一篇文章讲清楚!数据库和数据仓库到底有什么区别和联系?
有位做数据分析的小伙伴问我:老师,你们做商业智能BI的总在讲数据仓库、数据仓库,我感觉在数据仓库上还是跟其它数据库一样操作写SQL就可以跑一些数据出来,感觉跟数据库没有什么区别啊,他们的区别到底在哪里啊?
数据库和数据仓库的区别
事实上,数据仓库和数据库的区别到底在哪里,这个问题其实很多很多人也问过,简单来说:数据仓库的本质就是数据库,存储方式都是一样的。只是两者的定位和服务对象不同、内部的数据组织形式不同。
可以从这几个角度来描述:
第一, 数据库通常服务于业务,数据仓库通常服务于分析。我们通常所提到的数据库一般都是服务于业务应用软件的,不管这些软件是 B/S 架构还是 C/S 架构,例如企业里面常用到的 ERP 系统、OA 系统,或者像我们手机上的点餐 APP、网上购票的 APP 等等。
这些业务系统的特点都是用户在这些软件系统上操作,比如登录、填写个人的信息、修改个人资料、查询一条记录等等,数据通过这些软件程序和背后的数据库进行交互,在底层的数据表上进行增删改查的操作。所以,通常这些数据库是服务于各种各样跑在操作系统之上的各种业务系统、应用软件,更多的面向业务流程、业务管理。
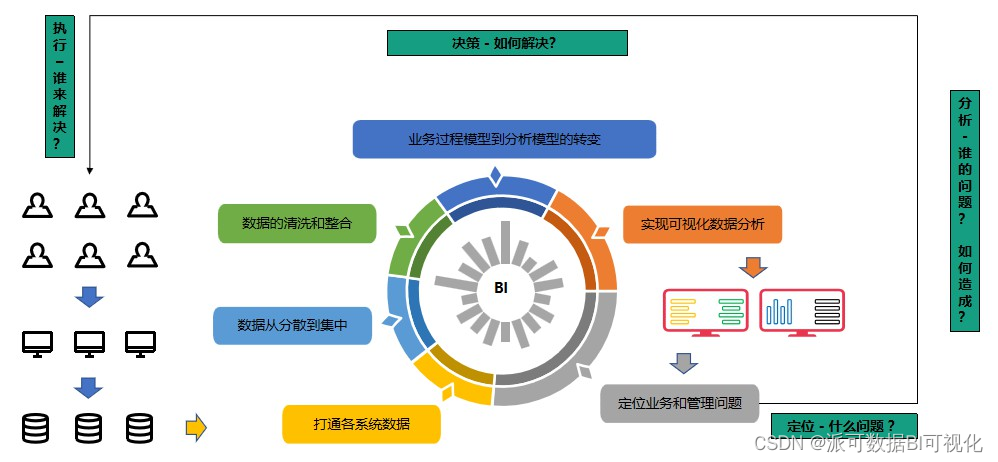 业务数据 - 派可数据商业智能BI可视化分析平台
业务数据 - 派可数据商业智能BI可视化分析平台
数据仓库就不一样了,它不是服务于业务信息化系统的,它是服务于分析型应用的。更多的是通过各种商业智能BI前端可视化分析工具或者报表工具来访问数据仓库,最终是面向报表查询,数据分析服务的。
第二,数据库的数据来源来自各种业务系统软件程序的产生的数据,或者是由和这些业务系统软件交互的用户产生的数据,而数据仓库的数据来源则直接是这些业务系统的一个或者多个数据库或者文件,比如 SQL Server、Oracle、MySQL、Excel、文本文件等。也可以简单理解为很多个业务系统的数据库往数据仓库输送数据,是各个数据库的集合体,一个更大的数据库,数据仓库的建立是要打通这些基础数据库的数据的。
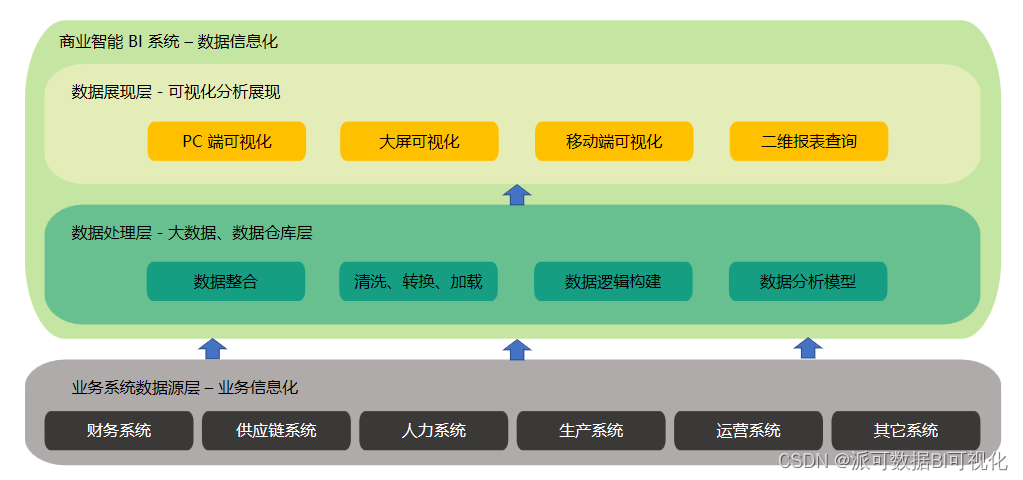 商业智能BI - 派可数据商业智能BI可视化分析平台
商业智能BI - 派可数据商业智能BI可视化分析平台
第三, 数据库在设计的时候很少存放历史数据,通常只是描述某一个业务时刻的数据,随着业务系统的变化而变化。数据仓库为了分析的目的会存放大量的历史数据,因为是每天抽取业务系统数据库的数据每天存放起来,大部分的数据都是静态的。
