8.11. Migrating MySQL Data into Elasticsearch using logstash
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html
安装 JDBC 驱动 和 Logstash
curl -s https://raw.githubusercontent.com/oscm/shell/master/database/mysql/5.7/mysql-connector-java.sh | bash curl -s https://raw.githubusercontent.com/oscm/shell/master/search/logstash/logstash-5.x.sh | bash
mysql 驱动文件位置在 /usr/share/java/mysql-connector-java.jar
创建配置文件 /etc/logstash/conf.d/jdbc-mysql.conf
mysql> desc article; +-------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+---------+-------+ | id | int(11) | NO | | 0 | | | title | mediumtext | NO | | NULL | | | description | mediumtext | YES | | NULL | | | author | varchar(100) | YES | | NULL | | | source | varchar(100) | YES | | NULL | | | ctime | datetime | NO | | NULL | | | content | longtext | YES | | NULL | | +-------------+--------------+------+-----+---------+-------+ 7 rows in set (0.00 sec)
input {jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *"statement => "select * from article"}
}
output {elasticsearch {hosts => "localhost:9200"index => "information"document_type => "article"document_id => "%{id}"}
}
root@netkiller /var/log/logstash % systemctl restart logstashroot@netkiller /var/log/logstash % systemctl status logstash
● logstash.service - logstashLoaded: loaded (/etc/systemd/system/logstash.service; enabled; vendor preset: disabled)Active: active (running) since Mon 2017-07-31 09:35:00 CST; 11s agoMain PID: 10434 (java)CGroup: /system.slice/logstash.service└─10434 /usr/bin/java -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -Djava.awt.headless=true -Dfi...Jul 31 09:35:00 netkiller systemd[1]: Started logstash.
Jul 31 09:35:00 netkiller systemd[1]: Starting logstash...root@netkiller /var/log/logstash % cat logstash-plain.log
[2017-07-31T09:35:28,169][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[2017-07-31T09:35:28,172][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://localhost:9200/, :path=>"/"}
[2017-07-31T09:35:28,298][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>#<Java::JavaNet::URI:0x453a18e9>}
[2017-07-31T09:35:28,299][INFO ][logstash.outputs.elasticsearch] Using mapping template from {:path=>nil}
[2017-07-31T09:35:28,337][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>50001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"_all"=>{"enabled"=>true, "norms"=>false}, "dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date", "include_in_all"=>false}, "@version"=>{"type"=>"keyword", "include_in_all"=>false}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2017-07-31T09:35:28,344][INFO ][logstash.outputs.elasticsearch] Installing elasticsearch template to _template/logstash
[2017-07-31T09:35:28,465][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>[#<Java::JavaNet::URI:0x66df34ae>]}
[2017-07-31T09:35:28,483][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>1000}
[2017-07-31T09:35:29,562][INFO ][logstash.pipeline ] Pipeline main started
[2017-07-31T09:35:29,700][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2017-07-31T09:36:01,019][INFO ][logstash.inputs.jdbc ] (0.006000s) select * from article 适合数据没有改变的归档数据或者只能增加没有修改的数据
input {jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *"statement => "select * from article"}
}
output {elasticsearch {hosts => "localhost:9200"index => "information"document_type => "article"document_id => "%{id}"}
}多张数据表导入到 Elasticsearch
# multiple inputs on logstash jdbcinput {jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *"statement => "select * from article"type => "article"}jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *"statement => "select * from comment"type => "comment"}
}
