如何创建复杂的机器学习项目?

翻译 | 光城
责编 | 郭芮
转载自CSDN(CSDNnews)
scikit-learn提供最先进的机器学习算法。但是,这些算法不能直接用于原始数据。原始数据需要事先进行预处理。因此,除了机器学习算法之外,scikit-learn还提供了一套预处理方法。此外,scikit-learn提供用于流水线化这些估计器的连接器(即变压器,回归器,分类器,聚类器等)。
在本文中,将介绍scikit-learn功能集,允许流水线估计器、评估这些流水线、使用超参数优化调整这些流水线以及创建复杂的预处理步骤。
基本用例:训练和测试分类器
对于第一个示例,我们将在数据集上训练和测试一个分类器。我们将使用此示例来回忆scikit-learn的API。
我们将使用digits数据集,这是一个手写数字的数据集。
# 完成数据集的加载
from sklearn.datasets import load_digits
# return_X_y默认为False,这种情况下则为一个Bunch对象,改为True,可以直接得到(data, target)
X, y = load_digits(return_X_y=True)
X中的每行包含64个图像像素的强度,对于X中的每个样本,我们得到表示所写数字对应的y。
# 下面完成灰度图的绘制
# 灰度显示图像
plt.imshow(X[0].reshape(8, 8), cmap='gray');
# 关闭坐标轴
plt.axis('off')
# 格式化打印
print('The digit in the image is {}'.format(y[0]))
输出:The digit in the image is 0