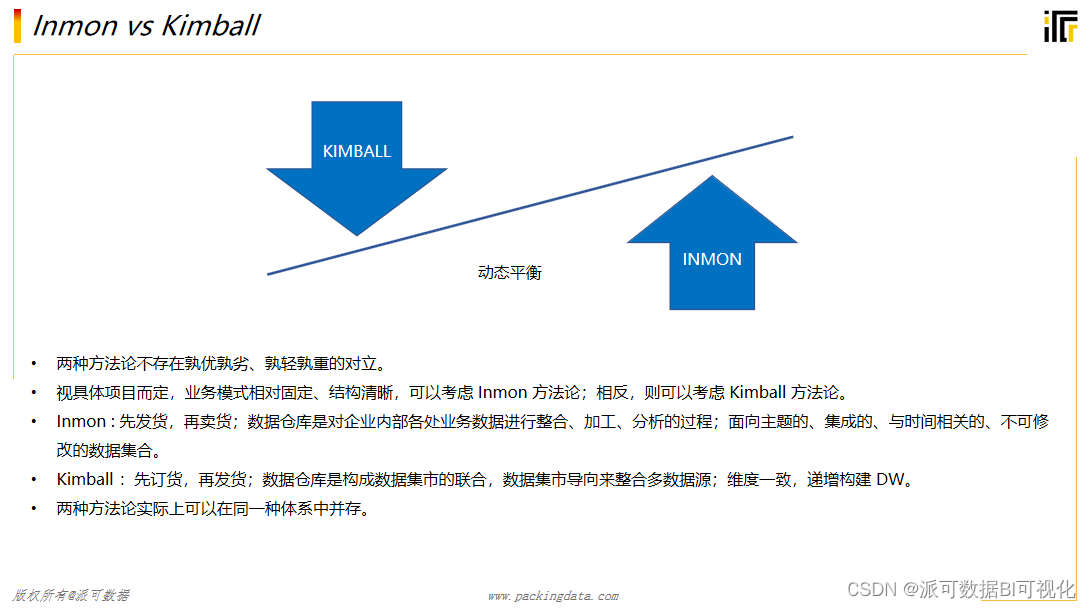
第四, 最核心的区别在于建模方式和数据的冗余。业务系统的数据库为了实现一个业务流程,在表的设计上通常采用的是三范式 3NF 建模方式,最小原子列不可细分、主外键等,通过一对多或者多对多的形式,减少数据冗余。而数据仓库在建模方式上既有三范式 3NF 建模,也有维度建模比如星型或雪花型的建模方式,通常一般都是使用 Kimball 的维度建模。
 建模方式 - 派可数据商业智能BI可视化分析平台
建模方式 - 派可数据商业智能BI可视化分析平台
像Kimball的这种维度建模的方式都是反规范性设计的,保留了大量的数据冗余,为了查询的效率。所以,业务系统的数据库更多的是增删改操作,而数据仓库更多的是查询操作,这就决定了建模方式会有很大的差异。一个是面向业务流程,一个是面向分析服务。
同时,为了底层架构的稳定性和健壮性,数据仓库还会进行底层表的分层设计,比如经常看到的 ODS 层、Staging 层、Trans 层、Dimension 层、Fact 层、Data Mart 层等。这种分层的好处就是解耦,隔离底层业务系统的变化对上层模型以及页面的影响,也便于后期的数据维护。
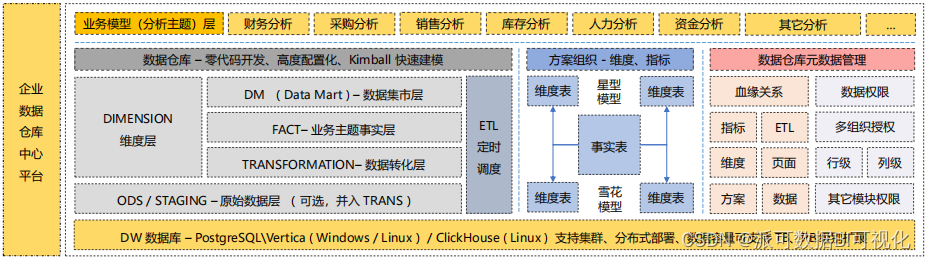 数据仓库 - 派可数据商业智能BI可视化分析平台
数据仓库 - 派可数据商业智能BI可视化分析平台
简单总结一下:数据仓库的本质仍然是数据库,只是服务对象不同。一个是服务于业务系统,一个是服务于商业智能BI可视化分析。服务对象的不同决定了数据库底层的数据组织形式主要是以三范式建模,来适应业务系统频繁增删改的需要。
而数据仓库为了业务分析的目的,因此需要拉通各个业务系统数据库的数据,保留大量历史数据,同时为了分析效率的提升改变了传统数据库的数据组织形式,例如利用适合于分析型模型的Kimball维度建模方式来组织底层数据架构。数据库服务于业务流程,通过业务软件来访问;数据仓库服务于商业智能BI分析,通过商业智能BI前端可视化分析工具来访问。
相关文章:

【Mongdb之数据同步篇】什么是Oplog、Mongodb 开启oplog,java监听oplog并写入关系型数据库、Mongodb动态切换数据源
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。Oplog 可以说是Mongodb Replication的纽带了。

Windows下安装和配置Redis
下载版本Redis-x64-5.0.14.1.zip。(可能需要开代理)
