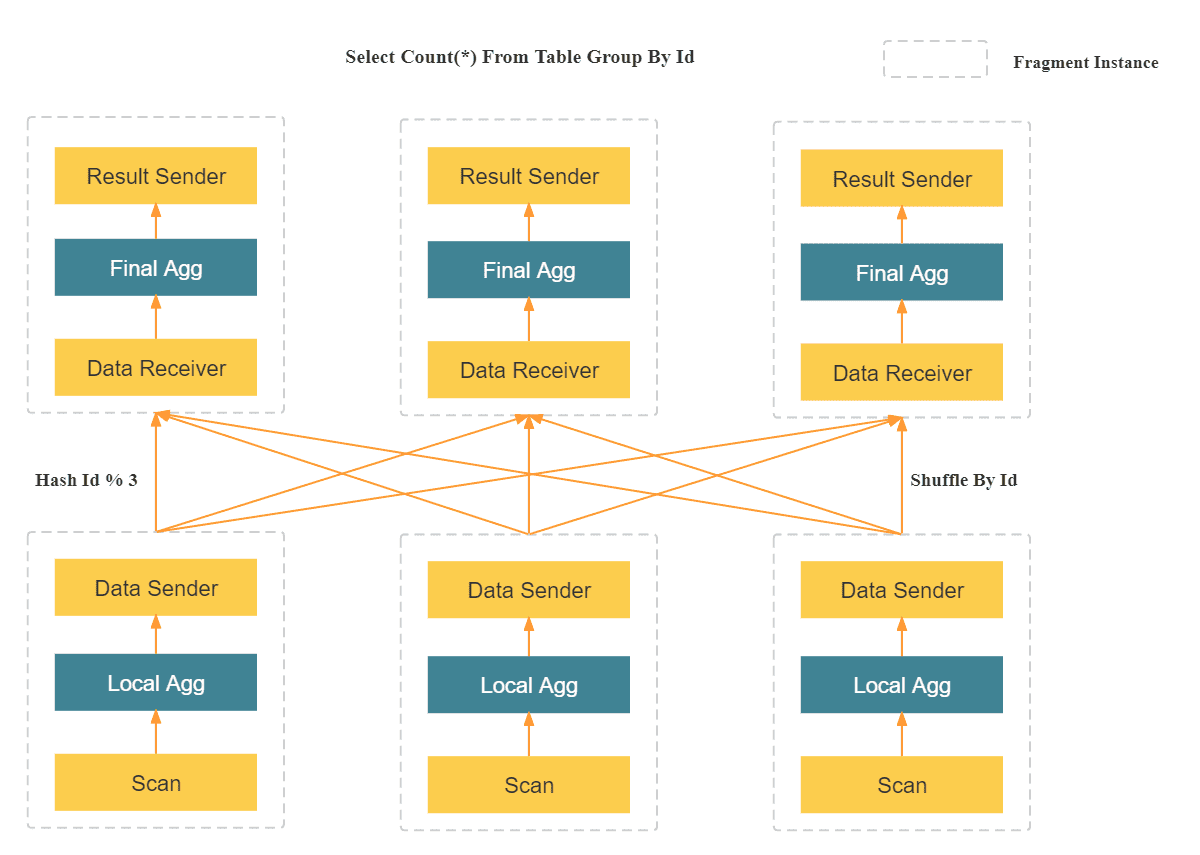
数据仓库系列:StarRocks 入门培训教程
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。提供千亿级大数据的在线多维分析和分布式存储。新一代极速全场景 MPP (Massively Parallel Processing) 数据库是forkdoris后独立运营的商业化版本StarRocks。

ClickHouse & StarRocks 使用经验分享
总结一下,如果是需要分析日志流数据,更加推荐 ClickHouse ,因为 ClickHouse 单机强悍,可以支撑亿级别数据量,架构简单,相比于 StarRocks 也更加稳定,相比集群,更推荐单机 ClickHouse。如果是分析业务流数据,更加推荐 StarRocks ,因为 StarRocks 对于更新场景性能更加,而且 JOIN 性能更好,而且更加推荐部署 StarRocks 集群,可以充分发挥 StarRocks 的性能。

大数据Hadoop、HDFS、Hive、HBASE、Spark、Flume、Kafka、Storm、SparkStreaming这些概念你是否能理清?