在机器学习中,我们应该通过在不同的数据集上进行训练和测试来评估我们的模型。train_test_split是一个用于将数据拆分为两个独立数据集的效用函数,stratify参数可强制将训练和测试数据集的类分布与整个数据集的类分布相同。
# 划分数据为训练集与测试集,添加stratify参数,以使得训练和测试数据集的类分布与整个数据集的类分布相同。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
一旦我们拥有独立的培训和测试集,我们就可以使用fit方法学习机器学习模型。我们将使用score方法来测试此方法,依赖于默认的准确度指标。
# 求出Logistic回归的精确度得分
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=5000, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))
Accuracy score of the LogisticRegression is 0.95
scikit-learn的API在分类器中是一致的。因此,我们可以通过RandomForestClassifier轻松替换LogisticRegression分类器。这些更改很小,仅与分类器实例的创建有关。
# RandomForestClassifier轻松替换LogisticRegression分类器
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))
输出:
Accuracy score of the RandomForestClassifier is 0.96
练习
完成接下来的练习:
加载乳腺癌数据集,从sklearn.datasets导入函数load_breast_cancer:
# %load solutions/01_1_solutions.py
使用sklearn.model_selection.train_test_split拆分数据集并保留30%的数据集以进行测试。确保对数据进行分层(即使用stratify参数)并将random_state设置为0:
# %load solutions/01_2_solutions.py
使用训练数据训练监督分类器:
# %load solutions/01_3_solutions.py
使用拟合分类器预测测试集的分类标签:
# %load solutions/01_4_solutions.py
计算测试集的balanced精度,需要从sklearn.metrics导入balanced_accuracy_score:
# %load solutions/01_5_solutions.py
更高级的用例:在训练和测试分类器之前预处理数据
2.1 标准化数据
在学习模型之前可能需要预处理。例如,一个用户可能对创建手工制作的特征或者算法感兴趣,那么他可能会对数据进行一些先验假设。在我们的例子中,LogisticRegression使用的求解器期望数据被规范化。因此,我们需要在训练模型之前标准化数据。为了观察这个必要条件,我们将检查训练模型所需的迭代次数。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=5000, random_state=42)
clf.fit(X_train, y_train)
print('{} required {} iterations to be fitted'.format(clf.__class__.__name__, clf.n_iter_[0]))
输出:
LogisticRegression required 1841 iterations to be fitted
MinMaxScaler变换器用于规范化数据。该标量应该以下列方式应用:学习(即,fit方法)训练集上的统计数据并标准化(即,transform方法)训练集和测试集。 最后,我们将训练和测试这个模型并得到归一化后的数据集。
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
clf = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=1000, random_state=42)
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))
print('{} required {} iterations to be fitted'.format(clf.__class__.__name__, clf.n_iter_[0]))
输出:
Accuracy score of the LogisticRegression is 0.96
LogisticRegression required 190 iterations to be fitted
通过归一化数据,模型的收敛速度要比未归一化的数据快得多(迭代次数变少了)。
2.2 错误的预处理模式
我们强调了如何预处理和充分训练机器学习模型。发现预处理数据的错误方法也很有趣。其中有两个潜在的错误,易于犯错但又很容易发现。
第一种模式是在整个数据集分成训练和测试集之前标准化数据。
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
X_train_prescaled, X_test_prescaled, y_train_prescaled, y_test_prescaled = train_test_split(
X_scaled, y, stratify=y, random_state=42)
clf = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=1000, random_state=42)
clf.fit(X_train_prescaled, y_train_prescaled)
accuracy = clf.score(X_test_prescaled, y_test_prescaled)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))
输出:
Accuracy score of the LogisticRegression is 0.96
第二种模式是独立地标准化训练和测试集。它回来在训练和测试集上调用fit方法。因此,训练和测试集的标准化不同。
scaler = MinMaxScaler()
X_train_prescaled = scaler.fit_transform(X_train)
# 这里发生了变化(将transform替换为fit_transform)
X_test_prescaled = scaler.fit_transform(X_test)
clf = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=1000, random_state=42)
clf.fit(X_train_prescaled, y_train)
accuracy = clf.score(X_test_prescaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))
输出:
Accuracy score of the LogisticRegression is 0.96
2.3 保持简单,愚蠢:使用scikit-learn的管道连接器