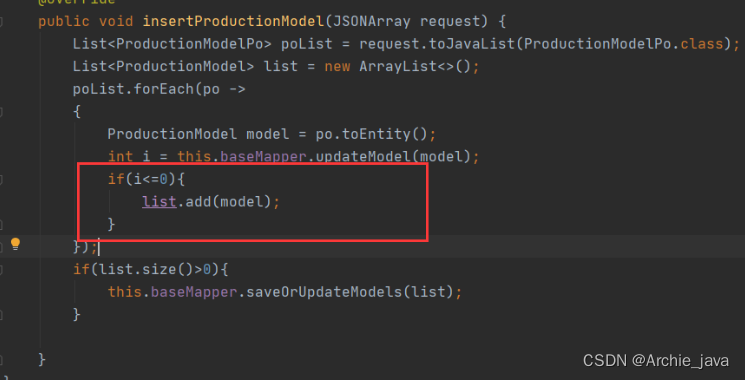
ON DUPLICATE KEY UPDATE 导致mysql自增主键ID跳跃增长
具体解决方案可以根据项目来选择,如果项目不大,可以考虑1和2。如果不考虑高并发问题,可以考虑3。
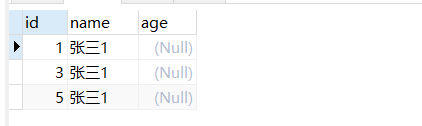
mysql唯一索引与null
根据NULL的定义,NULL表示的是未知,因此两个NULL比较的结果既不相等,也不不等,结果仍然是未知。根据这个定义,多个NULL值的存在应该不违反唯一约束,所以是合理的,在oracel也是如此。在mysql 的innodb引擎中,是允许在唯一索引的字段中出现多个null值的。有上面的表和数据可以看出,查询多条数据。

详解mybatis的insert,update,delete返回值
为什么要提数据的事呢,是因为据说这个save返回的就是插入的数据的条数。但是遗憾的是,我们的这个user怎么能没有id呢,没有id有怎么查,怎么删,怎么改。进来的是没有id的user,出去的是有id的user,真是太厉害了,没想到不仅把返回值改变了,连参数都发生了改变,真是太神奇了。keyProperty=“id” 这是id就是绑定的id,那我就疑惑了,这绑定的哪个id啊。这样一搞,如果插入成功的话返回的是1,如果不成功的话返回的是-1。我让你删id是222222的,我还没创建呢,看你怎么删。
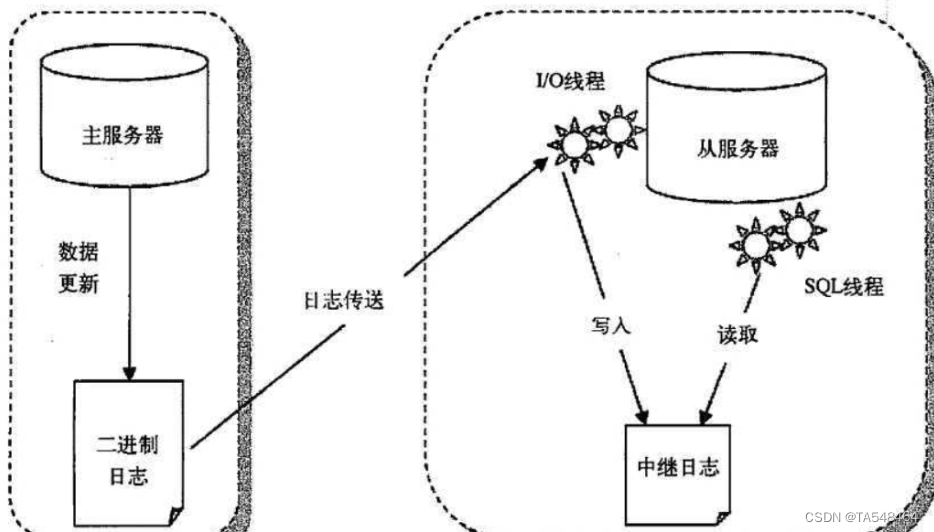
MySQL主从复制(基于binlog日志方式)
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。主从复制的作用1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。3.读写分离,使数据库能支撑更大的并发。a.从服务器可以执行查询工作(就是我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
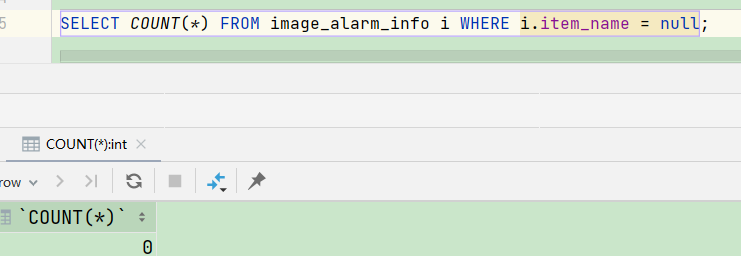
MySQL 中 is null 和 =null 的区别
如果 set ANSI_NULLS为 ON 时,表示SQL语句遵循SQL-92标准;如果 set ANSI_NULLS 为 OFF 时,表示不遵从 SQL-92 标准。但SQL-92 标准要求对null的 = 或不等于 (!= ,) 比较取值都为 false,也就是 =null 或者 null,返回的都是false。null 在MySQL中不代表任何值,通过运算符是得不到任何结果的,因此只能用 is null(默认情况)MySQL 中 null 不代表任务实际的值,类似于一个未知数。