output {elasticsearch {hosts => "localhost:9200"index => "information"document_type => "%{type}"document_id => "%{id}"}
} 需要在每一个jdbc配置项中加入 type 配置,然后 elasticsearch 配置项中加入 document_type => "%{type}"
input {jdbc {statement => "SELECT id, mycolumn1, mycolumn2 FROM my_table WHERE id > :sql_last_value"use_column_value => truetracking_column => "id"tracking_column_type => "numeric"# ... other configuration bits}
}tracking_column_type => "numeric" 可以声明 id 字段的数据类型, 如果不指定将会默认为日期
[2017-07-31T11:08:00,193][INFO ][logstash.inputs.jdbc ] (0.020000s) select * from article where id > '2017-07-31 02:47:00'
如果复制不对称可以加入 clean_run => true 配置项,清楚数据
input {jdbc {statement => "SELECT * FROM my_table WHERE create_date > :sql_last_value"use_column_value => truetracking_column => "create_date"# ... other configuration bits}
}如果复制不对称可以加入 clean_run => true 配置项,清楚数据
statement_filepath 指定 SQL 文件,有时SQL太复杂写入 statement 配置项维护部方便,可以将 SQL 写入一个文本文件,然后使用 statement_filepath 配置项引用该文件。
input {jdbc {jdbc_driver_library => "/path/to/driver.jar"jdbc_driver_class => "org.postgresql.Driver"jdbc_url => "jdbc://postgresql"jdbc_user => "neo"jdbc_password => "password"statement_filepath => "query.sql"}
} 将需要复制的条件参数写入 parameters 配置项
input {jdbc {jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"jdbc_user => "mysql"parameters => { "favorite_artist" => "Beethoven" }schedule => "* * * * *"statement => "SELECT * from songs where artist = :favorite_artist"}
} jdbc_fetch_size => 1000 #jdbc获取数据的数量大小jdbc_page_size => 1000 #jdbc一页的大小,jdbc_paging_enabled => true #和jdbc_page_size组合,将statement的查询分解成多个查询,相当于: SELECT * FROM table LIMIT 1000 OFFSET 4000
通过 if [type]=="news" 执行不同的区块,实现将不同的type输出到指定的 index 中。
output {if [type]=="news" {elasticsearch {hosts => "node1.netkiller.cn:9200"index => "information"document_id => "%{id}"}}if [type]=="comment" {elasticsearch {hosts => "node2.netkiller.cn:9200"index => "information"document_id => "%{id}"}}
} 日期格式化, 将ISO 8601日期格式转换为 %Y-%m-%d %H:%M:%S
input {jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/cms"jdbc_user => "cms"jdbc_password => "123456"schedule => "* * * * *"statement => "select * from article limit 5"}}
filter {ruby {init => "require 'time'"code => "event.set('ctime', event.get('ctime').time.localtime.strftime('%Y-%m-%d %H:%M:%S'))"}ruby {init => "require 'time'"code => "event.set('mtime', event.get('mtime').time.localtime.strftime('%Y-%m-%d %H:%M:%S'))"}
}
output {stdout {codec => rubydebug}} 下面的例子实现了新数据复制,旧数据更新
input {jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *" #定时cron的表达式,这里是每分钟执行一次statement => "select id, title, description, author, source, ctime, content from article where id > :sql_last_value"use_column_value => truetracking_column => "id"tracking_column_type => "numeric" record_last_run => truelast_run_metadata_path => "/var/tmp/article.last"}jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *" #定时cron的表达式,这里是每分钟执行一次statement => "select * from article where ctime > :sql_last_value"use_column_value => truetracking_column => "ctime"tracking_column_type => "timestamp" record_last_run => truelast_run_metadata_path => "/var/tmp/article-ctime.last"}
}
output {elasticsearch {hosts => "localhost:9200"index => "information"document_type => "article"document_id => "%{id}"action => "update" # 操作执行的动作,可选值有["index", "delete", "create", "update"]doc_as_upsert => true #支持update模式}
}jdbc-input-plugin 只能实现数据库的追加,对于 elasticsearch 增量写入,但经常jdbc源一端的数据库可能会做数据库删除或者更新操作。这样一来数据库与搜索引擎的数据库就出现了不对称的情况。
当然你如果有开发团队可以写程序在删除或者更新的时候同步对搜索引擎操作。如果你没有这个能力,可以尝试下面的方法。
这里有一个数据表 article , mtime 字段定义了 ON UPDATE CURRENT_TIMESTAMP 所以每次更新mtime的时间都会变化
mysql> desc article;