前面提到的两个模式是数据泄漏的问题。然而,当必须手动进行预处理时,很难防止这种错误。因此,scikit-learn引入了Pipeline对象。它依次连接多个变压器和分类器(或回归器)。我们可以创建一个如下管道:
from sklearn.pipeline import Pipeline
pipe = Pipeline(steps=[('scaler', MinMaxScaler()),
('clf', LogisticRegression(solver='lbfgs', multi_class='auto', random_state=42))])
我们看到这个管道包含了缩放器(归一化)和分类器的参数。有时,为管道中的每个估计器命名可能会很繁琐,而make_pipeline将自动为每个估计器命名,这是类名的小写。
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(MinMaxScaler(),
LogisticRegression(solver='lbfgs', multi_class='auto', random_state=42, max_iter=1000))
管道将具有相同的API。我们使用fit来训练分类器和socre来检查准确性。然而,调用fit会调用管道中所有变换器的fit_transform方法。调用score(或predict和predict_proba)将调用管道中所有变换器的内部变换。它对应于本文2.1中的规范化过程。
pipe.fit(X_train, y_train)
accuracy = pipe.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(pipe.__class__.__name__, accuracy))
Accuracy score of the Pipeline is 0.96
我们可以使用get_params()检查管道的所有参数。
pipe.get_params()
输出:
{'logisticregression': LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=1000, multi_class='auto',
n_jobs=None, penalty='l2', random_state=42, solver='lbfgs',
tol=0.0001, verbose=0, warm_start=False),
'logisticregression__C': 1.0,
...
...
...}
练习
重用第一个练习的乳腺癌数据集来训练,可以从linear_model导入SGDClassifier。使用此分类器和从sklearn.preprocessing导入的StandardScaler变换器来创建管道,然后训练和测试这条管道。
# %load solutions/02_solutions.py
当更多优于更少时:交叉验证而不是单独拆分
分割数据对于评估统计模型性能是必要的。但是,它减少了可用于学习模型的样本数量。因此,应尽可能使用交叉验证。有多个拆分也会提供有关模型稳定性的信息。
scikit-learn提供了三个函数:cross_val_score,cross_val_predict和cross_validate。 后者提供了有关拟合时间,训练和测试分数的更多信息。 我也可以一次返回多个分数。
from sklearn.model_selection import cross_validate
pipe = make_pipeline(MinMaxScaler(),
LogisticRegression(solver='lbfgs', multi_class='auto',
max_iter=1000, random_state=42))
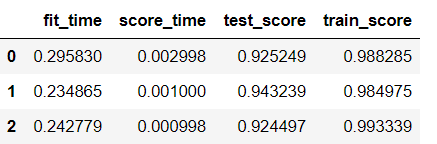
scores = cross_validate(pipe, X, y, cv=3, return_train_score=True)
使用交叉验证函数,我们可以快速检查训练和测试分数,并使用pandas快速绘图。
import pandas as pd
df_scores = pd.DataFrame(scores)
df_scores
输出:
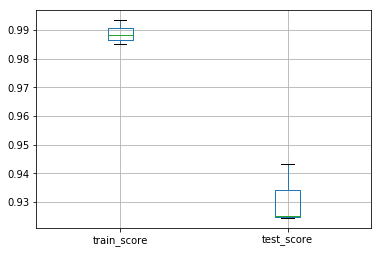
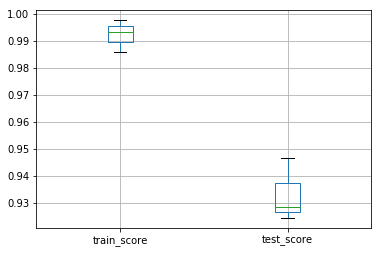
# pandas绘制箱体图
df_scores[['train_score', 'test_score']].boxplot()
输出:
练习
使用上一个练习的管道并进行交叉验证,而不是单个拆分评估。
# %load solutions/03_solutions.py
超参数优化:微调管道内部
有时希望找到管道组件的参数,从而获得最佳精度。我们已经看到我们可以使用get_params()检查管道的参数。
pipe.get_params()
输出:
{'logisticregression': LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=1000, multi_class='auto',
n_jobs=None, penalty='l2', random_state=42, solver='lbfgs',
tol=0.0001, verbose=0, warm_start=False),
'logisticregression__C': 1.0,
...
...
...}
可以通过穷举搜索来优化超参数。GridSearchCV 提供此类实用程序,并通过参数网格进行交叉验证的网格搜索。
如下例子,我们希望优化LogisticRegression分类器的C和penalty参数。
from sklearn.model_selection import GridSearchCV
pipe = make_pipeline(MinMaxScaler(),
LogisticRegression(solver='saga', multi_class='auto',
random_state=42, max_iter=5000))
param_grid = {'logisticregression__C': [0.1, 1.0, 10],
'logisticregression__penalty': ['l2', 'l1']}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3, n_jobs=-1, return_train_score=True)
grid.fit(X_train, y_train)
输出:
GridSearchCV(cv=3, error_score='raise-deprecating',
...
...
...
scoring=None, verbose=0)
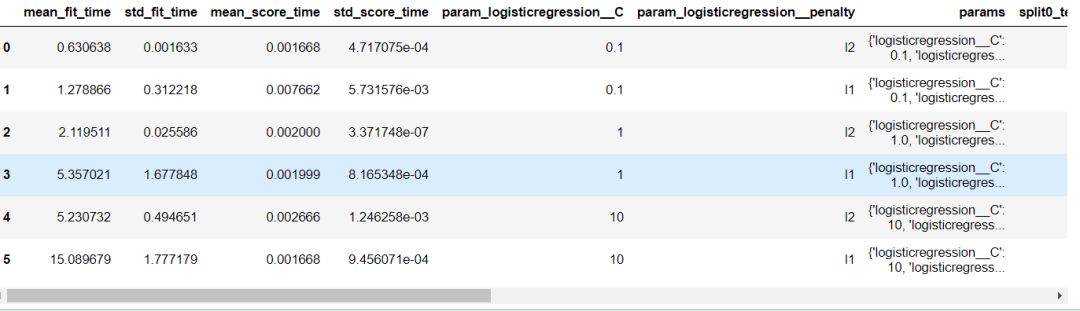
在拟合网格搜索对象时,它会在训练集上找到最佳的参数组合(使用交叉验证)。 我们可以通过访问属性cv_results_来得到网格搜索的结果。 通过这个属性允许我们可以检查参数对模型性能的影响。
df_grid = pd.DataFrame(grid.cv_results_)
df_grid
输出:
默认情况下,网格搜索对象也表现为估计器。一旦它被fit后,调用score将超参数固定为找到的最佳参数。
grid.best_params_