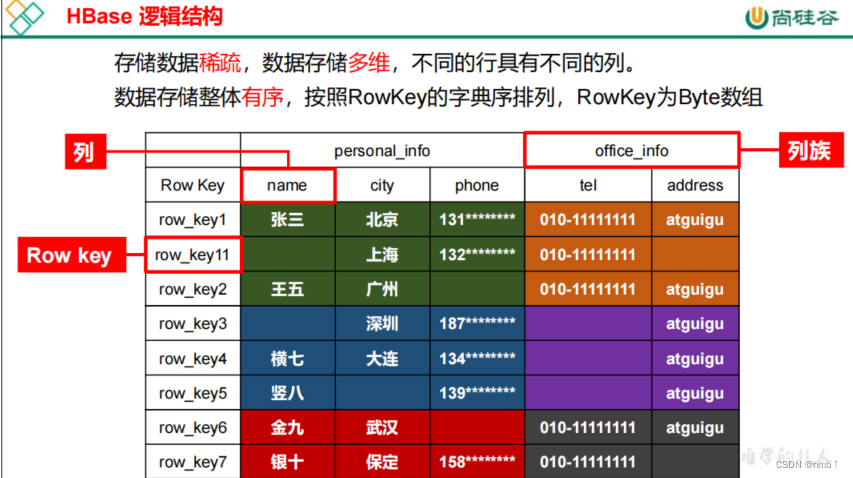
Springboot整合HBase——大数据技术之HBase2.x
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

终于有人把Web 3.0和元宇宙讲明白了
分散的数据网络使个人数据(例如个人的健康数据、农民的作物数据或汽车的位置和性能数据)出售或交换成为可能,与此同时,不会失去对数据的所有权控制、放弃数据隐私或依赖第三方平台来管理数据。Web 3.0的目标是在创作者经济中取得更好的平衡。互联网第二次迭代(Web 2.0)的缺陷,加上公有区块链技术的诞生,帮助我们朝着更加去中心化的Web 3.0 迈进,元宇宙和更广泛的去中心化网络都是关于现实世界和虚拟世界的融合。此时的网络中不再是静态内容,而是动态的内容,用户现在可以与发布在网络上的内容进行交互。

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。

配置nginx+keepalived高可用代理数据库ip端口
需求:配置nginx+keepalived高可用反向代理数据库ip端口(数据库服务器无法增加新SCAN IP或者需要隐藏数据库IP的情况下适用)本机ip为:192.168.20.10和192.168.20.11。2.任意节点关机或重启系统,浮动ip也会自动漂移到另外节点。1.任意节点停nginx:浮动ip会自动漂移到另外节点。安装依赖包和nginx和keepalived。浮动IP为:192.168.20.20。配置keepalived.conf。两台centos7.9。
万字详解数据仓库、数据湖、数据中台和湖仓一体
数字化转型浪潮卷起各种新老概念满天飞,数据湖、数据仓库、数据中台轮番在朋友圈刷屏,有人说“数据中台算个啥,数据湖才是趋势”,有人说“再见了数据湖、数据仓库,数据中台已成气候”……企业还没推开数字化大门,先被各种概念绊了一脚。那么它们 3 者究竟有啥区别?别急,先跟大家分享两个有趣的比喻。1、图书馆VS地摊如果把数据仓库比喻成“图书馆”,那么数据湖就是“地摊”。去图书馆借书(数据),书籍质量有保障,但你得等,等什么?等管理员先查到这本书属于哪个类目、在哪个架子上,你才能精准拿到自己想要的书;
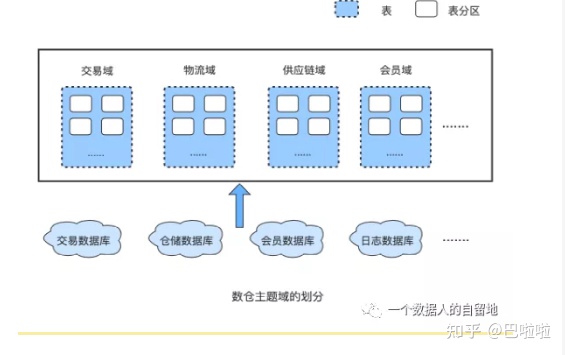
什么是数据中台?