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn只负责资 源 的 调 度。当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;
HDFS对比HBase、Hive对比Hbase
Hive和Hbase是两种基于Hadoop的不同技术Hive是一种类SQL的引擎,并且运行MapReduce任务Hbase是一种在Hadoop之上的NoSQL的Key/value数据库这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也 可以从Hive写到HBase,或者从HBase写回Hive。
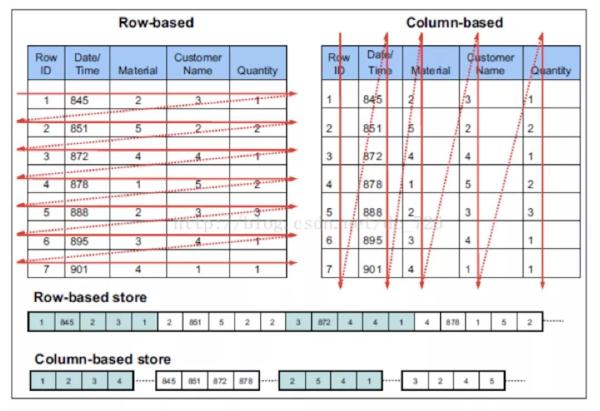
ClickHouse 与mysql等关系型数据库对比
先用一张图帮助理解两者的本质上的区。

牢牢把握“心价比”,徕芬的业绩爆发是一种必然?
业绩突破背后也有消费复苏的激励作用,但具体到电吹风市场,竞争态势在持续加剧,且有戴森这样的国外品牌盘踞于此。徕芬究竟是如何越走越稳的?
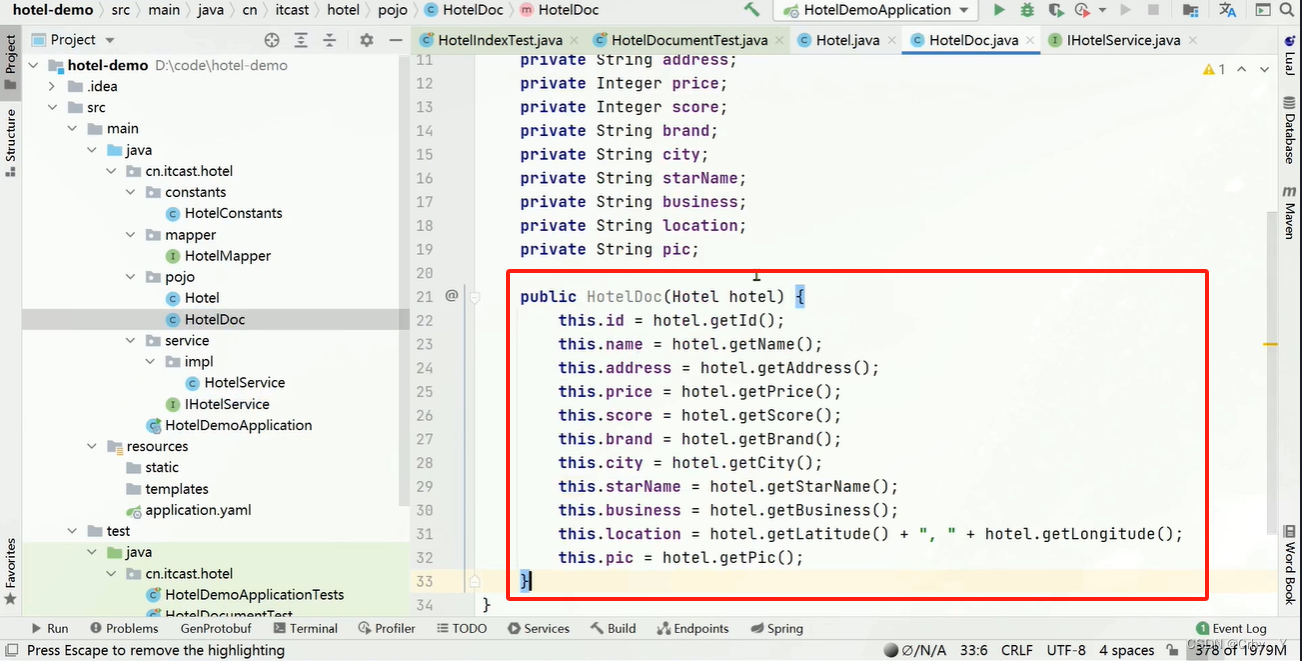
java中如何使用elasticsearch—RestClient操作文档(CRUD)
去数据库查询酒店数据,导入到hotel索引库,实现酒店数据的CRUD基本步骤如下。新建一个测试类,实现文档相关操作,并且完成JavaRestClient的初始化。方式一(全量更新):再次写入id一样的文档,就会删除旧文档,添加新文档。根据id查询到的文档数据是json,需要反序列化为java对象。(2)根据id查询数据库数据,并转换。方式二(局部更新):只更新部分字段。(1)创建文档对应实体。修改文档数据有两种方式。