输出:
{'logisticregression__C': 10, 'logisticregression__penalty': 'l2'}
此外,可以将网格搜索称为任何其他分类器以进行预测。
accuracy = grid.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(grid.__class__.__name__, accuracy))
Accuracy score of the GridSearchCV is 0.96
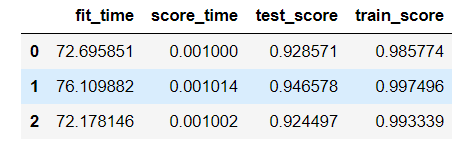
最重要的是,我们只对单个分割进行网格搜索。 但是,如前所述,我们可能有兴趣进行外部交叉验证,以估计模型的性能和不同的数据样本,并检查性能的潜在变化。 由于网格搜索是一个估计器,我们可以直接在cross_validate函数中使用它。
scores = cross_validate(grid, X, y, cv=3, n_jobs=-1, return_train_score=True)
df_scores = pd.DataFrame(scores)
df_scores
输出:
练习
重复使用乳腺癌数据集的先前管道并进行网格搜索以评估hinge(铰链) and log(对数)损失之间的差异。此外,微调penalty。
# %load solutions/04_solutions.py
总结:我的scikit-learn管道只有不到10行代码(跳过import语句)
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_validate
pipe = make_pipeline(MinMaxScaler(),
LogisticRegression(solver='saga', multi_class='auto', random_state=42, max_iter=5000))
param_grid = {'logisticregression__C': [0.1, 1.0, 10],
'logisticregression__penalty': ['l2', 'l1']}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3, n_jobs=-1)
scores = pd.DataFrame(cross_validate(grid, X, y, cv=3, n_jobs=-1, return_train_score=True))
scores[['train_score', 'test_score']].boxplot()
输出:
异构数据:当您使用数字以外的数据时
到目前为止,我们使用scikit-learn来训练使用数值数据的模型。
X
输出:
array([[ 0., 0., 5., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.],
[ 0., 0., 0., ..., 16., 9., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 2., ..., 12., 0., 0.],
[ 0., 0., 10., ..., 12., 1., 0.]])
X是仅包含浮点值的NumPy数组。但是,数据集可以包含混合类型。
import os
data = pd.read_csv(os.path.join('data', 'titanic_openml.csv'), na_values='?')
data.head()
输出:
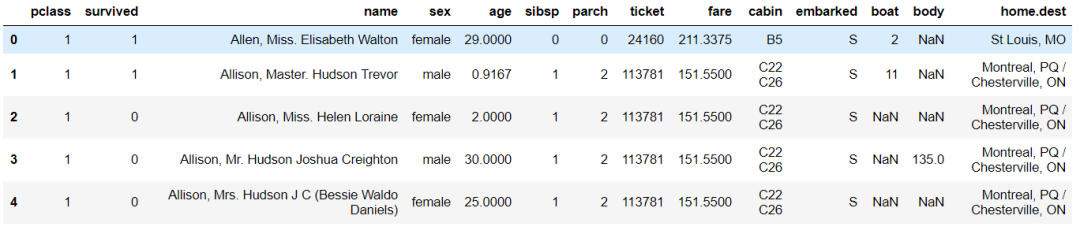
泰坦尼克号数据集包含分类、文本和数字特征。我们将使用此数据集来预测乘客是否在泰坦尼克号中幸存下来。
让我们将数据拆分为训练和测试集,并将幸存列用作目标。
y = data['survived']
X = data.drop(columns='survived')
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
首先,可以尝试使用LogisticRegression分类器,看看它的表现有多好。
clf = LogisticRegression()
clf.fit(X_train, y_train)
哎呀,大多数分类器都设计用于处理数值数据。因此,我们需要将分类数据转换为数字特征。最简单的方法是使用OneHotEncoder对每个分类特征进行读热编码。让我们以sex与embarked列为例。请注意,我们还会遇到一些缺失的数据。我们将使用SimpleImputer用常量值替换缺失值。
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
ohe = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder())
X_encoded = ohe.fit_transform(X_train[['sex', 'embarked']])
X_encoded.toarray()
输出:
array([[0., 1., 0., 0., 1., 0.],
[0., 1., 1., 0., 0., 0.],
[0., 1., 0., 0., 1., 0.],
...,
[0., 1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1., 0.],
[1., 0., 0., 0., 1., 0.]])
这样,可以对分类特征进行编码。但是,我们也希望标准化数字特征。因此,我们需要将原始数据分成2个子组并应用不同的预处理:(i)分类数据的独热编;(ii)数值数据的标准缩放(归一化)。我们还需要处理两种情况下的缺失值: 对于分类列,我们将字符串'missing_values'替换为缺失值,该字符串将自行解释为类别。 对于数值数据,我们将用感兴趣的特征的平均值替换缺失的数据。
分类数据的独热编:
col_cat = ['sex', 'embarked']
col_num = ['age', 'sibsp', 'parch', 'fare']
X_train_cat = X_train[col_cat]
X_train_num = X_train[col_num]
X_test_cat = X_test[col_cat]
X_test_num = X_test[col_num]
数值数据的标准缩放(归一化):
from sklearn.preprocessing import StandardScaler
scaler_cat = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder())
X_train_cat_enc = scaler_cat.fit_transform(X_train_cat)
X_test_cat_enc = scaler_cat.transform(X_test_cat)
scaler_num = make_pipeline(SimpleImputer(strategy='mean'), StandardScaler())
X_train_num_scaled = scaler_num.fit_transform(X_train_num)
X_test_num_scaled = scaler_num.transform(X_test_num)
我们应该像在本文2.1中那样在训练和测试集上应用这些变换。