说完了数据中台诞生的历史背景,现在,我们应该对数据中台有了一定的了解,那我们现在给数据中台下个定义。自2016年,数据中台被提出以来,不同的人对数据中台有不同的理解,就像一千个读者心中有一千个哈姆雷特,因此也有许多不同的定义,以下是我从一些文章、书籍中搜集到的关于数据中台的定义:数据中台是DT时代的大背景下,为实现数据快(快速)、准(准确)、省(低成本)赋能业务发展的目标,将企业的数据统一整合起来,基于Onedata方法论借助大数据平台完成数据的统一加工处理,对外提供数据服务的一套机制。
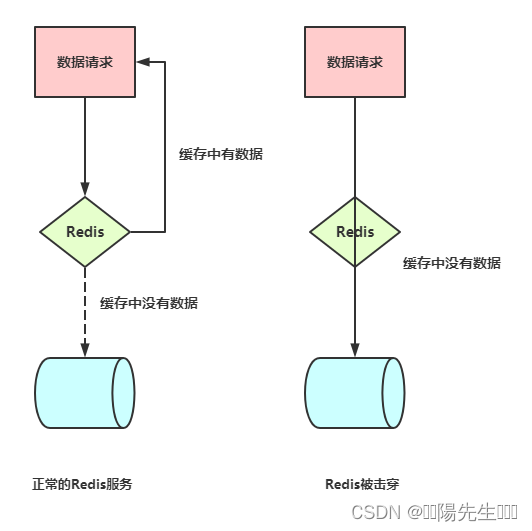
Redis 击穿、穿透、雪崩产生原因解决思路
也就是在设定的时间里数据没有取出来,但是锁由过期了,常见的思路是,锁过期时间值递增,但是想想不靠谱,因为第一个请求可能超时,如果后面的也超时呢,接连多次超时之后,锁过期时间值势必特别大了,这样做弊端太多。雪崩,和击穿类似,不同的是击穿是一个热点Key某时刻失效,而雪崩是大量的热点Key在一瞬间失效,网络上很多博客都在强调解决雪崩的策略是随机过期时间,这个非常不准确,举个例子,银行做活动,之前这个利息系数为2%,过了零点系数改为3%,这种情况能将用户的对应的key改为随机过期吗?如果用的过去的数据叫脏数据。
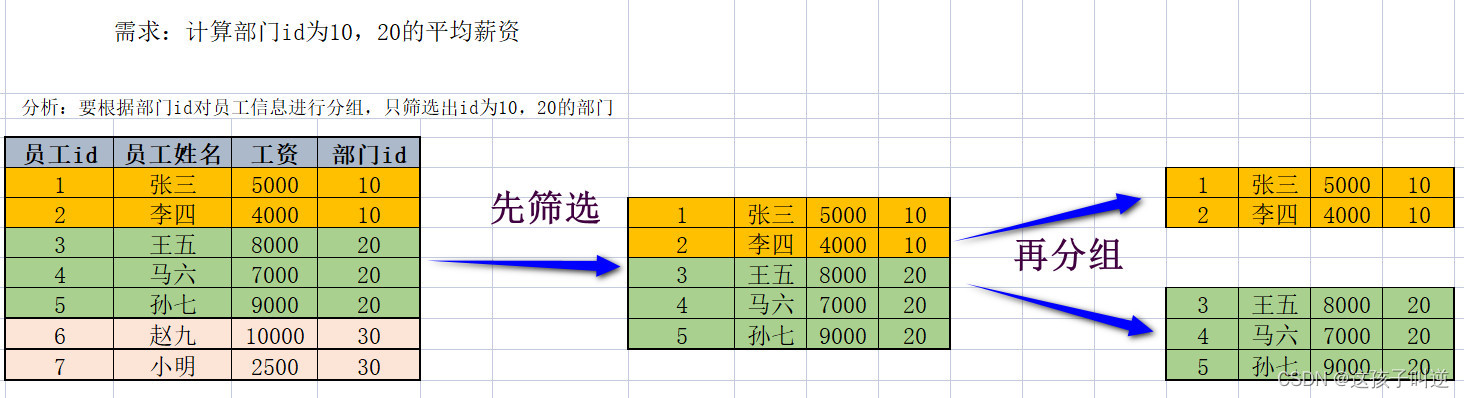
MySQL数据库查询语句之组函数,子查询语句
当一个SQL的执行需要借助另一个SQL的执行结果时,则需要进行SQL嵌套,该语法结构称之为子查询。先筛选出符合要求的数据,再对符合要求的数据进行分组时,分组的工作量会被减少,效率更高。先确定从哪张表进行操作-->对表中数据进行分组-->基于分组结果进行查询操作。执行顺序:优先执行小括号内的子SQL,根据子SQL的执行结果再执行外层SQL。执行顺序:from-->where-->group by-->select。执行顺序:from-->group by-->select。
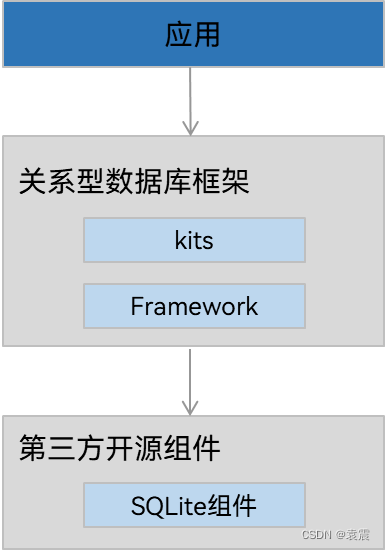
鸿蒙harmony--数据库sqlite详解