+-------------+--------------+------+-----+--------------------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+--------------------------------+-------+
| id | int(11) | NO | | 0 | |
| title | mediumtext | NO | | NULL | |
| description | mediumtext | YES | | NULL | |
| author | varchar(100) | YES | | NULL | |
| source | varchar(100) | YES | | NULL | |
| content | longtext | YES | | NULL | |
| status | enum('Y','N')| NO | | 'N' | |
| ctime | timestamp | NO | | CURRENT_TIMESTAMP | |
| mtime | timestamp | YES | | ON UPDATE CURRENT_TIMESTAMP | |
+-------------+--------------+------+-----+--------------------------------+-------+
7 rows in set (0.00 sec)logstash 增加 mtime 的查询规则
jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "password"schedule => "* * * * *" #定时cron的表达式,这里是每分钟执行一次statement => "select * from article where mtime > :sql_last_value"use_column_value => truetracking_column => "mtime"tracking_column_type => "timestamp" record_last_run => truelast_run_metadata_path => "/var/tmp/article-mtime.last"}创建回收站表,这个事用于解决数据库删除,或者禁用 status = 'N' 这种情况的。
CREATE TABLE `elasticsearch_trash` (`id` int(11) NOT NULL,`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
为 article 表创建触发器
CREATE DEFINER=`dba`@`%` TRIGGER `article_BEFORE_UPDATE` BEFORE UPDATE ON `article` FOR EACH ROW BEGIN-- 此处的逻辑是解决文章状态变为 N 的时候,需要将搜索引擎中对应的数据删除。IF NEW.status = 'N' THENinsert into elasticsearch_trash(id) values(OLD.id);END IF;-- 此处逻辑是修改状态到 Y 的时候,方式elasticsearch_trash仍然存在该文章ID,导致误删除。所以需要删除回收站中得回收记录。IF NEW.status = 'Y' THENdelete from elasticsearch_trash where id = OLD.id;END IF; ENDCREATE DEFINER=`dba`@`%` TRIGGER `article_BEFORE_DELETE` BEFORE DELETE ON `article` FOR EACH ROW BEGIN-- 此处逻辑是文章被删除同事将改文章放入搜索引擎回收站。insert into elasticsearch_trash(id) values(OLD.id); END
接下来我们需要写一个简单地 Shell 每分钟运行一次,从 elasticsearch_trash 数据表中取出数据,然后使用 curl 命令调用 elasticsearch restful 接口,删除被收回的数据。
systemctl stop logstashrm -rf /var/tmp/article*
修改 /etc/logstash/conf.d/jdbc.conf 配置文件
input {jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "123456"schedule => "* * * * *"statement => "select * from article where id > :sql_last_value"use_column_value => truetracking_column => "id"tracking_column_type => "numeric" record_last_run => truelast_run_metadata_path => "/var/tmp/article.last"}
jdbc {jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/cms"jdbc_user => "cms"jdbc_password => "123456"schedule => "* * * * *" #定时cron的表达式,这里是每分钟执行一次statement => "select * from article where ctime > :sql_last_value"use_column_value => truetracking_column => "ctime"tracking_column_type => "timestamp" record_last_run => truelast_run_metadata_path => "/var/tmp/article-ctime.last"}}filter {ruby {code => "event.set('ctime', event.get('[ctime]').time.localtime.strftime('%Y-%m-%d %H:%M:%S'))"}ruby {code => "event.set('mtime', event.get('[mtime]').time.localtime.strftime('%Y-%m-%d %H:%M:%S'))"}}output {elasticsearch {hosts => "localhost:9200"index => "information"document_type => "article"document_id => "%{id}"action => "update"doc_as_upsert => true}
}删除就的index,重新创建,并配置 mapping。
curl -XDELETE http://localhost:9200/informationcurl -XPUT http://localhost:9200/informationcurl -XPOST http://localhost:9200/information/article/_mapping -d'
{"properties": {"title": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"description": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"ctime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"mtime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}
}'curl "http://localhost:9200/information/article/_mapping?pretty"启动 logstash 重新复制数据。
rm -rf /var/log/logstash/* systemctl start logstash
原文出处:Netkiller 系列 手札
本文作者:陈景峯
转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。
相关文章:

佩奇扑街、外星人疯狂!Python 告诉你大年初二应该看哪部电影
作者 | 罗昭成责编 | 唐小引转载自 CSDN资讯(ID:CSDNnews)引言2019 年 1 月,《啥是佩奇》短片在互联网快速传播,各大社交平台形成刷屏之势。不到 24 小时,官博发出的视频已经收获 2800 万次观看,…

【POCO】POCO学习总结(二)——配置选择
使用方法: configure {options} options总结 –help:打印帮助 –config< config_name> 使用给定配置,在poco-1.7.8p3-all/build/config目录下,可以在对应的配置文件中修改编译工具的路径和名字,编译时的选项等。 AIX Darw…

告别排队!用Python定时自动挂号和快捷查询化验报告
作者 | 阿文来源 | 程序人生(ID: coder_life)我什么要做这个事情去年单位体检查出问题来,经过穿刺手术确诊是个慢性肾脏病2期, IGA 肾病三期,可能大家对于这个病并不是很了解,但是另外一个词可能大家都听过…
【POCO】POCO学习总结(三)——交叉编译
最小功能编译 编译选项:–minimal :只构建XML, JSON, 工具 and 网络 1 修改配置文件 $ vi poco-1.7.8p3-all/build/config/ARM-Linux13 LINKMODE ? SHARED 14 TOOL ? arm-linux 15 POCO_TARGET_OSNAME Linux 16 POCO_TARGET_OSARCH ? armv7l 主要…
转:入侵网站必备-sql server
来源:http://www.bitscn.com/plus/view.php?aid28692 1.判断有无注入点 ; and 11 and 12 2.猜表一般的表的名称无非是admin adminuser user pass password 等.. and 0(select count(*) from *) and 0(select count(*) from admin) ---判断是否存在admin这张表 3.猜…
27.5. PROCEDURE ANALYSE()
数据列优化 SELECT ... FROM ... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]]) 原文出处:Netkiller 系列 手札 本文作者:陈景峯 转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。
Linux 日志管理(RHEL7)
日志管理系统和程序的日记本记录系统,程序运行中发生的各种事件通过查看日志,了解及排除故障信息安全控制的依据 内核及系统日志由系统服务rsyslog统一记录/管理日志消息采用文本格式主要记录事件发生的时间,主机,进程,内容常见的日志文件 /var/log/messages 记录内核消息…

汇聚6年思想变迁:知识图谱报告幻灯片大全
本文汇总了中文知识图谱计算会议CCKS报告合集,涵盖从2013年至2018年,共48篇,从中可以看出从Google 2012年推出知识图谱以来,中国学术界及工业界这6年来知识图谱的主流思想变迁。作者 | 刘焕勇来源 | CSDN博客编辑 | apddd项目介绍…
【POCO】POCO学习总结(四)——MinGW编译poco
在window下使用MinGW编译poco 使用MSYS 下载MSYS 官网介绍:http://www.mingw.org/wiki/Getting_Started 官网下载:https://jaist.dl.sourceforge.net/project/mingw/Installer/mingw-get-setup.exe 安装 运行mingw-get-setup.exe,只选择…
辞职之后的思考--激励
本人曾拿过多次奖金,也曾与很多同事沟通过拿奖金的感觉,引发一些思考,这其实也是希望在以后有机会给别人发奖金时做参考之用。 并不是所有人都会有奖金,所以如果我没有奖金其实也没有什么关系,但是,我非…
【linux】串口编程(一)——配置串口
目前遇到的串口编程都是用于通信,很少作为终端显示。以前没有对串口编程做深入研究,本次以libmodbus源码中对串口的设置为例,详解总结串口编程时配置的属性(struct termios) 以libmodbus中_modbus_rtu_connect函数为例…