import numpy as np
from scipy import sparse
X_train_scaled = sparse.hstack((X_train_cat_enc,
sparse.csr_matrix(X_train_num_scaled)))
X_test_scaled = sparse.hstack((X_test_cat_enc,
sparse.csr_matrix(X_test_num_scaled)))
转换完成后,我们现在可以组合所有数值的信息。最后,我们使用LogisticRegression分类器作为模型。
clf = LogisticRegression(solver='lbfgs')
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))
输出:
Accuracy score of the LogisticRegression is 0.79
上面首先转换数据然后拟合/评分分类器的模式恰好是本节2.1的模式之一。因此,我们希望为此目的使用管道。
但是,我们还希望对矩阵的不同列进行不同的处理。应使用ColumnTransformer转换器或make_column_transformer函数。它用于在不同的列上自动应用不同的管道。
from sklearn.compose import make_column_transformer
pipe_cat = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder(handle_unknown='ignore'))
pipe_num = make_pipeline(SimpleImputer(), StandardScaler())
preprocessor = make_column_transformer((col_cat, pipe_cat), (col_num, pipe_num))
pipe = make_pipeline(preprocessor, LogisticRegression(solver='lbfgs'))
pipe.fit(X_train, y_train)
accuracy = pipe.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(pipe.__class__.__name__, accuracy))
输出:
Accuracy score of the Pipeline is 0.79
此外,它还可以被使用在另一个管道。 因此,我们将能够使用所有scikit-learn实用程序作为cross_validate或GridSearchCV。
pipe.get_params()
输出:
{'columntransformer': ColumnTransformer(n_jobs=None, remainder='drop', sparse_threshold=0.3,
transformer_weights=None,
transformers=[('pipeline-1', Pipeline(memory=None,
...]}
合并及可视化:
pipe_cat = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder(handle_unknown='ignore'))
pipe_num = make_pipeline(StandardScaler(), SimpleImputer())
preprocessor = make_column_transformer((col_cat, pipe_cat), (col_num, pipe_num))
pipe = make_pipeline(preprocessor, LogisticRegression(solver='lbfgs'))
param_grid = {'columntransformer__pipeline-2__simpleimputer__strategy': ['mean', 'median'],
'logisticregression__C': [0.1, 1.0, 10]}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5, n_jobs=-1)
scores = pd.DataFrame(cross_validate(grid, X, y, scoring='balanced_accuracy', cv=5, n_jobs=-1, return_train_score=True))
scores[['train_score', 'test_score']].boxplot()
输出:
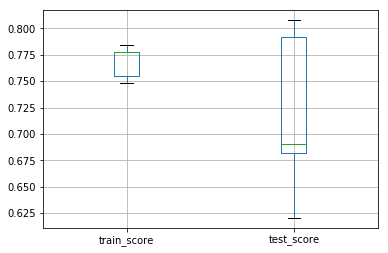
练习
完成接下来的练习:
加载位于./data/adult_openml.csv中的成人数据集,制作自己的ColumnTransformer预处理器,并用分类器管道化它,对其进行微调并在交叉验证中检查预测准确性。
使用pd.read_csv读取位于./data/adult_openml.csv中的成人数据集:
# %load solutions/05_1_solutions.py
将数据集拆分为数据和目标,目标对应于类列。对于数据,删除列fnlwgt,capitalgain和capitalloss:
# %load solutions/05_2_solutions.py
目标未编码,使用sklearn.preprocessing.LabelEncoder对类进行编码:
# %load solutions/05_3_solutions.py
创建一个包含分类列名称的列表,同样,对数值数据也一样:
# %load solutions/05_4_solutions.py
创建一个管道以对分类数据进行读热编码,使用KBinsDiscretizer作为数值数据,从sklearn.preprocessing导入它:
# %load solutions/05_5_solutions.py
使用make_column_transformer创建预处理器,应该将好的管道应用于好的列:
# %load solutions/05_6_solutions.py
使用LogisticRegression分类器对预处理器进行管道传输。随后定义网格搜索以找到最佳参数C.使用cross_validate在交叉验证方案中训练和测试此工作流程:
# %load solutions/05_7_solutions.py
原文链接:
https://github.com/glemaitre/pyparis-2018-sklearn。
译者简介:光城,研一,个人公众号:guangcity,博客:http://light-city.me/, 个人研究方向知识图谱,正致力于将机器学习运用到KG当中。
(本文仅代表作者观点,转载请联系原作者)
征稿
推荐阅读:
Playboy封面女郎、互联网第一夫人,程序员们的“钢铁审美”
2019全球AI 100强,中国占独角兽半壁江山,但忧患暗存
“百练”成钢:NumPy 100练
赵本山:我的时代还没有结束 | Python告诉你
“不厚道”的程序员:年后第一天上班就提辞职
Python 爬取了猫眼 47858 万条评论,告诉你《飞驰人生》值不值得看?!
Facebook神秘区块链部门首次收购,开放这些职位,你的技能符合吗?
写给程序员的裁员防身指南
这4门AI网课极具人气,逆天好评!(附代码+答疑)