今天是1月20号星期六,早安,岁末大寒至,静后春归来。愿他乡故人,漂泊有归宿,前程有奔赴,愿人间不寒,温暖常伴,诸事顺利,喜乐长安。
Git 的基本概念、使用方式及常用命令
Git的基本概念、使用方式及常用命令
Redis的key过期策略是怎么实现的
这是一道经典的Redis面试题,一个Redis中可能存在很多很多的key,这些key中可能有很大一部分都有过期时间,此时Redis服务器咋知道哪些key已经过期,哪些还没过期呢?如果直接遍历所有的key,这显然是行不通的,效率非常低!!Redis整体的策略是定期删除和惰性删除相结合。举个栗子:假如我去小卖铺买东西,付款的时候,发现东西过期了。就告知老板,于是老板下架此产品。消费者发现过期了,才去下架,这就叫。小卖铺老板主动定期抽取一部分商品,进行筛查,这就叫定期删除。
雪花算法生成ID、UUID生成ID和MySql自增ID优缺点分析
综上所述,UUID适用于分布式系统和需要保密的场景,雪花ID适用于分布式系统和高并发环境,MySQL自增ID适用于单机系统和高效查询的场景。根据具体的业务需求和系统架构,选择合适的主键类型。通过本文的介绍和对比,希望读者能够更好地理解在MySQL中不推荐使用UUID或者雪花ID作为主键的原因,并能够根据实际情况做出明智的选择。在MySQL中,使用自增整数作为主键是一种常见的做法,因为它具有较小的存储空间、高效的索引和自动增长的特性。然而,具体选择何种主键类型还是要根据具体的业务需求和数据特点来决定。
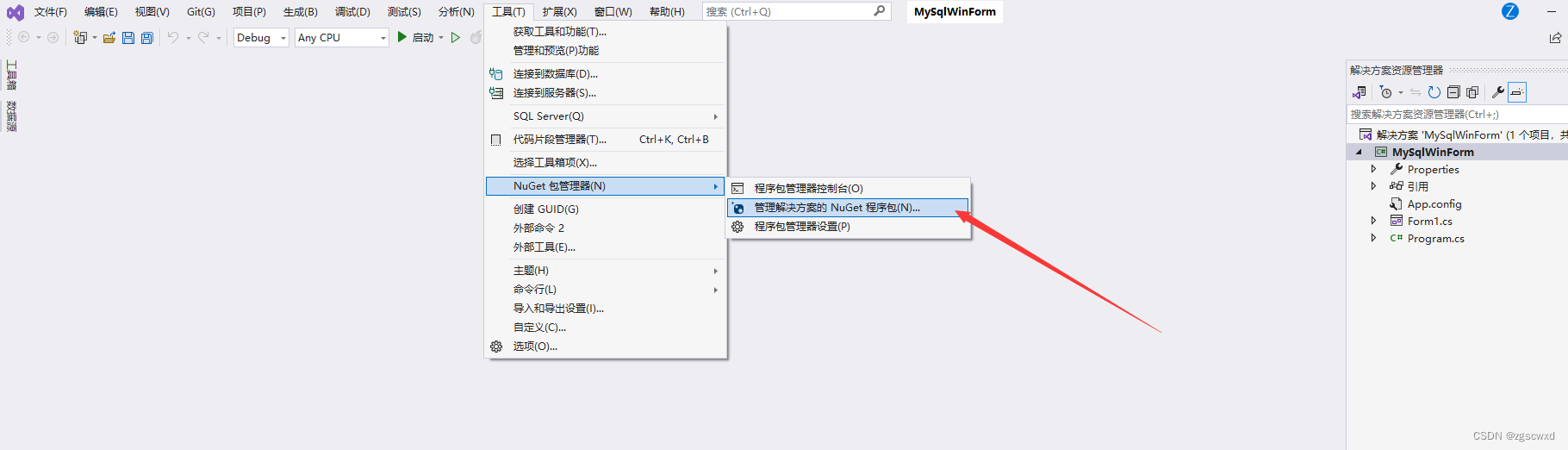
【小白专用】C# 连接 MySQL 数据库
C# 连接 MySQL 数据库
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
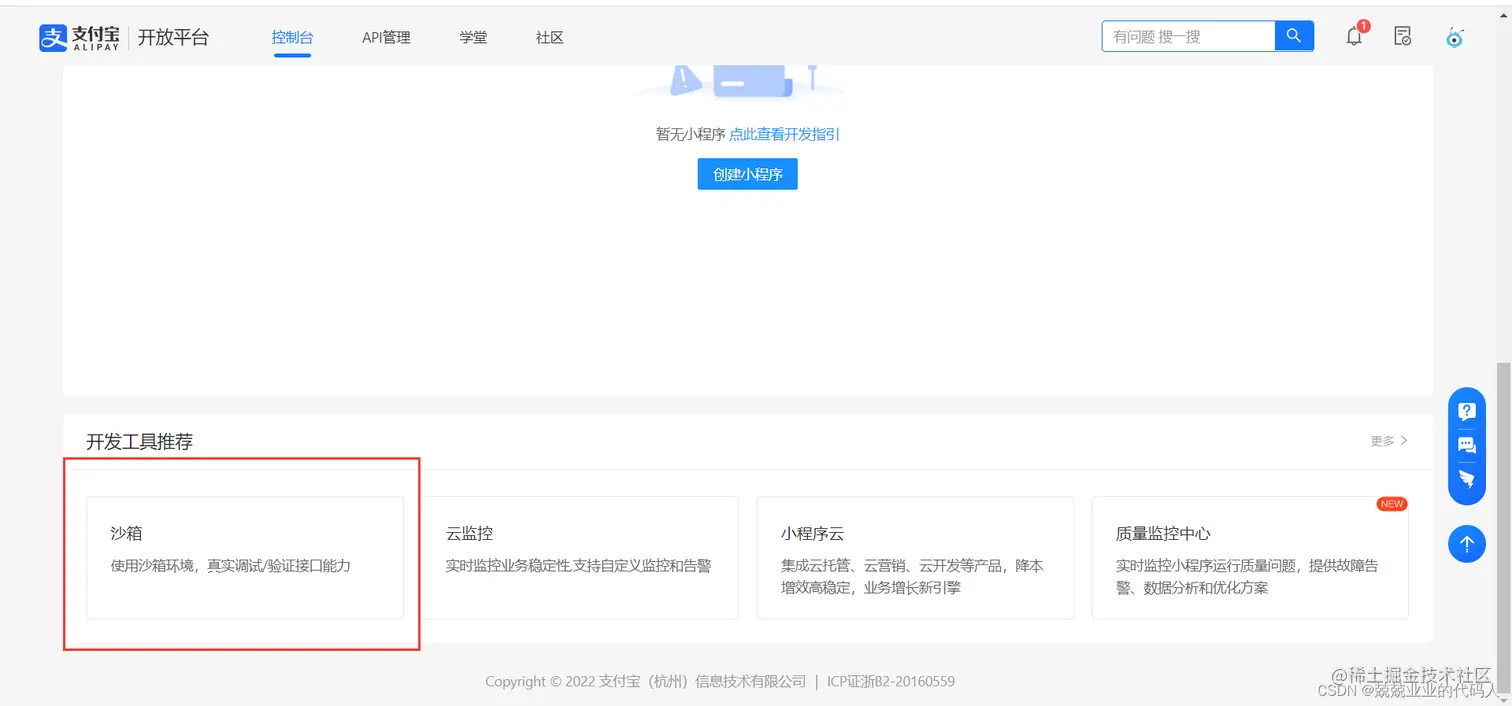
Springboot支付宝沙箱支付---完整详细步骤
两种方式进行配置。这里我采取的是默认方式: 开发者如需使用系统默认密钥/证书,可在开发信息中选择系统默认密钥。注意:使用API在线调试工具调试OpenAPI必须使用系统默认密钥。