获得JD商品评论 API 如何实现实时数据获取
随着互联网的快速发展,电商平台如雨后春笋般涌现,其中京东(JD)作为中国最大的自营式电商平台之一,拥有庞大的用户群体和丰富的商品资源。为了更好地了解用户对商品的反馈,京东开放了商品评论的API接口,允许开发者实时获取商品评论数据。本文将介绍如何通过JD商品评论API实现实时数据获取,并给出相应的代码示例。JD商品评论API提供了一系列的接口,允许开发者根据需要获取不同维度的评论数据。通过该API,开发者可以获取到商品的详细评论信息、评论的统计数据以及用户的评论行为数据等。

基于神经网络——鸢尾花识别(Iris)
鸢尾花识别是学习AI入门的案例,这里和大家分享下使用Tensorflow2框架,编写程序,获取鸢尾花数据,搭建神经网络,最后训练和识别鸢尾花。
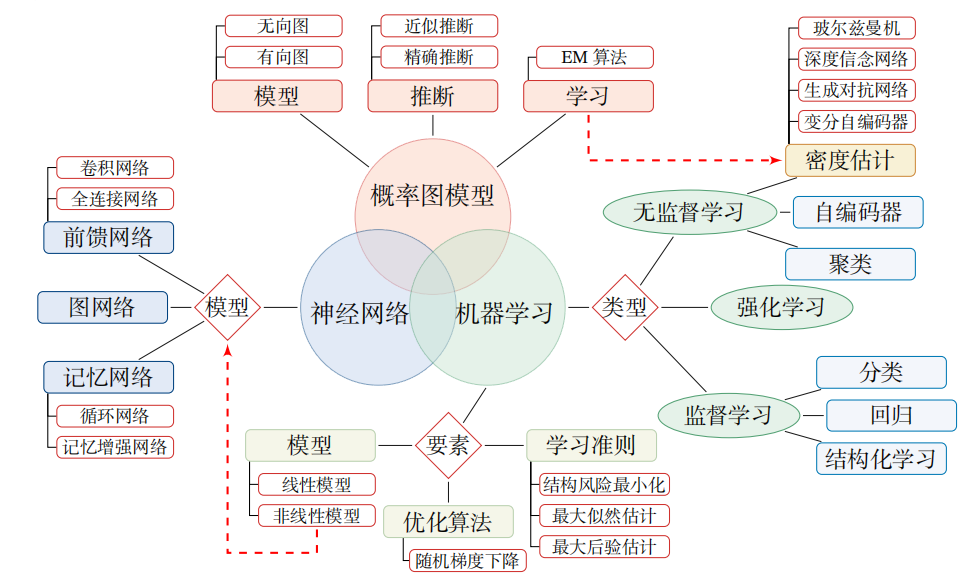
深度学习知识点全面总结
深度学习定义:一般是指通过训练多层网络结构对未知数据进行分类或回归深度学习分类:有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等; 无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。神经网络的计算主要有两种:前向传播(foward propagation, FP)作用于每一层的输入,通过逐层计算得到输出结果;
光伏发电模式中,分布式和集中式哪种更受欢迎?