点击“阅读原文”,打开CSDN APP 阅读更贴心!
相关文章:

关闭vmware喇叭报警声
关闭vmware喇叭报警声 在vmware里面安装linux系统后,操作时经常使用tab键或使用VI时经常听到pc speaker突然叫一声,如果正当戴着耳机欣赏音乐,被这么一叫还要吓一跳。下面是解决办法:C:\Documents and Settings\All Users\Applica…
【ubuntu工具】Atom的简介及安装
Atom中文社区:https://atom-china.org/ 知乎atom:https://www.zhihu.com/question/22867204 Atom,是github用nodejs编写的一个编辑器 Atom安装步骤: sudo add-apt-repository ppa:webupd8team/atomsudo aptitude updatesudo a…

破解Win2008口令-ERD6.0
我们在日常使用计算机的过程中,大多都经历过由于忘记口令从而无法进入系统的遭遇。遇到这种问题该如何处理呢?很多朋友一定想到了形形的口令破解工具,这些工具中名气最大的就是ERD Commander Boot CD。 ERD Commander Boot CD是一张可以启动操…
【Qt】Qt5.9.0: error: GL/gl.h: 没有那个文件或目录
重新安装ubuntu,在编译Qt时报错: /home/Qt5.9.0/Examples/Qt-5.9/widgets/widgets/calculator/button.cpp:51: from …/calculator/button.cpp:51: /home/Qt5.9.0/5.9/gcc_64/include/QtGui/qopengl.h:139: error: GL/gl.h: 没有那个文件或目录 解决方…
给Chrome“捉虫”16000个,Google开源bug自检工具
整理 | 一一出品 | AI科技大本营(ID:rgznai100) 在内部开发和使用八年之久,近日,Google 宣布开源 bug 自动化检测工具 ClusterFuzz。ClusterFuzz 是一款提供端到端的自动化模糊测试工具:从错误检测到分类排查&…
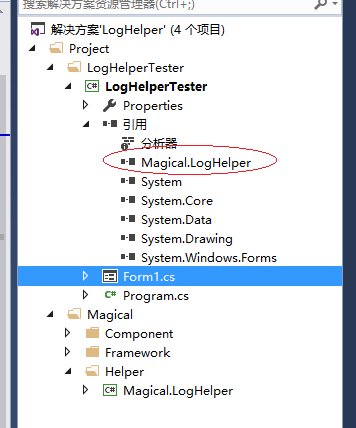
小巧的日志记录组件 - 开源研究系列文章
今天给大家带来一个小巧的日志记录组件LogHelper。这个组件是由Log4Net这个组件的由来而来的,不过只是写入.txt文本文件而已。如果能够对大家的项目有帮助那就更好了。 首先,打开.SLN解决方案,添加引用日志组件。 然后,先对日志组…
.NET开发人员值得关注的七个开源项目
微软近几年在.NET社区开源项目方面投入了相当多的时间和资源,不禁让原本对峙的开源社区阵营大吃一惊,从微软.NET社区中的反应来看,微软.NET开发阵营对开源工具的依赖正日益增强,本文就为所有.NET开发人员介绍7个应该关注的开源项目…