Playboy封面女郎、互联网第一夫人,程序员们的“钢铁审美”
整理 | 琥珀 出品 | AI科技大本营(ID:rgznai100) 46 年前,《花花公子》(Playboy)的一期杂志封面女郎 Lenna,成为数万“钢铁直男”的梦中女神。然而,这位女性更为人所知的是她在计算机图像处理领…
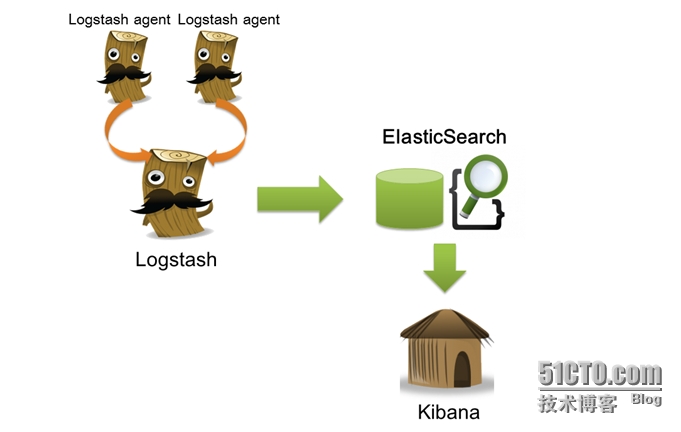
开源实时日志分析ELK
开源实时日志分析ELK 2018-01-04 转自:开源实时日志分析ELK平台部署 日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性…
【linux】串口编程(二)——非阻塞接收
项目中很少会使用阻塞接收,一般都是selectread监听模式来实现非阻塞接收。 使用selece时,需要处理一些异常情况的返回,比如:系统中断产生EINTR错误;超时错误ETIMEDOUT。 使用read时,需要处理读取时可能出现…

使用Photoshop制作网页模板
用图层组管理网页元素首先是在Photoshop中制作好网页的框架。网页中的元素有很多, 像Banner条、文本框、文字、版权、Logo、广告等。尽量把这些相对独立的元素放在不同的图层中,这样方便以后的再编辑。不过图层一多,就 显得很凌乱,…

赵本山:我的时代还没有结束 | Python告诉你
作者 | 丁彦军来源 | 恋习Python(ID: sldata2017)【AI科技大本营按】今年春晚的小品好看吗?没有了赵本山的春晚总觉得少了点什么,然而许久不登春晚舞台的本山大叔借着B站的东风证明了「你大爷还是你大爷」。最近很多人被“改革春…
038——VUE中组件之WEB开发中组件使用场景与定义组件的方式
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>组件之WEB开发中组件使用场景与定义组件的方式</title><script src"vue.js"></script> </head> <body> <…
IronPython系列:Composite Pattern及其实现
最近挺经常做鱼的。对于做鱼的步骤算是熟悉。以烤制为例,主要有三步:洗(Clean)、切(Cut)和烤(Bake)。烤鱼(Bake)又有两个小步:加热(Heat)和烤(Bak…

2019全球AI 100强,中国占独角兽半壁江山,但忧患暗存
整理 | apddd出品 | AI科技大本营(ID:rgznai100)日前,创投研究机构CB Insights发布了年度人工智能企业百强榜单——由100个最具前途的AI公司组成,它们从3000多个候选者中脱颖而出,其业务涵盖人工智能硬件、数据基础设施…
【linux】串口编程(三)——错误处理
一个程序的优劣,可以从多个角度来判断,错误处理就是其中之一。从代码中的错误处理部分,可以体现出一个程序员的水平和修养。 下面还是以libmodbus为例,总结下串口编程中的错误处理。 【1】基础 【1.1】modbus中错误处理有三种&a…