Linux安装MongoDB教程
将解压后的 mongodb-linux-x86_64-rhel70-4.2.23 中的所有文件全部移动到 /usr/local/mongodb 中 :注意/*是所有子文件。也可以不用设置环境变量进行启动,但是不设置环境变量启动的话要每次启动写很多启动参数,比较麻烦,所以做好配置环境变量。在 mongodb 下创建 data 和 logs 目录,以及日志文件mongodb.log。在 /usr/local 目录中创建 mongodb 文件夹。启动 MongoDB(-conf 使用配置文件方式启动)

怎么选择数据安全交换系统,能够防止内部员工泄露数据?
数据泄露可能给企业带来诸多风险:财产损失、身份盗窃、骚扰和诈骗、经济利益受损、客户信任度下降、法律风险和责任等,《2021年度数据泄漏态势分析报告》中显示,在数据泄露的主体中,内部人员导致的数据泄漏事件占比接近60%。飞驰云联文件安全交换系统,可以满足企业多场景下的文件交换需求,帮助企业终结多工具、 多系统并行使用的局面,减少因文件交换行为分散带来的数据管理不集中、难以管控的问题, 帮助企业内部构建统一、安全的企业数据流转通道。对于不能下载保存的数据,使用截屏、录屏的方式窃取并外泄数据;
弹性搜索引擎Elasticsearch:本地部署与远程访问指南
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问。
Hive(总)看完这篇,别说你不会Hive!
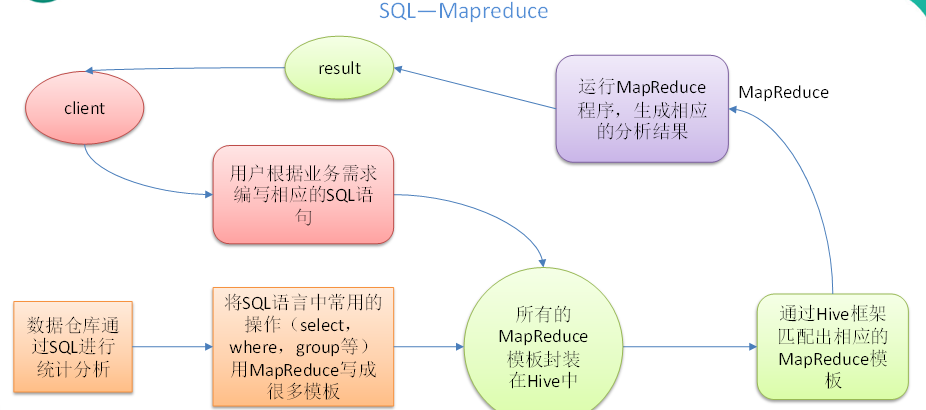
Hive:由Facebook开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。本质是:将HQL转化成MapReduce程序1)Hive处理的数据存储在HDFS2)Hive分析数据底层的实现是MapReduce3)执行程序运行在Yarn上创建一个数据库,数据库在HDFS上的默认存储路径是/opt/hive/warehouse/*.db避免要创建的数据库已经存在错误,增加if not exists判断。