SystemTap了解
SystemTrap是监控和跟踪运行中的Linux内核操作的动态方法。 http://www.ibm.com/developerworks/cn/linux/l-systemtap/ 使用SystemTrap需要使用trap来运行一个stp脚本 如何安装: Centos下直接yum install systemtrap就行了 测试是否可以运行 运行:stap …

Windows 95被做成了App,可玩扫雷和纸牌
6 秒重温 Windows95 开机画面 作者 | 琥珀 出品 | AI科技大本营(ID:rgznai100) “看到 Win95,再看到仙剑 DOS 的画面,突然有种想哭的感觉,小时候帮李逍遥实现了仗剑江湖的愿望,但自己却没有实现自己的愿望…
【Ubuntu】虚拟机VirtualBox安装win7完整步骤
在Ubuntu16.04中使用VirtualBox安装win7,亲测可以完美使用; 完整步骤参见如下链接: 1、VirtualBox安装步骤:http://www.xitongcheng.com/jiaocheng/xtazjc_article_23804.html 2、win7镜像下载:http://www.xitongcheng.com/jia…

全栈AI工程师指南,DIY一个识别手写数字的web应用
作者 | shadow chi本文经授权转载自 无界社区mixlab(ID:mix-lab)网上大量教程都是教如何训练模型,往往我们只学会了训练模型,而实际应用的环节是缺失的。def AIFullstack( ):本文从「…
mysql 中limit 用法!!
select * from mydb where id limit i,j; 意思就是从第i行开始,检索出j行,结束!主要用于分页技术中,比如说我们一页现实10行,可以这样做:select * from mydb where id order by id desc limit $page,10($pa…
【Qt】Qt动态库和静态库的创建和使用
动态库(共享库)的创建 在Qt Creator中新建项目,选择Library 点击“Choose”进入下一步 选择创建库的类型:共享库 选择Kit套件 选择需要的模块 配置工程路径、名字等 Qt Creator自动创建的文件 我配置的动态库名字为:Share pro文件内容
23.3. Ethernet0/0 - Wan口配置
23.3.1. DHCP 动态IP地址 <Netkiller>system-view System View: return to User View with CtrlZ.interface Ethernet0/0port link-mode routenat outboundip address dhcp-allocipsec policy navigator #[Netkiller]display dhcp client Ethernet0/0 DHCP client inform…

用Python解锁“吃鸡”正确姿势
大吉大利,今晚吃鸡~ 今天跟朋友玩了几把吃鸡,经历了各种死法,还被嘲笑说论女生吃鸡的100种死法,比如被拳头抡死、跳伞落到房顶边缘摔死 、把吃鸡玩成飞车被车技秀死、被队友用燃烧瓶烧死的。这种游戏对我来说就是一个让我明白原来…