5.可实现远距离输送,集中式光伏电站发出的电经高压并网,将电一层层的输送到更高的电压等级,如将高压电输送到华东等地区,以实现西电东输。分布式光伏发电:一般建在楼顶、屋顶、厂房等地方,较多的是基于建筑物表面,就近解决用户的用电问题,通过并网实现供电差额的补偿与外送。1.光伏电源处于用户侧,自发自用,就近发电,就近用电,发电供给当地负荷,视作负载,可以减少对电网供电的依赖,减少线路损耗。4.分布式光伏一般就近并网,线路的损耗很低或者可以说没有,可非常方便的补充当地的电量,供当地及附近的用电用户使用。
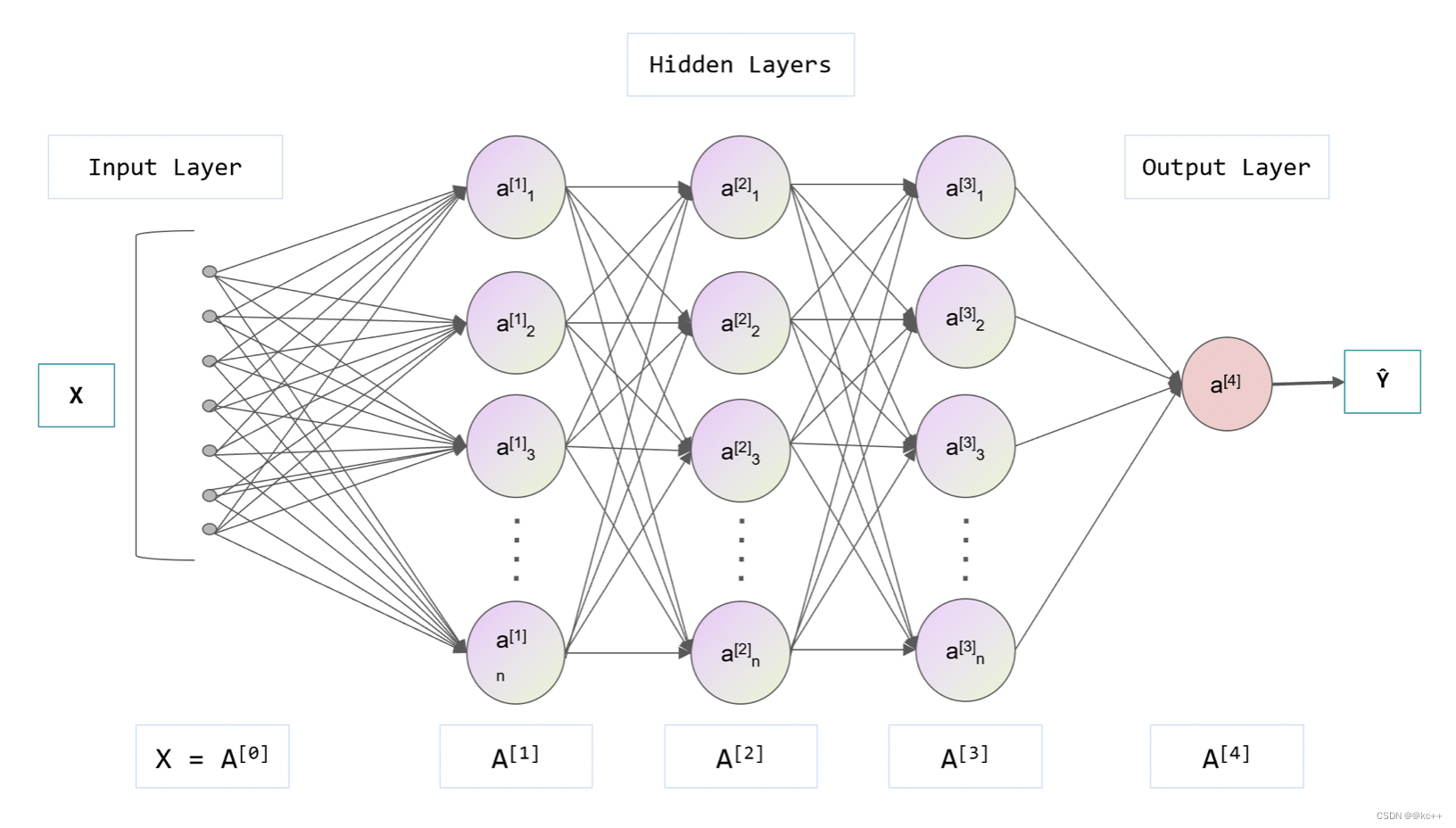
深度学习与神经网络
神经网络是一种模拟人脑神经元行为的计算模型,神经网络由大量的神经元(在计算领域中常被称为“节点”或“单元”)组成,并且这些神经元被分为不同的层,分别为输入层、隐藏层和输出层。每一个神经元都与前一层的所有神经元相连接,连接的强度(或权重)代表了该连接的重要性。神经元接收前一层神经元的信息(这些信息经过权重加权),然后通过激活函数(如Sigmoid、ReLU等)处理,将结果传递到下一层。输入层接收原始数据,隐藏层负责处理这些数据,而输出层则将处理后的结果输出。
一篇文章讲清楚!数据库和数据仓库到底有什么区别和联系?
数据库的数据来源来自各种业务系统软件程序的产生的数据,或者是由和这些业务系统软件交互的用户产生的数据,而数据仓库的数据来源则直接是这些业务系统的一个或者多个数据库或者文件,比如 SQL Server、Oracle、MySQL、Excel、文本文件等。也可以简单理解为很多个业务系统的数据库往数据仓库输送数据,是各个数据库的集合体,一个更大的数据库,数据仓库的建立是要打通这些基础数据库的数据的。所以,业务系统的数据库更多的是增删改操作,而数据仓库更多的是查询操作,这就决定了建模方式会有很大的差异。
一文读懂数据仓库、数据湖、湖仓一体
一个数据湖可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图形、音频、视频)。这套架构,以数据湖为中心,把数据湖作为中央存储库,再围绕数据湖建立专用“数据服务环”,环上的服务包括了数仓、机器学习、大数据处理、日志分析,甚至RDS和NOSQL服务等等。从数据含金量来比,数据仓库里的数据价值密度更高一些,数据的抽取和Schema的设计,都有非常强的针对性,便于业务分析师迅速获取洞察结果,用与决策支持。

绝地求生电脑版的最低配置要求?