什么是HBase?终于有人讲明白了
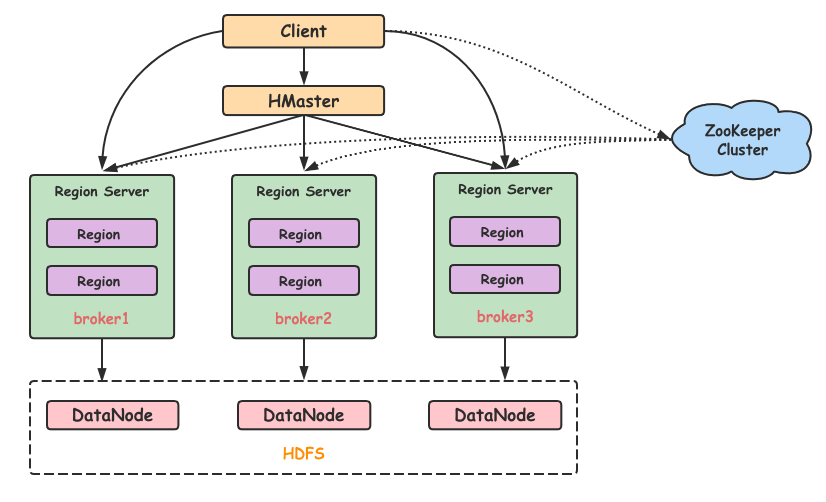
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息。
Spring中事务控制的API介绍(PlatformTransactionManager和TransactionDefinition)
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。例如:methodA事务方法调用methodB事务方法时,methodB是继续在调用者methodA的事务中运行呢,还是为自己开启一个新事务运行,这就是由methodB的事务传播行为决定的。属性,同时,Spring 还为我们提供了一个默认的实现类:DefaultTransactionDefinition,该类适用于大多数情况。作用:是一个事务管理器,负责开启、提交或回滚事务。
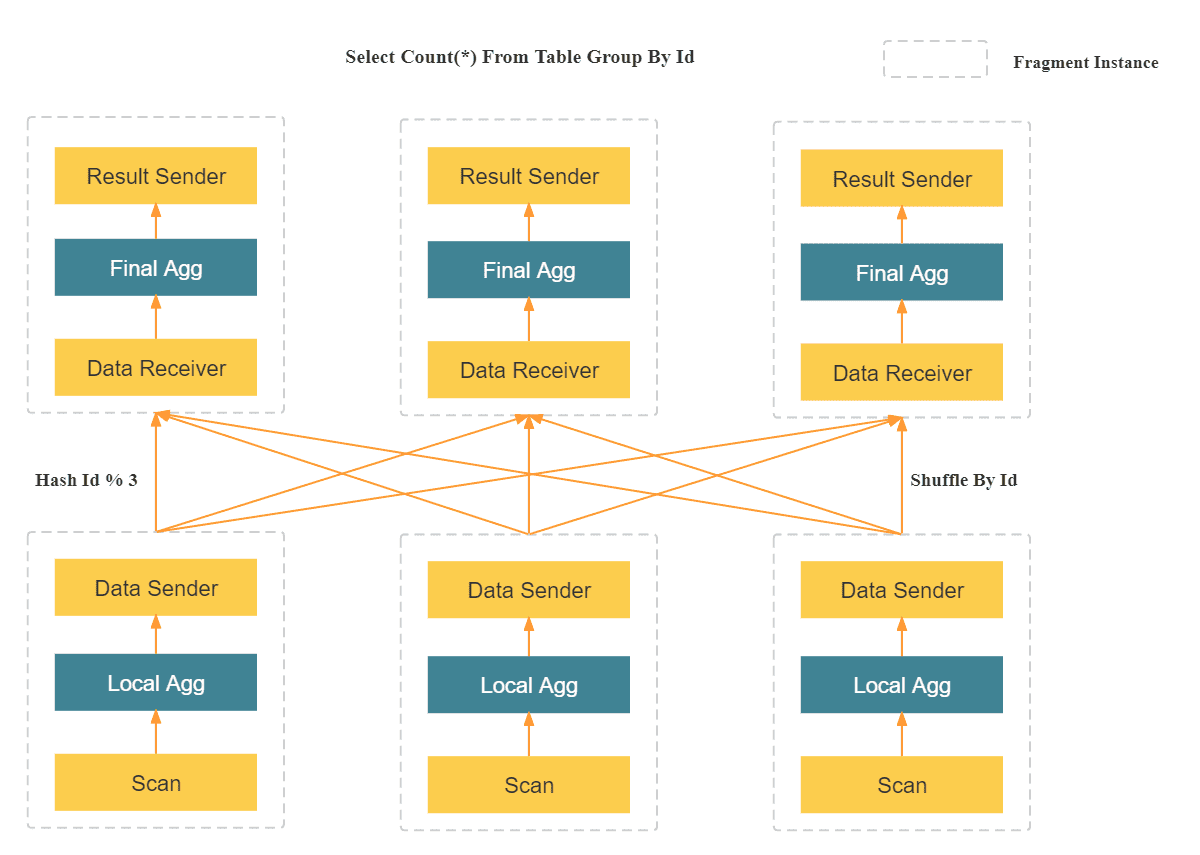
数据仓库系列:StarRocks 入门培训教程
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。提供千亿级大数据的在线多维分析和分布式存储。新一代极速全场景 MPP (Massively Parallel Processing) 数据库是forkdoris后独立运营的商业化版本StarRocks。

ClickHouse & StarRocks 使用经验分享
总结一下,如果是需要分析日志流数据,更加推荐 ClickHouse ,因为 ClickHouse 单机强悍,可以支撑亿级别数据量,架构简单,相比于 StarRocks 也更加稳定,相比集群,更推荐单机 ClickHouse。如果是分析业务流数据,更加推荐 StarRocks ,因为 StarRocks 对于更新场景性能更加,而且 JOIN 性能更好,而且更加推荐部署 StarRocks 集群,可以充分发挥 StarRocks 的性能。