Oracle Grid Control 10.2.0.5 for Linux 安装和配置指南
一、概述:Grid Control的组件包括Management Agent, Management Service (OMS), Management Repository. 系统架构如下: 10g oem是一个基于web的管理架构,这和10g之前的笨重的java客户端有很大的区别。我们可以从2方面来研究它的架构,一个是管…
【Qt】Qt Plugin:Qt插件创建与使用
插件接口设计 以a+b=c的接口为例:int add(int a, int b) 在 主项目 工程中创建接口文件(一个头文件)eg:Add.h #ifndef ADD_H #define ADD_H#include <QtPlugin> class Add { public:virtual int add(int a, int b)= 0;//纯虚函数 }; Q_DECLARE_INTERFACE(Add, &qu…
9.5. SELINUX
禁用SElinux编辑/etc/selinux/config,修改如下内容: SELINUXdisabled使用命令 getenforce setenforce 0lokkit --selinuxdisabledPlease enable JavaScript to view the <a href"http://disqus.com/?ref_noscript">comments powered by…
说说我们为什么需要加班
做软件这行,加班就是家常便饭。做了这么多年程序员,我还真没听哪个说公司不加班的,碰见好的不时、偶尔加班,差的就是无尽的加。加班是那么的邪恶、令人作呕,但又无法抗拒,它仿佛就像嫖客患上梅毒——摆脱不…

为 Django admin 登录页添加验证码
为什么80%的码农都做不了架构师?>>> 历史原因,使用上古版本 django 1.6.5,但新版本应该大同小异 首先添加自定义后台模块app, 如adm,并添加到 INSTALLED_APPS 下。 假设处理自定义登录的view是 apps/adm/v…

手机芯片谁是AI之王?高通、联发科均超华为
整理 | apddd出品 | AI科技大本营(ID:rgznai100)尽管相当数量的人工智能服务,是由云计算网络提供,但在响应低延迟、保护隐私、应用场景等方面,手机AI芯片无可替代。例如人脸解锁,图像增强、识别,…
【linux】error: stdio.h: No such file or directory
ubuntu 默认没有C和C编译环境 ubuntu 默认没有C和C编译环境,新装的ubuntu,使用gcc编译时,会报错,找不到某某头文件等。在编译一个demo,如hello world时,会报错: error: stdio.h: No such file …
SqlParameter的用法
1。一些面例子为例:List<SqlParameter> listp new List<SqlParameter>();listp.Add(new SqlParameter("userid", userid));string sql "select * from userbooks where useriduserid";在执行sql语句时 listp.Add(new SqlParamete…

程序员如何用“撞针“拯救35亿地球人?
春节假期即将结束,有多少程序员朋友已经离开家乡在返回北上广深等工作所在城市的路上?有多少程序员已经开工大吉开始了新一年的代码征程?回首这一个春节,8 部电影在大年初一齐上线,《流浪地球》在前期预售票房远不如《…
【linux】printf在终端打印彩色hello world
代码 #include <stdio.h>#define NONE "\033[m" #define RED "\033[0;32;31m" #define GREEN "\033[0;32;32m" #define BLUE "\033[0;32;34m" #define YELLOW "\033[1;33m&qu…

看腾讯运维应对“18岁照片全民怀旧”事件的方案,你一定不后悔!
作者丨魏旸:腾讯高级工程师,15年运维经验的老专家,负责QQ空间、微云、QQ空间相册的运维工作,亲历8亿军装照、QQ空间异地多活建设等重大架构升级事件。2017年12月30日,元旦假期的第一天,你的朋友圈被18岁照片…
基于svnserve的SVN服务器(windows下安装与配置)
基于svnserve的SVN服务器(windows下安装与配置)关键字: svn 安装SVNserve 从http://subversion.tigris.org/servlets/ProjectDocumentList?folderID91得到最新版本的Subversion。 如果你已经安装了Subversion,svnserve已经运行,你需要在继续之前把它停…
【c语言】C语言配置文件解析库——iniparser
转载自:http://blog.csdn.net/u011192270/article/details/49339071 C语言配置文件解析库——iniparser前言:在对项目的优化时,发现Linux下没有专门的供给C语言使用的配置文件函数,于是搜索到了iniparser库,可以像那些…
利用java虚拟机的工具jmap分析java内存情况
2019独角兽企业重金招聘Python工程师标准>>> 有时候碰到性能问题,比如一个java application出现out of memory,出现内存泄漏的情况,再去修改bug可能会变得异常复杂,利用工具去分析整个java application 内存占用情况,然…

代码测试意味着完全消灭了Bug?
日前,一位名为 Jens Neuse 的开发者在改进其 graphql 解析库的过程中,发现词法分析器和解析器中存在很多的低效率,因此不得不重构完整的代码库(https://medium.com/jens.neuse/want-to-write-good-unit-tests-in-go-dont-panic-or…