更好的方式是通过官方的渠道购买游戏账号,并遵守游戏的规则和使用协议,以保证自己的游戏体验和账号安全性。但请注意,游戏的配置要求可能随着游戏的更新而有所改变,建议您在购买或升级电脑时,参考官方的配置要求以获得最佳游戏体验。如果您的电脑配备了更高性能的处理器,游戏的运行体验将更为流畅。绝地求生是一款较为复杂的游戏,需要较大的内存来加载游戏资源并确保游戏的流畅运行。所以在安装游戏之前,确保您的电脑有足够的存储空间。这些推荐配置可以使您在绝地求生中获得更高的帧率和更好的画面表现,提供更加顺畅和逼真的游戏体验。

什么是 ClickHouse(实时数据分析数据库)
1、ClickHouse是俄罗斯搜索巨头 Yandex 公司早 2016年 开源的一个极具 " 战斗力 " 的实时数据分析数据库,开发语言为C++2、是一个用于联机分析OLAP:Online Analytical Processing) 的列式数据库管理系统(DBMS:Database Management System),简称CK3、工作速度比传统方法快100-1000倍,ClickHouse 的性能超过了目前市场上可比的面向列的DBMS。每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。
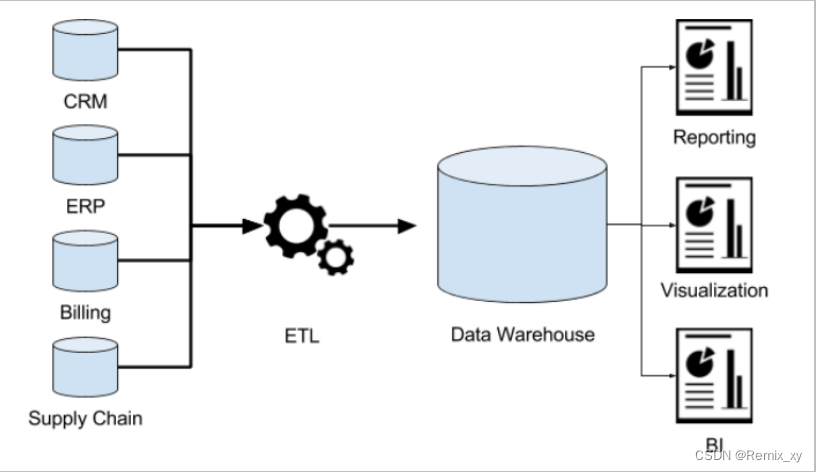
数据仓库介绍
1、什么是数据仓库? 存储数据的仓库, 主要是用于存储过去既定发生的历史数据, 对这些数据进行数据分析的操作, 从而对未来提供决策支持 2、数据仓库最大的特点: 既不生产数据, 也不消耗数据, 数据来源于各个数据源 3、数据仓库的四大特征: 1) 面向于主题的: 面向于分析, 分析的内容是什么 什么就是我们的主题 2) 集成性: 数据是来源于各个数据源, 将各个数据源数据汇总在一起。

【Flink】字节跳动 Flink 基于 Slot 的资源管理实践
总体上来讲,Flink 整个资源管理、申请和分配围绕 Slot 展开,同时每个 TaskManager 中的 Slot 数量决定了作业在该 TaskManager 中运行的并发计算任务数量。本篇文章主要介绍了 Slot 对资源分配、释放以及计算执行的影响,希望可以帮助大家更好地决策每个 TaskManager 中的 Slot 数量,对 Flink 作业进行调优。

【Flink】如何在 Flink 中规划 RocksDB 内存容量?
主要是自己学习。本文描述了一些配置选项,这些选项将帮助您有效地管理规划 Apache Flink 中 RocksDB state backend 的内存大小。在前面的文章 [1] 中,我们描述了 Flink 中支持的可选 state backend 选项,本文将介绍跟 Flink 相关的一些 RocksDB 操作,并讨论一些提高资源利用率的重要配置。

【redis】Redis 架构演化之路
里面大致说了redis的架构演进。开始学redis架构的时候,总是感觉架构好多,迷迷糊糊的,但是你知道Redis 架构演化之路之后,就明白了前因后果,这样学习更加深入以及搞笑。这篇文章我想和你聊一聊 Redis 的架构演化之路。现如今 Redis 变得越来越流行,几乎在很多项目中都要被用到,不知道你在使用 Redis 时,有没有思考过,Redis 到底是如何稳定、高性能地提供服务的?如果你对 Redis 已经有些了解,肯定也听说过。

Elasticsearch分布式搜索分析引擎本地部署与远程访问
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问