微服务实战之春云与刀客(三)—— 面向接口调用代码结构实例
2019独角兽企业重金招聘Python工程师标准>>> 概述 在上一篇中提到了spring cloud 面向接口调用的开发风格,这一篇会举一个简单的但完整的例子来说明整个代码结构。 代码已上传到 https://github.com/maruixiang/spring-cloud-demo/tree/master/demo1 代码…

如何创建复杂的机器学习项目?
翻译 | 光城责编 | 郭芮转载自CSDN(CSDNnews)scikit-learn提供最先进的机器学习算法。但是,这些算法不能直接用于原始数据。原始数据需要事先进行预处理。因此,除了机器学习算法之外,scikit-learn还提供了一套预处理方…
关闭vmware喇叭报警声
关闭vmware喇叭报警声 在vmware里面安装linux系统后,操作时经常使用tab键或使用VI时经常听到pc speaker突然叫一声,如果正当戴着耳机欣赏音乐,被这么一叫还要吓一跳。下面是解决办法:C:\Documents and Settings\All Users\Applica…
【ubuntu工具】Atom的简介及安装
Atom中文社区:https://atom-china.org/ 知乎atom:https://www.zhihu.com/question/22867204 Atom,是github用nodejs编写的一个编辑器 Atom安装步骤: sudo add-apt-repository ppa:webupd8team/atomsudo aptitude updatesudo a…

破解Win2008口令-ERD6.0
我们在日常使用计算机的过程中,大多都经历过由于忘记口令从而无法进入系统的遭遇。遇到这种问题该如何处理呢?很多朋友一定想到了形形的口令破解工具,这些工具中名气最大的就是ERD Commander Boot CD。 ERD Commander Boot CD是一张可以启动操…
【Qt】Qt5.9.0: error: GL/gl.h: 没有那个文件或目录
重新安装ubuntu,在编译Qt时报错: /home/Qt5.9.0/Examples/Qt-5.9/widgets/widgets/calculator/button.cpp:51: from …/calculator/button.cpp:51: /home/Qt5.9.0/5.9/gcc_64/include/QtGui/qopengl.h:139: error: GL/gl.h: 没有那个文件或目录 解决方…
给Chrome“捉虫”16000个,Google开源bug自检工具
整理 | 一一出品 | AI科技大本营(ID:rgznai100) 在内部开发和使用八年之久,近日,Google 宣布开源 bug 自动化检测工具 ClusterFuzz。ClusterFuzz 是一款提供端到端的自动化模糊测试工具:从错误检测到分类排查&…
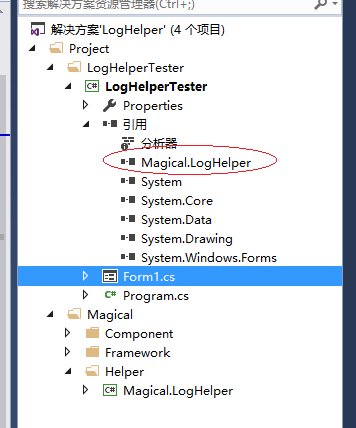
小巧的日志记录组件 - 开源研究系列文章
今天给大家带来一个小巧的日志记录组件LogHelper。这个组件是由Log4Net这个组件的由来而来的,不过只是写入.txt文本文件而已。如果能够对大家的项目有帮助那就更好了。 首先,打开.SLN解决方案,添加引用日志组件。 然后,先对日志组…
.NET开发人员值得关注的七个开源项目
微软近几年在.NET社区开源项目方面投入了相当多的时间和资源,不禁让原本对峙的开源社区阵营大吃一惊,从微软.NET社区中的反应来看,微软.NET开发阵营对开源工具的依赖正日益增强,本文就为所有.NET开发人员介绍7个应该关注的开源项目…

SystemTap了解
SystemTrap是监控和跟踪运行中的Linux内核操作的动态方法。 http://www.ibm.com/developerworks/cn/linux/l-systemtap/ 使用SystemTrap需要使用trap来运行一个stp脚本 如何安装: Centos下直接yum install systemtrap就行了 测试是否可以运行 运行:stap …